Python爬虫实战:Requests与Selenium详解
目录
一 网络爬虫的了解
1 爬虫库
urllib库
requests库
scrapy库
selenium库
2 注意!!!
二 requests库
1 request库的安装
2 认识网页资源
3 获取网页资源
4 小案例
5 代理服务器
三 selenium
1 准备工作
2 应用
3 实例
一 网络爬虫的了解
网络爬虫是一种自动化程序,用于从互联网上抓取、解析和存储网页数据。通常用于搜索引擎、数据分析或信息聚合等场景。
1 爬虫库
python给我们提供了多个爬虫库,下面我们来先了解四个
urllib库
urllib是Python内置的HTTP请求库,包含多个模块用于处理URL操作。主要模块包括urllib.request(打开和读取URL)、urllib.error(异常处理)、urllib.parse(解析URL)和urllib.robotparser(解析robots.txt文件)。适用于简单的HTTP请求,但功能相对基础,缺乏高级特性如会话保持和连接池。
requests库
requests是一个第三方HTTP库,基于urllib开发,但提供了更简洁的API和更强大的功能。支持HTTP连接保持、会话对象、Cookie持久化、文件上传等。其设计注重易用性,适合大多数HTTP请求场景,如API调用或网页抓取。
scrapy库
scrapy是一个开源的爬虫框架,用于大规模数据抓取。提供完整的爬虫工作流管理,包括请求调度、数据提取、存储等。支持异步处理、中间件扩展和分布式爬取。适合复杂爬虫项目,但学习曲线较陡峭,需遵循框架的设计模式。
selenium库
selenium是一个自动化测试工具,主要用于浏览器自动化。通过驱动真实浏览器(如Chrome、Firefox)模拟用户操作,支持JavaScript渲染页面的抓取。适用于动态网页或需要交互的场景,但性能较低,资源消耗较大。
四者的选择取决于需求:简单请求用requests,复杂爬虫用scrapy,动态页面用selenium,而urllib适合无需依赖第三方库的基础场景。
这篇我们来具体学习requests,selenium库
2 注意!!!
所有学习爬虫的学者在学习爬虫之前都要阅读爬虫规则,不是所有网站上的资源都允许爬取的,我们在爬取之前要查看该网站的robots.txt规则。下面以CSDN为例查看一下
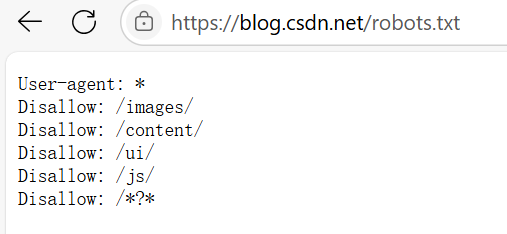
上面列举了这些不能爬取的。如果硬爬的话小心进局子!
二 requests库
1 request库的安装
在命令提示符窗口或pycharm终端进行安装。(如果比较慢,我们可以用清华源安装)
pip install requests -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple2 认识网页资源
我们可以通过在网页空白处,点击左键,会出现
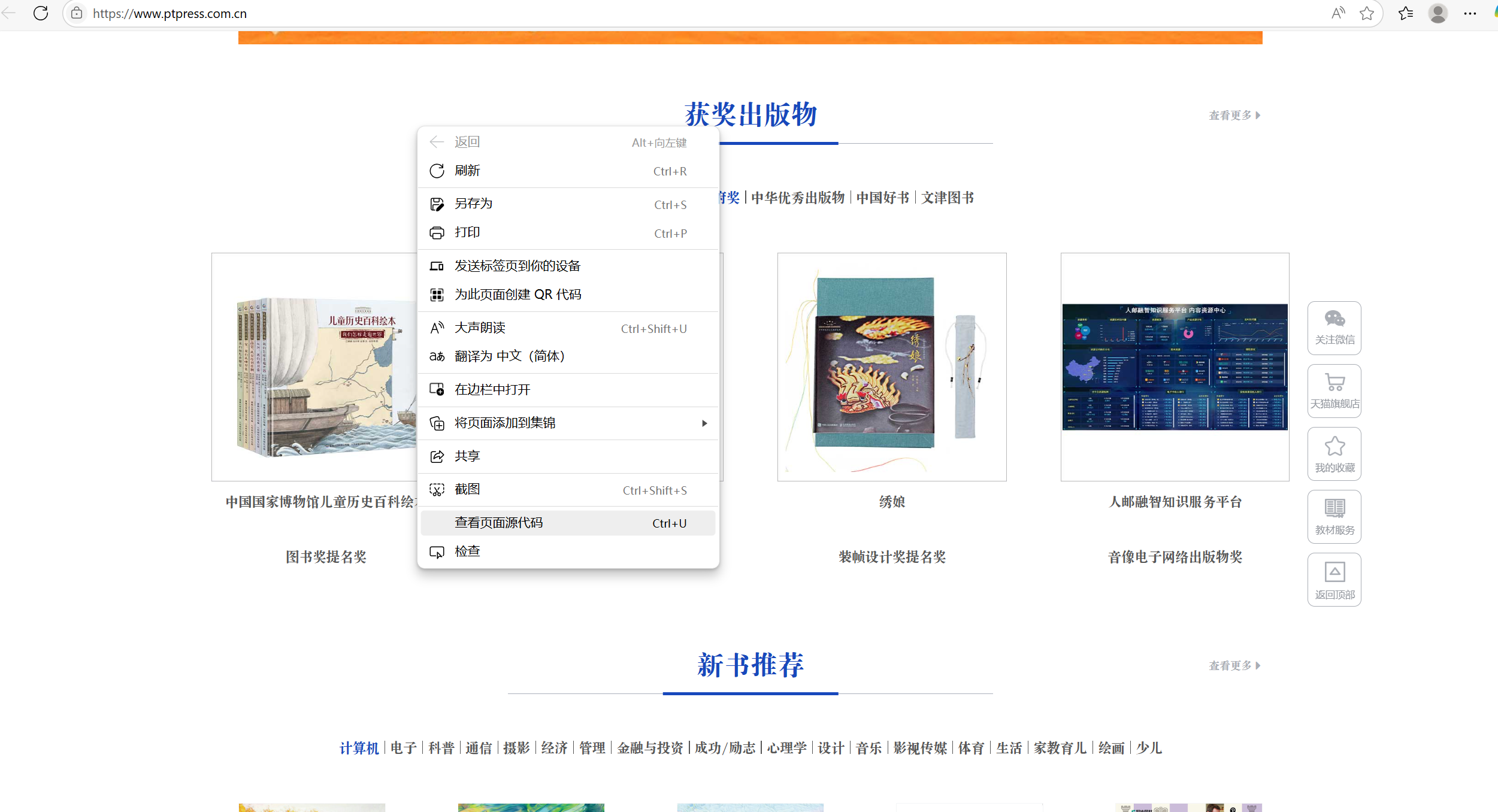
网页源代码
我们先点击一下查看页面源代码,我们查找一下.jpg发现没有一张图片但网页中却存在许多杂照片,这是是因为.jpg是经过浏览器渲染之后才会出现的,在源代码中不存在.jpg格式的数据
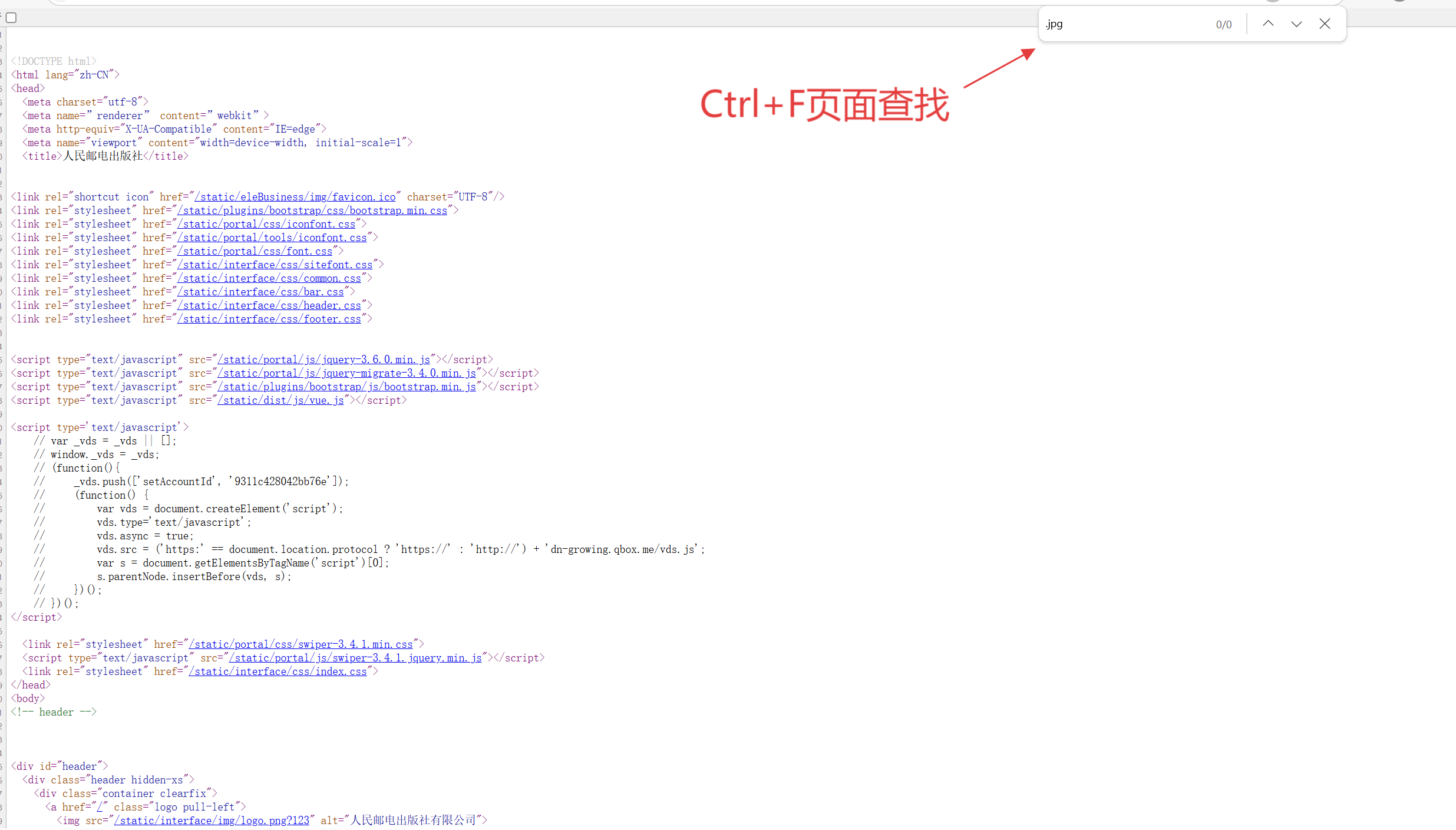
检查
我们点击完检查,然后再点击中间那个按钮,然后就可以自动定位到这个图片的url了,我们也就可以使用了,所有这个是渲染之后的
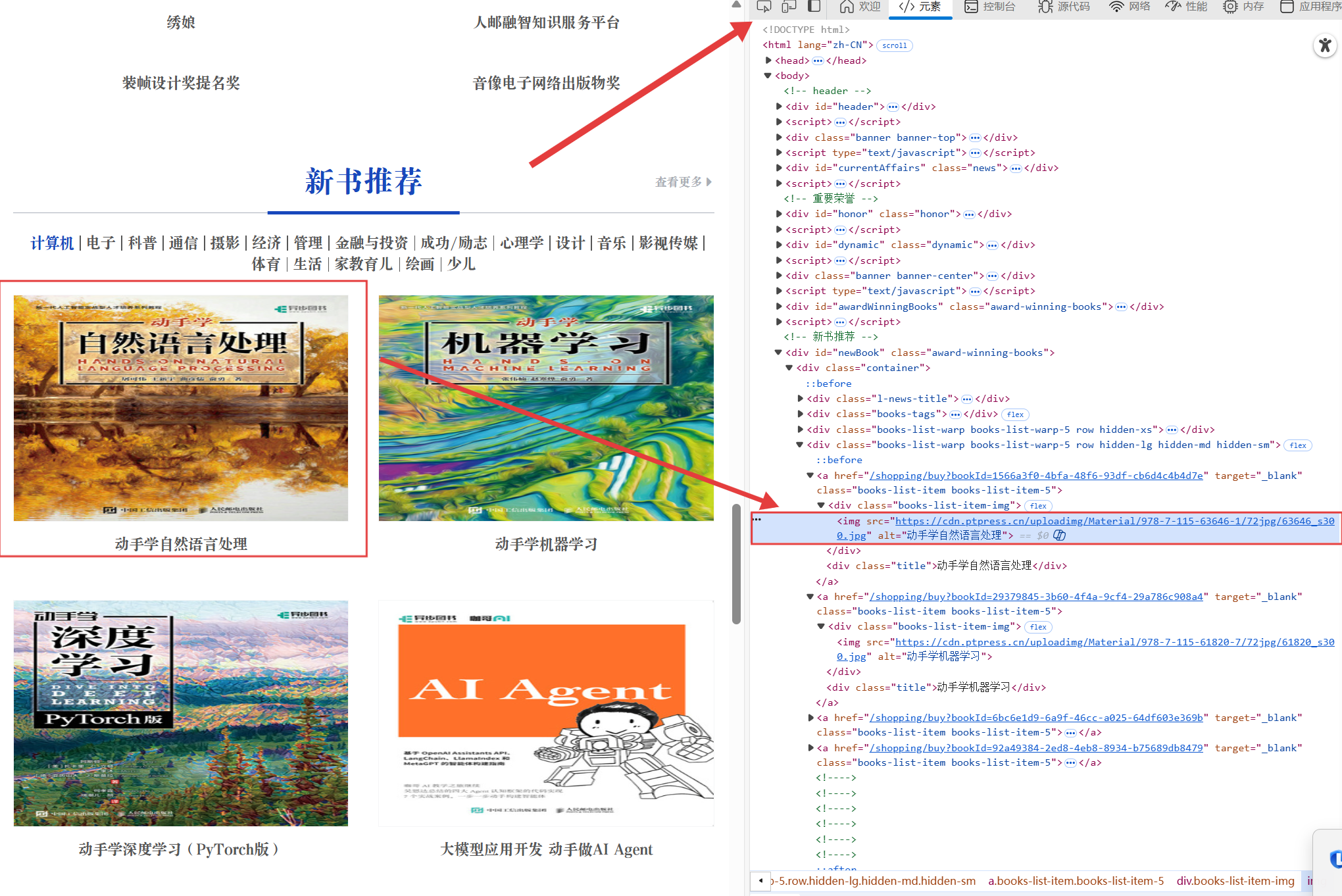
我们先点击中间那个按钮,然后就可以自动定位到这个图片的url了,我们也就可以使用了,所有这个是渲染之后的
3 获取网页资源
我们用get()函数来获取,这个函数有三个形参,分别是
url 图片的HTML网址
params 可选参数,构造url字符串的
返回值是一个由类Response创建的对象
下面举例
import requests
r=requests.get("https://www.ptpress.com.cn/search",params={'keyword': 'Python教程'})
r.encoding=r.apparent_encoding
n=r.status_code
print(r.text)
print(n)这段代码,在get中,我们有两个参数,一个url为中国邮电出版社的网址,一个params为一个字典{'keyword': 'Python教程'},这行代码也相当于
https://www.ptpress.com.cn/?keyword=python只查找一个python可能会有点麻烦,但如果要查找许多个这样写就会便捷许多
如果不对编码进行调整,返回的text就会有乱码的部分,这里将检测到的编码赋值给了我们设定对象类的编码。
这里我们还对状态码进行了检查,如果状态码为404,那么这个网页不存在、如果是200则请求成功,如果500则是内部服务器错误。
4 返回页面内容
有个问题,我们这里返回的是网页源代码还是检查得到的内容呢,
我们在返回值中查询,结果得到的.jpg的数量还是0,说明这个是返回的源代码的内容
import requests
r=requests.get(r"https://cdn.ptpress.cn/uploadimg/Material/978-7-115-66932-2/72jpg/66932_s300.jpg")
f=open("test.jpg","wb")
f.write(r.content)
f.close()这个代码中我们输入的一个.jpg格式的网站,然后我们把这个内容保存到了一个二进制文件中,然后就变成了一个图片了,这个说明了r.content返回的内容和上面.txt返回的内容不一样,这个返回的是一个保存着这个图片的二进制的文件。
图片、音频、视频、压缩包可以用.content保存,HTML、JSON等可以用.txt保存
4 小案例
我们把一个网站中所有的书名打印下来
import re
import requests
r=requests.get(r"https://www.ryjiaoyu.com/book")
# title="计算机应用基础习题与实验教程(Windows 10+Office 2016)(第3版)">计算机应用基础习题与实验教程(Windows 10+Office 2016)(第3版)</a></h4>
result=re.findall(r'title=(.+?)">(.+?)</a></h4>',r.text)
print(result)
for i in range(len(result)) :print('第'+str(i+1)+'本书:'+result[i][1])输出结果:
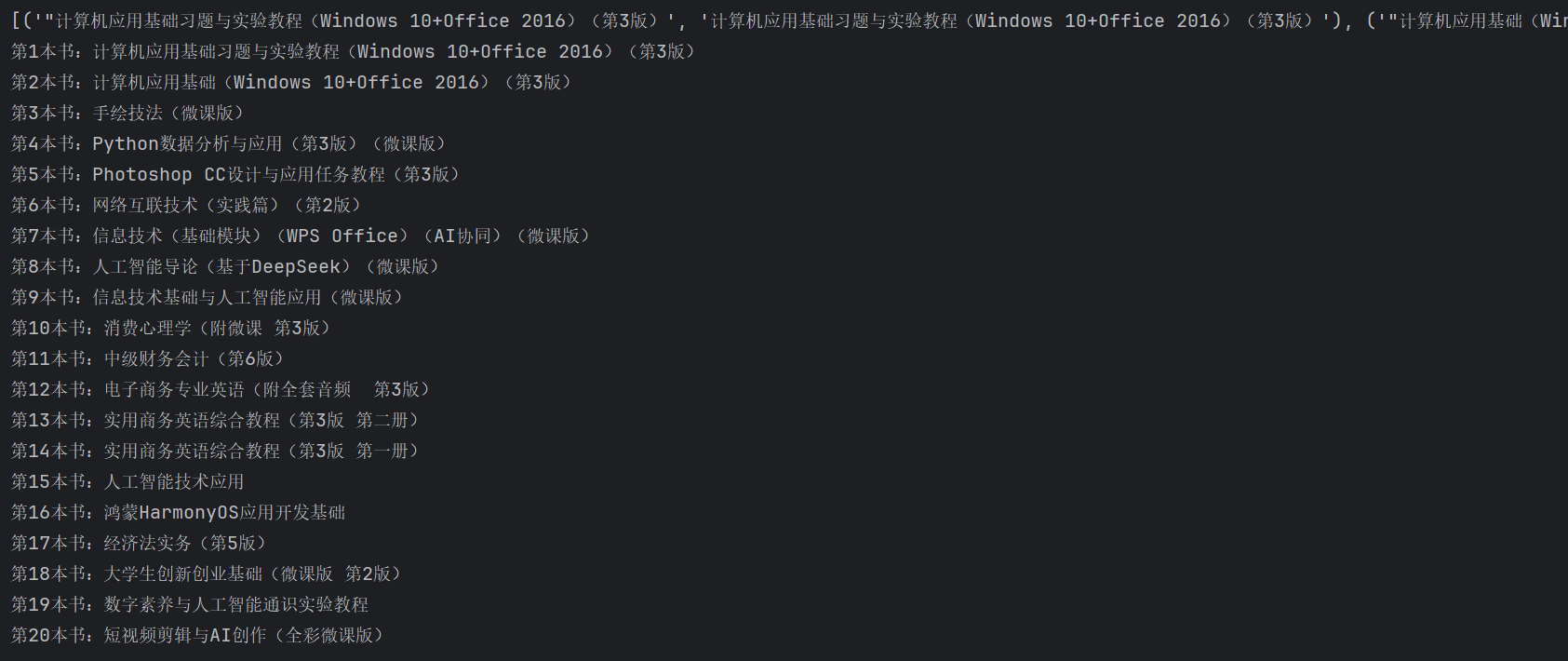
代码解读:
首先导入库,然后用requests.get()函数读取网址内容,然后观察网址中我们要找书名存在位置行的特征,写出正则表达式,我们这里保存下来的结果是一个列表,列表中包含若干个元组,然后我们循环打印出索引为1的值就出结果了
5 代理服务器
代理服务器就是当我们请求过多被加入黑名单之后,然后可以通过买代理服务器来继续请求,这个服务器可以理解成另一个电脑,建立链接,我们向代理服务器发送请求,然后代理服务器把请求发送给目标网站,然后目标网站返回信息,代理服务器在返回给我们。
使用方法
import requestsproxie={'http':'代理服务器ip'}
response = requests.get("https://www.ptpress.com.cn/",proxies=proxie)
print(response.text) # 获取网页内容
这里http应为代理服务器网址,可以买,免费的很少且不稳定。
三 selenium
驱动真实浏览器(如Chrome、Firefox)模拟用户操作,且浏览器可以实现页面的渲染,因此我们很容易获得选然后的数据信息。(说明这里我们得到的是’检查‘得到的内容)
1 准备工作
selenium可以驱动内核,但我们还是要安装对应版本的浏览器的内核驱动程序以便于更好的驱动浏览器。下面我们来安装下WebDriver
第一步 先查看我们电脑的浏览器版本号(不同浏览器的驱动也不一样,我这里是edge)
在右上角有三个点,下面可以看到关于Microsoft Edfe

然后可以查看到,我的浏览器内核版本为138.0.3351.95
第二步 去官网下载
Microsoft Edge WebDriver | Microsoft Edge Developer上面可以找到对应版本。一般我们电脑下载x64位就好了
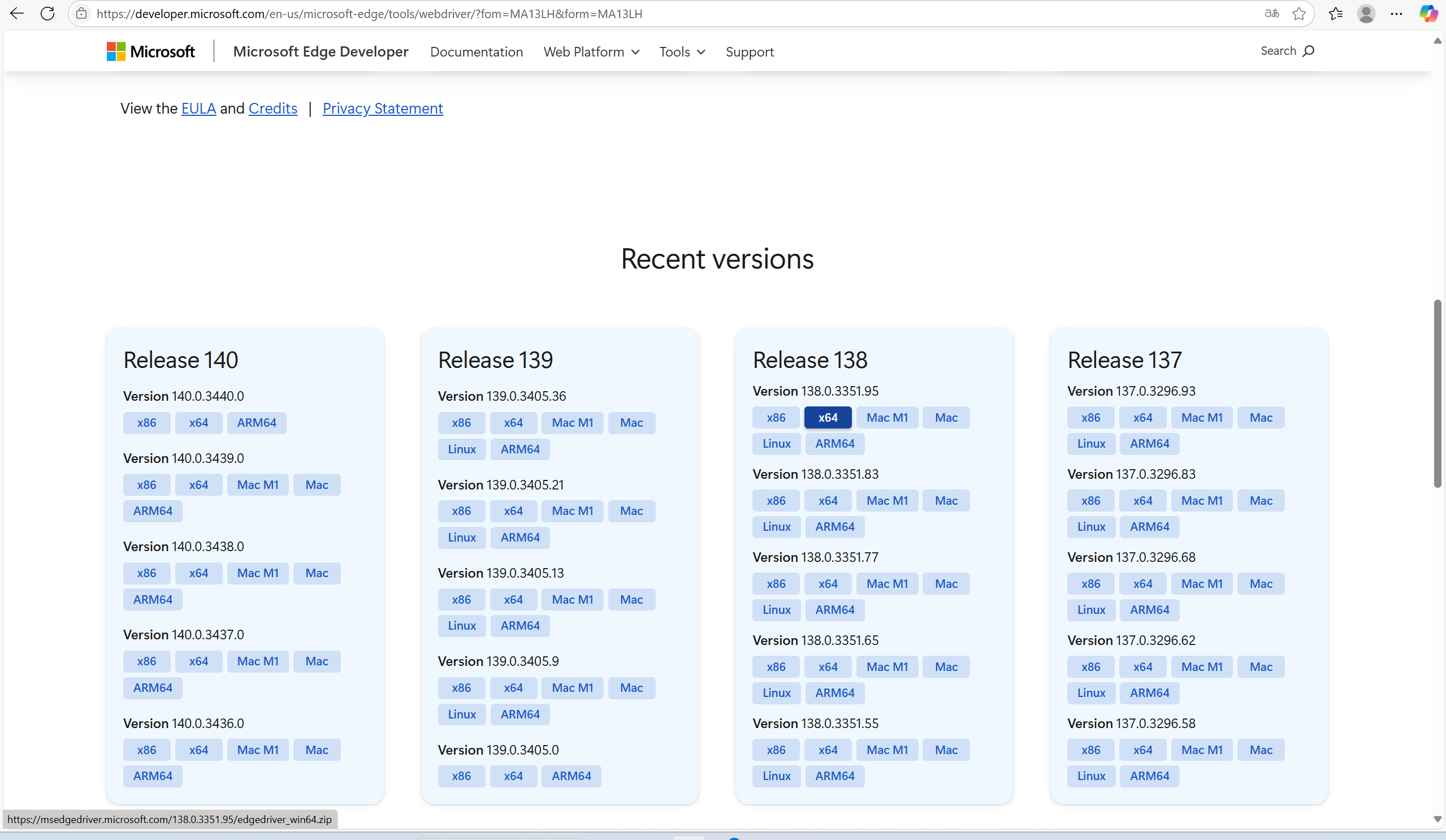
第三步 把msedgedriver放到我们python的Scripts中

(最好scripts中和python所在文件夹中分别放一个)
第四步 下载selenium库
直接在终端pip安装就好
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple2 应用
import time
import requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/search?keyword=c++&jc=")
print(driver.page_source)
sleep(100)不同人的edge的位置可能不用,要修改下edge_options.binary_locatio
不同浏览器的这个也不同,例如我的edge是这样webdriver.Edge(options=edge_options)驱动的
如果是谷歌就是driver = webdriver.Edge(options=chrome_options)
然后就可以驱动起来了,但是驱动完又会直接退出,这里可以sleep一下
加载网页用driver.get()来加载,填入url就可以加载页面了
可以通过driver.page_source来获取渲染后的网页代码,下面是部分

3 实例
使用selenium把中国邮电出版社的c++板块的几本书图片给爬下来。
import re
import timeimport requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/search?keyword=c++&jc=")
print(driver.page_source)
result=re.findall('<img src="(.+?jpg)">',driver.page_source)suresult=re.findall('</div><p>(.+?)</p></a>',driver.page_source)for i in range(len(result)):r = requests.get(result[i])name=r'c++图书/'+suresult[i].replace(" ", "")+'.jpg'f = open(name, "wb")f.write(r.content)f.close()
输出结果
