2 Studying《BPF.Performance.Tools》1-9
目录
1 Introduction
1.1 What Are BPF and eBPF?
1.2 What Are Tracing, Snooping, Sampling, Profiling, and Observability?
1.3 What Are BCC, bpftrace, and IO Visor?
1.4 A First Look at BCC: Quick Wins
1.5 BPF Tracing Visibility
1.6 Dynamic Instrumentation: kprobes and uprobes
1.7 Static Instrumentation: Tracepoints and USDT
1.8 A First Look at bpftrace: Tracing open()
1.9 Back to BCC: Tracing open()
1.10 Summary
2 Technology Background
2.1 BPF Illustrated
2.2 BPF
2.3 Extended BPF (eBPF)
2.4 Stack Trace Walking
2.5 Flame Graphs
2.6 Event Sources
2.7 kprobes
2.8 uprobes
2.9 Tracepoints
2.10 USDT
2.11 Dynamic USDT
2.12 PMCs
2.13 perf_events
2.14 Summary
3 Performance Analysis
3.1 Overview
3.2 Performance Methodologies
3.3 Linux 60-Second Analysis
3.4 BCC Tool Checklist
3.5 Summary
4 BCC
4.1 BCC Components
4.2 BCC Features
4.3 BCC Installation
4.4 BCC Tools
4.5 funccount
4.6 stackcount
4.7 trace
4.8 argdist
4.9 Tool Documentation
4.10 Developing BCC Tools
4.11 BCC Internals
4.12 BCC Debugging
4.13 Summary
5 bpftrace
5.1 bpftrace Components
5.2 bpftrace Features
5.3 bpftrace Installation
5.4 bpftrace Tools
5.5 bpftrace One-Liners
5.6 bpftrace Documentation
5.7 bpftrace Programming
5.8 bpftrace Usage
5.9 bpftrace Probe Types
5.10 bpftrace Flow Control
5.11 bpftrace Operators
5.12 bpftrace Variables
5.13 bpftrace Functions
5.14 bpftrace Map Functions
5.15 bpftrace Future Work
5.16 bpftrace Internals
5.17 bpftrace Debugging
5.18 Summary
6 CPUs
6.1 Background
6.2 Traditional Tools
6.3 BPF Tools
6.4 BPF One-Liners
6.5 Optional Exercises
6.6 Summary
7 Memory
7.1 Background
7.2 Traditional Tools
7.3 BPF Tools
7.4 BPF One-Liners
7.5 Optional Exercises
7.6 Summary
8 File Systems
8.1 Background
8.2 Traditional Tools
8.3 BPF Tools
8.4 BPF One-Liners
8.5 Optional Exercises
8.6 Summary
9 Disk I/O
9.1 Background
9.2 Traditional Tools
9.3 BPF Tools
9.4 BPF One-Liners
9.5 Optional Exercises
9.6 Summary
1 Introduction
本章介绍了一些关键术语,总结了一些技术,并演示了一些BPF性能工具。这些技术将在接下来的章节中进行更详细的解释。
1.1 What Are BPF and eBPF?
BPF代表伯克利包过滤器,这是一种首次开发于1992年的冷门技术,用于提高数据包捕获工具的性能 [McCanne 92]。2013年,Alexei Starovoitov提出了对BPF的重大重写[2],随后由Alexei和Daniel Borkmann进一步开发,并在2014年被纳入Linux内核[3]。这将BPF转变为一个通用的执行引擎,可用于多种用途,包括创建高级性能分析工具。
由于BPF功能强大,所以很难精确解释。它提供了一种在各种内核和应用事件上运行小型程序的方法。如果你熟悉JavaScript,你可能会发现一些相似之处:JavaScript允许网站在浏览器事件(如鼠标点击)上运行小型程序,从而实现各种基于网页的应用。BPF允许内核在系统和应用事件(如磁盘I/O)上运行小型程序,从而实现新的系统技术。它使内核完全可编程,使用户(包括非内核开发者)能够定制和控制他们的系统,以解决实际问题。
BPF是一种灵活且高效的技术,由指令集、存储对象和帮助函数组成。由于其虚拟指令集规范,它可以被视为一种虚拟机。这些指令由Linux内核BPF运行时执行,包括一个解释器和一个将BPF指令转换为原生指令以执行的JIT编译器。BPF指令首先必须通过一个验证器,验证器检查安全性,以确保BPF程序不会崩溃或破坏内核(但它不会防止用户编写可能执行但不合理的逻辑程序)。BPF的组件在第二章中详细解释。
到目前为止,BPF的三个主要用途是网络、可观察性和安全性。本书重点关注可观察性(跟踪)。
扩展的BPF通常缩写为eBPF,但官方缩写仍然是BPF,没有“e”。因此,在本书中,我使用BPF来指代扩展的BPF。内核中只有一个执行引擎,即BPF(扩展的BPF),它既运行扩展的BPF程序,也运行“经典的”BPF程序。
1.2 What Are Tracing, Snooping, Sampling, Profiling, and Observability?
这些术语都是用于分类分析技术和工具的。
**追踪**是一种基于事件的记录方法,也是这些BPF工具所使用的仪器类型。你可能已经使用过一些特定用途的追踪工具。例如,Linux的strace(1)记录并打印系统调用事件。有许多工具不进行事件追踪,而是使用固定的统计计数器来测量事件,然后打印摘要;Linux的top(1)就是一个例子。追踪器的一个显著特征是它能够记录原始事件及其元数据。这类数据可能非常庞大,可能需要后期处理成摘要。BPF使得编程追踪器成为可能,这些追踪器可以在事件上运行小程序,以实现自定义的实时统计摘要或其他操作,从而避免了昂贵的后处理。
虽然strace(1)的名称中带有“trace”(追踪),但并不是所有的追踪器都这样命名。例如,tcpdump(8)是另一种用于网络数据包的专用追踪器。(或许它应该被命名为tcptrace?)Solaris操作系统有自己的版本叫snoop(1M)2,是用来嗅探网络数据包的。我是第一个开发和发布许多追踪工具的人,并且是在Solaris上进行的,当时我(也许是遗憾地)为我早期的工具使用了“嗅探”这个术语。这就是为什么现在我们有execsnoop(8)、opensnoop(8)、biosnoop(8)等。嗅探、事件转储和追踪通常指的是同一件事。这些工具将在后续章节中介绍。
除了工具名称,内核开发者尤其使用“追踪”一词来描述用于可观察性的BPF。
**采样工具**通过获取部分测量数据来描绘目标的粗略图像,这也称为创建概要或概要分析。BPF有一个名为profile(8)的工具,通过定时器对运行中的代码进行采样。例如,它可以每10毫秒进行一次采样,或者换句话说,每秒钟(在每个CPU上)进行100次采样。采样器的一个优点是其性能开销可能比追踪器低,因为它们只测量更大事件集合中的一部分。缺点是采样只能提供粗略的图像,可能会遗漏事件。
**可观察性**指通过观察来理解系统,并对实现此目的的工具进行分类。这些工具包括追踪工具、采样工具和基于固定计数器的工具。不包括基准测试工具,因为基准测试工具通过执行工作负载实验来改变系统状态。本书中的BPF工具是可观察性工具,它们使用BPF进行编程追踪。
1.3 What Are BCC, bpftrace, and IO Visor?
这样直接编写BPF指令非常繁琐,因此开发了前端工具,提供了更高级别的语言;追踪领域的主要工具有BCC和bpftrace。

BCC(BPF编译器集合)是为BPF开发的第一个高级追踪框架。它提供了一个C编程环境,用于编写内核BPF代码,以及用户级接口的其他语言:Python、Lua和C++。它还是libbcc和当前libbpf库的起源,这些库提供了使用BPF程序进行事件仪表化的功能。BCC仓库还包含超过70个用于性能分析和故障排除的BPF工具。您可以在系统上安装BCC,然后运行提供的工具,而无需自己编写任何BCC代码。本书将向您展示这些工具的使用。
bpftrace是一个较新的前端,提供了一个专门的高级语言,用于开发BPF工具。bpftrace代码非常简洁,通常在本书中包含工具源代码,以展示工具的仪表化和处理方式。bpftrace建立在libbcc和libbpf库之上。
BCC和bpftrace如图1-1所示。它们是互补的:bpftrace非常适合强大的单行命令和定制短脚本,而BCC则更适合复杂的脚本和守护进程,并且可以利用其他库。例如,许多Python BCC工具使用Python argparse库提供复杂和精细的工具命令行参数控制。
另一个BPF前端叫做ply,目前正在开发中。它设计为轻量级,并且需要最少的依赖项,非常适合嵌入式Linux环境。如果ply更适合您的环境,您仍然会发现本书的示例可以通过切换到ply的语法进行执行。(ply的未来版本可能会直接支持bpftrace的语法。)本书侧重于bpftrace,因为它经历了更多的开发,并且具备分析所有目标所需的所有功能。
BCC和bpftrace并不存储在内核代码库中,而是存储在GitHub上的Linux基金会项目IO Visor中。它们的仓库链接如下:
- https://github.com/iovisor/bcc
- https://github.com/iovisor/bpftrace
本书中使用术语BPF追踪来指代BCC和bpftrace工具。
1.4 A First Look at BCC: Quick Wins
让我们直接看一些工具输出,以获取一些快速成果。以下工具跟踪新进程,并在每个进程启动时打印一行摘要。这个特定的工具是来自BCC的execsnoop(8),它通过跟踪execve(2)系统调用来工作,这是exec(2)的一个变体(因此得名)。关于安装BCC工具的信息在第四章中介绍,后续章节将更详细地介绍这些工具。

输出显示了在跟踪过程中执行的进程:这些进程可能如此短暂,以至于其他工具无法捕捉到它们。输出有许多行,展示了标准的Unix实用程序:ps(1)、grep(1)、sed(1)、cut(1)等。仅从页面上查看输出,你看不到的是它打印的速度。可以使用execsnoop(8)的-t选项来打印时间戳列:

我已经截取了输出(如[…]所示),但时间戳列显示了一个新线索:
新进程之间的时间间隔每隔一秒钟就会跳跃一次,这种模式循环重复。通过浏览输出,我发现每秒钟会启动30个新进程,这些进程之间会有一个一秒钟的暂停,然后又是30个进程的一批。
这里展示的输出来自我使用execsnoop(8)调试的Netflix的真实问题。这个问题发生在用于微基准测试的服务器上,但基准测试结果显示了过大的方差,不足以信任。在系统应该空闲时,我运行了execsnoop(8),发现系统并没有空闲!每秒钟都会启动这些进程,它们干扰了我们的基准测试。原因是一个配置错误的服务,每秒尝试启动一次,失败后再次尝试。一旦停止了这个服务,这些进程就停止了(通过execsnoop(8)确认),然后基准测试结果变得一致了。
execsnoop(8)的输出有助于性能分析方法论,称为工作负载特征化,本书中许多其他BPF工具也支持这一方法论。这种方法论很简单:定义正在施加的工作负载。理解工作负载通常足以解决问题,避免需要深入挖掘延迟或进行详细分析。在这种情况下,问题是应用到系统上的进程工作负载。第三章介绍了这种方法和其他方法。
尝试在你的系统上运行execsnoop(8),让它运行一个小时。你会发现什么?
execsnoop(8)打印每个事件的数据,但其他工具使用BPF计算高效的摘要。另一个可以用于快速成功的工具是biolatency(8),它将块设备I/O(磁盘I/O)汇总为延迟直方图。
以下是在一个对高延迟敏感的生产数据库上运行biolatency(8)的输出,因为它有服务级别协议要求在一定毫秒数内交付请求。

在运行biolatency(8)工具时,会对块I/O事件进行仪表化,并利用BPF计算和汇总它们的延迟。当用户停止运行该工具(按下Ctrl-C时),会打印汇总结果。我在这里使用了-m选项,以毫秒为单位打印汇总信息。
在这些输出中有一些有趣的细节,显示出双峰分布以及延迟的异常值。最大的峰值(通过ASCII分布可视化)位于0到1毫秒范围内,跟踪过程中有16,355个I/O操作落在此范围内。这说明速度很快,很可能是由于磁盘缓存命中以及闪存设备的作用。第二个峰值延伸到32到63毫秒范围内,比这些存储设备预期的速度慢得多,这表明可能存在排队现象。可以使用更多的BPF工具深入分析以确认这一点。最后,512到1023毫秒范围内有11个I/O操作。这些极慢的I/O被称为延迟异常值。现在我们知道它们的存在,可以使用其他BPF工具对其进行更详细的检查。
对于数据库团队而言,这些是需要重点研究和解决的问题:如果数据库在这些I/O操作上被阻塞,数据库的延迟目标将会超出。
1.5 BPF Tracing Visibility
BPF跟踪为您提供了对整个软件堆栈的可见性,并允许根据需要创建新的工具和仪表化。您可以立即在生产环境中使用BPF跟踪,无需重新启动系统或以任何特殊模式重新启动应用程序。这种感觉就像拥有X光视觉:当您需要检查某个深层次的内核组件、设备或应用程序库时,您可以以前所未有的方式直接观察到它——实时且在生产环境中。
举例来说,图1-2展示了一个通用的系统软件堆栈,我在其中用基于BPF的性能工具进行了标注,用于观察不同的组件。这些工具来自于BCC、bpftrace以及本书的内容。后续章节将详细解释其中许多工具的使用方法。

考虑一下您会使用哪些不同的工具来检查诸如内核CPU调度器、虚拟内存、文件系统等组件。通过简单浏览这张图表,您可能会发现以前的盲点,现在可以通过BPF工具进行观察。
传统上用于检查这些组件的工具总结在表1-1中,同时标明了BPF跟踪是否可以观察这些组件。

传统工具可以为分析提供有用的起点,您可以使用BPF跟踪工具进行更深入的探索。第3章总结了使用系统工具进行基本性能分析的内容,这可以作为您的起点。
1.6 Dynamic Instrumentation: kprobes and uprobes
BPF 跟踪支持多种事件源,以提供对整个软件堆栈的可见性。其中值得特别提及的是动态检测(也称为动态跟踪)——即在生产环境中将检测点插入到正在运行的软件中的能力。当不使用时,动态检测不会带来任何开销,因为软件运行未被修改。BPF 工具通常使用它来检测内核和应用程序函数的开始和结束,这些函数在一个典型的软件堆栈中可能有成千上万个。这种深度和全面的可见性让人感觉像是一种超能力。
动态检测最早在1990年代创造 [Hollingsworth 94],基于调试器用于在任意指令地址插入断点的技术。通过动态检测,目标软件记录信息,然后自动继续执行,而不是将控制权交给交互式调试器。动态跟踪工具(例如 kerninst [Tamches 99])被开发出来,并包含跟踪语言,但这些工具仍然不为人所知且很少使用。部分原因是它们涉及相当大的风险:动态跟踪需要在地址空间中实时修改指令,任何错误都可能导致立即的损坏和进程或内核崩溃。
动态检测第一次在2000年由IBM团队开发为Linux的DProbes,但补丁集被拒绝了。5 动态检测内核函数(kprobes)最终在2004年加入Linux,起源于DProbes,尽管它仍然不为人所知且难以使用。
一切在2005年发生了变化,当时Sun Microsystems推出了其自身版本的动态跟踪DTrace,具有易于使用的D语言,并将其包含在Solaris 10操作系统中。Solaris以生产稳定性而闻名和信赖,将DTrace作为默认包安装帮助证明动态跟踪可以安全地用于生产环境。这是该技术的一个转折点。我发表了许多文章展示了DTrace的实际用例,并开发和发布了许多DTrace工具。Sun的市场营销和销售部门也推广了这项技术;它被认为是一个引人注目的竞争特性。Sun教育服务部门将DTrace纳入标准Solaris课程并教授专门的DTrace课程。这些努力使动态检测从一种不为人所知的技术变成了一项广为人知且需求量大的功能。
Linux 在2012年增加了针对用户级函数的动态检测,以 uprobes 的形式。BPF 跟踪工具使用 kprobes 和 uprobes 来实现整个软件堆栈的动态检测。
为了展示如何使用动态跟踪,表1-2提供了使用 kprobes 和 uprobes 的 bpftrace 探针说明符示例。(bpftrace 在第5章中介绍。)

1.7 Static Instrumentation: Tracepoints and USDT
动态插装存在一个缺点:它会插装那些在软件的不同版本中可能被重命名或移除的函数。这被称为接口稳定性问题。在升级内核或应用程序软件后,您可能突然发现您的BPF工具不能正常工作。可能会打印关于找不到要插装的函数的错误,或者根本不打印任何输出。另一个问题是,编译器可能会将函数内联作为编译优化,使它们无法通过kprobes或uprobes进行插装。
解决稳定性和内联问题的一个方法是切换到静态插装,其中稳定的事件名称被编码到软件中,并由开发人员维护。BPF跟踪支持内核静态插装的跟踪点(tracepoints),以及用户级静态定义跟踪(USDT)用于用户级静态插装。静态插装的缺点在于,这些插装点对开发人员来说可能是维护负担,因此如果存在,通常数量有限。
这些细节只在您打算开发自己的BPF工具时才重要。如果是这样,建议的策略是首先尝试使用静态跟踪(使用tracepoints和USDT),然后在静态跟踪不可用时切换到动态跟踪(使用kprobes和uprobes)。
表1-3提供了使用tracepoints和USDT进行静态插装的bpftrace探针说明符示例。本表中提到的open(2) tracepoint 在第1.8节中有使用。

1.8 A First Look at bpftrace: Tracing open()
让我们从使用bpftrace跟踪open(2)系统调用开始。对于这个系统调用,有一个跟踪点(syscalls:sys_enter_open8),我将在命令行中编写一个简短的bpftrace程序,只有一行。
你暂时不需要理解下面这个一行程序中的代码;bpftrace语言和安装说明在第5章中有详细介绍。但你可能能够猜到这个程序的功能,即使不懂这种语言,因为它相当直观(一种直观的语言是设计良好的标志)。现在,只需关注工具的输出即可。

输出显示了进程名称和传递给open(2)系统调用的文件名:bpftrace正在进行系统范围的跟踪,因此任何使用open(2)的应用程序都会被观察到。每行输出总结了一个系统调用,这是一个产生每个事件输出的工具示例。BPF跟踪不仅可以用于生产服务器分析。例如,我在写这本书的同时在我的笔记本电脑上运行它,它展示了Slack聊天应用正在打开的文件。
BPF程序是在单引号中定义的,并且当我按下Enter键运行bpftrace命令时,它被编译并运行。bpftrace还激活了open(2)的跟踪点。当我按下Ctrl-C停止命令时,open(2)的跟踪点被停用,并且我的小型BPF程序被移除。这就是BPF跟踪工具按需仪器化的工作原理:它们只在命令的生命周期内激活和运行,这可能只有几秒钟。
生成的输出比我预期的要慢:我觉得我错过了一些open(2)系统调用事件。内核支持几种open的变体,而我只追踪了其中一种。我可以使用bpftrace通过使用-l和通配符列出所有的open跟踪点:

啊,我觉得现在openat(2)变种更常用。我会用另一个bpftrace的一行命令来确认一下:

再次强调,这个一行命令的代码将在第五章进行解释。目前,重要的是理解输出内容。现在显示的是这些跟踪点的计数,而不是每个事件一行显示。这证实了在跟踪过程中openat(2)系统调用更频繁——在跟踪期间调用了308次,而open(2)系统调用只被调用了五次。这个总结是由BPF程序在内核中高效计算的。
我可以在我的一行命令中添加第二个跟踪点,同时跟踪open(2)和openat(2)。然而,一行命令会开始变得有点长并且在命令行上不太方便操作,这时最好将其保存为一个脚本(一个可执行文件),这样可以更容易地在文本编辑器中进行编辑。这已经为您做好了:bpftrace附带了opensnoop.bt,它跟踪每个系统调用的开始和结束,并将输出打印为列。

这些列包括进程ID(PID)、进程命令名称(COMM)、文件描述符(FD)、错误代码(ERR)以及系统调用尝试打开的文件路径(PATH)。opensnoop.bt工具可用于排除失败的软件问题,例如尝试从错误路径打开文件,也可根据访问情况确定配置文件和日志文件的存储位置。它还可以识别一些性能问题,如文件打开过快或频繁检查错误的位置。它是一个具有多种用途的工具。
bpftrace附带超过20个此类现成可运行工具,而BCC则提供超过70个。除了直接帮助解决问题外,这些工具还提供源代码,展示如何跟踪各种目标。有时可能会遇到一些陷阱,正如我们在跟踪open(2)系统调用时看到的那样,它们的源代码可能展示了解决这些问题的方法。
1.9 Back to BCC: Tracing open()
现在让我们来看看BCC版本的opensnoop(8):

这里的输出看起来与之前的单行命令输出非常相似,至少具有相同的列。但是这个opensnoop(8)输出有一个bpftrace版本没有的东西:它可以使用不同的命令行选项调用:


虽然bpftrace工具通常简单且只做一件事,但BCC工具通常复杂且支持多种操作模式。虽然你可以修改bpftrace工具来仅显示失败的打开操作,但BCC版本已经支持这样的选项(-x):

这些输出显示了重复的失败。这样的模式可能指向效率低下或配置错误,可以进行修复。
BCC工具通常具有多个类似的选项,可以改变它们的行为,使它们比bpftrace工具更加灵活。这使它们成为一个很好的起点:希望它们可以满足你的需求,而无需编写任何BPF代码。然而,如果它们缺少你需要的可见性,你可以切换到bpftrace并创建自定义工具,因为这是一种更容易开发的语言。
后续可以将bpftrace工具转换为更复杂的BCC工具,支持各种选项,如之前展示的opensnoop(8)。BCC工具还可以支持使用不同的事件:在可用时使用tracepoints,不可用时切换到kprobes。但请注意,BCC编程要复杂得多,超出了本书的范围,本书专注于bpftrace编程。附录C提供了BCC工具开发的速成课程。
1.10 Summary
BPF跟踪工具可用于性能分析和故障排除,主要有两个项目提供支持:BCC和bpftrace。本章介绍了扩展BPF、BCC、bpftrace以及它们使用的动态和静态仪器技术。
下一章将更详细地探讨这些技术。如果你急于解决问题,可以暂时跳过第二章,直接阅读第三章或后续章节,这些章节涵盖了你感兴趣的主题。这些后续章节大量使用了术语,其中许多在第二章有解释,同时也在术语表中有总结。
2 Technology Background
第1章介绍了BPF性能工具使用的各种技术。本章将更详细地解释这些技术:它们的历史、接口、内部结构以及与BPF的使用。
本章是本书技术深度最大的章节,为了简洁起见,假设读者具有一定的内核内部和指令级编程知识。
学习目标不是记住本章的每一页内容,而是让你能够:
- 熟悉BPF的起源及扩展BPF在当今的角色
- 理解帧指针堆栈遍历和其他技术
- 掌握如何阅读火焰图
- 理解kprobes和uprobes的使用,并熟悉它们的稳定性注意事项
- 理解tracepoints、USDT探针和动态USDT的作用
- 了解性能计数器(PMC)及其与BPF跟踪工具的使用
- 关注未来的发展:BTF、其他BPF堆栈遍历器
理解本章将提高你对本书后续内容的理解,但你可能选择现在快速浏览本章,并根据需要随时返回以获取更多详细信息。第3章将帮助你开始使用BPF工具来提升性能。
2.1 BPF Illustrated
图2-1展示了本章介绍的许多技术及它们之间的关系。

2.2 BPF
BPF最初是为BSD操作系统开发的,其描述可见于1992年的论文《The BSD Packet Filter: A New Architecture for User-level Packet Capture》[McCanne 92]。这篇论文是在1993年USENIX冬季会议上在圣迭戈发表的,与《Measurement, Analysis, and Improvement of UDP/IP Throughput for the DECstation 5000》[7]一同展示。尽管DECstation已经退出市场,但BPF作为行业标准的数据包过滤解决方案仍然存在。
BPF的工作方式非常有趣:用户通过一个BPF虚拟机的指令集(有时称为BPF字节码)定义过滤表达式,然后将其传递给内核以由解释器执行。这使得过滤可以在内核级别完成,避免了每个数据包都要昂贵地复制到用户级进程的情况,从而提高了数据包过滤的性能,例如在tcpdump(8)中使用。它还提供了安全性,因为可以在执行之前验证来自用户空间的过滤器是否安全。由于早期的数据包过滤必须在内核空间进行,安全性是一个硬性需求。图2-2展示了这一工作原理。

你可以使用tcpdump(8)的-d选项来打印出它用于过滤表达式的BPF指令。例如:

最初的BPF,现在称为“经典BPF”,是一种有限的虚拟机。它包括两个寄存器、一个由16个内存槽组成的临时存储器,以及一个程序计数器。所有这些都是使用32位寄存器大小运行的。经典BPF首次出现在Linux内核中是在1997年,对应2.1.75内核版本 [8]。
自BPF添加到Linux内核以来,已经有一些重要的改进。Eric Dumazet在2011年7月发布的Linux 3.0版本中添加了BPF即时编译器(JIT),提升了性能以取代解释器 [9]。2012年,Will Drewry为seccomp(安全计算)系统调用策略添加了BPF过滤器 [10];这是BPF在网络之外的首次应用,展示了BPF作为通用执行引擎的潜力。
2.3 Extended BPF (eBPF)
Extended BPF由Alexei Starovoitov在其在PLUMgrid工作期间创建,当时该公司正在研究创建软件定义网络解决方案的新方法。这是BPF在20年间的首次重大更新,使BPF扩展为通用虚拟机 [3]。在该提议阶段,来自Red Hat的内核工程师Daniel Borkmann帮助重新设计,以便将其纳入内核并替代现有的BPF [4]。扩展BPF成功地被纳入,并自此以来得到许多其他开发者的贡献(详见致谢部分)。
扩展BPF增加了更多的寄存器,从32位切换到64位字,创建了灵活的BPF“映射”存储,并允许调用一些受限制的内核函数 [5]。它还被设计为通过一对一的映射到本机指令和寄存器进行即时编译,从而使先前的本机指令优化技术能够重新用于BPF。BPF验证器也进行了更新,以处理这些扩展并拒绝任何不安全的代码。
表2-1显示了经典BPF与扩展BPF之间的区别。

Alexei最初的提议是2013年9月的一个名为“扩展BPF”的补丁集 [2]。到了2013年12月,Alexei已经开始提议将其用于跟踪过滤器 [11]。经过与Daniel的讨论和开发,这些补丁从2014年3月开始逐步合并到Linux内核中 [3][12]。JIT组件在2014年6月的Linux 3.15版本中合并,用于控制BPF的bpf(2)系统调用在2014年12月的Linux 3.18版本中合并 [13]。Linux 4.x系列的后续增加则为kprobes、uprobes、tracepoints和perf_events增加了BPF支持。
在最早的补丁集中,这项技术被缩写为eBPF,但后来Alexei改为简称为BPF [7]。所有关于BPF的开发现在都在net-dev邮件列表上进行,统一称为BPF。
Linux BPF运行时的架构如图2-3所示,展示了BPF指令如何通过BPF验证器并由BPF虚拟机执行。BPF虚拟机的实现包括解释器和JIT编译器:JIT编译器生成本机指令进行直接执行。验证器拒绝不安全的操作,包括无界循环:BPF程序必须在有限时间内完成。

BPF可以利用帮助程序来获取内核状态,并使用BPF映射进行存储。BPF程序在事件发生时执行,这些事件包括kprobes、uprobes和tracepoints。
接下来的章节讨论为什么性能工具需要BPF、扩展BPF编程、查看BPF指令、BPF API、BPF的限制以及BTF。这些章节为理解在使用bpftrace和BCC时BPF的工作原理提供了基础。此外,附录D直接讲述了使用C进行BPF编程,附录E介绍了BPF指令。
2.3.1 Why Performance Tools Need BPF
性能工具部分使用扩展BPF是因为它的可编程性。BPF程序可以执行自定义的延迟计算和统计摘要。单凭这些特性就足以构建一个有趣的工具,而且许多其他跟踪工具也具备这些功能。BPF之所以与众不同,是因为它不仅高效且安全,而且已经集成在Linux内核中。有了BPF,你可以在生产环境中运行这些工具,而无需添加任何新的内核组件。
让我们看一些输出和图表,了解性能工具如何使用BPF。这个例子来自我早期发布的一个名为bitehist的BPF工具,它展示了磁盘I/O的直方图 [15]:

关键变化在于直方图可以在内核上下文中生成,这极大地减少了复制到用户空间的数据量。这种效率提升非常显著,使得原本成本过高的工具可以在生产环境中运行。具体来说:
在使用BPF之前,生成这种直方图摘要的完整步骤如下:
1. 在内核中:启用磁盘I/O事件的仪表化。
2. 在内核中,对于每个事件:将记录写入性能缓冲区。如果使用追踪点(推荐),记录包含有关磁盘I/O的多个元数据字段。
3. 在用户空间:定期将所有事件的缓冲区复制到用户空间。
4. 在用户空间:遍历每个事件,解析事件的元数据以获取字节字段。其他字段被忽略。
5. 在用户空间:生成字节字段的直方图摘要。
步骤2到4对于高I/O系统有很高的性能开销。想象一下,每秒传输10,000个磁盘I/O跟踪记录到一个用户空间程序中进行解析和汇总。
使用BPF后,bitesize程序的步骤如下:
1. 在内核中:启用磁盘I/O事件的仪表化,并附加一个由bitesize定义的自定义BPF程序。
2. 在内核中,对于每个事件:运行BPF程序。它仅获取字节字段并将其保存到自定义的BPF映射直方图中。
3. 在用户空间:读取一次BPF映射直方图并将其打印出来。
这种方法避免了将事件复制到用户空间和重新处理的成本。它还避免了复制未使用的元数据字段。唯一复制到用户空间的数据如前面的输出所示:即“count”列,这是一个数字数组。
2.3.2 BPF Versus Kernel Modules
理解BPF在可观测性方面的好处的另一种方法是将其与内核模块进行比较。kprobes和tracepoints已经存在多年,并且可以直接从可加载的内核模块中使用。使用BPF相比内核模块进行跟踪的好处包括:
- BPF程序通过验证器进行检查;而内核模块可能引入错误(如内核崩溃)或安全漏洞。
- BPF通过映射提供丰富的数据结构。
- BPF程序可以编译一次,随后在任何地方运行,因为BPF指令集、映射、辅助函数和基础设施构成了稳定的ABI。但是,某些BPF跟踪程序可能引入不稳定组件,如在内核结构中进行仪表化的kprobes,因此不能完全做到这一点(请参见第2.3.10节,关于解决方案的工作)。
- BPF程序不需要编译内核构建产物。
- 学习BPF编程比开发内核模块所需的内核工程更容易,使更多人能够使用它。
需要注意的是,当BPF用于网络时,还有其他好处,包括能够原子性地替换BPF程序。而内核模块需要先完全卸载出内核,然后再加载新版本到内核中,可能会导致服务中断。
内核模块的好处在于可以使用其他内核功能和设施,而不仅限于BPF辅助函数调用。然而,这也带来了风险,如果滥用任意内核功能,则可能引入错误。
2.3.3 Writing BPF Programs
BPF可以通过现有的多个前端进行编程。用于跟踪的主要前端,按照语言层级从低到高排列如下:
- LLVM
- BCC
- bpftrace
LLVM编译器支持BPF作为编译目标。可以使用LLVM支持的更高级语言编写BPF程序,例如通过Clang的C语言或LLVM中间表示(IR),然后将其编译成BPF。LLVM包括优化器,可提高生成的BPF指令的效率和大小。
在LLVM IR中开发BPF是一种改进,但切换到BCC或bpftrace更为便捷。BCC允许用C语言编写BPF程序,而bpftrace提供其自己的高级语言。它们内部都使用LLVM IR和LLVM库来编译成BPF。
本书中的性能工具是使用BCC和bpftrace编程的。直接使用BPF指令或LLVM IR编程属于BCC和bpftrace内部开发人员的领域,超出了本书的范围。对于我们使用和开发BPF性能工具的人来说并不必要。如果您希望成为BPF指令开发人员或感兴趣,以下是一些额外阅读资源:
- 附录E提供了BPF指令和宏的简要概述。
- BPF指令在Linux源树的文档中有记录,位于Documentation/networking/filter.txt [17]。
- LLVM IR在在线LLVM参考文档中有记录;可以从llvm::IRBuilderBase类的参考开始 [18]。
- 参阅Cilium BPF和XDP参考指南 [19]。
大多数人永远不会直接编写BPF指令,但有时会查看它们,例如在工具遇到问题时。接下来的两个部分将使用bpftool(8)和bpftrace展示示例。
2.3.4 Viewing BPF Instructions: bpftool
bpftool(8)是在Linux 4.15中添加的,用于查看和操作BPF对象,包括程序和映射。它位于Linux源代码中的tools/bpf/bpftool目录下。本节总结了如何使用bpftool(8)查找加载的BPF程序并打印它们的指令。
bpftool
从Linux 5.2版本开始,默认输出的bpftool(8)显示其操作对象的对象类型。


perf和prog子命令可用于查找和打印跟踪程序。这里未涵盖的bpftool(8)功能包括附加程序、读写映射、操作cgroups以及列出BPF功能。
bpftool perf
perf子命令显示通过perf_event_open()附加的BPF程序,这在Linux 4.17及更高版本上是BCC和bpftrace程序的标准操作方式。例如:

这些输出显示了三个不同的PID,每个PID都有不同的BPF程序:
- PID 1765 是用于实例分析的Vector BPF PMDA代理。 (详见第17章了解更多详情。)
- PID 21993 是 biolatency(8) 的bpftrace版本。它展示了两个uprobes,分别是来自bpftrace程序的BEGIN和END探针,以及两个kprobes,用于检测块I/O的开始和结束。(源代码可参见第9章。)
- PID 25440 是 biolatency(8) 的BCC版本,目前用于对块I/O的不同开始函数进行检测。
偏移字段显示了从被检测对象进行检测的偏移量。对于bpftrace,偏移量1781920匹配了bpftrace二进制文件中的BEGIN_trigger函数,偏移量1781927匹配了END_trigger函数(可以使用readelf -s bpftrace进行验证)。
prog_id 是BPF程序的ID,可以通过以下子命令打印出来。
bpftool prog show
prog show子命令列出所有程序(不仅限于基于perf_event_open()的程序):

这个输出显示了bpftrace程序的程序ID(从232到235)和BCC程序的程序ID(262和263),以及其他已加载的BPF程序。请注意,BCC kprobe程序具有BPF类型格式(BTF)信息,这在输出中通过btf_id的存在显示出来。关于BTF的详细信息可以参考第2.3.9节。暂时理解BTF是BPF版本的调试信息即可。
bpftool prog dump xlated
可以通过其ID打印(“dump”)每个BPF程序。xlated模式将BPF指令翻译成汇编语言。以下是程序234,即bpftrace块I/O完成程序的示例:

输出显示了BPF可以使用的受限内核辅助函数之一:bpf_probe_read()。(更多的辅助函数列在表2-2中。)
现在将前面的输出与已使用BTF编译的BCC块I/O完成程序的输出进行比较,其ID为263:


这个输出现在包含了来自BTF的源代码信息(用粗体突出显示)。请注意,这是一个不同的程序(具有不同的指令和调用)。
如果可用,linum修饰符还包括来自BTF的源文件和行号信息(用粗体突出显示)。

在这种情况下,行号信息指的是运行程序时BCC创建的虚拟文件。
opcodes修饰符包括BPF指令的操作码(用粗体突出显示):


BPF指令的操作码在附录E中有详细说明。
还有一个visual修饰符,以DOT格式输出控制流图信息,可以供外部软件进行可视化。例如,可以使用GraphViz及其dot(1)有向图工具 [20]:

然后可以查看生成的PNG文件,以查看指令流。GraphViz提供了不同的布局工具:我通常使用dot(1),neato(1),fdp(1)和sfdp(1)来绘制DOT数据图。这些工具允许进行各种自定义(例如边长:-Elen)。图2-5展示了使用GraphViz中的osage(1)来可视化这个BPF程序的结果。

这是一个复杂的程序!其他GraphViz工具会将代码块展开,以避免箭头的混乱,但会生成更大的文件。如果你需要阅读像这样的BPF指令,你应该尝试不同的工具,找到最适合你的那一个。
bpftool prog dump jited
prog dump jited子命令显示正在执行的处理器的机器码。本节显示了x86_64;然而,BPF支持Linux内核支持的所有主要架构的JIT。对于完成的BCC块I/O程序:

如前所示,此程序的BTF存在使得bpftool(8)能够包含源代码行;否则,这些行将不会存在。
bpftool btf
bpftool(8)还可以转储BTF ID。例如,BTF ID 5 是用于完成的BCC块I/O程序:


2.3.5 Viewing BPF Instructions: bpftrace
tcpdump(8)可以使用-d选项输出BPF指令,而bpftrace可以使用-v12选项进行相同的操作:


如果出现bpftrace内部错误,这些输出也会被打印出来。如果你在开发bpftrace内部功能时,可能会不小心违反BPF验证器的规则,导致程序被内核拒绝。此时,这些指令将被打印出来,你需要研究它们以确定问题的原因并开发修复方案。
大多数人永远不会遇到bpftrace或BCC的内部错误,也不会看到BPF指令。如果你确实遇到了这样的问题,请向bpftrace或BCC项目提交一个问题报告,或考虑自己贡献修复方案。
2.3.6 BPF API
为了更好地理解BPF的能力,以下部分总结了Linux 4.20版本中包含的扩展BPF API 的选定部分,来自include/uapi/linux/bpf.h。
BPF助手函数
BPF程序无法调用任意的内核函数。为了在这种限制下完成特定任务,提供了BPF可以调用的“助手”函数。选定的函数列在表2-2中。


一些这些助手函数在先前的bpftool(8)的xlated输出和bpftrace的-v输出中已经展示过了。
这些描述中的术语“current”指的是当前正在运行的线程——即当前在CPU上运行的线程。
请注意,include/uapi/linux/bpf.h 文件通常为这些助手函数提供了详细的文档。以下是从bpf_get_stackid()的摘录:


这些文件可以在任何托管Linux源代码的网站上在线浏览,例如:https://github.com/torvalds/linux/blob/master/include/uapi/linux/bpf.h。
还有许多其他的助手函数可用,主要用于软件定义网络。当前版本的Linux(5.2)有98个助手函数。
bpf_probe_read()
bpf_probe_read() 是一个特别重要的助手函数。在BPF中,内存访问受限于BPF寄存器和栈(以及通过助手的BPF映射)。对于任意内核内存(如BPF之外的其他内核内存),必须通过bpf_probe_read()来读取,它执行安全检查并禁用页面故障,以确保从探针上下文中的读取不会导致故障(这可能会引起内核问题)。
除了读取内核内存,这个助手函数还用于将用户空间内存读取到内核空间。这种操作的实现方式取决于架构:在x86_64架构上,用户和内核地址范围不重叠,因此可以通过地址确定模式。但在其他架构(如SPARC [21])中,情况并非如此,因此BPF要支持这些其他架构,可能需要额外的助手函数,比如bpf_probe_read_kernel()和bpf_probe_read_user()。
BPF系统调用命令
表2-3展示了用户空间可以调用的选定BPF操作。

这些操作作为bpf(2)系统调用的第一个参数传递。您可以使用strace(1)来查看它们的执行过程。例如,可以检查运行BCC execsnoop(8)工具时发出的bpf(2)系统调用:

**这些操作在输出中用粗体显示**。请注意,我通常避免使用strace(1),因为它当前的ptrace()实现可能会显著减慢目标进程的速度——减慢超过100倍 [22]。我在这里使用它是因为它已经为bpf(2)系统调用提供了翻译映射,将数字转换为可读字符串(例如,“BPF_PROG_LOAD”)。
BPF程序类型
不同的BPF程序类型指定了BPF程序附加到的事件类型和事件的参数。用于BPF跟踪程序的主要程序类型如表2-4所示。

之前的strace(1)输出包括两个类型为BPF_PROG_TYPE_KPROBE的BPF_PROG_LOAD调用,因为那个版本的execsnoop(8)使用了kprobe和kretprobe来检测execve()的开始和结束。
在bpf.h中还有更多用于网络和其他用途的程序类型,包括表2-5中显示的那些。

BPF Map Types
BPF映射类型,其中一些列在表2-6中,定义了不同类型的映射。

之前的strace(1)输出包括一个类型为BPF_MAP_TYPE_PERF_EVENT_ARRAY的BPF_MAP_CREATE调用,该调用由execsnoop(8)使用,用于将事件传递给用户空间以供打印。
在bpf.h中还有许多用于特殊目的的映射类型。
2.3.7 BPF Concurrency Controls
直到Linux 5.1版本之前,BPF缺乏并发控制,直到添加了自旋锁辅助函数。(然而,它们目前还不能在跟踪程序中使用。)在跟踪过程中,多个并行线程可以并行查找和更新BPF映射字段,导致其中一个线程覆盖另一个线程的更新,从而造成数据损坏。这也被称为“丢失更新”问题,即并发读写重叠,导致更新丢失。跟踪前端工具BCC和bpftrace尽可能使用每CPU哈希和数组映射类型来避免这种损坏。它们为每个逻辑CPU创建实例以供使用,防止并行线程更新共享位置。例如,用于计算事件数量的映射可以作为每CPU映射进行更新,然后在需要时将每CPU的值合并为总计数。

比较计数结果显示,普通哈希映射事件数量低估了0.01%。
除了每CPU映射外,还有其他用于并发控制的机制,包括独占的加法指令(BPF_XADD)、可以原子地更新整个映射的映射内映射,以及BPF自旋锁。通过bpf_map_update_elem()进行的常规哈希和LRU映射更新也是原子的,并且由于并发写入而没有数据竞争。自Linux 5.1版本中添加的自旋锁由bpf_spin_lock()和bpf_spin_unlock()辅助函数控制 [23]。
2.3.8 BPF sysfs Interface
在Linux 4.4中,BPF引入了通过虚拟文件系统暴露BPF程序和映射的命令,通常挂载在/sys/fs/bpf目录下。这种能力被称为“pinning”,具有多种用途。它允许创建持久的BPF程序(类似守护进程),即使加载它们的进程退出后仍然继续运行。它还提供了另一种用户级程序与运行中的BPF程序交互的方式:它们可以读取和写入BPF映射。
在这本书中,BPF可观测性工具并未使用pinning,这些工具模仿了标准的Unix实用程序,可以启动和停止。然而,如果需要,这些工具中的任何一个都可以转换为使用pinning的形式。这种技术更常用于网络程序(例如,Cilium软件 [24])。
作为pinning的一个示例,Android操作系统利用pinning自动加载和固定存放在/system/etc/bpf目录下的BPF程序 [25]。Android提供了库函数与这些固定的程序进行交互。
2.3.9 BPF Type Format (BTF)
本书中反复描述的一个问题是缺乏关于被插装代码的信息,这使得编写BPF工具变得困难。正如将在多个场合提到的那样,解决这些问题的理想方案是在此引入的BTF(BPF Type Format)。
BTF(BPF类型格式)是一种元数据格式,用于编码调试信息,用于描述BPF程序、BPF映射等等。BTF这个名称最初是用于描述数据类型,但后来扩展到包括定义子例程的函数信息、源代码/行信息的行信息,以及全局变量信息。
BTF调试信息可以嵌入到vmlinux二进制文件中,或者与BPF程序一起通过本地Clang编译或LLVM JIT生成,以便可以更轻松地使用加载器(例如libbpf)和工具(例如bpftool(8))检查BPF程序。检查和跟踪工具,包括bpftool(8)和perf(1),可以检索此类信息,以提供带有源代码注释的BPF程序,或者根据它们的C结构漂亮打印映射键/值,而不是原始的十六进制转储。先前的bpftool(8)示例演示了对LLVM-9编译的BCC程序进行转储。
除了描述BPF程序外,BTF正成为描述所有内核数据结构的通用格式。在某些方面,它正在成为BPF使用的内核调试信息的轻量级替代品,以及内核头文件的更完整和可靠的替代品。
BPF跟踪工具通常需要安装内核头文件(通常通过linux-headers软件包),以便可以导航到各种C结构。这些头文件不包含内核中所有结构的定义,这使得开发某些BPF可观察性工具变得困难:缺失的结构需要作为一种解决方法在BPF工具源代码中定义。还存在处理复杂头文件时出现问题的情况;在这些情况下,bpftrace可能会转向中止,而不是继续进行可能不正确的结构偏移量。BTF可以通过提供所有结构的可靠定义来解决此问题。(一个早期的bpftool btf输出展示了如何包含task_struct。)在未来,包含BTF的Linux内核vmlinux二进制文件将具备自我描述能力。
在编写本书时,BTF仍在开发中。为了支持一次编译,随处运行的倡议,将会为BTF添加更多信息。有关BTF的最新信息,请参阅内核源码中的Documentation/bpf/btf.rst [26]。
2.3.10 BPF CO-RE
BPF编译一次,随处运行(CO-RE)项目旨在允许将BPF程序编译为BPF字节码后,保存并分发到其他系统上执行。这将避免在每个系统上都安装BPF编译器(如LLVM和Clang),尤其对于空间受限的嵌入式Linux而言,这是一项挑战。此外,它还将避免在执行BPF可观察性工具时运行编译器所带来的运行时CPU和内存成本。
CO-RE项目的开发人员安德里·纳克里科(Andrii Nakryiko)正在解决诸如不同系统上的内核结构偏移处理等挑战,这需要根据需要重写BPF字节码中的字段偏移。另一个挑战是缺失的结构成员,这要求根据内核版本、内核配置和/或用户提供的运行时标志,条件性地访问字段。CO-RE项目将利用BTF信息,并在撰写本书时仍在开发中。
2.3.11 BPF Limitations
BPF程序不能调用任意内核函数;它们仅限于API中列出的BPF辅助函数。随着需求的增加,未来的内核版本可能会添加更多辅助函数。BPF程序还对循环施加限制:允许BPF程序在任意kprobes上插入无限循环是不安全的,因为这些线程可能持有关键锁,阻塞系统的其余部分。解决方法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3增加了对BPF有界循环的支持,这些循环具有可验证的上限运行时间。
BPF堆栈大小限制为MAX_BPF_STACK,设置为512。在编写BPF可观测性工具时,特别是在堆栈上存储多个字符串缓冲区时,有时会遇到此限制:单个char[256]缓冲区消耗了堆栈的一半。目前没有增加此限制的计划。解决方案是改用BPF映射存储,它在效果上是无限的。已经开始将bpftrace字符串切换到映射存储,而不是堆栈存储。
BPF程序中指令的数量最初限制为4096条。长的BPF程序有时会遇到此限制(如果没有LLVM编译器优化,它们将更快地遇到此限制)。Linux 5.2显著增加了此限制,因此不应再成为问题。BPF验证器的目标是接受任何安全的程序,这些限制不应成为障碍。
2.3.12 BPF Additional Reading
更多了解扩展BPF的信息来源包括:
- 内核源码中的Documentation/networking/filter.txt [17]
- 内核源码中的Documentation/bpf/bpf_design_QA.txt [29]
- bpf(2) 手册页 [30]
- bpf-helpers(7) 手册页 [31]
- Jonathan Corbet 的文章 "BPF: the universal in-kernel virtual machine" [32]
- Suchakra Sharma 的文章 "BPF Internals—II" [33]
- Cilium 的 "BPF and XDP Reference Guide" [19]
在第4章和附录C、D和E中还提供了BPF程序的额外示例。
2.4 Stack Trace Walking
堆栈跟踪是理解导致事件发生的代码路径以及对内核和用户代码进行性能分析的无价工具。BPF提供了专门的映射类型来记录堆栈跟踪,并可以使用基于帧指针或ORC(ORC unwinder)的堆栈遍历来获取它们。未来,BPF可能会支持其他的堆栈遍历技术。
2.4.1 Frame Pointer–Based Stacks
帧指针技术遵循一种约定,即在寄存器中始终可以找到一个链表的堆栈帧头部(在x86_64架构上是RBP),并且返回地址存储在存储的RBP的已知偏移量(+8)处[Huibicka 13]。这意味着任何中断程序的调试器或跟踪器可以读取RBP,然后通过遍历RBP链表并获取已知偏移处的地址轻松获取堆栈跟踪信息。这在图2-6中有展示。

AMD64 ABI指出,将RBP用作帧指针寄存器是一种传统做法,但可以避免使用它以节省函数前奏和后奏指令,并将RBP作为通用寄存器可用。
目前,gcc编译器默认省略帧指针并将RBP用作通用寄存器,这导致基于帧指针的堆栈遍历出现问题。可以通过使用 `-fno-omit-frame-pointer` 选项来恢复默认设置。关于引入省略帧指针作为默认的补丁有三个细节解释为何这样做 [34]:
- 该补丁最初是为i386引入的,该架构有四个通用寄存器。释放RBP将可用寄存器数从四个增加到五个,从而显著提高性能。但是对于x86_64而言,已经有16个可用寄存器,因此这种改变带来的收益要少得多 [35]。
- 假设堆栈遍历问题已经解决,这是因为gdb(1)支持其他技术。然而,这并未考虑到在中断禁用的有限上下文中运行的跟踪器堆栈遍历。
- 需要在基准测试中与Intel的icc编译器竞争。
如今,在x86_64上,大多数软件都使用gcc的默认设置,导致帧指针堆栈跟踪出现问题。我上次在生产环境中研究帧指针省略带来的性能增益时,通常不到百分之一,并且经常接近零,难以测量。Netflix的许多微服务都已经重新启用了帧指针,因为通过CPU分析获得的性能优势超过了微小的性能损失。
使用帧指针并非遍历堆栈的唯一方法;其他方法包括debuginfo、LBR和ORC。
2.4.2 debuginfo
附加调试信息通常以调试信息包的形式提供给软件,这些包包含以DWARF格式的ELF调试信息文件。这些文件包括.gdb(1)等调试器可以用来遍历堆栈的部分,即使没有使用帧指针寄存器。ELF文件的关键部分是.eh_frame和.debug_frame。
调试信息文件还包括包含源代码和行号信息的部分,使得调试的文件比原始的二进制文件要大得多。第12章中的一个例子展示了libjvm.so的大小为17兆字节,而其调试信息文件则达到了222兆字节。在某些环境中,由于其巨大的大小,调试信息文件未被安装。
BPF当前不支持使用这种堆栈遍历技术:这是处理器密集型的操作,需要读取可能未被置换的ELF部分。这使得在受限的禁止中断的BPF环境中实现此技术变得具有挑战性。
请注意,BPF前端工具BCC和bpftrace确实支持调试信息文件以进行符号解析。
2.4.3 Last Branch Record (LBR)
最后分支记录是Intel处理器的一种功能,用于在硬件缓冲区中记录分支,包括函数调用分支。这种技术没有额外开销,可以用来重构堆栈跟踪。然而,它的深度受处理器的限制,可能仅支持记录4到32个分支。生产软件,特别是Java,的堆栈跟踪可能超过32个帧。
目前,BPF不支持最后分支记录,但将来可能会支持。有限的堆栈跟踪总比没有堆栈跟踪要好!
2.4.4 ORC
一个新的调试信息格式被设计用于堆栈跟踪,称为Oops Rewind Capability(ORC),其处理器负荷比DWARF低 [36]。ORC使用. orc_unwind 和 .orc_unwind_ip ELF节,目前已在Linux内核中实现。在寄存器有限的架构上,可能希望在编译内核时不使用帧指针,而是使用ORC进行堆栈跟踪。
ORC堆栈展开通过perf_callchain_kernel()函数在内核中实现,BPF可以调用该函数。这意味着BPF也支持ORC堆栈跟踪。目前尚未为用户空间开发ORC堆栈。
2.4.5 Symbols
目前,堆栈跟踪在内核中被记录为一组地址,稍后由用户级程序转换为符号(例如函数名)。在采集和转换之间可能出现符号映射已更改的情况,导致转换无效或缺失。这在第12章第3.4节中有详细讨论。未来可能的工作包括在内核中添加符号转换的支持,以便内核可以立即收集和转换堆栈跟踪信息。
2.4.6 More Reading
堆栈跟踪和帧指针在第12章进一步讨论了C语言和Java,第18章则提供了总结概述。
2.5 Flame Graphs
火焰图经常在本书的后续章节中使用,因此本节总结了如何使用和阅读它们。
火焰图是堆栈跟踪的可视化形式,我在解决MySQL性能问题和比较两个数千页文本的CPU配置文件时发明了它们[Gregg 16]。除了CPU配置文件外,它们还可以用于可视化来自任何分析器或跟踪器记录的堆栈跟踪。本书后续部分将展示它们如何应用于BPF跟踪的CPU空闲事件、页面错误等。本节解释了这种可视化方法。
2.5.1 Stack Trace
堆栈跟踪,也称为堆栈回溯或调用链,是一系列函数的列表,显示代码的执行流程。例如,如果 func_a() 调用了 func_b(),而 func_b() 又调用了 func_c(),那么在这一点上的堆栈跟踪可能会写成:
func_c
func_b
func_a
堆栈的底部(func_a)是起始点,而它上面的行显示了代码的执行路径。换句话说,堆栈的顶部(func_c)是当前函数,向下移动显示其层级关系:父函数、祖父函数,依此类推。
2.5.2 Profiling Stack Traces
定时抽样堆栈跟踪可以收集成千上万个堆栈,每个堆栈可能有几十甚至几百行长。为了更方便地研究这么大量的数据,Linux 的 perf(1) 分析器将堆栈样本总结为调用树,并显示每条路径的百分比。而 BCC 的 profile(8) 工具则以另一种方式总结堆栈跟踪,显示每个唯一堆栈跟踪的计数。在第六章提供了 perf(1) 和 profile(8) 的真实世界示例。使用这两种工具,可以快速识别存在单一堆栈占用 CPU 时间大部分情况下的病态问题。然而,对于许多其他问题,包括小的性能退化,找出罪魁祸首可能需要研究数百页的分析器输出。火焰图的创建就是为了解决这个问题。
要理解火焰图,可以考虑这个CPU分析器输出的合成示例,显示堆栈跟踪的频率计数:
func_e
func_d
func_b
func_a
1
func_b
func_a
2
func_c
func_b
func_a
7
这个输出展示了一个堆栈跟踪,后跟一个计数,总共有10个样本。例如,代码路径 func_a() -> func_b() -> func_c() 被抽样了七次。这个代码路径显示 func_c() 在CPU上运行。而 func_a() -> func_b() 代码路径,其中 func_b() 在CPU上运行,被抽样了两次。还有一个以 func_e() 在CPU上运行结束的代码路径被抽样了一次。
2.5.3 Flame Graph
图2-7展示了先前分析的火焰图表示。

这个火焰图具有以下特性:
■ 每个框代表堆栈中的一个函数(称为“堆栈帧”)。
■ 纵轴显示堆栈深度(堆栈中帧的数量),从底部的根部到顶部的叶子部分排列。从底部向上看,可以理解代码的执行流程;从顶部向下看,可以确定函数的祖先关系。
■ 横轴跨越样本集合。需要注意的是,它不像大多数图表那样显示时间的流逝从左到右。左到右的排序实际上是对帧的字母排序,以最大化帧合并。结合纵轴对帧的排序,这意味着图表的原点是左下角(与大多数图表相同),代表0,a. x轴上的长度确实具有意义:框的宽度反映了其在分析中的出现频率。宽框的函数在分析中的存在比窄框的函数更为显著。
火焰图实际上是一种邻接图,采用倒置冰柱布局[Bostock 10],用于可视化一组堆栈跟踪的层次结构。
在图2-7中,出现频率最高的堆栈显示为中间最宽的“塔”,从 func_a() 到 func_c()。由于这是一个显示CPU样本的火焰图,我们可以描述顶部边缘为运行在CPU上的函数,正如图2-8所突出显示的那样。

图2-8显示,func_c() 直接在CPU上运行了70% 的时间,func_b() 在CPU上运行了20% 的时间,func_e() 在CPU上运行了10% 的时间。另外的函数,func_a() 和 func_d(),在CPU上没有直接采样过。
阅读火焰图时,首先寻找最宽的塔,并先理解它们。
对于包含数千个样本的大型分析,可能会有一些代码路径只被少数采样,它们显示出的塔非常窄,无法容纳函数名称。这实际上是一种好处:你的注意力自然会被吸引到那些带有可读函数名称的宽塔上,先看这些塔有助于你首先理解整体分析的大部分内容。
2.5.4 Flame Graph Features
我的原始火焰图实现支持以下章节描述的功能[37]。
颜色调色板
帧可以根据不同的方案进行着色。默认情况下,每个帧使用随机的暖色调,这有助于在视觉上区分相邻的塔。多年来,我添加了更多的颜色方案。我发现以下对火焰图最有用:
- 色调:色调表示代码类型。例如,红色可以表示本地用户级代码,橙色表示本地内核级代码,黄色表示C++代码,绿色表示解释函数,青色表示内联函数等,具体颜色取决于您使用的语言。洋红色用于突出搜索匹配项。一些开发人员已经定制了火焰图,以始终使用特定色调突出显示他们自己的代码。
- 饱和度:饱和度从函数名称中获取。它提供了一些颜色变化,有助于区分相邻的塔,同时保持函数名称的相同颜色,更容易比较多个火焰图。
- 背景颜色:背景颜色提供了火焰图类型的视觉提醒。例如,您可以使用黄色表示CPU火焰图,蓝色表示非CPU或I/O火焰图,绿色表示内存火焰图。
另一个有用的颜色方案是用于IPC(每周期指令)火焰图,其中使用从蓝到白到红的渐变为每个帧着色,以可视化IPC的额外维度。
鼠标悬停
原始火焰图软件创建带有嵌入式JavaScript的SVG文件,可以在浏览器中加载以进行交互功能。其中一个功能是,在鼠标悬停帧时,会显示信息行,显示该帧在配置文件中出现的百分比。
缩放
可以点击帧进行水平缩放[18]。这允许检查窄帧,放大以显示它们的函数名称。
搜索
搜索按钮或Ctrl-F允许输入搜索项,然后突出显示匹配该搜索项的帧。还显示累积百分比,指示包含该搜索项的堆栈跟踪有多少频繁出现。这使得计算特定代码区域在配置文件中的占比变得简单。例如,您可以搜索"tcp_"以显示有多少配置文件在内核TCP代码中。
2.5.5 Variations
Netflix正在开发一个更加互动的火焰图版本,使用d3技术 [38]。这个开源项目被应用在Netflix的FlameScope软件中 [39]。
一些火焰图实现默认翻转y轴顺序,创建了一个“icicle图”,根在顶部。这种反转确保了即使是比屏幕高度更高的火焰图,以及从顶部开始显示的火焰图,根和其直接函数仍然可见。我的原始火焰图软件支持这种反转,使用--inverted参数。我个人偏好将这种icicle布局保留给从叶到根的合并,这是另一种火焰图变体,先合并叶子,最后合并根。例如,在分析自旋锁时,这种方法非常有用。
火焰图与火焰图类似的火焰图表(flame charts)受到火焰图的启发 [Tikhonovsky 13],但x轴按时间顺序而不是字母顺序排序。火焰图表在Web浏览器分析工具中很受欢迎,用于检查JavaScript,因为它们适合理解单线程应用程序中基于时间的模式。一些性能分析工具同时支持火焰图和火焰图表。
差分火焰图显示两个配置文件之间的差异 [20]。
2.6 Event Sources
图2-9展示了可以进行仪器化的不同事件来源及其示例。该图还显示了BPF支持附加到这些事件的Linux内核版本。

以下各节将详细解释这些事件来源。
2.7 kprobes
kprobes提供了内核的动态仪器化功能,它是基于IBM团队在2000年开发的DProbes跟踪器而来。然而,DProbes并未合并到Linux内核中,而kprobes却成功合并了。kprobes首次出现在Linux 2.6.9中,该版本发布于2004年。
kprobes能为任何内核函数创建仪器化事件,还可以在函数内部仪器化指令。它可以在生产环境中实时运行,而无需重新启动系统或将内核运行在特殊模式下。这是一项令人惊叹的能力:它意味着我们可以为Linux中数以万计的内核函数之一创建新的自定义指标。
kprobes技术还有一个称为kretprobes的接口,用于在函数返回时以及记录返回值时进行仪器化。当kprobes和kretprobes同时为同一函数进行仪器化时,可以记录时间戳以计算函数的持续时间,这对性能分析来说是一个重要的指标。
2.7.1 How kprobes Work
使用kprobes仪器化内核指令的步骤如下 [40]:
A. 如果是kprobe:
1. kprobes会复制并保存目标地址的字节(足够多的字节以覆盖它们,替换为断点指令)。
2. 目标地址会被替换为断点指令:在x86_64架构下是int3。(如果可以进行kprobe优化,则指令为jmp。)
3. 当执行流程触发这个断点时,断点处理程序会检查断点是否是由kprobes安装的,如果是,则执行kprobe处理程序。
4. 然后执行原始指令,并且执行流程继续。
5. 当不再需要kprobe时,原始字节会被复制回目标地址,指令恢复到原始状态。
B. 如果是用于Ftrace已经仪器化的地址的kprobe(通常是函数入口),
可能会进行基于Ftrace的kprobe优化,步骤如下 [Hiramatsu 14]:
1. 将Ftrace kprobe处理程序注册为被跟踪函数的Ftrace操作。
2. 函数在其函数序言中执行内置调用(对于gcc 4.6+和x86,是__fentry__),该调用会调用到Ftrace。Ftrace调用kprobe处理程序,然后返回执行函数。
3. 当不再需要kprobe时,从Ftrace中移除Ftrace-kprobe处理程序。
C. 如果是kretprobe:
1. 为函数入口创建一个kprobe。
2. 当函数入口kprobe被触发时,保存返回地址,然后用替代(“跳板”)函数替换它:kretprobe_trampoline()。
3. 当函数最终调用返回(例如ret指令),CPU将控制传递给跳板函数,该函数执行kretprobe处理程序。
4. kretprobe处理程序通过返回保存的返回地址来结束。
5. 当不再需要kretprobe时,移除kprobe。
kprobe处理程序可能在禁止抢占或中断的情况下运行,具体取决于架构和其他因素。
修改内核指令文本实时可能听起来极具风险,但它已被设计为安全。这个设计包括一个黑名单,其中列出了kprobe不会仪器化的函数,包括kprobes本身,以避免递归陷阱条件。kprobes还使用安全技术来插入断点:在x86架构下使用本地的int3指令,或者在使用jmp指令时使用stop_machine()来确保其他核心不在修改过程中执行指令。实际应用中最大的风险是仪器化一个非常频繁的内核函数:如果发生这种情况,每次调用都会增加一点小的开销,累积起来可能会拖慢系统的速度。
由于安全原因,kprobes在某些ARM 64位系统上无法工作,因为不允许对内核文本部分进行修改。
2.7.2 kprobes Interfaces
原始的kprobes技术是通过编写定义了预处理程序和后处理程序的内核模块来实现的,这些程序用C语言编写,并通过调用kprobe API函数register_kprobe()进行注册。然后,可以加载内核模块,并通过调用printk()输出系统消息以发出自定义信息。完成后需要调用unregister_kprobe()来注销kprobe。
我没有看到有人直接使用这个接口,除了2010年Phrack的一篇文章《使用kprobes进行内核仪器化》,由一个名为ElfMaster22的研究人员撰写。这可能不是kprobes的失败,因为它最初是为Dprobes而设计的。现在,使用kprobes有三种接口:
- kprobe API:register_kprobe()等。
- 基于Ftrace的接口,通过/sys/kernel/debug/tracing/kprobe_events实现,可以通过向该文件写入配置字符串来启用和禁用kprobes。
- perf_event_open():perf(1)工具使用的接口,最近还被BPF跟踪所支持,Linux 4.17内核中添加了对perf_kprobe pmu的支持。
kprobes主要通过前端跟踪器使用,包括perf(1)、SystemTap以及BPF跟踪工具BCC和bpftrace。
原始的kprobes实现还有一个变体称为jprobes,专门设计用于跟踪内核函数入口。随着时间推移,我们意识到kprobes可以满足所有需求,jprobes接口变得不再必要。2018年,kprobe维护者Masami Hiramatsu从Linux中移除了jprobes接口。
2.7.3 BPF and kprobes
kprobes为BCC和bpftrace提供了内核动态仪器化功能,并被多种工具使用。其接口包括:
- BCC:attach_kprobe() 和 attach_kretprobe()
- bpftrace:kprobe 和 kretprobe 探针类型
BCC中的kprobe接口支持在函数开始时和函数加指令偏移量时进行仪器化,而bpftrace目前仅支持在函数开始时进行仪器化。这两种跟踪工具的kretprobe接口都用于仪器化函数的返回。
例如,来自BCC的一个示例是vfsstat(8)工具,用于仪器化关键的虚拟文件系统(VFS)接口调用,并打印每秒的汇总信息:

这些是attach_kprobe()函数。在"event="赋值之后可以看到内核函数。
例如,来自bpftrace的这个一行命令计算所有VFS函数调用的次数,通过匹配"vfs_*"实现:


这个输出显示,在跟踪过程中,vfs_unlink()函数被调用了两次,而vfs_read()函数被调用了5581次。
从任何内核函数中获取调用次数的能力是一种有用的功能,可以用于对内核子系统的工作负载特性进行表征。
2.7.4 kprobes Additional Reading
了解kprobes的更多资源:
- Linux内核源码中的 Documentation/kprobes.txt [42]
- Sudhanshu Goswami 的文章 "An Introduction to kprobes" [40]
- Prasanna Panchamukhi 的书籍 "Kernel Debugging with kprobes" [43]
2.8 uprobes
uprobes提供了用户级动态仪器化功能。该工作在多年前就开始了,最初使用了类似于kprobes接口的utrace接口。最终,这一技术发展成为uprobes,并在2012年7月发布的Linux 3.5内核中合并 [44]。
uprobes类似于kprobes,但针对用户空间进程。uprobes可以仪器化用户级函数的入口以及指令偏移量,而uretprobes则可以仪器化函数的返回。
uprobes也是基于文件的:当跟踪可执行文件中的函数时,所有使用该文件的进程都会被仪器化,包括将来启动的进程。这使得可以跟踪系统范围内的库调用。
2.8.1 How uprobes Work
uprobes与kprobes在其方法上类似:它在目标指令处插入一个快速断点,并将执行传递给一个uprobes处理程序。当不再需要uprobes时,目标指令会被返回到其原始状态。对于uretprobes,函数入口处使用uprobes进行仪器化,并且返回地址会被一个跳转函数(trampoline function)劫持,与kprobes类似。
您可以通过使用调试器来看到它的实际效果。例如,可以对bash(1) shell中的readline()函数进行反汇编操作:

请注意,第一条指令已经变成了int3断点(针对x86_64架构)。
为了对readline()函数进行仪器化,我使用了一个bpftrace的一行命令:

这个命令会统计在所有正在运行和未来启动的bash shell中调用readline()的次数,并在按下Ctrl-C后打印计数并退出。当bpftrace停止运行时,uprobes会被移除,原始指令也会被恢复。
2.8.2 Uprobes Interfaces
uprobes有两种接口:
- 基于Ftrace的接口,通过/sys/kernel/debug/tracing/uprobe_events:可以通过向该文件写入配置字符串来启用和禁用uprobes。
- 使用perf_event_open():这是perf(1)工具以及最近BPF跟踪所使用的方式,支持从Linux 4.17内核开始(使用perf_uprobe pmu)。
此外,还有一个register_uprobe_event()内核函数,类似于register_kprobe(),但它没有作为公共API公开。
2.8.3 BPF and uprobes
uprobes为BCC和bpftrace提供了用户级动态仪器化,并被许多工具使用。其接口包括:
- BCC:attach_uprobe() 和 attach_uretprobe()
- bpftrace:uprobe 和 uretprobe 探针类型
BCC中的uprobes接口支持对函数开头或任意地址进行仪器化,而bpftrace目前仅支持对函数开头进行仪器化。对于这两种跟踪器来说,uretprobes接口用于仪器化函数的返回过程。
例如,在BCC中,gethostlatency(8)工具通过解析器库调用getaddrinfo(3)、gethostbyname(3)等来仪器化主机解析调用(DNS)的过程。

这些是attach_uprobe()和attach_uretprobe()调用。用户级函数可以在“sym=”赋值后看到。
作为bpftrace的一个示例,以下这些一行命令列出并计算了从libc系统库中所有gethost函数的调用次数:
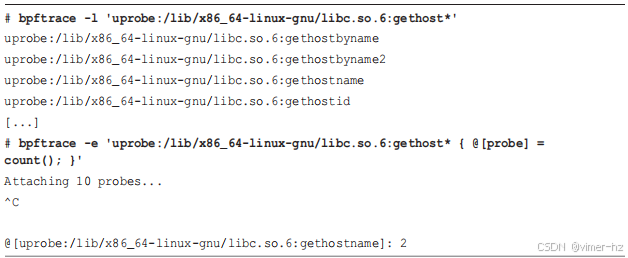
这个输出显示,在跟踪期间,gethostname()函数被调用了两次。
2.8.4 uprobes Overhead and Future Work
uprobes可以附加到每秒触发数百万次的事件,例如用户级分配例程:malloc()和free()。尽管BPF经过性能优化,但将微小的开销乘以每秒数百万次会累积起来。在某些情况下,malloc()和free()的跟踪,本应是BPF的首选用例,但可能会使目标应用程序的速度减慢十倍(10倍)甚至更多。这阻止了在这些情况下使用BPF;只有在测试环境中进行故障排除或在已经损坏的生产环境中才能接受这种速度变慢。第18章包括有关操作频率的部分,以帮助您解决这一限制。您需要了解哪些事件频繁发生,尽可能避免跟踪它们,并寻找较慢的事件来替代,以解决同样的问题。
未来用户空间跟踪可能会有很大改进——也许在您阅读此文时已经实现。正在讨论的不再使用当前的uprobes方法,该方法会陷入内核,而是采用共享库解决方案,可以提供不需要内核模式切换的用户空间BPF跟踪。多年来,LTTng-UST一直在使用这种方法,其性能测量结果显示速度提升了10倍到100倍。
2.8.5 uprobes Additional Reading
更多信息请参阅Linux内核源代码中的Documentation/trace/uprobetracer.txt文件【46】。
2.9 Tracepoints
跟踪点用于内核静态插装。它们涉及跟踪开发者在内核代码的逻辑位置插入的调用,并将这些调用编译到内核二进制文件中。由Mathieu Desnoyers于2007年开发,跟踪点最初被称为内核标记,并在2009年的Linux 2.6.32版本中提供。表2-7比较了kprobes和跟踪点。

跟踪点对内核开发者来说是一项维护负担,其作用范围远不及kprobes广泛。其优势在于,跟踪点提供了一个稳定的API:使用跟踪点编写的工具应该能够跨更高版本的内核继续工作,而使用kprobes编写的工具可能会因为被跟踪的函数被重命名或修改而失效。
如果有跟踪点可用且足够,您应该始终首选使用跟踪点,只有在需要时才考虑使用kprobes作为备选方案。
跟踪点的格式是 subsystem:eventname(例如,kmem:kmalloc)【47】。跟踪器使用不同术语来指代第一个组件:作为系统、子系统、类别或提供者。
2.9.1 Adding Tracepoint Instrumentation
作为一个跟踪点的示例,本节解释了如何将 sched:sched_process_exec 添加到内核中。
在 include/trace/events 目录中有用于跟踪点的头文件。以下是来自 sched.h 文件的内容:


这段代码将跟踪系统定义为 sched,并将跟踪点名称定义为 sched_process_exec。接下来的几行定义了元数据,包括在 TP_printk() 中的“格式字符串” —— 这是在使用 perf(1) 工具记录跟踪点时包含的一个有用的摘要。
前述信息在运行时也可以通过 Ftrace 框架在 /sys 下的格式文件获取,针对每个跟踪点都有相应的文件。例如:

这些格式文件由跟踪器处理,以理解与跟踪点相关联的元数据。
下面的跟踪点是通过内核源码中的 fs/exec.c 调用的,通过 trace_sched_process_exec():

trace_sched_process_exec() 函数标记了跟踪点的位置。
2.9.2 How Tracepoints Work
重要的是,未启用的跟踪点的开销应尽可能小,以避免因未使用的功能而付出性能代价。Mathieu Desnoyers 通过使用一种称为“静态跳转修补”的技术来实现这一点。这项技术如下运作,前提是编译器支持必要的特性(asm goto):
1. 在内核编译时,会在跟踪点位置添加一个不执行任何操作的指令。实际使用的指令取决于架构:对于 x86_64,这是一个5字节的无操作(nop)指令。此大小用于稍后替换为5字节的跳转(jmp)指令。
2. 也会在函数末尾添加一个跟踪点处理程序(trampoline),该处理程序会遍历注册的跟踪点探针回调函数数组。这会稍微增加指令文本大小(作为一个跳板,它是一个小型例程,所以执行会进入然后立即退出),这可能对指令缓存产生小的影响。
3. 在运行时,当跟踪器启用跟踪点时(它可能已经被其他运行中的跟踪器使用):
a. 跟踪点回调函数数组会被修改,为跟踪器添加一个新的回调函数,通过RCU进行同步。
b. 如果之前未启用跟踪点,则将 nop 的位置重写为跳转到跟踪点跳板的指令。
4. 当跟踪器禁用跟踪点时:
a. 跟踪点回调函数数组会被修改,移除回调函数,通过RCU进行同步。
b. 如果最后一个回调函数被移除,则将静态跳转指令重新写回 nop。
这样可以将未启用的跟踪点的开销最小化,使其几乎可以忽略不计。如果不支持 asm goto,则会使用回退技术:而不是将 nop 替换为 jmp,会基于从内存读取的变量使用条件分支。
2.9.3 Tracepoint Interfaces
有两种用于跟踪点的接口:
■ 基于 Ftrace,通过 /sys/kernel/debug/tracing/events:其中每个跟踪点系统都有子目录,并且每个跟踪点本身都有文件(通过向这些文件写入来启用和禁用跟踪点)。
■ perf_event_open():由 perf 工具使用,并且最近也被 BPF 跟踪所采用(通过 perf_tracepoint pmu)。
2.9.4 Tracepoints and BPF
跟踪点为 BCC 和 bpftrace 提供了内核静态工具。接口如下:
■ BCC:TRACEPOINT_PROBE()
■ bpftrace:tracepoint probe 类型
BPF 在 Linux 4.7 中支持了 tracepoints,但在此之前,我开发了许多依赖 kprobes 的 BCC 工具。这意味着在 BCC 中的 tracepoint 示例比我希望的要少,仅仅是支持开发的顺序导致了这种情况。
BCC 和 tracepoints 的一个有趣例子是 tcplife(8) 工具。它以一行摘要形式打印 TCP 会话的各种详细信息(在第10章中详细介绍)。


在 Linux 内核中适当的跟踪点出现之前,我编写了这个工具,因此我使用了 tcp_set_state() 内核函数上的 kprobe。在 Linux 4.16 中增加了一个合适的跟踪点:sock:inet_sock_set_state。我修改了工具以支持两者,这样它可以在较旧和较新的内核上运行。该工具定义了两个程序——一个用于跟踪点,一个用于 kprobes——然后通过以下测试选择要运行的程序:

作为 bpftrace 和 tracepoints 的示例,以下这行命令对之前显示的 sched:sched_process_exec 跟踪点进行了仪器化:

这个 bpftrace 命令一行打印出调用 exec() 的进程名称。
2.9.5 BPF Raw Tracepoints
Alexei Starovoitov在2018年为跟踪点开发了一个名为BPF_RAW_TRACEPOINT的新接口,该接口在Linux 4.17中加入。它避免了创建稳定跟踪点参数的成本(这些参数可能并非总是需要的),并且将原始参数暴露给跟踪点。在某种程度上,这类似于像使用kprobes那样访问跟踪点:虽然API不稳定,但可以访问更多字段,并且不需要支付常规跟踪点的性能开销。相比使用kprobes,它也更为稳定,因为跟踪点探针名称是稳定的,只有参数可能不稳定。
Alexei展示了在压力测试中,BPF_RAW_TRACEPOINT的性能优于kprobes和标准跟踪点的结果 [48]:

对于那些全天候仪器化跟踪点的技术来说,这可能尤其有趣,以最小化启用跟踪点的开销。
2.9.6 Additional Reading
更多信息,请查看内核源代码中的 Documentation/trace/tracepoints.rst,由Mathieu Desnoyers编写 [47]。
2.10 USDT
用户级静态定义跟踪(USDT)提供了用户空间版本的跟踪点。Sasha Goldshtein为BCC实现了USDT,我和Matheus Marchini为bpftrace实现了USDT。
对于用户级软件来说,有许多跟踪或日志记录技术,许多应用程序都带有自己的定制事件记录器,可以在需要时启用。USDT的不同之处在于它依赖于外部系统跟踪器来激活。如果没有外部跟踪器,应用程序中的USDT点无法使用,也不会执行任何操作。
USDT由Sun Microsystems的DTrace实用程序广为人知,现在已经在许多应用程序中可用。Linux开发了一种利用USDT的方式,这源自SystemTap跟踪器。BCC和bpftrace跟踪工具利用了这项工作,两者都可以对USDT事件进行仪器化。
仍然存在来自DTrace的一个遗留问题:许多应用程序默认不编译USDT探针,而是需要像 --enable-dtrace-probes 或 --with-dtrace 这样的配置选项。
2.10.1 Adding USDT Instrumentation
USDT探针可以通过使用systemtap-sdt-dev包中的头文件和工具,或者使用自定义头文件添加到应用程序中。这些探针定义了可以放置在代码中逻辑位置的宏,以创建USDT仪器化点。BCC项目包含一个名为examples/usdt_sample的USDT代码示例,可以使用systemtap-sdt-dev头文件或来自Facebook的Folly C++库[11]的头文件进行编译。在接下来的部分,我将介绍使用Folly的示例。
Folly
使用Folly添加USDT仪器化的步骤如下:
1. 将头文件添加到目标源代码中:
#include "folly/tracing/StaticTracepoint.h"
2. 在目标位置添加USDT探针,格式为:
FOLLY_SDT(provider, name, arg1, arg2, ...)
其中,"provider"用于分组探针,"name"是探针的名称,后跟可选的参数。BCC的USDT示例包含以下内容:
FOLLY_SDT(usdt_sample_lib1, operation_start, operationId, request.input().c_str());
这定义了一个名为usdt_sample_lib1:operation_start的探针,并提供了两个参数。USDT示例还包含一个operation_end探针。
3. 构建软件。您可以使用readelf(1)来检查USDT探针是否存在:

使用readelf(1)的-n选项打印注释部分,这部分应显示有关已编译USDT探针的信息。
4. 可选步骤:有时您想要添加到探针的参数在探针位置不容易获取,并且必须使用耗费CPU资源的函数调用进行构造。为了避免在探针不使用时频繁进行这些调用,您可以在函数之外的源文件中添加一个探针信号量:
FOLLY_SDT_DEFINE_SEMAPHORE(provider, name)
然后,探针点可以变为:

现在,昂贵的参数处理仅在探针被使用(启用)时发生。信号量的地址将在readelf(1)中可见,跟踪工具在使用探针时可以设置它。这确实使得跟踪工具复杂化了一些:当受信号量保护的探针被使用时,这些跟踪工具通常需要指定一个PID,以便为该PID设置信号量。
2.10.2 How USDT Works
在应用程序编译时,会在USDT探针的地址处放置一个空操作(nop)指令。然后,内核在仪器化时会动态地将该地址更改为一个断点,使用uprobes技术。
与uprobes类似,我可以展示USDT的运行情况,尽管这需要做更多工作。从前面的readelf(1)输出中可以看到探针的位置是0x6a2。这是相对于二进制段的偏移量,因此您首先需要了解二进制段的起始位置。由于位置无关可执行文件(PIE)的存在,这个起始位置可能会有所不同,PIE使得地址空间布局随机化(ASLR)更加有效。
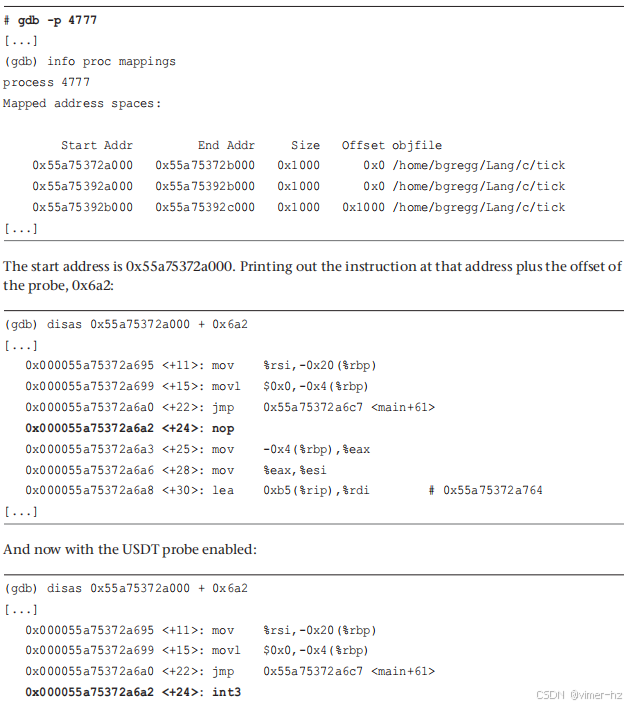

nop指令已经改变成int3(x86_64的断点指令)。当这个断点被触发时,内核会执行附加的BPF程序,并传递给USDT探针的参数。当USDT探针被停用时,nop指令会被恢复。
2.10.3 BPF and USDT
USDT为BCC和bpftrace提供了用户级静态插装。其接口包括:
- BCC: USDT().enable_probe()
- bpftrace: usdt探针类型
例如,对前面例子中的循环探针进行仪器化:

这个bpftrace的一行命令还打印出了传递给探针的整数参数。
2.10.4 USDT Additional Reading
理解USDT的更多资源包括:
- Brendan Gregg 的《Hacking Linux USDT with Ftrace》 [49]
- Sasha Goldshtein 的《USDT Probe Support in BPF/BCC》 [50]
- Dale Hamel 的《USDT Tracing Report》 [51]
2.11 Dynamic USDT
之前描述的USDT探针是添加到源代码中并编译到生成的二进制文件中的,在插装点留下nop指令,并在ELF注释部分中留下元数据。然而,一些语言如Java在JVM上是解释执行或即时编译的。动态USDT可用于在Java代码中添加插装点。
需要注意的是,JVM已经在其C++代码中包含了许多USDT探针,用于GC事件、类加载和其他高级活动。这些USDT探针正在对JVM的函数进行插装。但是,对于即时编译的Java代码,无法添加USDT探针。USDT需要一个包含探针描述的预编译ELF文件的notes部分,而对于JIT编译的Java代码这种文件是不存在的。
动态USDT通过以下方式解决了这个问题:
- 预先编译一个带有所需USDT探针嵌入函数中的共享库。这个共享库可以是C或C++编写的,并且具有用于USDT探针的ELF notes部分。它可以像任何其他USDT探针一样进行插装。
- 在需要时使用 `dlopen(3)` 加载共享库。
- 从目标语言添加共享库调用。可以使用适合该语言的API来实现这些调用,隐藏底层的共享库调用。
Matheus Marchini 在一个名为 libstapsdt 的库中实现了Node.js和Python的动态USDT支持,该库提供了在这些语言中定义和调用USDT探针的方法。通常可以通过包装这个库来为其他语言添加支持,比如 Dale Hamel 为Ruby所做的那样,利用了Ruby的C扩展支持 [54]。
例如,在Node.js中的JavaScript中:

probe1.fire()调用仅在探针被外部插装时执行其匿名函数。在这个函数内部,可以处理参数(如果有必要),然后将它们传递给探针,而不必担心这种参数处理会带来非启用状态下的CPU成本,因为如果探针未使用,这部分过程会被跳过。
libstapsdt会在运行时自动创建一个包含USDT探针和ELF notes部分的共享库,并将该部分映射到运行程序的地址空间中。
2.12 PMCs
性能监控计数器(PMC)也被称为性能仪器计数器(PIC)、CPU性能计数器(CPC)和性能监控单元事件(PMU事件)。这些术语都指的是处理器上可编程的硬件计数器。
尽管有许多种类的PMC,Intel选取了七个PMC作为“架构集”,提供了一些核心功能的高级概述[Intel 16]。这些架构集PMC的存在可以通过CPUID指令来检查。表2-8展示了这个集合,作为有用PMC的示例。

PMC(性能监控计数器)是性能分析中至关重要的资源。只有通过PMC,你才能测量CPU指令的效率、CPU缓存的命中率、内存、互连和设备总线的利用率、停顿周期等。利用这些测量数据来分析性能可以带来各种小型性能优化。
PMCs也是一种特殊的资源。虽然有数百种不同的PMC可用,但在CPU中同时只有固定数量的寄存器(可能只有六个)可用于同时测量它们。你需要选择在这六个寄存器上想要测量的PMC,或者通过循环使用不同的PMC集合来对它们进行采样(Linux的perf(1)支持这种自动循环)。其他软件计数器不受这些限制的影响。
2.12.1 PMC Modes
PMCs可以在两种模式下使用:
- 计数模式:在这种模式下,PMCs跟踪事件发生的速率。内核可以在需要时读取计数,例如获取每秒的度量指标。这种模式的开销几乎为零。
- 溢出采样模式:在这种模式下,PMCs可以向内核发送中断,用于监控的事件,以便内核可以收集额外的状态信息。被监视的事件可以每秒发生数百万次甚至数十亿次;如果每次事件都发送一个中断,系统几乎会停滞。解决方案是通过使用可编程计数器来对事件进行采样,当计数器溢出时(例如每10,000次LLC缓存未命中或每1百万个停顿周期),计数器向内核发出信号。
采样模式对于BPF跟踪特别有趣,因为它生成可以通过自定义BPF程序进行仪器化的事件。BCC和bpftrace都支持PMC事件。
2.12.2 PEBS
溢出采样可能由于中断延迟(通常称为“滑差”)或乱序指令执行而未记录触发事件的正确指令指针。对于CPU周期分析来说,这种滑差可能并不是问题,一些性能分析工具故意引入抖动以避免锁步采样(或使用偏移采样率,如99赫兹)。但对于测量其他事件,如LLC未命中,采样的指令指针需要是准确的。
英特尔开发了一种称为精确事件基础采样(PEBS)的解决方案。PEBS利用硬件缓冲区在PMC事件发生时记录正确的指令指针。Linux的perf_events框架支持使用PEBS。
2.12.3 Cloud Computing
许多云计算环境尚未向其虚拟机客户提供PMC(性能监控计数器)的访问权限。从技术上讲,可以启用这一功能;例如,Xen虚拟化管理程序具有vpmu命令行选项,允许向客户机公开不同的PMC集合[55]。亚马逊已经为其Nitro虚拟化管理程序的客户启用了许多PMC。
2.13 perf_events
perf_events设施用于perf(1)命令进行采样和跟踪,它于2009年添加到Linux 2.6.21中。值得注意的是,多年来perf(1)和其perf_events设施受到了广泛关注和开发,BPF跟踪器可以调用perf_events来利用其功能。BCC和bpftrace最初使用perf_events进行环形缓冲区,然后进行PMC仪器化,现在通过perf_event_open()进行所有事件仪器化。
虽然BPF跟踪工具利用了perf(1)的内部机制,但也开发并添加了一个面向BPF的接口到perf(1)中,使perf(1)成为另一个BPF跟踪器。与BCC和bpftrace不同,perf(1)的源代码位于Linux树中,因此perf(1)是唯一内置于Linux中的BPF前端跟踪器。
perf(1)的BPF仍在开发中且使用起来较为复杂。详细介绍超出了本章节的范围,本章节主要关注BCC和bpftrace工具。perf BPF的示例包含在附录D中。
2.14 Summary
BPF性能工具利用了多种技术,包括扩展BPF、内核和用户动态仪器化(kprobes和uprobes)、内核和用户静态跟踪(tracepoints和用户标记),以及perf_events。BPF还可以通过基于帧指针的遍历或ORC获取堆栈跟踪,这些可以以火焰图的形式进行可视化。本章节涵盖了这些技术,并提供了进一步阅读的参考资料。
3 Performance Analysis
本书中的工具可以用于性能分析、故障排除、安全分析等多种用途。为了帮助您理解如何应用它们,本章提供了性能分析的快速入门课程。
学习目标:
- 理解性能分析的目标和活动
- 进行工作负载特性分析
- 使用USE方法进行分析
- 进行深入分析
- 理解检查清单方法论
- 使用传统工具和Linux 60秒检查清单找到快速性能优化
- 使用BCC/BPF工具检查清单找到快速性能优化
本章首先描述了性能分析的目标和活动,然后总结了传统(非BPF)工具的方法论,可以首先尝试使用这些传统工具来直接找到快速的性能优化点,或者提供后续基于BPF的分析的线索和背景信息。章末包括了一个BPF工具的检查清单,后续章节将介绍更多的BPF工具。
3.1 Overview
在深入进行性能分析之前,思考一下你的目标以及可以帮助你实现这些目标的不同活动,这可能会有所帮助。
3.1.1 Goals
总体而言,性能分析的目标是提升终端用户性能并降低运营成本。将性能目标明确化为可测量的指标是有帮助的;这样的测量可以显示何时达到了性能目标,或者量化了不足之处。这些测量包括:
- 延迟:完成请求或操作所需的时间,通常以毫秒计量
- 比率:每秒的操作或请求率
- 吞吐量:通常以每秒传输的数据量(比特或字节)计量
- 利用率:资源在一段时间内的繁忙程度,以百分比表示
- 成本:性能与价格之比
终端用户性能可以量化为应用程序响应用户请求所需的时间,目标是缩短这个时间。这段等待时间通常称为延迟。通过分析请求时间并将其分解为组成部分,如运行在CPU上的时间及其代码、等待磁盘、网络和锁资源的时间、等待CPU调度器的时间等,可以改善延迟。可以编写一个BPF工具,直接跟踪应用程序请求时间及来自多个不同组件的延迟。这样的工具将是特定于应用程序的,并可能在同时跟踪多个不同事件时产生显著的开销。实际上,通常会使用较小的具体工具来研究特定组件的时间和延迟。本书包括许多这样的较小和具体的工具。
降低运营成本可以涉及观察软件和硬件资源的使用方式,并寻找优化方法,目标是减少公司在云或数据中心的支出。这可能涉及不同类型的分析,例如总结或记录组件的使用方式,而不是其响应的时间或延迟。本书中的许多工具也支持这一目标。
在进行性能分析时,请牢记这些目标。使用BPF工具很容易生成大量数据,并花费数小时来理解一个后来证明并不重要的度量指标。作为性能工程师,我经常收到开发人员发送的工具输出截图,他们担心一个表现看起来很糟糕的度量。我的第一个问题通常是:“您是否遇到了已知的性能问题?” 他们的答案往往是:“没有,我们只是觉得这个输出看起来...有趣。” 这可能确实很有趣,但我首先需要确定目标:我们是在试图减少请求延迟,还是运营成本?目标为进一步的分析设定了上下文。
3.1.2 Activities
BPF性能工具不仅可以用于分析特定问题,还可以用于以下性能活动[Gregg 13b],请考虑以下列表,并思考BPF性能工具如何在每个活动中发挥作用:

显而易见的是,本书中的许多工具适合研究特定的性能问题,但也要考虑它们如何改善监控、非回归测试以及其他活动。
3.1.3 Mulitple Performance Issues
在使用本书描述的工具时,请准备好发现多个性能问题。问题在于确定哪个问题最为重要:通常是对请求延迟或成本影响最大的那个问题。如果你并没有预期发现多个性能问题,请尝试查找你的应用程序、数据库、文件系统或软件组件的bug跟踪器,并搜索关键词“performance”。通常会存在多个未解决的性能问题,以及一些尚未列在跟踪器中的问题。关键在于找出哪些问题最为重要。
任何一个问题可能有多个根本原因。很多时候,当你修复了一个原因时,其他原因会变得显而易见。或者,当你解决了一个原因时,另一个组件就成了瓶颈。
3.2 Performance Methodologies
有了如此多的性能工具和功能可用(例如,kprobes、uprobes、tracepoints、USDT、PMCs;请参阅第2章),如何处理它们提供的所有数据可能会很困难。多年来,我一直在研究、创建和记录性能方法论。方法论是一种你可以遵循的过程,提供了起点、步骤和终点。我的先前著作《系统性能》记录了几十种性能方法论[Gregg 13b]。我在这里将总结其中一些,您可以使用BPF工具进行跟随。
3.2.1 Workload Characterization
工作负载特征化的目的是了解应用负载。您无需分析导致的性能问题,比如延迟。我发现最大的性能改进往往是“消除不必要的工作”。通过研究工作负载的组成部分可以找到这样的改进。
执行工作负载特征化的建议步骤如下:
1. 谁引起了负载(例如,PID、进程名称、UID、IP地址)?
2. 为什么负载被调用(代码路径、堆栈跟踪、火焰图)?
3. 负载是什么(IOPS、吞吐量、类型)?
4. 负载随时间如何变化(每个间隔的摘要信息)?
本书中的许多工具可以帮助您回答这些问题。例如,vfsstat(8):

这显示了应用在虚拟文件系统(VFS)层级上的工作负载的详细信息,并通过提供类型和操作速率回答了步骤3,并通过随时间提供每个间隔的摘要来回答步骤4。
作为步骤1的简单示例,我将转向bpftrace并使用一个单行命令(输出已截断):

这显示,在我跟踪时,名为“Web Content”的进程执行了1725次vfs_read()操作。
本书中有更多通过这些步骤的工具示例,包括稍后章节中的火焰图,可以用于第2步。
如果您分析的目标没有现成的工具可用,您可以创建自己的工作负载特征化工具来回答这些问题。
3.2.2 Drill-Down Analysis
钻取分析涉及检查一个指标,然后找到将其分解成组成部分的方法,接着将最大的组成部分进一步分解成其自身的组成部分,依此类推,直到找到一个或多个根本原因。
打个比方来解释一下。想象一下,你发现信用卡账单异常高。为了分析,你登录银行查看交易记录。在那里,你发现有一笔大额支付给一个在线书店。然后你登录到那家书店,查看是哪些书导致了这笔支出,结果发现你意外地购买了1000本这本书(谢谢您!)。这就是钻取分析:找到一个线索,然后深入挖掘,根据更多的线索进行进一步分析,直到解决问题。
钻取分析的建议步骤如下:
1. 从最高层级开始检查。
2. 检查下一级的详细信息。
3. 选择最有趣的分解或线索。
4. 如果问题未解决,回到步骤2。
钻取分析可能涉及定制工具,这些工具在使用bpftrace比使用BCC更为合适。
钻取分析的一种类型涉及将延迟分解为其构成部分。想象一下以下的分析序列:
1. 请求的延迟是100毫秒(ms)。
2. 其中10毫秒在CPU上运行,90毫秒在CPU之外阻塞。
3. 在CPU之外的时间中,有89毫秒是在文件系统上阻塞。
4. 文件系统在锁定上阻塞了3毫秒,并在存储设备上阻塞了86毫秒。
在这里,你的结论可能是存储设备存在问题,这是一个答案。但钻取分析也可以用来更精确地理解背景情况。考虑以下的替代序列:
1. 应用程序在文件系统上阻塞了89毫秒。
2. 文件系统在文件系统写入上阻塞了78毫秒,并在读取上阻塞了11毫秒。
3. 文件系统写入在访问时间戳更新上阻塞了77毫秒。
现在你的结论是文件系统访问时间戳是延迟的根源,可以通过禁用它们(这是一种挂载选项)来解决问题。这比得出需要更快的磁盘的结论要好得多。
3.2.3 USE Method
我开发了资源分析的USE方法论[Gregg 13c]。
针对每一种资源,检查以下内容:
1. 利用率(Utilization)
2. 饱和度(Saturation)
3. 错误(Errors)
你的第一个任务是找到或绘制软件和硬件资源的图表。然后,你可以迭代地对它们进行检查,寻找这三个指标。图3-1展示了一个通用系统的硬件目标示例,包括可以检查的组件和总线。

考虑你当前的监控工具及其显示图3-1中每一项的利用率、饱和度和错误的能力。你目前有多少盲点?
这种方法的优势在于它从重要的问题开始,而不是从以指标形式回答问题,然后试图逆向推导为何这些指标重要。它还能够揭示盲点:它从你想要回答的问题开始,无论是否存在便捷的工具来衡量这些问题。
3.2.4 Checklists
性能分析的检查清单可以列出工具和指标供运行和检查。它们可以集中在低 hanging fruit 上:识别一些十分常见的问题,提供每个人都能遵循的分析指导。这些适合广泛的公司员工执行,可以帮助你扩展技能。
接下来的部分将介绍两个检查清单:一个使用传统(非BPF)工具进行快速分析(第一分钟内),另一个是早期尝试的BCC工具清单。
3.3 Linux 60-Second Analysis
这份清单可以用于任何性能问题,并反映了我在登录到性能不佳的Linux系统后的头60秒内通常执行的操作。这是由我和Netflix性能工程团队共同发布的[56]:
需要运行的工具包括:
1. uptime
2. dmesg | tail
3. vmstat 1
4. mpstat -P ALL 1
5. pidstat 1
6. iostat -xz 1
7. free -m
8. sar -n DEV 1
9. sar -n TCP,ETCP 1
10. top
接下来的部分将解释每个工具的用途。在BPF书籍中讨论非BPF工具可能显得有些不合时宜,但如果不这样做,就会错过一个已经存在的重要资源。这些命令可能会直接帮助你解决一些性能问题。如果不能,它们可能会揭示性能问题的线索,指导你如何使用后续的BPF工具来找到真正的问题所在。
3.3.1 uptime

这是查看负载平均值的快速方式,它指示了想要运行的任务(进程)数量。在Linux系统中,这些数字包括希望在CPU上运行的进程,以及在不可中断I/O(通常是磁盘I/O)中被阻塞的进程。这提供了资源负载(或需求)的高级概念,可以进一步使用其他工具进行深入探索。
这三个数字是指数阻尼移动平均值,分别以1分钟、5分钟和15分钟为常数。这三个数字让你了解负载随时间的变化情况。在上面的示例中,负载平均值显示最近有轻微增加。在首次响应问题时,检查负载平均值是否仍然存在是值得的。
3.3.2 dmesg | tail

这显示了最近的10条系统消息(如果有)。查找可能导致性能问题的错误。上面的示例包括内存不足杀手(out-of-memory killer)和TCP丢弃请求的消息。TCP消息甚至指向下一个分析领域:SNMP计数器。
3.3.3 vmstat 1

这是源自BSD的虚拟内存统计工具,同时显示其他系统指标。当使用参数1调用时,它会打印每秒的摘要;注意,第一行数字是自系统启动以来的总结(除了内存计数器)。
需要检查的列包括:
- **r**: 在CPU上运行并等待轮换的进程数。这比负载平均值更好地指示CPU饱和情况,因为它不包括I/O。解释方式是,如果“r”值大于CPU核心数,则表示饱和。
- **free**: 空闲内存,以KB为单位。如果有太多数字难以计算,可能有足够的空闲内存。命令`free -m`可以更好地解释空闲内存的状态。
- **si** 和 **so**: 交换进和交换出。如果这些值不为零,表示内存不足。只有在配置了交换设备时才会使用这些。
- **us, sy, id, wa, st**: 这些是CPU时间的细分,平均分布在所有CPU上。它们分别是用户时间、系统时间(内核)、空闲时间、等待I/O时间和被偷取的时间(被其他虚拟机(guests)占用,或者在Xen中是被客户机自己的隔离驱动域占用)。
示例显示CPU时间大部分处于用户模式。这应该引导您下一步分析正在运行的用户级代码,可以使用性能分析工具。
3.3.4 mpstat -P ALL 1

这个命令打印每个CPU的时间分解状态。输出显示了一个问题:CPU 0 的用户时间达到了100%,表明存在单线程瓶颈。
另外要注意高% iowait时间,可以用磁盘I/O工具来探索,以及高% sys时间,可以用系统调用和内核跟踪,以及CPU性能分析工具来探索。
3.3.5 pidstat 1


pidstat(1)显示每个进程的CPU使用情况。top(1)是一个常用的用于此目的的工具;然而,pidstat(1)默认提供滚动输出,因此可以看到随时间变化的情况。这个输出显示一个Java进程每秒消耗不同数量的CPU;这些百分比是在所有CPU上求和的,因此500%相当于五个CPU每个都在100%利用。
3.3.6 iostat -xz 1

这个工具显示存储设备的I/O指标。输出中每个磁盘设备的列在此处被换行,使阅读变得困难。
需要检查的列包括:
- **r/s, w/s, rkB/s, wkB/s**: 这些是每秒向设备传递的读取次数、写入次数、读取的KB数和写入的KB数。用于工作负载的表征。性能问题可能仅仅是由于施加了过多的负载。
- **await**: I/O的平均时间,以毫秒计。这是应用程序遭受的时间,因为它包括排队时间和正在服务的时间。比预期的平均时间长可能表明设备饱和或设备问题的指示。
- **avgqu-sz**: 发送到设备的平均请求数。大于1的值可能表明饱和(尽管设备,特别是前端多个后端磁盘的虚拟设备通常并行处理请求)。
- **%util**: 设备利用率。这实际上是忙碌百分比,显示设备每秒执行工作的时间。它不显示容量规划意义上的利用率,因为设备可以并行处理请求。大于60%的值通常会导致性能不佳(应该在await列中看到),尽管这取决于设备。接近100%的值通常表明设备饱和。
输出显示对md0虚拟设备的写入工作负载约为每秒约300兆字节,看起来支持了nvme0设备的两者。
3.3.7 free -m

这显示了以兆字节为单位的可用内存。请检查可用值不接近零;它显示系统中实际可用的内存量,包括缓冲区和页面缓存中的内存。
在缓存中保留一些内存可以提升文件系统的性能。
3.3.8 sar -n DEV 1


sar(1)工具有多种模式用于不同组的指标。在这里,我使用它来查看网络设备的指标。检查接口吞吐量 rxkB/s 和 txkB/s,看是否已达到任何限制。
3.3.9 sar -n TCP,ETCP 1

现在我们正在使用sar(1)来查看TCP指标和TCP错误。需要检查的列包括:
- active/s:每秒本地发起的TCP连接数(例如,通过connect())
- passive/s:每秒远程发起的TCP连接数(例如,通过accept())
- retrans/s:每秒的TCP重传次数
活动和被动连接计数对于工作负载的特征化非常有用。重传表示可能存在网络或远程主机的问题。
3.3.10 top


到这一步,你已经通过之前的工具看到了许多这些指标,但通过使用top(1)实用程序并浏览系统和进程摘要进行最后的双重检查可能会很有帮助。
幸运的话,这60秒的分析将帮助你发现关于系统性能的一两个线索。你可以利用这些线索跳转到一些相关的BPF工具进行进一步分析。
3.4 BCC Tool Checklist
这个清单是BCC存储库中的一部分,位于docs/tutorial.md文件中,由我编写[30]。它提供了一个通用的BCC工具清单,可以逐个使用:
1. execsnoop
2. opensnoop
3. ext4slower(或者btrfs*、xfs*、zfs*)
4. biolatency
5. biosnoop
6. cachestat
7. tcpconnect
8. tcpaccept
9. tcpretrans
10. runqlat
11. profile
这些工具提供了关于新进程、打开的文件、文件系统延迟、磁盘I/O延迟、文件系统缓存性能、TCP连接和重传、调度器延迟以及CPU使用情况的更多信息。它们在后续章节中会有更详细的介绍。
3.4.1 execsnoop

execsnoop(8)通过每次execve(2)系统调用打印一行输出来显示新进程的执行情况。检查短暂存在的进程,因为这些进程可能消耗CPU资源,但可能不会出现在大多数定期拍摄运行进程快照的监控工具中。execsnoop(8)在第6章详细介绍了其功能。
3.4.2 opensnoop

opensnoop(8)为每个open(2)系统调用(及其变体)打印一行输出,包括被打开的路径及其是否成功("ERR"错误列)。打开的文件可以告诉您很多关于应用程序运行方式的信息:识别它们的数据文件、配置文件和日志文件。有时应用程序可能会因为不断尝试读取不存在的文件而表现不佳。opensnoop(8)在第8章中有更详细的介绍。
3.4.3 ext4slower

ext4slower(8)跟踪ext4文件系统的常见操作(读取、写入、打开和同步),并打印超过时间阈值的操作。这可以识别或证明一种性能问题:应用程序在通过文件系统等待缓慢的磁盘I/O。还有其他文件系统的类似工具,如btrfsslower(8)、xfsslower(8)和zfsslower(8)。详细内容请参阅第8章。
3.4.4 biolatency

biolatency(8)跟踪磁盘I/O延迟(即从设备发出到完成的时间),并将其显示为直方图。这比iostat(1)显示的平均值更能说明磁盘I/O的性能。可以检查多种模式。模式是分布中比其他值更频繁出现的值,例如,这个例子显示了一个多模态分布,一个模式在0到1毫秒之间,另一个模式集中在8到15毫秒范围内。也可以看到异常值:此截图显示了一个在512到1023毫秒范围内的异常值。biolatency(8)在第9章有更详细的介绍。
3.4.5 biosnoop
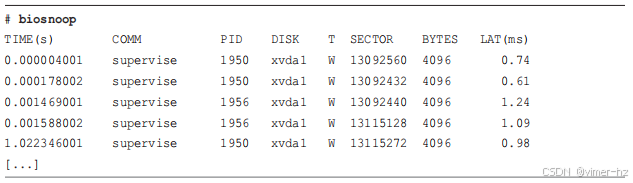
biosnoop(8)为每个磁盘I/O打印一行输出,包括延迟等详细信息。这使您能够更详细地检查磁盘I/O,并寻找时间顺序模式(例如,读取排队在写入后面)。biosnoop(8)在第9章有更详细的介绍。
3.4.6 cachestat

cachestat(8)每秒(或自定义间隔)打印一行摘要,显示来自文件系统缓存的统计信息。可以用它来识别低缓存命中率和高缺失率。这可能为性能调优提供线索。cachestat(8)在第8章有更详细的介绍。
3.4.7 tcpconnect

tcpconnect(8)为每个活动的TCP连接(例如,通过connect()建立的连接)打印一行输出,包括源地址和目标地址在内的详细信息。查找可能指向应用程序配置不足或入侵者的意外连接。tcpconnect(8)在第10章有更详细的介绍。
3.4.8 tcpaccept

tcpaccept(8)是tcpconnect(8)的配套工具。它为每个被动TCP连接(例如,通过accept()接受的连接)打印一行输出,包括源地址和目标地址在内的详细信息。tcpaccept(8)在第10章有更详细的介绍。
3.4.9 tcpretrans

tcpretrans(8)为每个TCP重传数据包打印一行输出,详细信息包括源地址、目标地址以及TCP连接的内核状态。TCP重传会导致延迟和吞吐量问题。对于状态为ESTABLISHED的重传,可以查找外部网络的问题。对于状态为SYN_SENT的重传,可能指向目标内核CPU饱和和内核数据包丢失的问题。tcpretrans(8)在第10章有更详细的介绍。
3.4.10 runqlat

runqlat(8)计算线程在等待CPU执行的时间,并将这些时间以直方图的形式打印出来。使用这个工具可以识别CPU访问等待时间超过预期的情况,线程可能因为CPU饱和、配置错误或调度程序问题而遭受影响。runqlat(8)在第6章有更详细的介绍。
3.4.11 profile

profile(8)是一个CPU分析器,你可以使用它来了解哪些代码路径正在消耗CPU资源。它在定时间隔内对堆栈跟踪进行采样,并打印出唯一堆栈跟踪的摘要及其出现次数计数。这里显示了截断的输出,只展示了一个堆栈跟踪,出现了58次。profile(8)在第6章有更详细的介绍。
3.5 Summary
性能分析旨在提高最终用户的性能并降低运营成本。有许多工具和指标可帮助您分析性能;事实上,这些工具如此之多,以至于在特定情况下选择合适的工具可能会让人感到不知所措。性能方法论可以指导您进行选择,指导您从何处开始、分析步骤以及结束位置。
本章总结了性能分析的方法论:工作负载特征化、延迟分析、USE方法和检查清单。接着介绍了Linux性能分析60秒检查清单,并解释了其用途,这可以作为解决任何性能问题的起点。它可能直接帮助您解决问题,或者至少提供线索,指示性能问题出现的位置,并使用BPF工具进行进一步分析。
此外,本章还包括了一个BPF工具检查清单,详细内容将在后续章节中进行解释。
4 BCC
BPF编译器集合(BCC,有时在项目和包名称后写成小写bcc)是一个开源项目,包含编译器框架和用于构建BPF软件的库。它是BPF的主要前端项目,由BPF开发人员支持,通常是首个使用最新内核追踪BPF增强功能的地方。BCC还包含超过70个现成的BPF性能分析和故障排除工具,本书中涵盖了其中许多工具。
BCC由Brenden Blanco于2015年4月创建。在Alexei Starovoitov的鼓励下,我于2015年加入了该项目,并成为性能工具、文档和测试的重要贡献者。现在有许多贡献者,BCC已经成为包括Netflix和Facebook在内的公司的默认服务器安装。
学习目标:
- 了解BCC的特性和组件,包括工具和文档
- 理解单一用途和多用途工具的好处
- 学习如何使用funccount(8)多工具进行事件计数
- 学习如何使用stackcount(8)多工具发现代码路径
- 学习如何使用trace(8)多工具进行每个事件的自定义打印
- 学习如何使用argdist(8)多工具进行分布摘要
- (可选)了解BCC内部结构
- 了解BCC调试技术
本章介绍了BCC及其特性;展示了如何安装BCC;提供了其工具、工具类型和文档的概述;最后,介绍了BCC的内部结构和调试。如果您希望开发自己的新工具,请务必学习本章和第5章(bpftrace),这样您就能选择最适合您需求的前端。附录C总结了使用示例开发BCC工具的过程。
4.1 BCC Components
BCC包含工具的文档、man页面和示例文件,以及使用BCC工具的教程,以及用于BCC工具开发的教程和参考指南。它提供了在Python、C++和lua(未显示)中开发BCC工具的接口;将来可能会添加更多接口。
该仓库地址为:
https://github.com/iovisor/bcc
在BCC仓库中,Python工具的文件扩展名为.py,但通过软件包安装BCC时通常会去掉这个扩展名。BCC工具和man页面的最终安装位置取决于您使用的软件包,因为不同的Linux发行版对其进行了不同的打包。工具可能安装在/usr/share/bcc/tools、/sbin或/snap/bin中,工具本身可能有前缀或后缀,以显示它们来自BCC集合。这些差异在第4.3节中有描述。
4.2 BCC Features
BCC是一个由来自各个公司的工程师创建和维护的开源项目。它不是商业产品。如果它是商业产品,就会有一个营销部门制作广告,吹嘘它的众多特性。
特性列表(如果准确)可以帮助您了解新技术的能力。在BPF和BCC的开发过程中,我创建了期望功能的列表[57]。随着这些功能的实现,它们已经成为已交付的功能列表,并分为内核级和用户级特性。这些特性在接下来的章节中描述。
4.2.1 Kernel-Level Features
BCC可以利用多种内核级特性,例如BPF、kprobes、uprobes等。以下列表包含一些实现细节(括号内):
- 动态插装,内核级(支持kprobes的BPF)
- 动态插装,用户级(支持uprobes的BPF)
- 静态跟踪,内核级(支持tracepoints的BPF)
- 定时采样事件(使用perf_event_open()的BPF)
- PMC(性能监控计数器)事件(使用perf_event_open()的BPF)
- 过滤(通过BPF程序)
- 调试输出(bpf_trace_printk())
- 每事件输出(bpf_perf_event_output())
- 基本变量(全局和线程级变量,通过BPF映射)
- 关联数组(通过BPF映射)
- 频率计数(通过BPF映射)
- 直方图(二的幂次方、线性和自定义,通过BPF映射)
- 时间戳和时间差(bpf_ktime_get_ns()和BPF程序)
- 堆栈跟踪,内核级(BPF stackmap)
- 堆栈跟踪,用户级(BPF stackmap)
- 覆写环形缓冲区(perf_event_attr.write_backward)
- 低开销插装(BPF JIT、BPF映射总结)
- 适用于生产环境(BPF验证器)
关于这些内核级特性的背景,请参阅第2章。
4.2.2 BCC User-Level Features
BCC用户级前端和BCC代码库提供以下用户级功能:
- 静态跟踪,用户级(通过uprobes实现SystemTap风格的USDT探针)
- 调试输出(使用Python的BPF.trace_pipe()和BPF.trace_fields())
- 每事件输出(使用BPF_PERF_OUTPUT宏和BPF.open_perf_buffer())
- 间隔输出(使用BPF.get_table()和table.clear())
- 直方图打印(table.print_log2_hist())
- C结构导航,内核级(BCC重写器映射到bpf_probe_read())
- 符号解析,内核级(ksym()和ksymaddr())
- 符号解析,用户级(usymaddr())
- 调试信息符号解析支持
- BPF tracepoint支持(通过TRACEPOINT_PROBE)
- BPF堆栈跟踪支持(BPF_STACK_TRACE)
- 各种其他辅助宏和函数
- 示例(位于/examples目录下)
- 多种工具(位于/tools目录下)
- 教程(/docs/tutorial*.md)
- 参考指南(/docs/reference_guide.md)
4.3 BCC Installation
BCC软件包适用于许多Linux发行版,包括Ubuntu、RHEL、Fedora和Amazon Linux,因此安装非常简便。如果需要,您也可以从源代码构建BCC。有关最新的安装和构建说明,请查看BCC代码库中的INSTALL.md文件[58]。
4.3.1 Kernel Requirements
BCC工具所使用的主要内核BPF组件在Linux 4.1和4.9之间的版本中添加,但是随着后续版本的推出,也不断有改进。因此,建议您使用Linux 4.9内核(于2016年12月发布)或更新版本。此外,还需要启用一些内核配置选项:CONFIG_BPF=y, CONFIG_BPF_SYSCALL=y, CONFIG_BPF_EVENTS=y, CONFIG_BPF_JIT=y, 以及CONFIG_HAVE_EBPF_JIT=y。这些选项现在在许多发行版中默认已经启用,因此通常您无需手动更改。
4.3.2 Ubuntu
BCC已经被打包到Ubuntu的multiverse仓库中,包名为bpfcc-tools。您可以使用以下命令进行安装:
sudo apt-get install bpfcc-tools linux-headers-$(uname -r)
这将把工具安装到/sbin目录下,并添加"-bpfcc"后缀。
您还可以从iovvisor仓库获取最新的稳定且经过签名的软件包:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install bcc-tools libbcc-examples linux-headers-$(uname -r)
这些工具将安装在/usr/share/bcc/tools目录下。
此外,BCC也作为Ubuntu的snap包可用:
sudo snap install bcc
这些工具将安装在/snap/bin目录下(可能已经包含在您的$PATH中),并以“bcc.”前缀提供(例如,bcc.opensnoop)。
4.3.3 RHEL
BCC已经包含在Red Hat Enterprise Linux 7.6的官方yum仓库中,可以使用以下命令进行安装:
sudo yum install bcc-tools
这些工具将安装在/usr/share/bcc/tools目录下。
4.3.4 Other Distributions
INSTALL.md中还包括了Fedora、Arch、Gentoo和openSUSE的安装说明,以及源代码构建的说明。
4.4 BCC Tools
图4-2展示了主要的系统组件以及许多可用于观察它们的BCC工具。
4.4.1 Highlighted Tools
请注意,这些章节还包含许多未列在表4-1中的额外bpftrace工具。在完成本章和第5章之后,您可以根据需要跳转到后面的章节,将本书作为参考指南使用。
4.4.2 Tool Characteristics
BCC工具都具有以下共同特点:
- 它们解决实际的可观测性问题,是出于必要性而构建的。
- 它们设计用于在生产环境中由root用户运行。
- 每个工具都有一个man页(位于man/man8目录下)。
- 每个工具都有一个示例文件,包含示例输出和输出解释(位于tools/*_example.txt目录下)。
- 许多工具接受选项和参数,如果使用-h选项,大多数会打印USAGE消息。
- 工具源代码以块注释介绍开头。
- 工具源代码遵循一致的风格(使用pep8工具进行检查)。
为了保持一致性,新工具的添加会经过BCC维护者的审核,并要求作者遵循BCC的CONTRIBUTING_SCRIPTS.md指南。
BCC工具的设计也旨在与系统上的其他工具(如vmstat(1)和iostat(1))看起来和感觉一致。与vmstat(1)和top(1)类似,了解BCC工具的工作原理是有帮助的,特别是对于估算工具开销。本书解释了这些工具的工作原理,并经常描述了预期的开销;本章和第2章介绍了BCC和正在使用的内核技术的内部工作原理。
尽管BCC支持不同的语言前端,但BCC工具主要使用Python进行用户级组件开发,使用C进行内核级BPF开发。这些Python/C工具得到了BCC开发人员最多的关注和维护,因此在本书中有所涵盖。
贡献者指南中的建议之一是“编写解决问题的工具,而不要过多”。这鼓励开发单一用途的工具,而不是多功能工具,只要可能。
4.4.3 Single-Purpose Tools
Unix的哲学是做好一件事并且做到精致。这一理念的体现之一是创建小而高质量的工具,可以通过管道连接在一起完成更复杂的任务。这导致了大量小型的、单一用途的工具,例如今天仍在使用的grep(1)、cut(1)和sed(1)等。
BCC包含许多类似的单一用途工具,包括opensnoop(8)、execsnoop(8)和biolatency(8)。其中,opensnoop(8)就是一个很好的例子。考虑一下它是如何针对追踪open(2)系统调用家族定制选项和输出的:
对于BPF工具而言,采用这种风格的好处包括:
- **易于初学者学习:** 默认的输出通常已经足够使用。这意味着初学者可以立即使用这些工具,而无需对命令行用法做出决策,也不需要了解要监控哪些事件。例如,opensnoop(8)只需运行opensnoop就能产生有用且简洁的输出。不需要了解kprobes或tracepoints来监控open系统调用。
- **易于维护:** 对于工具开发者而言,需要维护的代码量更小,测试负担也更轻。多用途工具可能会以多种不同的方式监控各种工作负载,因此对工具进行小改动可能需要数小时的测试,以确保没有引入回归问题。对于最终用户而言,这意味着单一用途的工具更有可能在需要时正常工作。
- **提供代码示例:** 每个小工具都提供了一个简洁而实用的代码示例。许多学习BCC工具开发的人会从这些单一用途的工具开始,并根据需要进行定制和扩展。
- **定制参数和输出:** 工具的参数、位置参数和输出不需要适应其他任务,可以专门为单一用途进行定制。这可以提高可用性和可读性。
对于刚接触BCC的人来说,单一用途的工具是一个很好的起点,然后再转向更复杂的多用途工具。
4.4.4 Multi-Purpose Tools
BCC包含可以用于各种不同任务的多用途工具。它们比单一用途工具更难学习,但也更加强大。如果你只偶尔使用多用途工具,可能不需要深入学习它们;你可以在需要时收集一些单行命令来执行。
多用途工具的优点包括:
- **更大的可见性:** 不仅仅分析单个任务或目标,而是可以同时查看各个组件。
- **减少代码重复:** 可以避免有多个类似代码的工具。
BCC中最强大的多工具包括funccount(8)、stackcount(8)、trace(8)和argdist(8),这些在接下来的章节中进行了介绍。这些多用途工具通常允许你决定追踪哪些事件。然而,要充分利用这种灵活性,你需要了解要使用哪些kprobes、uprobes和其他事件,以及如何使用它们。后续章节将回到单一用途工具的具体主题上。
表格4-2总结了本章中概述的多用途工具。
请查看BCC仓库以获取完整和更新的工具选项和功能列表。这里仅概述了一些最重要的功能。
4.5 funccount
funccount(8)用于计数事件,特别是函数调用,并可以回答以下问题:
- 这个函数调用是内核级还是用户级的?
- 这个函数调用的频率是多少,每秒多少次?
为了提高效率,funccount(8)通过使用BPF映射在内核上下文中维护事件计数,并仅将总计报告给用户空间。与传统的“转储后处理”工具相比,这极大地减少了funccount(8)的开销。然而,高频率事件仍然可能导致显著的开销,因为它们的频率很高。例如,内存分配(malloc()、free())可能每秒发生数百万次,使用funccount(8)来跟踪这些事件可能会导致超过30%的CPU开销。有关典型频率和开销的更多信息,请参阅第18章。
接下来的章节将演示funccount(8),并解释其语法和功能。
4.5.1 funccount Examples
答案:是的。这个调用简单地跟踪 tcp_drop() 内核函数,直到键入 Ctrl-C 为止。在跟踪过程中,它被调用了三次。
这个命令使用类似shell的通配符来匹配所有以"vfs_"开头的内核函数。在跟踪过程中,调用次数最多的内核函数是vfs_write(),共调用了6938次。
速率是可变的,但大约是每秒约2000次调用。这是对libc库中的一个函数进行仪器化,而且是系统范围内的:输出显示了所有进程的调用速率。
这个问题可以通过不同的事件源来回答。在这种情况下,我使用了来自syscalls系统的tracepoints,并简单地匹配了所有系统调用入口的tracepoints("sys_enter_*")。在跟踪过程中,调用次数最多的系统调用是futex(),共调用了42,929次。
4.5.2 funccount Syntax
funccount(8)的参数包括用于更改行为的选项以及描述要仪器化事件的字符串:
funccount [options] eventname
eventname的语法如下:
- **name** 或 **p:name**:仪器化名为name()的内核函数。
- **lib:name** 或 **p:lib:name**:仪器化位于库lib中名为name()的用户级函数。
- **path:name**:仪器化位于路径path中的文件中名为name()的用户级函数。
- **t:system:name**:仪器化名为system:name的跟踪点。
- **u:lib:name**:仪器化位于库lib中名为name的USDT探测点。
- **\***:通配符,匹配任何字符串(通配符匹配)。选项-r允许使用正则表达式代替。
这种语法在某种程度上受到了Ftrace的启发。在仪器化内核和用户级函数时,funccount(8)使用kprobes和uprobes。
4.5.3 funccount One-Liners
统计VFS内核调用次数:
funccount 'vfs_*'
统计TCP内核调用次数:
funccount 'tcp_*'
每秒统计TCP发送调用次数:
funccount -i 1 'tcp_send*'
显示每秒块I/O事件的速率:
funccount -i 1 't:block:*'
显示每秒新进程的产生率:
funccount -i 1 t:sched:sched_process_fork
显示每秒libc中getaddrinfo()(名称解析)的调用次数:
funccount -i 1 c:getaddrinfo
统计libgo中所有"os.*"调用的次数:
funccount 'go:os.*'
4.5.4 funccount Usage
间隔选项(-i)使funccount的一行命令在某种程度上变成了迷你性能工具,显示每秒自定义事件的速率。可以从成千上万的可用事件中创建自定义指标,并且如果需要,可以使用-p选项将其过滤到目标进程ID。
4.6 stackcount
stackcount(8)用于统计导致事件发生的堆栈跟踪。与funccount(8)类似,事件可以是内核级或用户级函数、跟踪点或USDT探测点。stackcount(8)可以回答以下问题:
- 为什么会调用这个事件?代码路径是什么?
- 所有不同的代码路径都是如何调用这个事件的,它们的频率是多少?
为了效率,stackcount(8)完全在内核上下文中执行这些总结,使用特殊的BPF映射来存储堆栈跟踪信息。用户空间读取堆栈ID和计数,然后从BPF映射中获取堆栈跟踪,进行符号转换并打印输出。与funccount(8)类似,stackcount(8)的开销取决于被仪器化事件的频率,由于stackcount(8)需要执行更多的工作来获取和记录堆栈跟踪,因此开销可能稍高。
4.6.1 stackcount Example
我注意到在一个空闲系统上使用funccount(8),我似乎有很高的ktime_get()内核函数调用率 — 每秒超过8000次。这些调用获取时间,但为什么我的空闲系统需要频繁获取时间呢?
这个例子使用stackcount(8)来识别导致ktime_get()调用的代码路径。
输出内容长达数百页,包含了1000多个堆栈跟踪。这里只包含了其中两个。每个堆栈跟踪以每个函数一行的方式打印,并且包括其出现次数。例如,第一个堆栈跟踪显示了通过dmcrypt_write()、blk_mq_make_request()和nvme_queue_rq()的代码路径。我猜测(没有查看代码的情况下),这可能是为了将I/O开始时间存储起来,以便后续优先处理。在追踪过程中,这个从ktime_get()到dmcrypt_write()的路径发生了52次。调用ktime_get()最频繁的堆栈来自于CPU空闲路径。
选项-P将进程名称和PID与堆栈跟踪一起显示。
这显示了PID为0,进程名称为"swapper/2"通过do_idle()调用了ktime_get(),进一步确认了这是空闲线程。使用-P选项会产生更多输出,因为先前分组的堆栈跟踪现在会根据每个单独的PID进行分割。
4.6.2 stackcount Flame Graphs
有时您会发现某个事件只打印了一个或几个堆栈跟踪,这在stackcount(8)的输出中很容易浏览。对于像ktime_get()这样的输出长达数百页的情况,可以使用火焰图来可视化输出。(火焰图在第2章介绍。)原始的火焰图软件[37]接受折叠格式的堆栈作为输入,每个堆栈跟踪一行,帧(函数名)用分号分隔,末尾带有空格和计数。stackcount(8)可以使用-f选项生成这种格式。
以下示例追踪ktime_get()持续10秒钟(-D 10),包含每个进程的堆栈(-P),并生成火焰图:
这里使用了wc(1)工具,显示输出共有1586行——代表着这么多个唯一的堆栈和进程名称组合。图4-3展示了生成的SVG文件的截图。
火焰图显示,大多数ktime_get()调用来自于八个空闲线程——系统上每个CPU一个,如相似的塔所示。其他来源显示为左侧较窄的塔。
4.6.3 stackcount Broken Stack Traces
堆栈跟踪及其在实际中遇到的诸多问题,已在第2、12和18章讨论过。常见的问题包括堆栈遍历中断以及符号丢失。
例如,之前的堆栈跟踪显示tick_nohz_idle_enter()调用了ktime_get()。然而,在源代码中并没有这个函数。实际上有一个调用tick_nohz_start_idle()的地方,其源代码位于(kernel/time/tick-sched.c)。
这种小型函数通常会被编译器内联,这就导致了一个堆栈,其中父函数直接调用ktime_get()。tick_nohz_start_idle符号在/proc/kallsyms(对于这个系统而言)中找不到,进一步表明它已经被内联。
4.6.4 stackcount Syntax
stackcount(8)命令的参数定义了要进行性能分析的事件:
stackcount [options] eventname
事件名称的语法与funccount(8)相同:
- name 或 p:name:分析内核函数 name()
- lib:name 或 p:lib:name:分析库 lib 中名为 name() 的用户级函数
- path:name:分析路径为 path 的文件中名为 name() 的用户级函数
- t:system:name:分析名为 system:name 的跟踪点
- u:lib:name:分析库 lib 中名为 name 的USDT探针
- *:通配符,匹配任何字符串(使用-g选项支持正则表达式)。
4.6.5 stackcount One-Liners
统计引起块I/O的堆栈跟踪:
stackcount t:block:block_rq_insert
统计导致发送IP数据包的堆栈跟踪:
stackcount ip_output
统计导致发送IP数据包并显示相关PID的堆栈跟踪:
stackcount -P ip_output
统计导致线程阻塞并移出CPU的堆栈跟踪:
stackcount t:sched:sched_switch
统计导致执行read()系统调用的堆栈跟踪:
stackcount t:syscalls:sys_enter_read
4.6.6 stackcount Usage
4.7 trace
trace(8)是一个BCC多功能工具,用于从多种不同的来源进行事件跟踪:kprobes、uprobes、tracepoints和USDT探针。
它可以回答诸如以下问题:
- 当内核或用户级函数被调用时,它们的参数是什么?
- 这个函数的返回值是什么?是否失败?
- 这个函数是如何被调用的?用户级或内核级堆栈跟踪是什么?
由于每个事件输出一行,trace(8)适用于调用不频繁的事件。非常频繁的事件,例如网络数据包、上下文切换和内存分配,可能每秒发生数百万次,trace(8)会产生大量输出,导致显著的性能开销。减少开销的一种方法是使用过滤表达式仅打印感兴趣的事件。频繁发生的事件通常更适合使用其他工具进行分析,如funccount(8)、stackcount(8)和argdist(8)这样在内核中进行总结的工具。argdist(8)将在下一节中介绍。
4.7.1 trace Example
以下示例显示通过跟踪do_sys_open()内核函数来进行文件打开操作,这是opensnoop(8)的trace(8)版本:
arg2是传递给do_sys_open()的第二个参数,是打开的文件名,类型为char *。最后一列标记为“-”,是提供给trace(8)的自定义格式字符串。
4.7.2 trace Syntax
trace(8)的参数是用于更改行为的选项和一个或多个探针:
trace [options] probe [probe ...]
探针的语法如下:
eventname(signature) (boolean filter) "format string", arguments
eventname签名是可选的,在某些情况下是必需的(参见第4.7.4节)。
过滤器也是可选的,并允许布尔运算符:==、<、>和!=。带有参数的格式字符串也是可选的。如果没有格式字符串,trace(8)仍会打印每个事件的元数据行;但是,没有自定义字段。
eventname的语法类似于funccount(8)的事件名称语法,还添加了返回探针:
- name或p:name:监控调用name()的内核函数
- r::name:监控调用name()的内核函数返回
- lib:name或p:lib:name:监控库lib中调用name()的用户级函数
- r:lib:name:监控库lib中调用name()的用户级函数返回
- path:name:监控路径处的文件中调用name()的用户级函数
- r:path:name:监控路径处的文件中调用name()的用户级函数返回
- t:system:name:监控名为system:name的跟踪点
- u:lib:name:监控库lib中名为name的USDT探针
- *:通配符,匹配任何字符串(globbing)。-r选项允许使用正则表达式。
格式字符串基于printf(),支持以下格式:
- %u:无符号整数
- %d:整数
- %lu:无符号长整数
- %ld:长整数
- %llu:无符号长长整数
- %lld:长长整数
- %hu:无符号短整数
- %hd:短整数
- %x:无符号整数,十六进制
- %lx:无符号长整数,十六进制
- %llx:无符号长长整数,十六进制
- %c:字符
- %K:内核符号字符串
- %U:用户级符号字符串
- %s:字符串
总体语法类似于其他语言中的编程。考虑下面的trace(8)单行命令:
trace 'c:open (arg2 == 42) "%s %d", arg1, arg2'
以下是更类似于C语言的等效程序(仅供示例;trace(8)不会执行此程序):
trace 'c:open { if (arg2 == 42) { printf("%s %d\n", arg1, arg2); } }'
在临时跟踪分析中经常需要自定义打印事件的参数,因此trace(8)是一个常用的工具。
4.7.3 trace One-Liners
以下是翻译:
在使用消息中列出了许多单行命令。这里是一些附加的单行命令选择。
跟踪内核的do_sys_open()函数,并输出文件名:
trace 'do_sys_open "%s", arg2'
跟踪内核的do_sys_open()函数返回,并打印返回值:
trace 'r::do_sys_open "ret: %d", retval'
使用模式和用户级堆栈跟踪do_nanosleep()函数:
trace -U 'do_nanosleep "mode: %d", arg2'
通过pam库跟踪认证请求:
trace 'pam:pam_start "%s: %s", arg1, arg2'
4.7.4 trace Structs
BCC使用系统头文件和内核头文件包来理解一些结构体。例如,考虑以下单行命令,它跟踪带有任务地址的do_nanosleep()函数:
trace 'do_nanosleep(struct hrtimer_sleeper *t) "task: %x", t->task'
幸运的是,hrtimer_sleeper结构体位于内核头文件包中(include/linux/hrtimer.h),因此BCC可以自动读取它。
对于不在内核头文件包中的结构体,可以手动包含它们的头文件。例如,以下单行命令仅在目标端口为53(DNS;以大端序写成13568)时跟踪udpv6_sendmsg()函数:
trace -I 'net/sock.h' 'udpv6_sendmsg(struct sock *sk) (sk->sk_dport == 13568)'
net/sock.h文件是必需的,以便理解struct sock,因此它使用了-I选项手动包含。这仅在系统上有完整的内核源代码时才能工作。
一种正在开发中的新技术可能会消除安装内核源代码的需要——BPF类型格式(BTF),它将在编译后的二进制文件中嵌入结构信息(见第2章)。
4.7.5 trace Debugging File Descriptor Leaks
这里有一个更为复杂的例子。我在调试Netflix生产实例上的一个真实问题——文件泄漏时开发了这个例子。目标是获取有关未被释放的套接字文件描述符的更多信息。通过sock_alloc()的堆栈跟踪可以提供这样的信息;然而,我需要一种区分已被释放(通过sock_release())和未被释放的分配的方法。问题在图4-4中有所说明。
追踪sock_alloc()并打印堆栈跟踪是直接的操作,但这会产生缓冲区A、B和C的堆栈跟踪。在这种情况下,只有缓冲区B是感兴趣的,因为它在追踪时没有被释放。
我能够使用一个单行命令来解决这个问题,尽管它需要后处理。以下是这个单行命令和一些输出:
这段话描述了如何在内核函数sock_alloc()的返回点上插入跟踪,并打印返回值、套接字地址以及堆栈跟踪(使用了-K和-U选项)。同时,它还追踪了__sock_release()内核函数的入口及其第二个参数:这显示了已关闭的套接字地址。使用-t选项可以打印这些事件的时间戳。
我已经截断了输出(输出和Java堆栈非常长),只展示了一个套接字地址为0xffff9c76526dac00的分配和释放配对(以粗体突出显示)。我能够通过后处理这些输出,找出已打开但未关闭的文件描述符(即没有匹配的关闭事件),然后使用分配的堆栈跟踪来识别导致文件描述符泄漏的代码路径(这里没有展示)。
这个问题也可以通过类似于第7章中介绍的专用BCC工具(如memleak(8))来解决,该工具将堆栈跟踪保存在BPF映射中,并在释放事件期间删除它们,以便稍后打印映射以显示长期存留的问题。
4.7.6 trace Usage
由于这是一种你可能偶尔使用的小型编程语言,用法消息结尾的示例是非常宝贵的提醒。
尽管trace(8)非常有用,但它并不是一个完整的语言。要了解完整的语言,请参阅第5章中的bpftrace。
4.8 argdist
argdist(8)是一个总结参数的多功能工具。以下是Netflix的另一个真实例子:一个Hadoop服务器遇到了TCP性能问题,我们追踪到问题是由于零大小的窗口广告导致的。我使用了argdist(8)的一行命令来总结生产环境中的窗口大小。以下是问题输出的部分内容:
这个工具对__tcp_select_window()内核函数的返回进行了仪器化,并将返回值以2的幂直方图(-H选项)的形式进行了总结。默认情况下,argdist(8)每秒打印一次这个总结。直方图显示了"0 -> 1"行中的零大小窗口问题:在上述时间间隔内,计数为6100。我们能够使用这个工具确认问题是否仍然存在,同时我们对系统进行了更改以纠正这个问题。
4.8.1 argdist Syntax
argdist(8)的参数设置了总结的类型、仪器化的事件以及要总结的数据:
argdist {-C|-H} [选项] 探针
argdist(8)要求使用-C或-H选项:
■ -C:频率计数
■ -H:2的幂直方图
探针的语法为:
eventname(signature)[:type[,type...]:expr[,expr...][:filter]][#label]
eventname和signature的语法几乎与trace(8)命令相同,唯一的例外是内核函数名的快捷方式不可用。例如,跟踪内核的vfs_read()函数使用"p::vfs_read",而不是"vfs_read"。通常需要提供signature。如果signature为空,则需要使用空括号"()"。
type显示了要总结的值类型:u32表示无符号32位整数,u64表示无符号64位整数,以此类推。支持多种类型,包括用于字符串的"char *"。
expr是要总结的表达式。它可以是函数的参数或跟踪点的参数。还有一些特殊变量只能在返回探针中使用:
■ $retval:函数的返回值
■ $latency:从进入到返回的时间,以纳秒为单位
■ $entry(param):进入探针时param的值
filter是一个可选的布尔表达式,用于过滤要添加到总结中的事件。支持的布尔运算符包括==、!=、<和>。
label是一个可选设置,将标签文本添加到输出中,以便自我记录。
4.8.2 argdist One-Liners
以下是使用消息中列出的许多单行命令。这里是一些额外的单行命令选择。
打印由内核函数vfs_read()返回的结果(大小)的直方图:
argdist.py -H 'r::vfs_read()'
打印由用户级libc read()在PID 1005上返回的结果(大小)的直方图:
argdist -p 1005 -H 'r:c:read()'
通过syscall ID计算syscalls的数量,使用raw_syscalls:sys_enter跟踪点:
argdist.py -C 't:raw_syscalls:sys_enter():int:args->id'
计算tcp_sendmsg()的大小:
argdist -C 'p::tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size):u32:size'
将tcp_sendmsg()的大小汇总为2的幂直方图:
argdist -H 'p::tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size):u32:size'
按文件描述符计算PID 181的libc write()调用次数:
argdist -p 181 -C 'p:c:write(int fd):int:fd'
按照读取的频率打印进程,其中延迟大于0.1毫秒:
argdist -C 'r::__vfs_read():u32:$PID:$latency > 100000'
4.8.3 argdist Usage
argdist(8)允许您创建许多功能强大的单行命令。对于超出其功能范围的分布总结,请参阅第5章。
4.9 Tool Documentation
每个BCC工具都有一个手册页和一个示例文件。BCC的/examples目录中包含一些类似工具的代码样本,但这些代码在其自身的代码之外并未有文档记录。您在/tools目录中找到的工具,或者在使用分发包时安装在系统其他位置的工具,应当有相应的文档记录。
接下来的部分以opensnoop(8)为例讨论工具文档。
4.9.1 Man Page: opensnoop
如果您的工具是通过软件包安装的,您可能会发现man opensnoop命令可用。如果您查看存储库,可以使用nroff(1)命令来格式化man页面(这些页面使用ROFF格式)。
man页面的结构基于其他Linux实用程序的结构。多年来,我不断完善了man页面内容的方法,并关注了某些细节。以下man页面包括了我的解释和建议:
这个man页面处于第8节,因为它是一个需要root权限的系统管理命令,正如我在DESCRIPTION部分的结尾所述。未来,扩展的BPF可能会对非root用户开放,就像perf(1)命令一样。如果发生这种情况,这些man页面将移动到第1节。
NAME部分包括对工具的一句描述。它说明这是一个为Linux设计的工具,使用eBPF/BCC(因为我为不同操作系统和跟踪器开发了多个版本的这些工具)。
SYNOPSIS部分总结了命令行的使用方法。
DESCRIPTION部分概述了工具的功能及其有用之处。描述工具为何有用是至关重要的,用简单的语言解释它解决了什么现实世界的问题(这对每个人可能并不显而易见)。提供这些信息有助于确保工具足够有用以发布。有时候,我在编写这一部分时会遇到困难,这让我意识到特定工具的使用案例可能过于狭窄,不值得发布。
DESCRIPTION部分还应指出主要的注意事项。提前告知用户可能存在的问题比让他们自己摸索要好。这个示例包括了有关动态跟踪稳定性和所需内核版本的标准警告。
接下来继续:
REQUIREMENTS部分列出任何特殊要求,而OPTIONS部分列出每个命令行选项:
EXAMPLES通过展示工具在不同方式下的执行来解释工具及其各种功能。这可能是man页面中最有用的部分。
FIELDS解释了工具可以输出的每个字段。如果一个字段有单位,应该在man页面中包含它们。例如,这个示例明确说明"TIME(s)"的单位是秒。
OVERHEAD部分是设定期望的地方。如果用户意识到存在较高的开销,他们可以进行计划,并仍然成功地使用这个工具。在这个例子中,预期开销应该很低。
最后的部分展示了这个工具来自BCC,以及其他元数据,并包括指向其他阅读材料的指针:示例文件,以及在SEE ALSO中列出的相关工具。
如果一个工具已经从其他跟踪器移植过来,或者基于其他工作,最好在man页面中进行文档化。有许多BCC工具已经移植到bpftrace存储库,bpftrace的man页面在它们的SOURCE部分声明了这一点。
4.9.2 Examples File: opensnoop
通过查看输出示例,可以是解释工具的最佳方式,因为它们的输出可能直观易懂,这是一个好工具设计的标志。BCC中的每个工具都有一个专门的文本文件,其中包含示例。
示例文件的第一句提供工具的名称和版本。输出示例从基础到更高级别都包括在内:
工具的输出在示例文件中得到了解释,尤其是在第一个示例中。示例文件的末尾包含了一份使用消息的副本。这可能看起来有些多余,但对在线浏览很有用。示例文件通常不会展示每个选项的使用方式,因此以使用消息结束可以展示工具的其他功能。
4.10 Developing BCC Tools
由于大多数读者可能更喜欢使用高级别的bpftrace语言进行编程,本书专注于使用bpftrace进行工具开发,并将BCC作为预先编写工具的来源。BCC工具开发作为附录C的可选内容进行了涵盖。
那么,在bpftrace已经存在的情况下,为什么还要开发BCC工具呢?BCC适合构建具有各种命令行参数和选项、以及完全定制输出和动作的复杂工具。例如,一个BCC工具可以使用网络库将事件数据发送到消息服务器或数据库。相比之下,bpftrace适合编写单行命令或接受零个或单个参数,并且仅打印文本输出的短小工具。
BCC还允许更低级别的控制,用于用C编写的BPF程序以及用Python或其他支持的语言编写的用户级组件。但这也带来了一些复杂性:开发BCC工具可能需要比bpftrace工具长10倍的时间,并且可能包含多达10倍的代码行数。
无论您是在BCC还是bpftrace中编码,通常都可以将核心功能从一种语言转移到另一种语言——一旦确定了这些功能应该是什么。在完全使用BCC开发工具之前,您可能还会使用bpftrace作为原型和概念验证语言。
关于BCC工具开发资源、技巧和带有源代码解释的示例,请参见附录C。接下来的章节涵盖了BCC内部和调试内容。即使您只是运行而不是开发BCC工具,但在需要调试出现问题的工具时,了解一些BCC内部知识可能也是必要的。
4.11 BCC Internals
BCC包括以下组成部分:
- 用于编写内核级BPF程序的C++前端API,包括:
- 一个预处理器,用于将内存解引用转换为bpf_probe_read()调用(以及在未来的内核中,bpf_probe_read()的变体)
- C++后端驱动程序:
- 通过Clang/LLVM编译BPF程序
- 在内核中加载BPF程序
- 将BPF程序附加到事件上
- 使用BPF映射进行读取/写入
- 用于编写BPF工具的语言前端API:Python、C++和lua
这些内容如图4-5所示。
图4-5中显示的BPF、Table和USDT Python对象是它们在libbcc和libbcc_bpf中实现的包装器。
Table对象与BPF映射进行交互。这些表已经成为BPF对象的BPF项目(使用Python的“魔法方法”,如__getitem__),因此以下行是等效的:
counts = b.get_table("counts")
counts = b["counts"]
USDT在Python中是一个单独的对象,因为其行为与kprobes、uprobes和tracepoints不同。在初始化期间,必须将其附加到进程ID或路径上,因为与其他事件类型不同,某些USDT探针需要在进程镜像中设置信号量以激活它们。这些信号量可供应用程序使用,以确定当前是否正在使用USDT探针,并决定是否准备其参数,或者是否可以跳过以进行性能优化。
C++组件编译为libbcc_bpf和libbcc,其他软件(如bpftrace)使用这些组件。libbcc_bpf源自Linux内核源代码中的tools/lib/bpf目录(它起源于BCC)。
BCC加载BPF程序并进行事件工具化的步骤包括:
1. 创建Python BPF对象,并将BPF C程序传递给它。
2. BCC重写器预处理BPF C程序,将解引用替换为bpf_probe_read()调用。
3. Clang将BPF C程序编译为LLVM IR。
4. 根据需要,BCC代码生成器添加额外的LLVM IR。
5. LLVM将IR编译成BPF字节码。
6. 如果使用映射,创建映射。
7. 将字节码发送到内核,并由BPF验证程序检查。
8. 启用事件,并将BPF程序附加到事件上。
9. BCC程序通过映射或perf_event缓冲区读取工具化数据。
接下来的章节将更详细地探讨这些内部机制。
4.12 BCC Debugging
除了插入printf()语句之外,还有多种调试和故障排除BCC工具的方法。本节总结了print语句、BCC调试模式、bpflist和重置事件等内容。如果您正在阅读本节是因为要解决问题,请同时查看第18章,该章涵盖了常见问题,如丢失事件、丢失堆栈和丢失符号。
图4-6显示了程序编译流程以及可以用于沿途检查的各种调试工具。
4.12.1 printf() Debugging
使用printf()进行调试可能会感觉像是一种简单粗暴的方法,与使用更复杂的调试工具相比,但它可以是有效和快速的。printf()语句不仅可以添加到Python代码中进行调试,还可以添加到BPF代码中。为此,有一个特殊的辅助函数:bpf_trace_printk()。它将输出发送到特殊的Ftrace缓冲区,可以通过读取/sys/kernel/debug/tracing/trace_pipe文件来查看。
例如,假设您在使用biolatency(8)工具时遇到问题,尽管它正在编译和运行,但输出看起来有些不对劲。您可以插入一个printf()语句来确认探测点是否触发,以及所使用的变量是否具有预期的值。以下是在biolatency.py中添加的示例,用粗体突出显示:
现在可以运行该工具:
# ./biolatency.py
跟踪块设备I/O... 按下Ctrl-C结束。
在另一个终端会话中,可以使用cat命令读取Ftrace的trace_pipe文件:
输出包含各种Ftrace默认字段,接着是我们自定义的bpf_trace_printk()消息(由于换行,消息可能被分割成多行)。
如果您使用cat命令读取trace文件而不是trace_pipe,将打印头信息:
这两个文件的区别如下:
- **trace**: 打印头信息;不会阻塞。
- **trace_pipe**: 阻塞以等待更多消息,并在读取时清除消息。
这个Ftrace缓冲区(通过trace和trace_pipe查看)被其他Ftrace工具使用,因此您的调试消息可能会与其他消息混合在一起。这对调试来说足够有效,如果需要的话,您可以过滤消息,只查看感兴趣的部分(例如,对于本例,您可以使用:grep BDG /sys/.../trace)。
使用第二章中介绍的bpftool(8),您可以通过bpftool prog tracelog命令打印Ftrace缓冲区。
4.12.2 BCC Debug Output
有些工具,比如funccount(8)的-D选项,已经提供了打印调试输出的选项。查看工具的使用消息(使用-h或--help选项)以查看是否有此选项。许多工具都有一个未记录的--ebpf选项,该选项会打印工具生成的最终BPF程序。
例如:
这在BPF程序被内核拒绝的情况下可能会很有用:您可以打印出来并检查是否存在问题。
4.12.3 BCC Debug Flag
BCC为所有工具提供了调试能力:可以在程序的BPF对象初始化器中添加调试标志。例如,在opensnoop.py中,有如下一行代码:
b = BPF(text=bpf_text)
可以修改为包含调试设置:
b = BPF(text=bpf_text, debug=0x2)
这样在运行程序时会打印BPF指令:
BPF调试选项是可以组合的单比特标志。它们列在src/cc/bpf_module.h中,如下所示:
debug=0x1f会打印所有内容,可能会输出数十页的内容。
4.12.4 bpflist
BCC中的bpflist(8)工具列出了正在运行BPF程序的工具以及一些详细信息。例如:
这显示opensnoop(8)工具正在使用PID 30231运行,并且使用了两个BPF程序和两个映射。这是有道理的:opensnoop(8)为每个事件使用一个BPF程序进行工具化,并且有一个映射用于在探测器之间传递信息,还有一个映射用于向用户空间发射数据。
-v(详细)模式计数kprobes和uprobes,-vv(非常详细)模式会计数并列出kprobes和uprobes。例如:
这显示有两个BPF程序在运行:systemd(PID 1)和opensnoop(PID 31364)。在-vv模式下还会列出开放的kprobes和uprobes。请注意,PID消费者31364编码在kprobe名称中。
4.12.5 bpftool
bpftool源自Linux源代码树,可以显示运行中的程序,列出BPF指令,与映射进行交互等功能。这些内容在第二章中有详细介绍。
4.12.6 dmesg
有时,来自BPF或其事件源的内核错误会出现在系统日志中,并可以使用dmesg(1)命令查看。例如:
# dmesg
[...]
[8470906.869945] trace_kprobe: Could not insert probe at vfs_rread+0: -2
这是一个关于尝试为vfs_rread()内核函数创建kprobe的错误信息;这是一个拼写错误,因为vfs_rread()函数并不存在。
4.12.7 Resetting Events
开发软件通常涉及编写新代码并修复错误的循环过程。在引入BCC工具或库中的错误时,可能会导致启用跟踪后BCC崩溃。这可能会使内核事件源处于启用状态,而没有进程来消费它们的事件,从而造成一些不必要的开销。
这个问题最初出现在旧的基于Ftrace的/sys接口中,BCC最初用于为除perf_events(PMCs)之外的所有事件源进行仪表化。perf_events使用了基于文件描述符的perf_event_open()。perf_event_open()的一个好处是,崩溃的进程会触发内核清理其文件描述符,进而触发已启用事件源的清理。从Linux 4.17版本开始,BCC已经全部转换为使用perf_event_open()接口来处理所有事件源,因此残留的内核启用问题应该已成为历史。
如果您使用的是较旧的内核,可以使用BCC中的一个名为reset-trace.sh的工具来清理Ftrace内核状态,从而移除所有已启用的跟踪事件。请仅在确定系统上没有任何跟踪消费者(不仅限于BCC,还包括任何跟踪器)运行时使用此工具,因为它可能会过早终止它们的事件源。
这是我在我的BCC开发服务器上的一些输出:
在这个详细模式操作下(-v),reset-trace.sh 所执行的所有步骤都会被打印出来。输出中在重置 kprobe_events 和 uprobe_events 后的空白行表示重置操作成功完成。
4.13 Summary
BCC项目提供了70多个BPF性能工具,其中许多支持通过命令行选项进行定制,并且所有工具都配备了文档:man手册和示例文件。大多数工具都是单一用途的,专注于良好地观察一项活动。也有一些是多用途工具;本章介绍了其中四个:funccount(8)用于计算事件数量,stackcount(8)用于计算导致事件的堆栈跟踪,trace(8)用于打印自定义事件输出,以及argdist(8)用于汇总事件参数作为计数或直方图。本章还涵盖了BCC调试工具。附录C提供了开发新BCC工具的示例。
5 bpftrace
bpftrace是基于BPF和BCC构建的开源跟踪器。与BCC类似,bpftrace提供了许多性能工具和支持文档。然而,它还提供了一种高级编程语言,允许您创建强大的一行命令和简短的工具。例如,使用bpftrace的一行命令将vfs_read()的返回值(字节或错误值)汇总为直方图:

bpftrace是由Alastair Robertson于2016年12月作为业余项目创建的。由于它设计良好,并且与现有的BCC/LLVM/BPF工具链非常匹配,我加入了该项目,并成为主要的代码、性能工具和文档贡献者。现在,我们已经有许多其他人加入进来,2018年我们完成了添加第一批重要功能的工作。
本章介绍了bpftrace及其特性,概述了其工具和文档,解释了bpftrace编程语言,并以bpftrace调试和内部结构的介绍结束。
学习目标:
- 理解bpftrace的特性及其与其他工具的比较
- 学习在哪里找到工具和文档,以及如何执行这些工具
- 学习如何阅读稍后章节中包含的bpftrace源代码
- 开发bpftrace编程语言中的新的一行命令和工具
- (可选)了解bpftrace的内部结构
如果您希望立即开始学习bpftrace编程,可以直接跳转到第5.7节,然后再回到这里继续了解bpftrace。
bpftrace非常适合使用自定义的一行命令和简短脚本进行即时仪表化,而BCC则更适合复杂的工具和守护程序。
5.1 bpftrace Components

bpftrace包含工具、man页、示例文件的文档,以及一个bpftrace编程教程(一行命令教程)和编程语言的参考指南。包含的bpftrace工具的扩展名为.bt。
前端使用lex和yacc解析bpftrace编程语言,使用Clang解析结构。后端将bpftrace程序编译成LLVM中间表示,然后通过LLVM库编译为BPF。详细信息请参见第5.16节。
5.2 bpftrace Features
特性列表可以帮助您了解新技术的能力。我为bpftrace创建了期望的特性列表,以指导开发,并且现在这些特性已经实现并列在本节中。在第4章中,我将BCC的特性列表按内核级别和用户级别的特性分组,因为它们使用不同的API。而对于bpftrace来说,只有一个API:bpftrace编程。这些bpftrace特性相反是根据事件源、动作和一般特性进行分组。
5.2.1 bpftrace Event Sources
这些事件源使用了第2章介绍的内核级技术。bpftrace接口(探针类型)显示在括号中:
- 动态仪表化,内核级(kprobe)
- 动态仪表化,用户级(uprobe)
- 静态跟踪,内核级(tracepoint、software)
- 静态跟踪,用户级(usdt,通过libbcc)
- 定时抽样事件(profile)
- 间隔事件(interval)
- PMC事件(hardware)
- 合成事件(BEGIN,END)
这些探针类型在第5.9节中有更详细的解释。未来计划添加更多事件源,可能在您阅读时已经存在;它们包括套接字和skb事件、原始跟踪点、内存断点和自定义PMC。
5.2.2 bpftrace Actions
这些是事件触发时可以执行的操作。以下是一些关键操作的选择;完整列表详见bpftrace参考指南:
- 过滤(predicates)
- 每个事件的输出(printf())
- 基本变量(global, $local 和 per[tid])
- 内建变量(pid, tid, comm, nsecs 等)
- 关联数组(key[value])
- 频率计数(count() 或 ++)
- 统计信息(min(), max(), sum(), avg(), stats())
- 直方图(hist(), lhist())
- 时间戳和时间差(nsecs,及哈希存储)
- 栈回溯,内核(kstack)
- 栈回溯,用户(ustack)
- 符号解析,内核级(ksym(), kaddr())
- 符号解析,用户级(usym(), uaddr())
- C结构导航(->)
- 数组访问([])
- Shell命令(system())
- 打印文件(cat())
- 位置参数($1, $2, …)
操作在第5.7节中有更详细的解释。如果有强烈的使用案例,可能会添加更多操作,但希望保持语言尽可能小以便更容易学习。
5.2.3 bpftrace General Features
以下是bpftrace的一般特性和存储库组件:
- 低开销的仪表化(BPF JIT 和 maps)
- 生产环境安全(BPF 验证器)
- 多种工具(位于 /tools 目录下)
- 教程(/docs/tutorial_one_liners.md)
- 参考指南(/docs/reference_guide.md)
5.2.4 bpftrace Compared to Other Observability Tools
比较bpftrace与其他也能仪表化所有事件类型的跟踪工具:
- **perf(1)**: bpftrace提供了一种更高级的语言,语法简洁,而perf(1)的脚本语言则比较冗长。perf(1)通过perf record支持高效的事件转储到二进制格式,并且支持像perf top这样的内存中摘要模式。bpftrace支持在内核中高效的自定义直方图等汇总功能,而perf(1)的内置内核汇总功能仅限于计数(perf stat)。perf(1)可以通过运行BPF程序来扩展其功能,尽管不像bpftrace那样使用高级语言;详见附录D中的perf(1) BPF示例。
- **Ftrace**: bpftrace提供了类似C和awk的更高级语言,而Ftrace的自定义仪表化(包括hist-triggers)有其特有的语法。Ftrace的依赖较少,适合于小型Linux环境。Ftrace还具有诸如函数计数之类的仪表化模式,迄今比bpftrace使用的事件源进行了更多性能优化(例如,我的Ftrace funccount(8)目前比相应的bpftrace具有更快的启动和停止时间以及更低的运行时开销)。
- **SystemTap**: bpftrace和SystemTap都提供了更高级的语言。bpftrace基于内置的Linux技术,而SystemTap添加了自己的内核模块,在非RHEL系统上的可靠性有所不足。SystemTap已经开始支持类似bpftrace的BPF后端,这应该使其在其他系统上更加可靠。目前,SystemTap在其库(tapsets)中具有更多的辅助功能,用于仪表化不同的目标。
- **LTTng**: LTTng优化了事件转储,并提供了分析事件转储的工具。这与bpftrace设计的即时分析方法有所不同。
- **应用程序工具**: 应用程序和运行时特定的工具仅限于用户级别的可见性。bpftrace可以仪表化内核和硬件事件,使其能够识别超出这些工具范围的问题来源。这些工具的优势在于它们通常针对目标应用程序或运行时进行了定制。例如,MySQL数据库分析器已经了解如何仪表化查询,而JVM分析器已经可以仪表化垃圾收集。在bpftrace中,你需要自己编写这样的功能。
不必孤立地使用bpftrace。目标是解决问题,而不是仅仅使用bpftrace,有时结合使用这些工具可能更快速有效。
5.3 bpftrace Installation
bpftrace应该可以通过你的Linux发行版的软件包安装,但在撰写本文时,这些软件包才刚刚开始出现;第一个bpftrace软件包是由Canonical提供的一个snap包[1],还有一个Debian软件包[2],也将会在Ubuntu 19.04上可用。你也可以从源代码构建bpftrace。查看bpftrace仓库中的INSTALL.md获取最新的软件包和构建说明[63]。
5.3.1 Kernel Requirements
建议您使用Linux 4.9内核(发布于2016年12月)或更新版本。bpftrace使用的主要BPF组件是在Linux内核4.1到4.9之间添加的。随着后续版本的发布,也增加了改进。因此,您的内核版本越新越好。BCC文档包含了按Linux内核版本列出的BPF功能列表,这有助于解释为什么较新的内核更好(参见[64])。
一些内核配置选项也需要启用。这些选项现在在许多发行版中已经默认启用,因此通常不需要更改它们。这些选项包括:CONFIG_BPF=y, CONFIG_BPF_SYSCALL=y, CONFIG_BPF_JIT=y, CONFIG_HAVE_EBPF_JIT=y, CONFIG_BPF_EVENTS=y。
5.3.2 Ubuntu
一旦bpftrace软件包在您的Ubuntu发行版中可用,安装步骤如下:

bpftrace也可以从源代码构建并安装:

5.3.3 Fedora
一旦bpftrace被打包好,安装步骤如下:
![]()
bpftrace也可以从源代码编译安装:

5.3.4 Post-Build Steps
要确认编译成功,请运行测试套件和一个单行命令作为实验:

运行 sudo make install 将bpftrace二进制文件安装为 /usr/local/bin/bpftrace,并将工具安装在 /usr/local/share/bpftrace/tools。您可以通过使用cmake(1)选项来更改安装位置,其中 -DCMAKE_INSTALL_PREFIX=/usr/local 是默认设置。
5.3.5 Other Distributions
请检查是否有可用的bpftrace软件包,以及bpftrace的INSTALL.md安装说明。
5.4 bpftrace Tools
图5-2展示了主要的系统组件,以及来自bpftrace存储库和本书可以观察它们的工具。

bpftrace存储库中当前的工具用黑色表示,而本书中的新bpftrace工具用不同的颜色标记(红色或灰色,取决于本书的版本)。这里未包含某些变体(例如第10章中的qdisc变体)。
5.4.1 Highlighted Tools
表5-1列出了按主题组织的一些工具选择。这些工具将在后面的章节中详细讨论。

请注意,本书还描述了未在表5-1中列出的BCC工具。
阅读完本章后,您可以跳转到后面的章节,并将本书用作参考指南。
5.4.2 Tool Characteristics
bpftrace工具具有以下几个共同特点:
- 它们解决真实世界中的可观测性问题。
- 它们被设计用于在生产环境中以root用户身份运行。
- 每个工具都有一个手册页面(位于man/man8目录下)。
- 每个工具都有一个示例文件,包含输出和讨论内容(位于tools/*_examples.txt目录下)。
- 每个工具的源代码以块注释介绍开始。
- 这些工具尽可能简单和短小。(更复杂的工具推荐使用BCC。)
5.4.3 Tool Execution
捆绑的工具是可执行的,可以立即作为root用户运行:

这些工具可以与其他系统管理工具放置在sbin目录中,例如/usr/local/sbin。
5.5 bpftrace One-Liners
这部分提供了一些单行命令,它们既有实际用途,也用来展示bpftrace的各种能力。接下来的部分将解释编程语言,后续章节将介绍针对特定目标的更多单行命令。请注意,其中许多单行命令总结了(内核)内存中的数据,在使用Ctrl-C终止前不会打印总结。
显示当前正在执行什么:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(args->filename)); }'
```
显示带参数的新进程:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
```
显示进程通过openat()打开的文件:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }'
```
按程序统计系统调用次数:
```bash
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
```
按系统调用探针名称统计系统调用次数:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
```
按进程统计系统调用次数:
```bash
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
```
显示进程总读取字节数:
```bash
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret/ { @[comm] = sum(args->ret); }'
```
按进程显示读取大小分布:
```bash
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
```
按进程显示追踪磁盘I/O大小:
```bash
bpftrace -e 'tracepoint:block:block_rq_issue { printf("%d %s %d\n", pid, comm, args->bytes); }'
```
按进程统计页面换入次数:
```bash
bpftrace -e 'software:major-faults:1 { @[comm] = count(); }'
```
按进程统计页面错误次数:
```bash
bpftrace -e 'software:faults:1 { @[comm] = count(); }'
```
针对PID 189,以49赫兹采样用户级堆栈:
```bash
bpftrace -e 'profile:hz:49 /pid == 189/ { @[ustack] = count(); }'
```
5.6 bpftrace Documentation
每个bpftrace工具都有一个相应的man手册和示例文件,就像BCC项目中的工具一样。第4章讨论了这些文件的格式和意图。
为了帮助人们学习开发新的单行命令和工具,我创建了《bpftrace单行命令教程》[65]和《bpftrace参考指南》[66]。它们可以在存储库的/docs目录中找到。
5.7 bpftrace Programming
本节提供了使用bpftrace和编程bpftrace语言的简短指南。这一节的格式受到了awk的原始论文[Aho 78]的启发,该论文用六页介绍了awk语言。bpftrace语言本身受到了awk和C的启发,以及包括DTrace和SystemTap在内的跟踪器。
以下是一个bpftrace编程的示例:它测量了vfs_read()内核函数的执行时间,并将其以微秒为单位打印成直方图。本节总结部分解释了这个工具的组成部分。

总结部分之后的五个部分详细介绍了bpftrace编程的内容,包括:探针、测试、操作符、变量、函数和映射类型。
5.7.1 Usage
该命令:
```
bpftrace -e program
```
将执行程序,并对其定义的任何事件进行仪表化。该程序会一直运行,直到按下Ctrl-C,或者显式调用exit()结束。作为-e参数运行的bpftrace程序被称为单行命令。另外,程序也可以保存到文件中并执行:
```
bpftrace file.bt
```
.bt扩展名并非必需,但有助于稍后识别。通过在文件顶部放置解释器行:
```
#!/usr/local/bin/bpftrace
```
可以使文件可执行(chmod a+x file.bt),并像其他程序一样运行:
```
./file.bt
```
bpftrace必须由root用户(超级用户)执行。对于某些环境,可以直接使用root shell执行程序,而其他环境可能更倾向于通过sudo(1)运行特权命令:
```
sudo ./file.bt
```
5.7.2 Program Structure
bpftrace程序由一系列带有关联动作的探针组成:
```
probes { actions }
probes { actions }
...
```
当探针触发时,将执行其关联的动作。可选的过滤表达式可以在动作之前包含:
```
probes /filter/ { actions }
```
只有当过滤表达式为真时,动作才会触发。这类似于awk(1)程序的结构:
```
/pattern/ { actions }
```
awk(1)编程与bpftrace编程也有相似之处:可以定义多个动作块,并且它们可以以任意顺序执行:当它们的模式或探针+过滤表达式为真时触发。
5.7.3 Comments
对于bpftrace程序文件,可以使用"//"前缀添加单行注释:
```
// 这是一个注释
```
这些注释不会被执行。多行注释使用与C语言相同的格式:
```
/*
* 这是一个
* 多行注释。
*/
```
此语法也可以用于部分行注释(例如,/* 注释 */)。
5.7.4 Probe Format
一个探针由探针类型名称开始,然后是一组由冒号分隔的标识符构成的层次结构:
```
type:identifier1[:identifier2[...]]
```
这个层次结构由探针类型定义。考虑以下两个示例:
```
kprobe:vfs_read
uprobe:/bin/bash:readline
```
kprobe探针类型用于监控内核函数调用,只需要一个标识符:内核函数的名称。uprobe探针类型用于监控用户级函数调用,需要提供二进制文件的路径和函数名称两个标识符。
可以使用逗号分隔符指定多个探针来执行相同的动作。例如:
```
probe1,probe2,... { actions }
```
还有两种特殊的探针类型不需要额外的标识符:BEGIN 和 END,分别用于bpftrace程序的开头和结尾(类似于awk(1))。
要了解更多有关探针类型及其用法的信息,请参阅第5.9节。
5.7.5 Probe Wildcards
一些探针类型接受通配符。例如,探针:
```
kprobe:vfs_*
```
将会监控所有以 "vfs_" 开头的 kprobe(内核函数)。
监控过多的探针可能会导致不必要的性能开销。为了避免意外情况,bpftrace 设置了一个可调的最大探针数量,通过环境变量 BPFTRACE_MAX_PROBES 进行设置(默认为 5125)。
在使用通配符之前,你可以通过运行 bpftrace -l 命令来测试它们:


探针名称用引号括起来,以防止意外的 shell 展开。
5.7.6 Filters
过滤器是布尔表达式,用于控制动作是否执行。例如,过滤器
```
/pid == 123/
```
只有当内置的 pid(进程ID)等于 123 时才会执行动作。
如果没有指定测试条件:
```
/pid/
```
该过滤器将检查内容是否非零(/pid/ 等同于 /pid != 0/)。过滤器可以与布尔运算符结合,例如逻辑与(&&)。例如:
```
/pid > 100 && pid < 1000/
```
这要求两个表达式都评估为“true”才会执行动作。
5.7.7 Actions
动作可以是单个语句,也可以是由分号分隔的多个语句组成的块:
```
{ 动作一; 动作二; 动作三 }
```
最后一个语句也可以附加分号。这些语句使用 bpftrace 语言编写,类似于 C 语言,可以操作变量并执行 bpftrace 函数调用。例如,动作
```
{ $x = 42; printf("$x is %d", $x); }
```
将变量 $x 设置为 42,然后使用 printf() 打印它。第5.7.9节和5.7.11节总结了其他可用的函数调用。
5.7.8 Hello, World!
你现在应该理解以下基本程序,在 bpftrace 开始运行时打印 "Hello, World!":

作为一个文件,可以格式化如下:

跨多行使用缩进的动作块并非必需,但它可以提高可读性。
5.7.9 Functions
除了用于打印格式化输出的 printf() 外,其他内置函数还包括:
- exit(): 退出 bpftrace
- str(char *): 从指针返回一个字符串
- system(format[, arguments ...]): 在 shell 中运行一个命令
以下动作:
```
printf("got: %llx %s\n", $x, str($x)); exit();
```
将会打印变量 $x 的十六进制整数,并将其视为以 NULL 结尾的字符数组指针(char *),然后将其打印为字符串,最后退出。
5.7.10 Variables
有三种变量类型:内建变量(built-ins)、临时变量(scratch)、和映射变量(maps)。
内建变量是由 bpftrace 预定义并提供的,通常是只读的信息源。它们包括:
- pid:进程 ID
- comm:进程名称
- nsecs:纳秒级时间戳
- curtask:当前线程的 task_struct 结构体地址
临时变量(scratch variables)用于临时计算,以 "$" 前缀开头。它们的名称和类型在首次赋值时确定。例如:
```
$x = 1;
$y = "hello";
$z = (struct task_struct *)curtask;
```
这些语句分别声明了 $x 为整数,$y 为字符串,$z 为指向 task_struct 结构体的指针。这些变量只能在它们被赋值的动作块中使用。如果引用变量而没有赋值,bpftrace 将报错(这有助于捕获拼写错误)。
映射变量(map variables)使用 BPF 映射存储对象,并以 "@" 前缀开头。它们可用于全局存储和在动作之间传递数据。例如:
```
probe1 { @a = 1; }
probe2 { $x = @a; }
```
当 probe1 触发时,将 1 赋给 @a;当 probe2 触发时,将 @a 赋给 $x。如果 probe1 先触发然后是 probe2,则 $x 将被设置为 1;否则为 0(未初始化)。
映射可以使用键来提供一个或多个元素,类似于哈希表(关联数组)。例如:
```
@start[tid] = nsecs;
```
这里经常使用 nsecs 内建变量,将其赋给名为 @start 的映射,并以 tid 作为键,表示当前线程的 ID。这允许线程存储自定义时间戳,不会被其他线程覆盖。
另一个例子是多键映射的使用:
```
@path[pid, $fd] = str(arg0);
```
这个例子中,使用了 pid 内建变量和 $fd 变量作为键,将 arg0 的字符串形式赋给 @path 映射。
5.7.11 Map Functions
映射可以分配给特殊函数。这些函数以自定义方式存储和打印数据。
赋值
```
@x = count();
```
对事件进行计数,当打印时会输出计数值。这使用了每个 CPU 的映射,并且 @x 变成了一种名为 count 的特殊对象。下面的语句也可以用来计数事件:
```
@x++;
```
然而,这使用了全局 CPU 映射,而不是每个 CPU 映射,将 @x 视为整数。这种全局整数类型有时对需要整数而不是计数的一些程序是必要的,但请注意,由于并发更新,可能存在一小部分误差(参见第2.3.7节第2章)。
赋值
```
@y = sum($x);
```
对 $x 变量进行求和,并且当打印时会输出总和。
赋值
```
@z = hist($x);
```
将 $x 存储在一个二的幂直方图中,当打印时会输出桶计数和ASCII直方图。
一些映射函数直接操作映射。例如:
```
print(@x);
```
将打印 @x 映射。由于方便起见,当 bpftrace 终止时,所有映射都会自动打印,因此这种用法并不经常使用。
一些映射函数操作映射键。例如:
```
delete(@start[tid]);
```
从 @start 映射中删除键为 tid 的键值对。
5.7.12 Timing vfs_read()
现在您已经学习了理解更复杂和实际示例所需的语法。
这个程序,vfsread.bt,计时 vfs_read 内核函数,并打印其执行时间的微秒(us)直方图。

这段代码通过在 vfs_read() 内核函数的开始处插入一个 kprobe 来计时其持续时间,将时间戳存储在一个以线程ID为键的 @start 哈希表中。然后通过在其结束处使用 kretprobe 来计算时间差:delta = 当前时间 - 开始时间。使用过滤器确保已记录开始时间,否则 delta 计算将不正确:当前时间 - 0。
示例输出:


程序运行直到输入 Ctrl-C,然后打印出这个输出并终止。这个直方图映射被命名为“us”,这样做是为了在输出中包含单位,因为映射名称会被打印出来。通过给映射起有意义的名称,比如“bytes”和“latency_ns”,您可以对输出进行注释,使其更加自解释。
这个脚本可以根据需要进行定制。考虑将 hist() 赋值行修改为:
```
@us[pid, comm] = hist($duration_us);
```
这样可以根据进程ID和进程名称存储一个直方图。输出变为:

这展示了 bpftrace 最有用的能力之一。传统的系统工具,比如 iostat(1) 和 vmstat(1),它们的输出是固定的,很难进行定制。但是使用 bpftrace,您看到的指标可以进一步细分,并且可以通过其他探针的指标增强,直到您获得所需的答案为止。
5.8 bpftrace Usage
没有参数(或使用 -h),bpftrace 将打印 USAGE 消息,该消息总结了重要的选项和环境变量,并列出了一些示例一行命令。

这个输出来自 bpftrace 版本 v0.9-232-g60e6,日期为 2019年6月15日。随着新增功能的增加,这个 USAGE 消息可能变得冗长复杂,可能会添加短版本和长版本。请检查您当前版本的输出,看看是否已经实现了这一点。
5.9 bpftrace Probe Types
表5-2列出了可用的探测器类型。其中许多类型还有快捷别名,有助于创建更短的一行命令。

这些探测器类型是对现有内核技术的接口。第2章解释了这些技术的工作原理:kprobes、uprobes、tracepoints、USDT以及由硬件探测器类型使用的PMCs。
一些探测器可能会频繁触发,比如调度器事件、内存分配和网络数据包。为了减少开销,在可能的情况下尽量使用较少频繁的事件来解决问题。请参阅第18章,讨论如何最小化开销,适用于BCC和bpftrace开发的情况。
接下来的章节总结了bpftrace探测器的使用方法。
5.9.1 tracepoint
tracepoint探测器类型用于插装跟踪点:即内核静态插装点。格式为:
tracepoint:tracepoint_name
tracepoint_name 是跟踪点的完整名称,包括冒号,用于将跟踪点分成其自己的类和事件名称层次结构。例如,跟踪点 net:netif_rx 可以在 bpftrace 中通过探测器 tracepoint:net:netif_rx 进行插装。
跟踪点通常提供参数:这些是可以通过 bpftrace 的 args 内建访问的信息字段。例如,net:netif_rx 具有一个名为 len 的字段,表示数据包长度,可以通过 args->len 访问。
如果您对 bpftrace 和跟踪还不熟悉,系统调用的跟踪点是一个很好的插装目标。它们提供了广泛的内核资源使用覆盖,并有一个详细记录的 API:系统调用的手册页。例如,跟踪点:
syscalls:sys_enter_read
syscalls:sys_exit_read
插装了 read(2) 系统调用的开始和结束。该系统调用的手册页描述了其签名:
ssize_t read(int fd, void *buf, size_t count);
对于 sys_enter_read 跟踪点,其参数应该作为 args->fd、args->buf 和 args->count 可用。可以使用 bpftrace 的 -l(列表)和 -v(详细)模式来检查这些信息。

该手册页还描述了这些参数以及 read(2) 系统调用的返回值,可以通过 sys_exit_read 跟踪点进行插装。该跟踪点有一个附加参数,在手册页中找不到,即 __syscall_nr,表示系统调用号。
作为一个有趣的跟踪点示例,我将跟踪 clone(2) 系统调用的进入和退出,该调用用于创建新进程(类似于 fork(2))。对于这些事件,我将使用 bpftrace 内建变量打印当前进程名称和 PID。对于退出事件,我还将使用一个跟踪点参数打印返回值:

这个系统调用与众不同,它有一个进入点和两个退出点!在跟踪过程中,我在一个 bash 终端中运行了 ls 命令。父进程(PID 2582)可以看到进入 clone(2) 系统调用,然后有两个返回点:一个是为了父进程返回子进程的 PID(27804),另一个是为了子进程返回零(成功)。当子进程开始时,它仍然是 "bash",因为它尚未执行 exec(2) 系列的系统调用以变成 "ls"。这也可以被跟踪到:

5.9.2 usdt
这种探针类型用于对用户级静态插装点进行插装。格式如下:

usdt 可以通过提供完整路径来对可执行文件或共享库进行插装。probe_name 是来自二进制文件的 USDT 探针名称。例如,MySQL 服务器中名为 query__start 的探针可能通过(依赖于安装路径)usdt:/usr/local/sbin/mysqld:query__start 进行访问。
当未指定探针命名空间时,默认为与二进制文件或库相同的名称。有许多探针,它们的命名空间不同,并且必须包含命名空间。一个例子是来自 libjvm(JVM 库)的 "hotspot" 命名空间探针。例如(完整库路径已截断):
usdt:/.../libjvm.so:hotspot:method__entry
USDT 探针的任何参数都可以作为 args 内建变量的成员使用。
可以使用 -l 参数列出一个二进制文件中可用的探针,例如:

与提供探针描述相反,你可以使用 -p PID 选项来列出正在运行进程中的 USDT 探针。
5.9.3 kprobe and kretprobe
这些探针类型用于内核动态插装。格式如下:
- kprobe:function_name
- kretprobe:function_name
kprobe 用于插装函数的开始(即其入口),而 kretprobe 用于插装函数的结束(即其返回)。function_name 是内核函数的名称。例如,vfs_read() 内核函数可以使用 kprobe:vfs_read 和 kretprobe:vfs_read 进行插装。
对于 kprobe,参数 arg0、arg1、…、argN 是函数的入口参数,类型为无符号 64 位整数。如果它们是指向 C 结构体的指针,则可以将其转换为该结构体类型。未来的 BPF 类型格式(BTF)技术可能会自动执行这种转换(详见第二章)。
对于 kretprobe,内建变量 retval 包含函数的返回值。retval 始终是 uint64 类型;如果这与函数的返回类型不匹配,则需要将其转换为该类型。
5.9.4 uprobe and uretprobe
这些探针类型用于用户级动态插装。格式如下:
- uprobe:binary_path:function_name
- uprobe:library_path:function_name
- uretprobe:binary_path:function_name
- uretprobe:library_path:function_name
uprobe 用于插装函数的开始(即其入口),而 uretprobe 用于插装函数的结束(即其返回)。function_name 是函数的名称。例如,在 /bin/bash 中的 readline() 函数可以使用 uprobe:/bin/bash:readline 和 uretprobe:/bin/bash:readline 进行插装。
对于 uprobe,参数 arg0、arg1、…、argN 是函数的入口参数,类型为无符号 64 位整数。它们可以转换为它们的结构体类型。
对于 uretprobe,内建变量 retval 包含函数的返回值。retval 始终是 uint64 类型,并且需要转换为匹配实际返回类型的类型。
5.9.5 software and hardware
这些探针类型适用于预定义的软件和硬件事件。格式如下:
- software:event_name:count
- software:event_name:
- hardware:event_name:count
- hardware:event_name:
软件事件类似于跟踪点,但更适合基于计数的度量和基于采样的插装。硬件事件是处理器级别分析的性能监控计数器(PMC)的选择。
这两种事件类型可能发生频率非常高,对每个事件进行插装可能会导致显著的性能开销,从而降低系统性能。为了避免这种情况,可以使用采样和 count 字段,这样探针只在每 [count] 次事件发生时触发一次。如果未提供计数,则使用默认值。例如,探针 software:page-faults:100 只会在每发生 100 次页面错误时触发一次。
可用的软件事件取决于内核版本,详情请参见表 5-3。

可用的硬件事件取决于内核版本和处理器类型,详细列在表 5-4 中。

由于硬件事件发生频率较高,因此使用了更高的默认采样计数。
5.9.6 profile and interval
这些探针类型是基于定时器的事件。格式如下:
- profile:hz:rate
- profile:s:rate
- profile:ms:rate
- profile:us:rate
- interval:s:rate
- interval:ms:rate
profile 类型在所有 CPU 上触发,并可用于对 CPU 使用情况进行采样。interval 类型仅在一个 CPU 上触发,并可用于基于间隔输出。
第二个字段是最后一个字段 rate 的单位。这个字段可以是:
- hz:赫兹(每秒事件数)
- s:秒
- ms:毫秒
- us:微秒
例如,探针 profile:hz:99 每秒在所有 CPU 上触发 99 次。通常使用 99 而不是 100 是为了避免锁步采样的问题。探针 interval:s:1 每秒触发一次,并可用于输出每秒的结果。
5.10 bpftrace Flow Control
在bpftrace中有三种类型的测试:过滤器(filters)、三元运算符(ternary operators)和if语句。这些测试根据布尔表达式有条件地改变程序的流程,支持以下操作符:
- ==:等于
- !=:不等于
- >:大于
- <:小于
- >=:大于等于
- <=:小于等于
- &&:与
- ||:或
表达式可以使用括号进行分组。
由于安全性考虑,BPF验证器会拒绝可能引发无限循环的代码,因此对循环的支持有限。bpftrace支持展开循环,并且将来的版本可能会支持有界循环。
5.10.1 Filter
之前介绍过,这些门控是否执行某个动作。格式如下:
```
probe /filter/ { action }
```
可以使用布尔运算符。例如,过滤器 `/pid == 123/` 只有在内建的 pid 等于 123 时才执行动作。
5.10.2 Ternary Operators
三元运算符是由一个测试和两个结果组成的三元操作符。格式如下:
```
test ? true_statement : false_statement
```
例如,你可以使用三元运算符来计算 $x 的绝对值:
```
$abs = $x >= 0 ? $x : - $x;
```
5.10.3 If Statements
if语句具有以下语法:
```
if (test) { true_statements }
if (test) { true_statements } else { false_statements }
```
一个常见的用例是针对IPv4和IPv6执行不同操作的程序。例如:
```
if ($inet_family == $AF_INET) {
// IPv4
...
} else {
// IPv6
...
}
```
目前不支持"else if"语句。
5.10.4 Unrolled Loops
BPF 在一个受限环境中运行,必须能够验证程序是否会结束,而不会陷入无限循环。对于需要一些循环功能的程序,bpftrace 支持展开循环(unrolled loops)通过 unroll() 函数实现。
语法如下:
```
unroll (count) { statements }
```
count 是一个整数字面量(常数),最大为20。不支持将 count 作为变量提供,因为在 BPF 编译阶段必须知道循环迭代的次数。
Linux 5.3 内核开始支持了有界的 BPF 循环。未来版本的 bpftrace 应该支持这种能力,例如提供 for 和 while 循环,除了展开循环外。
5.11 bpftrace Operators
前面的部分列出了在测试中使用的布尔运算符。bpftrace 还支持以下运算符:
- =: 赋值
- +, -, *, /: 加法、减法、乘法、除法
- ++, --: 自增、自减
- &, |, ^: 位与、位或、位异或
- !: 逻辑非
- <<, >>: 左移、右移
- +=, -=, *=, /=, %=, &=, ^=, <<=, >>=: 复合赋值运算符
这些运算符的设计灵感来源于 C 编程语言中的类似运算符。
5.12 bpftrace Variables
如第5.7.10节介绍的那样,有三种变量类型:内建变量、临时变量和映射变量。
5.12.1 Built-in Variables
bpftrace 提供的内建变量通常用于只读访问信息。最重要的内建变量列在表5-5中。

目前所有整数都是 uint64 类型。这些变量都指向当前运行的线程、探针、函数和触发探针的 CPU。有关完整和更新的内建变量列表,请参阅在线的《bpftrace 参考指南》[66]。
5.12.2 Built-ins: pid, comm, and uid
许多内建变量使用起来很简单。以下示例使用 pid、comm 和 uid 打印调用 setuid() 系统调用的进程信息:

调用了系统调用并不意味着它一定成功。您可以通过使用不同的跟踪点追踪返回值:

这个示例使用了另一个内建变量 args。对于跟踪点,args 是一个结构体类型,提供了自定义字段。
5.12.3 Built-ins: kstack and ustack
kstack 和 ustack 返回内核级和用户级堆栈跟踪,以多行字符串的形式返回。它们最多返回127个堆栈帧的跟踪信息。稍后介绍的 kstack() 和 ustack() 函数允许您选择要返回的堆栈帧数。
例如,使用 kstack 打印块输入/输出插入时的内核堆栈跟踪:


每个堆栈跟踪以子到父的顺序打印,并且每个帧都以函数名 + 函数偏移量的形式显示。
这些堆栈内建变量也可以作为映射中的键使用,允许对它们进行频率统计。
例如,统计导致块输入/输出的内核堆栈:


这里只显示了最后两个堆栈,它们的计数分别为39和52。相比于打印每个堆栈,计数更为高效,因为堆栈跟踪在内核上下文中进行计数以提高效率。
5.12.4 Built-ins: Positional Parameters
位置参数是通过命令行传递给程序的,其基于shell脚本中使用的位置参数。$1 表示第一个参数,$2 表示第二个参数,依此类推。
例如,简单程序 watchconn.bt:

监视通过命令行传递的 PID:
```
# ./watchconn.bt 181
Attaching 2 probes...
Watching connect() calls by PID 181
PID 181 called connect()
[...]
```
这些位置参数还适用于以下调用类型:
```
bpftrace ./watchconn.bt 181
bpftrace -e 'program' 181
```
它们默认是整数类型。如果参数为字符串,则必须通过 str() 调用来访问。例如:
```
# bpftrace -e 'BEGIN { printf("Hello, %s!\n", str($1)); }' Reader
Attaching 1 probe...
Hello, Reader!
^C
```
如果访问的参数在命令行中未提供,则在整数上下文中为零,或者如果通过 str() 访问则为空字符串 ("")。
5.12.5 Scratch
格式:
$name
这些变量可以在动作子句中用于临时计算。它们的类型在第一次赋值时确定,可以是整数、字符串、结构指针或结构体。
5.12.6 Maps
格式:
@name
@name[key]
@name[key1, key2[, ...]]
这些变量使用BPF映射对象进行存储,这是一个哈希表(关联数组),可以用于不同的存储类型。可以使用一个或多个键存储值。映射必须具有一致的键和值类型。与临时变量一样,类型在首次赋值时确定,这包括对特殊函数的赋值。在映射中,类型包括键(如果存在)以及值。例如,请考虑以下首次赋值:
@start = nsecs;
@last[tid] = nsecs;
@bytes = hist(retval);
@who[pid, comm] = count();
@start 和 @last 映射变量都变成了整数类型,因为它们被赋予了整数类型的内置变量(nsecs),即纳秒级时间戳。@last 映射还需要一个整数类型的键,因为它使用了整数键(线程ID tid)。@bytes 映射变成了一种特殊类型,即二次幂直方图,它处理直方图的存储和打印。最后,@who 映射有两个键,一个是整数类型(pid),一个是字符串类型(comm),值是 count() 映射函数。
这些函数在第5.14节中有详细介绍。
5.13 bpftrace Functions
bpftrace提供了用于各种任务的内置函数。其中最重要的函数列在表5-6中。

其中一些函数是异步的:内核将事件排队,稍后在用户空间中处理。异步函数包括 printf()、time()、cat()、join() 和 system()。而 kstack()、ustack()、ksym() 和 usym() 则同步记录地址,但对符号进行异步翻译。
请参阅在线的“bpftrace参考指南”获取完整和更新的函数列表[66]。接下来的章节将讨论其中部分函数的选择。
5.13.1 printf()
printf() 调用,简称为格式化打印,在C语言和其他语言中的行为类似。语法如下:
printf(format [, arguments ...])
格式字符串可以包含任何文本消息,以及以‘\’开头的转义序列和以‘%’开头的字段描述。如果没有提供参数,则不需要字段描述。
常用的转义序列包括:
- \n:换行
- \":双引号
- \\:反斜杠
其他转义序列请参阅 printf(1) 的手册页。
字段描述以‘%’开头,格式如下:
% [-] width type
‘-’ 表示输出左对齐, 默认为右对齐。
width 是字段的宽度,即字符的数量。
type 可以是以下之一:
- %u, %d:无符号整数,整数
- %lu, %ld:无符号长整型,长整型
- %llu, %lld:无符号长长整型,长长整型
- %hu, %hd:无符号短整型,短整型
- %x, %lx, %llx:十六进制:无符号整数,无符号长整型,无符号长长整型
- %c:字符
- %s:字符串
例如,这个 printf() 调用:
printf("%16s %-6d\n", comm, pid)
将以 comm 内置变量作为宽度为16的字符串字段(右对齐),pid 内置变量作为宽度为6的整数字段(左对齐),并在之后换行打印。
5.13.2 join()
join() 是一个特殊的函数,用于将字符串数组使用空格字符连接并打印出来。语法如下:
join(char *arr[])
例如,下面这个一行命令展示了尝试执行带有参数的命令:
# bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
附加了 1 个探针...
ls -l
df -h
date
ls -l bashreadline.bt biolatency.bt biosnoop.bt bitesize.bt
它打印了 execve() 系统调用的 argv 数组参数。请注意,这显示了尝试的执行:syscalls:sys_exit_execve 跟踪点及其 args->ret 值显示了系统调用是否成功。
在某些情况下,join() 可能是一个方便的函数,但它对可以连接的参数数量和它们的大小有限制。如果输出显示被截断,很可能是因为已经达到了这些限制,需要使用不同的方法。
有工作正在进行,以改变 join() 的行为,使其返回一个字符串而不是直接打印。这会改变之前的 bpftrace 一行命令为:
# bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s\n", join(args->argv)); }'
这个变化也会使 join() 不再是一个异步函数。
5.13.3 str()
str() 函数从指针(char *)返回字符串。语法如下:
str(char *s [, int length])
例如,bash(1) shell 的 readline() 函数返回一个字符串,可以通过以下方式打印出来:
# bpftrace -e 'ur:/bin/bash:readline { printf("%s\n", str(retval)); }'
附加了 1 个探针...
ls -lh
date
echo hello BPF
^C
这个一行命令可以显示系统范围内所有 bash 交互命令。
默认情况下,字符串的大小限制为 64 字节,可以通过 bpftrace 环境变量 BPFTRACE_STRLEN 进行调整。目前不允许超过 200 字节的大小;这是一个已知的限制,未来可能会大幅增加这个限制。
5.13.4 kstack() and ustack()
kstack() 和 ustack() 类似于内置的 kstack 和 ustack,但它们接受一个限制参数和一个可选的模式参数。语法如下:
kstack(limit)
kstack(mode[, limit])
ustack(limit)
ustack(mode[, limit])
例如,通过跟踪 block:block_rq_insert 这个跟踪点,显示导致创建块 I/O 的前三个内核帧:


当前允许的最大堆栈大小为1024帧。
模式参数允许以不同的格式输出堆栈。目前仅支持两种模式:"bpftrace" 是默认模式;"perf" 模式生成类似于 Linux perf(1) 实用程序的堆栈格式。例如:

将来可能会支持其他模式。
5.13.5 ksym() and usym()
ksym() 和 usym() 函数将地址解析为它们的符号名称(字符串)。ksym() 用于内核地址,而usym() 用于用户空间地址。语法如下:
ksym(addr)
usym(addr)
例如,timer:hrtimer_start 跟踪点具有一个函数指针参数。频率计数:

这些是原始地址。使用 ksym() 将其转换为内核函数名称:

usym() 依赖于二进制文件中的符号表进行符号查找。
5.13.6 kaddr() and uaddr()
kaddr() 和 uaddr() 接受一个符号名称,并返回其地址。kaddr() 用于内核符号,而uaddr() 用于用户空间符号。语法如下:
kaddr(char *name)
uaddr(char *name)
例如,在调用 bash(1) shell 函数时查找用户空间符号 "ps1_prompt",然后对其进行解引用并将其打印为字符串:

这将打印符号的内容——在这种情况下是 bash(1) 的 PS1 提示符。
5.13.7 system()
system() 在 shell 中执行一个命令。语法如下:
system(char *fmt [, arguments ...])
由于可以在 shell 中运行任何命令,system() 被视为不安全的函数,并需要使用 --unsafe bpftrace 选项。
例如,调用 ps(1) 命令打印调用 nanosleep() 的 PID 的详细信息:

如果被跟踪的事件频繁发生,使用 system() 可能会创建大量新的进程事件,消耗 CPU 资源。只有在必要时才使用 system()。
5.13.8 exit()
这会终止 bpftrace 程序。语法如下:
exit()
此函数可用于间隔探针,以便在固定时间段内进行仪器化。例如:
```bash
# bpftrace -e 't:syscalls:sys_enter_read { @reads = count(); }
interval:s:5 { exit(); }'
```
正在附加 2 个探针...
@reads: 735
这显示在五秒钟内,发生了 735 次 read() 系统调用。在 bpftrace 终止时,所有映射都会被打印出来,如此示例所示。
5.14 bpftrace Map Functions
映射(Maps)是来自BPF的特殊哈希表存储对象,可以用于不同的目的,例如作为哈希表来存储键值对或用于统计摘要。bpftrace提供了用于映射赋值和操作的内置函数,主要用于支持统计摘要映射。最重要的映射函数列在表5-7中。

其中一些函数是异步的:内核会将事件加入队列,稍后在用户空间中处理。异步动作包括 print()、clear() 和 zero()。在编写程序时,请牢记这种延迟。
请查阅在线的《bpftrace参考指南》,了解完整和更新的函数列表[66]。本节将讨论其中一些函数的选择。
5.14.1 count()
计数(count())函数用于统计事件发生的次数。语法如下:
```bash
@m = count();
```
此函数可以与探针通配符和内建探针一起使用,用于计算事件的次数。


这种基本功能也可以通过使用 perf(1) 和 perf stat,以及 Ftrace 来实现。bpftrace 提供了更多的定制功能:BEGIN 探针可以包含 printf() 调用来解释输出,而 interval 探针则可以包含 time() 调用,为每个时间间隔添加时间戳。
5.14.2 sum(), avg(), min(), and max()
这些函数将基本统计数据(总和、平均值、最小值和最大值)存储为映射。语法如下:
```bash
sum(int n)
avg(int n)
min(int n)
max(int n)
```
例如,使用 sum() 函数来查找通过 read(2) 系统调用读取的总字节数:
```bash
# bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret > 0/ {
@bytes = sum(args->ret); }'
Attaching 1 probe...
^C
@bytes: 461603
```
这里将映射命名为“bytes”以注释输出。请注意,此示例使用过滤器确保 args->ret 是正数:read(2) 的正返回值表示读取的字节数,而负返回值表示错误码。这在 read(2) 的 man 手册中有详细说明。
5.14.3 hist()
hist() 函数将值存储在二的幂直方图中。语法如下:
```bash
hist(int n)
```
例如,统计成功的 read(2) 调用的大小直方图:

直方图对于识别诸如多峰分布和异常值等分布特征非常有用。这个示例直方图具有多个模式,一个模式是大小为0或更小的读取(小于零的将是错误码),另一个模式是大小为一字节,还有一个模式是大小在八到十六字节之间的读取。
区间符号的含义如下:
- "■ "[": 大于或等于
- "■ "]": 小于或等于
- "■ "(": 大于
- "■ ")": 小于
- "■ "…": 无穷大
例如,范围 "[4, 8)" 表示大于或等于四,但小于八(即从四到7.9999等)的数值。
5.14.4 lhist()
lhist() 函数将值存储为线性直方图。语法如下:
```bash
lhist(int n, int min, int max, int step)
```
例如,一个 read(2) 调用返回值的线性直方图:

输出显示大多数读取在零到(小于)100字节之间。使用与 hist() 相同的区间符号进行打印。"(..., 0)" 行显示了错误计数:在跟踪期间发生了101次 read(2) 错误。请注意,错误计数最好通过不同的方式查看,例如使用错误码的频率计数:

5.14.5 delete()
delete() 函数从映射中删除键/值对。语法如下:
```bash
delete(@map[key])
```
根据需要可以有多个键来匹配映射类型。
5.14.6 clear() and zero()
clear() 函数从映射中删除所有键/值对,而zero() 函数将所有值设置为零。语法如下:
```bash
clear(@map)
zero(@map)
```
当 bpftrace 终止时,默认会打印所有的映射。某些用于时间戳差值计算等用途的映射,并不打算作为工具输出的一部分。可以在 END 探针中清理它们,以防止它们自动打印出来:
```bash
[...]
END
{
clear(@start);
}
```
5.14.7 print()
print() 函数用于打印映射。语法如下:
```bash
print(@m [, top [, div]])
```
可以提供两个可选参数:top 参数为整数,用于指定只打印前几个条目;div 参数为整数,用于对值进行除法运算。
为了演示 top 参数的使用,以下示例打印以 "vfs_" 开头的前五个内核函数调用:

在跟踪过程中,vfs_read() 被调用次数最多(2921次)。
为了演示 div 参数的使用,以下示例记录了每个进程名中在 vfs_read() 函数中花费的时间,并以毫秒打印出来:

为什么需要使用除数呢?你可以尝试像这样编写程序代替:
```bash
@ms[comm] = sum((nsecs - @start[tid]) / 1000000);
```
然而,sum() 函数操作的是整数,并且小数部分会被向下取整(截断)。因此,任何小于一毫秒的持续时间都会被作为零来累加。这会导致由于舍入误差而破坏输出结果。
解决方案是先对纳秒进行 sum() 运算,这样可以保留亚毫秒的持续时间,然后将总和作为 print() 函数的参数进行除法运算。
未来 bpftrace 的改进可能会允许 print() 函数打印任何类型的数据,而不仅仅是映射,并且无需进行格式化。
5.15 bpftrace Future Work
在您阅读本书时,bpftrace 将会有一些计划中的新功能。请查看 bpftrace 的发布说明和存储库中的文档以获取这些新功能的详情:https://github.com/iovisor/bpftrace。
本书中不包含 bpftrace 源代码的计划更改。如果确实需要进行更改,请查看本书网站上的更新:http://www.brendangregg.com/bpf-performance-tools-book.html。
5.15.1 Explicit Address Modes
bpftrace 最重要的新功能将是明确的地址空间访问,以支持将来将 bpf_probe_read() 拆分为 bpf_probe_read_kernel() 和 bpf_probe_read_user() [69]。这种拆分是为了支持某些处理器架构。这不应该影响本书中的任何工具。这将导致添加 kptr() 和 uptr() bpftrace 函数来指定地址模式。需要使用这些函数的情况应该很少:bpftrace 将尽可能根据探测类型或使用的函数确定地址空间上下文。以下展示了探测上下文的工作方式:
kprobe/kretprobe(内核上下文):
- arg0...argN、retval:当解引用时,是内核地址。
- *addr:解引用内核地址。
- str(addr):获取一个以 NULL 结尾的内核字符串。
- *uptr(addr):解引用用户地址。
- str(uptr(addr)):获取一个以 NULL 结尾的用户字符串。
uprobe/uretprobe(用户上下文):
- arg0...argN、retval:当解引用时,是用户地址。
- *addr:解引用用户地址。
- str(addr):获取一个以 NULL 结尾的用户字符串。
- *kptr(addr):解引用内核地址。
- str(kptr(addr)):获取一个以 NULL 结尾的内核字符串。
因此,*addr 和 str() 将继续工作,但会参考探测上下文的地址空间:对于 kprobe,是内核内存;对于 uprobe,是用户内存。要跨越地址空间,必须使用 kptr() 和 uptr() 函数。某些函数,例如 curtask(),将始终返回一个内核指针,无论上下文是什么(正如所预期的那样)。
其他探测类型默认为内核上下文,但会有一些例外情况,详见“bpftrace 参考指南” [66]。其中一个例外是系统调用追踪点,它们引用用户地址空间指针,因此它们的探测动作将在用户空间上下文中执行。
5.15.2 Other Additions
其他计划的新增功能包括:
- 针对内存监视点、套接字和skb程序以及原始tracepoints的额外探测类型
- uprobes 和 kprobes 函数偏移探测
- 在 Linux 5.3 中利用 BPF 有界循环的 for 和 while 循环
- 原始 PMC 探测(提供 umask 和事件选择)
- uprobes 还支持相对名称而非完整路径(例如,uprobe:/lib/x86_64-linux-gnu/libc.so.6:... 和 uprobe:libc:... 都应该能够工作)
- signal() 提升信号(包括 SIGKILL)到进程
- return() 或 override() 重写事件返回(使用 bpf_override_return())
- ehist() 用于指数直方图。任何当前使用二次幂 hist() 的工具或单行命令都可以切换到 ehist() 以获得更高的分辨率。
- pcomm 返回进程名称。comm 返回线程名称,通常相同,但某些应用程序(如 Java)可能会将 comm 设置为每个线程的名称;在这种情况下,pcomm 仍将返回 "java"。
- 为 struct file 指针提供完整路径名的辅助函数。
一旦这些新增功能可用,您可能希望将本书中的某些工具从 hist() 切换到 ehist() 以获得更高的分辨率,并且某些 uprobes 工具可以使用相对库名称而非完整路径,以便更易使用。
5.15.3 ply
ply BPF前端由Tobias Waldekranz创建,提供类似于bpftrace的高级语言,并且需要最少的依赖(无需LLVM或Clang)。这使其适用于资源受限环境,但缺点是无法进行结构体导航和包含头文件(这些是本书中许多工具所需的功能)。
一个ply仪表化open(2) tracepoint的示例:

上面的单行命令与bpftrace中的等效命令几乎完全相同。未来版本的ply可能直接支持bpftrace语言,提供一个轻量级工具来运行bpftrace的单行命令。这些单行命令通常不使用除了跟踪点参数之外的结构体导航(正如这个例子所示),而ply已经支持这种功能。在遥远的未来,随着BTF的可用性,ply可以使用BTF获取结构信息,从而能够运行更多的bpftrace工具。
5.16 bpftrace Internals

bpftrace使用libbcc和libbpf来连接探针、加载程序并使用USDT。它还使用LLVM将程序编译为BPF字节码。
bpftrace语言由通过flex和bison处理的lex和yacc文件定义。输出是作为抽象语法树(AST)的程序。然后跟踪点和Clang解析器处理结构体。语义分析器检查语言元素的使用,并在误用时抛出错误。接下来是代码生成——将AST节点转换为LLVM IR,最终由LLVM编译为BPF字节码。
接下来的部分介绍了bpftrace调试模式,显示这些步骤的操作:使用-d选项打印AST和LLVM IR,使用-v选项打印BPF字节码。
5.17 bpftrace Debugging
有多种方法可以调试和排除bpftrace程序的问题。本节总结了printf()语句和bpftrace调试模式。如果您因为要解决问题而来到这里,还可以查看第18章,其中涵盖常见问题,包括事件丢失、堆栈丢失和符号丢失。
虽然bpftrace是一种强大的语言,但它实际上由一组严格的功能组成,旨在安全地协同工作并拒绝误用。相比之下,BCC允许使用C和Python程序,它使用了一个更大的功能集合,这些功能不仅仅设计用于跟踪,并且可能无法完全协同工作。结果是,bpftrace程序通常会以人类可读的消息失败,不需要进一步的调试,而BCC程序可能会以意外的方式失败,并且需要调试模式来解决问题。
5.17.1 printf() Debugging
printf()语句可以添加以显示探针是否真正触发,以及变量是否符合您的预期。考虑以下程序:它打印了一个vfs_read()持续时间的直方图。然而,如果您运行它,您可能会发现输出包含持续时间非常高的异常值。您能发现bug吗?

如果bpftrace在vfs_read()调用进行到一半时开始运行,那么只有kretprobe会触发,而延迟计算会变成"nsecs - 0",因为@start[tid]未初始化。修复方法是在kretprobe上使用过滤器,在计算中使用它之前检查@start[tid]是否非零。可以通过printf()语句调试此问题以检查输入:
printf("$duration_ms = (%d - %d) / 1000000\n", nsecs, @start[tid]);
虽然有bpftrace调试模式(接下来会介绍),但像这样的bug可以通过适时放置的printf()语句迅速解决。
5.17.2 Debug Mode
bpftrace的-d选项运行调试模式,它不会运行程序,而是显示程序如何被解析并转换为LLVM IR。请注意,这种模式可能只对bpftrace开发者真正感兴趣,这里提及它只是为了增加认识。
调试模式首先会打印程序的抽象语法树(AST)表示:



还有一个-dd模式,即详细调试模式,它会打印额外的信息:LLVM IR汇编在优化前后的输出。
5.17.3 Verbose Mode
bpftrace的-v选项是详细模式,运行程序时打印额外的信息。例如:


程序ID可与bpftool一起使用,用于打印BPF内核状态的信息,如第2章所示。然后打印BPF字节码,接着是它所附加的探测器。
与-d选项一样,这种详细程度可能只对bpftrace内部的开发人员有用。用户在使用bpftrace时不需要阅读BPF字节码。
5.18 Summary
bpftrace是一个功能强大的追踪工具,具备简洁的高级语言。本章描述了它的特性、工具以及一行命令的示例。还涵盖了编程内容,并提供了关于探针、流控制、变量和函数的部分。章节最后讨论了调试和内部结构。
接下来的章节涵盖了分析的目标,并包括BCC和bpftrace工具。bpftrace工具的一个优势是它们的源代码通常非常简洁,可以包含在本书中。
6 CPUs
CPUs执行所有软件,并且是性能分析的常见起点。如果发现工作负载受到CPU限制(即“CPU绑定”),可以进一步使用与CPU和处理器相关的工具进行调查。有无数的采样分析器和度量工具可帮助您了解CPU使用情况。然而(也许令人惊讶的是),BPF追踪在CPU分析的许多领域仍然可以提供更深入的帮助。
学习目标:
■ 理解CPU模式、CPU调度器的行为以及CPU缓存
■ 了解使用BPF进行CPU调度器、使用情况和硬件分析的领域
■ 学习成功分析CPU性能的策略
■ 解决消耗CPU资源的短生命周期进程问题
■ 发现并量化运行队列延迟问题
■ 通过分析栈跟踪和函数计数来确定CPU使用率
■ 确定线程阻塞并离开CPU的原因
■ 通过跟踪系统调用了解系统CPU时间
■ 调查软中断和硬中断引起的CPU消耗
■ 使用bpftrace一行命令以自定义方式探索CPU使用情况
本章从您理解CPU分析所需的背景开始,总结了CPU调度器和CPU缓存的行为。我探讨了BPF可以回答的问题,并提供了一个总体策略。为了避免重复造轮子并指导进一步的分析,我首先总结了传统CPU工具,然后是BPF工具,包括BPF一行命令的列表。本章以可选练习结束。
6.1 Background
本节涵盖了CPU基础知识、BPF的能力以及CPU分析的建议策略。
6.1.1 CPU Fundamentals
CPU模式
CPU和其他资源由运行在特权状态下的内核管理,这种特权状态称为系统模式。用户级应用程序则在用户模式下运行,只能通过内核请求访问资源。这些请求可以是显式的,例如系统调用,也可以是隐式的,比如由内存加载和存储引发的页面错误。内核追踪CPU空闲时间以及在用户模式和系统模式下的CPU时间。各种性能工具显示了这种用户/系统时间分割。
内核通常只在需要fan时运行,由系统调用和中断触发。也有一些例外,例如在后台运行的系统维护线程,消耗CPU资源。例如,在非一致存储访问(NUMA)系统上平衡内存页面的内核例程,可以在没有用户级应用程序显式请求的情况下消耗大量CPU资源(这可以进行调整或禁用)。一些文件系统还有后台例程,例如定期验证数据完整性的校验和。
CPU调度器
内核还负责通过CPU调度器在消费者之间共享CPU资源。主要的消费者是属于进程或内核例程的线程(也称为任务)。其他CPU消费者包括中断例程:这些可以是由运行软件引发的软中断,或由硬件引发的硬中断。
图6-1展示了CPU调度器,描述了线程如何在运行队列中等待执行机会,以及它们如何在不同线程状态之间移动。
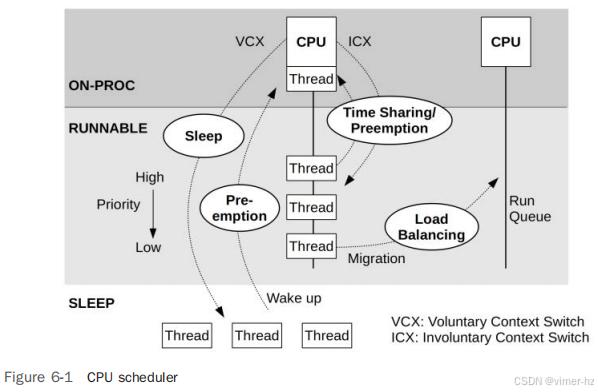
这个图表显示了三种线程状态:ON-PROC表示正在CPU上运行的线程,RUNNABLE表示可以运行但正在等待轮到它们执行的线程,SLEEP表示因等待其他事件(包括不可中断等待)而被阻塞的线程。在运行队列上等待的线程按优先级值排序,这些值可以由内核或用户进程设置,以提升更重要任务的性能。虽然调度最初是通过运行队列实现的,并且术语和心理模型仍然用于描述等待任务,但Linux CFS调度器实际上使用未来任务执行的红黑树。
本书使用基于这些线程状态的术语: "on CPU"指代ON-PROC,而 "off CPU"指代所有其他状态,即线程未在CPU上运行时的状态。
线程以两种方式离开CPU:(1)自愿地,如果它们因I/O、锁或休眠而阻塞;或者(2)非自愿地,如果它们超过了分配的CPU时间,并因此被调度程序使其它线程可以运行,或者被优先级更高的线程抢占。当CPU从一个进程或线程切换到另一个时,它会切换地址空间和其他元数据;这称为上下文切换。
图6-1还显示了线程迁移。如果一个线程处于可运行状态并在运行队列中等待,而另一个CPU处于空闲状态,调度程序可以将该线程迁移到空闲CPU的运行队列中,以便更快地执行。作为性能优化,调度程序使用逻辑来避免成本预期超过收益时的迁移,更倾向于在同一CPU上运行忙碌线程,以保持CPU缓存处于热状态。
CPU缓存
尽管图6-1展示了CPU的软件视图(调度程序),图6-2提供了CPU缓存的硬件视图。
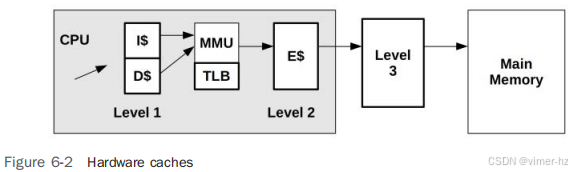
根据处理器型号和类型的不同,通常会有多层CPU缓存,它们在大小和延迟上逐级增加。它们从第一级缓存开始,该级别分为独立的指令缓存(I$)和数据缓存(D$),容量较小(几KB)且速度快(纳秒级)。缓存以最后一级缓存(LLC)结束,该级别容量大(几MB)但速度较慢。在具有三级缓存的处理器上,LLC也同时兼作第三级缓存。第一级和第二级缓存通常是每个CPU核心独享的,而第三级缓存通常是在整个插槽(socket)上共享的。内存管理单元(MMU)负责将虚拟地址转换为物理地址,还有其自己的缓存,称为转换后备缓冲器(TLB)。
几十年来,CPU通过提高时钟速度、增加核心数和硬件线程数量来进行扩展。内存带宽和延迟也有所改善,特别是通过增加和扩大CPU缓存的方式。然而,与CPU核心相比,内存性能的提升并没有达到同样的程度。工作负载已经受到内存性能限制(称为“内存限制”),而非CPU核心。
进一步阅读:
这篇简要概述为您提供了一些使用工具之前必备的基本知识。有关CPU软件和硬件的更深入讨论可在《系统性能》的第6章中找到[Gregg 13b]。
6.1.2 BPF Capabilities
传统性能工具提供了各种关于CPU使用情况的见解。例如,它们可以显示进程的CPU利用率、上下文切换率和运行队列长度。这些传统工具在下一节中进行了总结。
BPF跟踪工具可以提供许多额外的详细信息,回答如下问题:
- 新创建的进程是什么?它们的生命周期如何?
- 系统时间为什么高?系统调用是否是罪魁祸首?它们在做什么?
- 每次唤醒后,线程在CPU上的花费时间有多长?
- 线程在运行队列上等待的时间有多长?
- 运行队列的最大长度是多少?
- 运行队列在多个CPU之间是否平衡?
- 线程为什么会自愿离开CPU?离开多长时间?
- 哪些软中断和硬中断正在占用CPU?
- 当其他运行队列上有可用工作时,CPU多久闲置一次?
- 每个应用请求的LLC命中率是多少?
通过在调度器和系统调用事件的跟踪点、调度器内部函数的kprobes、应用程序级函数的uprobes以及定时采样和低级CPU活动的PMC来实现这些问题的回答。这些事件源还可以混合使用:一个BPF程序可以使用uprobes获取应用程序上下文,然后将其与已经instrumented的PMC事件关联起来。例如,这样的程序可以显示每个应用请求的LLC命中率。
BPF提供的指标可以按事件或摘要统计进行检查,并以直方图显示分布。还可以获取堆栈跟踪以显示事件原因。所有这些活动都通过内核中的BPF映射和输出缓冲区进行了优化以提高效率。
事件源
表6-1列出了用于检测CPU使用情况的事件源。
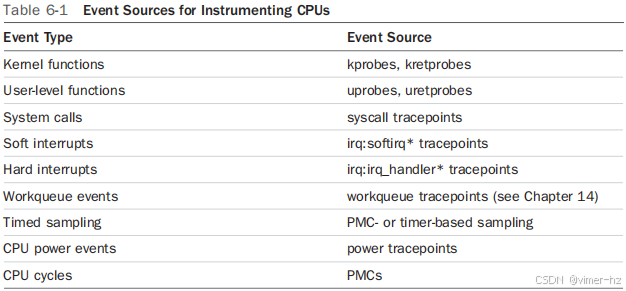
开销
在跟踪调度器事件时,效率尤为重要,因为诸如上下文切换之类的调度器事件可能每秒发生数百万次。虽然BPF程序很短且执行速度快(微秒级),但为每个上下文切换执行它们可能会导致这种微小的开销累积成可测量甚至显著的影响。在最坏的情况下,调度器跟踪可能会给系统增加超过10%的开销。如果没有优化BPF,这种开销将是难以接受的高昂费用。
使用BPF进行调度器跟踪可以用于短期的即时分析,但需要理解会有开销。可以通过测试或实验来量化这种开销,以确定:如果CPU利用率从一秒钟到下一秒钟保持稳定,在运行和不运行BPF工具时的差异是多少?
CPU工具可以通过不对频繁的调度器事件进行仪器化来避免开销。不频繁发生的事件,如进程执行和线程迁移(每秒最多几千次事件),可以带来可忽略的开销。定时采样(分析)还将开销限制在固定的采样率,将开销降至可以忽略的程度。
6.1.3 Strategy
如果你对CPU性能分析还不熟悉,可能不知道从何开始,应该分析哪个目标和使用哪种工具。以下是建议的整体策略,供参考:
1. 在使用分析工具之前,请确保有一个CPU工作负载在运行。检查系统的CPU利用率(例如使用mpstat(1)),确保所有CPU仍然在线(并且没有因某种原因被离线)。
2. 确认工作负载是否受限于CPU性能。
a. 查看系统范围内或单个CPU的高CPU利用率(例如使用mpstat(1))。
b. 查看高运行队列延迟(例如使用BCC的runqlat(1))。像容器这样的软件限制可能会人为地限制进程可用的CPU资源,因此一个应用程序可能在大部分空闲系统上受限于CPU。通过研究运行队列延迟可以识别这种反直觉的情况。
3. 量化CPU使用率,包括系统范围内的百分比利用率以及按进程、CPU模式和CPU ID进行的细分。这可以通过传统工具完成(例如mpstat(1)、top(1))。查找单个进程、模式或CPU的高利用率。
a. 对于高系统时间,通过进程和调用类型频率计数系统调用,并检查参数以查找低效性(例如使用perf(1)、bpftrace的单行命令和BCC的sysstat(8))。
4. 使用分析器对采样堆栈进行采样,可以通过CPU火焰图进行可视化。许多CPU问题可以通过浏览这样的火焰图找到。
5. 针对分析器确定的CPU消耗者,考虑编写自定义工具以显示更多上下文。分析器显示正在运行的函数,但不显示它们操作的参数和对象,这可能需要理解CPU使用情况。例如:
a. 内核模式:如果文件系统在执行对文件的stat()操作时消耗CPU资源,那么它们的文件名是什么?(例如可以使用BCC的statsnoop(8)来确定,或者一般使用BPF工具的tracepoints或kprobes。)
b. 用户模式:如果一个应用程序正在忙于处理请求,这些请求是什么?(如果没有应用程序特定的工具,可以使用USDT或uprobes和BPF工具开发一个。)
6. 测量硬件中断的时间,因为这段时间在基于定时器的分析器中可能不可见(例如BCC的hardirqs(1))。
7. 浏览并执行本章节列出的BPF工具中的工具。
8. 使用PMCs测量每周期的CPU指令数(IPC),以高层次解释CPU的停滞程度(例如使用perf(1))。可以使用更多的PMCs来探索低缓存命中率(例如BCC的llcstat)、温度停滞等等。
接下来的章节会更详细地解释这个过程中涉及的工具。
6.2 Traditional Tools
传统工具(参见表6-2)可以为每个进程(线程)和每个CPU提供CPU利用率指标,可自愿和非自愿上下文切换率,平均运行队列长度以及在运行队列上等待的总时间。分析器可以显示和量化正在运行的软件,而基于PMC的工具可以显示CPU在周期级别上的运行情况。除了解决问题外,传统工具还可以提供线索,指导您进一步使用BPF工具。这些工具根据其来源和测量类型进行了分类:内核统计信息、硬件统计信息和事件跟踪。
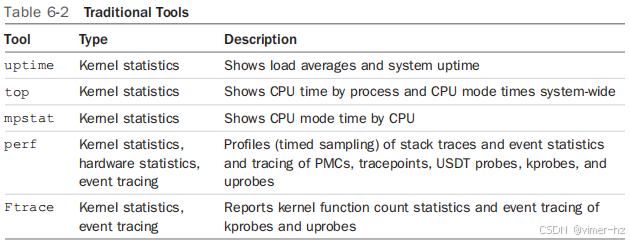
以下各节总结了这些工具的关键功能。更多的使用方法和解释,请参考它们的man页面和其他资源,包括《Systems Performance》[Gregg 13b]。
6.2.1 Kernel Statistics
Kernel statistics tools utilize statistical sources within the kernel, often accessible via the /proc interface. One advantage of these tools is that the metrics are typically enabled by the kernel itself, resulting in minimal additional overhead when using them. Moreover, they often permit access by non-root users.
**负载平均数**
uptime(1) 是几个打印系统负载平均数的命令之一:
```bash
$ uptime
00:34:10 up 6:29, 1 user, load average: 20.29, 18.90, 18.70
```
最后三个数字分别是1分钟、5分钟和15分钟的负载平均数。通过比较这些数字,您可以确定在过去约15分钟内负载是增加、减少还是稳定的。这个输出来自一个48-CPU的生产云实例,显示在比较1分钟(20.29)和15分钟(18.70)的负载平均数时,负载略有增加。
负载平均数不是简单的平均值,而是指数衰减移动总和,反映超过1分钟、5分钟和15分钟的时间段。这些汇总的指标显示了系统的需求:处于CPU可运行状态的任务以及处于不可中断等待状态的任务[72]。如果您假设负载平均数显示了CPU负载,您可以将它们除以CPU数量,以查看系统是否运行在CPU饱和状态,这将由超过1.0的比率表示。然而,负载平均数存在一些问题,包括它们包括不可中断任务(阻塞在磁盘I/O和锁中的任务),这对其解释构成了怀疑,因此它们仅在长时间内观察趋势时才真正有用。您必须使用其他工具,比如基于BPF的offcputime(8),来查看负载是基于CPU还是不可中断时间的。有关offcputime(8)的信息,请参见第6.3.9节,有关测量不可中断I/O的更多信息,请参见第14章。
top
top(1) 工具以进程详细信息表格的形式显示最消耗CPU的顶级进程,同时显示系统的头部摘要信息:
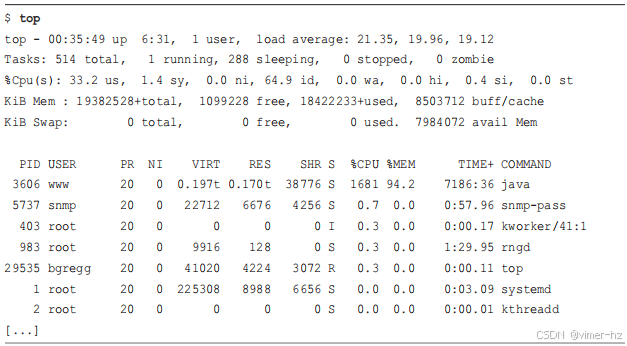
这段文字描述的是一个生产实例的输出,显示了仅有一个消耗CPU资源的进程:一个Java进程总共消耗了1681%的CPU,这个数字是在所有CPU上的总和。对于这个拥有48个CPU的系统,输出显示这个Java进程占据了总体CPU容量的35%。这与系统范围内的CPU平均利用率相符,头部摘要显示为34.6%(用户占比33.2%,系统占比1.4%)。
top(1) 尤其有助于识别由意外进程引起的CPU负载问题。常见的软件bug类型会导致线程陷入无限循环,这种情况可以很容易地通过top(1)找到,因为它会显示100% CPU运行的进程。进一步的分析可以使用性能分析器和BPF工具确认进程是否被卡在循环中,而不是在忙于处理工作。
top(1) 默认刷新屏幕,使其像实时仪表板一样工作。这也是一个问题:问题可能会在你截取屏幕截图之前出现和消失。将工具输出和截图添加到工单系统中对追踪性能问题和与他人分享信息至关重要。如pidstat(1)可用于此类目的,打印进程CPU使用的滚动输出;如果已使用监控系统,则可能已经记录了进程的CPU使用情况。
还有其他top(1)的变体,如htop(1),具有更多的自定义选项。不幸的是,许多top(1)变体侧重于视觉增强而非性能指标,使它们看起来更美观,但无法揭示原始top(1)以外的问题。例外包括tiptop(1),它使用PMCs作为数据来源;atop(1),它使用进程事件显示短暂的进程;以及biotop(8)和tcptop(8)工具,它们使用BPF(我开发的)作为数据源。
mpstat
mpstat(1)可以用来检查每个CPU的指标:
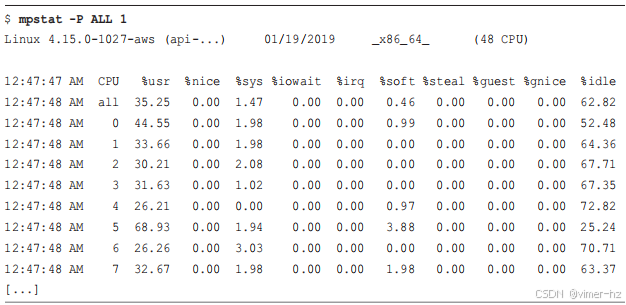
由于在这个有48个CPU的系统上,mpstat(1)每秒会打印48行输出,每行总结一个CPU的情况,因此这里显示的输出已被截断。这些输出可以用来识别平衡问题,即一些CPU的利用率很高,而其他CPU则处于空闲状态。CPU的不平衡可能由多种原因引起,比如配置错误的应用程序使用的线程池大小过小,无法充分利用所有CPU;软件限制将进程或容器限制在部分CPU上;以及软件bug。
时间在各个CPU之间被分为多种模式,包括硬中断时间(%irq)和软中断时间(%soft)。可以进一步使用hardirqs(8)和softirqs(8)的BPF工具来进行调查。
6.2.2 Hardware Statistics
硬件也可以作为统计数据的有用来源,特别是在CPU上可用的性能监控计数器(PMC)。PMC在第二章中介绍过。
perf(1)
Linux的perf(1)是一个多功能工具,支持不同的仪器来源和数据展示方式。它首次添加到Linux内核中是在2.6.31版本(2009年),被认为是标准的Linux性能分析器,其代码可以在Linux源代码的 tools/perf 目录下找到。我已经发布了一个详细的使用perf的指南 [73]。它的许多强大功能之一是能够在计数模式下使用PMC:
perf stat命令用-e参数指定要计数的事件。如果没有提供这些参数,它会默认使用基本的PMC集合,或者如果使用了-d参数,则使用扩展的集合,如下所示。输出和使用方式会根据你使用的Linux版本和处理器类型可用的PMC而略有不同。这个例子展示了在Linux 4.15上使用perf(1)。
根据你的处理器类型和perf版本,你可以使用perf list来获取PMC的详细列表。

这个输出显示了你可以在-e参数中使用的别名。例如,你可以在所有CPU上统计这些事件(使用-a,这最近变成了默认行为),并以1000毫秒的间隔打印输出:

这个输出显示了系统范围内这些事件的每秒速率。
有数百种PMC可用,详细记录在处理器供应商的指南中 [Intel 16] [AMD 10]。你可以与特定模型寄存器(MSR)一起使用PMC,以确定CPU内部组件的性能如何,CPU的当前时钟速率,它们的温度和能耗,CPU互连和内存总线的吞吐量等等。
tlbstat
作为PMC的一个示例用途,我开发了tlbstat工具来统计和总结与转换后备缓冲区(TLB)相关的PMC。我的目标是分析Linux内核页表隔离(KPTI)补丁的性能影响,这些补丁是为了解决Spectre漏洞 [74] [75]。
tlbstat打印以下列:
- K_CYCLES:CPU周期(每1000个单位)
- K_INSTR:CPU指令(每1000个单位)
- IPC:每周期指令数
- DTLB_WALKS:数据TLB行走(计数)
- ITLB_WALKS:指令TLB行走(计数)
- K_DTLBCYC:至少一个页面失效处理程序(PMH)活跃时,数据TLB行走的周期数(每1000个单位)
- K_ITLBCYC:至少一个PMH活跃时,指令TLB行走的周期数(每1000个单位)
- DTLB%:数据TLB活跃周期占总周期的比率
- ITLB%:指令TLB活跃周期占总周期的比率
之前显示的输出来自一项压力测试,其中KPTI的开销最大:显示数据TLB占27%的CPU周期,指令TLB占22%的CPU周期。这意味着系统范围内一半的CPU资源被用于内存管理单元服务虚拟到物理地址的转换。如果tlbstat在生产工作负载中显示类似的数字,你可能需要将优化工作集中在TLB上。
6.2.3 Hardware Sampling
perf(1)可以在不同的模式下使用PMC,在这种模式下选择一个计数,在每个计数的频率下,一个PMC事件会导致发送中断到内核,以便它可以捕获事件状态。例如,下面的命令记录了所有CPU上持续10秒钟的L3缓存未命中事件的堆栈跟踪(-g),其中“-e ...”用于指定事件:
```
perf record -a -g -e ... -- sleep 10
```
这里的`sleep 10`是一个用来设置持续时间的虚拟命令。
这个输出展示了一个单独的堆栈跟踪样本。堆栈按从子到父的顺序列出,本例中显示了导致L3缓存未命中事件的内核函数。
请注意,尽可能使用支持精确事件基础抽样(PEBS)的PMC来最小化中断偏移问题。
PMC硬件抽样也可以触发BPF程序。例如,可以在内核上下文中通过BPF对抽样的堆栈跟踪进行频率计数,而不是通过perf缓冲区将所有样本的堆栈跟踪转储到用户空间,以提高效率。
6.2.4 Timed Sampling
许多性能分析器支持基于定时器的抽样(在定时间隔内捕获指令指针或堆栈跟踪)。这些分析器提供了一个粗略的、成本较低的视图,用于查看哪些软件消耗了CPU资源。有不同类型的分析器,一些仅在用户模式下运行,而另一些在内核模式下也能操作。通常更倾向于使用内核模式分析器,因为它们可以捕获内核和用户级堆栈,提供更完整的视图。
perf
perf(1) 是一个基于内核的性能分析器,支持通过软件事件或PMC进行定时抽样:它默认使用目前最精确的技术。在这个例子中,它以每秒每CPU 99次的频率(即99 Hertz)在30秒内捕获所有CPU上的堆栈:
# perf record -F 99 -a -g -- sleep 30
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.661 MB perf.data (2890 samples) ]
选择99 Hertz 而不是100 Hertz,是为了避免与其他软件例程的同步采样,否则会使样本产生偏差。这在第18章中有更详细的解释。选择大约100而不是比如10或10000,是为了在详细程度和开销之间取得平衡:如果太低,就无法得到足够的样本来完整地查看执行过程,包括大和小的代码路径;如果太高,样本的开销会影响性能和结果的准确性。
当运行这个perf(1)命令时,它会将样本写入一个perf.data文件:通过使用内核缓冲区和最优化的文件系统写入次数来进行优化。输出告诉我们它只需要唤醒一次来写入这些数据。
可以使用perf report来汇总输出,或者使用perf script来逐个样本进行转储。例如:
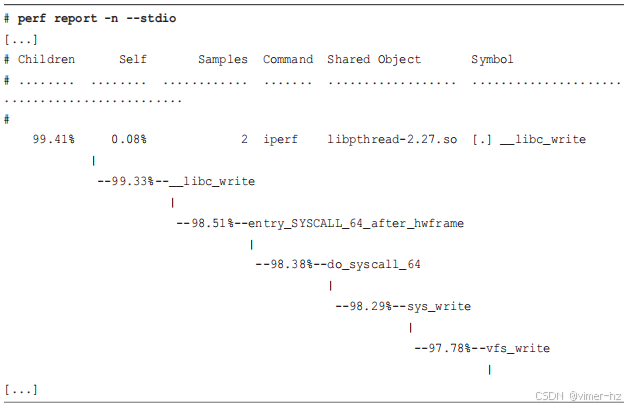
perf report的摘要显示了从根到子函数的函数树。(顺序可以反转,这在早期版本中是默认的。)不幸的是,从这个输出样本中很难得出什么确凿的结论——完整的输出有六千行。而perf script的完整输出,每个事件都进行了转储,有超过六万行。在更繁忙的系统上,这些分析文件可能会轻松达到这个大小的10倍。在这种情况下的解决方案是将堆栈样本可视化为火焰图。
CPU火焰图
火焰图在第2章引入,能够可视化堆栈跟踪。它们非常适合CPU分析,现在已经广泛用于CPU分析。
图6-3中的火焰图总结了前一节捕获的相同的分析数据。
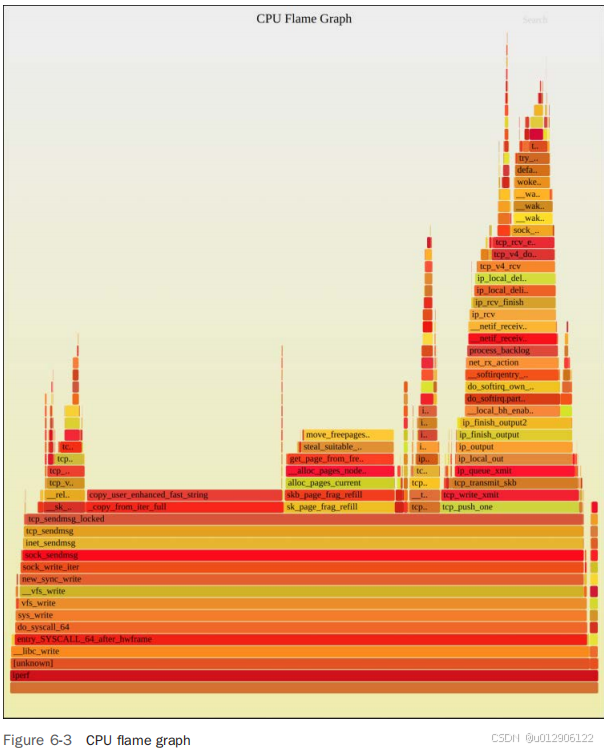
当这些数据被呈现为火焰图时,很容易看出名为iperf的进程正在消耗所有的CPU资源,以及具体是如何消耗的:通过sock_sendmsg()函数,导致两个高频CPU函数,即copy_user_enhanced_fast_string()和move_freepages_block(),显示为两个高原。在右侧是一个向后延伸到TCP接收路径的塔形结构;这表示iperf正在执行一个回环测试。
以下是使用perf(1)创建CPU火焰图的步骤,以便在49赫兹的频率下对堆栈进行30秒的采样,以及我的原始火焰图实现:
```bash
# git clone https://github.com/brendangregg/FlameGraph
# cd FlameGraph
# perf record -F 49 -ag -- sleep 30
# perf script --header | ./stackcollapse-perf.pl | ./flamegraph.pl > flame1.svg
```
stackcollapse-perf.pl程序将perf script的输出转换为flamegraph.pl程序可读的标准格式。FlameGraph仓库中还有其他分析器的转换工具。flamegraph.pl程序将生成一个包含嵌入式JavaScript以实现交互性的SVG格式的火焰图文件。flamegraph.pl支持许多选项进行自定义:运行`flamegraph.pl --help`获取详细信息。
我建议保存`perf script --header`的输出以备后续分析。Netflix开发了一个新的火焰图实现,使用d3和一个额外的工具FlameScope,可以读取perf script的输出并将其可视化为亚秒偏移热图,以便选择时间范围查看火焰图。[76] [77]
Internals
当perf(1)进行定时采样时,它会尝试使用基于PMC的硬件CPU周期溢出事件触发非可屏蔽中断(NMI)进行采样。然而,在云环境中,许多实例类型未启用PMC。这可以在dmesg(1)中看到:
```bash
# dmesg | grep PMU
[ 2.827349] Performance Events: unsupported p6 CPU model 85 no PMU driver,
software events only.
```
在这些系统上,perf(1)会回退到基于hrtimer的软件中断。当使用-v参数运行perf时可以看到这一点:
```bash
# perf record -F 99 -a -v
Warning:
The cycles event is not supported, trying to fall back to cpu-clock-ticks
[...]
```
这种软件中断通常是足够的,但请注意,它无法中断一些内核代码路径,如禁用IRQ的路径(包括调度和硬件事件中的某些代码路径)。因此,生成的性能分析数据会缺少这些代码路径的样本。
关于PMC的更多信息,请参阅第2章中的第2.12节。
6.2.5 Event Statistics and Tracing
工具可以追踪事件,也可用于CPU分析。传统的Linux工具包括perf(1)和Ftrace。这些工具不仅可以追踪事件并保存每个事件的详细信息,还可以在内核上下文中计算事件次数。
perf
perf(1)可以对tracepoints、kprobes、uprobes以及最近新增的USDT probes进行仪器化。这些功能能够提供CPU资源消耗的逻辑上下文。
例如,考虑一个系统中整体CPU利用率很高的问题,但在top(1)中找不到明显的负责进程。问题可能是短暂的进程。为了验证这个假设,可以使用perf script对系统范围内的sched_process_exec tracepoint进行计数,以展示exec()家族系统调用的速率:
输出显示,执行的进程包括名称为make、sh和cmake的进程,这让我怀疑是软件构建造成的问题。短暂的进程是一个如此常见的问题,以至于专门有一个用于此的BPF工具:execsnoop(8)。输出中的字段包括:进程名称、PID、[CPU]、时间戳(秒)、事件名称和事件参数。
perf(1)有一个专门用于CPU调度器分析的特殊子命令,称为perf sched。它使用转储和后处理的方法来分析调度器行为,并提供各种报告,可以显示每次唤醒的CPU运行时间、平均和最大调度延迟,以及ASCII可视化,展示每个CPU上的线程执行情况和迁移。以下是一些示例输出:
输出内容详尽,将所有调度器上下文切换事件以线条摘要显示,包括睡眠时间(等待时间)、调度延迟(sch延迟)和CPU运行时间,所有时间单位均为毫秒。此输出显示了一个睡眠了1秒的sleep(1)命令,以及一个运行了9.9毫秒并睡眠了19.9毫秒的cc1进程。
perf sched子命令可以帮助解决多种类型的调度器问题,包括与内核调度器实现相关的问题(内核调度器是一个复杂的代码,需要平衡多种需求)。然而,转储和后处理的风格成本高昂:例如,这个示例在一个八核系统上记录了1秒钟的调度器事件,生成了一个1.9兆字节的perf.data文件。在一个更大、更繁忙的系统上,并且持续时间更长的情况下,该文件可能会达到数百兆字节,这可能会导致生成文件所需的CPU时间增加,同时文件系统I/O写入磁盘也会成为问题。
为了理解如此多的调度器事件,通常会对perf(1)的输出进行可视化。perf(1)还有一个用于自身可视化的timechart子命令。
在可能的情况下,我建议使用BPF而不是perf sched,因为它可以进行内核摘要,回答类似的问题并生成结果(例如,runqlat(8)和runqlen(8)工具,在第6.3.3节和第6.3.4节中有详细介绍)。
Ftrace
Ftrace是由Steven Rostedt开发的一组不同的跟踪功能,首次添加到Linux 2.6.27(2008年)。与perf(1)类似,它也可以通过跟踪点和其他事件来探索CPU使用的上下文。
例如,我的perf-tools集合[78]主要使用Ftrace进行仪器化,包括funccount(8)用于函数计数。这个示例通过匹配以"ext"开头的文件系统调用来统计ext4文件系统的调用次数:
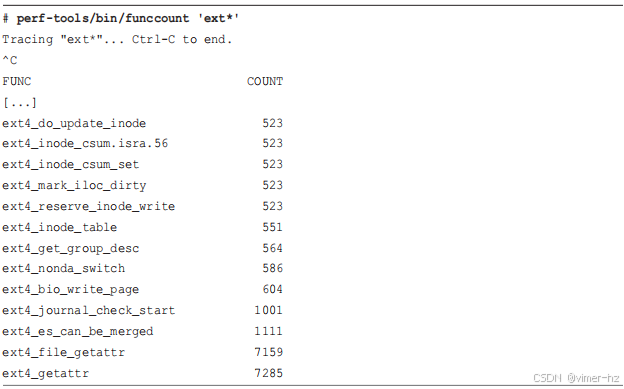
这里的输出已被截断,仅显示了最常用的函数。最常见的是ext4_getattr(),在跟踪过程中调用了7285次。
函数调用会消耗CPU资源,它们的名称通常可以提供执行工作负载的线索。在函数名称含糊不清的情况下,通常可以在网上找到函数的源代码,并阅读以理解其功能。这在Linux内核函数中尤为真实,因为它们是开源的。
Ftrace具有许多有用的预定义能力,最近的增强功能添加了直方图和更多的频率计数("hist triggers")。与BPF不同,Ftrace并非完全可编程,因此不能用于获取数据并以完全自定义的方式展示它们。
6.3 BPF Tools
本节介绍了用于CPU性能分析和故障排除的BPF工具。它们显示在图6-4中,并列在表6-3中。
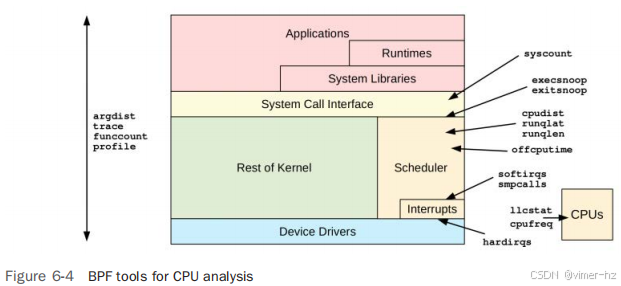
这些工具要么来自于第4章和第5章中介绍的BCC和bpftrace存储库,要么是为本书而创建的。有些工具同时出现在BCC和bpftrace中。表6-3列出了本节涵盖的工具的来源(BT是bpftrace的简称)。
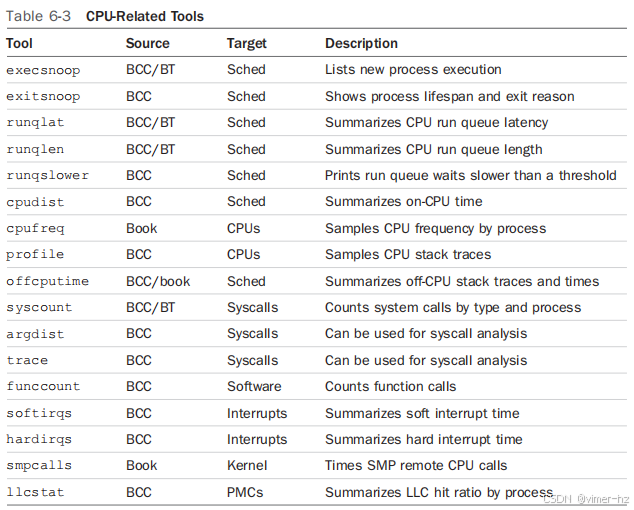
关于来自BCC和bpftrace的工具,请参阅它们的存储库获取完整和更新的工具选项和功能列表。以下是一些最重要功能的摘要。
6.3.1 execsnoop
execsnoop(8)3是一个BCC和bpftrace工具,用于跟踪系统范围内新进程的执行。它可以找出消耗CPU资源的短生命周期进程的问题,并且还可以用于调试软件执行,包括应用程序的启动脚本。
以下是BCC版本的示例输出:
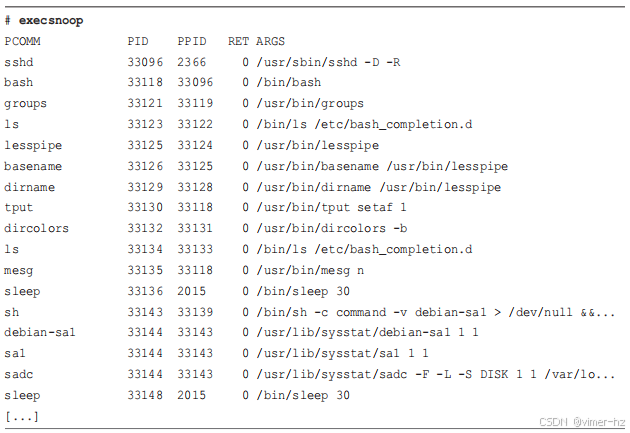
这个工具捕获了用户使用SSH登录系统的时刻,以及启动的进程,包括sshd(8)、groups(1)和mesg(1)。它还显示了系统活动记录器sar将指标写入日志的进程,包括sa1(8)和sadc(8)。
使用execsnoop(8)查找消耗资源的短生命周期进程的高频率。它们很难被发现,因为它们可能非常短暂,在像top(1)或监控代理这样的工具能够检测到它们之前就消失了。第1章展示了一个例子,其中一个启动脚本在循环中未能启动应用程序,影响了系统的性能。使用execsnoop(8)很容易发现了这个问题。execsnoop(8)已经被用于调试许多生产问题:来自后台作业的干扰、应用程序启动缓慢或失败、容器启动缓慢或失败等等。
execsnoop(8)跟踪execve(2)系统调用(常用的exec(2)变体),并显示execve(2)的参数和返回值的详细信息。这可以捕获遵循fork(2)/clone(2)->exec(2)序列的新进程,以及重新执行自身的进程。一些应用程序在创建工作进程池时,可能仅使用fork(2)或clone(2)而不调用exec(2)。这些不会出现在execsnoop(8)的输出中,因为它们没有调用execve(2)。这种情况应该是不常见的:应用程序应该创建工作线程池,而不是进程池。
由于进程执行的速率预计相对较低(<1000/秒),因此这个工具的开销预计可以忽略不计。
BCC
BCC版本支持多种选项,包括:
- -x:包括失败的exec()操作
- -n pattern:仅打印包含特定模式的命令
- -l pattern:仅打印其参数包含特定模式的命令
- --max-args args:指定要打印的最大参数数目(默认为20个)
bpftrace
以下是bpftrace版本的execsnoop(8)代码,总结了其核心功能。这个版本打印基本列,不支持选项:

BEGIN打印标题。为了捕获exec()事件,通过跟踪点syscalls:sys_enter_execve来实现,打印自程序开始运行以来的时间、进程ID,以及命令名和参数。它使用了join()函数来处理来自跟踪点args->argv字段的参数,以便将命令名和参数打印在同一行上。
未来版本的bpftrace可能会改变join()的行为,使其返回一个字符串而不是直接打印出来,这会使得这段代码变成:
```
tracepoint:syscalls:sys_enter_execve
{
printf("%-10u %-5d %s\n", elapsed / 1000000, pid, join(args->argv));
}
```
BCC版本同时对execve()系统调用的进入和返回进行了仪器化,以便打印返回值。bpftrace程序也可以轻松增强以实现这一点。
请参阅第13章中的类似工具threadsnoop(8),它跟踪线程的创建而不是进程的执行。
6.3.2 exitsnoop
exitsnoop(8)是一个BCC工具,用于跟踪进程退出的时间,显示它们的运行时间和退出原因。运行时间指的是进程从创建到终止的时间,包括在CPU上和CPU外的时间。与execsnoop(8)类似,exitsnoop(8)可以帮助调试短暂进程的问题,提供不同的信息来帮助理解这种工作负载。例如:
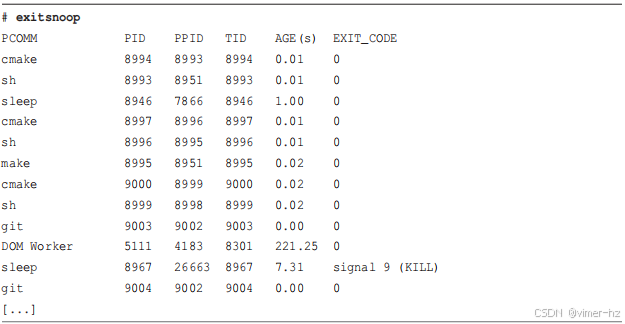
这个输出显示了许多短命进程的退出,如cmake(1)、sh(1)和make(1):正在运行软件构建。一个sleep(1)进程在1.00秒后成功退出(退出码为0),另一个sleep(1)进程由于接收到KILL信号在7.31秒后退出。还捕获到一个名为"DOM Worker"的线程在221.25秒后退出。
该工具通过仪器化sched:sched_process_exit跟踪点及其参数来工作,同时使用bpf_get_current_task()函数从任务结构中读取启动时间(这是一个不稳定的接口细节)。由于这个跟踪点的触发应该很少,因此该工具的开销应该可以忽略不计。
命令行用法:
```
exitsnoop [options]
```
选项包括:
- `-p PID`:仅测量指定PID的进程
- `-t`:包括时间戳
- `-x`:只跟踪失败(非零退出原因)
目前还没有bpftrace版本的exitsnoop(8),但对于正在学习bpftrace编程的人来说,创建这样一个版本可能是一个有用的练习。
6.3.3 runqlat
runqlat(8)是一个BCC和bpftrace工具,用于测量CPU调度延迟,通常称为运行队列延迟(即使不再使用运行队列实现)。它有助于识别和量化CPU饱和问题,即CPU资源需求超过其服务能力的情况。runqlat(8)测量的指标是每个线程(任务)等待在CPU上运行的时间。
以下是在一个使用48个CPU的生产API实例上运行runqlat(8),系统整体CPU利用率约为42%。runqlat(8)的参数为"10 1",表示设置一个10秒的间隔,并且只输出一次:
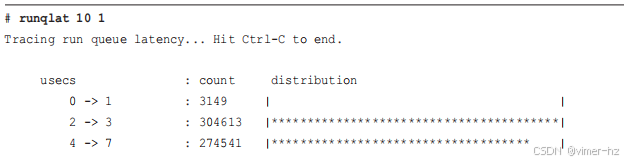
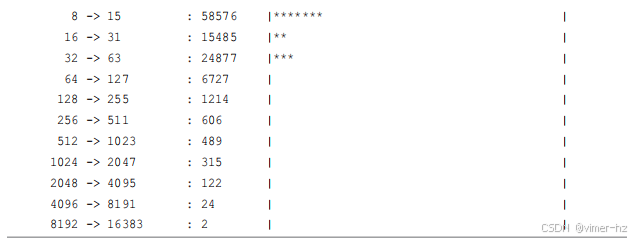
这个输出显示,大部分时间线程等待时间少于15微秒,在直方图中的模式介于两到15微秒之间。这相对来说很快——是一个健康系统的例子,并且对于运行在42% CPU利用率的系统来说是符合预期的。偶尔在这个例子中,运行队列的延迟会高达八到十六毫秒,但这些属于离群值。
runqlat(8)通过对调度器唤醒和上下文切换事件进行仪表化来工作,以确定从唤醒到运行的时间。这些事件在繁忙的生产系统中可能非常频繁,每秒超过一百万次。即使BPF已经进行了优化,在这些速率下,每个事件增加一微秒的开销也可能导致明显的额外负担。请谨慎使用。
错误配置的构建
这里是另一个比较的例子。这次是一个拥有36个CPU的构建服务器正在进行软件构建,由于错误地将并行作业数设置为72个,导致CPU过载:
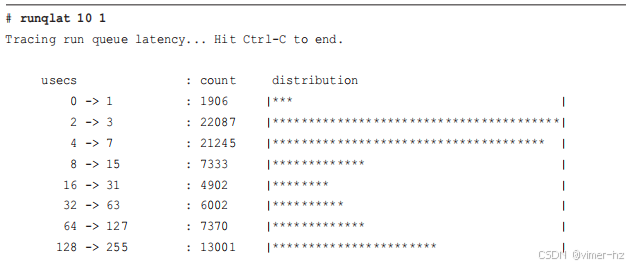

现在分布呈三峰形,最慢的模式集中在8到16毫秒的区间。这显示线程有显著的等待时间。
这个特定问题可以通过其他工具和指标轻松识别。例如,sar(1)可以显示CPU利用率(-u)和运行队列指标(-q):
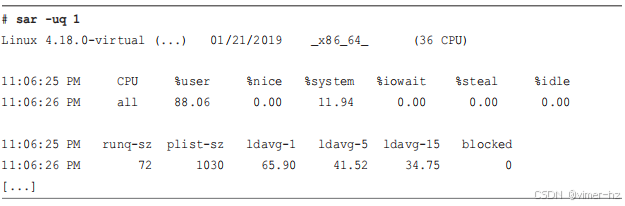
这个sar(1)的输出显示CPU空闲率为0%,平均运行队列大小为72(包括正在运行和可运行的任务)—超过了36个可用的CPU。
第15章包含了一个runqlat(8)的示例,展示了每个容器的延迟情况。
BCC
BCC版本的命令行用法:
runqlat [options] [interval [count]]
选项包括:
- -m:以毫秒打印输出
- -P:按进程ID打印直方图
- --pidnss:按PID命名空间打印直方图
- -p PID:仅跟踪指定的进程ID
- -T:在输出中包含时间戳
-T 选项对于在每个间隔输出中加入时间标记非常有用。例如,runqlat -T 1 可以生成每秒带时间戳的输出。
bpftrace
以下是bpftrace版本runqlat(8)的代码,概述了其核心功能。这个版本不支持选项。

该程序在 sched_wakeup 和 sched_wakeup_new 的跟踪点上记录一个时间戳,以 args->pid 作为键,该键表示内核线程ID。
在 sched_switch 动作中,如果前一个状态仍为可运行状态(TASK_RUNNING),则在 args->prev_pid 上存储一个时间戳。这处理了一种被动的上下文切换情况,在线程离开 CPU 时,它会立即返回到运行队列。该动作还会检查下一个可运行进程是否存储了时间戳,如果是,则计算时间差并将其存储在 @usecs 直方图中。
由于使用了 TASK_RUNNING,因此读取了 linux/sched.h 头文件(#include),以便其定义可用。
BCC 版本可以按 PID 进行分解,而此 bpftrace 版本可以通过向 @usecs 映射添加 pid 键来轻松实现相同的修改。在 BCC 中的另一个增强功能是跳过对 PID 为 0 的记录,以排除调度内核空闲线程的延迟。同样,该程序也可以轻松修改以执行相同的操作。
6.3.4 runqlen
runqlen(8) 是一个 BCC 和 bpftrace 工具,用于对 CPU 运行队列的长度进行采样,计算等待执行的任务数量,并将其呈现为线性直方图。这可以用来进一步分析运行队列延迟问题,或作为更便宜的近似方法。
以下展示了在一个具有48个CPU的生产API实例上运行的 BCC 的 runqlet(8)。该实例的系统整体CPU利用率约为42%(与之前显示的 runqlat(8) 相同)。runqlen(8) 的参数为 "10 1",表示设置10秒的采样间隔,并且只输出一次:

这显示大部分时间运行队列长度为零,这意味着线程无需等待执行。
我将运行队列长度描述为次要的性能指标,而运行队列延迟则是主要指标。与长度不同,延迟直接且成比例地影响性能。想象一下在杂货店排队结账。对你来说,更重要的是排队的长度还是实际等待的时间?运行队列延迟 (runqlat(8)) 更为重要。那么为什么要使用 runqlen(8) 呢?
首先,runqlen(8) 可用于进一步分析在 runqlat(8) 中发现的问题,并解释延迟为何变高。其次,runqlen(8) 使用99赫兹的定时采样,而 runqlat(8) 则跟踪调度器事件。与 runqlat(8) 的调度器跟踪相比,这种定时采样的开销微乎其微。对于全天候监控,可能更倾向于首先使用 runqlen(8) 来识别问题(因为成本更低),然后临时使用 runqlat(8) 来量化延迟。
四个线程,一个CPU
在这个示例中,有四个繁忙线程的CPU工作负载被绑定到CPU 0。执行了带有 -C 选项的 runqlen(8),以显示每个CPU的直方图:
CPU 0 上的运行队列长度为三:一个线程在CPU上运行,另外三个线程在等待。这种每个CPU的输出对于检查调度器的平衡非常有用。
BCC
BCC 版本的命令行用法:
runqlen [options] [interval [count]]
选项包括:
- -C:按CPU打印直方图
- -O:打印运行队列占用情况
- -T:在输出中包含时间戳
运行队列占用是一个单独的指标,显示了有线程等待的时间百分比。在需要单一指标进行监控、报警和绘图时,这有时是非常有用的。
bpftrace
以下是 bpftrace 版本的 runqlen(8) 代码,概述了其核心功能。此版本不支持选项。
该程序需要引用 cfs_rq 结构的 nr_running 成员,但是标准内核头文件中并未提供这个结构。因此,程序首先定义了一个 cfs_rq_partial 结构体,足以获取所需的成员。一旦 BTF 可用(详见第2章),这种解决方法可能就不再需要。
主要事件是 profile:hz:99 探针,它以99赫兹在所有CPU上对运行队列长度进行采样。长度是通过从当前任务结构体到其所在运行队列的路径来获取,然后读取运行队列的长度。如果内核源代码发生变化,可能需要调整这些结构体和成员名称。
您可以通过向 @runqlen 添加一个 cpu 键来让这个 bpftrace 版本按CPU进行分解。
6.3.5 runqslower
runqslower(8)12 是一个BCC工具,列出超过可配置阈值的运行队列延迟实例,并显示遭受延迟的进程及其持续时间。以下示例来自一个拥有48个CPU的生产API实例,当前系统范围内CPU利用率为45%:
这段输出显示,在13秒的时间内,出现了10次运行队列延迟超过默认的阈值10000微秒(10毫秒)。对于一个有55%空闲CPU余地的服务器来说,这可能看起来令人惊讶,但这是一个繁忙的多线程应用程序,直到调度程序能够将线程迁移到空闲的CPU上,某些运行队列不平衡是可能的。此工具可以确认受影响的应用程序。
当前,此工具通过使用 kprobes 监视内核函数 ttwu_do_wakeup()、wake_up_new_task() 和 finish_task_switch() 实现。将来的版本应该转向使用调度器的 tracepoints,采用类似于之前 bpftrace 版本 runqlat(8) 的代码。由于 kprobes 的成本,即使 runqslower(8) 没有打印任何输出,它在忙碌系统上的开销与 runqlat(8) 相似,可能会导致显著的性能开销。
命令行用法:
runqslower [选项] [min_us]
选项包括:
- -p PID:仅测量该进程
默认阈值为10000微秒。
6.3.6 cpudist
cpudist(8)13 是一个BCC工具,用于显示每个线程唤醒的CPU时间分布情况。这可用于帮助表征CPU工作负载,提供后续调优和设计决策的详细信息。例如,来自一个拥有48个CPU的生产实例:
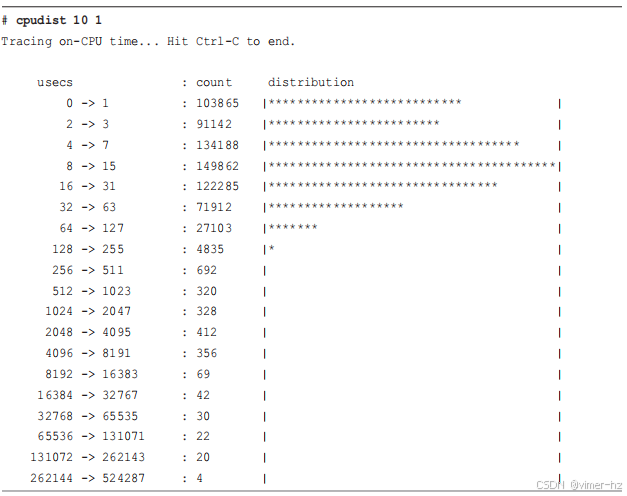
这个输出显示,生产应用通常只在CPU上花费很短的时间:从0到127微秒不等。
这是一个CPU密集型的工作负载,比可用CPU更多的繁忙线程,并且使用毫秒级的直方图(使用选项 -m):


现在出现了一个持续时间从4到15毫秒的CPU模式:这很可能是线程耗尽其调度器时间片,并遇到非自愿的上下文切换。
这个工具被用来帮助理解 Netflix 生产环境中的一次变更,一款机器学习应用程序开始运行快了三倍。使用 perf(1) 命令显示上下文切换率下降了,而 cpudist(8) 被用来解释这个变化的影响:应用程序现在通常在两到四毫秒之间运行,然后才会遇到上下文切换;而之前,它在被中断上下文切换前只能运行零到三微秒。
cpudist(8) 通过跟踪调度器上下文切换事件工作,这在繁忙的生产负载上可能非常频繁(每秒超过一百万次事件)。与 runqlat(8) 类似,这个工具的开销可能很大,因此请谨慎使用。
命令行用法:
cpudist [选项] [间隔 [次数]]
选项包括:
- -m:以毫秒打印输出(默认为微秒)
- -O:显示非CPU时间而不是CPU时间
- -P:按进程打印直方图
- -p PID:仅测量该进程
目前还没有 cpudist(8) 的 bpftrace 版本。我已经拒绝创建一个,并将其作为本章末尾的一个可选练习添加进去。
6.3.7 cpufreq
cpufreq(8)对CPU频率进行采样,并将其显示为系统范围的直方图,同时包括每个进程的名称直方图。这仅适用于改变频率的CPU调频管理器,如powersave,可用于确定应用程序运行的时钟速度。例如:

这显示,整个系统中,CPU频率通常在1200到1400 MHz范围内,因此这是一个大部分时间处于空闲状态的系统。Java进程遇到的频率类似,只有少数样本(在采样时有18个)达到了3.0到3.2 GHz范围。这个应用程序主要进行磁盘I/O操作,导致CPU进入节能状态。Python3进程通常以全速运行。
该工具通过跟踪频率变化的跟踪点来确定每个CPU的速度,然后以100赫兹的频率对其进行采样。性能开销应该很低,几乎可以忽略不计。前述输出来自一个使用powersave调频管理器设置的系统,如在/sys/devices/system/cpu/cpufreq/.../scaling_governor中设置的那样。当系统设置为performance调频管理器时,此工具将不显示任何内容,因为不再有频率变化需要进行监控:CPU被固定在最高频率。
这是我刚发现的一个生产工作负载的摘录:
显示生产应用程序nginx经常以较低的CPU时钟频率运行。CPU的调频管理器未被设置为performance,而是默认为powersave模式。
cpufreq(8)的源代码来自于:

频率变化是通过power:cpu_frequency跟踪点进行追踪,并保存在一个@curfreq的BPF映射中,按CPU分类,以便在采样时进行后续查找。直方图跟踪的频率范围从0到5000 MHz,步长为200 MHz;如果需要,可以在工具中调整这些参数。
6.3.8 profile
profile(8)是一个BCC工具,它以定时间隔对堆栈跟踪进行采样,并报告堆栈跟踪的频率计数。这是BCC中最有用的工具之一,用于理解CPU消耗,因为它总结了几乎所有消耗CPU资源的代码路径。(有关更多CPU消费者,请参阅第6.3.14节中的hardirqs(8)工具。)它还可以以相对可以忽略不计的开销使用,因为事件率被固定为采样率,可以进行调整。
默认情况下,该工具在所有CPU上以49赫兹采样用户和内核堆栈跟踪。可以使用选项进行自定义,并且在输出开始时会打印设置。例如:

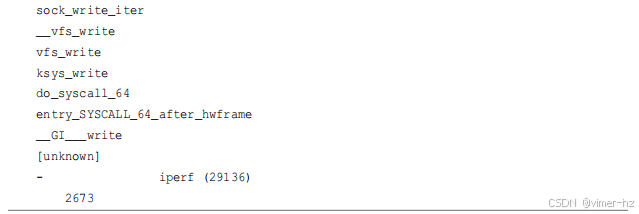
输出显示堆栈跟踪列表,格式为函数列表,后跟破折号("-"),括号内是进程名称和PID,最后是该堆栈跟踪的计数。堆栈跟踪按照频率计数的顺序从少到多进行打印。
在本例中,完整输出共有17,254行,并在此处进行了截断,只展示了首尾两个堆栈跟踪。最频繁的堆栈跟踪显示了通过vfs_write()并以get_page_from_freelist()结束的路径,在采样过程中出现了2673次。
CPU火焰图
火焰图是堆栈跟踪的可视化,可以帮助您快速理解profile(8)的输出。这些图表在第2章中介绍过。
为支持火焰图,profile(8)可以使用-f选项生成折叠格式的输出:堆栈跟踪打印在一行上,函数之间用分号分隔。例如,将30秒的profile写入out.stacks01文件并包括内核注释(-a):
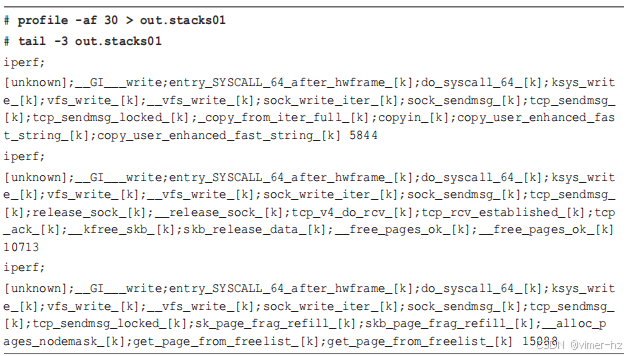
这里仅展示了最后三行。此输出可以输入到我原始的火焰图软件中生成CPU火焰图:
```bash
$ git clone https://github.com/brendangregg/FlameGraph
$ cd FlameGraph
$ ./flamegraph.pl --color=java < ../out.stacks01 > out.svg
```
flamegraph.pl支持不同的颜色调色板。此处使用的java调色板利用了内核注释("_[k]")选择颜色色调。生成的SVG显示在图6-5中。
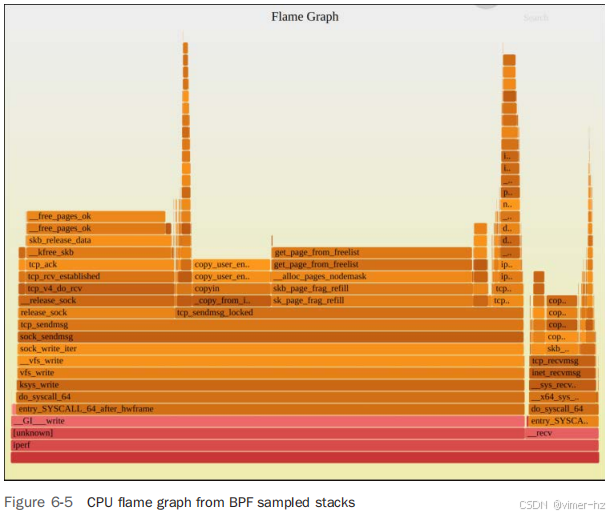
这个火焰图显示,最热门的代码路径以get_page_from_freelist_()和__free_pages_ok_()结尾,这些是最宽的塔楼,宽度与它们在profile中的频率成比例。在浏览器中,这个SVG支持点击缩放,以便展开窄塔楼并阅读其函数。
profile(8)与其他CPU分析器的不同之处在于,它在内核空间中计算频率计数以提高效率。其他基于内核的分析器,如perf(1),会将每个采样的堆栈跟踪发送到用户空间,然后在那里进行后处理以生成摘要。这可能会消耗大量CPU资源,并且根据调用方式,还可能涉及文件系统和磁盘I/O来记录样本。而profile(8)避免了这些开销。
命令行用法:
profile [选项] [-F 频率]
可用选项包括:
- -U:仅包括用户级堆栈
- -K:仅包括内核级堆栈
- -a:包括帧注释(例如内核帧的 "_[k]")
- -d:在内核/用户堆栈之间包括分隔符
- -f:以折叠格式提供输出
- -p PID:仅对该进程进行分析
bpftrace
profile(8)的核心功能可以作为bpftrace的一行命令实现:
bpftrace -e 'profile:hz:49 /pid/ { @samples[ustack, kstack, comm] = count(); }'
这会使用用户堆栈、内核堆栈和进程名称作为键来进行频率统计。包含对pid的过滤以确保它非零:这排除了CPU空闲线程的堆栈。这一行命令可以根据需要进行定制。
6.3.9 offcputime
offcputime(8)16是一个BCC和bpftrace工具,用于总结线程在阻塞和脱离CPU状态下花费的时间,并显示堆栈跟踪来解释原因。对于CPU分析,该工具解释了为什么线程未在CPU上运行。它是profile(8)的补充;它们共同展示了系统中线程的整体时间:profile(8)显示在CPU上的时间,而offcputime(8)显示脱离CPU的时间。
以下示例展示了来自BCC的offcputime(8),追踪五秒钟的情况:


输出已被截断,仅显示了从数百个打印信息中选取的三个堆栈。每个堆栈显示内核帧(如果存在),然后是用户级帧,接着是进程名称和PID,最后是此组合观察到的总时间,以微秒计。第一个堆栈显示iperf(1)在sk_stream_wait_memory()中因内存阻塞,总计5毫秒。第二个堆栈显示iperf(1)通过sk_wait_data()等待套接字上的数据,总计1.02秒。最后一个堆栈显示offcputime(8)工具本身在select(2)系统调用中等待了5.00秒;这很可能是因为命令行上指定的5秒超时。
需要注意的是,在所有三个堆栈中,用户级堆栈跟踪都是不完整的。这是因为它们以libc结束,并且此版本不支持帧指针。这在offcputime(8)中更为明显,因为阻塞堆栈经常通过系统库如libc或libpthread。请参阅第2章、第12章、第13章和第18章中有关堆栈跟踪问题及解决方案的讨论,特别是第13.2.9节。
offcputime(8)已被用于发现各种生产问题,包括发现在锁获取中意外阻塞的时间和相关的堆栈跟踪。
offcputime(8)的工作原理是通过检测上下文切换并记录线程从离开CPU到返回的时间,同时记录堆栈跟踪。为了效率,这些时间和堆栈跟踪在内核上下文中进行频率统计。然而,上下文切换事件可能非常频繁,而此工具的开销对于繁忙的生产工作负载可能会变得显著(例如,>10%)。最好仅在短时间内运行此工具,以最小化对生产环境的影响。
Off-CPU Time Flame Graphs
与profile(8)类似,offcputime(8)的输出可能非常冗长,因此您可能更喜欢将其作为火焰图来查看,尽管这种火焰图与第二章介绍的类型不同。offcputime(8)可以被视为一种“离CPU时间”火焰图,而不是CPU火焰图。
以下示例创建了一个针对内核堆栈的5秒离CPU时间火焰图:
```bash
# offcputime -fKu 5 > out.offcputime01.txt
$ flamegraph.pl --hash --bgcolors=blue --title="Off-CPU Time Flame Graph" < out.offcputime01.txt > out.offcputime01.svg
```
我使用了`--bgcolors`来将背景色更改为蓝色,以便与CPU火焰图进行视觉区分。您也可以使用`--colors`来更改帧的颜色,我已经发布了许多使用蓝色调色板的离CPU火焰图。
这些命令生成了图6-6中显示的火焰图。
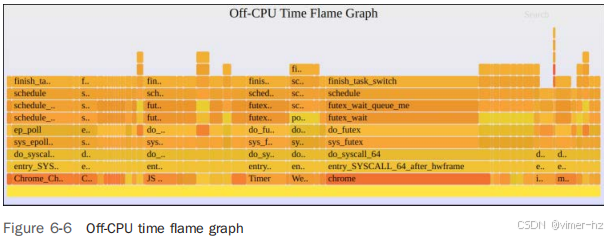
这个火焰图主要显示了正在休眠等待工作的线程。您可以点击应用程序的名称来放大查看感兴趣的部分。有关离CPU时间火焰图的更多信息,包括具有完整用户堆栈跟踪的示例,请参阅第12章、第13章和第14章。
BCC
命令行用法:
offcputime [选项] [持续时间]
选项包括:
- -f:以折叠格式打印输出
- -p PID:仅测量指定进程
- -u:仅跟踪用户线程
- -k:仅跟踪内核线程
- -U:仅显示用户堆栈跟踪
- -K:仅显示内核堆栈跟踪
这些选项中的一些可以通过筛选仅记录一个PID或堆栈类型来帮助减少开销。
bpftrace
以下是bpftrace版本的offcputime(8)代码,概述了其核心功能。此版本支持可选的PID参数用于指定要跟踪的目标进程:
这个程序在一个 `finish_task_switch()` 的 kprobe 中记录了线程离开 CPU 的时间戳,并且还对开始运行的线程的离 CPU 时间进行了累加。
6.3.10 syscount
syscount(8)是一个BCC和bpftrace工具,用于统计系统范围内的系统调用。它被包含在本章中,因为它可以作为调查高系统CPU时间案例的起点。
以下输出显示了来自BCC的syscount(8),以每秒系统调用率(-i 1)打印在生产实例上的情况:
这个输出每秒显示了前10个系统调用及其时间戳。最频繁的系统调用是 futex(2),达到每秒超过150,000次的调用。要进一步探索每个系统调用,可以查阅各自的man手册获取文档,并使用更多的BPF工具来跟踪和检查它们的参数(例如,BCC 的 trace(8) 或 bpftrace 的一行命令)。在某些情况下,运行 strace(1) 可能是理解特定系统调用如何使用的最快方法,但要记住,当前基于 ptrace 的 strace(1) 实现可能会使目标应用程序的性能减慢数百倍,这可能会在许多生产环境中引发严重问题(例如,超过延迟 SLOs 或触发故障切换)。在尝试过BPF工具后,应将 strace(1) 视为最后的手段。可以使用 -P 选项按进程ID进行计数:


这个Java进程每秒进行近 300,000 次系统调用。其他工具显示,在这个有 48 个CPU 的系统中,这些调用仅占据了系统时间的 1.6%。
该工具通过对 raw_syscalls:sys_enter 这个跟踪点进行插装来工作,而不是通常的 syscalls:sys_enter_* 跟踪点。原因是 raw_syscalls:sys_enter 能够看到所有的系统调用,使得初始化插装更加快速。缺点是它只提供系统调用的ID,需要将其转换回名称。BCC 提供了一个库调用 syscall_name() 来完成这个转换。
对于非常高的系统调用率,这个工具可能会带来明显的开销。举例来说,我在一个CPU上进行了3.2百万次/秒/CPU的系统调用率压力测试。在运行 syscount(8) 时,工作负载减慢了30%。这有助于估计在生产环境中的开销:在一个每秒 300,000 次系统调用的 48-CPU 实例中,每CPU每秒大约执行 6000 次系统调用,因此预计会遭遇到 0.06% 的减速(30% × 6250 / 3200000)。我试图直接在生产环境中测量这个值,但由于工作负载的变化,这个值太小以至于无法测量。
BCC
命令行用法:
syscount [选项] [-i 间隔] [-d 持续时间]
可用选项包括:
■ -T TOP:打印指定数量的前几项
■ -L:显示系统调用的总时间(延迟)
■ -P:按进程计数
■ -p PID:仅测量指定PID的进程
在第13章中展示了 -L 选项的示例。
bpftrace
有一个 bpftrace 版本的 syscount(8),具有核心功能,但你也可以使用以下这个单行命令:
在这种情况下,所有 316 个系统调用跟踪点被插装(针对此内核版本),并对探测点名称进行了频率计数。当前在程序启动和关闭时会有延迟来插装所有 316 个跟踪点。最好使用单个 raw_syscalls:sys_enter 跟踪点,就像 BCC 一样,但这会需要额外的步骤将系统调用ID转换回系统调用名称。这在第14章中作为示例包含进去。
6.3.11 argdist and trace
argdist(8) 和 trace(8) 在第4章中介绍,它们是 BCC 工具,可以以自定义方式检查事件。作为 syscount(8) 的补充,如果发现某个系统调用频繁调用,你可以使用这些工具来进行更详细的检查。
例如,read(2) 系统调用在之前的 syscount(8) 输出中频繁出现。你可以使用 argdist(8) 来通过插装系统调用跟踪点或其内核函数,总结其参数和返回值。对于跟踪点,你需要找到参数名称,可以使用带有 -v 选项的 BCC 工具 tplist(8) 打印出这些名称:

使用 argdist(8) 作为直方图 (-H) 来总结的话,count 参数表示了 read(2) 的大小。


这个输出显示,在 16 到 31 字节范围内和 1024 到 2047 字节范围内有许多读取操作。可以使用 argdist(8) 的 -C 选项代替 -H,将大小总结为频率计数而不是直方图。
这显示了自从进入系统调用以来请求的读取大小。将其与系统调用退出时的返回值进行比较,后者是实际读取的字节数:
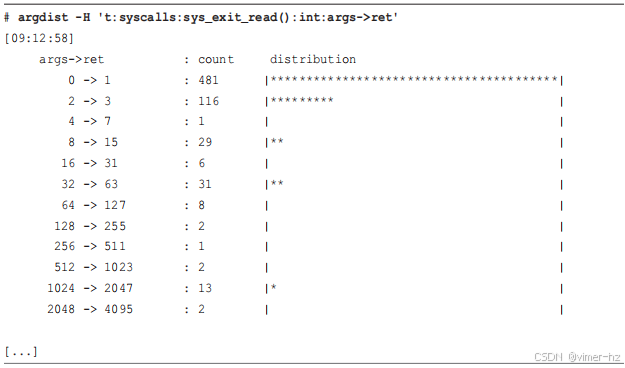
这些主要是零字节或一字节的读取操作。
由于其内核内摘要,argdist(8) 对于检查频繁调用的系统调用非常有用。而 trace(8) 则打印每个事件的输出,适合检查不太频繁的系统调用,显示每个事件的时间戳和其他细节。
bpftrace
使用 bpftrace 的一行命令可以实现这种级别的系统调用分析。例如,检查请求的读取大小作为直方图:
bpftrace有一个专门的存储桶用于负值("(..., 0)"),这些值是 read(2) 返回的错误码,用于指示错误。你可以编写一个 bpftrace 的一行命令来将这些值打印为频率计数(如第五章所示),或者作为线性直方图,以便可以看到各个数字:
```bash
# bpftrace -e 't:syscalls:sys_exit_read /args->ret < 0/ {
@ = lhist(- args->ret, 0, 100, 1); }'
```
正在附加 1 个探针...
^C
@:
[11, 12) 123 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
这个输出显示错误码 11 总是被返回。查看 Linux 头文件 (asm-generic/errno-base.h):
```c
#define EAGAIN 11 /* Try again */
```
错误码 11 是指“再试一次”,这是在正常操作中可能出现的错误状态。
6.3.12 funccount
funccount(8),在第四章中介绍,是一个 BCC 工具,可以对函数和其他事件进行频率计数。它可以用来提供软件 CPU 使用的更多上下文,显示哪些函数被调用以及调用频率。
profile(8) 可能能够显示某个函数在 CPU 上很活跃,但它无法解释为什么:这个函数是否运行缓慢,或者只是每秒被调用数百万次。
例如,通过以下方式,在一个繁忙的生产实例上对内核 TCP 函数进行频率计数,匹配以 "tcp_" 开头的函数:
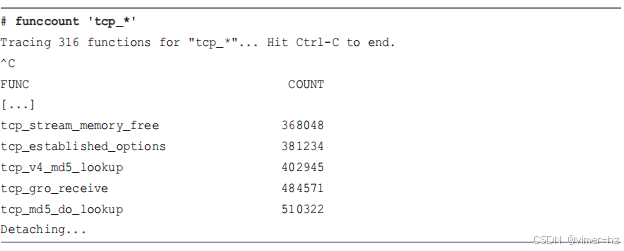
这个输出显示,在跟踪期间,tcp_md5_do_lookup() 被调用最频繁,达到了 510,000 次。
可以使用 -i 参数生成每个间隔的输出。例如,前面 profile(8) 的输出显示函数 get_page_from_freelist() 在 CPU 上很活跃。这是因为它经常被调用,还是因为它运行缓慢?可以通过测量它的每秒调用率来判断:
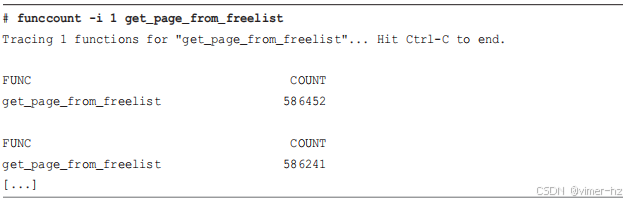
该函数每秒被调用超过五十万次。
这是通过对函数进行动态跟踪实现的:它使用 kprobes 跟踪内核函数和 uprobes 跟踪用户级函数(kprobes 和 uprobes 在第二章中有详细解释)。该工具的开销与函数的调用率相关。一些函数,比如 malloc() 和 get_page_from_freelist(),经常发生,因此跟踪它们可能会显著减慢目标应用程序,超过 10% 的额外开销,请谨慎使用。有关更多关于理解开销的信息,请参见第18章的第18.1节。
命令行用法:
funccount [选项] [-i 间隔] [-d 持续时间] 模式
选项包括:
■ -r: 使用正则表达式进行模式匹配
■ -p PID: 仅测量此进程
模式:
■ name 或 p:name: 对名为 name() 的内核函数进行仪器化
■ lib:name: 对名为 name() 的库 lib 中的用户级函数进行仪器化
■ path:name: 对路径为 path 的文件中名为 name() 的用户级函数进行仪器化
■ t:system:name: 仪器化名为 system:name 的跟踪点
■ *: 通配符,匹配任何字符串(通配符)
有关更多示例,请参见第4章的第4.5节。
bpftrace
将funccount(8)的核心功能实现为bpftrace的一行命令:
# bpftrace -e 'k:tcp_* { @[probe] = count(); }'
正在挂载 320 个探针...
[...]
@[kprobe:tcp_release_cb]: 153001
@[kprobe:tcp_v4_md5_lookup]: 154896
@[kprobe:tcp_gro_receive]: 177187
可以调整此命令以进行每个间隔的输出,例如,通过添加以下内容:
interval:s:1 { print(@); clear(@); }
与BCC一样,跟踪频繁调用的函数时要小心,因为它们可能会产生显著的开销。
6.3.13 softirqs
softirqs(8) 是一个BCC工具,用于显示服务软中断(soft IRQs,软中断)的时间。系统范围内的软中断时间可以从不同的工具中轻松获取。例如,mpstat(1) 将其显示为 %soft。还可以通过 /proc/softirqs 显示软中断事件的计数。而BCC的 softirqs(8) 工具不同之处在于它可以显示每个软中断的时间,而不是事件计数。
例如,在一个具有48个CPU的生产实例上进行了10秒的跟踪:

这个输出显示,在服务 net_rx 方面花费的时间最多,总共达到了 1358 毫秒。这是相当显著的,因为在这个拥有48个CPU的系统上,这相当于CPU时间的3%。
softirqs(8) 通过使用 irq:softirq_enter 和 irq:softirq_exit 跟踪点工作。这个工具的开销与事件速率相关,对于繁忙的生产系统和高网络数据包速率可能较高。请谨慎使用并检查开销。
命令行用法:
softirqs [选项] [间隔 [次数]]
选项包括:
- -d:将IRQ时间显示为直方图
- -T:在输出中包含时间戳
可以使用 -d 选项来探索分布并识别在处理这些中断时是否存在延迟异常值。
bpftrace
尽管不存在 softirqs(8) 的 bpftrace 版本,但可以创建一个。以下的一行命令是一个起点,通过向量 ID 计数 IRQs:
# bpftrace -e 'tracepoint:irq:softirq_entry { @[args->vec] = count(); }'
正在附加1个探针...
^C
@[3]: 11
@[6]: 45
@[0]: 395
@[9]: 405
@[1]: 524
@[7]: 561
这些向量 ID 可以像 BCC 工具一样通过查找表将其转换为软中断的名称。确定在软中断中花费的时间涉及跟踪 irq:softirq_exit 跟踪点。
6.3.14 hardirqs
hardirqs(8) 是一个 BCC 工具,用于显示在处理硬中断 (hard IRQs) 时花费的时间。系统范围内的硬中断时间可以从不同的工具中轻松获取。例如,mpstat(1) 显示为 %irq。还有 /proc/interrupts 可以显示硬中断事件的计数。BCC 的 hardirqs(8) 工具不同之处在于它可以显示每个硬中断的时间,而不是事件计数。
例如,在一个有48个CPU的生产实例上进行了10秒的跟踪:
这个输出显示,在这个10秒的跟踪中,几个名为 eth0-Tx-Rx* 的硬中断总共花费了大约50毫秒的时间。
hardirqs(8) 可以提供对于 CPU 使用情况的洞察,这是 CPU 分析器无法看到的。请参见第6.2.4节的内部部分,了解在缺乏硬件性能监视单元的云实例上进行分析的方法。
该工具目前通过动态跟踪 handle_irq_event_percpu() 内核函数实现,尽管未来版本应该会切换到 irq:irq_handler_entry 和 irq:irq_handler_exit 这两个跟踪点。
命令行用法:
hardirqs [选项] [间隔 [次数]]
选项包括:
- -d:将 IRQ 时间显示为直方图
- -T:在输出中包含时间戳
选项 -d 可用于探索分布并识别在处理这些中断时是否存在延迟异常值。
6.3.15 smpcalls
smpcalls(8) 是一个 bpftrace 工具,用于跟踪和总结 SMP 调用函数(也称为交叉调用)中的时间。这些函数允许一个 CPU 在其他 CPU 上运行函数,包括所有其他 CPU,在大型多处理器系统上可能会成为一项昂贵的活动。例如,在一个有36个CPU的系统上:

这是我第一次运行这个工具,它立即识别出一个问题:aperfmperf_snapshot_khz 交叉调用相对频繁且较慢,最高达到128微秒。
smpcalls(8) 的源代码是:

许多SMP调用通过kprobes跟踪 smp_call_function_single() 和 smp_call_function_many() 内核函数。进入这些函数时,远程CPU函数作为第二个参数,bpftrace 通过 arg1 访问并按线程ID存储以供kretprobe查找。然后,bpftrace 的 ksym() 内置函数将其转换为可读的符号。
有一个特殊的SMP调用未涵盖在这些函数中,即 smp_send_reschedule(),它通过 native_smp_send_reschedule() 进行跟踪。希望将来的内核版本支持SMP调用的跟踪点,以简化对这些调用的跟踪。
@time_ns 直方图键可以修改为包括内核堆栈跟踪和进程名称:
@time_ns[comm, kstack, ksym(@func[tid])] = hist(nsecs - @ts[tid]);
这样可以为慢调用提供更多详细信息:
这个输出显示,该进程是 snmp-pass,一个监控代理程序,正在执行一个 open() 系统调用,最终进入 cpuinfo_open() 和一个昂贵的交叉调用。使用另一个BPF工具 opensnoop(8),很快确认了这种行为:

这个输出显示,snmp-pass 每秒钟都在读取 /proc/cpuinfo 文件!这个文件中的大部分内容不会改变,除了 "cpu MHz" 字段。
对软件的检查显示,它读取 /proc/cpuinfo 文件只是为了计算处理器的数量;实际上并没有使用 "cpu MHz" 字段。这是一个不必要的操作,消除它应该会带来一些小但容易的优势。
在Intel处理器上,这些SMP调用最终实现为x2APIC IPI(处理器间中断)调用,包括 x2apic_send_IPI()。这些也可以被插装,如第6.4.2节所示。
6.3.16 llcstat
llcstat(8)23 是一个使用性能计数器(PMCs)来显示进程级别的最后级缓存(LLC)失效率和命中率的BCC工具。PMCs的介绍在第2章。
例如,来自一个包含48个CPU的生产实例:
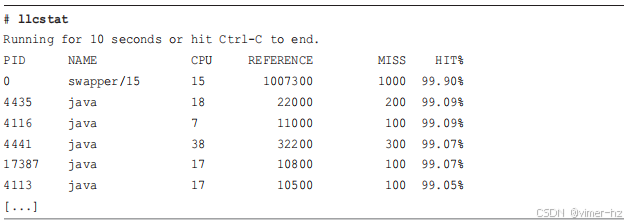
这个输出显示,Java进程(线程)的命中率非常高,超过了99%。
这个工具通过使用性能计数器(PMCs)的溢出采样来工作,其中每个缓存引用或失效的一部分触发一个BPF程序来读取当前运行的进程并记录统计信息。默认阈值为100,可以使用 `-c` 参数进行调整。这种百分之一的采样帮助保持了低开销(如果需要的话,可以调整为更高的数字);然而,与此相关的一些采样问题也存在。例如,一个进程可能偶然地比引用更频繁地溢出失效,这是没有意义的(因为失效是引用的一个子集)。
命令行用法:
```
llcstat [选项] [持续时间]
```
选项包括:
- `-c SAMPLE_PERIOD`:仅对每这么多事件中的一个进行采样
llcstat(8)的有趣之处在于它是第一个在定时采样之外使用PMCs的BCC工具。
6.3.17 Other Tools
其他值得一提的BPF工具包括:
- **cpuwalk(8)** 是来自bpftrace的工具,它对进程运行在哪些CPU上进行采样,并将结果打印为线性直方图。这提供了CPU负载均衡的直方图视图。
- **cpuunclaimed(8)** 是来自BCC的实验性工具,它采样CPU运行队列的长度,并确定空闲CPU和运行队列上仍处于可运行状态的线程之间的情况有多频繁。这种情况有时是由于CPU亲和性引起的,但如果频繁发生,可能是调度程序配置错误或者bug的迹象。
- **loads(8)** 是bpftrace的一个示例,用于获取BPF工具的负载平均数。正如之前讨论的,这些数字可能具有误导性。
- **vltrace** 是由Intel开发中的工具,它将是strace(1)的基于BPF的版本,可用于进一步表征消耗CPU时间的系统调用。
这些工具提供了对系统性能和资源利用情况更深入的分析和理解。
6.4 BPF One-Liners
这部分提供了BCC和bpftrace的一行命令示例。在可能的情况下,同一个一行命令会使用BCC和bpftrace来实现。
6.4.1 BCC
跟踪带有参数的新进程:
- **execsnoop**
显示谁在执行什么:
- **trace 't:syscalls:sys_enter_execve "-> %s", args->filename'**
按进程显示系统调用计数:
- **syscount -P**
按系统调用名称显示系统调用计数:
- **syscount**
以49赫兹的频率对PID为189的用户级堆栈进行采样:
- **profile -F 49 -U -p 189**
对所有堆栈跟踪和进程名称进行采样:
- **profile**
统计以 "vfs_" 开头的内核函数调用次数:
- **funccount 'vfs_*'**
通过 pthread_create() 跟踪新线程:
- **trace /lib/x86_64-linux-gnu/libpthread-2.27.so:pthread_create**
6.4.2 bpftrace
跟踪带有参数的新进程:
- **bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'**
显示谁在执行什么:
- **bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(args->filename)); }'**
按程序显示系统调用计数:
- **bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'**
按进程显示系统调用计数:
- **bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'**
按系统调用探针名称显示系统调用计数:
- **bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'**
按系统调用函数显示系统调用计数:
- **bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[sym(*(kaddr("sys_call_table") + args->id * 8))] = count(); }'**
以99赫兹的频率采样运行中的进程名称:
- **bpftrace -e 'profile:hz:99 { @[comm] = count(); }'**
以49赫兹的频率对PID为189的用户级堆栈进行采样:
- **bpftrace -e 'profile:hz:49 /pid == 189/ { @[ustack] = count(); }'**
对所有堆栈跟踪和进程名称进行采样:
- **bpftrace -e 'profile:hz:49 { @[ustack, stack, comm] = count(); }'**
以99赫兹的频率采样运行中的CPU,并将其显示为线性直方图:
- **bpftrace -e 'profile:hz:99 { @cpu = lhist(cpu, 0, 256, 1); }'**
统计以 "vfs_" 开头的内核函数调用次数:
- **bpftrace -e 'kprobe:vfs_* { @[func] = count(); }'**
按名称和内核堆栈统计SMP调用次数:
- **bpftrace -e 'kprobe:smp_call* { @[probe, kstack(5)] = count(); }'**
按名称和内核堆栈统计Intel x2APIC调用次数:
- **bpftrace -e 'kprobe:x2apic_send_IPI* { @[probe, kstack(5)] = count(); }'**
通过 pthread_create() 跟踪新线程:
- **bpftrace -e 'u:/lib/x86_64-linux-gnu/libpthread-2.27.so:pthread_create { printf("%s by %s (%d)\n", probe, comm, pid); }'**
6.5 Optional Exercises
如果未指定,可以使用bpftrace或BCC来完成以下任务:
1. 使用execsnoop(8)显示man ls命令的新进程。
2. 在生产或本地系统上,使用execsnoop(8)带有-t选项,并将输出记录到日志文件中,持续10分钟。你发现了哪些新进程?
3. 在测试系统上,创建一个过载的CPU。这会创建两个绑定到CPU 0的CPU密集型线程:
```
taskset -c 0 sh -c 'while :; do :; done' &
taskset -c 0 sh -c 'while :; do :; done' &
```
现在使用uptime(1)(负载平均值)、mpstat(1)(-P ALL)、runqlen(8)和runqlat(8)来描述CPU 0上的工作负载。(完成后记得终止工作负载。)
4. 开发一个工具/一行命令,仅对CPU 0采样内核堆栈。
5. 使用profile(8)捕获内核CPU堆栈,以确定以下工作负载消耗了多少CPU时间:
```
dd if=/dev/nvme0n1p3 bs=8k iflag=direct | dd of=/dev/null bs=1
```
将infile(if=)设备修改为本地磁盘(查看df -h找到候选设备)。你可以进行系统范围的profile,或者针对每个dd(1)进程进行过滤。
6. 生成Exercise 5输出的CPU火焰图。
7. 使用offcputime(8)捕获内核CPU堆栈,以确定Exercise 5的工作负载中阻塞时间的消耗情况。
8. 为Exercise 7的输出生成一个off-CPU时间火焰图。
9. execsnoop(8)仅能看到调用exec(2)(execve(2))的新进程,尽管有些进程可能只调用fork(2)或clone(2)而没有调用exec(2)(例如,工作进程的创建)。编写一个名为procsnoop(8)的新工具,尽可能显示所有新进程的详细信息。你可以跟踪fork()和clone(),或者使用sched跟踪点,或者采取其他方法。
10. 开发一个bpftrace版本的softirqs(8),打印softirq名称。
11. 在bpftrace中实现cpudist(8)。
12. 使用cpudist(8)(任何版本),显示自愿和非自愿上下文切换的单独直方图。
13. (高级,未解决)开发一个工具,显示在CPU亲和性等待中任务花费的时间直方图:在其他CPU空闲但由于缓存热度而没有迁移(参见kernel.sched_migration_cost_ns,task_hot()可能是内联的且不可跟踪,以及can_migrate_task())。
6.6 Summary
这一章节总结了系统如何利用CPU,并且使用传统工具(如统计数据、分析器和追踪器)进行分析的方法。此外,本章还展示了如何使用BPF工具来发现短期进程的问题,详细检查运行队列延迟,分析CPU使用效率,计算函数调用次数,并显示软中断和硬中断的CPU使用情况。
7 Memory
Linux是基于虚拟内存的系统,每个进程拥有自己的虚拟地址空间,物理内存的映射是按需进行的。其设计允许对物理内存进行超额分配,Linux通过页面守护程序、物理交换设备以及作为最后手段的内存不足杀手(OOM killer)来管理。Linux利用闲置内存作为文件系统缓存,这一主题在第8章中有详细讨论。
本章展示了如何利用BPF以新的方式揭示应用程序的内存使用情况,并帮助分析内核对内存压力的响应。随着CPU可扩展性的提升超过了内存速度,内存I/O已经成为新的瓶颈。理解内存使用可以帮助发现许多性能优化的机会。
学习目标:
- 理解内存分配和分页行为
- 学习使用追踪器成功分析内存行为的策略
- 使用传统工具了解内存容量的使用情况
- 使用BPF工具识别导致堆和常驻集大小增长的代码路径
- 根据文件名和堆栈跟踪特性化页面错误
- 分析虚拟内存扫描器的行为
- 确定内存回收的性能影响
- 识别哪些进程正在等待换页
- 使用bpftrace的一行命令以定制方式探索内存使用情况
本章从内存分析的必要背景开始,重点关注应用程序的使用情况,总结了虚拟和物理分配以及分页。探索了BPF能够回答的问题以及整体遵循的策略。首先总结了传统的内存分析工具,然后介绍了BPF工具,包括一些BPF的一行命令。本章最后附有可选练习。
第14章提供了用于内核内存分析的额外工具。
7.1 Background
本节涵盖了内存基础知识、BPF的能力,以及建议的内存分析策略。
7.1.1 Memory Fundamentals
内存分配器
图7-1展示了用户级和内核级软件常用的内存分配系统。对于使用libc进行内存分配的进程,内存存储在进程虚拟地址空间的动态段中,称为堆。libc提供了用于内存分配的函数,包括malloc()和free()。当释放内存时,libc会跟踪其位置,并可以利用该位置信息来满足后续的malloc()请求。只有在没有可用内存时,libc才需要扩展堆的大小。通常情况下,libc不需要缩小堆的大小,因为这都是虚拟内存,而不是实际的物理内存。
内核和处理器负责将虚拟内存映射到物理内存。为了效率,内存映射是以称为页面的内存组为单位创建的,每个页面的大小是处理器的细节;通常是4KB,尽管大多数处理器也支持更大的页面大小,被Linux称为大页面(huge pages)。内核可以从自身的空闲列表中为物理内存页面请求提供服务,它为每个DRAM组和CPU维护这些列表以提高效率。内核的软件也会从这些空闲列表中消耗内存,通常通过诸如slab分配器之类的内核分配器来完成。

其他用户级分配库包括tcmalloc和jemalloc,而像JVM这样的运行时环境通常会提供自己的分配器以及垃圾回收功能。其他的分配器也可能会映射私有段,用于在堆外进行分配。

内存页面和交换
图7-2展示了典型用户内存页面的生命周期,以下列出了各个步骤:
1. 应用程序开始通过内存分配请求(例如,libc的malloc())。
2. 分配库可以从自己的空闲列表中提供内存请求的服务,或者可能需要扩展虚拟内存来容纳。根据分配库的不同,它会执行以下操作之一:
a. 通过调用brk()系统调用来扩展堆的大小,并使用堆内存进行分配。
b. 通过调用mmap()系统调用创建一个新的内存段。
3. 随后,应用程序尝试通过存储和加载指令使用分配的内存范围,这涉及调用处理器内存管理单元(MMU)进行虚拟地址到物理地址的转换。在此时,虚拟内存的实际情况显现出来:该地址没有映射!这导致了MMU错误,称为页错误。
4. 内核处理页错误,它从物理内存的空闲列表建立映射到虚拟内存,然后通知MMU进行后续查找时的映射。此时,进程正在消耗额外的物理内存页面。进程使用的物理内存量称为其常驻集大小(RSS)。
5. 当系统上的内存需求过多时,内核的页面交换守护进程(kswapd)可能会查找要释放的内存页面。它将释放三种类型的内存之一(尽管图7-2中仅显示了(c),因为它展示了用户内存页面的生命周期):
a. 从磁盘读取而未修改的文件系统页面(称为“由磁盘支持”):这些可以立即释放,并在需要时简单重新读取。这些页面是应用程序可执行文本、数据和文件系统元数据。
b. 已修改的文件系统页面:这些是“脏页”,必须写入磁盘才能释放。
c. 应用程序内存页面:这些称为匿名内存,因为它们没有文件来源。如果正在使用交换设备,这些页面可以通过首先存储在交换设备上来释放。将页面写入交换设备的过程称为交换(在Linux上)。
内存分配请求通常是频繁的活动:对于繁忙的应用程序,用户级分配可能每秒发生数百万次。加载和存储指令以及MMU查找更为频繁;它们可能每秒发生数十亿次。在图7-2中,这些箭头用粗体绘制。其他活动相对不太频繁:brk()和mmap()调用、页错误和页交换(浅色箭头)。
页面交换守护进程
页面交换守护进程(kswapd)定期激活,扫描LRU(最近最少使用)列表中的非活跃和活跃页面,以释放内存。当空闲内存降到一个低阈值时,它会被唤醒;当空闲内存超过高阈值时,它会再次进入睡眠状态,如图7-3所示。

kswapd协调后台页面交换;除了CPU和磁盘I/O竞争外,这些操作通常不会直接影响应用程序性能。如果kswapd无法快速释放内存,会超过可调整的最小页面阈值,并启用直接回收模式;这是为了满足内存分配需求而采用的前台模式。在这种模式下,分配操作会被阻塞(停顿),并同步等待页面的释放[Gorman 04] [81]。
直接回收可以调用内核模块的收缩器函数:这些函数释放可能存储在缓存中的内存,包括内核的slab缓存。
交换设备
交换设备提供了系统内存不足时的一种降级操作模式:进程可以继续分配内存,但是较少使用的页面会被移动到和从它们的交换设备中,这通常导致应用程序运行速度明显变慢。一些生产系统运行时没有启用交换设备;其理由是,这些关键系统的降级操作模式对于那些可能有大量冗余(且健康)服务器的系统来说是不可接受的,这些服务器比已开始交换的服务器更适合使用(例如Netflix的云实例通常是这种情况)。如果一个没有启用交换设备的系统内存耗尽,内核会启动内存不足杀手进程来牺牲一个进程。为了避免这种情况,应用程序会配置成永远不超出系统的内存限制。
OOM Killer
Linux的内存耗尽杀手(OOM Killer)是释放内存的最后手段:它使用启发式方法查找受害进程,并通过杀死它们来牺牲它们。这种启发式方法寻找能够释放多个页面且不是关键任务(如内核线程或init,即PID 1)的最大受害者。Linux提供了调整系统范围和每个进程的OOM Killer行为的方法。
页面压缩
随着时间的推移,已释放的页面变得碎片化,这使得内核难以分配需要的大块连续内存。内核使用压缩例程来移动页面,从而释放连续的内存区域。
文件系统缓存和缓冲
Linux借用空闲内存进行文件系统缓存,并在需要时将其返回为自由状态。这种借用的结果是,Linux启动后报告的空闲内存迅速接近零,这可能会导致用户误以为系统内存不足,实际上只是在预热文件系统缓存。此外,文件系统还使用内存进行写回缓冲。
Linux可以通过调整设置(例如vm.swappiness)来优先从文件系统缓存中释放内存,或者通过交换来释放内存。
缓存和缓冲在第8章中进一步讨论。
进一步阅读
这是在使用工具之前武装你必需的知识的简要总结。第14章涵盖了其他主题,包括内核页面分配和NUMA。《系统性能》第7章对内存分配和分页进行了更深入的讨论(Gregg 13b)。
7.1.2 BPF Capabilities
传统的性能工具为内存内部提供了一些洞察。例如,它们可以显示虚拟内存和物理内存使用情况的详细分解,以及页面操作的速率。这些传统工具将在接下来的部分进行总结。
BPF跟踪工具可以提供内存活动的额外洞察,回答以下问题:
- 进程的物理内存(RSS)为什么持续增长?
- 哪些代码路径导致页面错误?对应哪些文件?
- 哪些进程因等待换页而阻塞?
- 系统范围内正在创建哪些内存映射?
- 在OOM杀死时的系统状态是什么?
- 应用程序代码路径在分配内存吗?
- 应用程序分配的是哪些类型的对象?
- 是否存在长时间未释放的内存分配?(可能表示潜在泄漏。)
这些问题可以通过BPF来回答,通过对软件事件或跟踪点进行仪表化来进行故障和系统调用;使用kprobes来跟踪内核内存分配函数;使用uprobes来跟踪库、运行时和应用程序分配器;使用USDT探针来跟踪libc分配器事件;以及使用PMCs进行内存访问溢出采样。这些事件源可以在一个BPF程序中混合使用,以便在不同系统之间共享上下文。
使用BPF可以对包括分配、内存映射、故障和换页在内的内存事件进行仪表化。可以获取堆栈跟踪,以显示这些事件的原因。
事件源
表7-1列出了用于仪表化内存的事件源。


这些探针提供了libc分配器内部操作的洞察力。
开销
如前所述,内存分配事件可能每秒发生数百万次。尽管BPF程序经过优化以提高速度,但每秒调用数百万次可能会导致显著的开销,使目标软件减慢超过10%,在某些情况下甚至可能达到10倍(10x),这取决于跟踪事件的频率和所使用的BPF程序。
为了解决这种开销,图7-2显示了使用粗箭头表示频繁路径,使用浅箭头表示不频繁路径。通过跟踪不频繁的事件(如页面错误、页面移出、brk()调用和mmap()调用),可以回答或近似回答许多关于内存使用的问题。跟踪这些事件的开销可以忽略不计。
跟踪malloc()调用的一个原因是显示导致malloc()调用的代码路径。可以使用不同的技术来显示这些代码路径:CPU堆栈的定时采样,如第6章所述。在CPU火焰图中搜索"malloc"是一种粗略但廉价的方法,可以识别频繁调用这个函数的代码路径,而无需直接跟踪该函数。
未来uprobes的性能可能通过涉及用户空间到用户空间跳转的动态库(而不是内核陷阱)大幅改进(提高10倍至100倍),详见第2章中的第2.8.4节。
7.1.3 Strategy
如果你对内存性能分析还不熟悉,以下是建议的整体策略:
1. 检查系统消息,查看OOM killer是否最近杀死了进程(例如,使用dmesg(1))。
2. 检查系统是否有交换设备,以及交换使用量;同时检查这些设备是否有活动的I/O(例如,使用swap(1), iostat(1), 和vmstat(1))。
3. 检查系统上的空闲内存量以及缓存的系统范围使用情况(例如,使用free(1))。
4. 检查每个进程的内存使用情况(例如,使用top(1)和ps(1))。
5. 检查页面错误率,并检查页面错误时的堆栈跟踪,这可以解释RSS增长。
6. 检查支持页面错误的文件。
7. 跟踪brk()和mmap()调用,以获取内存使用的不同视角。
8. 浏览并执行本章BPF工具部分列出的BPF工具。
9. 使用PMCs(尤其是启用了PEBS的情况下),测量硬件缓存未命中和内存访问,以确定导致内存I/O的函数和指令(例如,使用perf(1))。
以下各节将更详细地解释这些工具。
7.2 Traditional Tools
传统的性能工具提供了许多基于容量的内存使用统计数据,包括每个进程和整个系统正在使用的虚拟和物理内存量,有些还可以按进程段或slab进行细分。分析内存使用情况超越基础数据,如页面错误率,需要每个分配库、运行时或应用程序内置的仪器化;或者可以使用像Valgrind这样的虚拟机分析工具;但后者会导致目标应用程序运行时仪器化后慢10倍。
BPF工具更高效,开销更小。即使它们单独并不能解决问题,在不足以解决问题的情况下,传统工具可以提供线索,指导您使用BPF工具。根据它们的来源和测量类型,本章表7-2列出的传统工具已在此处进行分类。

以下几节总结了这些工具的关键功能。查阅它们的man手册和其他资源,包括《系统性能》(Gregg 13b),以获取更多的使用方法和解释。第14章包括用于内核slab分配的slabtop(1)工具。
7.2.1 Kernel Log
内核内存杀手会在每次需要终止进程时将详细信息写入系统日志,可以使用dmesg(1)查看。例如:

输出包括系统范围内存使用的摘要、进程表以及被终止的目标进程。在深入进行内存分析之前,您应该始终检查dmesg(1)。
7.2.2 Kernel Statistics
内核统计工具使用内核中的统计数据源,通常通过/proc接口公开(例如,/proc/meminfo、/proc/swaps)。这些工具的优点在于,这些指标通常由内核始终启用,因此在使用它们时几乎没有额外的开销。它们通常也可以被非root用户读取。
swapon
swapon命令可以显示是否配置了交换设备以及它们的使用量。例如:
```
$ swapon
NAME TYPE SIZE USED PRIO
/dev/dm-2 partition 980M 0B -2
```
这个输出显示了一个系统有一个980兆字节的交换分区,但目前没有使用任何交换空间。现在许多系统没有配置交换空间,如果是这种情况,swapon命令将不会输出任何内容。
如果交换设备有活动的I/O,可以在vmstat(1)命令的"si"和"so"列中看到,并且作为iostat(1)中的设备I/O。
free
free命令用于总结内存使用情况,并显示系统范围内可用的空闲内存。以下是使用-m选项(以兆字节为单位)的示例:
```
$ free -m
total used free shared buff/cache available
Mem: 189282 183022 1103 4 5156 4716
Swap: 0 0 0
```
free命令的输出在近年来已经改进,使其更少令人困惑;现在包括一个"available"列,显示可用于使用的内存量,包括文件系统缓存。这比"free"列少令人困惑,后者只显示完全未使用的内存。如果您认为系统因为"free"低而内存不足,应考虑使用"available"列。
文件系统缓存页面显示在"buff/cache"列中,它总和了两种类型:I/O缓冲区和文件系统缓存页面。您可以使用-w选项(宽格式)将这些页面在单独的列中查看。
此特定示例来自一个拥有184GB总主内存的生产系统,其中大约有4GB当前可用。要获取更详细的系统范围内存信息,可以查看/proc/meminfo文件。
ps
ps命令(进程状态命令)可以显示进程的内存使用情况:
```
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
[...]
root 2499 0.0 0.0 30028 2720 ? Ss Jan25 0:00 /usr/sbin/cron -f
root 2703 0.0 0.0 0 0 ? I 04:13 0:00 [kworker/41:0]
pcp 2951 0.0 0.0 116716 3572 ? S Jan25 0:00 /usr/lib/pcp/bin/pmwe...
root 2992 0.0 0.0 0 0 ? I Jan25 0:00 [kworker/17:2]
root 3741 0.0 0.0 0 0 ? I Jan25 0:05 [kworker/0:3]
www 3785 1970 95.7 213734052 185542800 ? Sl Jan25 15123:15 /apps/java/bin/java...
[...]
```
该输出包括以下列:
- %MEM:该进程使用的系统物理内存的百分比
- VSZ:虚拟内存大小
- RSS:驻留集大小:该进程使用的总物理内存
该输出显示了java进程在系统上使用了95.7%的物理内存。ps命令可以打印自定义列,以便专注于内存统计信息(例如,ps -eo pid,pmem,vsz,rss)。这些统计信息及更多可以在/proc文件中找到:/proc/PID/status。
pmap
pmap命令(进程映射命令)可以按地址空间段显示进程的内存使用情况。例如:


这种视图可以识别由库或映射文件消耗大量内存的情况。扩展的(-x)输出包括一个“dirty”页面的列:这些页面在内存中发生了更改,尚未保存到磁盘上。
vmstat
vmstat(虚拟内存统计)命令显示系统在一段时间内的各种系统统计信息,包括内存、CPU和存储I/O的统计数据。例如,每秒打印一次摘要行:
```
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
12 0 0 1075868 13232 5288396 0 0 14 26 16 19 38 2 59 0 0
14 0 0 1075000 13232 5288932 0 0 0 0 28751 77964 22 1 77 0 0
9 0 0 1074452 13232 5289440 0 0 0 0 28511 76371 18 1 81 0 0
15 0 0 1073824 13232 5289828 0 0 0 0 32411 86088 26 1 73 0 0
```
“free”、“buff”和“cache”列显示以Kbytes为单位的内存,分别表示空闲内存、存储I/O缓冲区使用的内存和文件系统缓存使用的内存。“si”和“so”列显示从磁盘中交换进和交换出的内存,如果活动。
输出的第一行是“自启动以来的摘要”,大多数列显示自系统启动以来的平均值;然而,内存列显示当前状态。第二行及后续行是每秒的摘要统计。
sar
sar(系统活动报告)命令是一个多功能工具,用于打印不同目标的指标。选项-B 显示页面统计信息:


这是从一个繁忙的生产服务器获取的输出。输出非常宽,因此列已换行,这里稍显难读。页面故障率("fault/s")很低,每秒不到300次。也没有任何页面扫描("pgscan"列),表明系统可能没有达到内存饱和状态。
这是从进行软件构建的服务器获取的输出:

现在页面故障率非常高——每秒超过一百万次故障。这是因为软件构建涉及许多短暂的进程,每个新进程在首次执行时会出现地址空间故障。
7.2.3 Hardware Statistics and Sampling
有许多用于内存I/O事件的性能监控计数器(PMC)。要明确一点,这里指的是来自处理器上的CPU单元到主内存银行的I/O,经由CPU缓存。在第2章中介绍的PMC可分为两种模式:计数模式和抽样模式。计数模式提供统计摘要,并且几乎没有额外开销。抽样模式则将一些事件记录到文件中,以供后续分析。
以下示例使用perf(1)以计数模式进行测量,监测系统范围内最后一级缓存(LLC)的加载和缺失情况,每秒输出一次结果(-I 1000):

为方便起见,perf(1)已经识别了这些PMC之间的关系,并输出了一个缺失率百分比。LLC缺失是衡量向主内存进行I/O的一种方式,因为一旦内存加载或存储未命中LLC,它就变成了对主内存的访问。
现在,perf(1)正在抽样模式下使用,记录每十万个L1数据缓存未命中的详细信息:

使用如此高的抽样阈值(-c 100000),是因为L1访问非常频繁,较低的阈值可能会收集太多样本,从而影响正在运行的软件的性能。如果您不确定PMC的速率,请首先使用计数模式(perf stat)查找,然后可以计算出一个适当的阈值。
perf report的输出显示了L1数据缓存未命中的符号。建议在使用内存PMC时使用PEBS,以确保采样指令指针的准确性。在perf中,可以在事件名称的末尾添加:p、:pp(更好)、或:ppp(最佳),以启用PEBS;ps越多,准确性越高。(详见perf-list(1)手册页中的p修饰符部分。)
7.3 BPF Tools
本节介绍了用于内存性能分析和故障排除的BPF工具(见图7-4)。

这些工具要么来自于第4章和第5章介绍的BCC和bpftrace代码库,要么是专门为本书创建的。有些工具同时出现在BCC和bpftrace中。表7-3列出了本节中涵盖的工具的来源(BT代表bpftrace)。

有关来自BCC和bpftrace的工具,请查看它们的代码库以获取完整和更新的工具选项和功能列表。以下是一些最重要的功能总结。
第14章提供了更多用于内核内存分析的BPF工具:kmem(8)、kpages(8)、slabratetop(8)和numamove(8)。
7.3.1 oomkill
oomkill(8)是一个BCC和bpftrace工具,用于跟踪内存耗尽杀手事件并打印详细信息,例如负载平均值。负载平均值为OOM时的系统状态提供了一些额外的背景信息,显示系统是否变得更忙或保持稳定。
以下示例展示了来自一个包含48个CPU的生产实例中的BCC的oomkill(8):
```
# oomkill
Tracing OOM kills... Ctrl-C to stop.
08:51:34 Triggered by PID 18601 ("perl"), OOM kill of PID 1165 ("java"), 18006224
pages, loadavg: 10.66 7.17 5.06 2/755 18643
[...]
```
这个输出显示PID 18601(perl)需要内存,触发了对PID 1165(java)的OOM杀手。PID 1165的大小达到了18006224页;每页通常为4KB,具体取决于处理器和进程内存设置。负载平均值显示在OOM杀手发生时系统变得更加繁忙。
该工具通过使用kprobes跟踪oom_kill_process()函数并打印各种详细信息来工作。在这种情况下,负载平均值通过简单读取/proc/loadavg来获取。此工具可以根据需要增强,打印其他调试OOM事件时所需的详细信息。此外,尚未使用该工具的oom tracepoints可以显示有关任务选择方式的更多详细信息。
当前BCC版本不使用命令行参数。
bpftrace
bpftrace版本的oomkill(8)的代码如下:(接下来是bpftrace版本的代码)


该程序跟踪oom_kill_process(),并将第二个参数转换为一个struct oom_control,其中包含牺牲进程的详细信息。它打印导致OOM事件的当前进程的详细信息(pid、comm),然后是目标进程的详细信息,最后使用system()调用打印负载平均值。
7.3.2 memleak
memleak(8)是一个BCC工具,用于跟踪内存分配和释放事件,并记录分配时的堆栈跟踪。随着时间的推移,它可以显示长期未被释放的内存分配,即长期生存者。以下示例展示了在一个bash shell进程上运行的memleak(8):


默认情况下,memleak(8)每五秒打印一次输出,显示分配的堆栈和尚未被释放的总字节数。最后一个堆栈显示,通过execute_command()和make_env_array_from_var_list()分配了1473字节。
单独使用memleak(8)无法确定这些分配是真正的内存泄漏(即分配的内存没有引用且永远不会被释放),还是内存增长,或者只是长期分配。要区分它们,需要研究和理解代码路径。
如果不提供-p PID参数,memleak(8)会跟踪内核分配:

对于进程目标,memleak(8)通过跟踪用户级别的分配函数工作:malloc()、calloc()、free()等。对于内核,它使用kmem跟踪点:kmem:kmalloc、kmem:kfree等。
命令行用法:
memleak [options] [-p PID] [-c COMMAND] [interval [count]]
选项包括:
- -s RATE:以RATE为单位采样每个分配,以降低开销
- -o OLDER:删除年龄小于OLDER(以毫秒为单位)的分配
分配,尤其是用户级别的分配,可能非常频繁,每秒数百万次。这可能使目标应用程序的运行速度减慢10倍甚至更多,具体取决于其忙碌程度。因此,目前来说,memleak(8)更多用于故障排除或调试工具,而不是日常生产分析工具。正如前面提到的,这种情况将持续到uprobes的性能得到显著改善。
7.3.3 mmapsnoop
mmapsnoop(8)4跟踪系统范围内的mmap(2)系统调用,并打印请求映射的详细信息。这对于一般的内存映射使用调试非常有用。示例输出:

这些输出首先包含了用于获取事件输出的perf_event环形缓冲区的映射,这是该BCC工具使用的。然后可以看到Java映射,用于新进程启动,以及相关的保护和映射标志。
保护标志(PROT):
- R:PROT_READ
- W:PROT_WRITE
- E:PROT_EXEC
映射标志(MAP):
- S:MAP_SHARED
- P:MAP_PRIVATE
- F:MAP_FIXED
- A:MAP_ANON
mmapsnoop(8)支持使用-T选项打印时间列。
该工具通过仪表化syscalls:sys_enter_mmap跟踪点来工作。由于新映射的频率应该相对较低,因此该工具的开销应该可以忽略不计。
第8章继续分析了内存映射文件,并包括了mmapfiles(8)和fmapfaults(8)工具。
7.3.4 brkstack
应用程序数据的通常存储区是堆,通过调用brk(2)系统调用来扩展。跟踪brk(2)并显示导致此扩展的用户级堆栈跟踪可能非常有用。Linux上还有一个sbrk(2)变体,但在Linux上,sbrk(2)被实现为调用brk(2)的库调用。
可以使用syscalls:syscall_enter_brk跟踪点来跟踪brk(2),并且可以使用BCC的trace(8)工具来显示此跟踪点的堆栈。可以使用stackcount(8)来计算此跟踪点的频率,也可以使用bpftrace的一行命令或者perf(1)来进行相似操作。以下是使用BCC工具的示例:
```bash
# trace -U t:syscalls:sys_enter_brk
# stackcount -PU t:syscalls:sys_enter_brk
```
例如:


这段截断的输出展示了来自一个名为"java"的进程的brk(2)堆栈,从JLI_List_new()、JLI_MemAlloc(),以及通过sbrk(3):看起来像是一个列表对象触发了堆扩展。来自cron的第二个堆栈跟踪中断了。为了使Java堆栈正常工作,我必须使用带有帧指针的libc版本。这在第13章的第13.2.9节中进一步讨论。
brk(2)的增长是不频繁的,堆栈跟踪可能揭示了一个需要比可用空间更多的大型且不寻常的分配,或者是一个正常的代码路径恰好需要比可用空间多一个字节的情况。需要研究代码路径以确定是哪种情况。由于这些增长不频繁,跟踪它们的开销可以忽略不计,使得brk跟踪成为一种廉价的技术,用于发现内存增长的一些线索。相比之下,直接跟踪频繁发生的内存分配函数(例如malloc())的开销可能非常昂贵,使得跟踪成本不可承受。另一个低开销的用于分析内存增长的工具是faults(8),在第7章的第7.3.6节中有所涵盖,它跟踪页面错误。
记住和查找工具通常比记住一行命令更容易,因此这里将这个重要的功能实现为bpftrace工具brkstack(8)5:

7.3.5 shmsnoop
shmsnoop(8)6是一个BCC工具,用于跟踪System V共享内存系统调用:shmget(2)、shmat(2)、shmdt(2)和shmctl(2)。它可用于调试共享内存的使用。例如,在启动Java应用程序期间:

这个输出展示了Java使用shmget(2)分配共享内存,接着是各种共享内存操作及它们的参数。shmget(2)的返回值是0x58c000a,即标识符,此标识符在后续的调用中被Java和Xorg共享;换句话说,它们共享内存。
这个工具通过跟踪共享内存系统调用来工作,这些调用应该足够少,以至于工具的开销可以忽略不计。
命令行用法:
shmsnoop [选项]
选项包括:
- -T:包括时间戳
- -p PID:仅测量指定进程
7.3.6 faults
跟踪页面错误及其堆栈跟踪提供了对内存使用的特定视角:不是分配内存的代码路径,而是首次使用并触发页面错误的代码路径。这些页面错误导致RSS增长,因此堆栈跟踪可以解释进程为何会增长。与brk()类似,可以使用其他工具的一行命令来跟踪这个事件,例如使用BCC和stackcount(8)来频繁计数带有堆栈跟踪的用户态和内核态页面错误:
```bash
# stackcount -U t:exceptions:page_fault_user
# stackcount t:exceptions:page_fault_kernel
```
示例输出,使用-P显示进程详细信息:

这个输出展示了一个Java进程的启动,以及其C2编译器线程在编译代码为指令文本时发生内存错误。
页面错误火焰图
页面错误的堆栈跟踪可以被可视化为火焰图,以帮助导航。(火焰图在第二章介绍。)这些指令使用了我的原始火焰图软件[37],生成了一个页面错误火焰图,其中一部分如图7-5所示:
```bash
# stackcount -f -PU t:exceptions:page_fault_user > out.pagefaults01.txt
$ flamegraph.pl --hash --width=800 --title="Page Fault Flame Graph" \
--colors=java --bgcolor=green < out.pagefaults01.txt > out.pagefaults01.svg
```

这个放大的区域展示了Java编译器线程的代码路径,它们增加了主内存并触发了页面错误。
Netflix已经通过Vector,一个实例分析工具,自动化生成页面错误火焰图,以便Netflix开发人员可以通过点击按钮生成这些图表(详见第17章)。
bpftrace
为了方便使用,这里是一个名为`faults(8)7`的`bpftrace`工具,用于跟踪带有堆栈的页面错误:
```bpftrace
#!/usr/local/bin/bpftrace
software:page-faults:1
{
@[ustack, comm] = count();
}
```
这个工具通过记录软件事件的页面错误,并设置溢出计数为一来运行BPF程序:它会针对每个页面错误运行BPF程序,并对用户级别堆栈跟踪和进程名称进行频率计数。
7.3.7 ffaults
`ffaults(8)8`根据文件名跟踪页面错误。例如,从软件构建过程中:

这个输出显示,大部分页面错误发生在没有文件名的区域,这些通常是进程堆(process heaps),在跟踪过程中发生了537,925次页面错误。libc库在跟踪过程中遇到了84,814次页面错误。这是因为软件构建过程创建了许多短暂的进程,它们在其新的地址空间中出现了页面错误。

这个工具使用kprobes来跟踪handle_mm_fault()内核函数,并根据其参数确定页面错误的文件名。文件错误率会根据工作负载的不同而变化;您可以使用诸如perf(1)或sar(1)的工具来检查它。对于高错误率,这个工具的开销可能会开始变得显著。
7.3.8 vmscan
vmscan(8) 使用vmscan跟踪点来监控页面回收守护程序(kswapd),在系统面临内存压力时释放内存以供重用。请注意,尽管术语“scanner”仍然用于指代这个内核函数,但为了提高效率,现代Linux通过活动和非活动内存的链表来管理内存。
在一个有36个CPU的系统上运行vmscan,当系统内存不足时:


每秒列显示的内容如下:
- **S-SLABms**: shrink slab 的总时间,单位为毫秒。这是从各种内核缓存中回收内存的过程。
- **D-RECLAIMms**: 直接回收的总时间,单位为毫秒。这是前台回收,当内存被写入磁盘时,会阻塞内存分配。
- **M-RECLAIMms**: 内存控制组回收的总时间,单位为毫秒。如果使用了内存控制组,这会显示当一个控制组超过其限制时,其内存被回收的时间。
- **KSWAPD**: kswapd 唤醒的次数。
- **WRITEPAGE**: kswapd 写入页面的次数。
这些时间是跨所有CPU的总计,这提供了比其他工具(如vmstat(1))所看到的计数更为详细的成本衡量。
注意直接回收(D-RECLAIMms)的时间:这种回收是“不好的”,但是必要的,会导致性能问题。通过调整其他vm sysctl可调参数,希望能够在必须进行直接回收之前尽早启动后台回收,从而消除这种影响。
输出的直方图显示了直接回收和shrink slab每个事件的时间,单位为纳秒。
vmscan(8)的源代码可以在以下位置找到:

这个工具使用各种vmscan跟踪点来记录事件开始的时间,以便维护持续时间的直方图和累计总数。
7.3.9 drsnoop
drsnoop(8)是一个用于跟踪直接回收内存方法的BCC工具,它展示了受影响的进程及其回收所需的延迟时间。这个工具可以用来量化内存受限系统对应用程序性能的影响。例如:

这些输出显示了一些Java 程序的直接回收过程,耗时在一到七毫秒之间。可以通过这些回收的频率和持续时间来评估其对应用程序的影响。
该工具通过跟踪vmscan中的mm_vmscan_direct_reclaim_begin和mm_vmscan_direct_reclaim_end跟踪点来实现。这些通常是低频事件(通常会突发发生),因此其开销应该可以忽略不计。
命令行用法:
```
drsnoop [选项]
```
选项包括:
- **-T**: 包括时间戳
- **-p PID**: 仅测量指定PID的进程
7.3.10 swapin
swapin(8)显示正在从交换设备中换入的进程,如果这些设备存在并正在使用。例如,当我使用vmstat(1)观察时,该系统将一些内存换出,并将36千字节换入("si"列)。


这段输出显示 systemd-logind(PID 1354)有9次换入操作。根据4KB页面大小,这累计到了vmstat(1)中看到的36KB。我通过ssh登录到系统,并且登录软件中的这个组件已经被换出,因此登录时间比平常更长。
当应用程序尝试使用已经移动到交换设备的内存时,就会发生换入操作。这是衡量由于交换而导致应用程序性能损失的重要指标。其他交换指标,如扫描和换出,可能不会直接影响应用程序性能。
swapin(8)的源代码位于:

该工具使用kprobes跟踪swap_readpage()内核函数,该函数在交换线程的上下文中运行,因此bpftrace内置的comm和pid反映了交换过程的进程信息。
7.3.11 hfaults
hfaults(8)可以跟踪巨大页面错误,并根据进程的详细信息确认巨大页面是否正在使用。例如:

这个输出包括一个测试程序hugemmap,其PID为884,触发了九次巨大页面错误。
hfaults(8)的源代码位于:

如果需要,可以从函数参数中获取更多详细信息,包括struct mm_struct和struct vm_area_struct。ffaults(8)工具(参见第7.3.7节)从vm_area_struct中获取了文件名。
7.3.12 Other Tools
还有两个值得一提的BPF工具:
- **llcstat(8)**,来自BCC,在第5章有详细介绍;它显示了按进程划分的最后一级缓存命中率。
- **profile(8)**,来自BCC,在第5章有详细介绍;它对堆栈跟踪进行采样,可作为一种粗略且廉价的方法,用于查找malloc()代码路径。
7.4 BPF One-Liners
7.4.1 BCC
统计用户级别堆扩展(brk())操作的方法,使用用户级堆栈跟踪:
```
stackcount -U t:syscalls:sys_enter_brk
```
统计用户级别页面错误的方法,使用用户级堆栈跟踪:
```
stackcount -U t:exceptions:page_fault_user
```
通过tracepoint统计vmscan操作的方法:
```
funccount 't:vmscan:*'
```
显示每个进程的hugepage_madvise()调用:
```
trace hugepage_madvise
```
统计页面迁移的次数:
```
funccount t:migrate:mm_migrate_pages
```
跟踪内存整理(compaction)事件:
```
trace t:compaction:mm_compaction_begin
```
7.4.2 bpftrace
统计进程堆扩展(brk())操作的代码路径:
```
bpftrace -e 'tracepoint:syscalls:sys_enter_brk { @[ustack, comm] = count(); }'
```
按进程统计页面错误:
```
bpftrace -e 'software:page-fault:1 { @[comm, pid] = count(); }'
```
通过用户级别堆栈跟踪统计用户级页面错误:
```
bpftrace -e 'tracepoint:exceptions:page_fault_user { @[ustack, comm] = count(); }'
```
通过tracepoint统计vmscan操作:
```
bpftrace -e 'tracepoint:vmscan:* { @[probe] = count(); }'
```
显示每个进程的hugepage_madvise()调用:
```
bpftrace -e 'kprobe:hugepage_madvise { printf("%s by PID %d\n", probe, pid); }'
```
统计页面迁移的次数:
```
bpftrace -e 'tracepoint:migrate:mm_migrate_pages { @ = count(); }'
```
跟踪内存整理(compaction)事件:
```
bpftrace -e 't:compaction:mm_compaction_begin { time(); }'
```
7.5 Optional Exercises
如果没有特别指定,可以使用bpftrace或BCC完成以下任务:
1. 在生产或本地服务器上运行vmscan(8)十分钟。如果在直接回收(D-RECLAIMms)中花费了任何时间,则还需运行drsnoop(8)以基于每个事件进行测量。
2. 修改vmscan(8),每20行打印一次标题,以保持屏幕显示。
3. 在应用程序启动期间(生产环境或桌面应用程序),使用fault(8)来计算页面故障堆栈跟踪次数。这可能涉及修复或找到支持堆栈跟踪和符号的应用程序(参见第13章和第18章)。
4. 根据练习3的输出创建一个页面故障火焰图。
5. 开发一个工具来通过brk(2)和mmap(2)跟踪进程虚拟内存的增长。
6. 开发一个工具来打印通过brk(2)进行扩展的大小。可以根据需要使用系统调用跟踪点、kprobes或libc USDT探针。
7. 开发一个工具来显示在页面整理中花费的时间。可以使用compaction:mm_compaction_begin和compaction:mm_compaction_end跟踪点。打印每个事件的时间并将其总结为直方图。
8. 开发一个工具来显示在shrink slab中花费的时间,按slab名称(或shrinker函数名称)细分。
9. 在测试环境中使用memleak(8)查找长期存活的对象。还要估计运行memleak(8)时的性能开销和不运行时的性能开销。
10. (高级,未解决)开发一个工具来调查交换抖动:显示页面在交换设备上的时间(以直方图显示)。这可能涉及测量从交换出到交换入的时间。
7.6 Summary
本章总结了进程如何使用虚拟和物理内存,并介绍了使用传统工具进行内存分析的方法,重点是通过使用类型来显示内存占用量。本章还展示了如何使用BPF工具来测量OOM killer、用户级分配、内存映射、页面故障、vmscan、直接回收和换入等内存活动的速率和持续时间。
8 File Systems
文件系统分析的历史重点通常集中在磁盘I/O及其性能上,但文件系统往往更适合作为分析的起点。应用程序通常直接与文件系统交互,文件系统可以利用缓存、预读、缓冲和异步I/O来避免将磁盘I/O延迟暴露给应用程序。
由于传统工具在文件系统分析方面较少,这是BPF跟踪真正有助益的领域。文件系统跟踪可以测量应用程序在I/O等待中的全部时间,包括磁盘I/O、锁定或其他CPU工作。它可以显示负责的进程以及操作的文件,这些信息对于从底层磁盘级别获取可能更为困难的上下文非常有用。
学习目标:
- 理解文件系统组件:VFS、缓存和写回
- 了解使用BPF进行文件系统分析的目标
- 学习成功分析文件系统性能的策略
- 根据文件、操作类型和进程特性来描述文件系统工作负载
- 测量文件系统操作的延迟分布,并识别双模分布和延迟异常问题
- 测量文件系统写回事件的延迟
- 分析页面缓存和预读性能
- 观察目录和inode缓存行为
- 使用bpftrace单行命令以自定义方式探索文件系统使用情况
本章从文件系统分析的必要背景开始,总结了I/O堆栈和缓存。我探讨了BPF可以解答的问题,并提供了一个整体的跟踪策略。接着,我重点介绍工具,首先是传统的文件系统工具,然后是BPF工具,包括一系列BPF单行命令。本章以可选的练习结束。
8.1 Background
这一部分涵盖了文件系统的基础知识、BPF的能力以及文件系统分析的建议策略。
8.1.1 File Systems Fundamentals
I/O堆栈
图8-1显示了通用的I/O堆栈,展示了从应用程序到磁盘设备的I/O路径。

在图表中包含了一些术语:逻辑I/O描述了对文件系统的请求。如果这些请求必须从存储设备上提供服务,则它们变成物理I/O。并非所有的I/O操作都会成为物理I/O;许多逻辑读请求可以从文件系统缓存中返回,从未成为物理I/O。图表中还包括了原始I/O,尽管现在很少使用:这是应用程序在没有文件系统的情况下使用磁盘设备的一种方式。
文件系统通过虚拟文件系统(VFS)进行访问,这是一个通用的内核接口,允许使用相同的调用支持多个不同的文件系统,并且可以轻松添加新的文件系统。它提供了读取、写入、打开、关闭等操作,这些操作由文件系统映射到它们自己的内部函数。
在文件系统之后,可能还会使用卷管理器来管理存储设备。此外,还有一个块I/O子系统来管理对设备的I/O操作,包括队列、合并功能等。这些内容将在第9章中进行详细讨论。
文件系统缓存
Linux使用多个缓存来通过文件系统提高存储I/O的性能,如图8-2所示。

这些缓存包括:
■ 页面缓存:包含虚拟内存页面,包括文件内容和I/O缓冲区(曾经是单独的“缓冲区缓存”),并提高了文件和目录I/O的性能。
■ Inode缓存:Inode(索引节点)是文件系统用来描述其存储对象的数据结构。VFS有自己的通用版本的inode,Linux会保持这些的缓存,因为它们经常被读取用于权限检查和其他元数据。
■ 目录缓存:称为dcache,这个缓存将目录条目名映射到VFS的inode,提高了路径名查找的性能。
页面缓存通常是这些缓存中最大的,因为它不仅缓存文件的内容,还包括“脏”页面,这些页面已被修改但尚未写入磁盘。各种情况可以触发这些脏页的写入,包括一组间隔(例如,30秒)、显式的sync()调用以及第7章中解释的页面换出守护进程(kswapd)。
预读取
一个名为预读取或预取的文件系统特性,涉及检测顺序读取的工作负载,预测将访问的下一个页面,并将它们加载到页面缓存中。这种预热仅改善顺序访问工作负载的读取性能,而不是随机访问工作负载。Linux还支持显式的readahead()系统调用。
回写
Linux支持以回写模式进行文件系统写入,在这种模式下,缓冲区在内存中被标记为脏,并由内核工作线程稍后刷新到磁盘,以避免直接在慢速磁盘I/O上阻塞应用程序。
进一步阅读
这是一个简要总结,旨在在您使用这些工具之前装备您必要的知识。文件系统在《系统性能》第8章中有更深入的讨论[Gregg 13b]。
8.1.2 BPF Capabilities
传统的性能工具主要关注磁盘I/O性能,而非文件系统性能。BPF工具可以提供这种缺失的可观测性,展示每个文件系统的操作、延迟和内部函数。BPF能够帮助回答的问题包括:
■ 文件系统请求是什么?按类型计数?
■ 对文件系统的读取大小是多少?
■ 同步写入的I/O量有多少?
■ 文件工作负载访问模式是什么:随机还是顺序?
■ 哪些文件被访问?由哪个进程或代码路径?字节数、I/O计数?
■ 发生了什么文件系统错误?是什么类型的,是为谁发生的?
■ 文件系统延迟的来源是什么?是磁盘、代码路径、锁定?
■ 文件系统延迟的分布是什么样的?
■ Dcache和Icache的命中与未命中比率如何?
■ 读取时的页面缓存命中率是多少?
■ 预取/预读取效果如何?是否需要调整?
如前所示的图表所示,您可以跟踪涉及的I/O,以找到这些问题的答案。
事件来源
在表8-1中列出了可以对其进行仪器化的I/O类型。

这提供了从应用程序到设备的可见性。文件系统I/O可以根据文件系统的不同通过文件系统的跟踪点可见。例如,ext4 提供了超过一百个跟踪点。
开销
逻辑I/O,特别是对文件系统缓存的读写,可能非常频繁:每秒超过100,000个事件。在跟踪这些事件时要谨慎,因为在这种速率下,性能开销可能开始变得显著。同时,对VFS(虚拟文件系统)的跟踪也要小心:VFS也被许多网络I/O路径使用,因此这也会增加数据包的开销,可能导致高速率的问题。
大多数服务器上的物理磁盘I/O通常很低(少于1000 IOPS),因此跟踪它们几乎不会带来什么开销。但某些存储和数据库服务器可能是例外情况:在使用iostat(1)之前检查I/O速率。
8.1.3 Strategy
如果你对文件系统性能分析还不熟悉,以下是建议的整体策略,供你参考。接下来的部分将详细解释这些工具。
1. 确定已挂载的文件系统:参考 df(1) 和 mount(8)。
2. 检查已挂载文件系统的容量:过去,在某些文件系统接近100%满时,由于使用了不同的空闲块查找算法(例如FFS、ZFS),可能会出现性能问题。
3. 在了解生产工作负载之前,不要使用不熟悉的BPF工具来理解未知的生产工作负载。在空闲系统上,创建一个已知的文件系统工作负载,例如使用 fio(1) 工具。
4. 运行 opensnoop(8) 来查看哪些文件正在被打开。
5. 运行 filelife(8) 检查存在短暂生存文件的问题。
6. 寻找异常缓慢的文件系统I/O,并检查进程和文件的详细信息(例如使用 ext4slower(8)、btrfsslower(8)、zfsslower(8) 等,或者使用 fileslower(8) 作为通用工具,尽管可能会带来更高的开销)。这可能会揭示一个可以消除的工作负载,或者量化一个需要进行文件系统调整的问题。
7. 检查文件系统的延迟分布(例如使用 ext4dist(8)、btrfsdist(8)、zfsdist(8) 等)。这可能会显示引起性能问题的双模分布或延迟异常值,可以用其他工具进行更深入的隔离和调查。
8. 随时间检查页面缓存命中率(例如使用 cachestat(8)):是否有其他工作负载影响了命中率,或者是否有任何调整可以改善它?
9. 使用 vfsstat(8) 将逻辑I/O率与 iostat(1) 的物理I/O率进行比较:理想情况下,逻辑I/O率远高于物理I/O率,表明缓存效果良好。
10. 浏览并执行本书BPF工具部分列出的BPF工具。
这些步骤将有助于你系统地分析和优化文件系统性能。
8.2 Traditional Tools
由于历史上分析通常集中在磁盘上,因此用于观察文件系统的传统工具较少。本节总结了使用 df(1)、mount(1)、strace(1)、perf(1) 和 fatrace(1) 进行文件系统分析的方法。
需要注意的是,文件系统性能分析通常更多使用微基准工具,而不是可观测性工具。一个推荐的文件系统微基准工具示例是 fio(1)。
8.2.1 df

输出包括一些使用 tmpfs 设备挂载的虚拟物理系统,用于存储系统状态。
检查基于磁盘的文件系统的使用百分比("Use%" 列)。例如,在上述输出中,根目录 "/" 和 "/mnt" 分别为 53% 和 15% 的使用率。一旦文件系统超过大约 90% 的使用率,可用的空闲块会变少并且更加分散,这可能导致性能问题,将顺序写入工作负载转变为随机写入工作负载。但这并非绝对,这取决于文件系统的实现方式。只是值得快速检查一下。
8.2.2 mount

这个输出显示 "/"(根目录)文件系统是 ext4,挂载选项包括 "noatime",这是一种性能调优选项,跳过记录访问时间戳。
8.2.3 strace
strace(1) 可以跟踪系统调用,从而提供文件系统操作的视图。在这个例子中,使用 -ttt 选项以微秒分辨率打印墙上时间戳作为第一个字段,并使用 -T 选项将系统调用耗时打印为最后一个字段。所有时间都以秒为单位打印。

所有这些信息对性能分析来说应该非常有价值,但有一个问题:strace(1) 历史上是使用 ptrace(2) 实现的,ptrace(2) 在系统调用的开始和结束处插入断点。这可能极大地减慢目标软件的运行速度,甚至可以使其减慢100倍以上,使得在生产环境中使用 strace(1) 变得危险。它更适用作为故障排除工具,这样的减速在故障排除过程中可以被容忍。
已经有多个项目致力于开发使用缓冲跟踪的 strace(1) 替代工具。其中一个是 perf(1),接下来将介绍它。
8.2.4 perf
Linux 的 perf(1) 多功能工具可以跟踪文件系统的跟踪点,使用 kprobes 检查虚拟文件系统(VFS)和文件系统的内部,并具有 trace 子命令作为 strace(1) 的更高效版本。例如:

perf trace 的输出在每个 Linux 版本中都在改进(上述示例展示的是 Linux 5.0)。Arnaldo Carvalho de Melo 进一步改进了这一功能,使用内核头文件解析和 BPF 来改善输出 [84];未来的版本中,例如,应该显示 openat() 调用的文件名字符串,而不仅仅是文件名指针地址。
更常用的 perf(1) 子命令,如 stat 和 record,在文件系统存在相应的跟踪点时可以与之配合使用。例如,通过 ext4 跟踪点在整个系统中统计 ext4 调用:


ext4 文件系统提供大约一百个跟踪点,用于查看其请求和内部情况。每个跟踪点都有用于相关信息的格式字符串,例如(请勿运行此命令):

嗯,这有点尴尬,但对于文件系统跟踪来说是一个重要的教训。因为 perf record 会将事件写入文件系统,如果你跟踪文件系统(或磁盘)的写操作,可能会导致反馈循环,就像我刚刚做的那样,结果是产生了 1400 万个样本和一个 1.3 GB 的 perf.data 文件!这个示例的格式字符串如下:

格式字符串(已经用粗体标出)包括设备、inode、位置、长度和写操作的标志位。
文件系统可能支持多个跟踪点,也可能只支持部分或者没有。例如,XFS 大约有 500 个跟踪点。如果你的文件系统没有跟踪点,可以尝试使用 kprobes 来对其内部进行仪表化。
为了与后续的 BPF 工具进行比较,考虑使用 bpftrace 对相同的跟踪点进行仪表化,以直方图的形式总结长度参数:


这显示大部分长度在四到八千字节之间。这种总结是在内核上下文中执行的,不需要将 perf.data 文件写入文件系统。这不仅避免了这些写操作的开销和后续处理的额外开销,还避免了反馈循环的风险。
8.2.5 fatrace
fatrace(1)是一种专门的跟踪工具,使用 Linux 的 fanotify API(文件访问通知)。示例输出:

每行显示进程名称、PID、事件类型、完整路径以及可选的状态。事件类型可以是打开(O)、读取(R)、写入(W)、关闭(C)。fatrace(1)可以用于工作负载特征化:理解访问的文件,并查找可以消除的不必要工作。
然而,对于繁忙的文件系统工作负载,fatrace(1)每秒可能产生数万行的输出,并且会消耗大量的CPU资源。通过过滤到某一类型的事件,例如仅限打开事件,可以在一定程度上缓解这种情况。

在下面的BPF部分中,提供了一个专用的BPF工具:opensnoop(8),它提供了更多的命令行选项,而且效率更高。比较对于相同繁重的文件系统工作负载,fatrace -f O 与BCC opensnoop(8) 的CPU开销:

8.3 BPF Tools
本节介绍了用于文件系统性能分析和故障排除的BPF工具(见图8-3)。

这些工具要么来自于BCC和bpftrace仓库(在第4章和第5章中介绍),要么是为本书而创建的。某些工具同时出现在BCC和bpftrace中。表8-2列出了本节中介绍的工具的来源(BT是bpftrace的简称)。

有关来自BCC和bpftrace的工具,请查阅它们的仓库以获取完整和更新的工具选项和功能列表。这里总结了一些最重要的功能。
以下工具摘要包括关于将文件描述符转换为文件名的讨论(参见scread(8))。
8.3.1 opensnoop
opensnoop(8) 在第1章和第4章中已经展示过,它由BCC和bpftrace提供。它用于跟踪文件打开操作,有助于发现数据文件、日志文件和配置文件的位置。opensnoop还能够发现由频繁打开文件引起的性能问题,或者帮助排查由缺少文件引起的问题。以下是在生产系统中使用 -T 参数输出的示例:

输出速率很高,显示Java每秒读取四个文件组约一百次(我刚刚发现了这一点)。为了适应本书的格式,文件名已部分截断。这些文件是系统指标的内存文件,理论上读取它们应该很快,但Java真的需要每秒读取一百次吗?我的下一步分析是获取负责的堆栈。由于这些是Java进程唯一执行的文件打开操作,我简单地使用以下命令统计了该PID的打开追踪点的堆栈:
```
stackcount -p 3862 't:syscalls:sys_enter_openat'
```
这显示了完整的堆栈跟踪,包括负责的Java方法。罪魁祸首原来是新的负载均衡软件。
opensnoop(8) 通过跟踪open(2)变体系统调用工作:open(2) 和 openat(2)。预期开销微乎其微,因为open(2)的频率通常很低。
BCC
命令行用法:
opensnoop [选项]
选项包括:
- -x:仅显示失败的打开操作
- -p PID:仅测量指定PID的进程
- -n NAME:仅在进程名称包含NAME时显示打开操作
bpftrace
以下是bpftrace版本的代码,它总结了其核心功能。这个版本不支持选项。

这个程序跟踪 open(2) 和 openat(2) 系统调用,从返回值中分离出文件描述符或错误号码。文件名在进入探针时被缓存,以便在系统调用退出时获取并打印,同时还会打印返回值。
8.3.2 statsnoop
`statsnoop(8)` 是一个类似于 `opensnoop(8)` 的 BCC 和 bpftrace 工具,但用于跟踪 `stat(2)` 系列系统调用。`stat(2)` 用于返回文件的统计信息。这个工具与 `opensnoop(8)` 的用途相似:用于发现文件位置、查找负载性能问题以及排除缺失文件的故障。以下是带有时间戳 `-t` 的示例生产输出:

这些输出显示 systemd-resolve(实际上是缩写的 "systemd-resolved")在一个循环中对同三个文件调用 stat(2)。
我发现在生产服务器上有多次 stat(2) 被调用,每秒达到数万次的情况,且没有很好的理由;幸运的是,stat(2) 是一个快速的系统调用,因此这些调用并没有引起主要的性能问题。然而,有一个例外情况是,Netflix 的一个微服务出现了100% 的磁盘利用率,我发现这是因为一个磁盘使用监控代理在一个大型文件系统上不断地调用 stat(2),而文件系统的元数据没有完全缓存,stat(2) 调用变成了磁盘 I/O 操作。
这个工具通过跟踪 stat(2) 的各种变体来工作,包括 tracepoints:statfs(2), statx(2), newstat(2) 和 newlstat(2)。除非 stat(2) 的调用频率非常高,否则该工具的开销预计是可以忽略不计的。
BCC
命令行用法:
statsnoop [选项]
选项包括:
- -x:仅显示失败的 stat 调用
- -t:包括一个时间戳列(秒)
- -p PID:仅监测指定进程
bpftrace
以下是 bpftrace 版本的代码,概述了其核心功能。这个版本不支持选项。

这个程序在系统调用进入时保存文件名,并在返回时获取它,以便在返回详情中显示。
8.3.3 syncsnoop
syncsnoop(8) 是一个基于 BCC 和 bpftrace 的工具,用于显示带有时间戳的 sync(2) 调用。sync(2) 用于将脏数据刷新到磁盘。以下是 bpftrace 版本的部分输出:

这个输出显示了一个名为 "TaskSchedulerFo"(被截断的名称)连续调用了五次 fdatasync(2)。sync(2) 调用可能会触发磁盘 I/O 的突发,从而影响系统的性能。时间戳被打印出来,以便与监控软件中观察到的性能问题进行关联,这将是 sync(2) 及其触发的磁盘 I/O 所导致的问题的线索。
这个工具通过跟踪 tracepoints 中的 sync(2) 变体来工作:sync(2), syncfs(2), fsync(2), fdatasync(2), sync_file_range(2) 和 msync(2)。预期该工具的开销将是可以忽略不计的,因为 sync(2) 的频率通常非常低。
BCC
目前的 BCC 版本不支持选项,并且其工作方式类似于 bpftrace 版本。
bpftrace
以下是 bpftrace 版本的代码:


如果发现 sync(2) 相关的调用是一个问题,可以使用自定义的 bpftrace 进行进一步检查,显示其参数、返回值和已发出的磁盘 I/O。
8.3.4 mmapfiles
mmapfiles(8) 是一个跟踪 mmap(2) 调用并统计映射到内存地址范围的文件频率的工具。例如:

这个例子跟踪了一个软件构建过程。每个文件通过文件名和其两级父目录显示出来。输出中的最后一个条目没有名称:它是程序私有数据的匿名映射。

它使用 kprobes 跟踪内核的 do_mmap() 函数,并从其 struct file * 参数中读取文件名,通过 struct dentry(目录条目)。dentry 只包含路径名的一个组成部分,为了提供更多关于文件位置的上下文信息,还读取并包含了父目录和祖父目录在输出中(第 10 页)。由于 mmap() 调用预计相对不频繁,因此该工具的开销预计将是可以忽略的。
聚合键可以很容易修改以包括进程名称,以显示执行这些映射的进程("@[comm, ...]"),也可以包括用户级堆栈以显示代码路径("@[comm, ustack, ...]")。
第 7 章包括一个基于事件的 mmap() 分析工具:mmapsnoop(8)。
8.3.5 scread
scread(8) 跟踪 read(2) 系统调用,并显示其操作的文件名。例如:

这显示在跟踪期间,“scriptCache-current.bin” 文件被 read(2) 调用读取了 48 次。这是基于系统调用的文件 I/O 视图;查看稍后的 filetop(8) 工具可以提供 VFS 级别的视图。这些工具有助于分析文件使用情况,帮助您查找效率低下的问题。
scread(8) 的源代码是:

File Descriptor to Filename
文件描述符到文件名的转换工具也作为一个示例,用于从文件描述符(FD)整数获取文件名。有至少两种方法可以实现这一功能:
1. 从 task_struct 开始遍历到文件描述符表,使用 FD 作为索引找到 struct file。然后可以从这个结构体中找到文件名。这种方法被 scread(2) 使用。然而,这是一种不稳定的技术:找到文件描述符表的方式(task->files->fdt->fd)涉及到内核内部结构,在不同的内核版本中可能会发生变化,这可能会破坏这个脚本。
2. 跟踪 open(2) 系统调用,并建立一个以 PID 和 FD 为键,文件/路径名为值的查找哈希表。然后可以在 read(2) 和其他系统调用期间查询这个哈希表。虽然这会增加额外的探测点(和开销),但这是一种稳定的技术。
本书中还有许多其他工具(如 fmapfault(8), filelife(8), vfssize(8) 等),这些工具在不同的操作中引用文件名;然而,这些工具通过 VFS 层的跟踪来实现,直接提供 struct file。虽然这也是一个不稳定的接口,但它可以在较少的步骤中找到文件名字符串。VFS 跟踪的另一个优势是,在每种操作类型中通常只有一个函数,而使用系统调用时可能会有多个变体(如 read(2), readv(2), preadv(2), pread64() 等),可能都需要进行跟踪。
8.3.6 fmapfault
fmapfault(8) 追踪内存映射文件的页面错误,并统计进程名和文件名。例如:

这段话的翻译如下:
这追踪了一个软件构建过程,并显示了构建过程中出现故障的构建过程和库。
本书中的后续工具,如 filetop(8), fileslower(8), xfsslower(8) 和 ext4dist(8),通过 read(2) 和 write(2) 系统调用(及其变体)显示文件 I/O。但这并非读取和写入文件的唯一方式:文件映射是另一种方法,它避免了显式的系统调用。fmapfault(8) 通过跟踪文件页面错误和新页面映射的创建,提供了它们的使用视图。请注意,实际的文件读取和写入可能远高于页面错误率。
fmapfault(8) 的源代码如下:

这个工具通过使用 kprobes 跟踪 filemap_fault() 内核函数,并从其 struct vm_fault 参数中确定映射的文件名。随着内核的变化,这些细节可能需要更新。对于故障率较高的系统,此工具的开销可能会显著。
8.3.7 filelife
filelife(8) 是一个基于 BCC 和 bpftrace 的工具,用于显示短寿命文件的生命周期:即在跟踪过程中创建并删除的文件。
以下是在软件构建过程中使用 BCC 的 filelife(8) 的示例:

这个输出展示了在构建过程中创建的许多短寿命文件,在不到一秒的时间内就被删除了。
这个工具已被用来发现一些小的性能优化:发现了应用程序使用临时文件的情况,这些文件可以避免使用。
它通过使用 kprobes 跟踪文件创建和删除,通过 VFS 调用 vfs_create() 和 vfs_unlink() 实现。由于这些操作的频率相对较低,此工具的开销应该可以忽略不计。
BCC
BCC的命令行用法如下:
```
filelife [options]
```
选项包括:
- `-p PID`:仅测量指定PID的进程
bpftrace
bpftrace版本的代码如下:

较新的内核版本可能不再使用 vfs_create(),因此文件创建也可以通过 security_inode_create() 获取,这是用于 inode 创建的访问控制钩子(LSM)。如果同一个文件同时触发这两个事件,则出生时间戳将被覆盖,但这不应显著影响文件寿命的测量。出生时间戳存储在这些函数的 arg1 参数上,即 struct dentry 指针,作为唯一的标识符。文件名也可以从 struct dentry 获取。
8.3.8 vfsstat
vfsstat(8) 是一个基于 BCC 和 bpftrace 的工具,用于汇总一些常见的 VFS 调用的统计信息:读取和写入(I/O)、创建、打开和 fsync 操作。这提供了对虚拟文件系统操作进行最高级别工作负载特征化的功能。以下是在一个拥有 36 个 CPU 的生产 Hadoop 服务器上使用 BCC 的 vfsstat(8) 的示例:


这些输出显示了一个工作负载,读取操作超过每秒一百万次。一个令人惊讶的细节是每秒文件打开操作的数量:超过五千次。这些操作较慢,需要内核进行路径名查找并创建文件描述符,如果文件元数据未被缓存,则还需创建额外的文件元数据结构。可以使用 opensnoop(8) 进一步调查这种工作负载,找到减少打开操作数量的方法。
vfsstat(8) 使用 kprobes 监控函数:vfs_read()、vfs_write()、vfs_fsync()、vfs_open() 和 vfs_create(),并将它们作为每秒汇总打印在表格中。正如这个实际示例展示的那样,VFS 函数可能非常频繁,以每秒超过一百万事件的速率计算,预计这个工具的开销是可以测量的(例如,在这个速率下可能为 1-3%)。该工具适用于临时调查,而不是全天候监控,在后者的情况下,我们更希望开销低于 0.1%。
这个工具仅适用于调查的初始阶段。VFS 操作涵盖了文件系统和网络,您需要使用其他工具(例如,下面提到的 vfssize(8))来进一步区分它们。
BCC
命令行用法:
vfsstat [interval [count]]
这是基于其他传统工具(如 vmstat(1))进行建模的。
bpftrace
也有一个基于 bpftrace 的版本的 vfsstat(8),打印相同的数据:


这个输出每秒都格式化为一个计数列表。通配符已被用来匹配 vfs_read() 和 vfs_write() 的变体,例如 vfs_readv() 等。如果需要的话,可以增强这个功能,使用位置参数来允许指定自定义的间隔。
8.3.9 vfscount
与由vfsstat(8)计算的这五个VFS函数不同,您可以使用BCC中的vfscount(8)工具统计所有VFS函数的调用次数(总数超过50个),并打印它们的频率计数。例如,可以使用如下BCC命令:


在跟踪过程中,vfs_read()是最频繁的函数,被调用了712,610次,而vfs_fallocate()只被调用了一次。像vfsstat(8)一样,这个工具的开销在VFS调用频率高时会变得显著。
其功能也可以通过BCC中的funccount(8)或者直接使用bpftrace(8)来实现:
```bash
# funccount 'vfs_*'
# bpftrace -e 'kprobe:vfs_* { @[func] = count(); }'
```
像这样计算VFS调用次数只适用于高层次的概览,在深入分析之前使用。这些调用可能涉及通过VFS操作的任何子系统,包括套接字(网络)、/dev 文件和/proc。接下来介绍的fsrwstat(8)工具展示了区分这些类型的一种方法。
8.3.10 vfssize
vfssize(8)是一个bpftrace工具,可以显示按进程名称和VFS文件名或类型细分的VFS读取和写入大小的直方图。以下是来自一个48核生产API服务器的示例输出:


这突显了VFS如何处理网络和FIFO。在跟踪过程中,名为"grpc-default-wo"(已截断)的进程进行了266,897次一字节的读写操作:这表明有优化性能的机会,可以通过增加I/O大小来实现。同样的进程名称还执行了许多TCP读写操作,其大小呈双峰分布。输出中只有一个文件系统文件的示例:"tomcat_access.log",被"tomcat-exec-393"进程进行了31次总的读写操作。
vfssize(8)的来源:


这个工具在调用vfs_read()、vfs_readv()、vfs_write()和vfs_writev()时,从第一个参数中提取struct file,并通过kretprobe获取结果大小。幸运的是,对于网络协议,协议名称存储在文件名中。(这源自于struct proto:有关此内容,请参阅第10章。)对于FIFOs,当前文件名中没有存储任何内容,因此在该工具中硬编码了文本"FIFO"。
vfssize(8)可以通过将"probe"作为关键字、进程ID("pid")以及其他所需的详细信息,来增强其功能,以包括调用类型(读取或写入)。
8.3.11 fsrwstat
`fsrwstat(8)18`展示了如何定制`vfsstat(8)`以包含文件系统类型。以下是示例输出:


这显示了不同的文件系统类型作为第一列,将套接字I/O与ext4文件系统I/O分开。此特定输出显示了一个重负载(超过100,000 IOPS)的ext4读取和写入工作负载。
fsrwstat(8)的来源:

该程序跟踪四个VFS函数,并频次计算文件系统类型和函数名称。由于这些函数的第一个参数是 struct file *,它可以从 arg0 转换,并且可以遍历其成员,直到读取到文件系统类型名称。遍历的路径是 file -> inode -> superblock -> file_system_type -> name。由于它使用了 kprobes,这条路径是一个不稳定的接口,需要随着内核变化进行更新。
fsrwstat(8)可以通过包含其他VFS调用来增强其功能,只要从被检测函数的参数中(如 arg0、arg1 或 arg2 等)存在到文件系统类型的路径即可。
8.3.12 fileslower
fileslower(8)19 是一个基于BCC和bpftrace的工具,用于显示同步文件读取和写入超过给定阈值的情况。以下是在一个36核的生产Hadoop服务器上使用BCC的 fileslower(8) 工具,跟踪读取/写入超过10毫秒(默认阈值)的操作:

这些输出显示一个Java进程遇到的写操作延迟长达34毫秒,并显示了所读取和写入文件的名称。方向显示在"D"列:"R"表示读取,"W"表示写入。"TIME(s)"列显示这些慢速读取和写入并不频繁,每秒只有几次。
同步读取和写入非常重要,因为进程在这些操作上阻塞并直接受到其延迟的影响。本章的介绍讨论了文件系统分析可能比磁盘I/O分析更相关,这是一个例子。在下一章中,将测量磁盘I/O延迟,但在这个层次上,应用程序可能不会直接受到延迟问题的影响。在磁盘I/O中,很容易发现看起来像延迟问题但实际上并不是问题的现象。然而,如果fileslower(8)显示存在延迟问题,那很可能确实存在问题。
同步读取和写入将会阻塞一个进程。这很可能导致应用程序级别的问题,尽管并非确定。应用程序可能正在使用后台I/O线程进行写入刷新和缓存预热,这些操作执行同步I/O但没有应用程序请求阻塞。
该工具已被用来证明生产环境中的延迟来自文件系统,或者在其他情况下证明文件系统并不是瓶颈:显示没有I/O像预期的那样慢。
fileslower(8)的工作原理是跟踪VFS中同步读取和写入的代码路径。当前的实现跟踪所有的VFS读取和写入,然后在同步操作上进行过滤,因此其开销可能比预期的要高。
BCC
命令行用法:
fileslower [选项] [min_ms]
选项包括:
■ -p PID:仅测量该进程
min_ms参数是以毫秒为单位的最小时间。如果提供0,则打印所有同步读取和写入。输出可能每秒达成千上万行,具体取决于它们的速率,除非你有充分理由需要查看所有内容,否则这不太可能是你想要做的事情。如果未提供参数,则默认使用10毫秒。
bpftrace
以下是bpftrace版本的代码:


这段代码使用kprobes来跟踪`new_sync_read()`和`new_sync_write()`内核函数。由于kprobes接口不稳定,不能保证这些功能在不同内核版本中都能正常工作。我已经遇到过一些内核版本,这些函数无法用于跟踪(已内联化)。BCC版本采用了一种解决方法,即通过跟踪更高级别的`__vfs_read()`和`__vfs_write()`内部函数,然后筛选出那些同步操作。
8.3.13 filetop
filetop(8) 是一个类似于 top(1) 的 BCC 工具,用于显示最频繁被读取或写入的文件名。以下是在一个具有 36 个 CPU 的生产 Hadoop 服务器上的示例输出:


默认情况下,显示前二十个文件,按照读取字节列排序,并且屏幕每秒重绘一次。这个特定的输出显示,在一个秒级间隔内,名为 "part-00903-37d00f8d" 的文件(文件名已截断)在读取字节上达到了约 60 兆字节,大约有 15,000 次读取操作。未显示的是平均读取大小,但可以从这些数字计算出平均每次读取约为 4.0 千字节。
这个工具用于工作负载特性分析和文件系统的普通观察。就像使用 top(1) 可以发现意外占用 CPU 的进程一样,filetop 可以帮助您发现意外的 I/O 繁忙文件。
filetop 默认只显示普通文件。使用 -a 选项可以显示所有文件,包括 TCP 套接字。

这个工具的各列包括:
- **TID**: 线程 ID
- **COMM**: 进程/线程名称
- **READS**: 指定时间间隔内的读取次数
- **WRITES**: 指定时间间隔内的写入次数
- **R_Kb**: 指定时间间隔内总的读取千字节数
- **W_Kb**: 指定时间间隔内总的写入千字节数
- **T**: 类型:R == 普通文件(Regular file),S == 套接字(Socket),O == 其他
- **FILE**: 文件名
该工具通过使用 kprobes 跟踪 vfs_read() 和 vfs_write() 内核函数实现。文件类型通过 inode 模式获取,使用 S_ISREG() 和 S_ISSOCK() 宏进行判断。
和之前的类似工具一样,这个工具的开销可能会变得显著,因为 VFS 读写操作可能非常频繁。它还跟踪各种统计信息,包括文件名,这使得它的开销比其他工具略高一些。
命令行用法如下:
```
filetop [options] [interval [count]]
```
可用的选项包括:
- **-C**: 不清屏:滚动输出
- **-r ROWS**: 打印这么多行(默认为 20 行)
- **-p PID**: 只测量指定 PID 的进程
选项 **-C** 对于保留终端的滚动缓冲区很有用,因此可以检查随时间变化的模式。
8.3.14 writesync
writesync(8)22 是一个 bpftrace 工具,用于跟踪 VFS 对普通文件的写入,并显示使用了同步写入标志(O_SYNC 或 O_DSYNC)的文件。例如:

这个输出显示了对文件的多次普通写入,以及一个来自名为 "dd" 的进程对名为 "outfile1" 的文件进行了一百次写入。这个 dd(1) 进程是通过以下人工测试实现的:
```
dd if=/dev/zero of=outfile oflag=sync count=100
```
同步写入需要等待存储 I/O 完成(写透),而不像普通 I/O 那样可以从缓存完成(写回)。这使得同步 I/O 操作较慢,如果同步标志是不必要的,去除它可以极大地提升性能。

8.3.15 filetype
filetype(8)23 是一个 bpftrace 工具,用于跟踪 VFS 的读取和写入操作,同时显示文件类型和进程名称。例如,在一个拥有 36 个 CPU 的系统上进行软件构建过程中:


这个输出显示大多数文件类型为 "regular",即普通文件,这些文件被构建软件(如 make(1)、cc1(1)、gcc(1) 等)读取和写入。输出还包括由 sshd 发送数据包的套接字写入,以及由 bash 从 /dev/pts/1 字符设备读取输入的字符读取。
输出还包括 FIFO24 的读取和写入。以下是一个简短的演示来说明它们的作用:

这个输出显示 FIFO 类型用于 shell 管道。在这里,tar(1) 命令正在读取普通文件,并将它们写入一个 FIFO。gzip(1) 则从这个 FIFO 中读取数据,并将数据写入一个普通文件。这一切都可以在输出中看到。
至于 **filetype(8)** 的源代码:


The **BEGIN**程序在inode文件模式和字符串之间设置了一个哈希表(@type),然后在kprobes的VFS函数中查找。
两个月后编写此工具,我正在开发套接字I/O工具时,注意到我没有编写一个从include/linux/fs.h(如DT_FIFO、DT_CHR等)中暴露文件模式的VFS工具。 我开发了这个工具来完成这个任务(去掉了“DT_”前缀):


当我准备将这个工具添加到这一章节时,我发现我意外地写了filetype(8)的第二个版本,这次使用了不同的头文件进行文件类型查找。我在这里包含了源代码,作为一个教训,说明有时编写这些工具确实有多种方式。
8.3.16 cachestat
cachestat(8)25 是 BCC 工具,用于显示页面缓存命中和未命中的统计信息。可以用于检查页面缓存的命中率和效率,并在系统和应用程序调优时运行,以获取关于缓存性能的反馈。例如,在一个拥有 36 个 CPU 的生产 Hadoop 实例中:

这段输出显示了命中率经常超过90%。调整系统和应用程序以将这个90%接近100%,可能会带来非常大的性能提升(远远大于命中率差异的10%),因为应用程序更频繁地从内存中运行,而不会等待磁盘I/O。
像Cassandra、Elasticsearch和PostgreSQL等大规模云数据库通常会大量使用页面缓存,以确保热数据集始终驻留在内存中。这意味着在配置数据存储时最重要的问题之一是工作集是否适合所配置的内存容量。Netflix团队管理有状态服务时使用cachestat(8)工具来帮助回答这个问题,并决定是否使用哪种数据压缩算法,以及向集群添加更多内存是否确实有助于性能。
几个简单的例子可以更好地解释cachestat(8)的输出。这里是一个空闲系统的例子,创建了一个1 GB的文件。现在使用-T选项显示时间戳列:

The "DIRTIES" 列显示正在写入页面缓存的页面(它们是“dirty”,即脏页面),并且 "CACHED_MB" 列增加了1024兆字节,即新创建文件的大小。
接下来,该文件被刷新到磁盘并从页面缓存中删除(这将清除页面缓存中的所有页面):
```bash
# sync
# echo 3 > /proc/sys/vm/drop_caches
```
现在该文件被读取两次。这次使用了10秒的cachestat(8)间隔来观察:

这个文件在21:09:08至21:09:48之间被读取,这一过程中观察到了高MISS率、低HITRATIO,并且页面缓存大小CACHED_MB增加了1024兆字节。在21:10:08时,文件第二次被读取时,完全命中了页面缓存(100%)。
cachestat(8)通过使用kprobes来仪表化这些内核函数:
- mark_page_accessed():用于测量缓存访问
- mark_buffer_dirty():用于测量缓存写入
- add_to_page_cache_lru():用于测量页面添加
- account_page_dirtied():用于测量页面污染
尽管这个工具提供了关键的页面缓存命中率洞察,但它也通过这些kprobes与内核实现细节紧密相关,需要进行维护以适配不同的内核版本。它最好的用途可能是展示这样一个工具的可能性。
这些页面缓存函数可能非常频繁:它们每秒可能被调用数百万次。对于极端工作负载,这个工具的开销可能超过30%,但对于正常工作负载,开销会少得多。在生产使用之前,应在实验环境中进行测试和量化。
命令行用法:
```
cachestat [options] [interval [count]]
```
有一个-T选项可以在输出中包含时间戳。
还有另一个BCC工具,cachetop(8),使用curses库以top(1)风格的显示打印cachestat(8)的统计信息,按进程分类显示。
8.3.17 writeback
writeback(8)28是一个bpftrace工具,显示页面缓存写回的操作:包括页面扫描时机、将脏页刷新到磁盘的时机、写回事件类型以及持续时间。例如,在一个36核CPU系统上:


这段输出首先显示了每隔五秒钟进行一次周期性的写回操作。这些操作没有写入很多页面(0页、40页、0页)。然后出现了一波后台写回操作,写入了数万页,并且每次写回操作耗时在6到22毫秒之间。这是系统在空闲内存不足时进行的异步页面刷新。如果时间戳与其他监控工具(例如,整个云环境的性能监控)所观察到的应用程序性能问题相关联,这表明应用程序问题可能是由文件系统写回引起的。写回刷新的行为是可调整的(例如,通过sysctl(8)和vm.dirty_writeback_centisecs)。在3:43:04发生了一个同步的写回操作,耗时64毫秒,写入了38,836页。
writeback(8)的源代码如下:


这段代码用来填充 @reason,将写回操作的原因标识符映射为可读的字符串。在写回过程中测量时间,以设备为键,所有细节都打印在 writeback_written 追踪点中。页面计数通过监视 args->nr_pages 参数的减少来确定,这遵循内核在此方面的处理方式(参见 fs/fs-writeback.c 中的 wb_writeback() 函数源码)。
8.3.18 dcstat
dcstat(8) 是一个 BCC 和 bpftrace 工具,用于显示目录条目缓存(dcache)的统计信息。以下是在一个拥有36个CPU的生产Hadoop实例上使用BCC显示的 dcstat(8) 的输出:


这段文字的翻译如下:
这个输出显示了超过99%的命中率,以及每秒超过500,000次的工作负载参考。各列的含义如下:
- **REFS/s**: dcache 的引用数。
- **SLOW/s**: 自 Linux 2.5.11 起,dcache 在查找常见条目(如 "/"、"/usr")时进行了优化,避免了缓存行跳跃 [88]。这一列显示未使用此优化时,dcache 查找采用了“慢”路径的次数。
- **MISS/s**: dcache 查找失败。目录条目可能仍然存在于页缓存中,但专用的dcache未能返回它。
- **HIT%**: 命中次数与引用次数的比率。
此工具通过使用 kprobes 对 `lookup_fast()` 内核函数进行检测,以及对 `d_lookup()` 使用 kretprobes 来实现。根据示例输出显示,这些函数可能频繁调用,因此此工具的开销可能会在工作负载中显著。建议在实验室环境中进行测试和量化。
BCC
BCC的命令行用法如下所示:
```
dcstat [interval [count]]
```
这个命令的模式类似于其他传统工具(例如,vmstat(1))。
bpftrace
关于bpftrace版本的示例输出,可以如下展示:


8.3.19 dcsnoop
dcsnoop(8)是一个BCC和bpftrace工具,用于跟踪目录条目缓存(dcache)的查找,显示每次查找的详细信息。输出可能非常详细,每秒可能会产生数千行输出,具体取决于查找率。以下是使用BCC的dcsnoop(8),使用-a选项以显示所有查找的示例输出:


这个输出显示了snmpd通过查找`/proc/sys/net/ipv6/conf/eth0/forwarding`路径,并展示了如何遍历该路径查找每个组件。"T"列表示类型:R表示引用(hit),M表示未命中(miss)。
这个工具与dcstat(8)相似,也是使用kprobes来实现的。由于它每个事件输出一行信息,因此预计在任何中等工作负载下的开销会很高。它旨在短期内使用,用于调查dcstat(8)中观察到的未命中情况。
**BCC**
BCC版本仅支持一个命令行选项:-a,用于同时显示引用和未命中。默认情况下,只显示未命中。
**bpftrace**
以下是bpftrace版本的代码:


这个程序需要引用nameidata结构体中的"last"成员,但这个成员在内核头文件中并没有定义,因此在程序中声明了足够的信息来找到这个成员。
8.3.20 mountsnoop
`mountsnoop(8)32` 是一个BCC工具,用于显示文件系统被挂载的时间。这个工具可用于故障排除,特别是对于在容器启动时挂载文件系统的容器环境。以下是示例输出:

这个输出显示了 `systemd-logind` 在 `/run/user/116` 上执行了 `mount(2)` 和 `umount(2)` 操作。
这个工具通过跟踪 `mount(2)` 和 `umount(2)` 系统调用来实现,使用 `kprobes` 来监视执行这些操作的函数。由于挂载操作通常是不频繁的,因此预计这个工具的开销可以忽略不计。
8.3.21 xfsslower
xfsslower(8)33 是一个BCC工具,用于跟踪常见的XFS文件系统操作;它会打印那些超过指定阈值的操作的详细信息。被跟踪的操作包括读取、写入、打开文件和fsync。
以下是来自一个有36个CPU的生产实例中,xfsslower(8)从BCC跟踪那些超过10毫秒(默认阈值)的操作的示例输出:

这个输出显示了Java 频繁的读取操作超过了10毫秒。类似于 fileslower(8),这种方法是在接近应用程序的层面进行的,这里看到的延迟很可能是应用程序遭受的延迟。
这个工作原理是通过使用 kprobes 跟踪文件系统的 struct file_operations 中的内核函数,这些函数是文件系统与虚拟文件系统(VFS)的接口。具体来自 Linux 的 fs/xfs/xfs_file.c 文件。


函数 `xfs_file_read_iter()` 用于跟踪读取操作,而 `xfs_file_write_iter()` 用于写入操作,依此类推。这些函数在不同的内核版本中可能会有所更改,因此这个工具需要定期维护。该工具的开销与操作的频率以及超过阈值打印的事件的频率成正比。在繁忙的工作负载下,操作的频率可能很高,即使没有超过阈值的操作导致没有输出打印,工具的开销也可能是显著的。
命令行使用方式:
```
xfsslower [options] [min_ms]
```
选项包括:
- `-p PID`:仅测量指定进程
`min_ms` 参数表示最小的时间阈值,单位为毫秒。如果提供 `0`,则打印所有跟踪的操作。这种输出可能每秒产生数千行,具体取决于其频率,除非你有充分的理由需要查看所有输出,否则通常是不希望的。如果未提供参数,默认为 10 毫秒。
下一个工具展示了一个 `bpftrace` 程序,用于为相同的函数生成延迟直方图,而不是逐事件输出。
8.3.22 xfsdist
xfsdist(8) 是一个由 BCC 和 bpftrace 提供的工具,用于对 XFS 文件系统进行仪表化,展示常见操作(读取、写入、打开和 fsync)的延迟分布直方图。以下是在一个拥有 36 个 CPU 的生产 Hadoop 实例上运行 xfsdist(8) 工具 10 秒钟的情况:


这个输出显示了针对读取、写入和打开操作的单独直方图,其中计数显示工作负载目前以写入为主。读取直方图显示双峰分布,其中许多读取操作在小于七微秒的范围内,另一个峰在16到31微秒之间。这两个峰的速度表明它们可能是从页面缓存中提供的。它们之间的差异可能是由读取数据的大小或者使用了不同代码路径的不同类型读取引起的。最慢的读取操作达到了65到131毫秒的范围:这些可能来自存储设备,并涉及排队。
写入直方图显示大多数写入操作在16到31微秒的范围内,速度也很快,可能使用了写回缓冲。
BCC(BPF Compiler Collection)
命令行用法:
```
xfsdist [选项] [间隔 [次数]]
```
选项包括:
- `-m`: 输出以毫秒为单位(默认为微秒)
- `-p PID`: 仅测量指定进程
间隔和次数参数允许对这些直方图随时间进行研究。
bpftrace
以下是 bpftrace 版本的核心功能代码。该版本不支持选项。

8.3.23 ext4dist
BCC中有一个名为`ext4dist(8)`的工具,它类似于`xfsdist(8)`,但是针对的是ext4文件系统而不是XFS。请参阅`xfsdist(8)`部分以了解输出和使用方法。
有一个区别,这也是使用kprobes的困难示例。以下是Linux 4.8版本中的`ext4_file_operations`结构体定义:

加粗显示的读取函数是`generic_file_read_iter()`,而不是特定于ext4的函数。这是一个问题:如果跟踪这个通用函数,您也会跟踪到来自其他文件系统类型的操作,导致输出混杂不清。
采用的解决方法是跟踪`generic_file_read_iter()`并检查其参数,以确定它是否来自ext4。BPF代码通过检查`struct kiocb *icb`参数来实现这一点。如果文件系统操作不是针对ext4的,跟踪函数会立即返回。
这种方法允许选择性地跟踪ext4特定的文件系统操作,同时过滤掉来自其他文件系统类型的操作,从而提高了跟踪数据的准确性和相关性。

EXT4_FILE_OPERATIONS被实际的ext4_file_operations结构体地址所取代,这个地址是在程序启动时通过读取/proc/kallsyms找到的。这种做法有些取巧,但却有效。然而,这会带来性能上的成本,因为它会跟踪所有generic_file_read_iter()调用,影响使用该函数的其他文件系统。此外,BPF程序还需要额外的测试来处理ext4特定的操作。
随后在Linux 4.10中,使用的函数发生了变化。现在我们可以实际检查内核变更对kprobes的影响,而不是仅仅假设可能性。file_operations结构体也因此发生了变化。

与之前的版本相比,现在有一个名为ext4_file_read_iter()的函数,您可以直接跟踪它,因此您不再需要从通用函数中分离出ext4的调用。
bpftrace
为了庆祝这一变化,我开发了适用于Linux 4.10及更高版本(直到下一次变化)的 ext4dist(8)。示例输出:


直方图以微秒为单位,该输出显示所有延迟均在毫秒以下。
来源:

8.3.24 icstat
`icstat(8)`跟踪inode缓存的引用和未命中,并每秒打印统计信息。例如:

这个输出显示了初始一秒钟的命中情况,接着是几秒钟主要是未命中的情况。工作负载是执行 `find /var -ls`,遍历inode并打印它们的详细信息。
`icstat(8)`的源代码是:


与`dcstat(8)`类似,百分比计算避免了除零错误,通过检查`@refs`是否为零来实现。
8.3.25 bufgrow
`bufgrow(8)`是一个bpftrace工具,用于提供关于缓冲缓存操作的一些洞察。它展示了仅限块页面(用于块I/O缓冲区的缓冲缓存)的页面缓存增长情况,显示了哪些进程以多少K字节增加了缓存。例如:

在跟踪过程中,"dd"进程通过大约100兆字节增加了缓冲缓存。这是一个合成测试,涉及从块设备进行的dd(1)操作,期间缓冲缓存确实增加了100兆字节。


这个工具通过使用kprobes来检测`add_to_page_cache_lru()`函数,并且根据块类型进行过滤。由于块类型需要进行结构体转换和解引用,所以在if语句中进行了测试,而不是在探针过滤器中。这是一个频繁调用的函数,因此运行这个工具可能会给繁忙的工作负载带来明显的开销。
8.3.26 readahead
`readahead(8)`是一个跟踪文件系统自动预读取(而非readahead(2)系统调用)的bpftrace工具,它展示了在跟踪期间预读取页面是否被使用,以及读取页面和使用页面之间的时间。例如:

这段描述说明了`readahead(8)`工具的功能和用途:
- 工具显示在跟踪期间,有128个页面被预读取但未被使用(这个数量并不多)。
- 直方图显示数千个页面被预读取并被使用,大多数在32毫秒内完成。
- 如果使用页面的时间延迟在数秒之内,这可能表明预读取加载过于激进,需要进行调优。
该工具的创建目的是帮助分析Netflix生产实例上的预读取行为,这些实例使用固态硬盘,预读取对于固态硬盘的作用远不及旋转硬盘,并且可能对性能产生负面影响。这个特定的生产问题也在第9章的`biosnoop(8)`部分描述,因为之前使用`biosnoop(8)`进行了这种分析。
至于`readahead(8)`工具的源代码,我目前无法提供。

这个工具通过使用kprobes来对各种内核函数进行仪表化。它在`__do_page_cache_readahead()` 函数执行期间设置了一个线程特定的标志,该标志在页面分配期间被检查,以确定页面是否用于预读。如果是预读页面,就会为页面保存一个基于页面结构地址的时间戳。在页面访问时,如果设置了时间戳,将用于时间直方图。未使用页面的计数是对预读页面分配次数减去实际使用次数的熵计数,跨程序运行期间持续统计。
如果内核实现发生更改,这个工具将需要进行更新以适应。此外,跟踪页面函数并为每个页面存储额外的元数据可能会增加显著的开销,因为这些页面函数的调用非常频繁。在非常繁忙的系统上,这个工具的开销可能会达到30%甚至更高。它适用于短期分析。
在第9章的结尾,展示了一个bpftrace的一行命令,可以统计读取与预读块I/O的比率。
8.3.27 Other Tools
其他值得一提的BPF工具包括:
■ ext4slower(8), ext4dist(8):在BCC中提供的用于分析ext4文件系统性能的工具,相当于xfsslower(8)和xfsdist(8)的ext4版本。
■ btrfsslower(8), btrfsdist(8):在BCC中提供的用于分析Btrfs文件系统性能的工具,相当于xfsslower(8)和xfsdist(8)的Btrfs版本。
■ zfsslower(8), zfsdist(8):在BCC中提供的用于分析ZFS文件系统性能的工具,相当于xfsslower(8)和xfsdist(8)的ZFS版本。
■ nfsslower(8), nfsdist(8):在BCC中提供的用于分析NFS(Network File System)性能的工具,支持NFSv3和NFSv4,相当于xfsslower(8)和xfsdist(8)的NFS版本。
8.4 BPF One-Liners
这些部分展示了BCC和bpftrace的一行命令。在可能的情况下,使用BCC和bpftrace实现相同的一行命令。
8.4.1 BCC
追踪通过open(2)打开的文件,显示进程名称:
```
opensnoop
```
追踪通过creat(2)创建的文件,显示进程名称:
```
trace 't:syscalls:sys_enter_creat "%s", args->pathname'
```
按文件名统计newstat(2)调用次数:
```
argdist -C 't:syscalls:sys_enter_newstat():char*:args->filename'
```
按syscall类型统计read()系统调用次数:
```
funccount 't:syscalls:sys_enter_*read*'
```
按syscall类型统计write()系统调用次数:
```
funccount 't:syscalls:sys_enter_*write*'
```
显示read()系统调用请求大小的分布情况:
```
argdist -H 't:syscalls:sys_enter_read():int:args->count'
```
显示read()系统调用读取字节数及错误的分布情况:
```
argdist -H 't:syscalls:sys_exit_read():int:args->ret'
```
按错误码统计read()系统调用错误次数:
```
argdist -C 't:syscalls:sys_exit_read():int:args->ret:args->ret<0'
```
统计VFS调用次数:
```
funccount 'vfs_*'
```
统计ext4跟踪点次数:
```
funccount 't:ext4:*'
```
统计xfs跟踪点次数:
```
funccount 't:xfs:*'
```
按进程名称和堆栈跟踪统计ext4文件读取次数:
```
stackcount ext4_file_read_iter
```
仅按进程名称和用户级堆栈跟踪统计ext4文件读取次数:
```
stackcount -U ext4_file_read_iter
```
追踪ZFS spa_sync()函数的调用时间:
```
trace -T 'spa_sync "ZFS spa_sync()"'
```
按堆栈和进程名称统计通过read_pages对存储设备的FS读取次数:
```
stackcount -P read_pages
```
按堆栈和进程名称统计ext4对存储设备的读取次数:
```
stackcount -P ext4_readpages
```
8.4.2 bpftrace
跟踪通过 open(2) 打开的文件,并显示进程名称:
```bash
bpftrace -e 't:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
```
跟踪通过 creat(2) 创建的文件,并显示进程名称:
```bash
bpftrace -e 't:syscalls:sys_enter_creat { printf("%s %s\n", comm, str(args->pathname)); }'
```
按文件名统计 newstat(2) 调用次数:
```bash
bpftrace -e 't:syscalls:sys_enter_newstat { @[str(args->filename)] = count(); }'
```
按系统调用类型统计 read 系统调用次数:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_*read* { @[probe] = count(); }'
```
按系统调用类型统计 write 系统调用次数:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_*write* { @[probe] = count(); }'
```
显示 read() 系统调用请求大小的分布:
```bash
bpftrace -e 'tracepoint:syscalls:sys_enter_read { @ = hist(args->count); }'
```
显示 read() 系统调用读取字节数(及错误)的分布:
```bash
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ = hist(args->ret); }'
```
按错误代码统计 read() 系统调用的错误次数:
```bash
bpftrace -e 't:syscalls:sys_exit_read /args->ret < 0/ { @[- args->ret] = count(); }'
```
按 VFS 调用计数:
```bash
bpftrace -e 'kprobe:vfs_* { @[probe] = count(); }'
```
按 ext4 追踪点计数:
```bash
bpftrace -e 'tracepoint:ext4:* { @[probe] = count(); }'
```
按 xfs 追踪点计数:
```bash
bpftrace -e 'tracepoint:xfs:* { @[probe] = count(); }'
```
按进程名称统计 ext4 文件读取次数:
```bash
bpftrace -e 'kprobe:ext4_file_read_iter { @[comm] = count(); }'
```
按进程名称和用户级堆栈统计 ext4 文件读取次数:
```bash
bpftrace -e 'kprobe:ext4_file_read_iter { @[ustack, comm] = count(); }'
```
跟踪 ZFS 的 spa_sync() 函数调用时间:
```bash
bpftrace -e 'kprobe:spa_sync { time("%H:%M:%S ZFS spa_sync()\n"); }'
```
按进程名称和 PID 统计 dcache 引用次数:
```bash
bpftrace -e 'kprobe:lookup_fast { @[comm, pid] = count(); }'
```
按内核堆栈统计到存储设备的 FS 读取次数(通过 read_pages):
```bash
bpftrace -e 'kprobe:read_pages { @[kstack] = count(); }'
```
按内核堆栈统计到存储设备的 ext4 读取次数(通过 read_pages):
```bash
bpftrace -e 'kprobe:ext4_readpages { @[kstack] = count(); }'
```
8.4.3 BPF One-Liners Examples
包括一些示例输出,就像我之前为每个工具所做的那样,对于说明一行命令也是很有用的。以下是一些选定的一行命令及其示例输出。

这个示例使用 `-d 10` 参数运行了 10 秒钟。这种一行命令,以及类似使用 "*write*" 和 "*open*" 的命令,对于确定正在使用哪些系统调用变体是很有用的,以便进行进一步研究。这个输出来自一个拥有36个CPU的生产服务器,几乎总是在使用 read(2),在跟踪的10秒内有将近1000万次调用。

这个输出显示了大量读取操作,其大小介于512字节到8KB之间。同时,它显示有15,609次读取仅返回了一个字节,这可能是性能优化的目标。可以通过以下方式进一步调查这些仅有一个字节读取的堆栈信息:
```bash
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret == 1/ { @[ustack] = count(); }'
```
此外,还有2,899次读取操作返回了零字节,这可能是基于读取目标和没有进一步字节可读的正常情况。另外,还有279个带有负返回值的事件,这些是错误代码,也可以单独进行调查。

XFS拥有非常多的追踪点,因此这个输出示例被截断以节省空间。这些追踪点提供了许多调查XFS内部的方法,有助于深入解决问题。

这个输出中只有两个事件,但它们正是我希望捕获作为示例的两个事件:第一个事件显示了一个页面错误(page fault),并展示了如何调用 `ext4_readpages()` 并从磁盘读取数据(实际上是由于 `execve(2)` 调用加载其二进制程序);第二个事件展示了一个正常的 `read(2)` 操作,通过预读取函数最终到达 `ext4_readpages()`。它们分别展示了地址空间操作读取和文件操作读取的示例。此外,输出还显示了内核堆栈跟踪如何提供有关事件的更多信息。这些堆栈来自Linux 4.18版本,可能在不同的Linux内核版本中有所变化。
8.5 Optional Exercises
如果未指定,可以使用bpftrace或BCC完成以下操作:
1. 重写filelife(8),使用creat(2)和unlink(2)的系统调用跟踪点。
2. 将filelife(8)切换到这些跟踪点的利弊是什么?
3. 开发一个版本的vfsstat(8),打印本地文件系统和TCP的分开行。 (参见vfssize(8)和fsrwstat(8)。) 模拟输出:
Mock output(模拟输出):

4. 开发一个工具,显示逻辑文件系统 I/O(通过VFS或文件系统接口)与物理 I/O(通过块跟踪点)的比率。
5. 开发一个工具来分析文件描述符泄漏:即在跟踪期间分配但未释放的文件描述符。一种可能的解决方案是跟踪内核函数__alloc_fd()和__close_fd()。
6. (高级)开发一个工具,按挂载点显示文件系统 I/O 的统计信息。
7. (高级,未解决)开发一个工具,以分布方式显示页缓存中访问之间的时间间隔。这个工具的挑战是什么?
如果需要更详细的解释或有其他问题,请随时告诉我!
8.6 Summary
这章节总结了用于文件系统分析的BPF工具,涵盖了对系统调用、VFS调用、文件系统调用和文件系统跟踪点的仪器化;写回(write-back)和预读(read-ahead)操作;以及页缓存、dentry缓存、inode缓存和缓冲区缓存的运行情况。我还包括了能够显示文件系统操作延迟直方图的工具,用以识别多模态分布和异常值,帮助解决应用程序性能问题。
9 Disk I/O
磁盘I/O是性能问题的常见来源,因为对于负载高的磁盘,I/O延迟可能会达到几十毫秒甚至更长时间——比CPU和内存操作的纳秒或微秒速度慢了几个数量级。使用BPF工具进行分析可以帮助找到调整或消除这些磁盘I/O的方法,从而实现应用程序性能的显著提升。
术语“磁盘I/O”指的是任何存储I/O类型:旋转磁介质、基于闪存的存储和网络存储。在Linux中,这些都可以作为存储设备公开,并使用相同的工具进行分析。
在应用程序和存储设备之间通常存在一个文件系统。文件系统利用缓存、预读、缓冲和异步I/O来避免在慢速磁盘I/O上阻塞应用程序。因此,建议您从文件系统开始分析,该内容在第8章有详细介绍。
跟踪工具已经成为磁盘I/O分析的重要工具:我在2004年编写了第一个流行的磁盘I/O跟踪工具iosnoop(8),并在2005年编写了iotop(8),现在这些工具已经随不同的操作系统分发。我还开发了BPF版本的工具,称为biosnoop(8)和biotop(8),最终为块设备I/O补上了长期缺失的“b”。本章还涵盖了这些及其他磁盘I/O分析工具。
学习目标:
■ 理解I/O栈及Linux I/O调度器的作用
■ 学习成功分析磁盘I/O性能的策略
■ 识别磁盘I/O延迟的异常值问题
■ 分析多模态磁盘I/O分布
■ 确定哪些代码路径发出了磁盘I/O及其延迟情况
■ 分析I/O调度器的延迟
■ 使用bpftrace一行命令以自定义方式探索磁盘I/O
本章从磁盘I/O分析所需的背景开始,总结了I/O栈。我探讨了BPF可以回答的问题,并提供了一个整体的策略。然后重点介绍工具,首先是传统的磁盘工具,然后是BPF工具,包括一系列BPF一行命令。本章以可选练习结束。
9.1 Background
本节涵盖了磁盘基础知识、BPF的能力以及建议的磁盘分析策略。
9.1.1 Disk Fundamentals
块I/O堆栈
Linux块I/O堆栈的主要组件如图9-1所示。

块I/O这个术语指的是以块为单位访问设备,传统上是512字节的扇区。块设备接口起源于Unix。Linux通过引入调度器来提高I/O性能,引入卷管理器用于管理多个设备的分组,以及设备映射器用于创建虚拟设备,进一步增强了块I/O功能。
内部机制
后续的BPF工具将涉及I/O堆栈中使用的一些内核类型。在此介绍它们:I/O通过类型为struct request(来自include/linux/blkdev.h)的数据结构以及更低级别的struct bio(来自include/linux/blk_types.h)传递到堆栈中。
rwbs
为了跟踪可观察性,内核提供了一种描述每个I/O类型的方式,使用名为rwbs的字符串。这在内核的blk_fill_rwbs()函数中定义,并使用以下字符:
- R:读取(Read)
- W:写入(Write)
- M:元数据(Metadata)
- S:同步(Synchronous)
- A:预读(Read-ahead)
- F:刷新或强制单元访问(Flush or force unit access)
- D:丢弃(Discard)
- E:擦除(Erase)
- N:无(None)
这些字符可以组合使用。例如,“WM”表示元数据的写入操作。
I/O调度器
I/O在块层中被排队和调度,可以通过经典调度器(仅存在于Linux版本5.0之前)或较新的多队列调度器进行。经典调度器包括:
- Noop:无调度(空操作)
- Deadline:强制延迟期限,适用于实时系统
- CFQ:完全公平队列调度器,将I/O时间片分配给进程,类似于CPU调度
经典调度器的问题在于它们使用单个请求队列,由单个锁保护,在高I/O速率下会成为性能瓶颈。多队列驱动程序(blk-mq,在Linux 3.13中添加)通过为每个CPU使用单独的提交队列和为设备使用多个调度队列来解决这个问题。这种方法相比经典调度器提供了更好的性能和更低的I/O延迟,因为请求可以在并行处理中处理,并在与发起I/O的同一CPU上处理。这对支持基于闪存和其他能够处理数百万IOPS的设备类型是必要的。
现有的多队列调度器包括:
- None:无排队
- BFQ:预算公平队列调度器,类似于CFQ,但还分配带宽和I/O时间
- mq-deadline:deadline的blk-mq版本
- Kyber:根据性能调整读取和写入调度队列长度的调度器,以满足目标读取或写入延迟
经典调度器和传统I/O堆栈已在Linux 5.0中移除。所有调度器现在都是多队列调度器。
Disk I/O Performance
Figure 9-2 展示了带有操作系统术语的磁盘I/O性能。
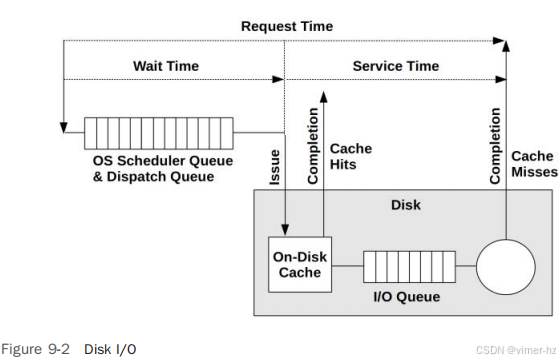
在操作系统中,等待时间是指在块层调度队列和设备调度队列中花费的时间。服务时间是从设备发出到完成的时间。这可能包括在设备上等待队列上花费的时间。请求时间是从将I/O插入到操作系统队列到其完成的整体时间。请求时间最为重要,因为这是应用程序必须等待的时间,如果I/O是同步的话。
这张图表中未包含的一个指标是磁盘利用率。这个指标在容量规划时可能看起来很理想:当磁盘接近100%利用率时,你可能会认为存在性能问题。然而,利用率是由操作系统计算的磁盘正在进行操作的时间,并不考虑可能由多个设备支持的虚拟磁盘或磁盘队列。这可能会使磁盘利用率指标在某些情况下误导,包括当磁盘利用率达到90%时,它可能能够接受比额外的10%工作负载更多。尽管如此,利用率作为一个线索仍然是有用的,并且是一个容易获得的指标。然而,像等待时间这样的饱和度指标更能有效地衡量磁盘性能问题。
9.1.2 BPF Capabilities
传统的性能工具为存储I/O提供了一些洞察,包括IOPS速率、平均延迟和队列长度,以及按进程划分的I/O。这些传统工具将在下一节总结。
BPF跟踪工具可以为磁盘活动提供额外的洞察,回答以下问题:
- 磁盘I/O请求是什么?类型、数量和I/O大小是多少?
- 请求时间和排队时间是多少?
- 是否存在延迟的异常值?
- 延迟分布是否是多模态的?
- 是否存在任何磁盘错误?
- 发送了哪些SCSI命令?
- 是否存在任何超时情况?
为了回答这些问题,需要跟踪整个块I/O堆栈中的I/O。
事件来源
表9-1列出了用于仪表化磁盘I/O的事件来源。

这些工具从块I/O接口到设备驱动程序提供了可见性。
举例来说,以下是发送块I/O到设备的 block:block_rq_issue 事件的参数:

可以通过以下这条一行命令使用该跟踪点来回答诸如“请求的I/O大小是多少?”这类问题:
```bash
bpftrace -e 'tracepoint:block:block_rq_issue { @bytes = hist(args->bytes); }'
```
通过结合不同的跟踪点,可以测量事件之间的时间间隔。
9.1.3 Strategy
如果你是新手对磁盘I/O分析不甚了解,这里有一个建议的总体策略可以供你参考。接下来的部分将更详细地解释这些工具。
1. 对于应用程序性能问题,首先进行文件系统分析,可以参考第8章。
2. 检查基本的磁盘指标:请求时间、IOPS和利用率(例如使用 iostat(1))。查看高利用率(这是一个线索),以及高于正常的请求时间(延迟)和IOPS。
- 如果你不熟悉什么是正常的IOPS速率或延迟,可以在空闲系统上使用微基准工具如 fio(1) 运行一些已知的工作负载,然后运行 iostat(1) 来进行检查。
3. 跟踪块I/O延迟分布,并检查是否存在多模态分布和延迟异常值(例如使用 BCC 的 biolatency(8))。
4. 跟踪单个块I/O,并查找例如读取在写入后排队等模式(可以使用 BCC 的 biosnoop(8))。
5. 使用本章中的其他工具和一行命令。
进一步解释第一步:如果你从磁盘I/O工具开始,可能很快就能识别出高延迟的情况,但接下来的问题是:这对性能有多大影响?I/O可能是异步进行到应用程序的,如果是这样的话,这是有趣的分析点,但出于不同的原因:理解与其他同步I/O的争用,以及设备容量规划。
9.2 Traditional Tools
这部分涵盖了以下内容:
- **iostat(1)**:用于磁盘活动摘要的工具。
- **perf(1)**:用于块I/O跟踪的工具。
- **blktrace(8)**:详细跟踪块I/O的工具。
- **SCSI日志**:用于记录SCSI设备活动的日志。
9.2.1 iostat
iostat(1)总结了每个磁盘的I/O统计信息,提供IOPS、吞吐量、I/O请求时间和利用率等指标。它可以由任何用户执行,并且通常是在命令行中用于调查磁盘I/O问题的第一个命令。这个工具的统计数据默认由内核维护,因此其开销被认为是可以忽略的。
iostat(1)提供了许多选项来自定义输出。一个有用的组合是 `-dxz 1`,用于仅显示磁盘利用率(-d)、扩展列(-x)、跳过没有指标的设备(-z),并以每秒的频率输出(1)。输出非常宽,我将展示左侧部分,然后是右侧部分;这是我帮助调试生产问题时的输出示例:


这些列总结了应用的工作负载,并对工作负载的特征化非常有用。
前两列提供了关于磁盘合并的洞察:这是指发现一个新的I/O正在读取或写入与另一个排队的I/O相邻(前或后)的磁盘位置,因此它们被合并以提高效率。
这些列是:
- rrqm/s:每秒排队和合并的读请求
- wrqm/s:每秒排队和合并的写请求
- r/s:每秒完成的读请求(经过合并后)
- w/s:每秒完成的写请求(经过合并后)
- rkB/s:每秒从磁盘设备读取的千字节
- wkB/s:每秒写入磁盘设备的千字节
第一组输出(显示了xvda和xvdb设备)是自引导以来的总结,可与随后的每秒总结进行比较。这些输出显示,xvdb通常的读吞吐量为每秒5,507千字节,但当前的一秒钟总结显示读取速度超过了每秒90,000千字节。系统承载了比正常更重的读取工作负载。
可以对这些列应用一些数学运算来计算平均读取和写入大小。将rkB/s列除以r/s列可以得出平均读取大小约为124千字节。较新版本的iostat(1)还包括平均大小作为rareq-sz(读取平均请求大小)和wareq-sz列。
右侧的列显示:

这些展示了设备的性能结果。各列如下:
- **avgrq-sz**: 平均请求大小,以扇区计(每扇区512字节)。
- **avgqu-sz**: 平均排队的请求数量,包括等待在驱动请求队列中和活动在设备上的请求。
- **await**: 平均I/O请求时间(也称为响应时间),包括等待在驱动请求队列中的时间和设备的I/O响应时间(毫秒)。
- **r_await**: 仅针对读取的平均等待时间(毫秒)。
- **w_await**: 仅针对写入的平均等待时间(毫秒)。
- **svctm**: 磁盘设备的平均(推断)I/O响应时间(毫秒)。
- **%util**: 设备用于处理I/O请求的时间百分比(利用率)。
对于性能提供的最重要指标是await。如果应用程序和文件系统使用某种技术来减轻写入延迟(例如写通道),那么w_await可能并不那么重要,可以专注于r_await。
对于资源使用和容量规划而言,%util很重要,但请记住它仅是繁忙度的度量(非空闲时间),对于由多个磁盘支持的虚拟设备可能意义不大。这些设备可能更适合通过应用的负载来理解:IOPS(r/s + w/s)和吞吐量(rkB/s + wkB/s)。
此示例输出显示磁盘利用率达到了100%,平均读取I/O时间为33毫秒。对于施加的工作负载和磁盘设备而言,这显示了预期的性能。真正的问题是,所读取的文件变得如此之大,以至于无法再缓存在页面缓存中,并且必须从磁盘中读取。
9.2.2 perf
perf(1)在第6章引入,用于PMC分析和定时堆栈抽样。它的跟踪能力也可以用于磁盘分析,特别是使用块跟踪点。
例如,可以跟踪请求的排队(block_rq_insert),它们被发送到存储设备(block_rq_issue),以及它们的完成(block_rq_complete):


输出包含许多细节,从事件发生时在CPU上的进程开始,这个进程可能或可能不是事件的责任方。其他细节包括时间戳、磁盘的主次编号、编码I/O类型的字符串(如前所述的rwbs),以及有关I/O的其他细节。
过去我曾构建过工具,用于后处理这些事件以计算延迟直方图,并可视化访问模式。然而,对于繁忙的系统,这意味着将所有块事件转储到用户空间进行后处理。BPF可以在内核中更高效地进行这种处理,然后仅发出所需的输出。例如,可以查看后面提到的biosnoop(8)工具作为示例。
9.2.3 blktrace
blktrace(8)是一个专门用于跟踪块I/O事件的实用程序。可以使用其btrace(8)前端跟踪所有事件:

每个I/O事件会打印多行事件。其列包括:
1. 设备的主次编号
2. CPU ID
3. 序列号
4. 动作时间,单位为秒
5. 进程ID
6. 动作标识符(参见blkparse(1)):Q表示排队,G表示获取请求,P表示插入,M表示合并,D表示已发出,C表示完成,等等。
7. RWBS描述(参见本章前面的“rwbs”部分):W表示写入,S表示同步,等等。
8. 地址 + 大小 [设备]
输出可以通过后处理和使用Chris Mason的seekwatcher [91]进行可视化。
与perf(1)每个事件转储类似,blktrace(8)的开销在繁忙的磁盘I/O工作负载下可能成为问题。使用BPF进行内核摘要可以大大减少这种开销。
9.2.4 SCSI Logging
Linux提供了一种内置的SCSI事件记录设施,可以通过sysctl(8)或/proc启用。例如,这两个命令将设置所有事件类型的日志记录级别为最大(警告:根据您的磁盘工作负载,这可能会导致系统日志被淹没):
```bash
# sysctl -w dev.scsi.logging_level=0x1b6db6db
# echo 0x1b6db6db > /proc/sys/dev/scsi/logging_level
```
这个数字的格式是一个位域,用于设置10种不同事件类型的日志记录级别从1到7。它在`drivers/scsi/scsi_logging.h`中定义。sg3-utils包提供了一个`scsi_logging_level(8)`工具用于设置这些日志级别。例如:
```bash
scsi_logging_level -s --all 3
```
示例事件包括:

这可以用来帮助调试错误和超时问题。尽管时间戳已提供(第一列),但如果没有唯一的标识细节,使用它们来计算I/O延迟是困难的。
BPF跟踪可用于生成定制的SCSI级和其他I/O堆栈级日志,其中包括在内核中计算的更多I/O细节,包括延迟。
9.3 BPF Tools
这部分介绍了用于磁盘性能分析和故障排除的BPF工具。它们显示在图表9-3中。

这些工具要么来自于在第4章和第5章介绍的BCC和bpftrace仓库,要么是专门为本书创建的。有些工具同时出现在BCC和bpftrace中。表9-2列出了本节中介绍的工具的来源(BT代表bpftrace)。

对于来自BCC和bpftrace的工具,请查看它们的仓库获取完整和更新的工具选项和功能列表。这里总结了一些最重要的功能。有关文件系统工具,请参见第8章。
9.3.1 biolatency
biolatency(8)2 是一个BCC和bpftrace工具,用于将块I/O设备的延迟显示为直方图。设备延迟指从向设备发出请求到其完成的时间,包括在操作系统中排队的时间。
以下是在生产Hadoop实例上,使用BCC中的 biolatency(8) 工具追踪块I/O 10秒钟的示例:

这个输出显示了一个双峰分布,一个峰值在128到2047微秒之间,另一个峰值大约在4到32毫秒之间。现在我知道设备延迟是双峰的,理解其原因可能会带来调优,将更多的I/O移动到更快的模式。例如,较慢的I/O可能是随机I/O,或者较大尺寸的I/O(这可以通过其他BPF工具确定)。在这个输出中,最慢的I/O达到了262到524毫秒的范围:这听起来像是设备上的深度排队。
biolatency(8) 和后来的 biosnoop(8) 工具已经用于解决许多生产问题。它们对于分析云环境中的多租户驱动器特别有用,这些环境可能会嘈杂并破坏延迟SLOs。在运行在小型云实例上时,Netflix的云数据库团队能够使用 biolatency(8) 和 biosnoop(8) 来隔离具有不可接受的双峰或延迟驱动器的机器,并从分布式缓存层和分布式数据库层中将其清除。在进一步分析后,团队决定根据这些发现改变部署策略,现在部署到较少的节点上,并选择具有足够大的独立驱动器的节点。这个小改变有效地消除了延迟的异常值,而没有增加额外的基础设施成本。
biolatency(8) 工具当前通过使用kprobes跟踪各种块I/O内核函数来工作。它是在BCC中的tracepoint支持可用之前编写的,因此使用了kprobes。在大多数磁盘IOPS低(<1000)的系统上,此工具的开销应该可以忽略不计。
Queued Time
BCC的biolatency(8)工具具有一个-Q选项,可以包括操作系统排队时间:

这个输出并没有太大的不同:这一次在更慢的模式下有更多的I/O操作。iostat(1)确认了队列长度很小(avgqu-sz < 1)。
磁盘
系统可以拥有多种混合存储设备:用于操作系统的磁盘、用于存储池的磁盘以及用于可移动介质的驱动器。biolatency(8)工具的-D选项显示了各个磁盘的直方图,分别展示它们的性能表现,帮助您进行分析。例如:

这个输出显示了两种非常不同的磁盘设备:nvme0n1,一种基于闪存存储的磁盘,其I/O延迟通常在32到127微秒之间;以及sdb,一种外部USB存储设备,其I/O延迟呈双峰分布,单位是毫秒。
标志
BCC biolatency(8)还具有 `-F` 选项,可以以不同方式打印每组I/O标志。例如,使用 `-m` 可以生成毫秒级别的直方图:


这些标志可能会被存储设备以不同方式处理;将它们分开可以让我们单独研究它们。上述输出显示,同步写入在性能上呈双峰分布,其中较慢的模式在512毫秒至1023毫秒的范围内。
这些标志也可以通过块追踪点中的 `rwbs` 字段和单字母编码来查看:请参阅本章前面的“rwbs”部分,以了解该字段的解释。
BCC
命令行用法:
biolatency [选项] [间隔 [次数]]
选项包括:
■ -m:以毫秒打印输出(默认为微秒)
■ -Q:包括操作系统排队时间
■ -D:分别显示每个磁盘
■ -F:分别显示每组 I/O 标志
■ -T:在输出中包含时间戳
使用间隔为一将打印每秒直方图。这些信息可以视为延迟热图,完整的秒作为列,延迟范围作为行,颜色饱和度显示该时间范围内的 I/O 次数 [Gregg 10]。详见第17章中使用 Vector 的示例。
bpftrace
以下是 bpftrace 版本的代码,它总结了其核心功能。此版本不支持选项。


这个工具需要在每次 I/O 开始时存储一个时间戳来记录其持续时间(延迟)。然而,可能会有多个 I/O 同时进行。使用单个全局时间戳变量是行不通的:每个 I/O 必须关联一个时间戳。在许多其他的 BPF 工具中,通过将时间戳存储在带有线程 ID 作为键的哈希表中来解决这个问题。但这种方法在磁盘 I/O 中不适用,因为磁盘 I/O 可能在一个线程上启动并在另一个线程上完成,这样线程 ID 就会改变。在这里使用的解决方案是使用这些函数的 arg0,即 I/O 的 struct request 的地址,并将该内存地址作为哈希键。只要内核在发出和完成之间不改变内存地址,这就适合作为唯一的标识符。
跟踪点
在可能的情况下,BCC 和 bpftrace 版本的 biolatency(8) 应该使用块跟踪点,但是存在一个挑战:当前的跟踪点参数中没有 struct request 指针,因此必须使用其他键来唯一标识 I/O。一种方法是使用设备 ID 和扇区号。程序的核心可以改变为以下内容(biolatency-tp.bt):

这假设同一设备和扇区没有多个并发的I/O操作。这只测量设备时间,不包括操作系统排队的时间。
9.3.2 biosnoop
`biosnoop`是BCC和bpftrace工具的一部分,它会为每个磁盘I/O打印一行摘要信息。以下是在Hadoop生产实例上运行的`biosnoop`示例:

这个输出显示Java进程,PID为5136,正在对不同的磁盘进行读取操作。共有六次读取操作,每次读取的延迟约为15毫秒。如果你仔细观察TIME(s)列,这些I/O操作都在几毫秒内完成,并且都是对同一个磁盘(xvdy)的操作。你可以推断这些操作是一起排队执行的:从14.00毫秒到15.15毫秒的延迟上升,也是排队I/O顺序完成的另一个线索。扇区偏移量也是连续的:45056字节的读取等同于88个512字节扇区。
作为生产使用的一个例子:Netflix团队经常使用`biosnoop(8)`来分离与读取预取相关的问题,这些问题会降低对I/O密集型工作负载性能的影响。Linux试图智能地预先读取数据到操作系统页面缓存中,但这可能会对运行在快速固态驱动器上的数据存储造成严重的性能问题,特别是在默认的预读设置下。在识别到过度的读取预取后,这些团队通过分析按线程组织的I/O大小和延迟直方图,执行有针对性的重构。然后通过使用适当的`madvise`选项、直接I/O或将默认的预读设置更改为较小的值,例如16KB,来改善性能。关于I/O大小的直方图,请参见第8章中的`vfssize(8)`和本章节中的`bitesize(8)`;同时还可以参考第8章中专门用于分析此问题的`readahead(8)`工具。
`biosnoop(8)`的列包括:
- TIME(s): I/O完成时间(秒)
- COMM: 进程名称(如果已缓存)
- PID: 进程ID(如果已缓存)
- DISK: 存储设备名称
- T: 类型,R表示读取,W表示写入
- SECTOR: 磁盘上的地址,以512字节扇区为单位
- BYTES: I/O的大小
- LAT(ms): 从设备发出到设备完成的I/O持续时间(毫秒)
这与`biolatency(8)`的工作方式相同:跟踪内核块I/O函数。未来的版本应该切换到块跟踪点。这个工具的开销略高于`biolatency(8)`,因为它打印每个事件的输出。
OS Queued Time
使用`-Q`选项来调用`biosnoop(8)`可以显示在创建I/O和将其提交给设备之间消耗的时间:这段时间主要用于操作系统的队列中,但也可能包括内存分配和锁获取。例如:

队列时间显示在`QUE(ms)`列中。这个高队列时间的示例是来自使用CFQ I/O调度程序的USB闪存驱动器的读取操作。写入I/O的队列时间甚至更长:

写入操作的队列时间超过两秒钟。请注意,较早的I/O缺少大部分列的详细信息:它们在跟踪开始之前就已经入队,因此`biosnoop(8)`错过了缓存这些详细信息,只显示了设备的延迟时间。
BCC
命令行用法:
biosnoop [选项]
选项包括 -Q 用于显示操作系统队列时间。
bpftrace
以下是bpftrace版本的代码,它跟踪I/O的全部持续时间,包括队列时间:


`blk_account_io_start()` 函数通常在进程上下文中触发,当 I/O 被排队时会发生。随后的事件,比如将 I/O 发送到设备和完成 I/O,可能发生在不同的上下文中,因此您不能依赖于这些后续时间点上的 `pid` 和 `comm` 内建变量的值。解决方案是在 `blk_account_io_start()` 运行时将它们存储在 BPF 映射中,以请求 ID 作为键,这样它们可以在以后被检索出来使用。
与 `biolatency(8)` 类似,可以重新编写此工具以使用块跟踪点(参见第 9.5 节)。
9.3.3 biotop
`biotop(8)`是BCC工具集中用于磁盘的类似于`top(1)`的工具。以下是它在生产Hadoop实例上运行的示例,使用了`-C`选项以在更新之间不清除屏幕:


这表明一个Java进程正在从多个不同的磁盘读取数据。列表顶部是启动写入操作的kworker线程:这是后台写入刷新,此时并不清楚真正脏页的进程(可以使用第8章的文件系统工具来识别)。
这个工具使用与 `biolatency(8)` 相同的事件,并具有类似的性能开销预期。
命令行用法:
```
biotop [选项] [间隔 [次数]]
```
选项包括:
- `-C`:不清除屏幕
- `-r ROWS`:打印的行数
默认情况下输出被截断为20行,可以使用 `-r` 进行调整。
9.3.4 bitesize
`bitesize(8)`是一个BCC和bpftrace工具,用于显示磁盘I/O的大小。以下是在生产Hadoop实例上运行的BCC版本示例:


这个输出显示,无论是kworker线程还是Java进程,它们的大部分I/O操作大小都在32到63 KB之间。检查I/O大小可以带来优化的机会:
- 对于顺序工作负载,应尝试使用尽可能大的I/O大小以达到最佳性能。更大的大小有时会导致稍微更差的性能;根据内存分配器和设备逻辑,可能存在一个最佳点(例如128 KB)。
- 对于随机工作负载,应尽量与应用程序记录大小匹配I/O大小。较大的I/O大小会使页面缓存中出现不必要的数据;较小的I/O大小则会导致比必要更多的I/O开销。
这是通过对 `block:block_rq_issue` 这个跟踪点进行仪表化实现的。
BCC
目前的 `bitesize(8)` 不支持选项。
bpftrace
以下是 bpftrace 版本的代码:


该跟踪点提供了进程名称作为 `args->comm`,并且提供了大小作为 `args->bytes`。此插入跟踪点在请求被插入操作系统队列时触发。之后的完成等跟踪点不再提供 `args->comm`,也不能使用 `comm` 内置变量,因为它们是异步地对进程触发的(例如,在设备完成中断时)。
9.3.5 seeksize
`seeksize(8)6` 是一个 bpftrace 工具,用于显示进程请求磁盘寻道的扇区数。这仅对旋转磁介质(如硬盘)有影响,因为驱动器头必须物理移动到不同的扇区偏移,导致延迟。示例输出:


这段输出显示,名为“dd”的进程通常不请求任何寻道操作:在跟踪过程中,请求了29,908次偏移量为0的操作。这是预期的,因为我运行的是dd(1)的顺序工作负载。我还运行了一个tar(1)文件系统备份,这生成了混合的工作负载:一些是顺序的,一些是随机的。seeksizem(8)的来源是:


这段工作原理是查看每个设备 I/O 的请求扇区偏移量,并将其与记录的先前位置进行比较。如果脚本改为使用 `block_rq_completion` 跟踪点,它将显示磁盘遇到的实际寻道次数。但现在它使用 `block_rq_issue` 跟踪点来回答一个不同的问题:应用程序请求的工作负载有多随机?这种随机性可能在 I/O 被 Linux I/O 调度程序和磁盘调度程序处理后发生变化。我最初编写这个脚本是为了证明哪些应用程序造成了随机工作负载,因此我选择测量请求的工作负载。接下来的工具 `biopattern(8)` 则是测量 I/O 完成时的随机性。
9.3.6 biopattern


这个例子从一个文件系统备份工作负载开始,这会导致主要是随机的 I/O。在 6:00,我切换到了顺序磁盘读取,这个过程是99%或100%顺序的,并且提供了更高的吞吐量(KBYTES)。`biopattern(8)` 的来源是:


这段工作原理是通过对块 I/O 完成进行仪器化,并记录每个设备上使用的最后一个扇区(磁盘地址),以便与随后的 I/O 进行比较,以查看它是否从前一个地址继续(顺序)或没有继续(随机)。这个工具可以改为仪器化 `tracepoint:block:block_rq_insert`,这将显示应用的工作负载的随机性(类似于 `seeksize(8)`)。
9.3.7 biostacks


我遇到过一些情况下,磁盘 I/O 显得神秘莫测,没有任何应用程序造成这种情况。原因实际上是后台文件系统任务。(在一个例子中,是 ZFS 的后台检查程序,它会定期验证校验和。)`biostacks(8)` 可以通过显示内核栈跟踪来识别磁盘 I/O 的真实原因。
上述输出包含两个有趣的栈。第一个是由页面错误触发的,导致了交换进程:这就是交换。第二个是一个 `newfstatat()` 系统调用,变成了预读取操作。`biostacks(8)` 的来源是:

这段工作原理是:在 I/O 启动时保存内核栈和时间戳,并在 I/O 完成时检索保存的栈和时间戳。这些信息保存在一个以 `struct request` 指针为键的映射中,该指针是被跟踪内核函数的 arg0。内核栈跟踪使用 `kstack` 内置功能记录。你可以将其更改为 `ustack` 以记录用户级栈跟踪,或者两者都添加。
随着 Linux 5.0 版本改为仅支持多队列,`blk_start_request()` 函数从内核中被移除。在该版本及之后的内核中,这个工具会打印警告信息:
```
警告:无法附加探针 kprobe:blk_start_request,跳过。
```
这个警告可以忽略,或者可以从工具中删除该 kprobe。这个工具也可以重写为使用 tracepoints。请参阅第 9.3.1 节的“Tracepoints”小节。
9.3.8 bioerr

这个输出比我预期的要有趣得多。(我并不期望出现任何错误,但还是运行了一下以防万一。)每两秒钟,就会有一个零字节的请求发送到设备 0,0,这看起来是无效的,并且返回了 -5 错误(EIO)。
之前的工具 `biostacks(8)` 是为了调查这种问题而创建的。在这种情况下,我不需要查看延迟,只想看到设备 0,0 的 I/O 堆栈。我可以调整 `biostacks(8)` 来实现这一点,尽管也可以用 `bpftrace` 一行命令来完成(在这种情况下,我会检查堆栈跟踪在这个 tracepoint 被触发时是否仍然有意义;如果它不再有意义,我将需要切换回 `blk_account_io_start()` 的 kprobe 以真正捕捉到这个 I/O 的初始化)。


这表明设备 0 的 I/O 是由 `scsi_test_unit_ready()` 创建的。进一步挖掘其父函数显示,它正在检查 USB 可移动介质。作为实验,我在插入 USB 闪存驱动器时跟踪了 `scsi_test_unit_ready()`,这改变了它的返回值。这是我的笔记本电脑检测 USB 驱动器的过程。
`bioerr(8)` 的源代码如下:

虽然 `bioerr(8)` 是一个很方便的工具,但请注意,`perf(1)` 也可以通过错误过滤来实现类似的功能。输出包括由 `/sys` 格式文件定义的格式字符串。例如:

BPF 工具可以自定义以包含更多信息,超越 `perf(1)` 的标准功能。例如,返回的错误(在这种情况下是 -5 对应于 EIO)已经从块错误代码映射过来。查看原始块错误代码可能很有趣,这可以通过处理它的函数进行追踪,例如:

`bioerr(8)` 可以改进为打印这些 BLK_STS 代码名称,而不是错误编号。这些代码实际上是从 SCSI 结果代码映射过来的,可以通过 SCSI 事件进行追踪。我将在第 9.3.11 和 9.3.12 节中演示 SCSI 追踪。
9.3.9 mdflush
`mdflush(8)13` 是一个 BCC 和 `bpftrace` 工具,用于追踪来自 md 的刷新事件,md 是用于在某些系统上实现软件 RAID 的多设备驱动程序。例如,在使用 md 的生产服务器上运行 BCC 版本:

md 刷新事件通常不频繁发生,但会导致磁盘写入的突发,影响系统性能。准确了解它们发生的时间对于与监控仪表板的关联很有用,以查看它们是否与延迟峰值或其他问题对齐。该输出显示一个名为 filebeat 的进程每五秒进行一次 md 刷新(我刚刚发现的)。filebeat 是一个将日志文件发送到 Logstash 或直接到 Elasticsearch 的服务。这是通过使用 kprobe 追踪 `md_flush_request()` 函数来实现的。由于事件频率较低,开销应当可以忽略。
BCC
BCC 的 `mdflush(8)` 目前不支持任何选项。
bpftrace
下面是 bpftrace 版本的代码:


9.3.10 iosched
`iosched(8)14` 追踪请求在 I/O 调度器中排队的时间,并按调度器名称对其进行分组。例如:

这显示了 CFQ 调度器正在使用,排队时间通常在 8 到 64 毫秒之间。`iosched(8)` 的源代码是:

这通过在请求通过升降机函数 `__elv_add_request()` 添加到 I/O 调度器时记录时间戳,然后在 I/O 被发出时计算排队时间来实现。这使得追踪 I/O 仅关注那些通过 I/O 调度器的请求,并且专注于追踪排队时间。调度器(升降机)名称从 `struct request` 中获取。
随着 Linux 5.0 版本转向仅支持多队列,`blk_start_request()` 函数已从内核中移除。在该版本及后续版本的内核中,该工具会打印关于跳过 `blk_start_request()` kprobe 的警告,该警告可以忽略,或者可以将该 kprobe 从程序中移除。
9.3.11 scsilatency

这提供了每种 SCSI 命令类型的延迟直方图,显示操作码和命令名称(如果可用)。`scsilatency(8)` 的源代码是:


有许多可能的 SCSI 命令;该工具仅将其中一部分翻译为操作码名称。由于输出中会打印操作码号码,如果翻译缺失,可以通过参考 `scsi/scsi_proto.h` 来确定,并且该工具可以增强以包含这些翻译。
存在 SCSI tracepoints,其中一个在下一个工具中使用,但这些 tracepoints 缺乏唯一标识符,这个标识符作为 BPF map 键来存储时间戳是必需的。
由于 Linux 5.0 版本转向仅支持多队列,`scsi_done()` 函数已被移除,因此可以删除 `kprobe:scsi_done`。在该版本及后续版本的内核中,该工具会打印关于跳过 `scsi_done()` kprobe 的警告,该警告可以忽略,或者可以将该 kprobe 从程序中移除。
9.3.12 scsiresult

在这些结果中,显示了 2202 个结果,代码分别为 `DID_OK` 和 `SAM_STAT_GOOD`,还有一个结果为 `DID_BAD_TARGET` 和 `SAM_STAT_GOOD`。这些代码在内核源代码中定义,例如,可以从 `include/scsi/scsi.h` 文件中找到定义。


该工具通过跟踪 `scsi:scsi_dispatch_cmd_done` tracepoint,提取主机和状态字节,并将其映射到内核名称。内核在 `include/trace/events/scsi.h` 中有类似的查找表用于 tracepoint 格式字符串。结果还包含驱动程序字节和消息字节,但该工具未显示。其格式为:
`driver_byte << 24 | host_byte << 16 | msg_byte << 8 | status_byte`
该工具可以增强以将这些字节和其他细节作为附加键添加到映射中。其他细节可以在该 tracepoint 中轻松获得。

9.3.13 nvmelatency
`nvmelatency(8)` 跟踪 NVMe 存储驱动程序,并按磁盘和 NVMe 命令操作码显示命令延迟。这对于将设备延迟与在块 I/O 层测量的更高层延迟进行隔离非常有用。例如:


该输出显示仅有一个磁盘在使用,`nvme0n1`,以及三种 NVMe 命令类型的延迟分布。NVMe 的 tracepoints 最近才被添加到 Linux,但我在一个没有这些 tracepoints 的系统上编写了这个工具,以展示使用 kprobes 和存储驱动程序可以实现的功能。我开始通过频率计数来查看在不同 I/O 工作负载期间哪些 NVMe 函数被使用。


浏览这些函数的源代码显示,延迟可以从 `nvme_setup_cmd()` 到 `nvme_complete_rq()` 的时间来追踪。即使在缺少 tracepoints 的系统上,tracepoints 的存在也能帮助工具开发。通过检查 NVMe tracepoints 的工作原理 [187],我能够更快地开发这个工具,因为 tracepoint 源代码展示了如何正确解释 NVMe 操作码。`nvmelatency(8)` 的源代码是:


如果一个请求是在没有磁盘的情况下创建的,那它就是一个管理命令。可以通过解码和计时这些管理命令(参见 `include/linux/nvme.h` 中的 `nvme_admin_opcode`)来增强该脚本。为了保持工具的简洁,我只是计算了管理命令的数量,以便在输出中标注出它们的存在。
9.4 BPF One-Liners
这些部分展示了 BCC 和 bpftrace 的一行命令。在可能的情况下,使用 BCC 和 bpftrace 实现了相同的一行命令。
9.4.1 BCC
这些命令用于跟踪和分析块 I/O 和 SCSI 操作:
- **统计块 I/O tracepoints**:
`funccount t:block:*`
- **将块 I/O 大小总结为直方图**:
`argdist -H 't:block:block_rq_issue():u32:args->bytes'`
- **统计块 I/O 请求的用户栈跟踪**:
`stackcount -U t:block:block_rq_issue`
- **统计块 I/O 类型标志**:
`argdist -C 't:block:block_rq_issue():char*:args->rwbs'`
- **跟踪块 I/O 错误,包含设备和 I/O 类型**:
`trace 't:block:block_rq_complete (args->error) "dev %d type %s error %d", args->dev, args->rwbs, args->error'`
- **统计 SCSI 操作码**:
`argdist -C 't:scsi:scsi_dispatch_cmd_start():u32:args->opcode'`
- **统计 SCSI 结果代码**:
`argdist -C 't:scsi:scsi_dispatch_cmd_done():u32:args->result'`
- **统计 NVMe 驱动函数**:
`funccount 'nvme*'`
9.4.2 bpftrace
这些 `bpftrace` 命令用于跟踪和分析块 I/O 和 SCSI 操作:
- **统计块 I/O tracepoints**:
`bpftrace -e 'tracepoint:block:* { @[probe] = count(); }'`
- **将块 I/O 大小总结为直方图**:
`bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'`
- **统计块 I/O 请求的用户栈跟踪**:
`bpftrace -e 't:block:block_rq_issue { @[ustack] = count(); }'`
- **统计块 I/O 类型标志**:
`bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = count(); }'`
- **按 I/O 类型显示总字节数**:
`bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = sum(args->bytes); }'`
- **跟踪块 I/O 错误,包含设备和 I/O 类型**:
`bpftrace -e 't:block:block_rq_complete /args->error/ { printf("dev %d type %s error %d\n", args->dev, args->rwbs, args->error); }'`
- **将块 I/O 插入时间总结为直方图**:
`bpftrace -e 'k:blk_start_plug { @ts[arg0] = nsecs; } k:blk_flush_plug_list /@ts[arg0]/ { @plug_ns = hist(nsecs - @ts[arg0]); delete(@ts[arg0]); }'`
- **统计 SCSI 操作码**:
`bpftrace -e 't:scsi:scsi_dispatch_cmd_start { @opcode[args->opcode] = count(); }'`
- **统计 SCSI 结果代码(所有四个字节)**:
`bpftrace -e 't:scsi:scsi_dispatch_cmd_done { @result[args->result] = count(); }'`
- **显示 `blk_mq` 请求的 CPU 分布**:
`bpftrace -e 'k:blk_mq_start_request { @swqueues = lhist(cpu, 0, 100, 1); }'`
- **统计 SCSI 驱动函数**:
`bpftrace -e 'kprobe:scsi* { @[func] = count(); }'`
- **统计 NVMe 驱动函数**:
`bpftrace -e 'kprobe:nvme* { @[func] = count(); }'`
9.4.3 BPF One-Liners Examples

这段频率统计了编码 I/O 类型的 `rwbs` 字段。在跟踪过程中,发现了 3635 次读取("R")和 2128 次预读取 I/O("RA")。本章开头的 “rwbs” 部分描述了这个 `rwbs` 字段。
这个单行命令可以回答关于工作负载特征的问题,例如:
- 读取与预读取块 I/O 的比例是多少?
- 写入与同步写入块 I/O 的比例是多少?
通过将 `count()` 替换为 `sum(args->bytes)`,这个单行命令将按 I/O 类型汇总字节数。
9.5 Optional Exercises
如果未指定,这些可以使用 bpftrace 或 BCC 完成:
1. 修改 `biolatency(8)` 以打印线性直方图,范围从 0 到 100 毫秒,步长为 1 毫秒。
2. 修改 `biolatency(8)` 以每秒打印一次线性直方图摘要。
3. 开发一个工具显示按 CPU 划分的磁盘 I/O 完成情况,以检查这些中断的平衡情况,可以以线性直方图形式显示。
4. 开发一个类似于 `biosnoop(8)` 的工具,以 CSV 格式打印每个事件的块 I/O,仅包含以下字段:`completion_time`、`direction`、`latency_ms`。`direction` 是读取或写入。
5. 保存两分钟的 (4) 输出,并使用绘图软件将其可视化为散点图,读取用红色表示,写入用蓝色表示。
6. 保存两分钟的 (2) 输出,并使用绘图软件将其显示为延迟热图。(你也可以开发一些绘图软件:例如,使用 `awk(1)` 将计数列转换为 HTML 表格的行,背景颜色根据值进行缩放。)
7. 重写 `biosnoop(8)` 以使用块追踪点。
8. 修改 `seeksize(8)` 显示存储设备遇到的实际寻道距离:基于完成情况进行测量。
9. 编写一个工具来显示磁盘 I/O 超时。一种解决方案是使用块追踪点和 `BLK_STS_TIMEOUT`(参见 `bioerr(8)`)。
10. (高级,未解决)开发一个工具,显示块 I/O 合并长度的直方图。
9.6 Summary
本章展示了 BPF 如何在存储 I/O 堆栈的所有层级进行追踪。工具追踪了块 I/O 层、I/O 调度器、SCSI 和 nvme 作为示例驱动程序。