领域驱动设计(DDD)【27】之CQRS四个层面的策略
文章目录
- 一 案例情景引入
- 二 代码结构分离
- 三 数据库结构分离
- 四 应用服务分离
- 五 数据库实例分离
- 六 各种策略的组合
- CQRS(Command Query Responsibility Segregation,命令查询职责分离)是一种架构模式,它的核心思想是将系统的**写操作(命令)和读操作(查询)**分离,使用不同的模型来处理。
为了实现命令而进行的查询是不会绕过领域模型的。比如说,修改员工信息,相应的应用服务可以经过后面这四个步骤:
- 第一步,把这个员工聚合从数据库里查询出来。(为了实现命令而进行的查询)
- 第二步,进行校验,看看是否符合修改的条件。
- 第三步,在内存中对员工聚合进行修改。
- 第四步,把修改的员工聚合存回数据库。
第一步中的查询一般仍然要在命令处理器内部完成,而不是在查询处理器中完成。因为这种查询的目的就是查出领域对象,然后进一步执行领域逻辑。而查询模型中的表结构可能已经按照查询的要求进行了反规范化,返回结果也是 DTO 而不是领域对象,这时候,转换回领域模型反而会更麻烦。
- 从另一个角度来理解。CQRS 中的 Q(查询),指的其实是来自客户端的意图。也就是说,客户端的目的就是查询,才算是 CQRS 里的 Q,如果客户端的目的是增、删、改,在这个过程中发生的查询,一般不算是 CQRS 里的 Q。
一 案例情景引入
- 假设项目需求:给定一个工时项,要求查询出这个工时项下的所有工时记录,并显示在屏幕上。要求每条返回记录的字段包括“员工号”“员工姓名”“日期”“工时”和“备注”,并根据员工号和日期升序排序。
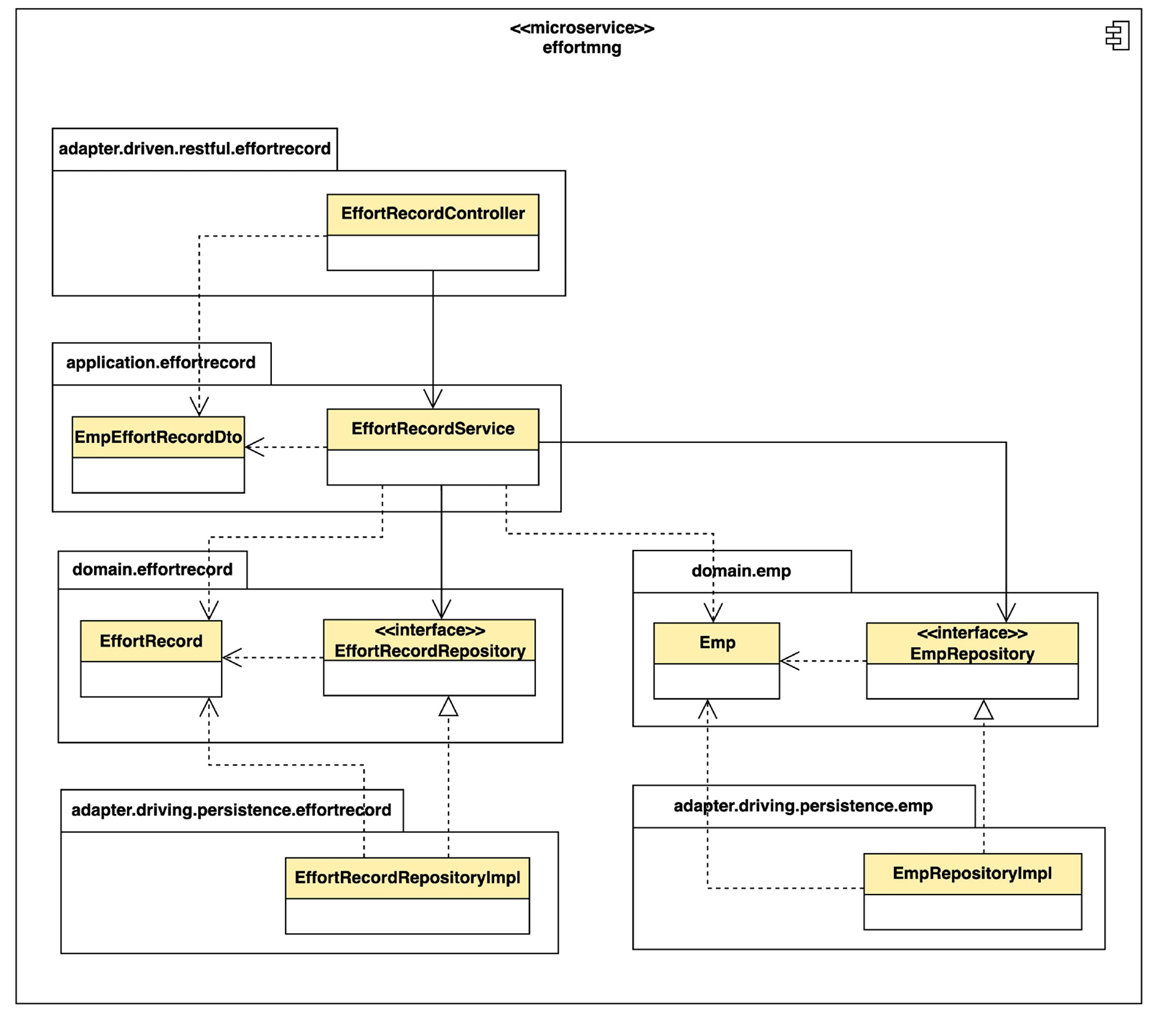
- EffortRecordService(工时记录服务)中的方法会接收一个 EffortItemID(工时项 ID),最后返回一个含有所需数据的列表。每一条数据记录封装在名为 EmpEffortRecordDto 的 DTO 里。具体分为三步:
- 第一步,EffortRecordService(工时记录服务)会调用 EffortRecordRepository,根据工时项ID取得一堆 EffortRecord (工时记录)实体。
- 第二步,再根据每个工时记录实体中的员工ID,调用 EmpRepository ,为每个工时记录取得相应的员工实体。这里要注意避免对同一个员工实体重复查询数据库。
- 第三步,把所有工时记录和对应的员工实体信息拼成相应的 EmpEffortRecordDto ,排序后组装成列表返回。
- 这样做带来的问题:程序编写复杂和程序性能问题。
- 要回答这个问题,首先要考虑一下为什么之前的逻辑要经过领域模型。其中主要原因是,如果绕过领域模型,领域逻辑和数据就可能分散,无法保证数据的完整和一致性,程序也将很难理解和维护。对于增、删、改这样的逻辑,符合原来的设计。但是,查询的逻辑并不会改变数据,所以并不会造成数据的不完整和不一致。
- 因此,Greg Young把增、删、改功能称为 Command(命令),把查询称为 Query,这两种功能的职责不同,应该采用不同的方式来处理,因此叫做“命令查询职责分离”(Command Query Responsibility Segregation ),简称 CQRS。我们可以先粗放一点来理解CQRS,一共是两条规则:
- 命令要走领域模型。
- 查询不走领域模型,直接用 SQL 和 DTO。
接下来,我们从代码结构、数据库结构、应用服务、数据库实例四个层面来看待CQRS。
二 代码结构分离
- 第一个层面是代码结构的分离。代码结构的分离,是最简单的 CQRS,多数采用了DDD 分层架构的程序都可以尝试使用。
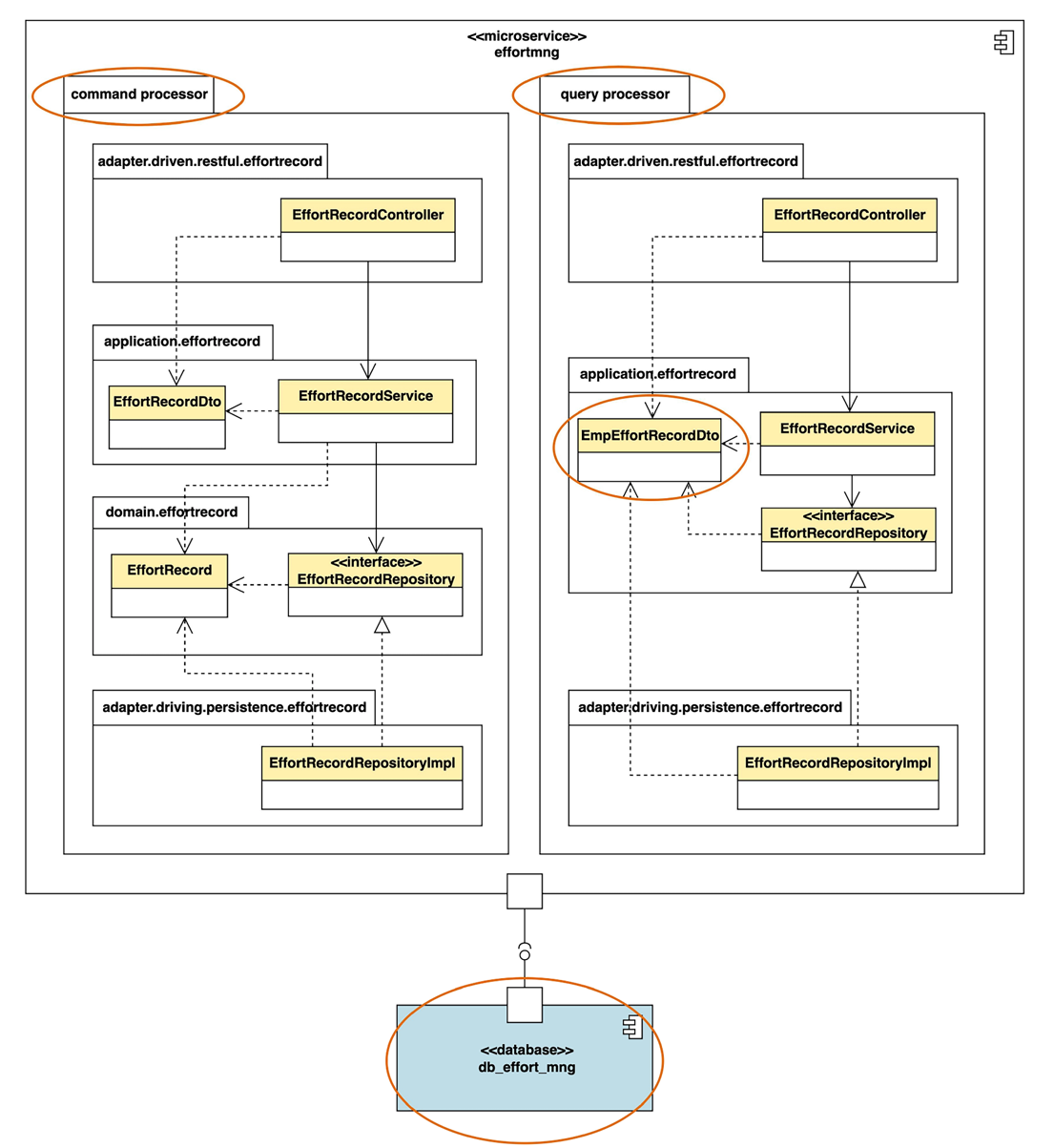
- 代码分成两个包包括command processor(命令处理器)和 query processor(查询处理器)。命令处理器采用的就是之前基于领域模型的分层架构。查询处理器,里面没有领域层,也没有领域对象,直接用 EmpEffortRecordDto 来表示数据。应用服务调用仓库,仓库里用 SQL 语句进行连表查询,得到的数据直接填到 DTO 里。应用服务可能还要对DTO再做少许加工直接返回。
- 由于 EmpEffortRecordDto 表示的是要查询的数据的结构,所以,也有人把由这些对象组成的模型称为“查询模型”(query model)或者“读模型”(read model)。
三 数据库结构分离
- 前面的程序里SQL 用连表查询,可能造成性能问题。本质原因是,程序里的查询模型和物理数据模型(数据库里表结构)不一致。数据库表结构是根据领域模型,而不是查询模型设计的。从物理数据模型到程序中的查询模型的转换,是通过 SQL完成的。而这种转换需要表连接,可能造成性能问题。
- 一种解决思路是为查询单独创建一套表,采用“反规范化设计”(引入冗余字段),使表结构和查询模型吻合,从而避免或减少表连接。
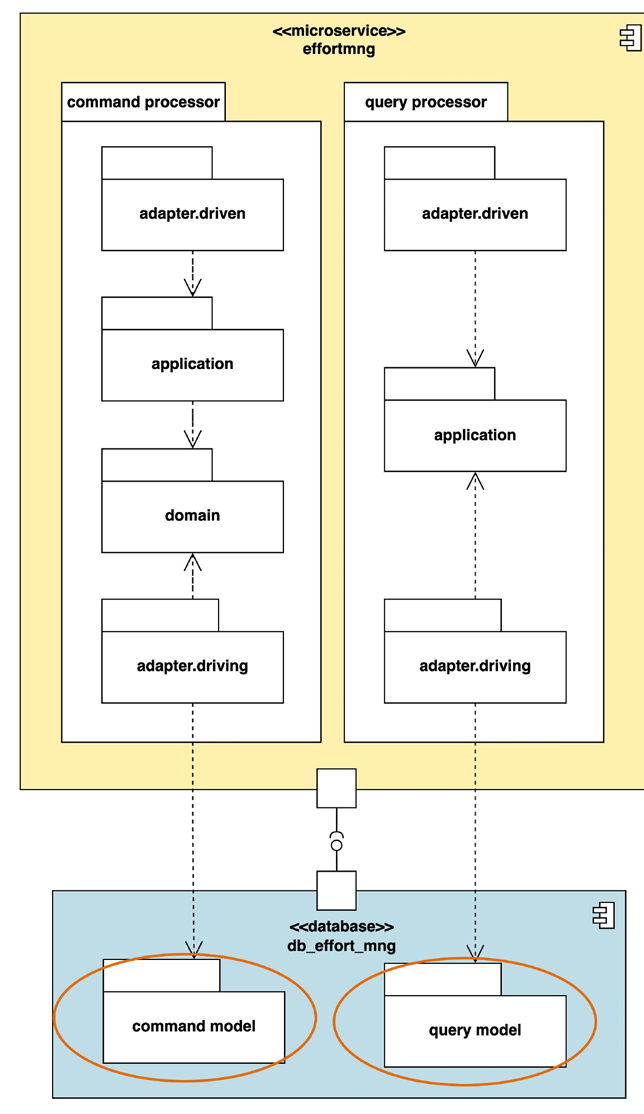
- 数据库表分成两套——命令模型(command model)和查询模型(query model),分别由命令处理器和查询处理器访问。其中命令模型中的表是根据领域模型设计,查询模型部分的表就是根据查询需求进行了反规范化设计。
- 命令处理器对命令模型里的表进行操作后,要把数据同步给查询模型,如,命令模型中的仓库同时写两边的数据表,或者使用触发器,还可以用同步或异步的事件驱动机制。
四 应用服务分离
- 在之前的两种策略中,程序仍然在同一个微服务,数据库也只有一个实例。但是,当遇到更高
的并发性能需求时,就要需要分布式程序和数据库,可以考虑应用服务分离、数据库实例分离策略解决问题。
- 项目需求在采用应用服务分离后的架构图:
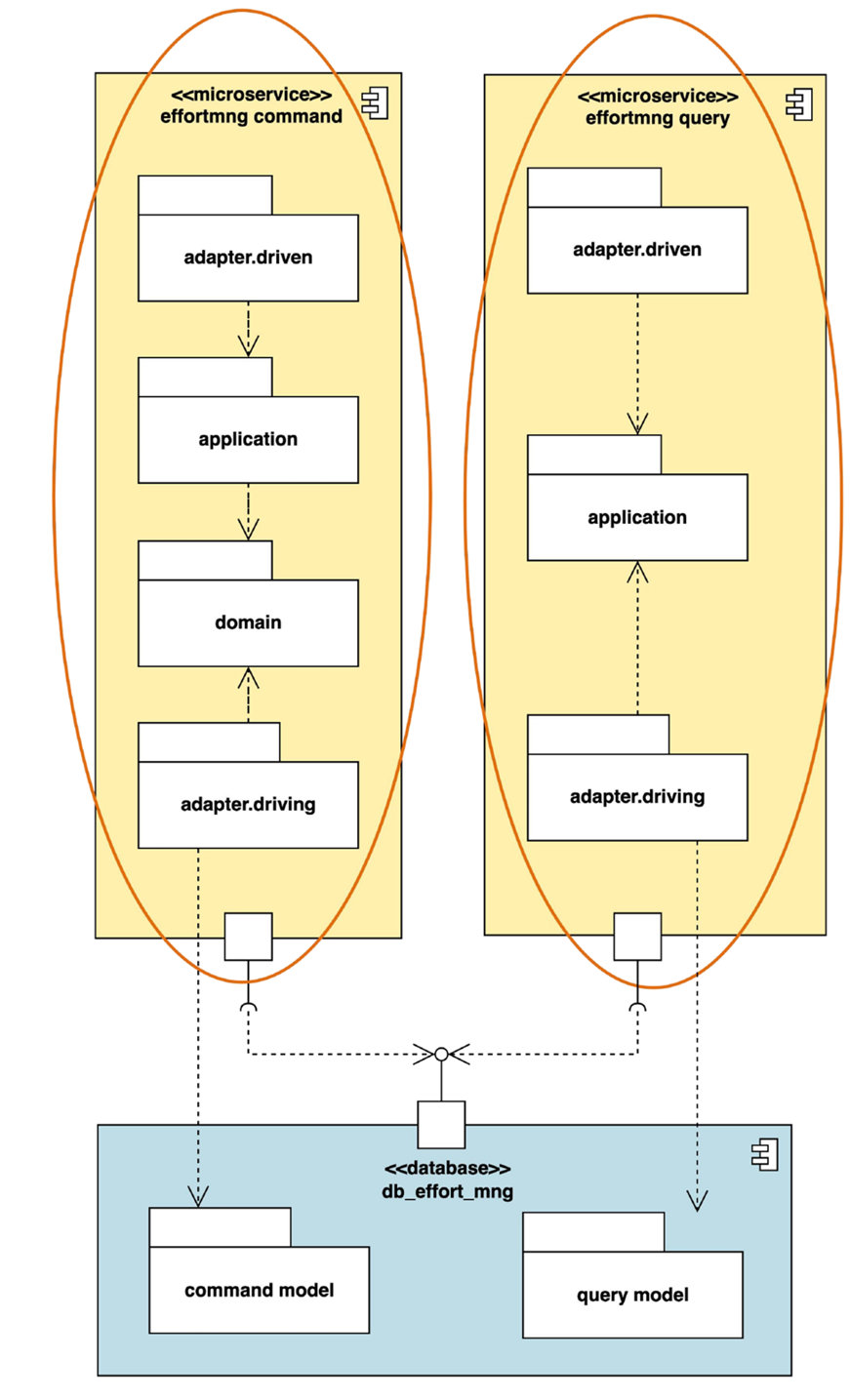
- 命令处理器和查询处理器原来是在同一个微服务中的,现在拆成到两个微服务中。两个服务的可伸缩性可以不同,如负责处理命令的微服务可以部署在 5 个容器里,而负责处理查询的微服务部署在 10 个容器里。
- 应用服务分离策略的好处是容易横向扩展,代价则是微服务的数量增加了,相应的运维和治理成本也就随之增加。
五 数据库实例分离
- 在上面的例子里微服务分开了,但是数据库实例并没有分开。虽然通过微服务的横向扩展,可以解决由于应用程序造成的性能瓶颈,但是如果性能瓶颈是由数据库引发的,那么拆分微服务的策略就无法解决问题。这时候,可以考虑“数据库实例分离”策略。
- 数据库实例分离的架构图:
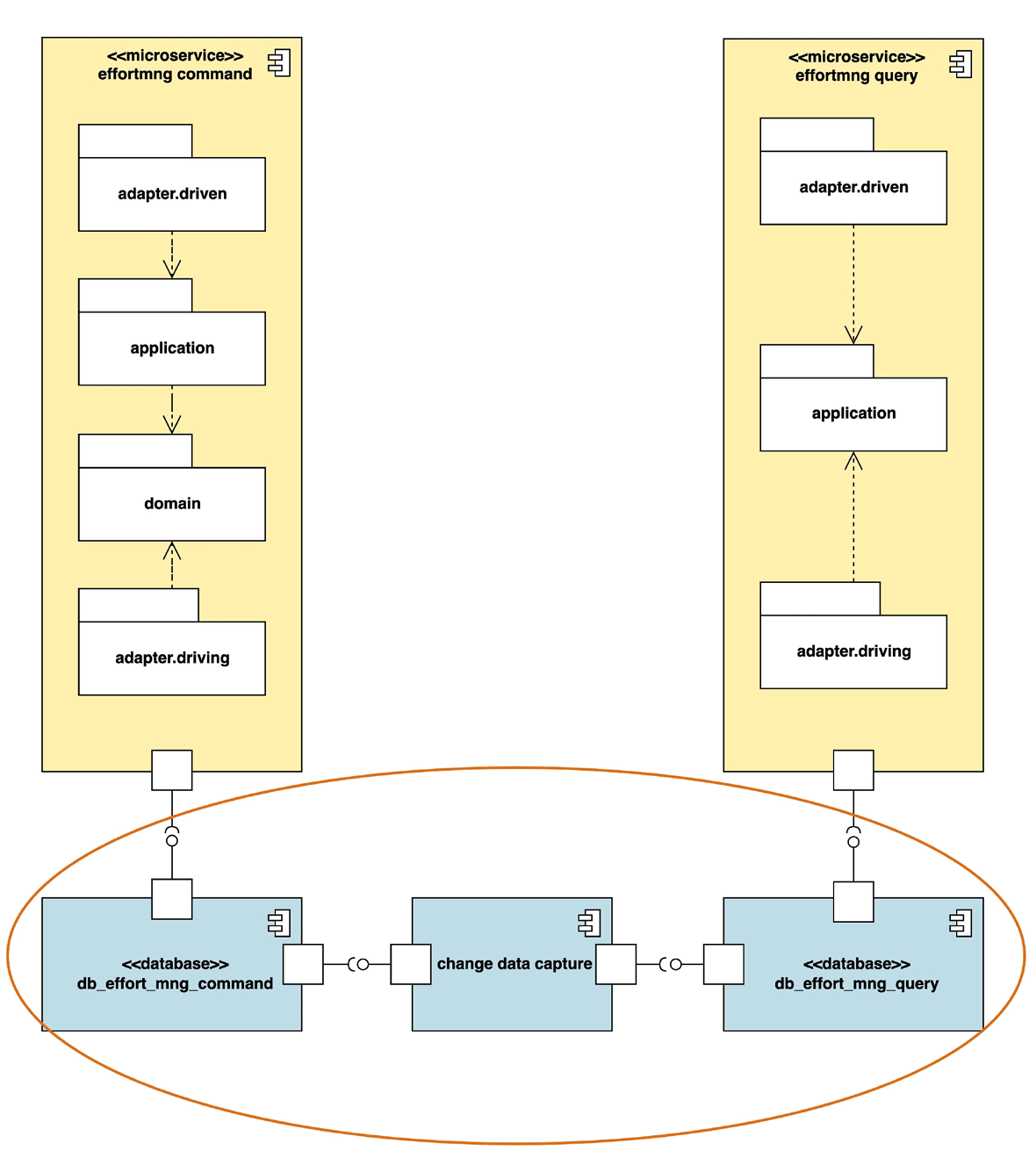
- 这种策略把数据库实例也分成两个,分别用于命令和查询两种数据模型。
- 数据库之间用“变更数据捕获”(change data capture, 简称 CDC)机制来同步。目前有多种开源或商业的方案可以选择。多数方案的原理都是由命令模型的数据库日志的变化来触发,然后同步到查询模型的数据库。
- 同时也可以在应用程序层面同步数据。

六 各种策略的组合
- CQRS 四个层面的策略,分别是代码结构分离、数据库结构分离、应用服务分离、数据库实例分离。其中,代码结构分离是其他几种策略的基础,对于 CQRS 是必选的,而其他三种策略都是可选的。
- 由于一共3种可选策略,每种都有使用和不使用两种选择,所以一共就可以有 8 种组合。它们各自的优缺点如下:
| 应用服务分离 | 数据库结构分离 | 数据库实例分离 | 主要优点 | 主要缺点 |
|---|---|---|---|---|
| ✖️ | ✖️ | ✖️ | 📌 实现简单 | ❌ 不容易通过横向扩展解决性能问题 |
| ✖️ | ✖️ | ✔️ | 📌 可通过横向扩展数据库实例,解决性能问题 | ❌ 数据同步比较复杂 ❌ 程序横向扩展成本较高 ❌ 连表查询仍可能影响性能 |
| ✖️ | ✔️ | ✖️ | 📌 通过减少表连接,解决性能问题 | ❌ 不容易通过横向扩展数据库解决性能问题 ❌ 表结构的转换逻辑比较复杂 |
| ✖️ | ✔️ | ✔️ | 📌 可通过横向扩展数据库解决性能问题 📌 通过减少表连接,解决性能问题 | ❌ 程序横向扩展成本较高 ❌ 表结构的转换逻辑比较复杂 |
| ✔️ | ✖️ | ✖️ | 📌 容易通过横向扩展程序解决性能问题 | ❌ 微服务运维成本高 ❌ 不容易通过横向扩展数据库解决性能问题 ❌ 连表查询仍可能影响性能 |
| ✔️ | ✖️ | ✔️ | 📌 容易通过横向扩展程序解决性能问题 📌 可通过横向扩展数据库实例,解决性能问题 | ❌ 微服务运维成本高 ❌ 连表查询仍可能影响性能 ❌ 数据同步比较复杂 |
| ✔️ | ✔️ | ✖️ | 📌 容易通过横向扩展程序解决性能问题 📌 通过减少表连接,解决性能问题 | ❌ 微服务运维成本高 ❌ 不容易通过横向扩展数据库解决性能问题 |
| ✔️ | ✔️ | ✔️ | 📌 容易通过横向扩展程序和数据库解决性能问题 📌 通过减少表连接,解决性能问题 | ❌ 微服务运维成本高 ❌ 数据同步比较复杂 |