C++编程语言:抽象机制:模板和层级结构(Bjarne Stroustrup)
目录
27.1 引言(Introduction)
27.2 参数化和层级结构(Parameterization and Hierarchy)
27.2.1 生成类型(Generated Types)
27.2.2 模板转换(Template Conversions)
27.3 类模板层级结构(Hierarchies of Class Templates)
27.3.1 模板对比接口(Templates as Interfaces)
27.4 模板参数对比基类(Template Parameters as Base Classes)
27.4.1 组合数据结构(Composing Data Structures)
27.4.2 线性化类层级结构(Linearizing Class Hierarchies)
27.5 建议(Advice)
27.1 引言(Introduction)
模板和派生是从现有类型构建新类型、指定接口的机制,通常用于编写利用各种形式的共性的有用代码:
• 模板类定义一个接口。可以通过该接口访问模板自身的实现及其特化的实现。实现模板的源代码(在模板定义中)对于所有参数类型都是相同的。不同特化的实现可能非常不同,但它们都应该实现为主模板指定的语义。特化可以为主模板提供的功能添加功能。
• 基类定义一个接口。可以通过该接口(使用虚函数)访问类自身的实现及其派生类的实现。不同派生类的实现可能非常不同,但它们都应该实现为基类指定的语义。派生类可以为基类提供的功能添加功能。
从设计角度来看,这两种方法非常接近,值得拥有一个共同的名称。由于两者都允许算法表达一次并应用于多种类型,因此人们将两者都称为多态(源自希腊语“多种形状(many shapes)”)。为了区分它们,虚函数提供的功能称为运行时多态性,而模板提供的功能称为编译时多态或参数多态。
通用方法和面向对象方法的粗略二元性可能会产生误导。面向对象程序员倾向于专注于类(类型)层级结构的设计,其中接口是单个类(第 21 章)。通用程序员倾向于专注于算法的设计,其中模板参数的概念提供了可以容纳多种类型的接口(第 24 章)。程序员的理想状态应该是掌握这两种技术,以至于可以在最合适的情况下使用其中任何一种。在许多情况下,最佳设计包含两者的元素。例如,vector<Shape∗> 是一个编译时多态(通用)容器,它保存来自运行时多态(面向对象)层级结构的元素(§3.2.4)。
一般来说,良好的面向对象编程比良好的通用编程需要更多的远见,因为层级结构中的所有类型都必须显式共享定义为基类的接口。模板将接受符合其概念的任何类型作为参数,即使这些类型之间没有明确声明的共同点。例如,accumulate()(§3.4.2,§24.2,§40.6.1)将接受 int 型 vector和 complex<double> 型 list,即使两种元素类型之间没有声明关系,两种序列类型之间也没有声明关系。
27.2 参数化和层级结构(Parameterization and Hierarchy)
如 §4.4.1 和 §27.2.2 所示,模板和类层级结构的组合是许多实用技术的基础。因此:
• 何时我们选择使用类模板?
• 何时我们依赖类层级结构?
从稍微简化和抽象的角度考虑这些问题:
template<typename X>
class Ct { // 根据参数描述的接口
X mem;
public:
X f();
int g();
void h(X);
};
template<>
class Ct<A> { // 特为 (为 A)
A∗ mem; // 表示可以不同于主模板
public:
A f();
int g();
void h(A);
void k(int); // 添加功能
};
Ct<A> cta; // 特化为 A
Ct<B> ctb; // 特化为 B
鉴于此,我们可以分别使用 Ct<A> 和 Ct<B> 的实现对变量 cta 和 ctb 使用 f(),g() 和 h()。我使用了显式特化(§23.5.3.4)来表明实现可以与主模板提供的内容不同,并且可以添加功能。更简单的情况(没有添加功能)是迄今为止更常见的情况。
使用层级结构的粗略等效方法是:
class X {
// ...
};
class Cx { // 根据作用域中的类型表述的接口
X mem;
public:
virtual X& f();
virtual int g();
virtual void h(X&);
};
Class DA : public Cx { // 派生类
public:
X& f();
int g();
void h(X&);
};
Class DB : public Cx { // 派生类
DB∗p; //可以对类提供的表示进行更多扩展
public:
X& f();
int g();
void h(X&);
void k(int); // 添加功能
};
Cx& cxa {∗new DA}; // cxa 是一个指向 DA 的接口
Cx& cxb {∗new DB}; // cxb 是一个指向 DB 的接口
鉴于此,我们可以分别使用 DA 和 DB 的实现对变量 cxa 和 cxb 使用 f(),g() 和 h()。我在分层版本中使用引用来反映我们必须通过指针或引用来操作派生类对象,以保留运行时多态行为。
无论哪种情况,我们操作的对象都具有一组共同的操作。从这个简化和抽象的角度来看,我们可以观察到:
• 如果生成类或派生类的接口类型需要不同,则模板具有优势。要通过基类访问派生类的不同接口,我们必须使用某种形式的显式转换(§22.2)。
• 如果生成类或派生类的实现仅在一个参数上有所不同,或者仅在少数特殊情况下有所不同,则模板具有优势。不规则的实现可以通过派生类或特化来表达。
• 如果在编译时无法知道所用对象的实际类型,则类层级结构必不可少。
• 如果生成类型或派生类型之间需要层级关系,则层级结构具有优势。基类提供通用接口。模板特化之间的转换必须由程序员明确定义(§27.2.2)。
• 如果不希望明确使用自由存储(§11.2),则模板具有优势。
• 如果运行时效率非常重要,以至于操作的内联必不可少,则应使用模板(因为有效使用层级结构需要使用指针或引用,这会抑制内联)。
保持基类最小化和类型安全可能很困难。用现有类型来表达接口可能也很困难,因为派生类无法改变现有类型。通常,结果是一种妥协,要么过度限制基类接口(例如,我们选择一个具有“丰富接口”的类 X,该接口必须由所有派生类实现,并且“永远”如此),要么限制不足(例如,我们使用 void∗ 或最小 Object∗)。
模板和类层级结构的组合提供了设计选择和灵活性,这超出了它们单独提供的功能。例如,指向基类的指针可用作模板参数,以提供运行时多态性(§3.2.4),模板参数可用于指定基类接口,以提供类型安全性(§26.3.7,§27.3.1)。
27.2.1 生成类型(Generated Types)
类模板可以理解为创建特定类型的规范。换言之,模板实现是一种根据规范在需要时生成类型的机制。因此,类模板有时被称为类型生成器。
就 C++ 语言规则而言,由单个类模板生成的两个类之间没有任何关系。例如:
class Shape {
// ...
};
class Circle : public Shape {
{
// ...
};
鉴于这些声明,人们有时会认为 set<Circle> 和 set<Shape> 之间或至少 set<Circle∗> 和 set<Shape∗> 之间必须存在继承关系。这是一个基于有缺陷的论点的严重逻辑错误:“‘Circle 是 Shape,因此 Circle 的集合也是 Shape 的集合;因此,我应该能够将 Circle 的集合用作 Shape 的集合。’”这个论点的“因此”部分不成立。原因是 Circle 的集合保证集合的成员是 Circle;而 Shape 的集合不提供这种保证。例如:
class Triangle : public Shape {
// ...
};
void f(set<Shape∗>& s)
{
// ...
s.insert(new Triangle{p1,p2,p3});
}
void g(set<Circle∗>& s)
{
f(s); // 错, 类型不匹配: s 是一个 set<Circle*>, 不是一个 set<Shape*>
}
这不会编译,因为没有从 set<Circle∗>& 到 set<Shape∗>& 的内置转换。也不应该有。一个set<Circle∗> 成员的保证是,众 Circle 使我们能够安全有效地将 Circle 特定的操作(例如确定半径)应用于集合的成员。如果我们允许将 set<Circle∗> 视为 set<Shape∗>,我们就无法再维持该保证。例如,f() 将 Triangle∗ 插入其 set<Shape∗> 参数中。如果 set<Shape∗> 可以是 set<Circle∗>,则将违反 set<Circle∗> 仅包含众 Circle∗ 的基本保证。
从逻辑上讲,我们可以将不可变集合 <Circle∗> 视为不可变集合 <Shape∗>,因为当我们无法更改集合时,不会发生将不适当元素插入集合的问题。也就是说,我们可以提供从 const set<const Circle∗> 到 const set<const Shape∗> 的转换。语言默认不这样做,但集合的设计者可以。
数组和基类的组合尤其糟糕,因为内置数组不提供容器提供的类型安全性。例如:
void maul(Shape∗ p, int n) // 当心!
{
for (int i=0; i!=n; ++i)
p[i].draw(); //看起来优雅; 实质不是
}
void user()
{
Circle image[10]; // 由 10 个圆构成的图片
// ...
maul(image,10); // ‘‘maul’’ 10 个圆
// ...
}
我们怎样才能用 image 调用 maul()?首先,image 的类型从 Circle[] 转换(降级)为 Circle∗ 。接下来,Circle∗ 转换为 Shape∗ 。将数组名称隐式转换为指向数组第一个元素的指针是 C 风格编程的基础。同样,将指向派生类的指针隐式转换为指向其基类的指针是面向对象编程的基础。结合起来,它们提供了灾难的机会。
在上面的例子中,假设 Shape 是一个大小为 4 的抽象类,而 Circle 则添加了一个中心和一个半径。然后 sizeof(Circle) > sizeof(Shape),当我们查看图像的布局时,我们会发现类似以下内容:

当 maul() 尝试在 p[1] 上调用虚函数时,在预期的位置没有虚函数指针,因此调用可能会立即失败。
请注意,不需要显式转换即可获遭遇此灾难:
• 优先使用容器而不是内置数组。
• 高度怀疑诸如 void f(T∗ p, int count) 之类的接口;当 T 可以是基类并且 count 是元素计数时,麻烦就来了。
• 考虑将 .(点)应用于应该是运行时多态的东西时,除非它显然应用于引用,否则要怀疑它。
27.2.2 模板转换(Template Conversions)
从同一模板生成的类之间不能存在任何默认关系(§27.2.1)。但是,对于某些模板,我们想表达这种关系。例如,当我们定义指针模板时,我们希望反映指向的对象之间的继承关系。成员模板(§23.4.6)允许我们在需要的地方指定许多这样的关系。考虑:
template<typename T>
class Ptr { // pointer to T
T∗ p;
public:
Ptr(T∗);
Ptr(const Ptr&); // 复制构造函数
template<typename T2>
explicit operator Ptr<T2>(); // 将Ptr<T> 转换为 Ptr<T2>
// ...
};
我们希望定义转换运算符,为这些用户定义的 Ptr 提供我们习惯的内置指针的继承关系。例如:
void f(Ptr<Circle> pc)
{
Ptr<Shape> ps {pc}; // 应当有效
Ptr<Circle> pc2 {ps}; // 应当会出现错误
}
我们希望当且仅当 Shape 确实是 Circle 的直接或间接公共基类时才允许第一次初始化。一般来说,我们需要定义转换运算符,以便当且仅当 T∗ 可以分配给 T2∗ 时,才接受 Ptr<T> 到 Ptr<T2> 的转换。可以这样做:
template<typename T>
template<typename T2>
Ptr<T>::operator Ptr<T2>()
{
return Ptr<T2>{p};
}
当且仅当 p(T∗)可以作为 Ptr<T2>(T2∗) 构造函数的参数时,返回语句才会编译。因此,如果 T∗ 可以隐式转换为 T2∗,则 Ptr<T> 到 Ptr<T2> 的转换将起作用。例如,我们现在可以写:
void f(Ptr<Circle> pc)
{
Ptr<Shape> ps {pc}; // 正确: 可以将 Circle* 转换为 Shape*
Ptr<Circle> pc2 {ps}; // 错误:不能将 Shape* 转换至 Circle*
}
请务必谨慎定义具有逻辑意义的转换。如有疑问,请使用命名转换函数,而不是转换运算符。命名转换函数可减少出现歧义的机会。
模板和其模板成员之一的模板参数列表不能组合。例如:
template<typename T, typename T2> // error
Ptr<T>::operator Ptr<T2>()
{
return Ptr<T2>(p);
}
该问题的另一种解决方案是使用类型特征和 enable_if() (§28.4)。
27.3 类模板层级结构(Hierarchies of Class Templates)
使用面向对象技术,基类通常用于为一组派生类提供通用接口。可以使用模板来参数化这样的接口,并且当这样做时,很容易用相同的模板参数来参数化派生类的整个层级结构。例如,我们可以用用于提供目标输出“设备”抽象的类型来参数化经典形状示例(§3.2.4):
template<typename Color_scheme , typename Canvas> // 值得怀疑的例子
class Shape {
// ...
};
template<typename Color_scheme , typename Canvas>
class Circle : public Shape {
// ...
};
template<typename Color_scheme , typename Canvas>
class Triangle : public Shape {
// ...
};
void user()
{
auto p = new Triangle<RGB,Bitmapped>{{0,0},{0,60},{30,sqr t(60∗60−30∗30)}};
// ...
}
习惯于面向对象编程的程序员在看到类似 vector<T> 的东西后,通常会首先想到类似的想法。但是,在混合使用面向对象和泛型技术时,建议谨慎行事。
如上所述,这种参数化的形状层级结构对于实际使用来说过于冗长。可以使用默认模板参数(§25.2.5)解决这个问题。但是,冗长并不是主要问题。如果程序中只使用 Color_scheme 和 Canvas 的一个组合,则生成的代码量几乎与未参数化的等效代码量完全相同。之所以说“几乎”,是因为编译器将抑制类模板中未使用的非虚拟成员函数定义的代码生成。但是,如果程序中使用了 N 个 Color_scheme 和 Canvas 组合,则每个虚拟函数的代码将被复制 N 次。由于图形层级结构可能有许多派生类、许多成员函数和许多复杂函数,因此结果可能是代码膨胀。特别是,编译器无法知道是否使用了虚函数,因此它必须为所有此类函数以及此类函数调用的所有函数生成代码。使用许多虚成员函数来参数化庞大的类层级结构通常是一个糟糕的想法。
对于此形状示例,Color_scheme 和 Canvas 参数不太可能对接口产生太大影响:大多数成员函数不会将它们作为其函数类型的一部分。这些参数是“逃逸”到接口中的“实现细节”——可能会对性能产生严重影响。实际上,并不是整个层级结构都需要这些参数;而是一些配置函数和(最有可能)一些较低级别的绘制/渲染函数。“过度参数化”(§23.4.6.3)通常不是一个好主意:尽量避免仅影响少数成员的参数。如果只有少数成员函数受参数影响,请尝试使用该参数制作这些函数模板。例如:
class Shape {
template<typename Color_scheme , typename Canvas>
void configure(const Color_scheme&, const Canvas&);
// ...
};
如何在不同的类和不同的对象之间共享配置信息是一个单独的问题。显然,我们不能简单地将 Color_scheme 和 Canvas 存储在 Shape 中,而不使用 Color_scheme 和 Canvas 参数化 Shape 本身。一种解决方案是让 configure() 将 Color_scheme 和 Canvas 中的信息“翻译”为一组标准的配置参数(例如,一组整数)。另一种解决方案是为 Shape 提供一个 Configuration∗ 成员,其中 Configuration 是一个基类,为配置信息提供通用接口。
27.3.1 模板对比接口(Templates as Interfaces)
模板类可用于为通用实现提供灵活且类型安全的接口。§25.3 中的向量就是一个很好的例子:
template<typename T>
class Vector<T∗>
: private Vector<void∗>
{
// ...
};
一般来说,这种技术可用于提供类型安全的接口和将强制转换局部化到实现,而不是强迫用户编写它们。
27.4 模板参数对比基类(Template Parameters as Base Classes)
在使用类层级结构的经典面向对象编程中,我们将不同类可能不同的信息放置在派生类中,并通过基类中的虚函数访问这些信息(§3.2.4,§21.2.1)。这样,我们就可以编写通用代码,而不必担心实现中的变化。但是,这种技术不允许我们改变接口中使用的类型(§27.2)。此外,与内联函数的简单操作相比,这些虚函数调用可能很昂贵。为了弥补这一点,我们可以将专门的信息和操作作为模板参数传递给基类。事实上,模板参数可以用作基类。
以下两个小节要解决的一般问题是“我们如何将单独指定的信息组合成一个具有明确指定接口的单一紧凑对象?”这是一个基本问题,其解决方案具有普遍的重要意义。
27.4.1 组合数据结构(Composing Data Structures)
考虑编写一个平衡二叉树库。由于我们提供了一个供许多不同用户使用的库,因此我们无法将用户(应用程序)的数据类型构建到我们的树节点中。我们有很多替代方案:
• 我们可以将用户的数据放在派生类中,并使用虚函数访问它。但是虚函数调用(或等效地,运行时解析和检查的解决方案)相对昂贵,并且我们对用户数据的接口不是以用户的类型来表示的,因此我们仍然需要使用强制类型转换来访问它。
• 我们可以在我们的节点中放置一个 void∗,并让用户使用它来引用分配在我们节点之外的数据。但这会使分配的数量增加一倍,增加许多(可能昂贵的)指针取消引用,并增加每个节点中指针的空间开销。我们还需要使用强制类型转换来使用其正确的类型访问我们的用户数据。该强制类型转换无法进行类型检查。
• 我们可以将 Data∗ 放入我们的节点中,其中 Data 是我们数据结构的“通用基类”。这将解决类型检查问题,但它结合了前两种方法的成本和不便。
还有更多选择,但请考虑:
template<typename N>
struct Node_base { // 不知道关于 Val (用户数据)
N∗ left_child;
N∗ right_child;
Node_base();
void add_left(N∗ p)
{
if (left_child==nullptr)
left_child = p;
else
// ...
}
// ...
};
template<typename Val>
struct Node : Node_base<Node<Val>> { // 使用派生类作为其自身基类的一部分
Val v;
Node(Val vv);
// ...
};
这里,我们将派生类 Node<Val> 作为模板参数传递给它自己的基类 (Node_base)。这样 Node_base 就可以在其接口中使用 Node<Val>,甚至无需知道其真实名称!
请注意,Node 的布局非常紧凑。例如,Node<double> 看起来大致相当于:
struct Node_base_double {
double val;
Node_base_double∗ left_child;
Node_base_double∗ right_child;
};
遗憾的是,对于这种设计,用户必须了解 Node_base 的操作和生成的树的结构。例如:
using My_node = Node<double>;
void user(const vector<double>& v)
{
My_node root;
int i = 0;
for (auto x : v) {
auto p = new My_node{x};
if (i++%2) // 选择何处插入
root.add_left(p);
else
root.add_right(p);
}
}
然而,对于用户来说,保持树的结构合理并不容易。通常,我们希望通过实现树平衡算法让树来处理这个问题。然而,为了平衡树以便您可以有效地搜索它,平衡器(balancer)需要知道用户的值。
我们如何将平衡器添加到我们的设计中?我们可以将平衡策略硬连线到 Node_base 中,并让 Node_base “查看”用户数据。例如,平衡树实现(例如标准库映射)(默认情况下)要求值类型提供小于操作。这样,Node_base 操作就可以简单地使用 < :
template<typename N>
struct Node_base {
static_assert(Totally_ordered<N>(), "Node_base: N must have a <");
N∗ left_child;
N∗ right_child;
Balancing_info bal;
Node_base();
void insert(N& n)
{
if (n<left_child)
// ... do something ...
else
// ... do something else ...
}
// ...
};
这很有效。事实上,我们在 Node_base 中构建的节点信息越多,实现就越简单。特别是,我们可以用值类型而不是节点类型来参数化 Node_base(就像对 std::map 所做的那样),这样我们就可以将树放在一个紧凑的包中。然而,这样做并不能解决我们在这里试图解决的基本问题:如何组合来自多个单独指定的来源的信息。把所有东西都写在一个地方可以避免这个问题。
因此,让我们假设用户想要操纵节点(例如,将节点从一棵树移动到另一棵树),这样我们就不能简单地将用户数据存储到匿名节点中。让我们进一步假设我们希望能够使用各种平衡算法,因此我们需要将平衡器作为一个参数。这些假设迫使我们面对根本问题。最简单的解决方案是让 Node 将值类型与平衡器类型结合起来。但是,Node 不需要使用平衡器,因此它只是将其传递给 Node_base:
template<typename Val, typename Balance>
struct Search_node : public Node_base<Search_node<Val, Balance>, Balance>
{
Val val; // user data
search_node(Val v): val(v) {}
};
这里两次提到 Balance,因为它是节点类型的一部分,并且 Node_base 需要创建一个 Balance 类型的对象:
template<typename N, typename Balance>
struct Node_base : Balance {
N∗ left_child;
N∗ right_child;
Node_base();
void insert(N& n)
{
if (this−>compare(n,left_child)) // 使用来自 Balance 的 compare()
// ... do something ...
else
// ... do something else ...
}
// ...
};
我本可以使用 Balance 来定义成员,而不是将其用作基础。但是,一些重要的平衡器不需要每个节点的数据,因此通过将 Balance 作为基础,我可以从空基类优化中受益。该语言保证,如果基类没有非静态数据成员,则不会在派生类的对象中为其分配内存(§iso.1.8)。此外,这种设计与真正的二叉树框架在风格上略有不同 [Austern,2003]。我们可以像这样使用这些类:
struct Red_black_balance {
// 数据和操作需实现为红黑树
};
template<typename T>
using Rbnode = Search_node<T,Red_black_balance>; // 红黑树别名
Rbnode<double> my_root; // double 红黑树
using My_node = Rb_node<double>;
void user(const vector<double>& v)
{
for (auto x : v)
root.insert(∗new My_node{x});
}
节点的布局紧凑,我们可以轻松内联所有性能关键函数。我们通过略微复杂的定义集实现了类型安全性和易于组合。与将 void∗ 引入数据结构或函数接口的每种方法相比,这种精心设计带来了性能优势。这种 void∗ 的使用禁用了有价值的基于类型的优化技术。在平衡二叉树实现的关键部分选择低级(C 风格)编程技术意味着巨大的运行时成本。
我们将平衡器作为单独的模板参数传递:
template<typename N, typename Balance>
struct Node_base : Balance {
// ...
};
template<typename Val, typename Balance>
struct Search_node
: public Node_base<Search_node<Val, Balance>, Balance>
{
// ...
};
有些人认为这很清晰、明确且通用;其他人则认为这冗长且令人困惑。另一种方法是将平衡器设为关联类型(Search_node 的成员类型)形式的隐式参数:
template<typename N>
struct Node_base : N::balance_type { // use N’s balance_type
// ...
};
template<typename Val, typename Balance>
struct Search_node
: public Node_base<Search_node<Val,Balance>>
{
using balance_type = Balance;
// ...
};
标准库中大量使用此技术来最小化显式模板参数。
从基类派生的技术非常古老。它在 ARM (1989) 中被提及,有时被称为 Barton-Nackman 技巧,因为它在数学软件中早期使用[Barton,1994]。Jim Coplien 将其称为奇怪的循环模板模式 (CRTP) [Coplien,1995]。
27.4.2 线性化类层级结构(Linearizing Class Hierarchies)
§27.4.1 中的 Search_node 示例使用其模板来压缩其表示并避免使用 void∗。这些技术是通用的并且非常实用。特别是,许多处理树的程序都依赖它来实现类型安全和性能。例如,“内部程序表示”(IPR)[DosReis,2011] 是 C++ 代码作为类型抽象语法树的通用和系统表示。它广泛使用模板参数作为基类,既作为实现辅助(实现继承),也以经典的面向对象方式提供抽象接口(接口继承)。该设计解决了一组困难的标准,包括节点的紧凑性(可能有数百万个节点)、优化的内存管理、访问速度(不要引入不必要的间接或节点)、类型安全、多态接口和通用性。
用户看到的是抽象类的层级结构,它们提供了完美的封装和干净的功能接口,代表了程序的语义。例如,变量是声明,是语句,是表达式,是节点:
Var −> Decl −> Stmt −> Expr −> Node
显然,在 IPR 的设计中已经做了一些概括,因为在 ISO C++ 中语句不能用作表达式。
此外,还有一个并行的具体类层结结构,为接口层级结构中的类提供紧致、高效的实现:
impl::Var −> impl::Decl −> impl::Stmt −> impl::Expr −> impl::Node
总共有大约 80 个叶类(例如 Var、If_stmt 和 Multiply)和大约 20 个泛化(例如 Decl、Unary 和 impl::Stmt)。
设计的第一次尝试是经典的多重继承“菱形”层级结构(使用实线箭头表示接口继承,使用虚线箭头表示实现继承):
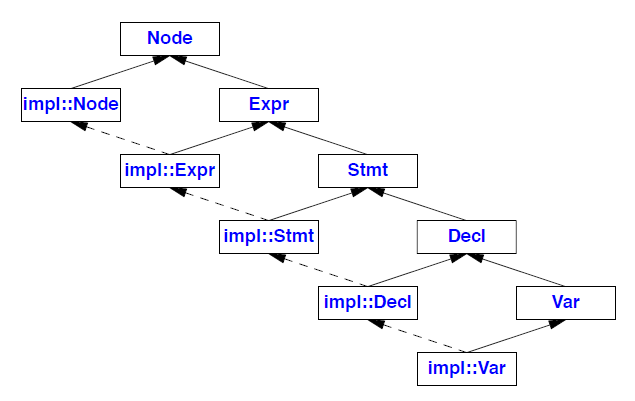
这种方法虽然有效,但会导致过多的内存开销:由于需要数据来导航虚基类,因此节点太大。此外,由于需要多次间接访问每个对象中的许多虚基类,程序运行速度严重减慢(§21.3.5)。
解决方案是线性化双重层级结构,以便不使用虚基类:

对于完整的类集,派生链变为:
impl::Var −>
impl::Decl<impl::Var> −>
impl::Stmt<impl::Var> −>
impl::Expr<impl::Var> −>
impl::Node<impl::Var> −>
ipr::Var −>
ipr::Decl −>
ipr::Stmt −>
ipr::Expr −>
ipr::Node
它表示为一个紧致的对象,除了单个 vptr(§3.2.3,§20.3.2)之外没有内部“管理数据”。
我将展示如何做到这一点。首先描述在命名空间 ipr 中定义的接口层次结构。从底部开始,Node 保存用于优化遍历和 Node 类型识别(code_category)以及简化 IPR 图在文件中存储(node_id)的数据。这些是相当典型的“实现细节”,对用户隐藏。用户会知道的是,IPR 图中的每个节点都有一个唯一的 Node 类型基类,并且可以使用访问者模式 [Gamma,1994](§22.3)来实现操作:
struct ipr::Node {
const int node_id;
const Category_code category;
virtual void accept(Visitor&) const = 0; // 访问者类的钩子
protected:
Node(Category_code);
};
Node 仅用作基类,因此其构造函数受到保护。它还有一个纯虚函数,因此除了作为基类之外,无法实例化。
表达式(Expr)是具有以下类型的节点:
struct ipr::Expr : Node {
virtual const Type& type() const = 0;
protected:
Expr(Category_code c) : Node(c) { }
};
显然,这是对 C++ 的相当概括,因为它意味着即使语句和类型也有类型:IPR 的目标是表示所有 C++,而无需实现 C++ 的所有不规则性和局限性。
语句 (Stmt) 是一个具有源文件位置并可以用各种信息注释的 Expr:
struct ipr::Stmt : Expr {
virtual const Unit_location& unit_location() const = 0; // 文件中的行
virtual const Source_location& source_location() const = 0; // file
virtual const Sequence<Annotation>& annotation() const = 0;
protected:
Stmt(Category_code c) : Expr(c) { }
};
声明(Decl)是引入名称的 Stmt:
struct ipr::Decl : Stmt {
enum Specifier { /* storage class, vir tual, access control, etc. */ };
virtual Specifier specifiers() const = 0;
virtual const Linkage& lang_linkage() const = 0;
virtual const Name& name() const = 0;
virtual const Region& home_region() const = 0;
virtual const Region& lexical_region() const = 0;
virtual bool has_initializer() const = 0;
virtual const Expr& initializer() const = 0;
// ...
protected:
Decl(Category_code c) : Stmt(c) { }
};
正如您所料,Decl 是表示 C++ 代码的核心概念之一。在这里您可以找到范围信息、存储类、访问说明符、初始化器等。
最后,我们可以定义一个类来表示变量(Var),作为接口层级结构的叶类(最后的派生类):
struct ipr::Var : Category<var_cat, Decl> { };
基本上,Category 是一种符号辅助工具,其作用是从 Decl 派生 Var 并提供用于优化 Node 类型识别的 Category_code:
template<Category_code Cat, typename T = Expr>
struct Category : T {
protected:
Category() : T(Cat) { }
};
每个数据成员都是一个变量。其中包括全局变量、命名空间变量、局部变量和类静态变量及常量。
与编译器中的表示相比,此接口非常小。除了 Node 中用于优化的一些数据外,这只是一组具有纯虚函数的类。请注意,它是一个没有虚基类的单一层次结构。这是一种简单的面向对象设计。但是,要简单、高效且可维护地实现这一点并不容易,而且 IPR 的解决方案肯定不是经验丰富的面向对象设计师首先想到的。
对于每个 IPR 接口类(在 ipr 中),都有一个对应的实现类(在 impl 中)。例如:
template<typename T>
struct impl::Node : T {
using Interface = T; // 使用户可获得模板参数
void accept(ipr::Visitor& v) const override { v.visit(∗this); }
};
“技巧”在于建立 ipr 节点和 impl 节点之间的对应关系。具体来说,impl 节点必须提供必要的数据成员并覆盖 ipr 节点中的抽象虚函数。对于 impl::Node,我们可以看到,如果 T 是 ipr::Node 或任何从 ipr::Node 派生的类,则 accept() 函数被正确覆盖。
现在,我们可以继续为其余的 ipr 接口类提供实现类:
template<typename Interface>
struct impl::Expr : impl::Node<Interface> {
const ipr::Type∗ constraint; // constraint 是表达式的类型
Expr() : constraint(0) { }
const ipr::Type& type() const override { return ∗util::check(constraint); }
};
如果接口参数是 ipr::Expr 或任何从 ipr::Expr 派生的类,则 impl::Expr 是 ipr::Expr 的实现。我们可以确定这一点。由于 ipr::Expr 是从 ipr::Node 派生的,这意味着 impl::Node 获得了它所需的 ipr::Node 基类。
换句话说,我们成功地为两个(不同的)接口类提供了实现。我们可以按以下方式进行:
template<typename S>
struct impl::Stmt : S {
ipr::Unit_location unit_locus; // 编译单元中的逻辑位置
ipr::Source_location src_locus; // 源文件, 行, 和列
ref_sequence<ipr::Annotation> notes;
const ipr::Unit_location& unit_location() const override { return unit_locus; }
const ipr::Source_location& source_location() const override { return src_locus; }
const ipr::Sequence<ipr::Annotation>& annotation() const override { return notes; }
};
也就是说,impl:Stmt 提供了实现 ipr::Stmt 接口所需的三个数据项,并覆盖了 ipr::Stmt 的三个虚函数来实现这一点。
基本上,所有 impl 类都遵循 Stmt 的模式:
template<typename D>
struct impl::Decl : Stmt<Node<D> > {
basic_decl_data<D> decl_data;
ipr::Named_map∗ pat;
val_sequence<ipr::Substitution> args;
Decl() : decl_data(0), pat(0) { }
const ipr::Sequence<ipr::Substitution>& substitutions() const { return args; }
const ipr::Named_map& generating_map() const override { return ∗util::check(pat); }
const ipr::Linkage& lang_linkage() const override;
const ipr::Region& home_region() const override;
};
最后,我们可以定义叶类 impl::Var:
struct Var : impl::Decl<ipr::Var> {
const ipr::Expr∗ init;
const ipr::Region∗ lexreg;
Var();
bool has_initializer() const override;
const ipr::Expr& initializer() const override;
const ipr::Region& lexical_region() const override;
};
请注意,Var 不是模板;它是我们应用程序中的用户级抽象。Var 的实现是泛型编程的一个示例,但它的使用是经典的面向对象编程。
继承和参数化的组合非常强大。这种表达能力可能会让初学者感到困惑,有时甚至会让经验丰富的程序员在面对新的应用领域时感到困惑。然而,这种组合的好处是显而易见的:类型安全、性能和最小的源代码大小。类层级结构和虚函数提供的可扩展性不会受到影响。
27.5 建议(Advice)
[1] 当必须用代码表达一个总体思路时,请考虑将其表示为模板还是类层级结构;§27.1。
[2] 模板通常为各种参数提供通用代码;§27.1。
[3] 抽象类可以完全向用户隐藏实现细节;§27.1。
[4] 不规则的实现通常最好表示为派生类;§27.2。
[5] 如果不希望明确使用自由存储,则模板比类层级结构更有优势;§27.2。
[6] 在内联很重要的情况下,模板比抽象类更有优势;§27.2。
[7] 模板接口很容易用模板参数类型来表达;§27.2。
[8] 如果需要运行时解析,则类层级结构是必需的;§27.2。
[9] 模板和类级次结构的组合通常比单独使用任何一种都要好;§27.2。
[10] 将模板视为类型生成器(和函数生成器);§27.2.1。
[11] 从同一模板生成的两个类之间没有默认关系;§27.2.1。
[12] 不要混合类层级结构和数组;§27.2.1。
[13] 不要天真地模板化大型类层级结构;§27.3。
[14] 模板可用于为单个(弱类型)实现提供类型安全的接口;§27.3.1。
[15] 模板可用于组成类型安全和紧致的数据结构;§27.4.1。
[16] 模板可用于线性化类层级结构(最小化空间和访问时间);§27.4.2.
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup