机器学习16-强化学习-马尔科夫决策
强化学习-马尔科夫决策
参考网址:https://zhuanlan.zhihu.com/p/698124828
强化学习(Reinforcement Learning)是一种机器学习方法,旨在让智能体通过与环境的交互学习如何做出决策以达到既定的目标。在强化学习中,智能体通过尝试不同的行动来最大化累积的奖励,而不是依赖标记的数据进行学习。

强化学习系统通常包括以下几个要素:
1.智能体(Agent):负责与环境进行交互的实体,可以是机器人、程序或其他自主决策的实体。
2.环境(Environment):智能体所处的外部系统,对智能体的行为做出响应并提供反馈(奖励)。
3.状态(State):描述环境的特定情况的变量,智能体根据状态来做出决策。
4.动作(Action):智能体根据当前状态所采取的行为。
5.奖励(Reward):环境根据智能体的动作提供的反馈,用于评估动作的好坏。
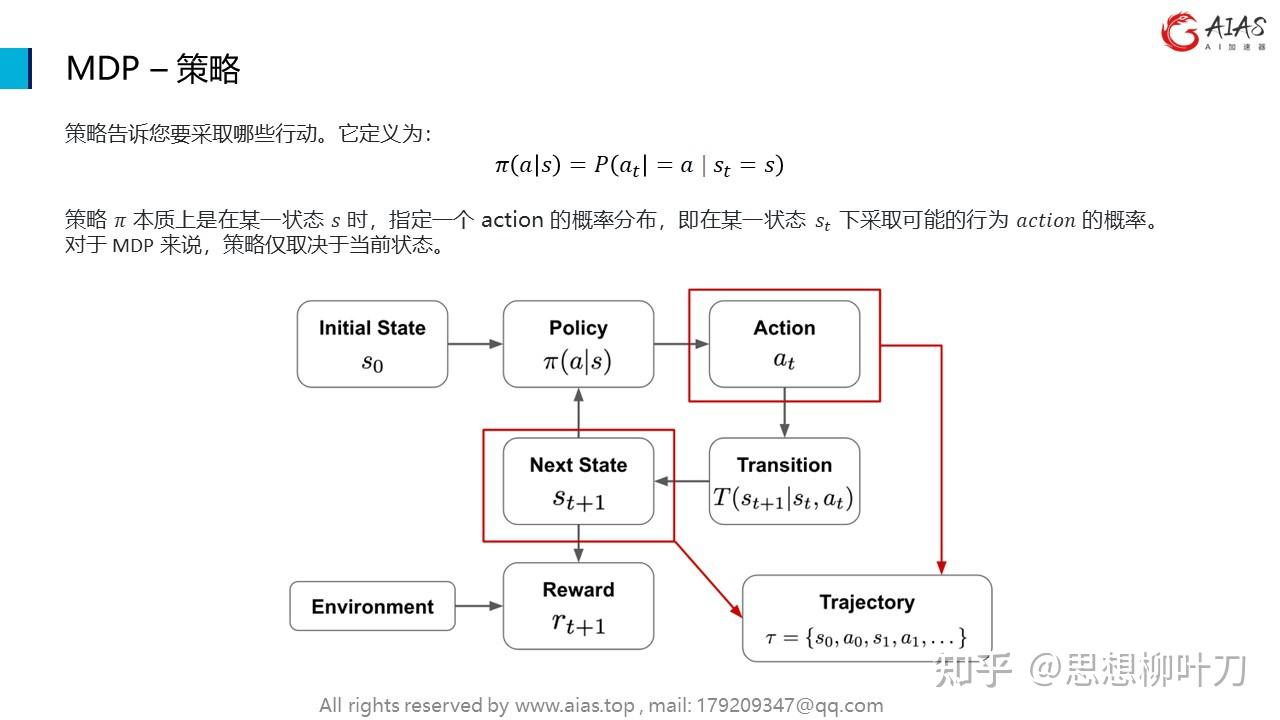
6.策略(Policy):定义了智能体在特定状态下选择动作的方式。
在强化学习中,智能体的目标是通过尝试不同的动作来学习一个最优的策略,使得在长期累积的奖励最大化。强化学习算法通常基于价值函数(Value Function)或者策略函数(Policy Function)来指导智能体的决策过程,常见的算法包括Q-learning、Deep Q Network(DQN)、Policy Gradient等。

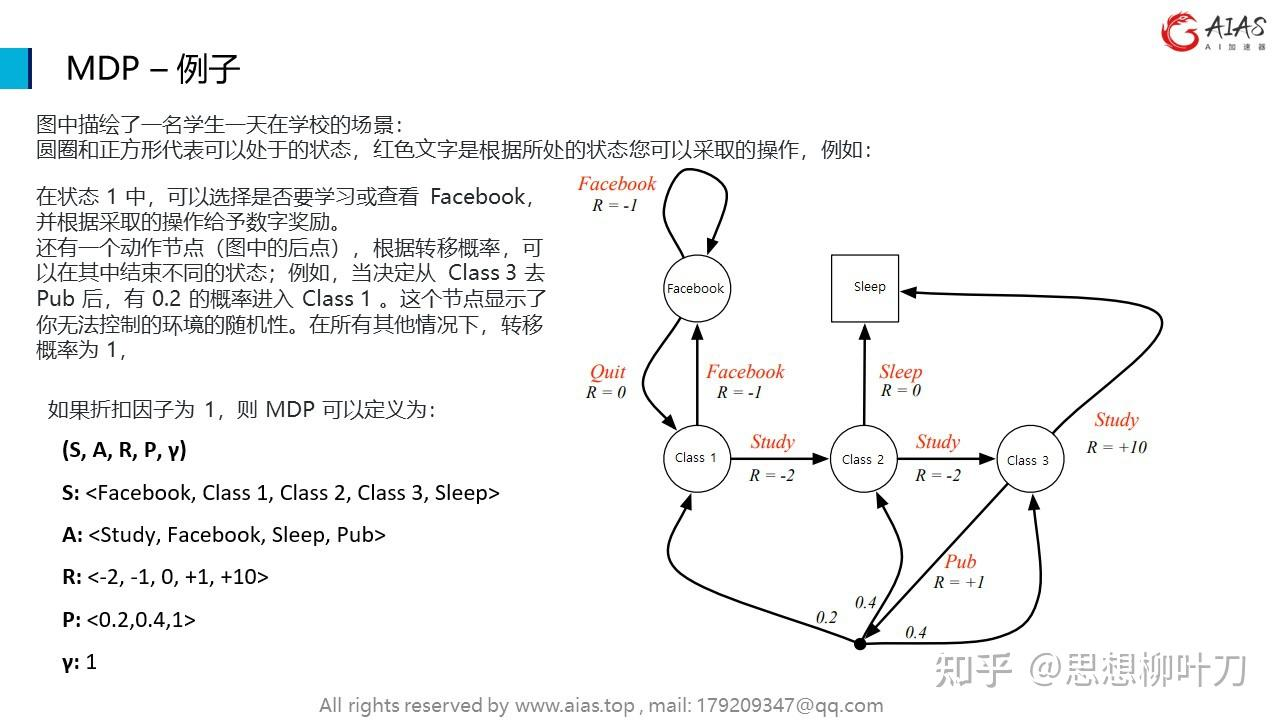
马尔可夫决策过程(MDP)是一个具有马尔可夫状态的环境;马尔可夫状态满足马尔可夫性质:该状态包含过去预测未来的所有相关信息。 MDP通常用于强化学习领域,其中智能体需要在不确定性环境中做出决策以最大化长期累积奖励。


一个马尔可夫决策过程由以下要素组成:
1.状态(State):表示系统可能处于的各种情况。在每个时间步,系统都处于某个状态。记作 。
2.动作(Action):智能体可以采取的行动或决策。记作 。
3.状态转移概率(Transition Probability):描述在某个状态下执行某个动作后系统转移到下一个状态的概率。通常用转移概率函数 表示在状态 执行动作 后转移到状态 ′ 的概率。
4.奖励(Reward):在每个时间步,智能体执行某个动作后会收到一个奖励,表示该动作的好坏程度。记作 。
5.折扣因子(Discount Factor):用于平衡当前奖励和未来奖励的重要性。
在一个MDP中,智能体根据当前的状态和奖励,以及预测未来可能的状态和奖励,制定出一个策略(Policy),即在每个状态下选择哪个动作。目标是找到一个最优策略,使得长期累积奖励最大化。
解决MDP问题的方法包括值迭代(Value Iteration)、策略迭代(Policy Iteration)、Q-learning、深度强化学习等。这些方法通过不断地评估和改进策略,使得智能体能够学习到在不确定环境中做出最优决策的方法。



两个值函数:
•状态值函数:状态价值函数告诉您您所处的状态“有多好”
•状态-动作值函数:告诉您在特定状态下采取特定行动“有多好”
状态(或状态-动作对)的“多好”是根据预期的未来奖励来定义的。
如果我们对所有策略取价值函数的最大值,我们就得到最优价值函数。一旦我们知道了最优价值函数,我们就可以求解 MDP 来找到最佳策略。



