python-字典、集合、序列切片、字符串操作(笔记)
一、字符串常见操作(重点)
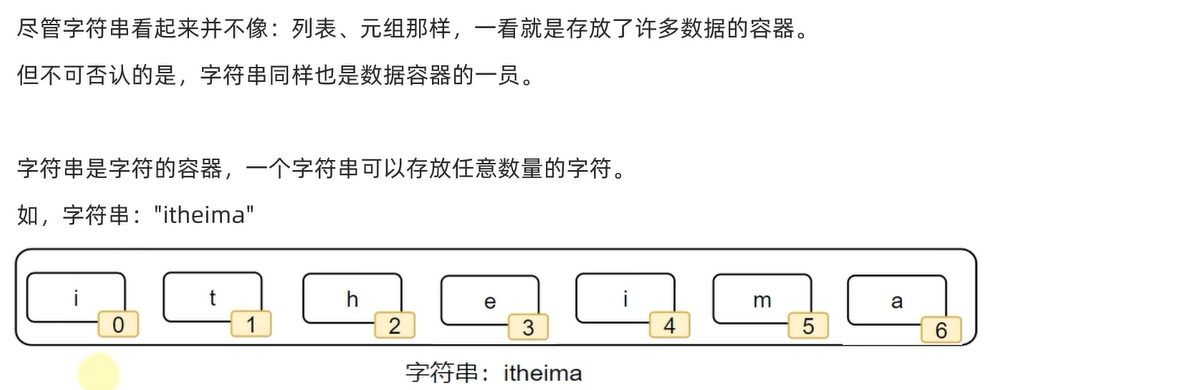
1.

2.字符串无法修改
#错误示范
str1="djskds"
str1[2]="3"
3.
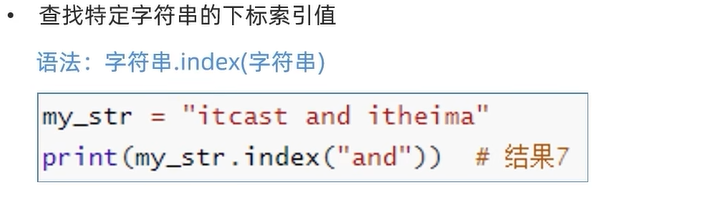
str1="abcand"
# 输出3
print(str1.index("and"))
4.

str1="abcand"
newStr=str1.replace("and","sel")
print(newStr)
5.

str2="a b c d e"
print(str2.split(" "))
6.
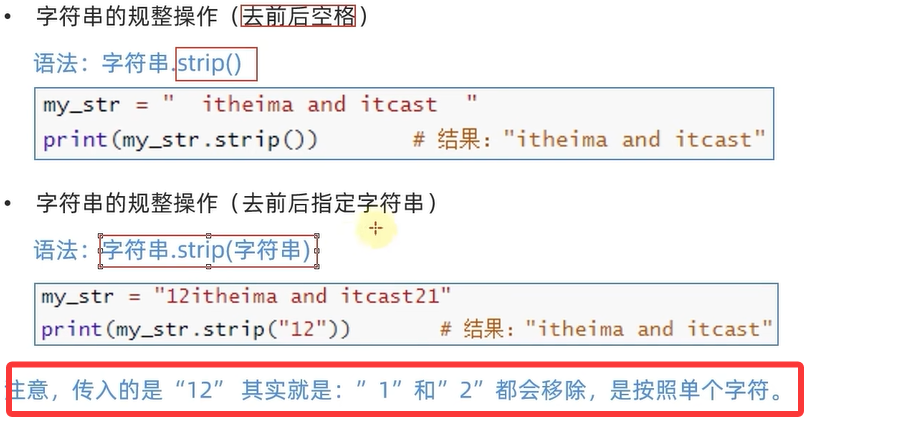
str2=" a b c d e "
print(str2.strip())
str2="12a b c d e12"
print(str2.strip("12"))
7.![]()
str2=" a b c d e "
print(str2.count(" "))
str2=" a b c d e "
print(len(str2))二、序列容器切片(重点)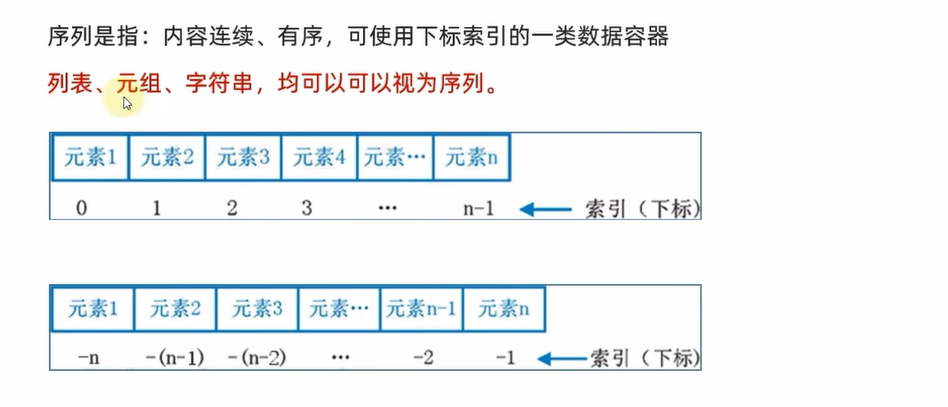


![]()






list=[1,2,3,4,5,6,7,8,9,10]
# 针对List进行切片 不包括4这个结尾
print(list[0:4])
# 起始留空默认从头开始 结尾留空默认到末尾
print(list[:])
# 起始留空默认从头开始 结尾留空默认到末尾(包含最后一个,也就是全部了) 但是间隔要为2
print(list[::2])
# 起始留空默认从头开始 结尾留空默认到末尾 但是间隔要为-1 这时候就是要逆着取,相当于倒序输出
print(list[::-1])
# 从三开始到1结束 不包括1 下标间隔为-1
print(list[3:1:-1])
# 逆序 下标为-2
print(list[::-2])
#输出
[1, 2, 3, 4]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 3, 5, 7, 9]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[4, 3]
[10, 8, 6, 4, 2]

三、集合
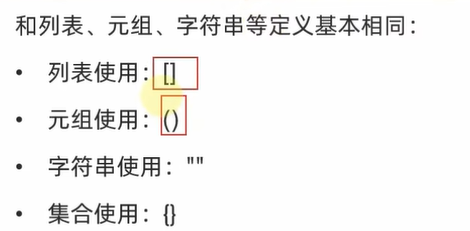

my_set={1,1,2,3,3,3,4,5,5,5,5,5,6,7,7,8,9,9,9,9,9,10}
print(my_set)#out
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}1.

2.

#添加后,该元素的位置也是不固定的,以及添加相同的元素也会自己去重
my_set={"xxx","yyy","zzzz","aaaa"}my_set.add("dddd")print(my_set)3.

my_set={"xxx","yyy","zzzz","aaaa"}my_set.remove("aaaa")print(my_set)4.

my_set={"xxx","yyy","zzzz","aaaa"}print(my_set.pop())5.
6.

my_set={"xxx","yyy","zzzz","aaaa"}my_set2={"xxx"}print(my_set.difference(my_set2))#out
{'yyy', 'aaaa', 'zzzz'}7.

my_set={"xxx","yyy","zzzz","aaaa"}my_set2={"xxx"}print(my_set.difference_update(my_set2))
#out
{'yyy', 'aaaa', 'zzzz'}
#就是消除两个不同集合共有的8.

my_set={"xxx","yyy","zzzz","aaaa"}my_set2={"xxx","yyy","xxx"}
print(my_set.union(my_set2))9.![]() 去重后的长度
去重后的长度
10.
#每次循环遍历的顺序都不一样
my_set={"xxx","yyy","zzzz","aaaa"}for x in my_set:print(x)
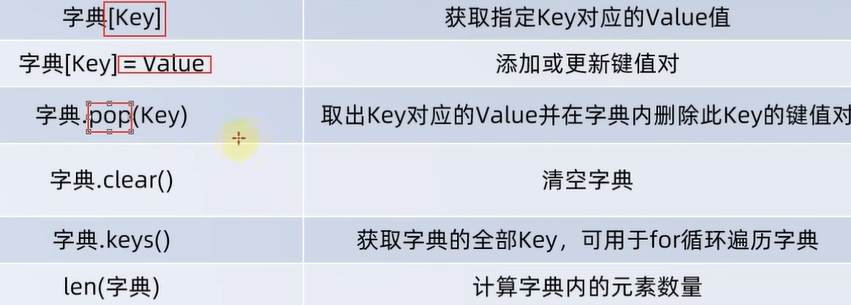
三、字典(重点,后端返回的json格式等数据,经常需要用到)


![]()

1.key不能重复,否则取出来的值会被覆盖

my_dick={"zs":90,"ls":80,"ww":70}
print(my_dick["zs"])2.这个键和值都是不受限,除了key不能是字典


my_dick={"zs":{"math":30,"chinese":44,"English":50},"lssi":{"math":330,"chinese":443,"English":530},"ww":{"math":330,"chinese":434,"English":503}}
print(my_dick["zs"])
print(my_dick["zs"]["math"])
#out
{'math': 30, 'chinese': 44, 'English': 50}
30
3.

4.
my_dick={"zs":66,"lssi":77,"ww":55}
my_dick["zhaoliu"]=5
print(my_dick){'zs': 66, 'lssi': 77, 'ww': 55, 'zhaoliu': 5}5.

my_dick={"zs":66,"lssi":77,"ww":55}
my_dick["zs"]=5
print(my_dick)
{'zs': 5, 'lssi': 77, 'ww': 55}6.

my_dick={"zs":66,"lssi":77,"ww":55}
my_dick.pop("zs")
print(my_dick)
{'lssi': 77, 'ww': 55}
7.

my_dick={"zs":66,"lssi":77,"ww":55}print(my_dick.keys())
dict_keys(['zs', 'lssi', 'ww'])8.遍历字典
#方法一:
my_dick={"zs":66,"lssi":77,"ww":55}
keys1=my_dick.keys()
for key in keys1:print(my_dick[key])
#方法二:直接遍历字典,然后以key名称作为临时变量,字典自己会去识别这个变量名
for key in my_dick:print(my_dick[key])
66
77
559.![]()