Linux操作系统之线程:线程概念
目录
前言:
一、进程与线程
二、线程初体验
三、分页式存储管理初谈
总结:
前言:
大家好啊,今天我们就要开始翻阅我们linux操作系统的另外一座大山:线程了。
对于线程,大体结构上我们是划分为两部分,一部分是线程的概念与控制,另外一部分是线程的同步与互斥的相关内容。
本篇文章我将会为大家介绍线程的一些基础知识,加上对我们之前所学内容与线程之间的联系。
一、进程与线程
我们之前学过进程。
当时我们说:进程是一个执行起来的程序,进程=内核数据结构+代码与数据。
而什么是线程呢?
线程是一个执行流,执行粒度比进程更细,是进程内部的一个执行分支。
也就是说,一个进程可以包含多个线程,而这些线程共享进程的资源(如内存空间,我们后面会解释),但各自拥有独立的执行上下文(如栈、寄存器)
我们之前所说的进程,只有一个执行流,这种“单线程进程”其实是多线程模型的一种特例,如今更常见的是多线程程序,以提高并发性和资源利用率。
我们现在要更新一下对于线程进程的概念。
对于进程来说,进程是分配系统资源的基本实体。
对于线程来说,线程是OS调度的基本单位。
进程都需要被管理起来,那么比进程执行粒度更细的线程呢?
自然也要被管理起来,提到管理,就不得不说出那六个字:先描述,再组织!!
那我们就应该类似管理进程一样,专门弄出一个类似于PCB的结构来管理线程?
那我们的操作系统未免也太复杂了吧。
所以,linux的设计者也考虑到了这一点,于是linux的设计者就决定,我们可不可以让PCB(task_struct)近似的拿去管理线程呢?
所以线程,实际上也是通过PCB来进行管理的,没错,你没有听错,线程,也是通过PCB来进行管理的。
一个程序是一个进程,但是这个进程不一定只有一个PCB,我们从来没说过一个进程只能有一个PCB。所以有着多个PCB的进程,这多出来的,就是一个一个的执行流,就是一个一个的线程。线程也是task_struct描述起来的。
我们之前的模型,都是单线程进程,这唯一一个PCB,代表着这个进程的主执行流。
该进程唯一的 task_struct(PCB)即代表其主执行流,二者是等价的。此时 “进程”=“线程”,因为只有一个执行流,无需区分概念。
而我们之前讲进程的PCB的时候说过,PCB中包含很多数据结构,包括页表,mm_struct,vm_area_struct list。那现在的多线程进程中,我们有多个PCB,这里面的每一个PCB都有着这些结构吗?
当然,要不然为什么他们都是由PCB管理起来的呢?
那他们的数据也是一样的吗?
是,也不是。
一个进程中可以含多个PCB,我们就以主执行流的PCB数据为准,其他执行流(线程)的PCB,里面的mm_struct,vm_area_struct list这些结构数据,其实是共享的,他们之间共享相同的地址空间和资源,但是他们的寄存器和用户栈空间是每个线程各自独立的:
struct task_struct {pid_t pid; // 线程ID(内核视角)pid_t tgid; // 线程组ID(用户视角的进程ID)struct mm_struct *mm; // 指向共享的内存描述符// 每个线程有独立的:struct thread_struct thread; // 寄存器状态void *stack; // 内核栈
};
我们可以理解为每一个线程存储的大部分数据都是一样的,在执行代码时,由于我们的执行上下文不同,各自维护独立的执行状态,所以我们可以并发的执行不同的代码。
所以我们今天就有了更清楚的概念:一个PCB(task_struct)<= 进程
我们也不在区分执行流到底是线程还是进程,转而把linux执行流统一称为:轻量级进程(LWP)
linux系统中没有真正意义上的“线程”,只有 “共享资源的轻量级进程”。
值得提的是,Windows是真的有线程的专属数据结构,所以它的内核代码极其复杂。
二、线程初体验
我们接下来写一下简单的测试代码,让大家体验一下线程的概念:
在linux中,我们一般用pthread_create函数来创建一个线程。

值得注意的是,这个函数并不是一个系统调用,而是我们glibc封装的一个函数。
他有四个参数,第一个参数是一个指针,函数成功返回后,会将新线程的 ID 写入该地址。所以我们在使用这个函数前,一般会创建一个pthread_t类型的id。
第二个参数指定线程的属性(如栈大小、调度策略等),如果是NULL,则使用默认属性。
第三个参数是一个函数指针,代表值这个线程将要执行的方法,而第四个参数表示传递给线程函数的参数。
#include <pthread.h>
#include <iostream>
#include <unistd.h>void* func(void *argv)
{while(true){std::cout<<"I am func pthread,my pid :"<<getpid()<<std::endl; sleep(1);}
}
int main()
{pthread_t tid;int i = 100;pthread_create(&tid, nullptr, func, (void *)i);while (true){std::cout << "I am main pthread,my pid :" << getpid() << std::endl;sleep(1);}return 0;
}在编译这个代码时应该注意,我们的编译指令应该是 g++ test.cc -o test -lpthread ,因为我们需要需要链接 pthread 库。
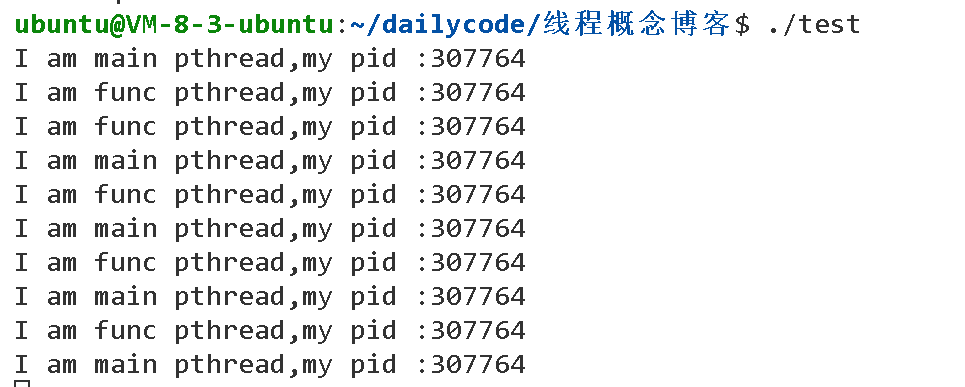
可以看见,如果只有一个执行流,是不能同时执行两个while循环的。
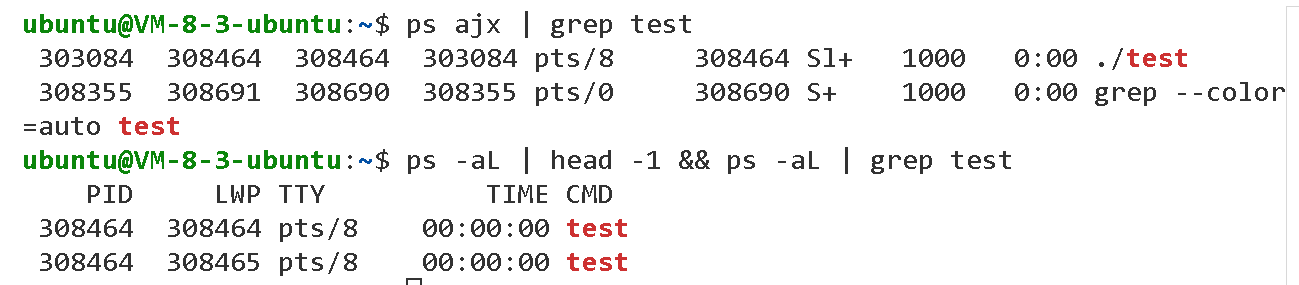 我们再次运行代码,通过新的bash输入以上两个命令可以查看进程运行信息。
我们再次运行代码,通过新的bash输入以上两个命令可以查看进程运行信息。
可以看见,操作系统中叫做test的进程只有这一个,我们可以使用ps -aL来查看线程信息。
这里就多出来一个叫做LWP的东西。这个就是表示轻量级进程。
我们LWP与PID相同的,就是主执行流,如果光看PID的话,我们是区分不出来两个执行流的。所以,我们可以通过LWP来区分执行流唯一性,我们的OS真实调度时,也是用的LWP而不是PID。
三、分页式存储管理初谈
如果在没有虚拟内存和分页机制的情况下,每一个用户程序在物理内存上所对应的空间必须是连续的,如下图:
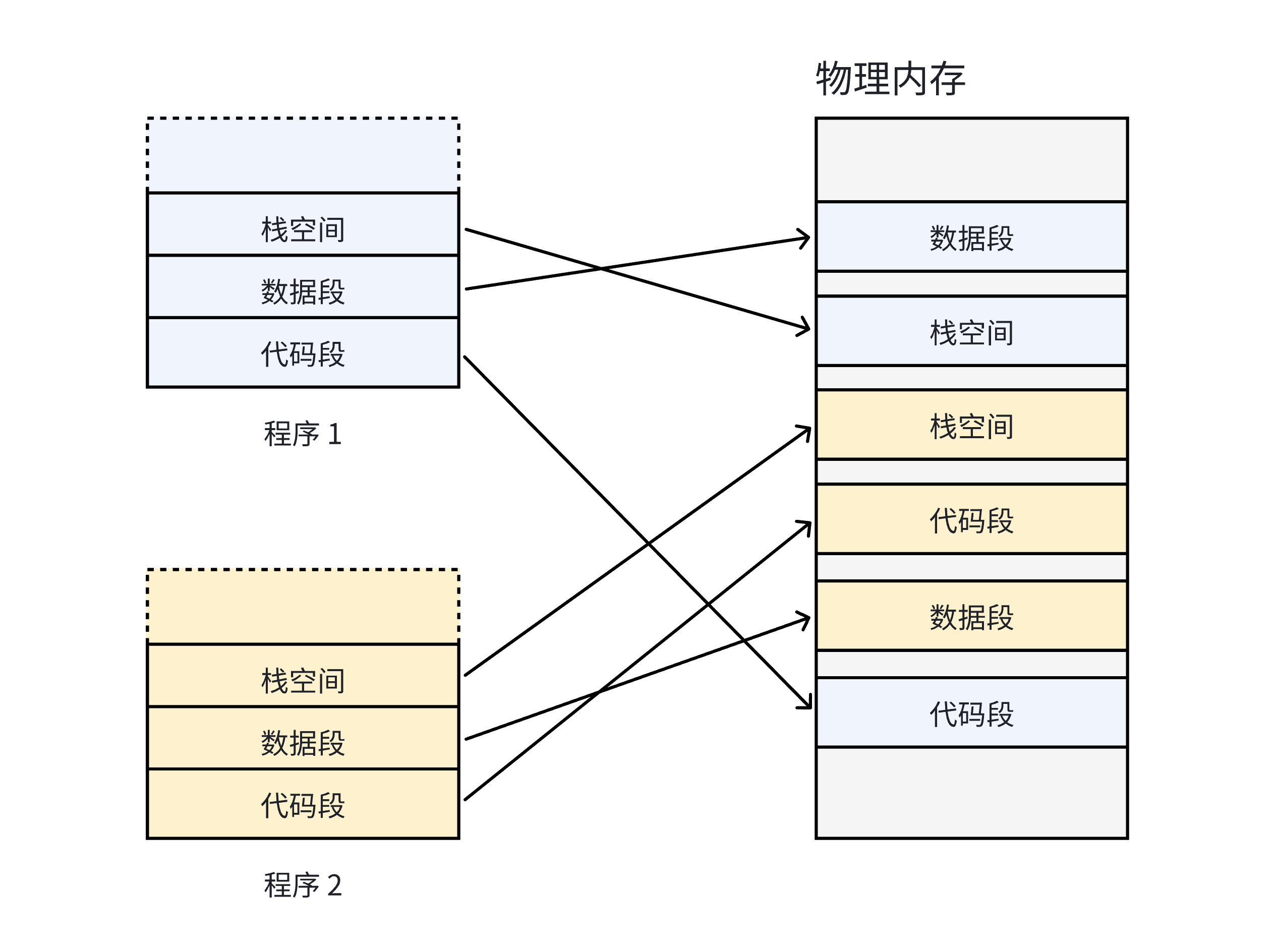
因为每一个程序的代码、数据长度都是不一样的,按照这样的映射方式,物理内存将会被分割成各种离散的、大小不同的块。结果一段时间运行后,有些程序会退出,那么他们占据的物理内存空间就会被回收,导致这些物理内存都是以很多碎片的形式存在的。
我们希望操作系统提供给用户的空间必须是连续的,但是物理内存又不连续,该怎么办呢?
所以此时虚拟内存与分页就出现了。
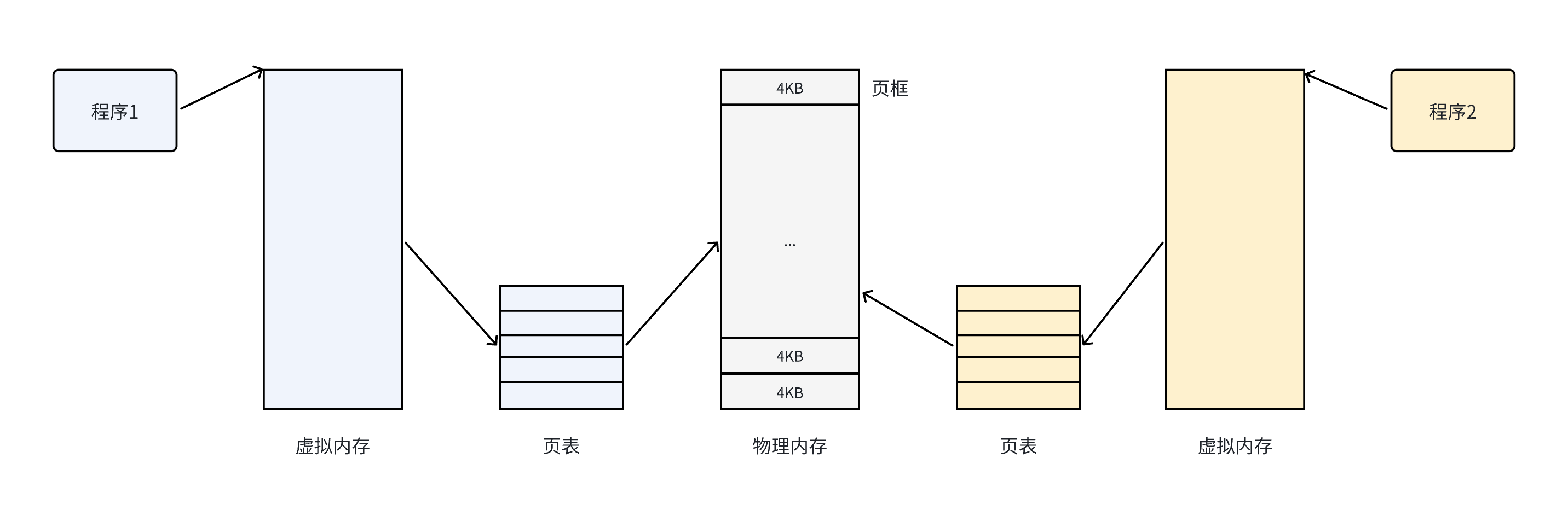
我们这张图中牵涉到了页框的概念,那么什么是页框呢?
同学们,还记得我们学过的物理内存管理吗?
我们当时说过块的概念,我们可以把一定数量的扇区,划分为一个块。一个块的数据大小为4kb,也就是八个扇区。(ext2下)
我们说:块是文件系统管理数据的最小单位,一个块的大小是4kb。
这里的块是文件系统读写磁盘的最小逻辑单位,类似的,我们的一个页框的大小也是固定为4kb,他是操作系统管理物理内存的最小单位。
我们把物理内存按照一个固定的长度的页框进行分割,有时候叫做物理页。每一个页框包含一个物理页(page)。一个页的大小等于页框的大小,32位大多支持4kb,64为8kb。
我们需要区分页与页框:
页是一个数据块,可以存放在任何页框或者磁盘中,而页框是一个存储区域!
有了这种机制,CPU便并非是直接访问物理内存地址,而是通过虚拟地址空间来间接访问物理内存地址。所谓的虚拟空间,是操作系统为每一个正在执行的进程分配的一个逻辑地址。操作系统将虚拟地址空间与物理内存地址之间建立映射关系,也就是页表,这张表上记录了每一页和页框的映射关系。
总结一下,其思想就是将虚拟内存下的逻辑地址空间分为若干页,将物理内存空间划分为若干页框,通过页表就能把连续的虚拟内存,映射到若干个不同的物理内存页,就解决了碎片问题。
/* include/linux/mm_types.h */
struct page
{/* 原⼦标志,有些情况下会异步更新 */unsigned long flags;union{struct{/* 换出⻚列表,例如由zone->lru_lock保护的active_list */struct list_head lru;/* 如果最低为为0,则指向inode* address_space,或为NULL* 如果⻚映射为匿名内存,最低为置位* ⽽且该指针指向anon_vma对象*/struct address_space *mapping;/* 在映射内的偏移量 */pgoff_t index;/** 由映射私有,不透明数据* 如果设置了PagePrivate,通常⽤于buffer_heads* 如果设置了PageSwapCache,则⽤于swp_entry_t如果设置了PG_buddy,则⽤于表⽰伙伴系统中的阶*/unsigned long private;};struct{ /* slab, slob and slub */union{struct list_head slab_list; /* uses lru */struct{ /* Partial pages */struct page *next;
#ifdef CONFIG_64BITint pages; /* Nr of pages left */int pobjects; /* Approximate count */
#elseshort int pages;short int pobjects;
#endif};};struct kmem_cache *slab_cache; /* not slob *//* Double-word boundary */void *freelist; /* first free object */union{void *s_mem; /* slab: first object */unsigned long counters; /* SLUB */struct{ /* SLUB */unsigned inuse : 16; /* ⽤于SLUB分配器:对象的数⽬ */unsigned objects : 15;unsigned frozen : 1;};};};...};union{/* 内存管理⼦系统中映射的⻚表项计数,⽤于表⽰⻚是否已经映射,还⽤于限制逆向映射搜索*/atomic_t _mapcount;unsigned int page_type;unsigned int active; /* SLAB */int units; /* SLOB */};...
#if defined(WANT_PAGE_VIRTUAL)/* 内核虚拟地址(如果没有映射则为NULL,即⾼端内存) */void *virtual;
#endif /* WANT_PAGE_VIRTUAL */...
}系统启动时,内核会根据检测到的物理内存大小,为每个物理页框(page frame)分配一个对应的 struct page 结构体。
在 Linux 内核中, struct page 是用于管理物理内存页(页框)的核心数据结构,每个物理页都对应一个这样的结构体。该结构体包含几个关键字段:
-
flags:这是一个多功能的标志位字段,用于记录页的各种状态。每位代表一种独立的状态,可同时表示32种不同的状态(定义在<linux/page-flags.h>中)。其中重要的标志位包括:
-
PG_locked:表示页是否被锁定在内存中
-
PG_uptodate:表示页数据已从块设备正确读取
-
-
_mapcount:这个计数器记录有多少个页表项指向该物理页,即页的引用计数。当值为-1时,表示内核不再引用该页,可以被重新分配使用。
-
virtual:存储页的虚拟地址。对于常规内存,这就是页在虚拟地址空间中的映射地址;而对于高端内存(不永久映射到内核地址空间的部分),此字段为NULL,需要时再动态映射。
值得注意的是, struct page 描述的是物理页而非虚拟页。以典型的4KB页大小和4GB物理内存为例,系统需要管理约1百万个物理页(4GB/4KB=1M)。假设每个 struct page 占用40字节,则总内存开销约为40MB(1M*40B),仅占系统总内存的1%,这个管理开销是相当合理的。
我们之所以扯到这里,主要是想帮助大家理解虚拟地址空间与线程之间的关系,同一进程的所有线程共享同一个 mm_struct(内存描述符),因此它们看到的是完全相同的虚拟地址空间.
我们可以把struct page当做数组来理解,Linux 内核通过一个名为 mem_map 的全局数组(元素类型为 struct page)管理所有物理页。而当作数组,就有了下标,我们就可以快速转化为物理地址,一个页框是4kb,所以物理地址就等于=下标*4kb
总结:
由于时间原因,我们今天就讲到这里。
但是我们的分页式存储管理还是没有讲完,我们还没用深刻理解页表的分级存储。
所以明天我们将会讲解页表的分级存储,之后会继续讲解线程的概念!