K8s入门指南:架构解析浓缩版与服务间调用实战演示
目录
- 前言
- 一、k8s概念理解
- 1、k8s整体架构
- (1) Master 主节点
- (2) Node 工作节点
- (3) Etcd 键值存储数据库
- 2、Pod被视为最小的部署单元
- 3、k8s的五种控制器类型
- (1)一个创建 deployment 的流程原理
- (2)水平扩缩容和更新/回滚
- 4、k8s中的服务发现和网络调用
- (1)服务间调用
- (2)服务外访问
- 5、注解、ConfigMap与Secret
- (1)注解与标签的区别
- (2)ConfigMap与Secret
- 二、k8s可视化平台部署微服务架构服务间调用demo实践
- 1、服务代码打包成镜像文件上传到镜像仓库
- 2、创建Deployment
- 3、创建Service抽象层
- 4、服务间调用验证
前言
小马最近在重拾微服务,上一篇介绍了《领域驱动设计(DDD)初见面(附示例代码)》,本次自然而然到了k8s这一趴。k8s无疑是云原生中的庞然大物,也是云原生的基石。本次小马顺手做了对k8s整个体系理解的浓缩版整理,无论是k8s知识快速入门还是极速复盘,本文都是居家良药。本文旨在一文理解k8s基本概念和原理,并实现了一个k8s部署微服务架构服务间调用demo实践,便于加深理解和指引,希望对大家有所帮助。如果需要完整版的也可以通过这个链接直达k8s官方官网教程。

一、k8s概念理解
Google 在 2000 年代开发了名为 Borg 的大规模容器集群管理系统,用于管理其全球数据中心的容器化应用(如搜索、广告服务)。Borg 积累了十多年的分布式系统运维经验,为 Kubernetes 提供了核心技术基础。
2014 年,Google 将 Borg 的核心设计思想开源,推出 Kubernetes(希腊语“舵手”之意),旨在推动容器编排技术的标准化。
名称缩写 K8s 源于用“8”替代“ubernete”这 8 个字符。
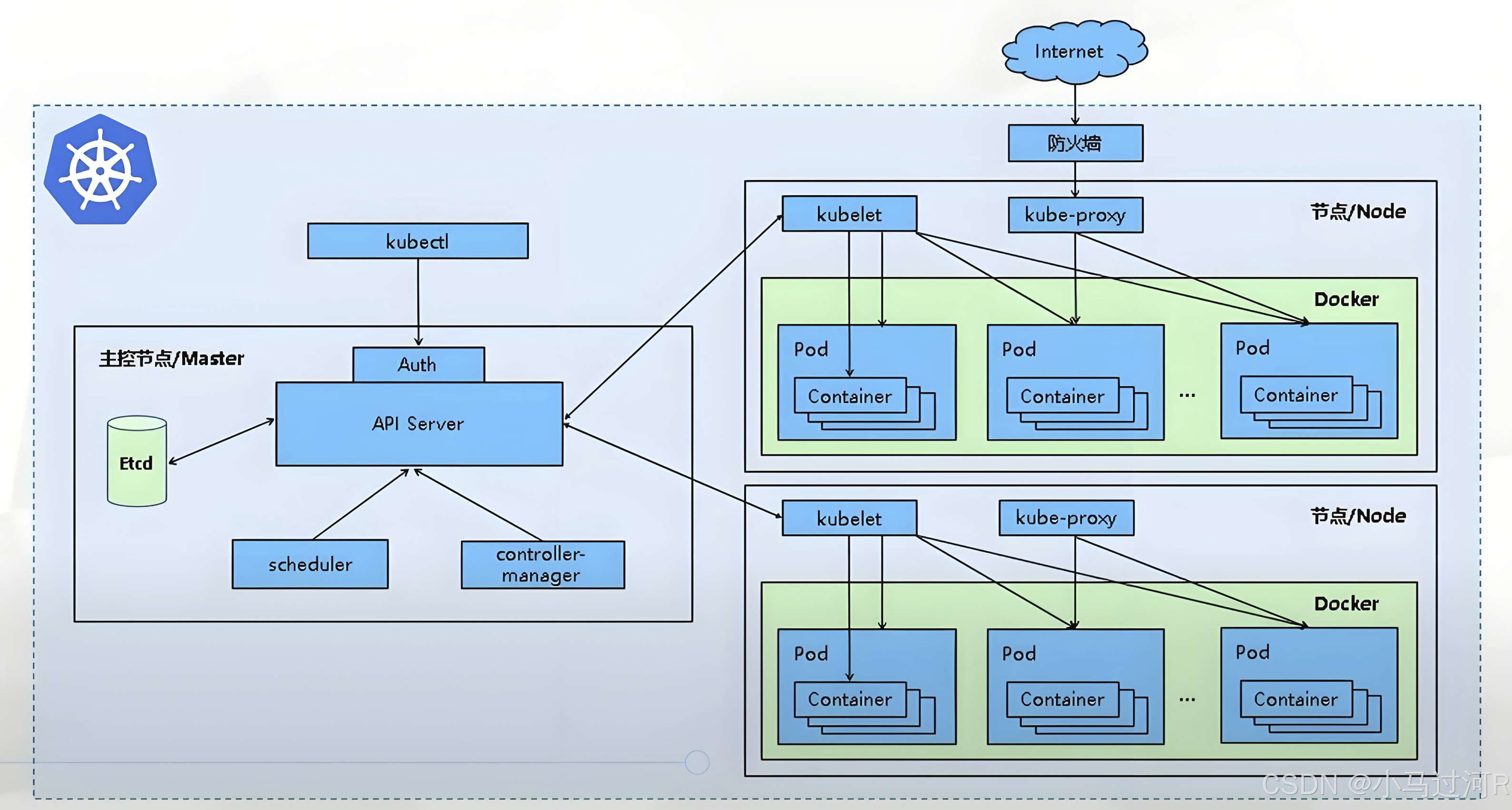
1、k8s整体架构

Kubernetes 架构从宏观上来看,包括 Master、Node 以及 Etcd。
(1) Master 主节点
Master 即主节点,负责控制整个 Kubernetes 集群。它包括 Api Server、Scheduler、Controller 等组成部分,这些组件都需要和 Etcd 进行交互以存储数据。
| 组成部分 | 作用 |
|---|---|
| Api Server | Api Server 主要提供资源操作的统一入口(即命令行命令会先请求Api Server更改Etcd数据配置),屏蔽了与 Etcd的直接交互,功能包括安全、注册与发现等。 |
| Scheduler | Scheduler 负责调度Pod到Node上(即在发现未绑定的Pod后按照规则绑到合适的Node上)负责按照一定的调度规则将 Pod 调度到 Node 上。 |
| Controller | Controller 是资源控制中心(即检测资源变化,变化也可能来自Etcd数据,随后发起资源创建的请求),确保资源处于预期的工作状态。 |
(2) Node 工作节点
Node 即工作节点,为整个集群提供计算力,是容器真正运行的地方,Node包括运行容器container、kubelet、kube-proxy。
| 组成部分 | 作用 | 拓展 |
|---|---|---|
| kubelet | kubelet负责容器生命周期节点状态(即如果发现自己的Node上需要创建Pod,比如是Scheduler 调度器分配的,则开始创建Pod)。主要工作包括管理容器的生命周期、结合 cAdvisor 进行监控、健康检查以及定期上报节点状态。 | |
| kube-proxy | kube-proxy负责集群内负载均衡,(即负责初始化init service 相关的资源,用户可利用service抽象层定义Pod访问策略)。主要利用 service 提供集群内部的服务发现和负载均衡,同时监听 service/endpoints 变化并刷新负载均衡。 | k8s中的Service是一个抽象层,用于定义一组Pod的访问策略,提供负载均衡和服务发现功能。Service解决了Pod IP地址不稳定的问题,通过为Pod提供一个稳定的入口点,使得服务可以透明地扩展和访问。Service 是一个应用服务抽象,定义了 Pod 逻辑集合和访问这个 Pod 集合的策略。Service 代理 Pod 集合对外表现是为一个访问入口,分配一个集群 IP 地址及端口,来自这个 IP 的请求将被负载均衡 (kube-proxy)转发到后端 Pod 中的容器。Service 通过 LableSelector 选择一组 Pod 提供服务。(以标签的形式标识服务) |
Kubernetes 通过将容器放入在节点(Node)上运行的 Pod 中来执行你的工作负载。 节点可以是一个虚拟机或者物理机器,取决于所在的集群配置。 每个节点包含运行 Pod 所需的服务; 这些节点由控制面负责管理。通常集群中会有若干个节点;而在一个学习所用或者资源受限的环境中,你的集群中也可能只有一个节点。节点上的组件包括 kubelet、 容器运行时以及 kube-proxy。
在Kubernetes中,控制面指的是Kubernetes集群的控制和管理部分,负责协调和管理整个集群的运行。它可以理解为集群的“大脑”,负责决定集群中的资源分配、调度、监控等关键任务。
更具体地来说,Kubernetes控制面由以下几个核心组件组成:
- API服务器(API Server):
这是控制面的核心,负责暴露Kubernetes API,接收来自用户和控制组件的请求,并对集群资源进行管理。 - etcd:
这是Kubernetes集群的存储,用于存储集群的状态和配置信息。 - 控制器管理器(Controller Manager):
负责运行集群的控制器,这些控制器会监控集群的状态,并根据需要采取相应的操作,例如部署新的Pod、删除故障的Pod等。 - 调度器(Scheduler):
负责将Pod分配到集群中的节点上,保证资源得到有效的利用。
Node 节点是相对于 Master 来说的工作主机,以前叫 Minion,现在叫 Node,它既可以是物理的,也就可以是虚拟的,每个Node 上管理着 Pod 生命周期的 Kubelet 同时也被 Master 管理,在 Node上面运行的服务进程主要有:Kubelet、Kube-proxy 和 docker daemon。
Node 的主要信息有:地址、运行状态、条件、系统容量等。
Node 管理
有个看起来不太令人相信的事情是:Node 并不是由 K8s 创建的,Node 节点其实是由物理机、虚拟机或者是云服务商提供的资源,我们在K8s 创建的其实是 Node 对象,创建完成在之后再进行一系列的检查,比如服务是否正常启动、是否可以创建 Pod等,如果检查不通过则会被标记为不可用;
Node Controller
Node Controller 是管理 Node 对象的,主要负责集群范围内的 Node 信息同步和单个 Node 的生命周期的管理。
在 Kubernetes 集群里使用了 Service(服务),它提供了一个虚拟的 IP 地址(Cluster IP)和端口号,Kubernetes 集群里的任何服务都可以通过 Cluster IP+端口的方式来访问此服务,至于访问请求最后会被转发到哪个 Pod,则由运行在每个 Node 上的 kube-proxy 负责。kube-proxy 进程其实就是一个智能的软件负载均衡器,它负责把对 Service 的请求转发到后端的某个 Pod 实例上,并在内部实现服务的负载均衡与会话保持机制。
在 Kubernetes 中,Pod 的 IP 地址是动态分配的,Pod 可能随时被销毁或重建,因此不能直接依赖 Pod IP 进行通信。为了解决这个问题,Kubernetes 提供了 Service 作为稳定的访问入口。
Service 共有四种类型(即Service的type值有四个):
ClusterIP(默认) :仅能在集群内部访问,适用于微服务之间的通信,是默认的type也是最常用的架构形式。例如,后端服务暴露 ClusterIP(集群IP),前端 Pod 通过 DNS 访问它;
NodePort:将 Service 绑定到每个节点的固定端口,使得外部可以通过 : 来访问服务,适合测试环境,但端口范围(30000-32767)受限;
LoadBalancer:集成云厂商的负载均衡器(如 AWS ELB、GCP Load Balancer),适用于生产环境。外部流量可以通过云负载均衡器访问后端 Pod;
ExternalName:将 K8s 内部请求映射到外部 DNS(如 example.com),适用于集成外部 API;
我们来看一个最精简的Service的配置示例:
#serverb 的 Service yaml配置
apiVersion: v1
kind: Service
metadata:name: serverb-svc #服务的访问名称namespace: my-test-space
spec:ports:- port: 9602 #服务暴露的端口,服务间其他服务访问serverb的地址http://serverb-svc:9602 protocol: TCPtargetPort: 9502 #容器暴露的端口selector:app: serverb #对应服务标签type: ClusterIP #可不写,默认也是ClusterIP
(3) Etcd 键值存储数据库
在K8s中,Etcd是一个高度可靠、分布式的键值存储数据库,用于存储集群的共享配置和服务发现信息。Etcd 在 Kubernetes架构中扮演着核心组件的角色,是集群状态数据的关键存储后端。

Kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。
2、Pod被视为最小的部署单元
Pod在Kubernetes众多的API资源中,是最重要和基础的,被视为最小的部署单元。一个Pod可以包含一个或多个容器,这些容器共享相同的网络命名空间、存储卷和资源限制。
首先,我们需要理解为什么需要Pod。Pod是一种容器设计模式,专为那些具有“超亲密”关系的容器而设计。例如,在servlet容器部署war包、日志收集等场景中,这些容器之间往往需要共享网络、共享存储和共享配置。因此,Pod的概念应运而生。

对于Pod来说,不同的容器之间通过infra container的方式统一识别外部网络空间。这意味着,尽管容器可能运行在不同的宿主机上,但它们通过Pod的网络命名空间相互通信(可以理解为在逻辑上构建了虚拟网络),就像它们在同一台机器上一样。此外,通过挂载同一份volume,容器可以共享存储。例如,这个volume可能对应宿主机上的一个目录,使得容器可以访问相同的文件系统区域。(即各个容器都可以共享宿主机的某个目录)
Kubernetes 不会直接管理容器,而是通过 Pod 来管理。一个Pod包含如下内容:
一个或多个容器,一般是一个,除非多个容器紧密耦合共享资源才放在一个 Pod 中;
共享的存储资源(如数据卷),一个 Pod 中的容器是可以共享存储空间的;
一个共享的 IP 地址,Pod 中容器之间可以通过 localhost:port 彼此访问;
定义容器该如何运行的选项。
Pod 中的容器可包括两种类型:
工作容器:就是我们通常运行服务进程的容器;
初始化容器:完成一些初始化操作的容器,初始化容器在工作容器之前运行,所有的初始化容器成功执行后,才开始启动工作容器;
容器编排是Kubernetes的看家本领。Kubernetes提供了多种编排相关的控制资源,如编排无状态应用的deployment、编排有状态应用的statefulset、编排守护进程的daemonset以及编排离线业务的job/cronjob等。(这里的应用可理解为等同于一些可视化平台上的工作负载)
以应用最广泛的deployment为例,deployment(负责replicaset的版本控制,可支持更新或回滚)、replicaset(负责控制pod的数量,replicaset这个对象的存在是有“个数”版本的)和pod之间的关系是一种层级控制的关系。
简单来说,replicaset负责控制pod的数量,确保有足够的pod实例在运行以满足应用的需求。而deployment则负责控制replicaset的版本属性,使得我们可以轻松地更新或回滚应用版本。这种设计模式为两种最基本的编排动作提供了基础:数量控制的水平扩容(或缩容)以及版本属性控制的更新/回滚。
3、k8s的五种控制器类型
Kubernetes中内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为。总体来说k8s有五种控制器,分别对应处理无状态应用、有状态应用、守护型应用和批处理应用。
| 应用类型 | 适用场景 |
|---|---|
| Deployment | 适合无状态的服务部署 |
| StatefullSet | 适合有状态的服务部署,如DB服务 |
| DaemonSet | 一次部署,所有的node节点都会部署,例如一些典型的应用场景:运行集群存储 daemon,例如在每个Node上运行 glusterd、ceph;在每个Node上运行日志收集 daemon,例如 fluentd、 logstash;在每个Node上运行监控 daemon,例如 Prometheus Node Exporter; |
| Job | 一次性的执行任务 |
| Cronjob | 周期性的执行任务 |
(1)一个创建 deployment 的流程原理

从创建 deployment (编排无状态应用的资源控制deployment )开始,整个流程涉及多个组件的协作。以下是各组件在创建 deployment 资源过程中的具体作用:
kubectl 发起创建 deployment 的请求。(kubectl是K8S官方的命令行工具,用于与Kubernetes集群交互,管理集群中的资源如Pod、Service、Deployment等。它通过向Kubernetes API发送REST请求实现资源的增删改查操作,是运维和开发人员管理K8S集群的核心工具。)
apiserver 接收到该请求后,将相关资源写入 etcd。 之后,所有组件与 apiserver/etcd 的交互都遵循类似的模式。
deployment controller 通过 list/watch 机制检测到资源变化,并发起创建 replicaSet 的请求。(replicaSet 也叫副本集合,是Replication Controller的下一代副本控制器)
replicaSet controller 同样通过 list/watch 机制检测到资源变化,并发起创建 pod 的请求。
scheduler 检测到未绑定的 pod 资源,通过一系列匹配和过滤规则,选择合适的 node 进行绑定。
kubelet 发现自己 node 上需要创建新 pod,负责 pod 的创建及其后续生命周期管理。
kube-proxy 负责初始化 service 相关的资源,包括服务发现、负载均衡等网络规则。
至此,经过 Kubernetes 各组件的分工协调,完成了从创建一个 deployment 请求开始到具体各 pod 正常运行的全过程。
(2)水平扩缩容和更新/回滚

水平扩缩容:
Deployment 水平扩缩容非常好理解,只需修改 replicaset 控制的 pod 副本数量即可。
例如,从 2 个副本增加到 3 个副本,即完成了水平扩容;反之,则是水平收缩。

更新/回滚:
更新/回滚则体现了 replicaset 这个对象的存在必要性。
当需要应用 3 个实例的版本从 v1 改到 v2 时,v1 版本 replicaset 控制的 pod 副本数会逐渐从 3 变到 0。
同时,v2 版本 replicaset 控制的 pod 数会从 0 变到 3。
当 deployment 下只存在 v2 版本的 replicaset 时,就完成了更新。
回滚的动作与之相反。
在同一个 Kubernetes 集群中,这些微服务副本(Pod)通过一个统一的 Service 对外暴露,IP 和端口是一样的。
拟最佳实践部署方式参考:
每个微服务都用一个kind:Deployment + type: ClusterIP 类型的 Service部署;
统一使用一个 Ingress Controller(如 Nginx Ingress)提供对外访问; 编写一个 Ingress
资源,根据不同的 path 或域名转发到对应服务;
我们来看一个最精简的Deployment的配置示例:
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: serverbname: deployment-test-name #Deployment namenamespace: my-test-space #命名空间(隔离)
spec:replicas: 2selector:matchLabels:app: serverb #label标签template:metadata:labels:app: serverb #label标签spec:containers:- image: 'mirrors-registry-hub.com/mytestspace:serverb-v2' #容器将运行的镜像仓库中的镜像serverb-v2name: serverb #容器nameports:- containerPort: 9502 #容器的端口(相当于docker run时指定的端口)resources:limits:cpu: 250mmemory: 128Mirequests:cpu: 250mmemory: 128Mi一个Deployment部署不直接等于一个微服务部署,但通常被用作为一个微服务对应一个Deployment。通常情况下一个微服务的某个服务会对应一个Deployment。下面是一个更复杂的yaml案例。

如上,气氛都烘托到这了,我们下一步来讲网络调用。
4、k8s中的服务发现和网络调用
这一块内容似乎和上文提到的service四种type类型息息相关。
(1)服务间调用

首先是东西向的流量调用,即服务间调用。这部分主要包括两种调用方式:
clusterIp 模式:clusterIp 是 service 的一种类型,在这种类型模式下,kube-proxy 通过 iptables/ipvs 为 service 实现了一种 VIP(虚拟 ip)的形式。只需要访问该 VIP,即可负载均衡地访问到 service 背后的 pod。此外,clusterIp 的实现方式还包括 userSpace 代理模式(基本不用)以及 ipvs 模式(性能更好)。
如创建一个type:clusterIp 的service 则将会得到一个clusterIp。
dns 模式:对 clusterIp 模式的 service 来说,它有一个 A 记录是 service-name.namespace-name.svc.cluster.local,指向 clusterIp 地址。所以一般使用过程中,直接调用 service-name 即可。参考上文对service的 yaml 配置文件来理解。
(2)服务外访问
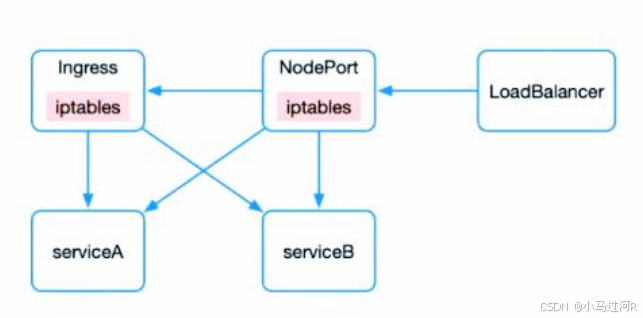
南北向的流量,即外部请求访问 kubernetes 集群(service 服务),主要包括三种方式:
nodePort:同样是 service 的一种类型,通过 iptables 赋予了调用者主机上的特定 port 就能访问到其后 service 的能力。
loadbalancer:是另一种 service 类型,通过公有云提供的负载均衡器实现。
ingress(进入):通过 ingress 控制器实现外部访问。
我们来看一个最精简的ingress的配置示例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/rewrite-target: / #路由转发name: ingress-test-namenamespace: my-test-space
spec:rules: #路由规则- http:paths:- backend:service:name: serverb-svcport:number: 9602path: /myservers #外部域名/myservers/路径下的请求访问转发到服务b即serverb-svc:9602/pathType: Prefix
Kubernetes集群里有三种IP地址,分别如下:
Node IP:Node 节点的IP地址,即物理网卡的IP地址。但不绝对node就是物理的。
Pod IP:Pod 的IP地址,即 docker 容器的IP地址,此为虚拟IP地址。
Cluster IP:Service 的IP地址,此为虚拟IP地址。

如上,一个Deployment应用serverb下的两个pod,可以看到会出现有多种ip。(因为集群里有两个node所以pod被自动合理分配到两个node上)
ip互通性经验总结:
(1)同一Deployment应用之内(同一服务之间不同pod),pod ip可以互通,host ip不行;
(2)不同Deployment应用之间(不同服务之间不同pod),pod ip也可以互通;
也就是呼应了上文说到的服务之间的调用其实可以直接通过pod ip 即可。但是【Pod 的 IP 地址是动态分配的,Pod 可能随时被销毁或重建,因此不能直接依赖 Pod IP 进行通信。为了解决这个问题,Kubernetes 提供了 Service 作为稳定的访问入口。】
Service 有分配ClusterIP。

外部访问 Kubernetes 集群里的某个节点或者服务时,必须要通过 Node IP 进行通信。 Pod IP 是 Docker Engine 根据 flannel.1 网桥的 IP 地址段进行分配的一个虚拟二层网络IP地址,Pod 与 Pod 之间的访问就是通过这个虚拟二层网络进行通信的,而真实的TCP/IP 流量则是通过 Node IP 所在的物理网卡流出的。
5、注解、ConfigMap与Secret
(1)注解与标签的区别
标签(Labels):用于标识和选择对象,通常用于组织和选择一组对象,例如标识应用程序的不同版本、环境类型或角色。标签可以通过Label Selector来过滤或选择具有特定标签的对象,这对于部署和服务发现非常有用。
注解(Annotations):不用于标识和选择对象,主要用于存储不会影响系统行为的信息,如构建信息、发布日期、团队联系人等。注解不能作为选择器使用,因此对于键值的内容没有太多的限制,可以存放较长的文本或结构化的数据。
(2)ConfigMap与Secret
ConfigMap 是 Kubernetes 中用于管理非敏感配置数据的核心资源对象,实现配置与应用容器的解耦,支持动态更新与集中管理。

二、k8s可视化平台部署微服务架构服务间调用demo实践
本次案例将实现基于k8s可视化平台部署的微服务架构服务间调用demo的过程,旨在说明k8s中微服务架构中内部服务之间的通信调用方式,非完整微服务架构部署案例(计划将在后续文章逐步介绍)。相对比较适合新手参考理解。
我们将编写两个服务,servera和serverb,并由serverb在服务内通过servera的 service name来调用servera服务的api。
在进行本地案例之前,需要先在本地安装好docker,最好也一起安装好swoole运行环境(可用于本地验证服务run success)。
1、服务代码打包成镜像文件上传到镜像仓库
我们为了便捷,server代码仅写了一份,同时兼容servera和serverb,注意甄别即可。

server代码start.php和Dockerfile文件参考如下:
//servera的代码同时也是serverb的代码
$server->on('request', function (Swoole\Http\Request $request, Swoole\Http\Response $response) {$ip = 'servera-svc'; // 由server B调用server A的api$port = 9601; // 服务端口$response->header('Content-Type', 'text/plain');$path = $request->server['request_uri']; switch ($path) {case '/clientapi':$client = new Swoole\Coroutine\Http\Client($ip, $port); //创建HTTP客户端$client->set(['timeout' => 5]); $client->get('/serverapi'); //发起GET请求if ($client->statusCode === 200) {$response->end("callapi succ, strlen: ".strlen($client->body));} else {$response->end("callapi fail, code: ".$client->statusCode); }$client->close(); break;case '/serverapi':$response->end(json_encode(['iRet'=>0,'sMsg'=>'ok','data'=>'this is serverapi'])); break;case '/':$response->end("Hello, Swoole!"); break;}
});
# Dockerfile文件
# To install the MySQL extensions.
# NOTE: The pdo_mysql extension is included in 4.8.12+ and 5.0.1+ images.
FROM phpswoole/swoole:php8.3-alpine#RUN docker-php-ext-install mysqli pdo_mysql
# 设置工作目录
WORKDIR /var/www# 复制项目文件到容器中
COPY . .
# 暴露端口
EXPOSE 9502# 设置容器启动时运行的命令
CMD ["php", "/var/www/start.php"]
我们在代码目录下运行命令docker build -t my-php-serverab .,构建打包成镜像文件,my-php-serverab为本地镜像的名字。我们在本地可以查看到当前的镜像ID。类似于这个值:

我们平常在本地运行的起容器类似命令docker run -d -p 9502:9502 --name my-swoole-server-name my-php-serverab将交由Deployment来处理。
现在,我们根据docker仓库操作相关命令,仓库一般也有直接的命令提示,copy即可;通过本地镜像ID将本地镜像推送到远程镜像仓库中(需要先在远程仓库创建一个仓库用来推动镜像)。
因为我们在这里用了同一份server代码和镜像,所以镜像名取名serverab-v2。
假设push成功后镜像地址:mirrors-registry-hub.com/mytestspace:serverab-v2
2、创建Deployment
创建两个Deployment,对应两个服务servera和serverb。
yaml文件的参考代码:
# servera的Deployment
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: serveraname: deployment-test-name #Deployment namenamespace: my-test-space #命名空间(隔离)
spec:replicas: 2selector:matchLabels:app: servera #label标签template:metadata:labels:app: servera #label标签spec:containers:- image: 'mirrors-registry-hub.com/mytestspace:serverab-v2' #容器将运行的镜像仓库中的镜像name: servera #容器nameports:- containerPort: 9502 #容器的端口resources:limits:cpu: 250mmemory: 128Mirequests:cpu: 250mmemory: 128Mi
# serverb的Deployment
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: serverbname: deployment-test-name #Deployment namenamespace: my-test-space #命名空间(隔离)
spec:replicas: 2selector:matchLabels:app: serverb #label标签template:metadata:labels:app: serverb #label标签spec:containers:- image: 'mirrors-registry-hub.com/mytestspace:serverab-v2' #容器将运行的镜像仓库中的镜像name: serverb #容器nameports:- containerPort: 9502 #容器的端口resources:limits:cpu: 250mmemory: 128Mirequests:cpu: 250mmemory: 128Mi
3、创建Service抽象层
#servera 的 Service yaml配置
apiVersion: v1
kind: Service
metadata:name: servera-svc #服务的访问名称namespace: my-test-space
spec:ports:- port: 9601 #服务暴露的端口,服务间其他服务访问servera的地址http://servera-svc:9601 protocol: TCPtargetPort: 9502 #容器暴露的端口selector:app: servera #对应服务标签type: ClusterIP #可不写,默认也是ClusterIP
#serverb 的 Service yaml配置
apiVersion: v1
kind: Service
metadata:name: serverb-svc #服务的访问名称namespace: my-test-space
spec:ports:- port: 9602 #服务暴露的端口,服务间其他服务访问serverb的地址http://serverb-svc:9602 protocol: TCPtargetPort: 9502 #容器暴露的端口selector:app: serverb #对应服务标签type: ClusterIP #可不写,默认也是ClusterIP
我们在上文中其实也能找到创建成功的截图。
至此,两个服务已经搭建完毕。
4、服务间调用验证
我们访问serverb的api,通过serverb内部发起的对servera的调用来验证服务间的调用成功。(如果想更清晰点可以优化代码,将serverapi的json返回也在clientapi中返回打印即可)


至此,k8s可视化平台部署微服务架构服务间调用demo实践成功结束。至于整个微服务架构如何实现我们只有下次再见啦,感谢评阅!
参考资料:
kubernetes.io官方 https://kubernetes.io/zh-cn/docs/home/
Kubernetes中文社区 https://www.kubernetes.org.cn/doc-11
docker菜鸟教程 https://www.runoob.com/docker/docker-tutorial.html