MySQL(2)索引篇
1、什么是索引?
索引相当于是数据库的目录,是以空间换时间的设计思想,索引的定义就是帮助存储引擎快速获取数据的一种数据结构。
所谓的存储引擎,说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法,存储引擎就是一个方法库。


2、为什么MySQL采用B+树作为索引?
为什么 MySQL 采用 B+ 树作为索引? | 小林coding
MySQL的数据是持久化的,即数据(索引+记录)是保存到磁盘上的,因为这样即使设备断电了,数据也不会丢失。
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block)。Linux 中的块大小为 4KB,也就是一次磁盘 I/O 操作会直接读写8个扇区。
由于数据库的索引是保存到磁盘上的,因此当我们通过索引查找某行数据的时候,就需要先从磁盘读取索引到内存,再通过索引从磁盘中找到某行数据,然后读入到内存,也就是说查询过程中会发生多次磁盘 I/O,而磁盘 I/O 次数越多,所消耗的时间也就越大。所以,我们希望索引的数据结构能在尽可能少的磁盘的 I/O 操作中完成查询工作。那么采用什么数据结构能够尽可能减少磁盘 I/O 的次数呢?
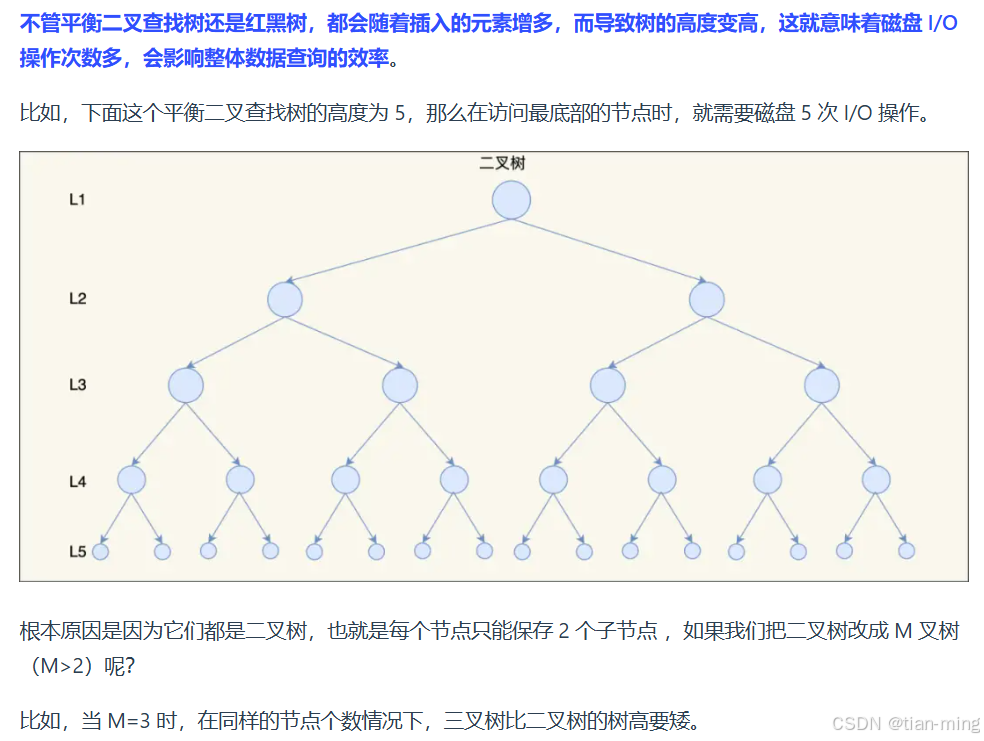


综上所示,平衡二叉查找树(AVL树)、红黑树、B树都不适合作为索引的数据结构。
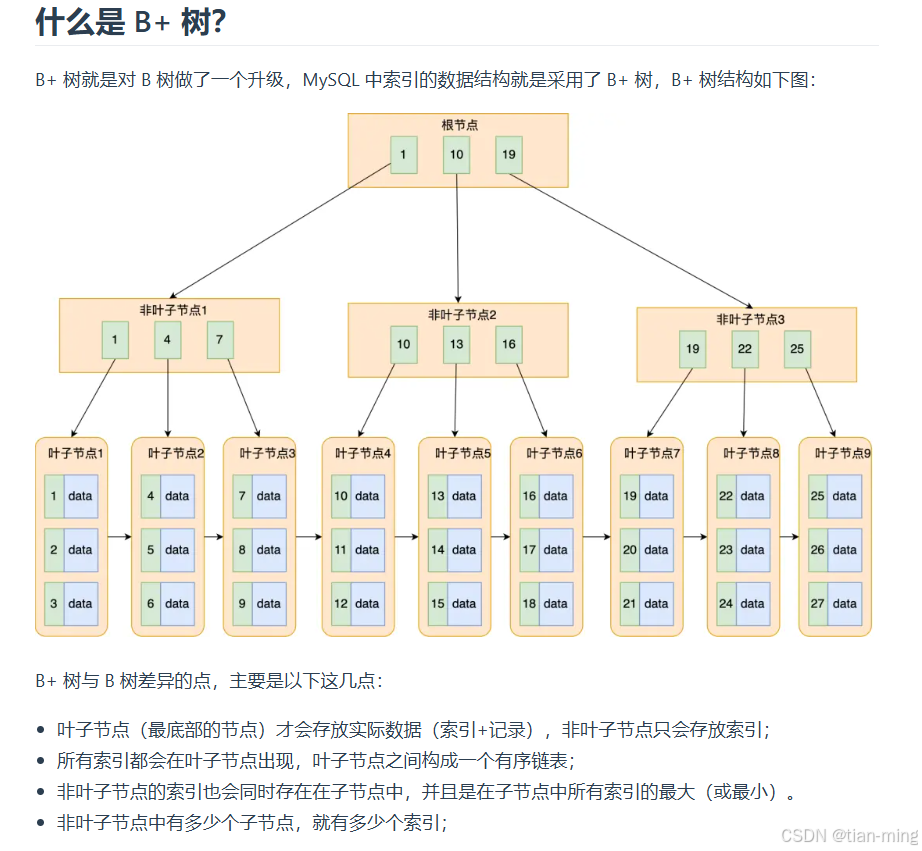
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储既存索引又存记录的 B树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B树更「矮胖」,查询底层节点的磁盘 I/O次数会更少
换一个角度看 B+ 树

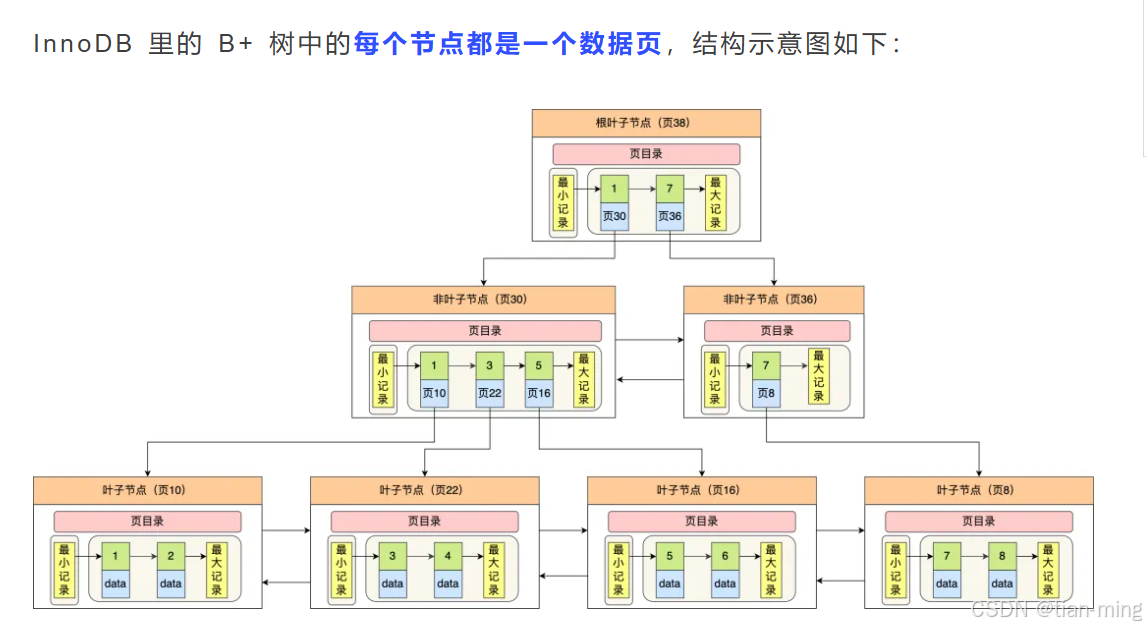
通过上图,我们看出 B+树的特点:
- 只有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他上层节)仅用来存放目录项作为索引
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量
- 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询

