Re:从零开始的地址映射基本分页存储管理方式(考研向)
地址映射与基本存储管理方式
- 前言
- 主存与cache的地址映射
- Cache是什么?它有什么作用?
- 映射冲突(标志位的由来)
- 小结
- 直接相联映射
- 初步
- 进阶
- 例题
- 组相联映射
- 初步
- 进阶
- 例题
- 全相联映射(easy money)
- 地址映射总结
- 存储管理方式(不连续)
- 基本分页存储管理方式
- 基本思想
- 重要概念
- 页(逻辑地址)——>页框(物理地址)重要*
- 建立映射(页表)
- 基本地址变换结构(重点)
- 页表寄存器
- 地址变换
- 初步
- 进阶(引入快表TLB)
- 思考(计组相关)
- 二级页表
- 引入
- 结构
- 实现
- 结语
前言
前情预告,此篇学习耗时将近两个月 花了我整整两天时间整理而来 预计超1W字!!!
都是博主在学习计组和操作系统的经验和心得 建议先点赞收藏以免后续丢失
下面我们开始:
在学习计算机组成原理这门课程的时候地址映射就是一个重难点 而过了一个月当我学到操作系统的时候 这个基本分页(段)存储管理方式又是一个重难点,而这两个知识点却出奇的类似 我相信对于很多跟我一样基础一般的同学一开始都会觉得晦涩难懂
所以我把他们放同一篇文章里供大家对比着消化吸收 而且由于操作系统与计算机组成原理这两门课本身就是密不可分的 所以在很多很多知识点上都是有紧密联系的 我找了个图放着 大家自然就懂了

后续我也会把一些我认为一开始在计组那里比较难以理解的知识结合操作系统串联起来写成文章供大家参考 敬请期待 不妨点个关注 QAQ~
主存与cache的地址映射
Cache是什么?它有什么作用?
在我们学习cache的时候,我们首先知道他是一个高速缓冲处理器,这是不是就联想到一个金字塔的图片 在这个图片中cache位于这个金字塔的第二层 第一层当然毫无疑问是我们的CPU,之后下层就是所谓的主存 磁盘 磁带 光盘…

而cache 一个非常显著的作用就是存储主存当中频繁使用的数据块副本,而我们又在之前学习了***程序的局部性原理***——时间局部性和空间局部性
理解如下图:

这样的话我们就知道cache的存在 会极大的提高计算机处理问题的效率,而事实上我们在弄清楚什么是地址映射之前我们需要知道 CPU的访存流程:

对于上图的解读:首先我们CPU会首先访问cache,如果cache里正好有那么我们就直接把找到的主存地址交给CPU就好,如果cache中没有我们想要的数据副本,那么我们就会去访问主存(慢),在主存中找到我们想要的地址之后,我们在把主存地址交给CPU的同时会生成一个副本放在cache里面 因为由于程序包含大量的循环,依据程序的局部性原理,计算机会有很大的概率会再次访问这条地址,所以下次就减少了访存操作
好在弄懂整个CPU的访存流程之后,我们不难发现,刚刚其实有一个很重要的细节我们没有交代清楚,就是CPU到底是怎么拿到我们的主存地址的呢?
这就引出了所谓的 “地址映射”,地址映射将主存地址定位到cache中从而帮助我们的CPU能够顺利地找到主存地址

我们可以把这三种地址映射方式看成是一份指南,这份指南帮助我们的CPU找到cache当中的主存地址
对于每一种映射方式具体的主存地址的构成并不需要考虑太多

在具体介绍三种地址映射方式我们首先需要知道一个很重要的事情就是主存与cache之间是以数据块为单位进行数据交换的,也就是说我们主存地址与cache的块内地址是相同的,也就是说:映射之后数据块内部的信息是不会变化的
那现在我们是不是就解决了一半问题,为什么这么说,因为我们一开始的目的就是将主存地址定位到cache上,换句话来说就是找到他们两个之间的映射关系 现在我们发现块内地址是一致的
我的理解就是:这个过程就像A(主存)给B(cache)送快递(地址)一样,我们只关心或者说只是改变了这个快递的位置,而对于快递内部的逻辑顺序是不会发生变化的(如果还是理解不了看后文解释)
那现在问题就转化为了知道主存地址的块号,怎么找到对应cache的行号 如果这个解决了 那么是不是对于每一个主存的数据块都知道自己应该映射到对应cache的位置 而我们后面的三种映射关系就是解决这个问题的
这就不难联想到我们OS分页存储管理方式当中的页内偏移量与块内偏移量,这也正是使得他俩相同的重要原因
PS:如果你还是不理解前文当中为什么说他们是相同的? 打个形象的比方来说:

映射冲突(标志位的由来)
还有一个小问题需要解决就是 我们知道cache的存储容量往往是比主存小很多的,所以很有可能发生多个主存地址映射到同一个cache行上,所以就会发生所谓的映射冲突
为了解决这个问题 我们在cache的每一行前面加上一个标志位T,用来说明这一行是主存当中哪一块的副本,当然了 在不同映射方式之下这个标志位所代表的含义就会有一些不一样
小结

直接相联映射
初步
这个映射方式非常好理解,首先我们对于这个主存进行分区,分区的依据就是cache的大小(cache的行数),有了前面的铺垫结合直接相联映射的特点,我们不难发现,区内第几块就映射到cache第几行,在之前我们给出了主存地址以及cache地址的构成 而且解决了块内地址的问题 (完全一致)
现在我们是不是只需要搞懂在不同映射方式下主存块号与cache行号的关系,
对于直接相联映射,我们可以将左边的块号分为区号(位于分区之后的第几区)和区内块号(区内第几行)
依据就是直接映射关系,针对下图就是主存块号的后两位(2^2=4)

结合之前我们说的映射规则:区内第几块就是cache第几行
所以就自然而然的将主存地址初步重新划分为了三个部分
即:区号 cache行号 块内地址
进阶
在之前我们还提到了映射冲突的问题,而在直接相联映射的模式下,主存当中每个区的第i块都会映射到同一个cache的第i行,所以我们需要设置一个标记tag来防止映射冲突 而由于主存当中的每一个区只有唯一的一个数据块可以映射到cache的第i行
所以为了区分到底是哪个区的主存块,这个tag就正正好就是我们的区号 例如下图当中tag就是由两位二进制数构成,分别是00,01,10,11,分别表示四个区,所以此时主存地址就进一步被划分成了 tag(主存区号——>cache的标志位tag)+cache行号(区内块号——>cache行号)+块内地址(一样)
这就是一次完整的映射关系!!!

例题

组相联映射
初步
这个是先将cache进行分组 若为X(未知数)路组相联就分成X组,例如下图中cache就被分为了四组,这样我们也将主存以四个为一组进行分区,这样我们不难发现主存区内第几块就映射到cache第几组,但是组内是任意行
这是与直接相联映射的最大区别,
类似的,我们将主存块号分成区号和区内块号,此时,依据我们前面所发现的映射规则,我们就能够完成从
区内块号——>cache组号的映射

进阶
类似的 对于这种映射方式当然更需要在cache的每一行设置一个tag标志位,因为是组内任意行,一旦分组比较大的时候不确定性就提升了,也就是说有很多主存的数据块能够映射到同一个cache行上,还是依据我们前面所说的映射关系
我们不妨将区号设置为tag 这样就自然而然的完成了区号——>标记tag的映射
这样就完成了完整的一次地址映射,由于是组相联模式(对cache进行分组),所以成为组相联映射
怎么样 是不是很清晰呢

例题

全相联映射(easy money)
全相联映射是最简单的一种映射 这人没什么底线,为什么怎么说呢 主存当中的每一个数据块都能拷贝到cache的任意行中,这时候我们需要将整个块号作为我们的标记位tag,这样才能区分到底是哪一个主存块映射到了我们的cache行中

地址映射总结

存储管理方式(不连续)
为啥要学习分页存储

基本分页存储管理方式
基本思想
在学习分页存储(不连续)之前我们学习了三种连续存储管理方式 在学习这些的时候我们接触到了一种思想——分块思想 就是将内存进行分块 而我个人认为分页存储就是基于这个思想而来的

这里的分页说白了就是将我们的进程也进行分块 分多大呢,
就是跟我们的内存块的大小一致

- 这样的话可以想象一下 如果我们此时内存当中只有两个5KB的空闲区也就是没有连续的10KB的空间,而此时如果采用连续的存储管理方式,显然我们这时这个程序就必须等待内存的释放再去尝试
- 而如果系统支持分页存储管理方式,我就可以将这个10KB对半劈开,分别放到这个两个5KB的空闲区内 wow是不是很神奇呢!
重要概念

页(逻辑地址)——>页框(物理地址)重要*

- 生动形象地解释页内偏移量和块内偏移量
想象一下,你正在管理一座巨大的图书馆(这代表计算机的内存系统)。这座图书馆里有无数的书籍(数据),但为了高效找到每本书,你需要一套聪明的组织方法。页内偏移量和块内偏移量就像是帮助你精确定位到某本书的具体位置的“小工具”。
- 页内偏移量(Page Offset)
-
是什么? 在图书馆的比喻中,假设图书馆被划分成许多固定的“书架单元”(这相当于内存中的“页”,每个页大小固定,比如 4KB)。当你查找一本书时,你需要先知道它在哪个书架单元(页号),然后再精确找到它在这个书架单元中的位置(页内偏移量)。
-
生动比喻:
把每个书架单元想象成一个标准大小的格子。每个格子能放 100 本书。现在,你想找一本叫《哈利·波特》的书: -
首先,管理员告诉你它在“第 5 号书架单元”(页号)。
然后,你在这个书架单元里数一数,发现它排在第 30 本的位置——这个“30”就是页内偏移量。它告诉你从书架单元的开头数起,第 30 本书就是你要找的。 -
为什么重要?
页内偏移量确保了你能在页内精确定位到数据。计算上,一个地址可以拆成两部分:
虚拟地址(逻辑地址) = 页号 × 页大小 + 页内偏移量 \text{虚拟地址(逻辑地址)} = \text{页号} \times \text{页大小} + \text{页内偏移量} 虚拟地址(逻辑地址)=页号×页大小+页内偏移量
例如,如果页大小是 4096 字节(4KB),偏移量范围就是 0 到 4095。就像在书架单元中,位置编号从 0 到 99(对应 100 本书)。 -
关键点:页内偏移量是“页内”的细节位置,不会改变页的整体大小。
- 块内偏移量(Block Offset)
-
是什么? 现在,图书馆里有些热门书籍被缓存到一个“快速取书区”(这相当于计算机的缓存或磁盘块)。这个快速取书区也分成固定大小的“块”(比如缓存行大小 64 字节)。块内偏移量就是用来指定数据在块内的具体位置。
-
生动比喻:
想象快速取书区是一个个小推车(块),每个推车能放 10 本书。你想借《指环王》,管理员说它在“第 3 号推车” -
你跑到第 3 号推车前,发现推车上的书从左到右排列。
《指环王》就放在推车的第 4 个位置——这个“4”就是块内偏移量。它告诉你从推车开头数起,第 4 本书就是目标。 -
为什么重要?
块内偏移量让系统能快速访问缓存或磁盘中的数据。地址计算类似:
物理地址 = 块号 × 块大小 + 块内偏移量 \text{物理地址} = \text{块号} \times \text{块大小} + \text{块内偏移量} 物理地址=块号×块大小+块内偏移量
例如,块大小是 64 字节,偏移量范围就是 0 到 63。就像在推车上,位置编号从 0 到 9。 -
关键点:块内偏移量是“块内”的精确定位
-
为什么用这个比喻? 图书馆的书架单元代表页(大而稳定),推车代表块(小而快速)。偏移量就是你的“位置指南针”,确保你每次都能秒速找到书!
-
希望通过这个比喻,能让大家轻松理解:
页内偏移量和块内偏移量都是内存管理的“定位神器”,让计算机像智能图书馆一样高效运作。
而为什么他俩往往是相同的?
就是因为页框大小和页面大小是相等的 我们在进行映射的时候是不会改变内部顺序的 这就是原因(在前文的地址映射有具体解释)
建立映射(页表)
这里特别说一下为什么页号是可以隐含存储的?
其实我们就完完全全可以把这个所谓的页表横过来放置 这不就是一个数组/vector(可变长)吗 由于页表也是连续存储的所以 类似的 页号不就可以看做我们数组的下标吗 我们只需要知道页表的首地址 就能随机地存取页表中的所有元素了 这就是原因所在!
Meanwhile,这也为我们后面的二级页表奠定了基础 这里先不用了解
好了 回过头看 页表其实就是帮助我们建立了一个映射:
进程的页面——>pos 实际存放在内存的位置

基本地址变换结构(重点)
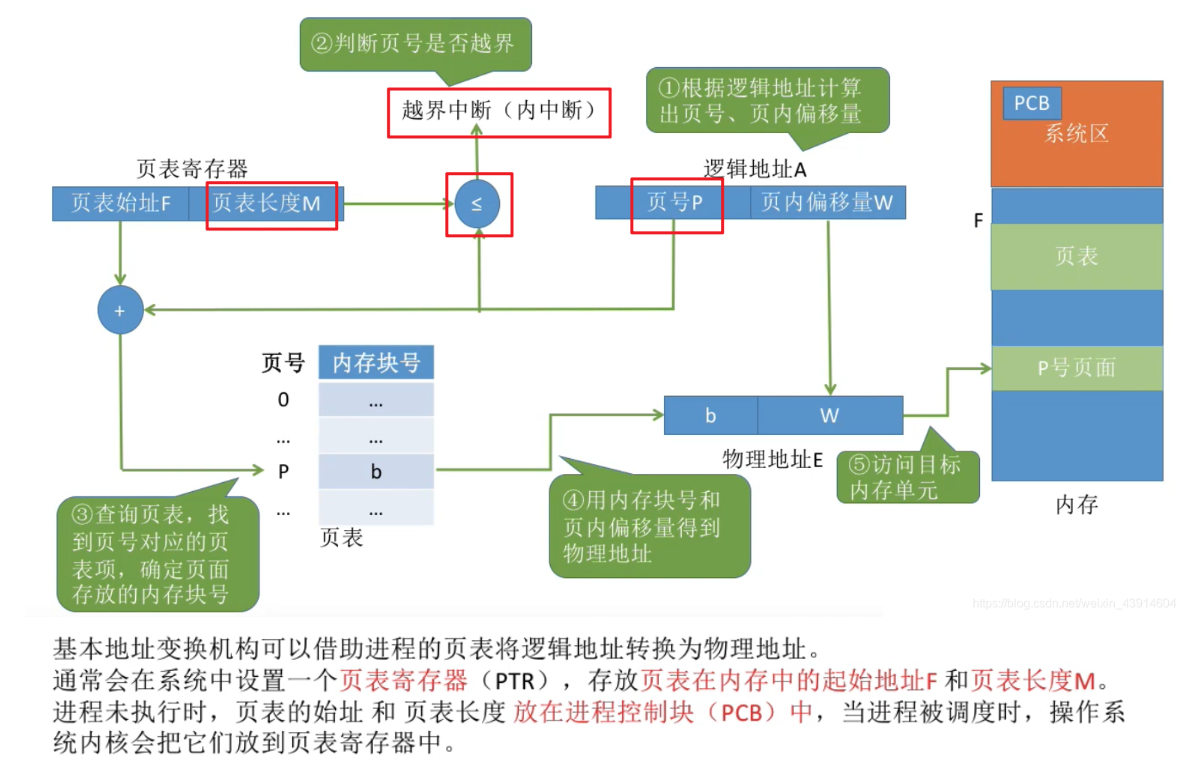
页表寄存器
再具体介绍地址的变换过程之前 我们需要了解一个叫页表寄存器的东西 英文名儿叫PTR 不是指针奥 指针我记得是小写的ptr 可以对比记忆
这个东西就是帮助我们获得页表起始地址
这样一来 对于每个进程 我们都能找到他对应的页表 再通过我们进程的页号找到内存块号(页表的作用)
同时页表长度M也放在这个寄存器里面,我觉得他存在的价值就是防止出现越界访问(毕竟本质上就是个数组)的现象
具体的看后面的地址变换过程就可以 这里不需要搞太多 烦得很

地址变换
初步
正如我上文所说 在具体的流程里面 这个页表长度就是在一开始与我们的页号做比较,只有当页号P小于等于我们的页表长度M的时候才是合法的
这又是为啥?
个人理解:不论是站在页表长度的角度还是页号的角度 我们是不是都是从零开始数的 什么意思?就是他俩为什么可以比较 是不是就是他俩都指的是逻辑地址
所以P<=M就是页号的最大值没有超过页表的最大长度 不就这意思么
我们还需要知道像这种跟进程有关的小信息往往是存放在PCB中的 要用的时候再给他放到PTR里面
进阶(引入快表TLB)
在看懂了上面的流程之后 我们引入了一个叫快表(TLB)的东西放在查询页表前面
它有什么用?
它的作用大了 类似于计组的cache 而且从名字我们可以看出来它很快 事实上它跟cache一样属于高速缓冲处理器 由于程序的局部性原理 能够帮助我们大大提升程序运行效率
类似的如果我们在TLB中能够找到我们要找的页面所对应的页号 那么我们就不必访问页表(存放在内存中 访存操作是比较耗时间的) 只要快表中有我们想要的东西就仅仅是需要在最后进行一次访存操作

思考(计组相关)
Q:

Solution :

Comprehensive Practice:
(计组替换算法 & 组相联映射结合 & 分页存储管理方式)

二级页表
引入


结构

实现

结语
如果你正在被这些专业课所困扰 焦虑 崩溃 请不用担心 因为说白了它就是难 我认为即便是在网络如此发达的当下 计算机的学习成本和难度就是当之无愧的TOP 山永远在那 只要每天做好自己的事情就可以 前不久我也完成了我给自己定下的阶段性目标
感恩一直以来帮助过我的朋友和 不懂事时 对我眼里一直充满爱意和爱护的她 感恩一直以来扶持我的家人 让我即便至今都有 只要我想要就能得到 的信念感和自信心!哈尔滨的天气真的很难有丁达尔效应
——逸霜写於冰城