Linux C 进程基本操作
背景简介
操作系统最初的原型是一种批处理系统(batch):在最开始我们把正在执行的程序称为作业,操作员将所有的作业放在一起,由批处理系统进行读取并交给计算机执行,当一个作业执行完成以后,批处理系统会自动地取出下一个作业。在批处理系统中,存在的最严重的问题是任务执行的过程,会经常需要等待IO操作,这会导致CPU经常性地空闲。
为了充分提高CPU的利用率,一种解决方案是引入多道程序设计,在内存当中划分多个区域,每个区域存储一个作业的指令和数据,当其中一个作业在等待IO操作时,另外一个作业可以使用CPU。
除了希望充分利用CPU资源,程序员还希望自己的对计算机的操作能够得到迅速的响应,这种需求导致了分时系统的诞生。在分时系统中,操作系统会给每个作业分配一些时间来使用CPU,这样CPU就不会沉浸在一个大型的作业中,期间的用户操作也会很快地得到响应。
由于同时执行多个作业,所以计算机需要提供一种优雅的方式来在各个任务之间来分配CPU,并且同一时间也会有多个作业的数据和指令在内存当中驻留。传统的基于硬件的CPU和内存保护机制显得十分复杂,并且程序员编写程序的时候需要花费很多心智负担来考虑计算机硬件的限制。因此,操作系统在计算机硬件和用户之间引入一个中间层——进程。在用户的视角中,会把运行中的程序看成一个进程,每个进程拥有自己独立的CPU和内存资源,并且可以管理各种其他所有资源,当然这种看起来的独占都是虚拟的;操作系统的作用就要管理真实、复杂和丑陋的底层硬件,为用户视角当中简单且美好的进程来提供支持。
进程的概念
通过对操作系统发展史的简单回顾,我们就可以给进程下一个完善的定义了。
从用户的角度来看,进程是一个程序的动态执行过程。程序是静态文件,是一系列二进制指令和数据的集合,程序通常存储在磁盘当中。进程则是动态的,当程序被触发以后(比如用户启动程序或者被其他进程启动程序),启动者的权限和属性以及程序的指令和数据会被加载到内存当中,并且占用CPU和其他系统资源动态地执行指令和读写数据。进程的状态会在动态地在创建、调度、运行和消亡之间转换。
从操作系统的角度来看,进程是各种计算机资源分配的基本单位。操作系统需要提供支持让每个进程以为自己能够独占CPU和内存等资源——即所谓的虚拟CPU和虚拟内存。每个进程需要占用CPU资源以执行程序指令;而除了需要占用CPU资源以外,进程还需要占据存储资源来保存状态。进程需要保存的内容包括数据段、代码段、堆以及其他内存空间,进程也需要占用资源管理打开的文件、挂起的信号、内核内部数据、处理器状态、存在内存映射的内存空间以及执行线程,而执行线程的信息则包含程序计数器、栈和寄存器状态。
虚拟CPU和虚拟内存
虚拟CPU
利用进程机制,所有的现代操作系统都支持在同一个时间来完成多个任务。尽管某个时刻,真实的CPU只能运行一个进程,但是从进程自己的角度来看,它会认为自己在独享CPU(即虚拟CPU),而从用户的角度来看多个进程在一段时间内是同时执行的,即并发执行。在实际的实现中,操作系统会使用调度器来分配CPU资源。调度器会根据策略和优先级来给各个进程一定的时间来占用CPU,进程占用CPU时间的基本单位称为时间片,当进程不应该使用CPU资源时,调度器会抢占CPU的控制权,然后快速地切换CPU的使用进程。这种切换在用户的视角中对程序执行毫无影响,可以认为是透明的。由于切换进程消耗的时间和每个进程实际执行的时间片是在非常小的,以至于用户无法分辨,所以在用户看起来,多个进程是在同时运行的。
调度器和优先级
Linux内核存在一个专门用来调度进程的内核线程,称为调度器(或者是调度程序)。调度器的基本工作是从一组处于可执行状态的进程中选择一个来执行。和很多其他操作系统一样,Linux提供了抢占式的多任务模式。调度器会决定某个进程在什么时候停止运行,并且可以让另一个进程进入执行,这个动作即所谓的抢占。
传统的Unix操作系统采用的时间片轮转法。这种方法的大致流程是这样的:调度器它把所有的可运行的非实时的进程组织在一起,这个数据结构被称为就绪队列。通常调度器取一个固定时间作为调度周期(又称为调度延迟),当一个调度周期开始的时候,调度器会为就绪队列当中的每个进程分配时间片,每个进程能够获取的时间片长度和进程的优先级有关。正在执行的进程会在执行的过程逐渐消耗它的时间片,当时间片耗尽时,如果该进程依然处于运行状态,那么它就会被就绪队列中的下一个进程抢占。
如果整个调度周期执行完成,调度器就会抢占该进程,并且根据优先级分配新的时间片。在进程执行过程中,会出现等待IO操作的情况。此时,进程就会从就绪队列当中移除,并且将其放入等待队列,并且将自己的状态调整为等待状态。进程运行终止时,进程也会从就绪队列中移除。当进程被创建或者被从等待状态唤醒时,调度器会根据优先级分配时间片,再将其插入到就绪队列当中。
Linux所使用的调度算法之一是完全公平调度算法,简称CFS,虽然在概念上和时间片轮转法有很多区别,但是具体表现基本一致。
虚拟内存
在进程本身的视角中,它除了会认为CPU是独占的以外,它还会以为自己是内存空间的独占者,这种从进程视角看到的内存空间被称为虚拟内存空间。当操作系统中有多个进程同时运行时,为了避免真实的物理内存访问在不同进程之间发生冲突,操作系统需要提供一种机制在虚拟内存和真实的物理内存之间建立映射。
因此,进程之间具有并行性、互不干扰等特点。也就是说,进程之间是分离的任务,拥有各自的权利和责任。每个进程都运行在各自独立的虚拟地址空间,因此,即使一个进程发生了异常,它也不会影响到系统的其他进程。
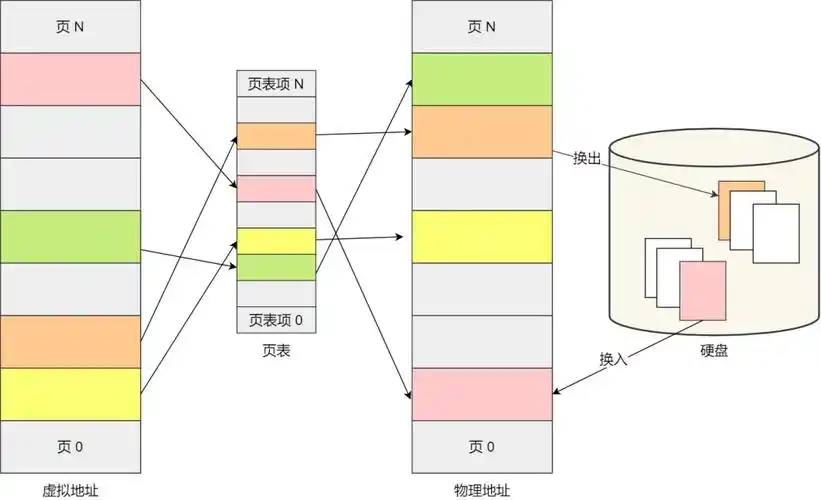
进程地址空间
Linux为每个进程维持了一个单独的虚拟地址空间,也就是进程地址空间。
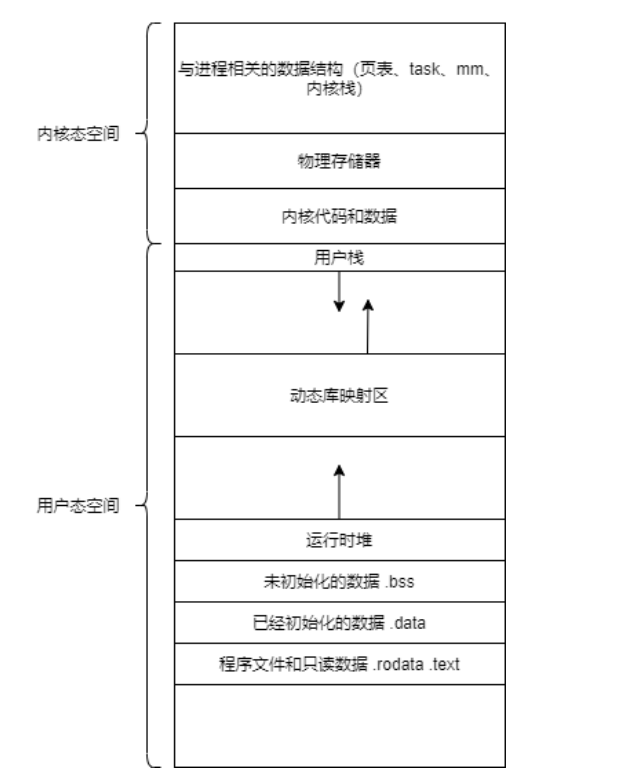
在内核态空间里面,与进程相关的数据结构是每个进程都不同的,物理存储器和内核代码数据是所有进程共享的。
内核态和用户态
CPU或者说计算机硬件的运行状态可以分为内核态和用户态。在计算机处于内核态的情况下,它可以执行所有的指令;在计算机处于用户态的情况下,它只能执行部分的指令。所有涉及到内存管理、外部设备访问(比如读写网卡、读写文件等等)以及需要访问内核态地址空间的指令都需要在内核态下完成。计算机可以通过中断或者是异常的方式从用户态陷入到内核态。系统调用的底层实现当中,就使用了主动触发中断即异常的指令。
进程管理
进程标识符PID
为了方便普通用户定位每个进程,操作系统为每个进程分配了一个唯一的正整数标识符,称为进程ID(PID)。在Linux中,进程之间存在着亲缘关系,如果一个进程在执行过程中启动了另外一个进程,那么启动者就是父进程,被启动者就是子进程。从 task_struct 声明可知,进程的信息中包含它的进程ID和父进程ID,实际上PID和PCB之间存在着一一对应的关系。使用ps命令可以查看进程相关信息。
在Linux启动时,如果所有的硬件已经配置好的情况下,进程0会被bootloader程序启动起来,它会配置实时时钟,启动init进程(进程1)和页面守护进程(进程2)。init就是所谓的“盘古”进程(在新版本中被systemd取代),它会启动shell进程。在多用户的情况下,init会开启运行/etc/rc中配置的脚本进程,然后这个进程再从 /etc/ttys 中读取数据。 /etc/ttys 中列出了所有的终端,终端可以用于让用户从某种渠道登陆操作系统。
使用系统调用 getpid 和 getppid 可以获取当前运行进程的进程ID和父进程ID。
进程的用户ID和组ID和其他相关信息
进程在运行过程中,存在一个用户身份的属性,以便于控制进程的权限。在默认情况下,程序进程拥有启动用户的身份。例如,假设当前登录用户为student,他运行了任意一个程序(无论是不是他创建的),则程序在运行过程中就具有student的身份,该进程的用户ID和组ID分别为student和student所属的组,其ID和组ID就被称为进程的真实用户ID和真实组ID。真实用户ID和真实组ID可以通过函数getuid() 和 getgid() 获得。
getuid()
#include <unistd.h>
uid_t getuid(void);参数
无参数:
getuid()不接受任何参数。
返回值
返回值是一个
uid_t类型的值,表示当前进程的真实用户 ID(Real User ID)。uid_t是一个无符号整数类型,通常定义为unsigned int或uint32_t,具体取决于系统架构。如果调用成功,返回值是非负整数;如果调用失败,返回值是
-1。
功能
获取当前进程的真实用户 ID(Real User ID)。
真实用户 ID 是创建该进程的用户的 ID,它不会因为进程权限的改变(如通过
setuid())而改变。
getgid()
#include <unistd.h>
gid_t getgid(void);参数
无参数:
getgid()不接受任何参数。
返回值
返回值是一个
gid_t类型的值,表示当前进程的真实组 ID(Real Group ID)。gid_t是一个无符号整数类型,通常定义为unsigned int或uint32_t,具体取决于系统架构。如果调用成功,返回值是非负整数;如果调用失败,返回值是
-1。
功能
获取当前进程的真实组 ID(Real Group ID)。
真实组 ID 是创建该进程的用户所属的用户组 ID,它不会因为进程权限的改变(如通过
setgid())而改变。
示例:
int main(){uid_t uid;gid_t gid;uid = getuid();gid = getgid();printf("uid = %d, gid = %d\n",uid,gid);
} geteuid()
#include <unistd.h>
uid_t geteuid(void);参数
无参数:
geteuid()不接受任何参数。
返回值
返回值是一个
uid_t类型的值,表示当前进程的有效用户 ID(Effective User ID)。uid_t是一个无符号整数类型,通常定义为unsigned int或uint32_t,具体取决于系统架构。如果调用成功,返回值是非负整数;如果调用失败,返回值是
-1。
功能
获取当前进程的有效用户 ID(Effective User ID)。
有效用户 ID 是用于权限检查的用户 ID。它可能与真实用户 ID(Real User ID)不同,尤其是在进程通过
setuid()系统调用更改了有效用户 ID 的情况下。有效用户 ID 决定了进程在访问文件和资源时的权限。
getegid()
#include <unistd.h>
gid_t getegid(void);参数
无参数:
getegid()不接受任何参数。
返回值
返回值是一个
gid_t类型的值,表示当前进程的有效组 ID(Effective Group ID)。gid_t是一个无符号整数类型,通常定义为unsigned int或uint32_t,具体取决于系统架构。如果调用成功,返回值是非负整数;如果调用失败,返回值是
-1。
功能
获取当前进程的有效组 ID(Effective Group ID)。
有效组 ID 是用于权限检查的组 ID。它可能与真实组 ID(Real Group ID)不同,尤其是在进程通过
setgid()系统调用更改了有效组 ID 的情况下。有效组 ID 决定了进程在访问文件和资源时的权限。
示例:
int main(){uid_t euid;gid_t egid;uid = geteuid();gid = getegid();printf("euid = %d, egid = %d\n",euid,egid);
}进程的状态
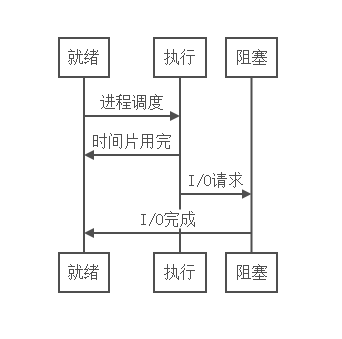
在进程从创建到消亡的过程中,进程会存在很多种状态。其中最基本的三种的状态是执行态、就绪态、等待态
- 执行态:该进程正在运行,即进程正在占用CPU。
- 就绪态:进程已经具备执行的一切条件,正在等待分配CPU的处理时间片。
- 等待态:进程不能使用CPU,通常由于等待IO操作、信号量或者其他操作。
PS命令
除了最基本的上面3种状态以外,使用ps命令还可以观察到一些更细致划分的状态
$ps -elf
#找到第二列,也就是列首为S的一列
#R 运行中
#S 睡眠状态,可以被唤醒
#D 不可唤醒的睡眠状态,通常是在执行IO操作
#T 停止状态,可能是被暂停或者是被跟踪
#Z 僵尸状态,进程已经终止,但是无法回收资源ps(process status)是 Linux 系统中用于显示当前运行的进程信息的命令。它可以帮助用户查看系统中正在运行的进程的详细信息,例如进程 ID、用户、进程状态、占用的资源等。
常用选项
-a:显示当前终端的所有进程(包括其他用户的进程)。-u:显示进程的用户信息。-x:显示没有控制终端的进程(例如后台运行的进程)。-e:显示系统中所有的进程。-f:显示完整格式的进程信息,包括进程的父进程 ID、启动时间等。-l:显示长格式的进程信息,包含更多细节。-o:自定义显示的列,例如-o pid,comm只显示进程 ID 和命令名。-p:指定要显示的进程 ID,例如-p 1234只显示进程 ID 为 1234 的进程。-t:指定终端,例如-t pts/0只显示在终端 pts/0 上运行的进程。-U:按用户过滤进程,例如-U username只显示指定用户的进程。-G:按用户组过滤进程。
组合选项
ps aux:a:显示当前终端的所有进程(包括其他用户的进程)。u:显示进程的用户信息。x:显示没有控制终端的进程。这是查看系统中所有进程的常用组合,输出信息较为全面。
ps -ef:e:显示系统中所有的进程。f:显示完整格式的进程信息。这个组合也常用于查看所有进程的详细信息。
ps命令的选项很多很复杂,具体的细节可以使用man命令查看手册,不过工作中使用最多的是两种: ps -elf 和 ps aux
UNIX风格:ps -elf
执行结果:
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 42068 - 7月05 ? 00:00:10 /sbin/init splash
1 S root 2 0 0 80 0 - 0 - 7月05 ? 00:00:00 [kthreadd]
1 S root 3 2 0 80 0 - 0 - 7月05 ? 00:00:00 [pool_workqueue_release]
1 I root 4 2 0 60 -20 - 0 - 7月05 ? 00:00:00 [kworker/R-rcu_g]
1 I root 5 2 0 60 -20 - 0 - 7月05 ? 00:00:00 [kworker/R-rcu_p]
1 I root 6 2 0 60 -20 - 0 - 7月05 ? 00:00:00 [kworker/R-slub_]
1 I root 7 2 0 60 -20 - 0 - 7月05 ? 00:00:00 [kworker/R-netns]
........
每个字段的含义
| 字段 | 含义 |
|---|---|
| F | 进程的标志位,表示进程的优先级和状态等信息。 |
| S | 进程的状态 |
| UID | 进程所属的用户 ID。 |
| PID | 进程的唯一标识符(进程 ID)。 |
| PPID | 父进程的 ID。 |
| C | 进程的 CPU 使用率。 |
| PRI | 进程的优先级,数值越小优先级越高。 |
| NI | 进程的 nice 值,用于调整进程的优先级。 |
| ADDR | 进程的内存地址。 |
| SZ | 进程使用的物理页面数。 |
| WCHAN | 进程正在等待的内核函数。 |
| TTY | 进程相关的终端设备。 |
| TIME | 进程占用的 CPU 时间。 |
| CMD | 进程的命令行。 |
其中,进程状态 S 的几种含义如下所示:
| 状态代码 | 状态描述 | 说明 |
|---|---|---|
| R | 运行状态 (Running) | 进程正在运行或处于可运行状态,等待 CPU 时间片分配。 |
| S | 中断状态 (Sleeping) | 进程处于休眠状态,等待某些事件发生(如 I/O 操作完成)。 |
| D | 不可中断状态 (Disk Sleep) | 进程处于不可中断的休眠状态,通常是等待磁盘 I/O 操作完成,这种状态下进程不会响应信号。 |
| T | 停止状态 (Stopped) | 进程被停止,可能是由于收到停止信号(如 SIGSTOP 或 SIGTSTP),或者在调试过程中被暂停。 |
| Z | 僵尸状态 (Zombie) | 进程已经完成,但其父进程尚未读取其状态信息。僵尸进程不能被终止,因为它们已经“死亡”,但它们仍然占用系统资源,直到父进程读取其状态信息。 |
| W | 无内存页面 (Paging) | 进程正在等待内存页面分配(在某些旧版本的系统中可能会出现)。 |
| X | 死亡状态 (Dead) | 进程已经死亡,但尚未被父进程回收。 |
| < | 高优先级进程 | 表示该进程具有高优先级。 |
| N | 低优先级进程 | 表示该进程具有低优先级。 |
| L | 锁定在内存中 | 表示进程的某些部分被锁定在内存中,不会被交换到磁盘。 |
BSD风格:ps aux
执行结果
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168272 12096 ? Ss 7月05 0:10 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 7月05 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 7月05 0:00 [pool_workqueue_release]
root 4 0.0 0.0 0 0 ? I< 7月05 0:00 [kworker/R-rcu_g]
root 5 0.0 0.0 0 0 ? I< 7月05 0:00 [kworker/R-rcu_p]
root 6 0.0 0.0 0 0 ? I< 7月05 0:00 [kworker/R-slub_]
root 7 0.0 0.0 0 0 ? I< 7月05 0:00 [kworker/R-netns]
root 9 0.0 0.0 0 0 ? I< 7月05 0:00 [kworker/0:0H-events_highpri]
每个字段的含义
| 字段 | 含义 |
|---|---|
| PID | 进程 ID,唯一标识一个进程 |
| USER | 进程所属的用户 |
| PR | 进程的优先级(数值越小优先级越高) |
| NI | 进程的 nice 值(数值越大优先级越低) |
| VIRT | 进程占用的虚拟内存大小(单位为 KB) |
| RES | 进程占用的物理内存大小(单位为 KB) |
| SHR | 进程占用的共享内存大小(单位为 KB) |
| S | 进程状态(R:运行,S:睡眠,D:不可中断睡眠,Z:僵尸进程,T:暂停) |
| %CPU | 进程占用的 CPU 使用率 |
| %MEM | 进程占用的物理内存使用率 |
| TIME | 进程占用的 CPU 时间 |
| COMMAND | 运行的命令及其参数 |
优先级和nice值
Linux的优先级总共的范围有140,对于ubuntu操作系统而言,其范围是-40到99,优先级的数值越低,表示其优先级越高。
Linux中拥有两种类型的调度策略,分别是实时调度策略和普通调度策略。普通调度策略又称为OTHER策略,其调度规则即CFS算法。
普通调度策略不会一定保证某个进程会在规定时间执行。普通调度策略的优先级是从60到99范围之间。在ubuntu系统中,当一个普通进程创建时,其默认优先级是80。普通调度策略优先级的调整是依赖于nice值的。nice值可以用来调整优先级,其范围为-20~19。其中正数表示降低权限,负数表示提升权限。root用户可以任意地修改进程的nice值,其他用户只能提升自己的进程的nice值。使用nice命令和renice命令可以用来调整nice值。
$nice -n 10 ./a.out #注意之后不能使用renice调整它的优先级
$renice -5 pid #执行失败
$renice 5 pid #执行成功,普通用户只能提升nice实时调度策略是针对于实时进程,这些实时进程对于时间延迟非常敏感(想象下如果航天飞机的指令出现延迟造成的灾难性后果),所以普通调度策略不足以满足实时性需求。Linux的实时调度策略有两种,分别是RR和FIFO。其中FIFO以按照先进先出的方式运行进程,除非主动退出,它不会被同级或着更低优先级的进程抢占,只能被更高优先级的进程抢占;RR在FIFO的基础上增加时间片管理,相同优先级的进程会分配相同的时间片,而低优先级的进程无法抢占高优先级的进程,即使高优先级的进程时间片耗尽。只有系统调用 sched_getscheduler 和 sched_setscheduler 才能修改调度策略,使用 nice 系统调用(以及基于它的同名命令)或者 setpriority系统调用这种修改优先级数值的方法无法改变调度策略。
$sudo renice -21 pid
#使用renice最多只能降低20kill命令和任务控制
kill 命令可以用来给指定的进程发送信号。
通常用户经常会从终端启动shell再启动进程,当进程正在运行时,它可以接受一些键盘发送的信号:比如 ctrl+c 表示终止信号, ctrl+z 表示暂停信号。这种可以直接接受键盘信号的状态被称为前台,否则称为后台。当进程处于后台的时候,只能通过 kill 命令发送信号给它。
$kill -9 pid
# 以异常方式终止进程
$kill -l
# 显示所有信号选项:
| 选项 | 含义 |
|---|---|
-s <signal> 或 -<signal> | 指定要发送的信号,可以是信号名称(如 SIGTERM)或信号编号(如 15)。 |
-p | 仅打印目标进程的进程 ID(PID),而不发送信号。 |
-l 或 --list | 列出所有可用的信号名称。如果提供信号编号,则将其转换为信号名称。 |
-L 或 --table | 以表格形式列出所有可用的信号名称及其编号。 |
-a 或 --all | 不限制“命令名到 PID”的转换为具有与当前进程相同 UID 的进程。 |
-q <value> | 使用 sigqueue 而不是 kill,允许发送信号时附加数据。 |
-u <user> | 指定用户,向该用户的所有进程发送信号。 |
--verbose | 打印信号以及接收信号的 PID。 |
--version | 显示 kill 命令的版本信息。 |
--help | 显示帮助信息。 |
kill命令可以发出的所有信号:
| 信号编号 | 信号名称 | 含义 |
|---|---|---|
| 1 | SIGHUP | 挂起信号,通常用于通知进程重新加载配置文件。 |
| 2 | SIGINT | 中断信号,通常由用户按下 Ctrl+C 触发,用于终止进程。 |
| 3 | SIGQUIT | 退出信号,通常由用户按下 Ctrl+\ 触发,用于终止进程并生成核心转储文件。 |
| 6 | SIGABRT | 中止信号,通常用于程序异常终止。 |
| 9 | SIGKILL | 强制终止信号,无法被进程捕获或忽略。 |
| 11 | SIGSEGV | 段错误信号,通常由非法内存访问触发。 |
| 15 | SIGTERM | 终止信号,用于请求进程终止(默认信号)。 |
| 17 | SIGCHLD | 子进程状态改变信号,用于通知父进程子进程已结束或暂停。 |
| 18 | SIGCONT | 继续信号,用于恢复暂停的进程。 |
| 19 | SIGSTOP | 暂停信号,用于暂停进程。 |
| 20 | SIGTSTP | 用户暂停信号,通常由用户按下 Ctrl+Z 触发。 |
| 21 | SIGTTIN | 后台进程读取终端输入时触发的信号。 |
| 22 | SIGTTOU | 后台进程写入终端输出时触发的信号。 |
使用shell启动进程的时候如果在末尾加上 & 符号可以用来直接运行后台进程。
$vim test &
#它会输出一个整形数字,表示它的任务编号使用 ctrl+z 可以暂停当前运行的前台进程,并将其放入后台。它也会输出一个任务编号到屏幕上。
- 使用 jobs 命令可以查看和管理所有的后台任务。
- 使用 fg 命令可以将后台进程拿到前台来。
- 使用 bg 命令可以将后台暂停的程序运行起来。
使用系统调用创建进程
system
system() 是 C 标准库中的一个函数,用于在程序中执行系统命令。
#include <stdlib.h>
int system(const char *command);参数
command:类型:
const char *含义:指向一个以空字符(
\0)结尾的字符串,该字符串包含要执行的系统命令。如果
command是NULL,system()会检查系统是否支持命令处理器(如 shell),但不会执行任何命令。
返回值
返回值是一个
int类型的值,表示命令的执行状态。返回值的含义如下:
0:命令成功执行。非零值:命令执行失败,具体值取决于系统和命令的退出状态。
如果系统不支持命令处理器(如没有 shell),
system()返回-1,并设置errno为ENOSYS。
功能
system()函数通过调用系统的命令处理器(通常是 shell)来执行指定的命令。它会创建一个子进程来运行命令,并等待命令执行完成。
命令的输出会直接显示在终端上,而不是被捕获到程序中。
//system.c
#include <func.h>
int main(){system("sleep 20");return 0;
}如果在程序执行过程使用 ps 命令查看所有进程,我们会发现创建了3个进程,并且3个进程之间存在父子亲缘关系。由于创建进程的时间消耗是很大的,对于性能要求比较苛刻的任务来说,这种使用 system 的方式往往是不能被接受的。
除了可以执行shell指令, system 函数还可以嵌入其他编程语言所编写的程序,比如 python :
//systemPy.c
int main(){//需要在操作系统上装好python3解释器system("python3 hello.py");return 0;
}fork
fork 用于拷贝当前进程以创建一个新进程。
#include <unistd.h>
pid_t fork(void);参数
无参数:
fork()不接受任何参数。
返回值
返回值是一个
pid_t类型的值,表示进程 ID。pid_t是一个整数类型,通常定义在<sys/types.h>或<unistd.h>中。返回值的含义如下:
在父进程中返回子进程的 PID:如果
fork()成功,父进程会收到子进程的进程 ID(PID),这是一个正整数。在子进程中返回 0:子进程会收到返回值
0,表示它是新创建的子进程。失败时返回 -1:如果
fork()失败(例如,系统资源不足),父进程会收到返回值-1,同时会设置errno以指示错误类型。
功能
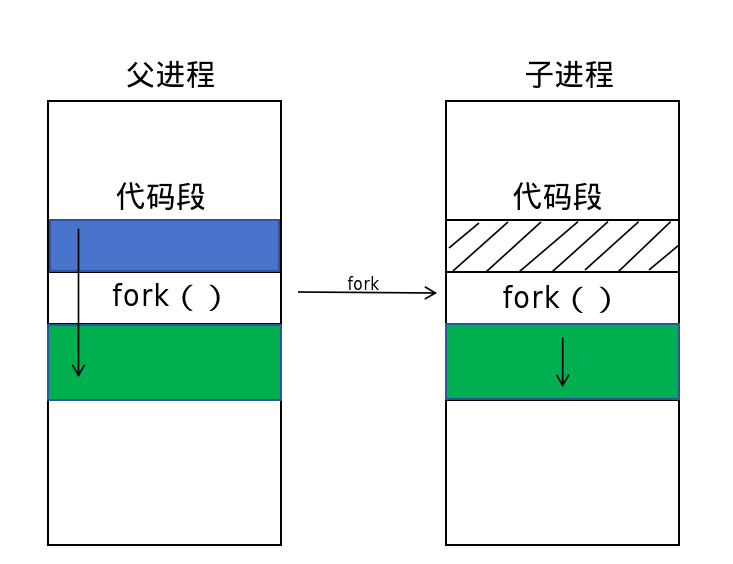
fork()创建一个新的进程(子进程),该子进程是调用进程(父进程)的副本。子进程继承父进程的大部分属性,包括:
文件描述符:子进程继承父进程打开的文件描述符。
环境变量:子进程继承父进程的环境变量。
工作目录:子进程的工作目录与父进程相同。
信号处理:子进程继承父进程的信号处理设置。
子进程的初始状态与父进程相同,但它们是独立的进程,具有不同的进程 ID。
int main() {pid_t pid = fork();if (pid == -1) {perror("fork");return 1;} else if (pid == 0) {// 子进程printf("Child process: PID = %d, Parent PID = %d\n", getpid(), getppid());} else {// 父进程printf("Parent process: PID = %d, Child PID = %d\n", getpid(), pid);wait(NULL); // 等待子进程结束}return 0;
}输出结果
Parent process: PID = 1234, Child PID = 1235
Child process: PID = 1235, Parent PID = 1234fork的资源
通过 fork 创建的子进程,它从父进程继承了进程的地址空间,包括进程上下文、进程堆栈、内存信息、打开的文件描述符、信号控制设定、进程优先级、进程组ID、当前工作目录、根目录、资源限制、控制终端,而子进程所独有的只有它的进程ID、资源使用和计时器等。
int global = 2;
int main(){pid_t pid = fork();int i = 0;if(pid == 0){puts("child");printf("child i = %d,&i = %p, global p = %d, &p = %p\n",i, &i, global, &global);++i;sleep(1);printf("child i = %d,&i = %p, global p = %d, &p = %p\n",i, &i, global, &global);}else{puts("parent");printf("parent i = %d,&i = %p, global p = %d, &p = %p\n",i,&i, global, &global);global++;sleep(2);printf("parent i = %d,&i = %p, global p = %d, &p = %p\n",i,&i, global, &global);//子进程会拷贝父进程的内容,但是修改的内容会互相独立}
}输出结果:
ubuntu@ubuntu:~/MyProject/Linux/process$ ./fork
parent
parent i = 0,&i = 0x7ffd928d38b0, global p = 2, &p = 0x6245e54b7010
child
child i = 0,&i = 0x7ffd928d38b0, global p = 2, &p = 0x6245e54b7010
child i = 1,&i = 0x7ffd928d38b0, global p = 2, &p = 0x6245e54b7010
parent i = 0,&i = 0x7ffd928d38b0, global p = 3, &p = 0x6245e54b7010可以看到进程和线程之间的堆栈和其他数据空间是独立的
fork的写时复制
当执行了 fork 了以后,父子进程地址空间的内容是完全一致,所以完全可以共享同一片物理内存,也就是父子进程的同一个虚拟地址会对应同一个物理内存字节。通常来说,内存的分配单位是页,我们可以为每一个内存页维持一个引用计数。代码段的部分因为只读,所以完全可以多个进程同时共享。而对于地址空间的其他部分,当进程对某个内存页进行写入操作的时候,我们再真正执行被修改的虚拟内存页分配物理内存并拷贝数据,这就是所谓的写时复制。在执行拷贝以后,同样的虚拟地址就无法对应同样物理内存字节了。
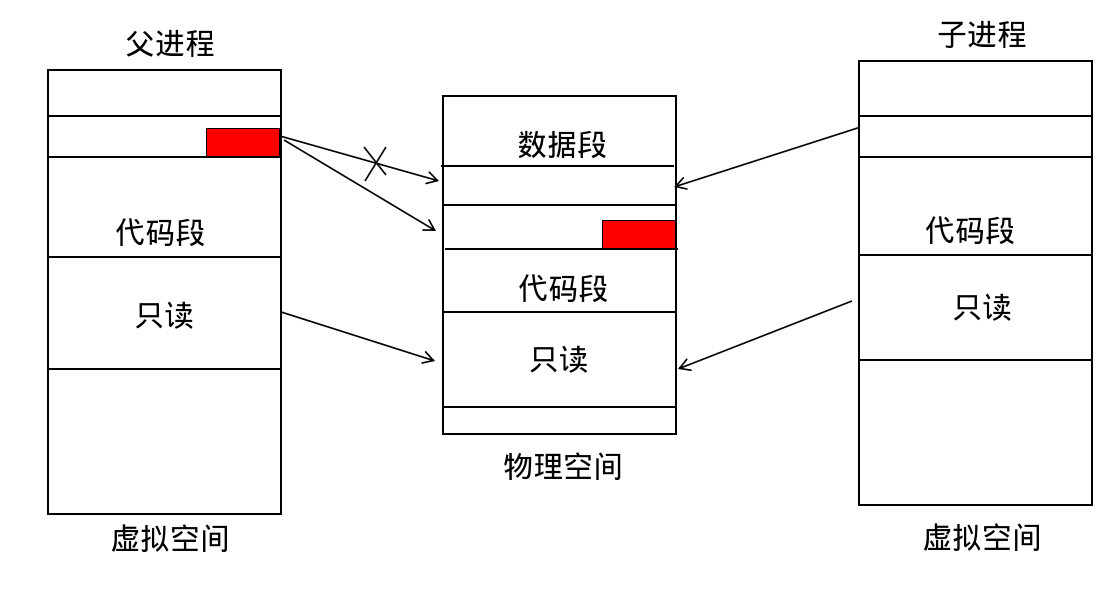 fork对打开文件的影响
fork对打开文件的影响
内核态地址空间拷贝和用户态会有所区别。 fork 产生的子进程会拷贝一份文件描述符数组,但是通过文件描述符所指向的文件对象是共享的。这种拷贝方式类似于 dup 系统调用,所以父子进程对同一个文件对象会共享读写位置。
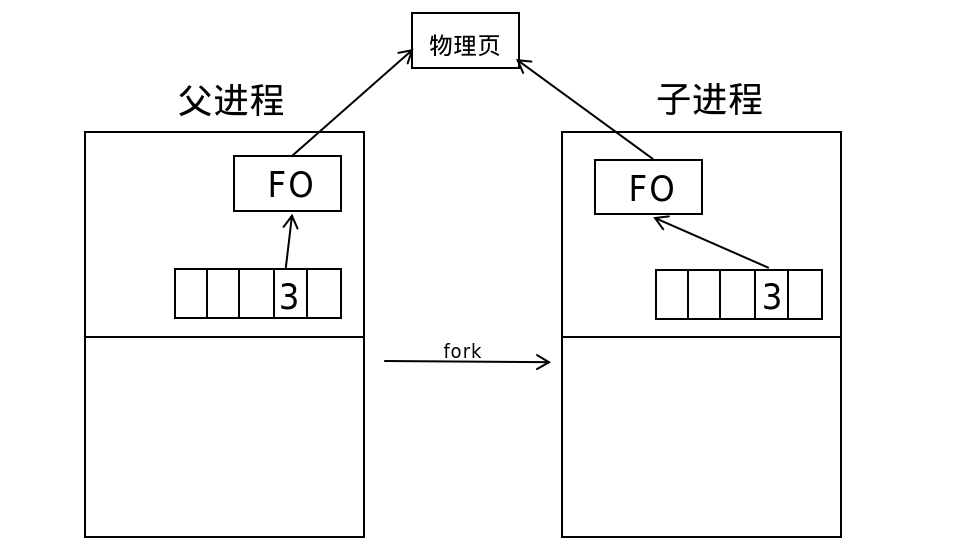
示例:fork()之前打开文件
int main(){int fd = open("file", O_RDWR);//特别注意,文件打开要在fork之前。ERROR_CHECK(fd,-1,"open");pid_t pid = fork();if(pid == 0){printf("I am child process\n");write(fd,"hello",5);lseek(fd,5,SEEK_SET);}else{printf("I am parent process\n");sleep(1);char buf[6] = {0};read(fd,buf,5);printf("I am parent process, buf = %s\n", buf);}
}输出结果:
ubuntu@ubuntu:~/MyProject/Linux/process$ ./forkfile
I am parent process
I am child process
I am parent process, buf = hello可以观察到,在fork之前打开文件的父子进程是共享文件偏移指针的,当子进程写入数据后,如果不重置偏移量,会从写入数据后位置读取,自然读不到数据
示例:fork()之后打开文件
int main(){pid_t pid = fork();if(pid == 0){int fd = open("file", O_RDWR);ERROR_CHECK(fd,-1,"open");printf("I am child process\n");write(fd,"hello",5);}else{printf("I am parent process\n");sleep(1);int fd = open("file", O_RDWR);ERROR_CHECK(fd,-1,"open");char buf[6] = {0};read(fd,buf,5);printf("I am parent process, buf = %s\n", buf);}
}
ubuntu@ubuntu:~/MyProject/Linux/process$ ./forkfile
I am parent process
I am child process
I am parent process, buf = hello可以观察到,在fork之后打开文件的父子进程是不共享文件偏移指针的,当子进程写入数据后,父进程打开的是自己的文件描述符,会从头开始读取数据。
父子进程共享偏移量在文件是标准输出的时候非常有效,这样可以在一个终端界面上显示父子进程的输出。如果尝试对一个文件使用多进程读写,由于共享偏移量的原因,速度并不会更快。此外,文件读写的瓶颈是磁盘的读写效率,所以即便父子进程设法不共享偏移量,对文件读写的速度提升也不会有效果。
exec函数族
当我们执行fork函数创建子进程后,就可以对根据返回的文件描述符分别对子进程和父进程编程。但是,子进程和父进程的程序写在同一个源文件里面十分麻烦。同时子进程还包含了父进程多余的代码段,造成了空间的浪费。对此,我们考虑使用一种函数可以在创建子进程后对进程的内存空间进行“大换血”,重置子进程的全部内容,使其更好的运行。
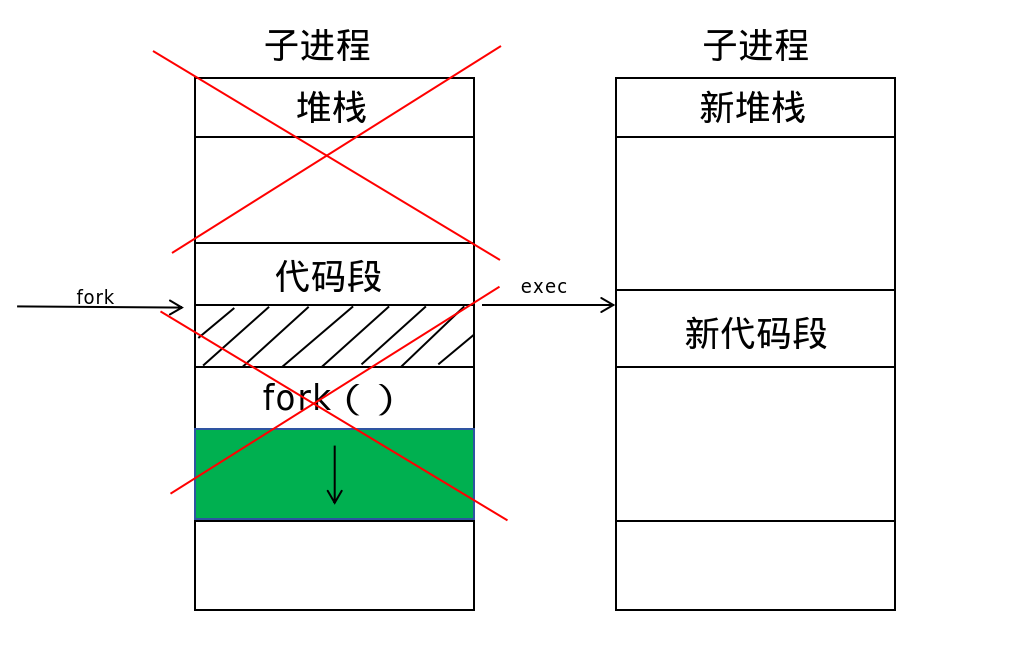
exec* 是一系列的系统调用。它们通常适用于在 fork 之后,将子进程的指令部分进行替换修改。当进程执行到 exec* 系统调用的时候,它会将传入的指令来取代进程本身的代码段、数据段、栈和堆,然后将PC指针重置为新的代码段的入口。 exec* 当中包括多个不同的函数,这些函数之间只是在传入参数上面有少许的区别。
execl
#include <unistd.h>
int execl(const char *path, const char *arg, ...);参数
path:类型:
const char *含义:指向可执行文件的路径名(可以是绝对路径或相对路径)。
如果路径是绝对路径(如
/bin/ls),execl会直接使用该路径查找文件。如果路径是相对路径(如
./my_program),execl会从当前工作目录开始查找。不会在环境变量
PATH中查找。
execl("/bin/ls", "ls", "-l", NULL); // 绝对路径
execl("./my_program", "my_program", NULL); // 相对路径arg:类型:
const char *含义:传递给新程序的参数列表。第一个参数通常是程序的名称,后续参数是程序的参数,最后一个参数必须是
NULL,表示参数列表的结束。参数通过可变参数列表传递,适合参数数量已知且固定的情况。
参数列表以
NULL结尾,表示参数的结束。
execl("/bin/ls", "ls", "-l", NULL);返回值
如果调用成功,
execl不会返回,因为当前进程会被新程序替换。如果调用失败,返回
-1,并设置errno以指示错误类型。
功能
execl用于加载并执行指定路径的可执行文件。参数通过可变参数列表传递,适合参数数量已知的情况。
execlp
#include <unistd.h>
int execlp(const char *file, const char *arg, ...);参数
file:类型:
const char *含义:指向可执行文件的文件名(可以不包含路径)。
如果路径是绝对路径(如
/bin/ls),execlp会直接使用该路径查找文件。如果路径是相对路径(如
./my_program),execlp会从当前工作目录开始查找。如果路径未指定(如只提供文件名),
execlp会在环境变量PATH中查找可执行文件。
execlp("ls", "ls", "-l", NULL); // 在 PATH 中查找
execlp("/bin/ls", "ls", "-l", NULL); // 绝对路径
execlp("./my_program", "my_program", NULL); // 相对路径arg:类型:
const char *含义:传递给新程序的参数列表。第一个参数通常是程序的名称,后续参数是程序的参数,最后一个参数必须是
NULL,表示参数列表的结束。
返回值
如果调用成功,
execlp不会返回,因为当前进程会被新程序替换。如果调用失败,返回
-1,并设置errno以指示错误类型。
功能
execlp用于加载并执行指定文件名的可执行文件。如果路径未指定,
execlp会在环境变量PATH中查找可执行文件。参数通过可变参数列表传递,适合参数数量已知的情况。
execv
#include <unistd.h>
int execv(const char *path, char *const argv[]);参数
path:类型:
const char *含义:指向可执行文件的路径名(可以是绝对路径或相对路径)。与execl类似
argv:类型:
char *const argv[]含义:一个以
NULL结尾的字符串数组,包含传递给新程序的参数。argv[0]通常是程序的名称,argv[1]是第一个参数,依此类推。参数通过字符串数组传递,适合参数数量未知或动态生成的情况。
参数数组以
NULL结尾,表示参数的结束。
char *argv[] = {"ls", "-l", NULL};
execv("/bin/ls", argv);返回值
如果调用成功,
execv不会返回,因为当前进程会被新程序替换。如果调用失败,返回
-1,并设置errno以指示错误类型。
功能
execv用于加载并执行指定路径的可执行文件。参数通过数组传递,适合参数数量未知或动态生成的情况。
execvp
#include <unistd.h>
int execvp(const char *file, char *const argv[]);参数
file:类型:
const char *含义:指向可执行文件的文件名(可以不包含路径)。与execlp类似
argv:类型:
char *const argv[]含义:一个以
NULL结尾的字符串数组,包含传递给新程序的参数。argv[0]通常是程序的名称,argv[1]是第一个参数,依此类推。
返回值
如果调用成功,
execvp不会返回,因为当前进程会被新程序替换。如果调用失败,返回
-1,并设置errno以指示错误类型。
功能
execvp用于加载并执行指定文件名的可执行文件。如果路径未指定,
execvp会在环境变量PATH中查找可执行文件。参数通过数组传递,适合参数数量未知或动态生成的情况。
execlp 和 execvp 会在环境变量 PATH 中查找可执行文件,而 execl 和 execv 需要显式指定路径。
如果文件名中包含路径分隔符(如 /),则不会在 PATH 中查找。
如果
exec系列函数失败,会返回-1,并设置errno。常见的错误包括:文件未找到(
ENOENT)。权限不足(
EACCES)。文件不是可执行文件(
ENOTDIR或EISDIR)。
成功调用
exec系列函数后,当前进程的代码、数据和堆栈会被新程序替换,但文件描述符、环境变量等会保留。
示例
int main(int argc, char const *argv[]){pid_t pid = fork();if(pid == 0){printf("I am child\n");//execl("./add","add","3","4",(char *)0);char *const argv[] = {"add","3","4",NULL};execv("./add",argv);printf("you can not see me!\n");//这句话并不会打印}else{printf("I am parent\n");printf("you can see me!\n");sleep(1);}return 0;
}int main(int argc, char const *argv[])
{int a = atoi(argv[1]);int b = atoi(argv[2]);printf("%d\n",a + b);return 0;
}
结果:
ubuntu@ubuntu:~/MyProject/Linux/process$ ./exec
I am parent
you can see me!
I am child
7实际上,我们之前所使用的 system 函数以及从bash或者是其他shell启动进程的本质就是 fork+exec 。
进程控制
孤儿进程
如果父进程先于子进程退出,则子进程成为孤儿进程,此时将自动被PID为1的进程(即init)收养。当一个孤儿进程退出以后,它的资源清理会交给它的父进程(此时为init)来处理。
int main(int argc, char *argv[]){pid_t pid =fork();if(pid == 0){printf("I am child\n");while(1);}else{printf("I am parent\n");return 0;//在main函数中执行return语句是退出进程}
}
//随后可以使用ps -elf|grep orphan 查看子进程的父进程ID就是1
//也可以在代码中使用getppid()int main(int argc, char const *argv[])
{int a = atoi(argv[1]);int b = atoi(argv[2]);printf("%d\n",a + b);return 0;
}
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./orphan
I am parent
I am child
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
我们打开另外一个终端, 将这个孤儿进程终止
(base) ubuntu@ubuntu:~$ ps -elf | grep orphan
1 S ubuntu 605990 601887 0 80 0 - 695 hrtime 21:27 pts/1 00:00:00 ./orphan
0 S ubuntu 606120 603491 0 80 0 - 3048 pipe_r 21:28 pts/0 00:00:00 grep --color=auto orphan
(base) ubuntu@ubuntu:~$ kill 605990
可以看到 orphan 的父进程是 601887,我们搜索这个进程
(base) ubuntu@ubuntu:~$ ps -elf | grep 601887
4 S ubuntu 601887 1 0 80 0 - 4521 ep_pol 21:15 ? 00:00:00 /lib/systemd/systemd --user
5 S ubuntu 601888 601887 0 80 0 - 42821 - 21:15 ? 00:00:00 (sd-pam)
0 S ubuntu 601895 601887 0 69 -11 - 10664 ep_pol 21:15 ? 00:00:00 /usr/bin/pipewire
0 S ubuntu 601896 601887 0 80 0 - 6637 ep_pol 21:15 ? 00:00:00 /usr/bin/pipewire-media-session
0 S ubuntu 601897 601887 0 69 -11 - 618655 do_pol 21:15 ? 00:00:02 /usr/bin/pulseaudio --daemonize=no --log-target=journal
该进程是systemd,专门用于回收孤儿进程,它的父进程是 1 号进程(init)
僵尸进程
如果子进程先退出,系统不会自动清理掉子进程的环境,而必须由父进程调用 wait 或 waitpid 函数来完成清理工作,如果父进程不做清理工作,则已经退出的子进程将成为僵尸进程(defunct),在系统中如果存在的僵尸(zombie)进程过多,将会影响系统的性能,所以必须对僵尸进程进行理。
int main(int argc, char *argv[])
{pid_t pid =fork();if(pid == 0){printf("I am child\n");return 0;}else{printf("I am parent\n");while(1){printf("hello\n");sleep(1);}}
}
//随后使用ps -elf|grep zombie 可以看到一个<defunct>的僵尸标记输出结果:
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./zombie
I am parent
hello
I am child
hello
hello
hello
hello
hello
hello
hello
(base) ubuntu@ubuntu:~$ ps -elf | grep zombie
0 S ubuntu 606648 603876 0 80 0 - 695 hrtime 21:46 pts/1 00:00:00 ./zombie
1 Z ubuntu 606649 606648 0 80 0 - 0 - 21:46 pts/1 00:00:00 [zombie] <defunct>
0 S ubuntu 606681 603491 0 80 0 - 3048 pipe_r 21:46 pts/0 00:00:00 grep --color=auto zombie
其中 606649 号进程,也就该程序的子进程,已经变为了僵尸进程。
当一个进程执行结束时,它会向它的父进程发送一个SIGCHLD信号,从而父进程可以根据子进程的终止情况进行处理。在父进程处理之前,内核必须要在进程队列当中维持已经终止的子进程的PCB。如果僵尸进程过多,将会占据过多的内核态空间。并且僵尸进程的状态无法转换成其他任何进程状态。
wait和waitpid
wait 和 waitpid 系统调用都会阻塞父进程,等待一个已经退出的子进程,并进行清理工作; wait 随机地等待一个已经退出的子进程,并返回该子进程的PID; waitpid 等待指定PID的子进程;如果为-1表示等待所有子进程。
wait
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);参数
status:类型:
int *含义:指向一个整数的指针,用于存储子进程的退出状态。
如果不需要获取子进程的退出状态,可以将此参数设置为
NULL。
返回值
返回值是一个
pid_t类型的值,表示子进程的 PID。成功:返回子进程的 PID。
失败:返回
-1,并设置errno以指示错误类型。
功能
wait使父进程暂停执行,直到任意一个子进程结束。如果父进程没有子进程,
wait会立即返回-1,并设置errno为ECHILD。子进程的退出状态通过
status参数返回。可以通过宏(如WIFEXITED、WEXITSTATUS等)来解析状态值。
int main(int argc, char const *argv[])
{pid_t pid = fork();if(pid == 0){printf("I am child,pid = %d, ppid = %d\n",getpid(),getppid());sleep(5);return 0;}else{printf("I am parent\n");pid_t cpid;cpid = wait(NULL);printf("cpid = %d\n", cpid);return 0;}return 0;
}
waitpid
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);参数
pid:类型:
pid_t含义:指定要等待的子进程的 PID。
可能的值:
-1:等待任意子进程。>0:等待指定的子进程(PID)。0:等待与调用进程在同一进程组的任意子进程。< -1:等待在指定进程组中的任意子进程(-pid)。
status:类型:
int *含义:指向一个整数的指针,用于存储子进程的退出状态。
如果不需要获取子进程的退出状态,可以将此参数设置为
NULL。
options:类型:
int含义:控制
waitpid的行为。可以是以下标志的组合:WNOHANG:非阻塞模式,如果子进程尚未结束,立即返回-1,并设置errno为EAGAIN。WUNTRACED:报告被暂停的子进程。WCONTINUED:报告被继续执行的子进程。
返回值
返回值是一个
pid_t类型的值,表示子进程的 PID。成功:返回子进程的 PID。
失败:返回
-1,并设置errno以指示错误类型。
功能
waitpid提供了更灵活的等待子进程的方式。可以指定等待特定的子进程,或者等待符合某些条件的子进程。
支持非阻塞模式(
WNOHANG),允许父进程在子进程尚未结束时继续执行。
解析子进程状态
status 参数是一个整型指针。如果不关心进程的退出状态,那么该参数可以是一个空指针;否则
wait 函数会将进程终止的状态存入参数所指向的内存区域。这个整型的内存区域中由两部分组成,其中一些位用来表示退出状态(当正常退出时),而另外一些位用来指示发生异常时的信号编号,有以下几个宏可以用来检查状态的情况
WIFEXITED(status):检查子进程是否正常退出。子进程正常退出的时候返回真,此时可以使用 WEXITSTATUS(status),获取子进程的返回情况WEXITSTATUS(status):获取子进程的退出状态码(仅当WIFEXITED为真时有效)。WIFSIGNALED(status):检查子进程是否因信号而终止。子进程异常退出的时候返回真,此时可以使用 WTERMSIG(status) 获取信号编号,可以使用 WCOREDUMP(status) 获取是否产生core文件WTERMSIG(status):获取终止子进程的信号编号(仅当WIFSIGNALED为真时有效)。WIFSTOPPED(status):检查子进程是否被暂停(仅当WUNTRACED被设置时有效)。子进程暂停的时候返回真,此时可以使用 WSTOPSIG(status) 获取信号编号WSTOPSIG(status):获取暂停子进程的信号编号(仅当WIFSTOPPED为真时有效)。
示例:
int main()
{pid_t pid = fork();int status;if(pid == 0){printf("child, pid = %d, ppid = %d\n", getpid(),getppid());char *p = NULL;*p = 'a';return 123;}else{printf("parent, pid = %d, ppid = %d\n", getpid(),getppid());//wait(&status);waitpid(pid,&status,0);//第三个参数为0,和直接使用wait没有说明区别if(WIFEXITED(status)){printf("child exit code = %d\n", WEXITSTATUS(status));}else if(WIFSIGNALED(status)){printf("child crash, signal = %d\n",WTERMSIG(status));}}return 0;
}输出结果:
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./waitpid
parent, pid = 611045, ppid = 603876
child, pid = 611046, ppid = 611045
child crash, signal = 11由于我们定义了一个字符指针,在未实例化的情况下强行赋值导致进程异常终止。WIFSIGNALED(status) 根据返回的status对应的位捕获到了这个问题,并输出了对应的信号。
默认情况下, wait 和 waitpid 都会使进程处于阻塞状态,也就是执行系统调用时,进程会中止运行。如果给 waitpid 的options参数设置一个名为WNOHANG的宏,则系统调用会变成非阻塞模式:当执行这个系统调用时,进程会立刻检查是否有子进程发送子进程终止信号,如果没有则系统调用立即返回。
示例:
int main()
{pid_t pid = fork();int status;if(pid == 0){printf("child, pid = %d, ppid = %d\n", getpid(),getppid());sleep(5);return 123;}else{printf("parent, pid = %d, ppid = %d\n", getpid(),getppid());int ret = waitpid(pid,&status,WNOHANG);//第三个参数为0,和直接使用wait没有说明区别if(ret > 0){if(WIFEXITED(status)){printf("child exit code = %d\n", WEXITSTATUS(status));}else if(WIFSIGNALED(status)){printf("child crash, signal = %d\n",WTERMSIG(status));}}printf("ret = %d\n",ret);}return 0;
}输出结果:
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./waitpid
parent, pid = 614136, ppid = 603876
ret = 0
child, pid = 614137, ppid = 601887进程的终止
在进程阶段,进程总共有5种终止方式,其中3种是正常终止,还有2种是异常终止:
| 终止方式 | 终止情况 |
| 在main函数调用return | 正常 |
| 调用exit函数 | 正常 |
| 调用_Exit函数或者_exit函数 | 正常 |
| 调用abort函数 | 异常 |
| 接受到能引起进程终止的信号 | 异常 |
exit 函数、 _Exit 函数和 _exit 函数可以立刻终止进程,无论当前进程正在执行什么函数。注意,和一般的函数不同,调用这3个退出函数是没有返回返回值这个过程的。当调用 _exit 和 _Exit 的时候,进程会直接终止返回内核,而 exit 它的实现会多一些额外步骤,它会首先执行终止处理程序(使用atexit 函数可以注册终止处理程序),然后清理标准IO(就是把所有打开的流执行一次 fclose ),最后再终止进程回到内核。
exit
#include <stdlib.h>
void exit(int status);参数
status:类型:
int含义:退出状态码,通常用于向父进程或操作系统报告程序的退出状态。
常见的退出状态码:
0:表示程序成功退出。EXIT_SUCCESS:表示程序成功退出(等同于0)。EXIT_FAILURE:表示程序失败退出(通常为1)。
功能
exit是 C 标准库中的函数,用于终止程序。它会执行以下操作:
调用已注册的退出处理函数:通过
atexit()注册的函数会在exit被调用时依次执行。关闭所有文件流:关闭所有打开的文件流(如
FILE *),并刷新缓冲区。清理动态分配的内存:虽然 C 标准库不会自动释放动态分配的内存,但
exit会确保程序的资源被正确清理。返回状态码给操作系统:将
status传递给操作系统,表示程序的退出状态。
_exit
#include <unistd.h>
void _exit(int status);参数
status:类型:
int含义:退出状态码,与
exit的参数相同。
功能
_exit是 Unix 系统调用,用于立即终止进程。它不会执行以下操作:
不会调用注册的退出处理函数:不会执行通过
atexit()注册的函数。不会关闭文件流:不会刷新文件流的缓冲区。
不会清理动态分配的内存:不会执行任何资源清理操作。
_exit直接通知操作系统终止进程,并返回状态码。
_Exit
#include <stdlib.h>
void _Exit(int status);参数
status:类型:
int含义:退出状态码,与
exit和_exit的参数相同。
功能
_Exit是 C99 标准引入的函数,行为类似于_exit。它不会执行以下操作:
不会调用注册的退出处理函数:不会执行通过
atexit()注册的函数。不会关闭文件流:不会刷新文件流的缓冲区。
不会清理动态分配的内存:不会执行任何资源清理操作。
_Exit直接通知操作系统终止进程,并返回状态码。
适用场景
exit:适用于主程序中,需要确保资源被正确清理的情况。
适用于需要执行退出前的清理操作(如关闭文件、释放内存)的情况。
_exit和_Exit:适用于子进程中,尤其是在调用
fork()后,子进程执行完任务需要立即退出的情况。适用于需要快速终止进程且不需要执行任何清理操作的情况。
如果在程序没有注意缓冲区,并且又使用了 _exit 或者是 _Exit 的话,很容易出现缓冲区内容丢失的情况。
int func(){printf("func");//这里不要添加换行符_exit(3);//这种情况func不会打印
}
int main(int argc, char *argv[]){pid_t pid = fork();if(pid == 0){puts("child");func();return 0;}else{puts("parent");int status;wait(&status);if(WIFEXITED(status)){printf("child exit code = %d\n",WEXITSTATUS(status));}}return 0;
}abort
abort 是 C 标准库中的一个函数,用于终止程序的执行,并生成一个异常信号(通常是 SIGABRT)。这个函数常用于处理错误情况,特别是在程序检测到不可恢复的错误时。
#include <stdlib.h>
void abort(void);参数
无参数:
abort不接受任何参数。
返回值
abort不返回任何值。它会终止程序的执行,并且不会返回到调用它的代码。
功能
发送信号:
abort会向当前进程发送SIGABRT信号。默认情况下,
SIGABRT信号会导致程序终止,并且可能生成一个核心转储文件(core dump),这有助于调试程序。如果不希望生成核心转储文件,可以调整操作系统的设置或禁用核心转储。
终止程序:
如果
SIGABRT信号没有被捕捉或处理,程序将立即终止。如果程序安装了信号处理函数来处理
SIGABRT,则信号处理函数会被调用。如果信号处理函数返回,abort会再次尝试终止程序。
清理操作:
与
exit不同,abort不会调用通过atexit或on_exit注册的清理函数。也不会关闭文件流或刷新缓冲区。
abort是一种“紧急终止”机制,通常用于处理不可恢复的错误。如果可能,尽量使用更优雅的错误处理机制(如
exit或返回错误码)来终止程序。
示例:
void handle_abort(int sig) {printf("SIGABRT caught. Cleaning up...\n");// 执行清理操作exit(EXIT_FAILURE);
}int main() {signal(SIGABRT, handle_abort); // 设置信号处理函数abort(); // 触发 SIGABRTreturn 0;
}守护进程
大致上来说,所谓守护进程(daemon),就是在默默运行在后台的进程,也称作“后台服务进程”,通常守护进程的命名会以d结尾。为了更准确地把握守护进程的概念,需要先了解一些其他的概念。
终端
终端是登录到Linux操作系统所需要的入口设备。终端可以是本地的,也可以是远程的。当操作系统启动的时候,init进程会创建子进程并使用 exec 来执行getty程序,从而打开终端设备或者等待远程登录,然后再使用 exec 调用login程序验证用户名和密码。
进程组
每个进程除了有一个进程ID以外,还属于一个进程组。前文曾经提到过,使用键盘中断给前台进程发送信号的时候,是会给一个进程组的所有进程来发送信号的。进程组是一个或者多个进程构成的集合。不同的进程组拥有不同的进程组ID,每个进程组有一个组长进程,组长的PID就是进程组ID。进程组组长可以创建一个进程组、创建组中进程,但是只要进程组当中存在至少一个进程(这个进程可以不是组长),该进程组就存在。
getpgrp
#include <unistd.h>
pid_t getpgrp(void);参数
无参数:
getpgrp不接受任何参数。
返回值
返回值是一个
pid_t类型的值,表示调用进程的进程组 ID(PGID)。如果调用成功,返回值是非负整数。
如果调用失败,返回值是
-1,并设置errno以指示错误类型。
功能
getpgrp用于获取调用进程的进程组 ID(PGID)。进程组是一个或多个进程的集合,通常用于信号发送和作业控制。
getpgid
#include <sys/types.h>
#include <unistd.h>
pid_t getpgid(pid_t pid);参数
pid:类型:
pid_t含义:指定要查询的进程的 PID。
可能的值:
0:查询调用进程的进程组 ID。>0:查询指定进程的进程组 ID。<0:无效值,会导致错误。
返回值
返回值是一个
pid_t类型的值,表示指定进程的进程组 ID(PGID)。如果调用成功,返回值是非负整数。
如果调用失败,返回值是
-1,并设置errno以指示错误类型。
功能
getpgid用于获取指定进程的进程组 ID(PGID)。如果
pid为0,则等同于getpgrp,返回调用进程的进程组 ID。如果
pid为其他正值,则返回指定进程的进程组 ID。
注意这里要区别一下之前的 getegid(),它是用于获取有效组 ID,而不是进程组 ID。
有效组ID(Effective Group ID,EGID)是与进程权限相关的属性,用于决定进程在访问文件和资源时的权限。
假设有一个文件,其权限设置为仅允许特定用户组访问。当一个进程尝试访问该文件时,操作系统会检查该进程的有效组 ID 是否属于该用户组。
进程组(Process Group)是一个或多个进程的集合,用于信号发送和作业控制。
假设你在一个终端中运行了一个程序,该程序启动了多个子进程。这些子进程通常属于同一个进程组,这样你可以通过向整个进程组发送信号来控制它们。
示例:
int main()
{pid_t pid = fork();if(pid == 0){printf("child, pid = %d, ppid = %d, pgid = %d\n", getpid(), getppid(),getpgid(0));exit(0);}else{printf("parent, pid = %d, ppid = %d, pgid = %d\n", getpid(), getppid(),getpgid(0));wait(NULL);exit(0);}
}输出结果:
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./pgid
parent, pid = 11866, ppid = 11505, pgid = 11866
child, pid = 11867, ppid = 11866, pgid = 11866进程 fork 产生一个子进程以后,子进程默认和父进程属于同一个进程组。 setpgid 系统调用可以用来修改进程或者是 exec 之前的子进程的进程组ID。
setpgid
#include <sys/types.h>
#include <unistd.h>
int setpgid(pid_t pid, pid_t pgid);参数
pid:类型:
pid_t含义:指定要设置进程组 ID 的进程的 PID。
可能的值:
0:表示设置调用进程自身的进程组 ID。>0:表示设置指定进程的进程组 ID。<0:无效值,会导致错误。
pgid:类型:
pid_t含义:指定要加入的进程组 ID。
可能的值:
0:表示将指定进程加入到其父进程所在的进程组。>0:表示将指定进程加入到指定的进程组。<0:无效值,会导致错误。
返回值
成功:返回
0。失败:返回
-1,并设置errno以指示错误类型。
功能
setpgid()用于将一个进程加入到一个进程组中。如果
pid为0,则操作作用于调用进程自身。如果
pgid为0,则进程会被加入到其父进程所在的进程组。进程组通常用于信号发送和作业控制。
错误处理
EPERM:调用进程没有权限将指定进程加入到指定的进程组。ESRCH:指定的pid不存在。EINVAL:指定的pgid无效。EACCES:调用进程试图将自己加入到一个它没有权限加入的进程组。ELOOP:调用进程试图将自己加入到一个循环的进程组结构中。
示例:
int main()
{pid_t pid = fork();if(pid == 0){printf("child, pid = %d, ppid = %d, pgid = %d\n", getpid(), getppid(), getpgid(0));setpgid(0,0);printf("child, pid = %d, ppid = %d, pgid = %d\n", getpid(), getppid(), getpgid(0));while(1){sleep(1);}}else{printf("parent, pid = %d, ppid = %d, pgid = %d\n", getpid(), getppid(), getpgid(0));while(1){sleep(1);}}
}输出结果:
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./setpgid
parent, pid = 13078, ppid = 11505, pgid = 13078
child, pid = 13079, ppid = 13078, pgid = 13078
child, pid = 13079, ppid = 13078, pgid = 13079调用了 setpgid 后,子进程从父进程组中脱离。此时按下 ctrl + c 只会终止父进程,发出的信号不再影响子进程。
然后我们用 ps 查看一下子进程
(base) ubuntu@ubuntu:~$ ps -elf | grep setpgid
1 S ubuntu 13079 1512 0 80 0 - 695 hrtime 19:49 pts/0 00:00:00 ./setpgid
0 S ubuntu 13124 12920 0 80 0 - 3048 pipe_r 19:49 pts/1 00:00:00 grep --color=auto setpgid可以看到它还在正常执行。
会话
会话是一个或者多个进程组的集合。创建新会话的进程被称为新会话的会话首进程,会话首进程的PID就是会话ID。shell当中的管道可以用来构造如下所示的会话。
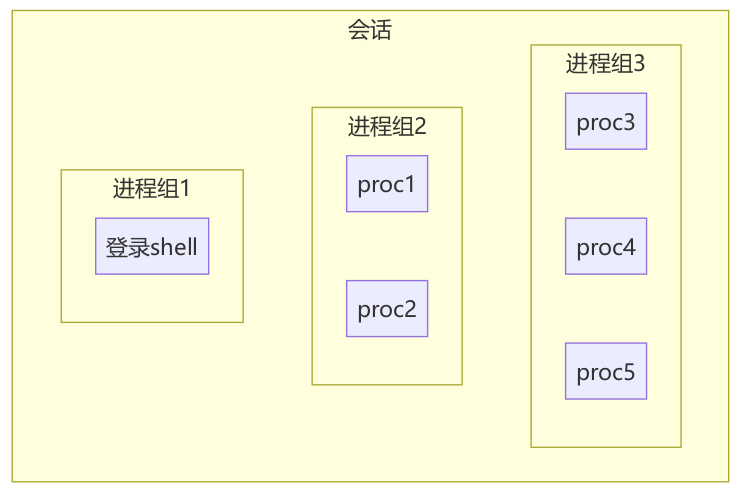
会话拥有一些特征:
- 一个会话可以有一个控制终端。
- 和控制终端建立连接的会话首进程被称为控制进程。(通常登录时会自动连接,或者使用 open 打开文件 /dev/tty )
- 一个会话存在最多一个前台进程组和多个后台进程组,如果会话和控制终端相连,则必定存在一个前台进程组。
- 从终端输入的中断,会将信号发送到前台进程组所有进程
- 终端断开连接,挂断信号会发送给控制进程
对于目前不是进程组组长的进程,可以使用系统调用 setsid 可以新建一个会话。使用 getsid 可以获取会话ID。
getsid
#include <sys/types.h>
#include <unistd.h>
pid_t getsid(pid_t pid);参数
pid:类型:
pid_t含义:指定要查询的进程的 PID。
可能的值:
0:查询调用进程的会话 ID。>0:查询指定进程的会话 ID。<0:无效值,会导致错误。
返回值
返回值是一个
pid_t类型的值,表示指定进程的会话 ID。如果调用成功,返回值是非负整数。
如果调用失败,返回值是
-1,并设置errno以指示错误类型。
功能
getsid()用于获取指定进程的会话 ID(Session ID)。会话 ID 是一个进程组的集合,通常用于管理多个进程组。
会话 ID 的组长进程通常是会话的创建者。
setsid
#include <unistd.h>
pid_t setsid(void);参数
无参数:
setsid()不接受任何参数。
返回值
返回值是一个
pid_t类型的值,表示新创建的会话 ID。如果调用成功,返回值是非负整数。
如果调用失败,返回值是
-1,并设置errno以指示错误类型。
功能
setsid()用于创建一个新的会话,并将调用进程设置为该会话的组长。调用
setsid()的进程必须满足以下条件:进程不能是会话的组长。
进程不能是进程组的组长。
setsid()会执行以下操作:创建一个新的会话。
将调用进程设置为该会话的组长。
将调用进程的进程组 ID 设置为新的会话 ID。
调用进程与控制终端断开连接(如果存在)。
示例:
#include<54func.h>
int main(){pid_t pid = fork();if(pid == 0){printf("child, pid = %d, ppid = %d, pgid = %d, sid = %d\n", getpid(), getppid(), getpgid(0), getsid(0));int ret = setsid();//注意不能是进程组组长ERROR_CHECK(ret,-1,"setsid");printf("child, pid = %d, ppid = %d, pgid = %d, sid = %d\n", getpid(), getppid(), getpgid(0), getsid(0));while(1){sleep(1);}exit(0);}else{printf("parent, pid = %d, ppid = %d, pgid = %d, sid = %d\n\n", getpid(), getppid(), getpgid(0), getsid(0));while(1){sleep(1);}wait(NULL);exit(0);}
}输出结果:
(base) ubuntu@ubuntu:~/MyProject/Linux/process$ ./getsid
parent, pid = 17217, ppid = 11505, pgid = 17217, sid = 11505child, pid = 17218, ppid = 17217, pgid = 17217, sid = 11505
child, pid = 17218, ppid = 17217, pgid = 17218, sid = 17218守护进程的创建流程
要手动创建一个守护进程,无论如何都要从终端运行一个程序来实现,但是一旦终端关闭,这个进程就结束了。但是我们可以通过运行程序创建一个子进程,然后改变会话使其脱离父进程管制。再关闭父进程,这样子进程就不再依赖于终端,变成了守护进程。
- 父进程创建子进程,然后让父进程终止。
- 在子进程当中创建新会话,脱离父进程。
- 修改当前工作目录为根目录,因为正在使用的目录是不能卸载的。
- 重设文件权限掩码为0,避免创建文件的权限受限。守护进程继承了父进程的掩码,这可能不符合守护进程的需求。
- 关闭不需要的文件描述符,比如0、1、2。守护进程不再依赖于终端,对标准输入输出的执行是非法的,因为它们默认向终端输出结果。之后的的输出会重定向到日志文件中,
这些操作的目的是确保守护进程能够独立运行,不会受到父进程环境的影响,同时避免资源泄漏和安全问题。
创建示例:
void Daemon()
{const int MAXFD=64;int i=0;if(fork()!=0){exit(0);} //父进程退出setsid();//成为新进程组组长和新会话领导,脱离控制终端chdir("/");//设置工作目录为根目录umask(0);//重设文件访问权限掩码for(;i<MAXFD;i++){close(i);//尽可能关闭所有从父进程继承来的文件}}
int main(int argc, char *argv[]){Daemon(); //成为守护进程while(1){sleep(1);}return 0;
}守护进程和日志
使用守护进程经常可以用记录日志。操作系统的日志文件存储在 /var/log/messages 中。
syslog
#include <syslog.h>
void syslog(int priority, const char *format, ...);参数
priority:类型:
int含义:日志消息的优先级,由设施(facility)和日志级别(log level)组合而成。
设施(facility)表示消息的来源,例如
LOG_USER、LOG_DAEMON等。日志级别(log level)表示消息的严重性,例如
LOG_INFO、LOG_ERR等。优先级的计算公式为:
priority = facility | log_level。常见的日志级别包括:
LOG_EMERG:紧急情况,系统无法使用。LOG_ALERT:必须立即采取行动的情况。LOG_CRIT:严重错误,需要立即处理。LOG_ERR:普通错误。LOG_WARNING:警告信息。LOG_NOTICE:正常但重要的信息。LOG_INFO:普通信息。LOG_DEBUG:调试信息。
日志设施用于指定消息的来源,常见的日志设施包括:
LOG_USER:用户级消息。LOG_DAEMON:系统守护进程。LOG_MAIL:邮件系统。LOG_SYSLOG:内部 syslog 服务。
format:类型:
const char *含义:格式化字符串,类似于
printf的格式化字符串。用于指定日志消息的格式。
...:类型:可变参数列表
含义:与
format指定的格式化字符串对应的参数。
返回值
syslog是一个void函数,没有返回值。
功能
syslog用于将日志消息发送到系统日志守护进程。日志消息的优先级由设施和日志级别组合而成,这决定了消息的来源和严重性。
日志消息的格式和内容由
format和可变参数列表决定。日志消息最终会被记录到系统的日志文件中,通常由
syslogd守护进程管理。
示例:
int main(){int i = 0;if(fork() > 0)exit(0);setsid();chdir("/");umask(0);for(; i < 64; i++){close(i);}i = 0;while(i < 10){printf("%d\n",i);time_t ttime;time(&ttime);struct tm *pTm = gmtime(&ttime);syslog(LOG_INFO,"%d %04d:%02d:%02d", i, (1900 + pTm->tm_year), (1 + pTm->tm_mon), (pTm->tm_mday));i++;sleep(2);}
}