大模型领域主流向量模型相似度算法、架构及指标对比
大模型领域主流向量模型相似度算法、架构及指标对比
引言
语义向量模型(Semantic Vector Model)是自然语言处理(NLP)领域的核心技术,其核心功能在于将词汇、句子或文档等文本单元映射为高维向量,从而在数学空间中实现语义信息的量化表达[1]。通过计算向量间的距离(如余弦相似度),该模型能够有效衡量文本语义的相似性,为搜索引擎、情感分析、机器翻译、信息检索、文档分类及聚类等众多NLP实际任务提供了关键技术支撑[1][2][3]。
在技术发展进程中,面对“同义表达”“句式改写”等语义级理解需求,传统关键词或哈希方法逐渐显现局限性,而以BERT为代表的上下文模型与向量相似度技术的结合,成为语义级文本理解的主流解决方案[2]。近年来,随着技术的持续演进,新兴模型如BGE-M3等在多语言处理、多粒度检索等场景中取得显著突破,进一步拓展了语义向量模型的应用边界[3]。
为全面把握当前大模型领域向量模型的技术现状,本报告将围绕主流相似度算法、模型架构及评价指标展开系统性对比分析,为相关研究与应用提供参考。
主流向量模型概述
经典模型延续与优化
在大模型快速发展的背景下,经典向量模型通过持续优化仍展现出显著的生命力和不可替代性。这些模型不仅为新兴技术提供了基础框架,其在特定场景下的稳定性、效率及部署轻量化优势,使其在2025年的实际应用中仍占据重要地位。
Sentence-BERT(S-BERT)作为BERT的重要变体,针对句子级向量生成进行了专门优化,其核心改进在于引入池化层(如均值池化策略),将Transformer输出的词向量聚合为固定长度的句子向量,有效避免了传统BERT计算句子相似度时需两两比较的效率瓶颈[2][4]。该模型基于自然语言推理(NLI)数据(如SNLI、MNLI)训练,通过预测句子对的逻辑关系(蕴含、中立、矛盾)优化向量表示,生成的句子嵌入在语义检索、聚类等任务中表现稳定,且部署轻量,成为语义相似度计算的经典基线[4]。
对比学习框架下的SimCSE及其改进模型进一步推动了无监督句子嵌入的发展。SimCSE通过Dropout机制对同一输入生成不同扰动作为正例,实现无监督训练,但存在“长度偏置”问题,即模型可能过度依赖句子长度而非语义信息进行匹配[2]。ESimCSE针对这一缺陷提出“单词重复”数据增强策略,通过随机重复句子中的单词生成长度不同的正例,并引入动量对比学习增加负例多样性,在BERT-base模型上的STS(语义文本相似度)数据集平均性能提升2.02%,显著增强了模型对语义细节的捕捉能力[2]。
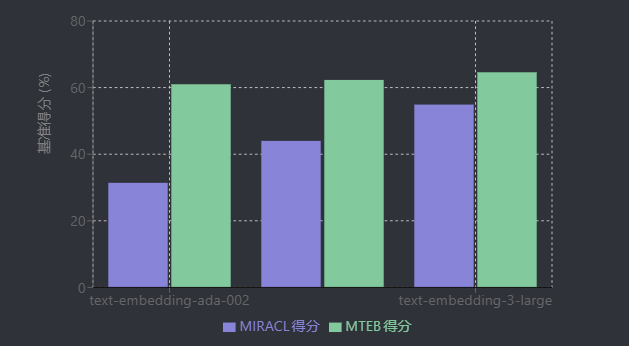
经典预训练语言模型的延续优化还体现在架构改进与性能迭代上。以BERT为代表的双向上下文模型,通过变体如RoBERTa(去除NSP任务、动态掩码、扩大训练数据)、ALBERT(跨层参数共享减少参数量)、StructBERT(融入语言结构信息)等持续提升性能,其中RoBERTa较原始BERT在多项任务上性能提升2-20%[5]。OpenAI的经典文本嵌入模型(如text-embedding-ada-002)也通过迭代优化(如text-embedding-3-small/large)实现性能与效率的平衡:text-embedding-3-small在MIRACL多语言检索基准得分从31.4%提升至44.0%,价格降低5倍;text-embedding-3-large则通过3072维向量将MTEB英文任务得分提升至64.6%,展现了经典架构通过参数调整和训练策略优化的持续竞争力[6]。
尽管新兴大模型在复杂任务上表现突出,经典模型在特定领域的不可替代性依然显著。例如,轻量化模型FastText通过子词嵌入解决OOV问题,训练速度快且适用于多语言场景;Sentence-BERT因部署成本低、效果稳定,仍是中小规模语义检索系统的首选[1]。实际应用中,即使在2025年,开源社区仍广泛使用BGE-M3等经典优化模型,印证了传统模型在成本敏感型任务、边缘设备部署及数据资源有限场景下的核心价值[7]。
新兴模型技术突破
近年来,向量模型领域涌现出多项技术突破,通过创新架构设计、训练策略与跨模态融合,显著提升了语义表征能力与任务适应性。谷歌Gemini Embedding模型基于双向Transformer编码器架构,采用Matryoshka表示学习(MRL)技术与多维度NCE损失函数,支持768/1536/3072维动态嵌入输出,允许用户根据存储约束截断向量同时保持核心语义信息。该模型在MTEB多语言榜单中以68.37分超越OpenAI同类模型(58.93分),并将语言覆盖范围扩展至100+种(前代模型的两倍),8k token输入长度进一步增强了长文本处理能力[8][9]。
| 模型 | 开发机构 | MTEB得分 | 语言支持 | 输入长度 | 主要创新点 | 数据来源 |
|---|---|---|---|---|---|---|
| Gemini Embedding | 68.37 | 100+ | 8k token | MRL技术, 多维度NCE损失 | [8] | |
| Qwen3-Embedding(8B) | 阿里 | 70.58 | 100+ | - | LLM合成数据, 三阶段训练, 指令感知 | [10] |
| Jina Embeddings V4 | Jina AI | 66.49* | - | 32k token | 多模态处理, LoRA适配器, 单/多向量输出 | [13] |
| NV-Embed | NVIDIA | 69.32 | - | - | latent attention layer, 两阶段对比学习 | [14] |
*注:Jina的MTEB分数为多语言检索专项得分
阿里Qwen3-Embedding系列则通过大语言模型(LLM)驱动的合成数据生成突破标注数据限制,构建了三阶段训练流程:首先利用Qwen3 LLM生成1.5亿对弱监督查询-文档对进行对比预训练,再筛选1200万高质量数据结合700万榜单数据进行监督微调(SFT),最终通过球面线性插值(slerp)模型合并技术提升鲁棒性。该系列提供0.6B/4B/8B多尺寸模型,支持指令感知与动态维度调整(最小32维),在MTEB多语言基准测试中以70.58分位列榜首,代码检索任务得分80.68,超越Gemini-Embedding等专有模型[7][10][11][12]。
Jina Embeddings V4则开创了多模态向量模型新范式,基于Qwen2.5-VL-3B-Instruct多模态语言模型构建,首次实现文本与图像的同步处理,支持32768 token文本上下文与2000万像素富视觉文档输入。其架构集成三个6000万参数的LoRA适配器(检索、文本匹配、代码任务专用),并创新提供单向量(2048维,可截断至128维)与多向量(每token 128维)双输出模式,适配迟交互检索策略。在ViDoRe(90.2分)、CLIP(84.1分)等多模态基准中表现顶尖,多语言检索性能较OpenAI text-embedding-3-large提升12%(66.49 vs 59.27),长文档任务性能提升28%(67.11 vs 52.42),综合能力与Gemini-Embedding-001并驾齐驱[13]。
此外,智源BGE-M3模型通过整合稠密/稀疏/多向量检索能力,实现8192 token超长输入与100+语言统一表征,在MIRACL、MKQA等跨语言基准中超越OpenAI Text-Embedding-003;NVIDIA NV-Embed引入latent attention layer简化序列表示,并采用两阶段对比学习(in-batch负例+非检索任务混合训练),以69.32的MTEB NDCG@10分刷新准确率纪录,共同推动向量模型向多功能、高效率、跨模态方向发展[3][14]。
相似度算法对比
余弦相似度主导地位
余弦相似度在大模型向量相似度计算中占据主导地位,其核心优势源于对向量方向差异的精准捕捉、高维空间的稳定性及与语义匹配任务的内在契合性。从本质上看,余弦相似度通过计算向量空间中两个向量夹角的余弦值衡量相似性,取值范围为[-1, 1],值越接近1表明方向越一致,语义相似度越高[15][16][17]。
对向量长度不敏感是其关键特性之一。该算法通过向量点积与模长乘积的比值消除向量长度影响,更关注语义方向而非数值规模。例如,在评委打分场景中,若第一个评委打分(10,8,9),第二个评委打分(4,2,3),尽管评分绝对值差异显著,但两者对歌手实力的排序逻辑一致,余弦相似度会将其归为相似类别;而欧氏距离可能因数值绝对值接近将第一评委与排序逻辑相反的第三评委(8,10,9)归为一类,此时余弦相似度的结果更符合实际语义需求[18]。在文本领域,当两段文本长度差异较大但内容相近时,余弦相似度仍能准确反映语义相似性,而欧氏距离可能因向量模长差异给出误导性结果[19]。
高维空间稳定性使其在大模型向量场景中表现突出。文本、图像等数据经大模型编码后通常形成高维稀疏向量,余弦相似度可有效忽略零值维度干扰,聚焦有效特征方向。例如,在长文本Embedding的“迟分”策略验证中,通过余弦相似度评估发现,优化后句子与核心词“柏林”的相似度显著提升(如“其超过385万人口使其成为欧盟人口最多的城市,以市区人口计”的相似性从0.708提升至0.825),印证了其在高维语义特征评估中的可靠性[20]。此外,在Word2Vec等向量模长归一化场景中,余弦相似度与欧氏距离存在单调关系(||A−B||₂ = √(2(1−cos(A,B)))),进一步保障了高维空间中相似性排序的稳定性[19]。
与对比学习目标的深度契合推动了其在语义匹配任务中的广泛应用。以CoSENT(Cosine Sentence Transformer)模型为例,其核心机制是通过余弦相似度优化排序损失函数,最大化正例句子对(如语义相似的句子)的余弦相似度,同时最小化负例句子对的余弦相似度,损失函数定义为L=max(0,−cos(vi,vj)+cos(vi,vk)+α)(其中vi、vj为正例向量,vk为负例向量,α为间隔超参数)[4][21]。这种设计直接对齐语义匹配任务目标,使CoSENT在中文短文本匹配、语义搜索等任务中表现优异。此外,Qwen3-Embedding模型在数据筛选阶段也采用余弦相似度(保留相似度大于0.7的样本),进一步体现其在模型训练流程中的核心地位[7]。
在语义匹配任务中,余弦相似度的优势可通过具体案例直观体现。例如,句子“我喜欢吃苹果”与“我爱吃苹果”的余弦相似度达0.9966,而与语义相反的“我不喜欢吃苹果”相似度为0.8603,准确区分了细微语义差异[22];“人工智能发展前景”与“AI技术的未来趋势”的相似度为0.92,“机器学习”与“深度学习”的相似度亦达0.92,有效捕捉了专业术语间的语义关联[23][24]。在日常对话场景中,“你今天吃饭了吗?”与“你吃过饭没?”的余弦相似度为0.89,成功识别了口语化表达的同义关系[25]。
| 句子1 | 句子2 | 余弦相似度 | 语义关系 | 数据来源 |
|---|---|---|---|---|
| “我喜欢吃苹果” | “我爱吃苹果” | 0.9966 | 同义表达 | [22] |
| “我喜欢吃苹果” | “我不喜欢吃苹果” | 0.8603 | 语义相反 | [22] |
| “人工智能发展前景” | “AI技术的未来趋势” | 0.92 | 专业术语同义转换 | [1] |
| “机器学习” | “深度学习” | 0.92 | 专业术语关联 | [23] |
| “你今天吃饭了吗?” | “你吃过饭没?” | 0.89 | 口语化同义表达 | [2] |
| "其超过385万人口…"¹ | "柏林"核心词 | 0.825 | 文本片段与核心词关联 | [20] |
| "这座城市也是德国…"² | "柏林"核心词 | 0.850 | 文本片段与核心词关联 | [20] |
注:
- “其超过385万人口使其成为欧盟人口最多的城市,以市区人口计”
- “这座城市也是德国的一个州,在面积上是全国第三小的州”
然而,余弦相似度并非万能,其局限性主要体现在无法捕捉数值绝对差异。由于仅关注向量方向,当任务需考虑特征数值大小(如用户评分的绝对偏好强度)时,余弦相似度可能失效。例如,用户评分向量(1,2)和(4,5)未调整时余弦相似度为0.98,但减去均值(消除评分偏差)后相似度变为-0.8,表明其对数值分布敏感,需结合业务场景进行预处理[26]。此外,其对极度稀疏向量的区分能力较弱,在零值维度占比极高的场景中,可能出现“维度灾难”导致相似性评估失真[16]。因此,在实际应用中,需根据任务特性(如是否关注数值大小、数据稀疏程度),考虑与欧氏距离等指标结合使用,以实现更全面的相似性评估。
欧氏距离与混合策略
欧氏距离作为n维向量空间中两点之间的直线距离度量方法,其核心价值在于能够有效捕捉向量间的绝对数值差异和全局特征,适用于需关注维度数值大小差异的分析场景。在用户活跃度分析中,当以登陆次数和平均观看时长为特征向量时,欧氏距离可直接反映用户活跃度的绝对差异,例如通过量化不同用户在这两个维度上的数值偏离程度,实现用户活跃度的相似度评估[18][19]。此外,欧氏距离在图像处理(如像素值长度有实际意义的场景)、物理空间距离计算(需直接反映绝对距离)、低维稠密数据的全局差异衡量及异常检测(通过距离偏差识别离群点)等领域也展现出独特优势[27][28]。与余弦距离侧重方向上的相对差异不同,欧氏距离更适合处理连续空间中的距离计算任务,如在人脸识别中使用FaceNet、ArcFace等模型时,能有效衡量嵌入向量的相似性[28]。
混合策略通过结合不同相似度算法的优势,可显著提升系统的鲁棒性和准确性。典型实现方式包括“混合检索+重排序”架构:在检索阶段,利用余弦相似度等方法快速召回候选结果(如基于方向相似性的文本或用户兴趣召回);在精排阶段,采用欧氏距离对候选结果进行优化排序,以引入绝对差异特征提升结果精度[2][3][29]。例如,结合BGE-M3模型的密集与稀疏检索(生成密集嵌入的同时获取词元权重),或嵌入检索与BM25算法结合,可通过Vespa、Milvus等工具实现高效检索;后续再使用交叉编码器(如bge-reranker)进行重排序,进一步优化结果质量[2]。
在生物信息学领域,欧氏距离的应用凸显了其在特定场景下的必要性。例如,在基因表达分析中,通过计算样本基因表达谱向量间的欧氏距离,可量化不同样本的基因表达差异;在蛋白质序列比对中,欧氏距离用于衡量序列相似性;在分子结构分析中,可比较不同分子结构的空间差异;在生物聚类分析中,欧氏距离作为距离度量标准辅助划分生物样本簇[30]。这些应用场景均依赖于欧氏距离对多维向量绝对差异的精准捕捉能力,验证了其在科学研究中的不可替代性。
欧氏距离与余弦距离的适用场景对比可进一步说明其特性:
| 场景 | 余弦距离 | 欧氏距离 |
|---|---|---|
| 文本相似度 | ✔️ 更适合(高维稀疏,方向敏感) | ❌ 不适用(长度影响大) |
| 推荐系统 | ✔️ 更适合(用户兴趣方向) | ❌ 不适用(活跃度影响大) |
| 高维稀疏数据 | ✔️ 更适合(忽略零值维度) | ❌ 不适用(受噪声维度干扰) |
| 图像处理 | ❌ 不适用(像素值长度有意义) | ✔️ 更适合(绝对差异重要) |
| 物理空间距离 | ❌ 不适用(需要绝对距离) | ✔️ 更适合(直接反映距离) |
| 低维稠密数据 | ❌ 不适用(方向可能不显著) | ✔️ 更适合(全局差异重要) |
| 异常检测 | ❌ 不适用(需要绝对差异) | ✔️ 更适合(衡量偏差) |
[27]
模型架构分析
Transformer变体与优化
Transformer架构的持续优化推动了长文本建模能力的显著提升,针对上下文长度受限、计算效率低下及注意力分散等核心痛点,业界已形成多维度技术方案。旋转位置编码(RoPE)通过将位置信息编码为旋转矩阵,有效解决了传统位置编码在长序列下的精度衰减问题,典型如Jina Embeddings V3基于XLM-RoBERTa架构引入RoPE,支持8192 token的长文本输入,其升级版本Jina Embeddings V4进一步采用多模态旋转位置编码(M-RoPE),扩展了跨模态场景的长上下文处理能力[13][31]。此类技术为“迟分”等长文本处理策略提供了基础,例如jina-embeddings-v2-base-en凭借8192 token支持能力,可先对完整文本进行Transformer层编码,再通过平均池化生成包含丰富上下文的块Embedding,有效保留邻近块信息,优于传统预处理分块导致的上下文丢失问题[20]。
FlashAttention 2作为高效注意力计算技术,通过重构内存访问模式降低显存占用并加速计算,已成为长文本模型训练与推理的关键优化手段。Jina Embeddings V3/V4均集成该技术提升注意力效率,LongAlign方法在长指令微调中进一步结合FlashAttention 2的flash_attn_varlen_func函数实现变长序列打包(Packing),避免不同长度文本交叉污染,同时通过排序批处理(Sorted Batching)减少计算空闲时间,显著提升8k-64k长度文本的训练效率[13][31][32]。
稀疏注意力机制通过聚焦关键信息缓解传统Transformer对无关上下文的过度关注,DIFF Transformer提出的差分注意力机制是典型代表。其核心通过计算两组Softmax注意力图的差值放大关键上下文权重,在64K上下文长度的书籍数据评估中,累积平均负对数似然(NLL)指标优于传统Transformer;在关键信息检索任务中,当答案位于25%深度时准确率较传统模型提升76%,且注意力分数更集中于核心内容[33]。
不同优化方案的适用场景存在显著差异:RoPE及其多模态扩展(M-RoPE)通过稳定的位置编码支持通用长文本场景,适用于需要完整上下文理解的任务(如文档问答、多模态内容检索)[13][31];FlashAttention 2作为底层优化技术,可与各类Transformer变体结合,尤其适合计算资源受限或大规模训练场景[32];稀疏注意力(如DIFF Transformer)则在法律条款检索、技术文档关键信息提取等特定领域任务中表现突出,通过定向聚焦提升检索精度[33]。
传统分块与迟分策略对比如下:
| 传统分块 | 迟分 | |
|---|---|---|
| 边界线索需求 | 是 | 是 |
| 边界线索使用时机 | 预处理阶段 | transformer层处理后 |
| 块Embedding特性 | 独立同分布(i.i.d.) | 有条件,编码更多上下文信息 |
| 邻近块上下文保留 | 易丢失,需启发式方法缓解 | 长文本Embedding模型能有效保留 |
多模态与跨语言架构
多模态架构通过创新技术路径打破文本、图像等模态间的壁垒,实现统一语义空间的构建。例如,Jina Embeddings V4采用共享路径处理文本与图像,其视觉编码器将图像转换为token序列,再由语言模型解码器通过上下文注意力层联合处理两种模态数据,有效缩小模态鸿沟[13][31]。CLIP模型则通过文本-图像联合训练策略生成统一语义空间,支持图文匹配与多模态搜索,实现图像与文本的跨模态向量空间映射及文图互搜[1][23]。此外,BETR模型通过整合多模态信息与上下文感知能力优化句子嵌入和推理任务,在强上下文感知需求的场景中表现优异[4];BGE visualized模型在文本模型基础上拓展视觉数据处理能力,进一步支持多模态混合检索[34]。
跨语言架构的核心目标是构建多语言统一语义空间,以支持不同语言间的语义匹配与迁移。当前多语言模型普遍面临低资源语言数据稀缺等挑战,但主流模型已在语言覆盖范围与性能上取得显著进展。BGE-M3作为多语言语义向量模型的代表,支持超100种语言的统一表征,可实现各语言内部的多语言能力及不同语种间的跨语言精准语义匹配[3][34]。Qwen3嵌入模型系列继承基础模型的强大多语言能力,支持超过100种语言及多种编程语言,能将不同语言内容映射到统一语义空间进行检索,并在涵盖112种语言的MTEB多语言基准测试及跨语言检索任务中取得最先进结果[10][11][35][36]。Gemini Embedding同样支持100+语言,性能与OpenAI的多语言产品相当,为全球应用提供灵活性[8]。其他跨语言模型如LaBSE支持55种语言的句子编码,XLM通过多语言共享语义空间实现跨语言迁移,微软模型支持93种语言,Cohere模型可理解超过100种语言文本,共同推动跨语言语义分析与检索任务的发展[1][5][37]。
性能指标对比
MTEB基准综合表现
MTEB(Massive Text Embedding Benchmark)作为大规模文本嵌入评估基准,具备多样性(涵盖检索、分类、聚类等8类任务,58个数据集,112种语言)、简单性(10行代码即可评估)、可扩展性及可重复性等特点,已成为评估嵌入模型性能的核心标准[3][11]。通过对MTEB榜单数据的分析,当前向量模型领域呈现三大技术趋势:
一是大模型底座性能全面超越传统小模型。以Qwen3-Embedding系列为例,其8B模型在MTEB多语言基准得70.58分,代码基准得80.68分,超越谷歌Gemini Embedding(多语言平均68.32分)、OpenAI text-embedding-3-large及微软multilingual-e5-large-instruct等顶尖模型[8][10][11]。同系列模型性能与参数量正相关,如Qwen3-Embedding-0.6B可超过其他7B参数模型,4B较0.6B提升显著,但8B较4B边际效用递减,印证了模型规模对性能的正向影响[12]。此外,NV-Embed在MTEB检索任务中以69.32的NDCG@10分位居榜首,进一步体现大模型底座的技术优势[14]。
二是多语言能力成为核心竞争力。Qwen3支持100+语言,在MTEB多语言排行榜中位列第一;BGE-M3在多语言、跨语言及长文档检索任务中达到最优水平;Jina Embeddings V3在跨语言任务中超越multilingual-e5-large-instruct,凸显多语言支持已成为模型竞争的关键维度[31][36][38]。
三是开源模型与闭源模型性能差距持续缩小。开源模型如BGE-M3、Jina Embeddings V3/V4表现突出:BGE-M3在MIRACL、MKQA等多语言基准中效果领先;Jina Embeddings V3在MTEB英文任务中超越OpenAI、Cohere的闭源模型,V4版本进一步在MMTEB等基准中展现顶尖性能[13][31][38]。
从模型得分分布看(如下表),任务平均得分最高的gemini-embedding-exp-03-07为68.32分,主要优势体现在双语挖掘(79.28分)、语义文本相似度(79.40分)等任务;而聚类任务普遍得分较低,多数模型聚类得分在50-55分区间(如Linq-Embed-Mistral 51.27分、gte-Qwen2-7B-instruct 53.36分),成为当前向量模型的主要性能瓶颈[23]。
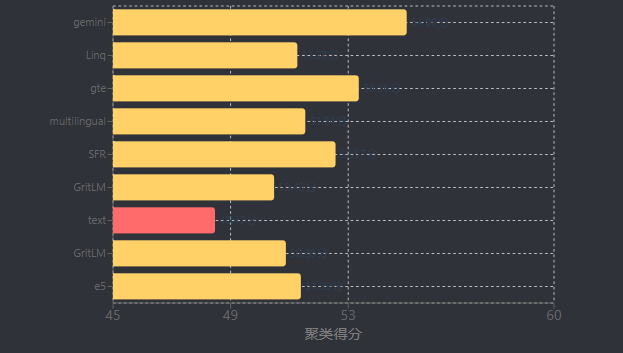
| 排名 | 模型名称 | Zero-shot | 参数量 | 向量维度 | 最大令牌数 | 任务平均得分 | 任务类型平均得分 | 双语挖掘 | 分类 | 聚类 | 指令检索 | 多标签分类 | 成对分类 | 重排序 | 检索 | 语义文本相似度(STS) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gemini-embedding-exp-03-07 | 99% | Unknown | 3072 | 8192 | 68.32 | 59.64 | 79.28 | 71.82 | 54.99 | 5.18 | 29.16 | 83.63 | 65.58 | 67.71 | 79.40 |
| 2 | Linq-Embed-Mistral | 99% | 7B | 4096 | 32768 | 61.47 | 54.21 | 70.34 | 62.24 | 51.27 | 0.94 | 24.77 | 80.43 | 64.37 | 58.69 | 74.86 |
| 3 | gte-Qwen2-7B-instruct | ⚠️ NA | 7B | 3584 | 32768 | 62.51 | 56.00 | 73.92 | 61.55 | 53.36 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98 |
| 4 | multilingual-e5-large-instruct | 99% | 560M | 1024 | 514 | 63.23 | 55.17 | 80.13 | 64.94 | 51.54 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81 |
| 5 | SFR-Embedding-Mistral | 96% | 7B | 4096 | 32768 | 60.93 | 54.00 | 70.00 | 60.02 | 52.57 | 0.16 | 24.55 | 80.29 | 64.19 | 59.44 | 74.79 |
| 6 | GritLM-7B | 99% | 7B | 4096 | 4096 | 60.93 | 53.83 | 70.53 | 61.83 | 50.48 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33 |
| 7 | text-multilingual-embedding-002 | 99% | Unknown | 768 | 2048 | 62.13 | 54.32 | 70.73 | 64.64 | 48.47 | 4.08 | 22.80 | 81.14 | 61.22 | 59.68 | 76.11 |
| 8 | GritLM-8x7B | 99% | 57B | 4096 | 4096 | 60.50 | 53.39 | 68.17 | 61.55 | 50.88 | 2.44 | 24.43 | 79.73 | 62.61 | 57.54 | 73.16 |
| 9 | e5-mistral-7b-instruct | 99% | 7B | 4096 | 32768 | 60.28 | 53.18 | 70.58 | 60.31 | 51.39 | -0.62 | 22.20 | 81.12 | 63.82 | 55.75 | 74.02 |
效率与资源消耗对比
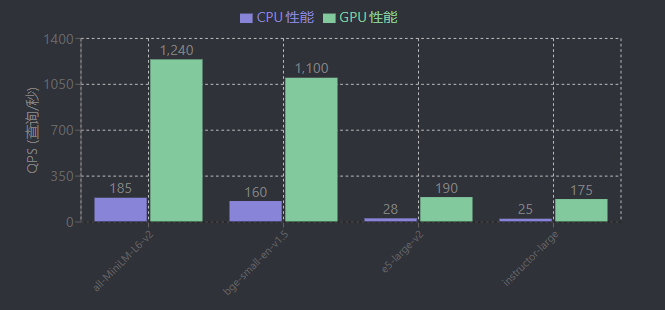
在大模型向量应用中,效率与资源消耗的权衡是实际部署的核心考量因素,需结合模型规模、计算性能、维度优化及成本效益综合评估。轻量级模型与大型模型在效率上呈现显著差异:以AWS c5.2xlarge(CPU)和g4dn.2xlarge(GPU)环境测试为例,轻量级模型如all-MiniLM-L6-v2(33M参数)的CPU QPS达185,GPU QPS达1240;bge-small-en-v1.5的CPU QPS为160,GPU QPS为1100,展现出高效的实时处理能力[39]。相比之下,大型模型如e5-large-v2、instructor-large的CPU QPS仅28-32,GPU QPS不足200,资源消耗显著更高[39]。这种差异使得轻量级模型更适用于边缘设备、低算力场景或高并发需求(如实时检索),而大型模型(如Qwen3-8B)则在大规模文档集索引等对深度语义理解要求较高的场景中更具优势,但需通过向量数据库优化召回效率以平衡资源消耗[35]。
架构设计对效率的影响同样关键。CoSENT采用单句编码模式,效率显著优于需句子对拼接编码的SBERT;BETR的效率则取决于上下文优化需求,而Transformers框架的性能表现依赖具体实现细节[4]。模型规模与速度的关系呈现阶梯式差异:SimHash(极小模型)和MinHash(中等模型)速度远快于BERT类模型,后者需GPU或ONNX加速才能满足实用需求[2]。例如,Qwen3-Embedding系列中,0.6B尺寸模型因召回速度优势更适合工业部署,而4B、8B模型虽性能略有提升(如top30召回率提升约1%),但资源消耗显著增加[7]。
维度压缩技术是优化效率与资源消耗的重要手段,可在小幅性能损失下显著降低计算与存储成本。Gemini通过MRL(Maximum Relevant Leading)技术将3072维向量截断至768维,性能损失小于5%[40];Jina Embeddings V4支持将向量维度动态截断至128维,以适配不同效率需求[31]。语义压缩技术则通过识别重复或相似文本减少输入量,例如Bazaarvoice实践中实现97.7%的语义压缩率(压缩比42),使LLM使用成本(含嵌入与存储)降低82.4%[41]。
商业模型的成本效益需结合性能与定价综合评估。Google Gemini embedding model的使用成本为每百万tokens 0.15美元,具有较高性价比[42];OpenAI的text-embedding-3-small相比前代text-embedding-ada-002价格降低5倍(0.00002美元/1k tokens vs 0.0001美元),且计算效率更高,适合成本敏感场景[6]。在实际应用中,某银行RAG系统处理2.3TB文档时,通过优化实现1200 QPS并发能力与1.8秒平均响应时间(P99<4秒),HNSW索引构建的召回率达98%且延迟<50ms,验证了效率优化策略的实际价值[43]。此外,轻量级专用模型如DeepSeek-Lite仅需300MB内存占用,在同等准确度下响应延迟降低60%,为低算力环境提供了可行方案[1]。
| 指标类别 | 指标项 | 数值 | 性能说明 |
|---|---|---|---|
| 系统规模 | 知识库文档量 | 2.3 TB | 含财报/法规/产品手册 |
| 响应性能 | 平均响应时间 | 1.8 秒 | - |
| P99响应时间 | <4 秒 | 高百分位性能 | |
| 并发能力 | QPS | 1200 | 每秒查询处理能力 |
| 准确性 | 回答准确率 | 94.7% | 对比纯LLM的68% |
| 索引性能 | HNSW召回率 | 98% | - |
| HNSW延迟 | <50 ms | 索引查询延迟 |
数据来源: [43]
| 模型名称 | 价格 (美元/千tokens) | 相对前代成本变化 | 适用场景 |
|---|---|---|---|
| text-embedding-ada-002 | 0.0001 | 基准 | 通用场景 |
| text-embedding-3-small | 0.00002 | 降低80% | 成本敏感型应用 |
| text-embedding-3-large | 0.00013 | 增加30% | 高性能需求场景 |
| Google Gemini embedding | 0.00015 | - | 高性价比需求 |
数据来源: [6][44]
应用场景与推荐
行业特定应用
向量模型在行业特定场景中的有效应用高度依赖领域适配技术,需结合行业数据特性与任务需求优化模型架构与训练策略。法律领域通过领域数据微调与专用算法设计提升专业术语理解与检索精度,例如DeepSeek-Law模型通过法律文书微调实现合同审查与判例推荐,而法律检索系统则采用基于中性样本的深度语义表示方法(在STS数据集性能超越SimCSE)与注意力交互排序学习方法(在LeCaRD数据集超越Lawformer),构建粗排(双塔无监督语义编码器快速召回)与精排(长文本排序重排)二级检索架构[1][45]。生物医学领域则通过预训练与知识库融合增强专业性,BioBERT模型在生物医学文本上预训练后,在蛋白质关系抽取、药物发现等任务中表现突出,其在PubMed数据集上的性能较通用模型提升15%以上[1]。
金融与电商领域聚焦检索系统的实用性与数据质量优化。某银行通过向量引擎与LLM服务集群构建RAG方案,将法规、财报等文档的检索准确率提升至94.7%;电商领域知识库建设明确提出覆盖率(关键实体召回率≥95%)、新鲜度(90%文档1年内更新)与结构化(50%以上文档含元数据标签)三大核心指标,以支撑精准推荐与智能问答[43]。农林牧渔等垂直领域亦有专用评测数据集支撑模型优化,如中文农林牧渔QA数据集(数据量800K+,随机1k问题测试)为领域模型性能评估提供基准[7][46]。
通用模型与领域专用模型的性能差距在专业任务中尤为显著。除BioBERT外,法律领域专用模型在LeCaRD法律检索数据集、金融RAG系统在法规文档检索任务中的表现均大幅超越通用嵌入模型,印证了领域适配的必要性[1][43][45]。针对不同行业需求,迁移学习与微调策略需差异化设计:成本敏感或边缘设备部署场景推荐Jina Embeddings V3(支持多语言检索、长文档检索);多模态检索(视觉文档、图文检索)与代码检索任务优先选择Jina Embeddings V4;RAG系统可采用BGE系列模型(被Milvus、Langchain等广泛集成)或Qwen3嵌入模型(支持多语言与代码查询)[13][31][34][35]。此外,语义压缩技术(如句子分割、向量嵌入计算、层次聚类)在产品评论摘要等场景中已实现百万级数据处理,其生成的摘要关键信息覆盖率与用户认可度均表现优异[41]。
未来趋势
技术挑战与解决方案
当前向量模型在实际应用中面临多维度技术挑战,需通过针对性创新方案突破瓶颈。在长文本处理领域,核心问题包括上下文长度限制(如BERT默认512词元需切块处理)、语义信息过度压缩(长文本编码为单一向量导致关键信息丢失)、检索粒度不足(RAG系统需小片段检索而非全文匹配)及深层语义推理能力薄弱(依赖表面文字匹配而非逻辑关联)[2][20][47]。对此,学界和工业界提出多层次解决方案:模型结构层面,DIFF Transformer通过差分注意力机制提升长文本关键信息检索精准性,其跨模态通用潜力已在视觉领域初步验证[48];训练策略层面,ESimCSE采用“单词重复”和动量对比缓解长度偏置,BGE-M3通过自知识蒸馏与批处理优化提升训练质量[2];分块策略层面,“迟分”方法利用长上下文模型生成token级向量后再分块池化,有效保留长距离依赖关系[20]。
低资源语言支持不足是另一突出挑战,根源在于模型对标注数据的强依赖性[1]。跨语言迁移学习与合成数据生成成为关键突破路径:Gemini嵌入模型通过检索任务生成查询过滤、分类任务多阶段提示等方式构建高质量训练数据,结合Model Soup参数平均技术提升泛化能力[9];微软则利用大模型生成多任务数据,缓解任务多样性与多语言覆盖度问题[37]。
评估体系与可解释性瓶颈亦制约模型发展。传统NIAH测试依赖关键词匹配,无法有效评估深层语义理解能力[47],亟需动态评估指标(如NoLiMA)实现细粒度能力刻画;向量空间的“黑箱”特性导致可解释性不足,需结合知识图谱等外部结构增强嵌入过程的逻辑透明度[1]。
未来,跨学科融合将驱动向量模型革新。神经符号系统等交叉技术有望实现符号推理与向量计算的有机结合,而DIFF Transformer在多模态领域的拓展验证了跨模态通用架构的潜力,为视觉-语言联合嵌入等复杂任务提供新思路[48]。此外,基于LLM的基础模型构建(如Qwen3)、多阶段训练流程(无监督预训练+有监督微调+LLM数据合成)及模型合并技术(如球面线性插值slerp),将进一步提升模型的可扩展性与下游任务对齐能力[11]。