【推荐100个unity插件】使用C#或者unity实现爬虫爬取静态网页数据——Html Agility Pack (HAP)库和XPath 语法的使用
文章目录
- 前言
- 一、安装HtmlAgilityPack
- 1、从NuGet下载HtmlAgilityPack包
- 2、获取HtmlAgilityPack.dll
- 二、HtmlAgilityPack常用操作
- 1、加载 HTML
- 2、查询方式
- 2.1 使用 XPath 查询(推荐)
- 2.2 使用 LINQ 查询
- 3、常用查询操作
- 3.1 选择节点
- 3.2 获取属性值
- 3.3 遍历节点
- 3.4 获取节点内容
- 三、XPath 语法
- 1、节点类型
- 2、路径表达式
- 3、节点选择
- 4、谓语(Predicates)
- 5、通配符
- 6、多条件筛选
- 7、文本内容匹配
- 8、轴(Axes)选择
- 9、函数
- 四、XPath使用示例
- 1、案例
- 2、常见用法
- 五、HAP 中的实际应用示例
- 1. 获取所有链接
- 2. 获取特定 class 的内容
- 3. 处理表格数据
- 六、性能优化
- 七、实战
- 1、爬取静态网页文本数据
- 2、爬取并保持图片数据
- 专栏推荐
- 完结
前言
Html Agility Pack (HAP) 是一个强大的 .NET HTML 解析库,特别适合在 C# 和 Unity 中实现爬虫功能。它支持有缺陷的 HTML 解析、XPath 查询和 LINQ 操作。
核心组件
-
HtmlWeb:网页下载器 -
HtmlDocument:HTML 文档容器 -
HtmlNode:HTML 节点对象 -
github:https://github.com/zzzprojects/html-agility-pack?tab=readme-ov-file
一、安装HtmlAgilityPack
1、从NuGet下载HtmlAgilityPack包
https://www.nuget.org/packages/HtmlAgilityPack/#versions-body-tab
选择版本点击下载
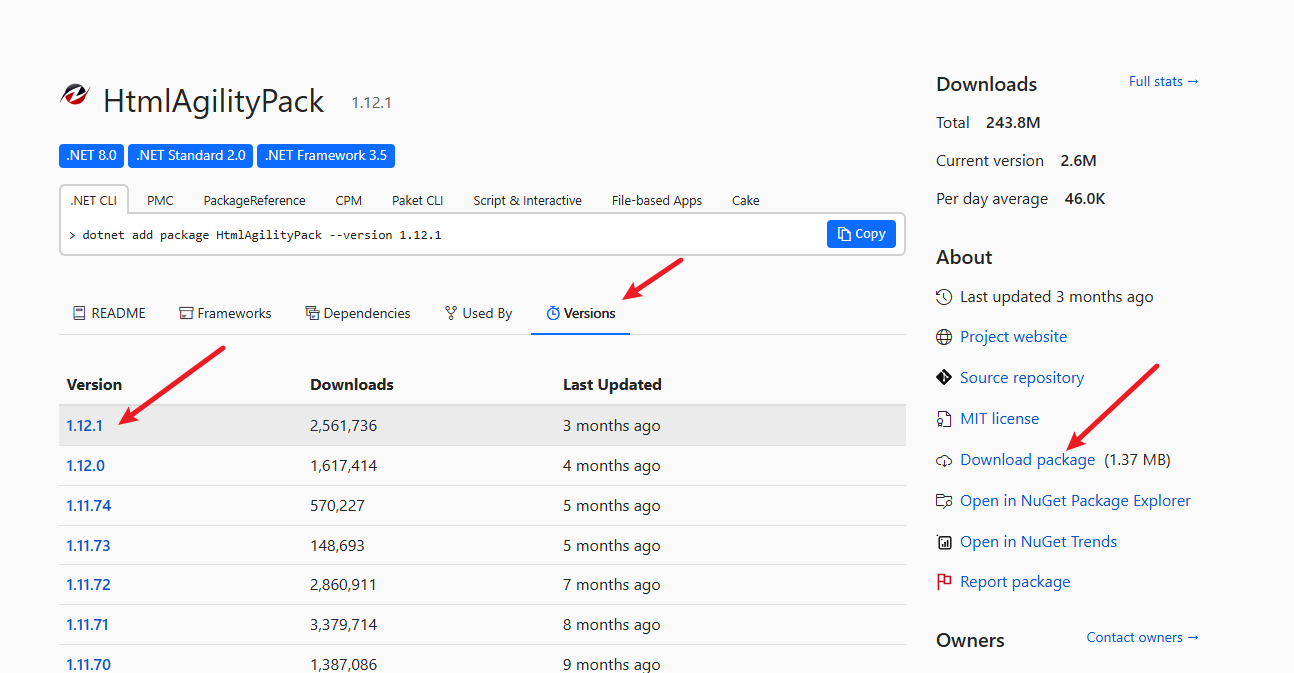
2、获取HtmlAgilityPack.dll
下载的是nupkg文件,解压后在lib文件夹下, 有不同版本的不同.NET版本对应的包
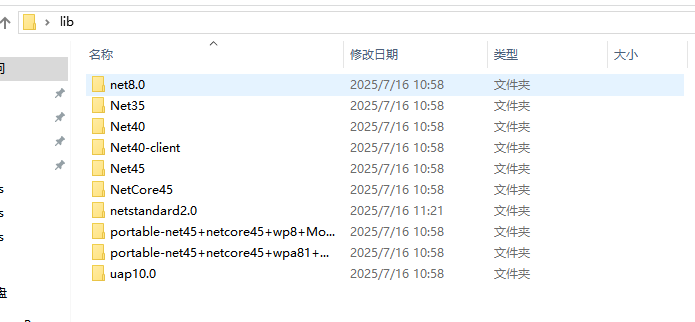
各版本核心区别
| 特性/版本 | .NET 8.0版 | .NET Standard 2.0版 | .NET Framework 3.5版 |
|---|---|---|---|
| 兼容性 | 仅支持.NET 6.0+ | 跨平台(兼容.NET Core/.NET 5+/Unity等) | 仅限传统.NET Framework |
| 性能 | 最优(AOT优化) | 中等 | 较低 |
| API完整性 | 最新API(如CSS选择器) | 大部分核心功能 | 基础功能 |
| Unity支持情况 | 需Unity 2021.2+ | 最佳支持(推荐) | 旧版Unity(2018-2020) |
| NuGet包名 | HtmlAgilityPack | HtmlAgilityPack.NetCore或标准版 | HtmlAgilityPack |
建议大多数Unity项目选择**.NET Standard 2.0**版本,平衡兼容性和功能性。仅当明确需要新特性时再考虑.NET 8.0版本。
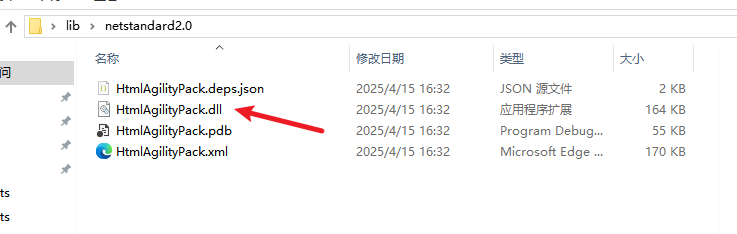
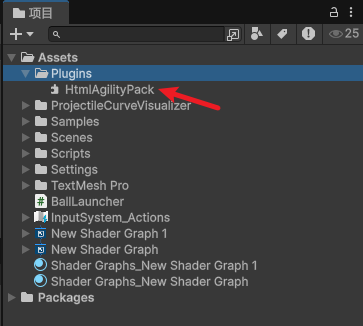
将HtmlAgilityPack.DLL文件放入Unity项目的Assets/Plugins文件夹中即可
二、HtmlAgilityPack常用操作
1、加载 HTML
// 从 URL 加载
var web = new HtmlWeb();
HtmlDocument doc = web.Load("https://example.com");// 从字符串加载
var doc = new HtmlDocument();
doc.LoadHtml(htmlContent);// 从文件加载(Unity 使用 Application.dataPath)
doc.Load("path/to/file.html");
2、查询方式
2.1 使用 XPath 查询(推荐)
// 获取所有链接
HtmlNodeCollection links = doc.DocumentNode.SelectNodes("//a[@href]");if (links != null)
{foreach (HtmlNode link in links){string href = link.GetAttributeValue("href", "");string text = link.InnerText.Trim();Debug.Log($"链接: {text} -> {href}");}
}// 获取特定 class 的元素
var products = doc.DocumentNode.SelectNodes("//div[@class='product-item']");
2.2 使用 LINQ 查询
using System.Linq;var titles = doc.DocumentNode.Descendants("h2").Where(node => node.GetAttributeValue("class", "") == "title").Select(node => node.InnerText.Trim()).ToList();
3、常用查询操作
3.1 选择节点
// 通过XPath选择节点
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//div[@class='content']");// 选择单个节点
HtmlNode node = doc.DocumentNode.SelectSingleNode("//h1");
3.2 获取属性值
string href = node.GetAttributeValue("href", ""); // 第二个参数是默认值
string id = node.Attributes["id"]?.Value;
3.3 遍历节点
foreach (HtmlNode link in doc.DocumentNode.SelectNodes("//a[@href]"))
{string hrefValue = link.GetAttributeValue("href", string.Empty);Debug.Log(hrefValue);
}
3.4 获取节点内容
string innerText = node.InnerText; // 不含HTML标签的文本
string innerHtml = node.InnerHtml; // 包含HTML标签
string outerHtml = node.OuterHtml; // 包含节点自身及其内容
三、XPath 语法
XPath (XML Path Language) 是一种用于在 XML 和 HTML 文档中定位节点的查询语言,Html Agility Pack (HAP) 完全支持 XPath 查询。掌握 XPath 是高效使用 HAP 的关键。
1、节点类型
- 元素节点:HTML 标签(如
<div>、<a>) - 属性节点:元素的属性(如
href、class) - 文本节点:元素内的文本内容
- 文档节点:整个文档
2、路径表达式
XPath 使用路径表达式来选取节点,类似于文件系统路径:
/从根节点开始//从当前节点选择匹配节点,不考虑位置.当前节点..父节点@选取属性
3、节点选择
| 表达式 | 说明 | 示例 |
|---|---|---|
nodename | 选取所有该名称的节点 | div 选择所有 <div> |
/ | 从根节点开始 | /html/body/div |
// | 从任意位置选择 | //div 选择所有 <div> |
. | 当前节点 | ./span 当前节点的子 <span> |
.. | 父节点 | ../div 父节点下的 <div> |
@ | 选择属性 | @href 选择 href 属性 |
4、谓语(Predicates)
用于查找特定节点,放在方括号中:
//div[1] // 第一个<div>
//div[last()] // 最后一个<div>
//div[position()<3] // 前两个<div>
//a[@href] // 带有href属性的<a>
//div[@class='main'] // class为"main"的<div>
5、通配符
| 通配符 | 说明 | 示例 |
|---|---|---|
* | 匹配任何元素节点 | //* 所有元素 |
@* | 匹配任何属性节点 | //div[@*] 带任意属性的 |
node() | 匹配任何类型节点 | //div/node() div的所有子节点 |
6、多条件筛选
//div[@class='article' and @data-id='123']
//a[contains(@class,'btn') or @type='submit']
7、文本内容匹配
//h1[text()='Welcome'] // 精确匹配
//p[contains(text(),'Hello')] // 包含文本
//span[starts-with(text(),'Copyright')]
8、轴(Axes)选择
| 轴 | 说明 | 示例 |
|---|---|---|
child:: | 子节点(默认轴,可省略) | //div/child::span 或 //div/span |
parent:: | 父节点 | //span/parent::div |
ancestor:: | 所有祖先节点 | //span/ancestor::div |
descendant:: | 所有后代节点 | //div/descendant::span |
following:: | 文档中当前节点之后的所有节点 | //div/following::span |
preceding:: | 文档中当前节点之前的所有节点 | //div/preceding::span |
following-sibling:: | 同一层级之后的兄弟节点 | //li/following-sibling::li |
preceding-sibling:: | 同一层级之前的兄弟节点 | //li/preceding-sibling::li |
9、函数
//div[contains(@class, 'header')] // 属性包含特定字符串
//a[starts-with(@href, 'https')] // 属性以特定字符串开头
//p[string-length(text()) > 100] // 文本长度大于100
count(//div) // 统计div数量
四、XPath使用示例
1、案例
比如我想要查找 id="liveroom__sidebar" 的 div 元素内部所有 class="status" 的子元素(无论嵌套层级),可以使用以下 XPath 表达式:
//div[@id='liveroom__sidebar']//*[contains(@class, 'status')]
或精确匹配(如果 class 只有 ‘status’):
//div[@id='liveroom__sidebar']//*[@class='status']
关键点说明
//双斜杠:表示搜索所有后代节点(不限层级)
*星号:匹配任何标签名(div/span/p等)
contains(@class, 'status'):
比
@class='status'更灵活能匹配复合
class如<div class="status active">精确匹配场景:
- 如果确定 class 只有
"status"(没有其他class),可以用@class='status'
2、常见用法
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性
/bookstore/* 选取 bookstore 元素的所有子元素
//* 选取文档中的所有元素
//title[@*] 选取所有带有属性的 title 元素//div/a/@href 获取a标签的href的值
//div/a/text() 获取a标签的文本内容
/div/book[1] 选取属于div子元素的第一个 book 元素。
/div/book[last()] 选取属于 div 子元素的最后一个 book 元素。
/div/book[last()-1] 选取属于 div子元素的倒数第二个 book 元素。
//title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
//title[@name='a'] 选取所有 title 元素,且这些元素拥有值为 a的 name 属性。
/div/book[price>35.00] 选取 div元素的所有 book 元素,且其中的 price 元素的值须大于 35.00
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
五、HAP 中的实际应用示例
1. 获取所有链接
var links = doc.DocumentNode.SelectNodes("//a[@href]");
foreach (HtmlNode link in links)
{string href = link.GetAttributeValue("href", "");Console.WriteLine(href);
}
2. 获取特定 class 的内容
var nodes = doc.DocumentNode.SelectNodes("//div[contains(@class,'product')]");
foreach (HtmlNode node in nodes)
{string title = node.SelectSingleNode(".//h3").InnerText;string price = node.SelectSingleNode(".//span[@class='price']").InnerText;
}
3. 处理表格数据
var rows = doc.DocumentNode.SelectNodes("//table[@id='data']/tr");
foreach (HtmlNode row in rows)
{var cells = row.SelectNodes("./td");if (cells != null && cells.Count >= 2){string name = cells[0].InnerText.Trim();string value = cells[1].InnerText.Trim();}
}
六、性能优化
- 尽量使用具体路径而非
//开头 - 优先使用属性而非文本内容定位
- 缓存常用 XPath 查询结果
七、实战
1、爬取静态网页文本数据
比如我实现爬取自己的博客的简介数据,按f12查看html代码结构
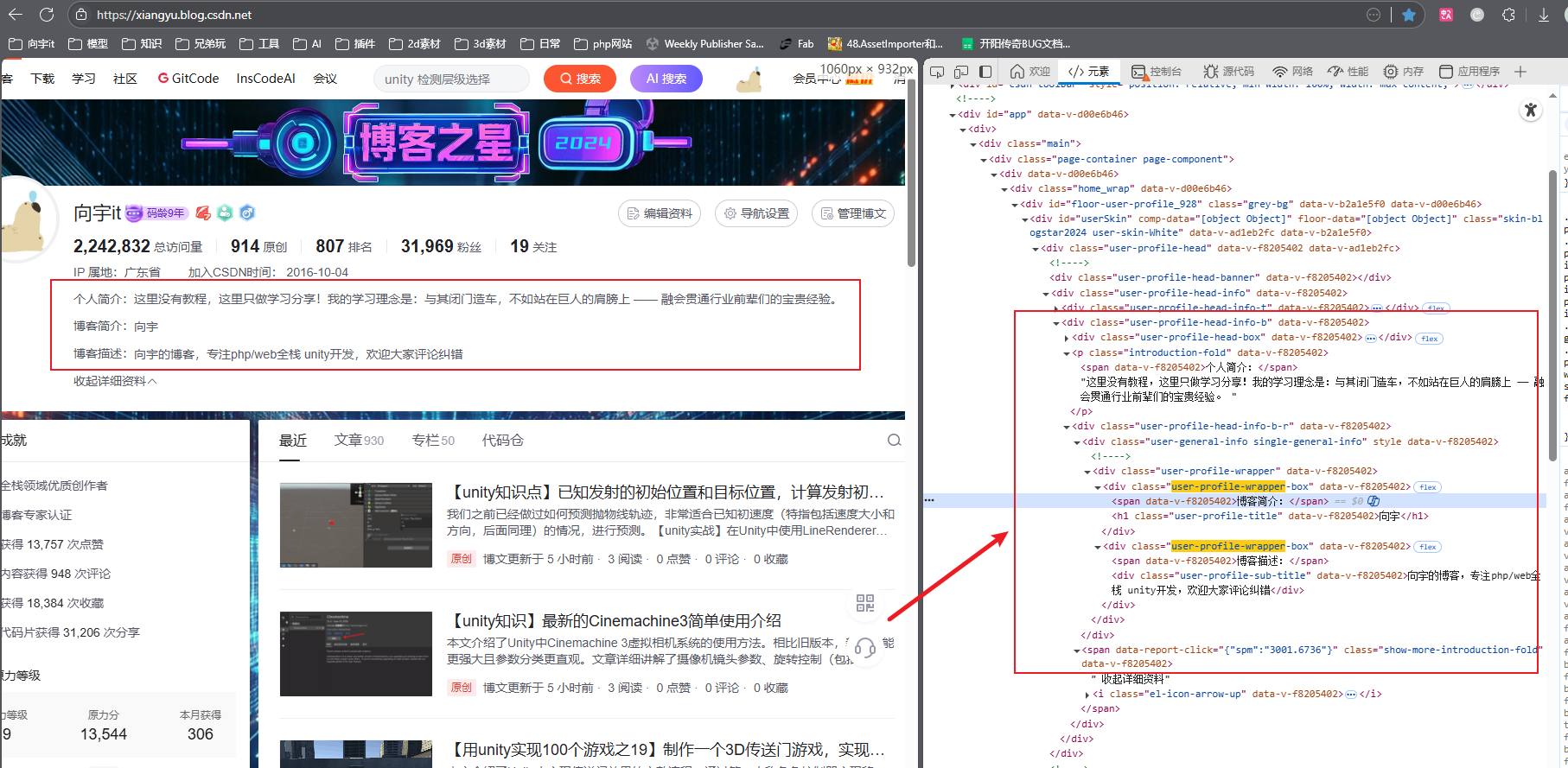
代码如下
using System.Collections;
using HtmlAgilityPack;
using UnityEngine;public class WebCrawler : MonoBehaviour
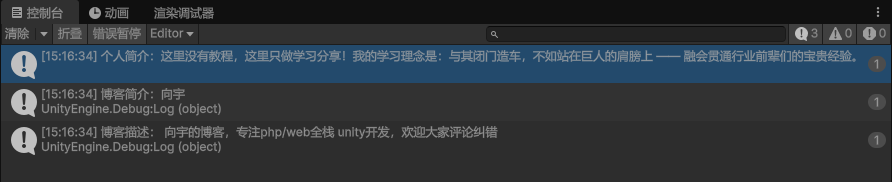
{// 目标网站URL(请替换为实际网址)public string targetUrl = "https://xiangyu.blog.csdn.net";void Start(){StartCoroutine(FetchWebData());}IEnumerator FetchWebData(){// 从URL加载HTML文档HtmlWeb web = new HtmlWeb();HtmlDocument doc = web.Load(targetUrl);//个人简介(这里故意分两段获取只是为了演示效果)HtmlNode nodeIntro = doc.DocumentNode.SelectSingleNode("//div[@class='user-profile-head-info-b']");string strIntro = nodeIntro.SelectSingleNode("//p[contains(@class, 'introduction-fold')]").InnerText;Debug.Log(strIntro);// 博客简介和博客描述HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//div[@class='user-profile-wrapper-box']");if (nodes != null){foreach (HtmlNode node in nodes){Debug.Log(node.InnerText);}}yield return null;}
}
结果
2、爬取并保持图片数据
using UnityEngine;
using UnityEngine.Networking;
using System.IO;
using HtmlAgilityPack;
using System.Collections;
using System.Web;public class SimpleImageDownloader : MonoBehaviour
{public string url = "https://cn.bing.com/images/search?q=%E5%8F%AF%E7%88%B1%E5%9B%BE%E7%89%87&form=HDRSC2&first=1&cw=1177&ch=917"; // 目标网页public string saveFolder = "DownloadedImages"; // 保存文件夹void Start(){StartCoroutine(DownloadImages());}IEnumerator DownloadImages(){// 1. 下载网页UnityWebRequest webRequest = UnityWebRequest.Get(url);yield return webRequest.SendWebRequest();if (webRequest.result != UnityWebRequest.Result.Success){Debug.LogError("网页加载失败: " + webRequest.error);yield break;}// 2. 解析图片var htmlDoc = new HtmlDocument();htmlDoc.LoadHtml(webRequest.downloadHandler.text);var imgNodes = htmlDoc.DocumentNode.SelectNodes("//img[@src]");if (imgNodes == null) yield break;// 3. 创建保存目录string savePath = Path.Combine(Application.dataPath, "../", saveFolder);Directory.CreateDirectory(savePath);// 4. 下载图片foreach (var imgNode in imgNodes){string imgUrl = imgNode.GetAttributeValue("src", "");if (!imgUrl.StartsWith("http")) {// 处理相对路径imgUrl = new System.Uri(new System.Uri(url), imgUrl).AbsoluteUri;}UnityWebRequest imgRequest = UnityWebRequestTexture.GetTexture(imgUrl);yield return imgRequest.SendWebRequest();if (imgRequest.result == UnityWebRequest.Result.Success){Texture2D texture = DownloadHandlerTexture.GetContent(imgRequest);byte[] bytes = texture.EncodeToPNG();string fileName = Path.GetFileName(imgUrl.Split('?')[0])+".png";if (string.IsNullOrEmpty(fileName)) fileName = "image.png";File.WriteAllBytes(Path.Combine(savePath, fileName), bytes);Debug.Log("已保存: " + fileName);}else{Debug.LogWarning("下载失败: " + imgUrl);}}Debug.Log("图片下载完成!保存在" + savePath);}
}
结果
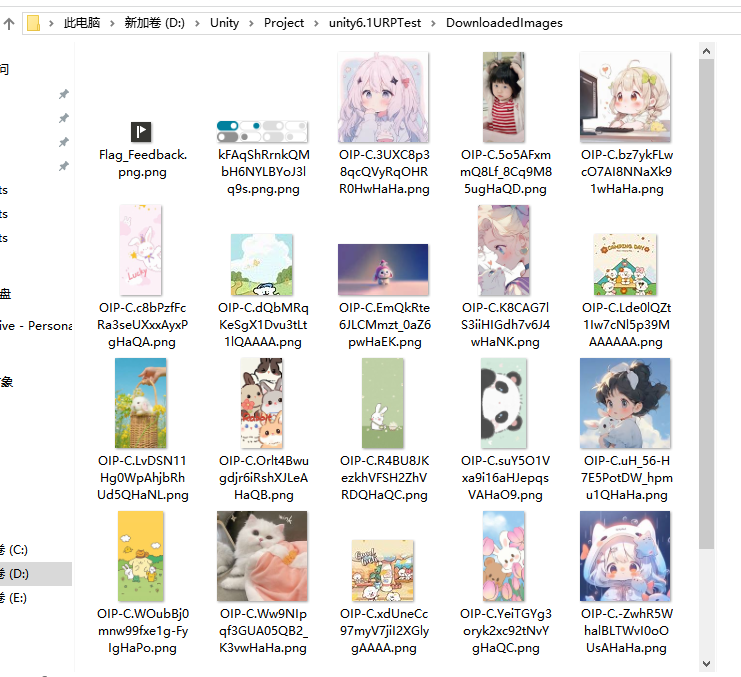
专栏推荐
| 地址 |
|---|
| 【unity游戏开发入门到精通——C#篇】 |
| 【unity游戏开发入门到精通——unity通用篇】 |
| 【unity游戏开发入门到精通——unity3D篇】 |
| 【unity游戏开发入门到精通——unity2D篇】 |
| 【unity实战】 |
| 【制作100个Unity游戏】 |
| 【推荐100个unity插件】 |
| 【实现100个unity特效】 |
| 【unity框架/工具集开发】 |
| 【unity游戏开发——模型篇】 |
| 【unity游戏开发——InputSystem】 |
| 【unity游戏开发——Animator动画】 |
| 【unity游戏开发——UGUI】 |
| 【unity游戏开发——联网篇】 |
| 【unity游戏开发——优化篇】 |
| 【unity游戏开发——shader篇】 |
| 【unity游戏开发——编辑器扩展】 |
| 【unity游戏开发——热更新】 |
| 【unity游戏开发——网络】 |
完结
好了,我是向宇,博客地址:https://xiangyu.blog.csdn.net,如果学习过程中遇到任何问题,也欢迎你评论私信找我。
赠人玫瑰,手有余香!如果文章内容对你有所帮助,请不要吝啬你的点赞评论和关注,你的每一次支持都是我不断创作的最大动力。当然如果你发现了文章中存在错误或者有更好的解决方法,也欢迎评论私信告诉我哦!
