R语言使用nonrandom包进行倾向评分匹配
倾向评分匹配(Propensity Score Matching,简称PSM)是一种统计学方法,用于处理观察研究(Observational Study)的数据,在SCI文章中应用非常广泛。在观察研究中,由于种种原因,数据偏差(bias)和混杂变量(confounding variable)较多,倾向评分匹配的方法正是为了减少这些偏差和混杂变量的影响,以便对实验组和对照组进行更合理的比较。
为什么需要做倾向评分匹配?
我们知道RCT的证据力度高,是因为对患者进行了严格的筛选。我们的回顾性研究都是过去的数据,很难像RCT一样进行严格的筛选出两组患者基线相近的基础资料,但我们可以通过倾向评分匹配把回归性的数据进行筛选,把基线资料相近的患者进行匹配,得到近似RCT的效果。
应用场景
1.基线资料不平
2.开展病例对照研究病阳性例数较少,如罕见病研究
3.将众多混杂因素变为一个变量:倾向值
以下为一个实例,没进行匹配前两组患者基线资料相差很大,进行倾向评分匹配后,基线资料近似一致了

既往咱们已经介绍了Matching包进行倾向评分匹配,今天咱们来介绍nonrandom包进行倾向评分匹配,这个包需要在github上安装,咱们先把这个包安装上去
library(devtools) # Load devtools
install_github("cran/nonrandom")
安装好后R导入R包自带得stu1数据
library(nonrandom)
data(stu1)

我介绍几个关键变量,pst是咱们得结局变量,therapie是等会咱们要进行匹配得变量,是两种治疗方法:1:乳房切除术;2:保乳 ,其他都是一些协变量
咱们可以先看下没调整前协变量对模型得影响
rel.eff <- relative.effect(data = stu1,formula = pst~therapie+tgr+age)
summary(rel.eff)

刚才已经说了,我们是要对therapie两种治疗方法:1:乳房切除术;2:保乳进行匹配,好查看预后,先进行倾向评分
ps <- pscore(data = stu1,formula = therapie~tgr+age)
对根据PS数据分层
strata <- ps.makestrata(object = ps)
对分层数据进行倾向评分匹配,ratio = 1是1:1匹配,caliper
表示卡钳
match <- ps.match(object = ps,ratio = 1,caliper = 0.5,givenTmatchingC = FALSE)
匹配好后可以从match中提取匹配好后得数据
data.matched<-match[["data.matched"]]

对匹配后得数据进行可视化
bal.plot1 <- dist.plot(object = strata,sel = c("tmass"))

bal.plot2 <- dist.plot(object = match,sel = c("alter"),plot.type = 2,compare = TRUE)
bal.plot2
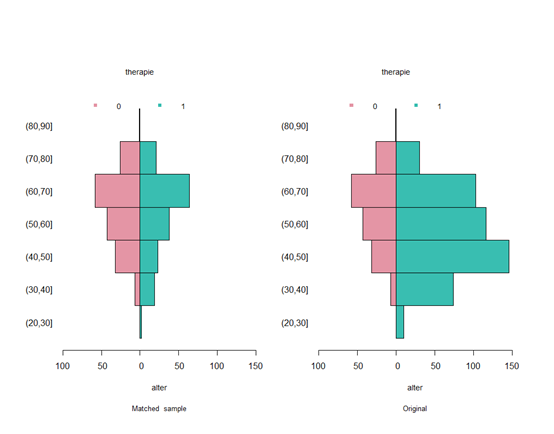
可以看出匹配前和匹配后差别很明显,还可以比较标准化差异
bal.table <- ps.balance(object = match,sel = c("tgr","age"),method = "stand.diff",alpha = 20)
bal.table

还可以比较匹配前后对效应值得影响
ps.est <- ps.estimate(object = strata,resp = "pst",regr = pst~therapie+tgr+age)
ps.est
