【NLP项目设计】自定义风格歌词生成app
目录
硬件需求和环境配置
n卡驱动配置
以cuda11.8 版本为例
下载对应的cudnn(version11+)
安装GPU版本的torch
安装gpu版本的TensorFlow
检查
项目简介
要求
需要考虑的问题
开发说明
项目名称:Lyricist AI - 歌词仿写生成器
项目架构
01数据预处理
02
03
04
05
说明:目前项目还在调优,文章内容后续会继续更新优化,需要源码的小伙伴们麻烦动动金贵的小手点个关注、收藏,笔者后续会将项目代码发布到GitHub,更新后的文章会附上地址!
硬件需求和环境配置
n卡驱动配置
以cuda11.8 版本为例
CUDA Toolkit 11.8 Downloads | NVIDIA Developer








该提示是说未找到支持版本的 Visual Studio ,部分 CUDA 工具包组件可能无法正常工作,建议先安装 Visual Studio 。若你:
不打算在 Visual Studio 中使用 CUDA 开发:勾选 “I understand, and wish to continue the installation regardless.”,然后点击 “NEXT” 继续安装 CUDA,不影响 CUDA 在其他场景或非集成开发环境下的基本使用。
后续有在 Visual Studio 中进行 CUDA 开发的计划:可先停止 CUDA 安装,安装合适版本的 Visual Studio(CUDA 不同版本对应支持特定的 Visual Studio 版本,需提前确认适配关系 ),之后再重新安装 CUDA。



建议就默认安装路径,方便后续管理
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
添加环境变量
CUDA_PATH和CUDA_PATH_V11.8

添加后查看 cmd里输入
nvcc -V

cuda toolkit就安装完成
下载对应的cudnn(version11+)
跑深度学习任务还需要对应版本的cudnn,才能在执行模型训练等脚本时调用到gpu
cuDNN Archive | NVIDIA Developer


因为限制,国内无法注册nvidia账号,所以不能直接从官网下载,需要另找资源
需要这两个包

获取之后解压
cudnn


将这三个(bin include lib)复制,合并到上面下载cuda的目录下(要到对应版本的目录)

粘贴进去
然后来到这个路径下
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\extras\demo_suite
查看是否存在这两个文件

打开cmd
进入这个路径

依次执行
bandwidthTest.exe

看到末尾有‘PASS’说明成功

deviceQuery.exe


最后添加、检查系统环境变量
Path中

需要有这三个路径



安装GPU版本的torch
版本是2.3.0 这个版本和cuda11.8 cudnn11.8兼容性较好 目前也使用得比较多
下载torch torchvision torchaudio
pip install torch==2.3.0 --index-url https://download.pytorch.org/whl/cu118
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ torchvision==0.14.0
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ torchaudio==2.3.0
测试脚本
import torch
import platformdef test_pytorch_gpu():"""测试当前环境中PyTorch与GPU的兼容性"""print(f"Python版本: {platform.python_version()}")print(f"PyTorch版本: {torch.__version__}")# 检查CUDA是否可用if torch.cuda.is_available():print("\n=== CUDA 可用 ===")print(f"CUDA版本: {torch.version.cuda}")print(f"GPU数量: {torch.cuda.device_count()}")# 获取并打印第一个GPU的信息
gpu_name = torch.cuda.get_device_name(0)print(f"第一个GPU: {gpu_name}")# 创建张量并在GPU上执行简单运算try:# 创建在GPU上的张量
x = torch.tensor([1.0, 2.0], device='cuda')
y = torch.tensor([3.0, 4.0], device='cuda')# 执行加法运算
z = x + y# 将结果传回CPU并打印print(f"\n在GPU上执行运算: {x} + {y} = {z.cpu().numpy()}")# 测试CUDA流
stream = torch.cuda.Stream()with torch.cuda.stream(stream):
a = torch.ones(1000, 1000, device='cuda')
b = a * 2
c = b.mean()
torch.cuda.synchronize()print("CUDA流测试成功")print("\nPyTorch与GPU环境兼容正常!")return Trueexcept Exception as e:print(f"\nGPU运算测试失败: {str(e)}")print("PyTorch与GPU环境存在兼容性问题!")return Falseelse:print("\n=== CUDA 不可用 ===")print("PyTorch未检测到可用的CUDA设备")print("可能原因: 没有NVIDIA GPU、驱动未安装或PyTorch版本与CUDA不匹配")# 检查是否有MPS (Apple Silicon) 支持if hasattr(torch, 'has_mps') and torch.has_mps:print("\nMPS (Apple Silicon) 支持已检测到")print("提示: 当前测试针对CUDA GPU,建议在NVIDIA GPU环境下运行")return Falseif __name__ == "__main__":
test_pytorch_gpu()
看到这个表示框架和软硬件环境兼容了


安装gpu版本的TensorFlow
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ tensorflow-gpu==2.9.1
# 深度学习框架
# tensorflow-gpu==2.9.1
# keras==2.9.0

测试安装
import tensorflow as tfdef test_tensorflow_gpu():
"""测试TensorFlow-GPU与CUDA的兼容性"""
try:
# 检查TensorFlow版本
tf_version = tf.__version__
print(f"TensorFlow版本: {tf_version}") # 检查GPU是否可用
gpus = tf.config.list_physical_devices('GPU')
if not gpus:
print("未发现GPU设备。请确保安装了正确的GPU驱动和CUDA工具包。")
return print(f"发现{len(gpus)}个GPU设备:")
for gpu in gpus:
print(f" - {gpu}") # 测试GPU计算
with tf.device('/GPU:0'):
a = tf.constant([1.0, 2.0, 3.0], shape=[1, 3])
b = tf.constant([1.0, 2.0, 3.0], shape=[3, 1])
c = tf.matmul(a, b) print("GPU计算测试成功!")
print(f"计算结果: {c.numpy()}") # 检查CUDA版本兼容性
try:
# 获取TensorFlow编译时的CUDA版本
cuda_compile_version = tf.sysconfig.get_build_info()['cuda_version']
print(f"TensorFlow编译时使用的CUDA版本: {cuda_compile_version}") # 获取运行时CUDA版本(通过TensorFlow)
runtime_cuda_version = tf.test.is_built_with_cuda()
if runtime_cuda_version:
print("TensorFlow已启用CUDA支持。")
else:
print("TensorFlow未启用CUDA支持,可能无法使用GPU。") # 尝试获取更详细的CUDA运行时版本
try:
from tensorflow.python.platform import build_info
cuda_version = build_info.cuda_version_number
cudnn_version = build_info.cudnn_version_number
print(f"TensorFlow使用的CUDA版本: {cuda_version}")
print(f"TensorFlow使用的cuDNN版本: {cudnn_version}")
except Exception as e:
print(f"无法获取详细的CUDA/cuDNN版本信息: {e}") # 检查GPU驱动版本
try:
from tensorflow.python.client import device_lib
local_device_protos = device_lib.list_local_devices()
for x in local_device_protos:
if x.device_type == 'GPU':
print(f"GPU驱动信息: {x.physical_device_desc}")
except Exception as e:
print(f"无法获取GPU驱动信息: {e}") except Exception as e:
print(f"CUDA版本检查失败: {e}")
print("请手动检查您的CUDA版本是否与TensorFlow兼容。")
print("TensorFlow CUDA兼容性矩阵: https://www.tensorflow.org/install/source#gpu") except Exception as e:
print(f"测试过程中发生错误: {e}")if __name__ == "__main__":
test_tensorflow_gpu()
检查
NVIDIA 显卡:使用 nvidia-smi 命令
若已安装 NVIDIA 驱动,输入:
nvidia-smi
可查看:
GPU 型号、驱动版本、CUDA 版本。
显存使用情况、GPU 温度、功耗等实时数据。

需要电脑有配置5G及以上显存的显卡,这里我使用n卡
再配置conda环境,创建一个项目环境
这是我的显卡信息,现在用conda创建一个支持tensorflow2.x版本(同时tf编写的源代码使用的是2版本以下的numpy,降级numpy到2以下才能正常使用tf)的conda环境,注意python版本:
conda create -n nlp_tf python=3.9

完成后输入conda activate nlp_tf启动环境
在环境里下载tensorflow-gpu版本2.x以上
用华为云安装:
pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ tensorflow-gpu==2.9.1
# pip install -i https://mirrors.huaweicloud.com/repository/pypi/simple/ tensorflow==2.5.0

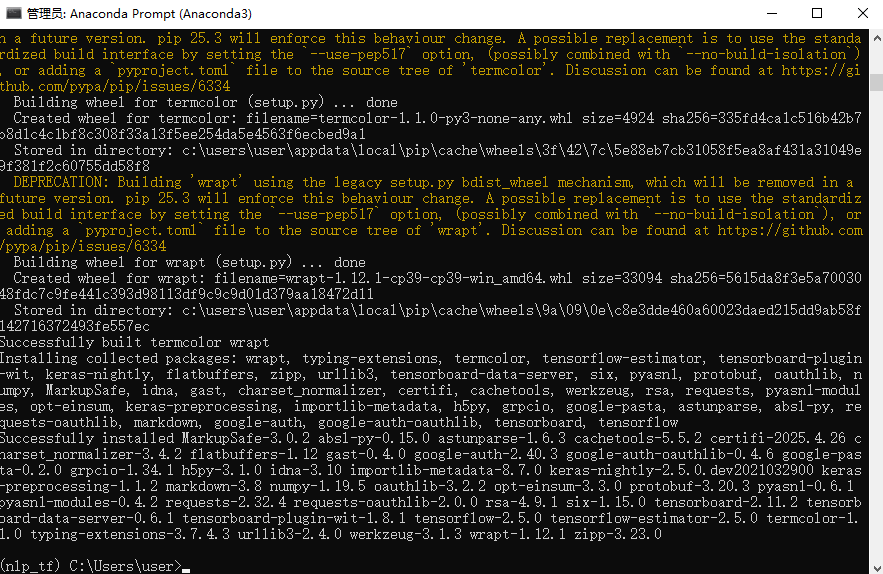
tensorflow安装成功(目前很多镜像源都下不成功,用华为云的源还可以,如果也不行只能自行再找找镜像站或者资源)

在编译器里面激活环境并更改解释器

项目简介
训练一个模型,实现歌词仿写生成
任务类型:文本生成;
数据集是一份歌词语料,训练一个模型仿写歌词。
要求
1.清洗数据。歌词语料中包含韩文等非中英文符号,可对语料做预处理,仅保留中英文与标点符号;
2.训练模型、生成歌词;
3.用Gradio网页展示生成的歌词;
需要考虑的问题
1.使用语料数据集csv:lyric.csv,不用到数据库;
2.硬件使用的gpu是5g的n卡,比较有限,项目本身数据量和模型参数规模都不是特别大;
3.使用tensorflow2.9.1gpu版本的框架进行构建;
4.使用的网络架构,以及每个部分的组件网络、骨干网络等,优先在各个环节选用目前的sota模型;
5.在模型训练过程中要使用tensorboard可视化训练过程;6.对于数据的处理,先对csv进行必要的可视化,然后进行多语言歌词清洗(可参考的步骤:多语言过滤、特殊格式处理、分词策略、序列对齐、同义词替换、句式重组等);7.项目构建严格规范文件架构,做到一个脚本做一个环节(数据预处理脚本、模型构建脚本、训练、测试、推理等等);
开发说明
开发阶段使用jupyter notebook 测试与推理使用结构化的python项目包来运行
1. 激活 conda 环境
首先,打开 Anaconda Prompt(Windows)或终端(Linux/macOS),激活之前创建的环境:
conda activate nlp_tf # 替换为你的环境名称
2. 安装 ipykernel
在激活的环境中安装 ipykernel 包,这是连接 conda 环境和 Jupyter 的桥梁:
conda install ipykernel # 使用conda安装
# 或者使用pip安装
# pip install ipykernel

3. 将环境注册为 Jupyter 内核
安装完成后,运行以下命令将当前环境注册为 Jupyter 的一个内核:
python -m ipykernel install --user --name=nlp_tf --display-name="Python (TF 2.5.0)"
--user:表示只安装在当前用户目录下
--name:内核的内部名称(通常使用环境名)
--display-name:在 Jupyter 中显示的名称(可以自定义)

4. 验证内核是否已添加
重启 Jupyter Notebook,然后在菜单中选择:
New → 查看是否有你刚添加的内核(如 "Python (TF 2.12)")
或者在已打开的 Notebook 中,选择 Kernel → Change kernel → 查看是否有新内核


项目名称:Lyricist AI - 歌词仿写生成器
项目架构
lyric_generation/
├── data/
│ ├── raw/
│ │ └── lyric.csv
│ ├── processed/
│ │ ├── cleaned_lyrics.csv
│ │ ├── tokenizer.pkl
│ │ └── vocab.json
│ └── visualizations/
│ ├── data_analysis.html
│ └── length_distribution.png
├── src/
│ ├── data/
│ │ ├── init.py
│ │ ├── data_loader.py
│ │ ├── preprocessor.py
│ │ └── visualizer.py
│ ├── models/
│ │ ├── init.py
│ │ ├── transformer_model.py
│ │ ├── lstm_model.py
│ │ └── model_utils.py
│ ├── training/
│ │ ├── init.py
│ │ ├── trainer.py
│ │ └── callbacks.py
│ ├── inference/
│ │ ├── init.py
│ │ ├── generator.py
│ │ └── post_processor.py
│ └── utils/
│ ├── init.py
│ ├── config.py
│ └── helpers.py
├── scripts/
│ ├── 01_data_visualization.py
│ ├── 02_data_preprocessing.py
│ ├── 03_model_training.py
│ ├── 04_model_evaluation.py
│ └── 05_gradio_app.py
├── models/
│ ├── checkpoints/
│ └── saved_models/
├── logs/
│ └── tensorboard/
├── requirements.txt
├── config.yaml
└── README.md
Markdown
## 技术架构### 网络架构设计
1. **骨干网络**: Transformer-based架构
- 使用轻量化的GPT-2风格decoder
- 针对5GB GPU优化的模型参数2. **组件网络**:
- **Embedding层**: 词嵌入 + 位置编码
- **Multi-Head Attention**: 8个注意力头
- **Feed Forward Network**: 隐藏层维度1024
- **Layer Normalization**: 每个子层后应用
- **Dropout**: 防止过拟合3. **模型规模优化**:
- 模型参数: ~50M (适合5GB GPU)
- 序列长度: 512 tokens
- 批大小: 8-16### SOTA模型选择理由
1. **Transformer架构**: 当前文本生成的SOTA
2. **GPT-2结构**: 自回归生成,适合歌词创作
3. **BERT tokenizer**: 中英文混合处理能力强
4. **Gradient Accumulation**: 模拟大批量训练## 核心脚本功能### 1. 数据可视化脚本 (01_data_visualization.py)
- 歌词长度分布分析
- 语言成分统计
- 歌手作品数量分析
- 词频统计和可视化### 2. 数据预处理脚本 (02_data_preprocessing.py)
- 多语言过滤 (保留中英文)
- 特殊格式处理 (去除标记符号)
- 分词策略 (jieba + 英文分词)
- 序列对齐和填充
- 构建词汇表### 3. 模型训练脚本 (03_model_training.py)
- 模型构建和编译
- 训练循环实现
- TensorBoard集成
- 检查点保存
- 早停机制### 4. 模型评估脚本 (04_model_evaluation.py)
- 困惑度计算
- BLEU分数评估
- 生成样本质量分析### 5. Gradio应用脚本 (05_gradio_app.py)
- Web界面构建
- 实时生成展示
- 参数调节界面## 使用流程### 环境准备
```bash
# 创建虚拟环境
conda create -n lyric_gen python=3.8
conda activate lyric_gen# 安装依赖
pip install -r requirements.txt
数据处理
模型训练
模型评估
01数据预处理



python scripts/01_data_visualization.py
终端反馈
Loading data...
Data loaded: 19995 records
Preprocessing lyrics...
Processed 19995 lyrics
=== 基本统计信息 ===
总歌曲数: 19995
歌手数量: 107
平均歌词长度: 347.42
最长歌词: 3257
最短歌词: 0
平均词数: 50.69
作品最多的歌手: {'陈淑桦': 288, '罗文': 287, '陈慧娴': 282, '林淑容': 281, '郑少秋': 277, '张清芳': 276, '高凌风': 274, '梁咏琪': 273, '邰正宵': 266, '苏永康': 262}
=== 语言成分分析 ===
平均中文比例: 0.916
平均英文比例: 0.077
平均标点比例: 0.007
=== 词频分析 (前50词) ===
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\user\AppData\Local\Temp\jieba.cache
Loading model cost 0.496 seconds.
Prefix dict has been built successfully.
中文高频词:
没有: 10151
一个: 9845
我们: 9222
自己: 8091
什么: 6476
爱情: 6243
不要: 6100
知道: 5635
永远: 5500
世界: 5117
不会: 4574
寂寞: 4466
一切: 4373
快乐: 4313
不能: 4064
如果: 4045
可以: 3941
不再: 3907
这样: 3882
怎么: 3869
英文高频词:
you: 11839
me: 5521
to: 5307
love: 4334
my: 4325
it: 3986
oh: 3922
in: 3015
your: 2670
be: 2401
we: 2345
baby: 2220
la: 2144
that: 2134
of: 2117
can: 2068
so: 2033
all: 1933
on: 1918
for: 1774
HTML报告已生成: data/visualizations/data_analysis.html
=== 数据可视化分析完成 ===
请查看以下文件:
- data/visualizations/length_distribution.png
- data/visualizations/language_composition.png
- data/visualizations/word_frequency.png
- data/visualizations/data_analysis.html
02
注意:
降级 NumPy 到 1.x 版本,TensorFlow 2.9.1 和 2.10.0 需要 NumPy 1.x 版本
终端返回
� 运行调试模式...
=== 调试模式启动 ===
Loading raw data...
Loaded 19995 records
原始数据样本:
Sample 1:
Name: 水瓶座男孩的心愿
Singer: 杜德伟
Lyric: ['深情的人在夜里扬着脸', '星光闪烁在天边', '耳语喧哗在不眠树影间', '灵魂游走夜的边缘', '风中的真心呼唤有谁听见', '水瓶星座有透明心愿', '为谁永不厌倦的吟唱春天
', '为谁诞生...
--------------------------------------------------
Sample 2:
Name: I Just Want To Be Your Everthing
Singer: 杜德伟
Lyric: ['《I Just Want To Be Your Everthing》', '☆杜德伟☆', '', '√Edited By CrazyXP√', 'For so long you and me b...
--------------------------------------------------
Sample 3:
Name: 印象
Singer: 杜德伟
Lyric: ['谁令我当晚举止失常', '难自禁望君你能见谅', '但觉万分紧张 皆因跟你遇上', '谁令我突然充满幻想', '谁令我音韵脑际飘扬', '撩动我内心爱情酝酿', '为我拨开忧伤 找得
失去乐畅', ...
--------------------------------------------------
Cleaning all lyrics...
=== 处理第 1/19995 条记录 ===
处理歌曲: 水瓶座男孩的心愿 - 杜德伟
原始歌词前100字符: ['深情的人在夜里扬着脸', '星光闪烁在天边', '耳语喧哗在不眠树影间', '灵魂游走夜的边缘', '风中的真心呼唤有谁听见', '水瓶星座有透明心愿', '为谁永不厌
倦的吟唱春天', '为谁诞生
格式处理后: 深情的人在夜里扬着脸 星光闪烁在天边 耳语喧哗在不眠树影间 灵魂游走夜的边缘 风中的真心呼唤有谁听见 水瓶星座有透明心愿 为谁永不厌倦的吟唱春天 为谁诞生在冷冷
二月天 想说出人间最后一句誓言 也许不够
过滤后: 深情的人在夜里扬着脸 星光闪烁在天边 耳语喧哗在不眠树影间 灵魂游走夜的边缘 风中的真心呼唤有谁听见 水瓶星座有透明心愿 为谁永不厌倦的吟唱春天 为谁诞生在冷冷二月
天 想说出人间最后一句誓言 也许不够
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\user\AppData\Local\Temp\jieba.cache
Loading model cost 0.503 seconds.
Prefix dict has been built successfully.
分词结果前10个: ['深情', '的', '人', '在', '夜里', '扬着', '脸', '星光', '闪烁', '在']
✅ 成功处理,词数: 121, 有意义词数: 121
=== 处理第 2/19995 条记录 ===
处理歌曲: I Just Want To Be Your Everthing - 杜德伟
原始歌词前100字符: ['《I Just Want To Be Your Everthing》', '☆杜德伟☆', '', '√Edited By CrazyXP√', 'For so long you and me b
格式处理后: I Just Want To Be Your Everthing 杜德伟 Edited By CrazyXP For so long you and me been finding each othe
过滤后: I Just Want To Be Your Everthing 杜德伟 Edited By CrazyXP For so long you and me been finding each othe
分词结果前10个: ['i', 'just', 'want', 'to', 'be', 'your', 'everthing', '杜德伟', 'edited', 'by']
✅ 成功处理,词数: 383, 有意义词数: 383
=== 处理第 3/19995 条记录 ===
处理歌曲: 印象 - 杜德伟
原始歌词前100字符: ['谁令我当晚举止失常', '难自禁望君你能见谅', '但觉万分紧张 皆因跟你遇上', '谁令我突然充满幻想', '谁令我音韵脑际飘扬', '撩动我内心爱情酝酿', '为我
拨开忧伤 找得失去乐畅',
格式处理后: 谁令我当晚举止失常 难自禁望君你能见谅 但觉万分紧张 皆因跟你遇上 谁令我突然充满幻想 谁令我音韵脑际飘扬 撩动我内心爱情酝酿 为我拨开忧伤 找得失去乐畅 谁令我
仿似初恋再尝 我心中蕴藏 爱意千百丈
过滤后: 谁令我当晚举止失常 难自禁望君你能见谅 但觉万分紧张 皆因跟你遇上 谁令我突然充满幻想 谁令我音韵脑际飘扬 撩动我内心爱情酝酿 为我拨开忧伤 找得失去乐畅 谁令我仿似
初恋再尝 我心中蕴藏 爱意千百丈
分词结果前10个: ['谁', '令', '我', '当晚', '举止', '失常', '难', '自禁', '望君', '你']
✅ 成功处理,词数: 95, 有意义词数: 95
=== 处理第 4/19995 条记录 ===
处理歌曲: 刻板都市 - 杜德伟
原始歌词前100字符: ['床前仍然亮了暗灯,闹钟声叫得过分,迷迷糊糊又再转身,开始去再次做机器人。', '沿途红黄绿正变更,是交通灯说不要问,垂头无言习惯了等,给支配,给操纵
这命运。', '啊,机器似的发动,每个没意识的冲
格式处理后: 床前仍然亮了暗灯,闹钟声叫得过分,迷迷糊糊又再转身,开始去再次做机器人。 沿途红黄绿正变更,是交通灯说不要问,垂头无言习惯了等,给支配,给操纵这命运。 啊
,机器似的发动,每个没意识的冲,啊,心里似没有
过滤后: 床前仍然亮了暗灯,闹钟声叫得过分,迷迷糊糊又再转身,开始去再次做机器人。 沿途红黄绿正变更,是交通灯说不要问,垂头无言习惯了等,给支配,给操纵这命运。 啊,机
器似的发动,每个没意识的冲,啊,心里似没有
分词结果前10个: ['床前', '仍然', '亮', '了', '暗灯', ',', '闹', '钟声', '叫', '得']
✅ 成功处理,词数: 351, 有意义词数: 283
=== 处理第 5/19995 条记录 ===
处理歌曲: My Girl - 杜德伟
原始歌词前100字符: ['《My Girl》', '', '', '√Edited By CrazyXP√', "I\\'ve got sunshine on a cloudy day", "And when it\\'s
格式处理后: My Girl Edited By CrazyXP I\'ve got sunshine on a cloudy day And when it\'s cold outside I\'ve got t
过滤后: My Girl Edited By CrazyXP I've got sunshine on a cloudy day And when it's cold outside I've got the
分词结果前10个: ['my', 'girl', 'edited', 'by', 'crazyxp', "I've", 'got', 'sunshine', 'on', 'a']
✅ 成功处理,词数: 228, 有意义词数: 205
=== 处理第 6/19995 条记录 ===
处理歌曲: Love Is Love - 杜德伟
原始歌词前100字符: ["You don't have to touch it to know", 'Love is everywhere that you go', "You don't have to touch it
格式处理后: You don't have to touch it to know Love is everywhere that you go You don't have to touch it to feel
过滤后: You don't have to touch it to know Love is everywhere that you go You don't have to touch it to feel
分词结果前10个: ['you', "don't", 'have', 'to', 'touch', 'it', 'to', 'know', 'love', 'is']
✅ 成功处理,词数: 118, 有意义词数: 118
=== 处理第 7/19995 条记录 ===
处理歌曲: 爱人请你不要紧张 - 杜德伟
原始歌词前100字符: ['我偶尔独来独往', '只因为生活过于繁忙 想逛逛', '你何必那么紧张', '我从来都不曾有 背叛的思想 别乱想', '我爱你天经地义 地久又天长', '请相信 我的忧
郁 只是短暂', '爱人请你
格式处理后: 我偶尔独来独往 只因为生活过于繁忙 想逛逛 你何必那么紧张 我从来都不曾有 背叛的思想 别乱想 我爱你天经地义 地久又天长 请相信 我的忧郁 只是短暂 爱人请你不要
紧张 那个人只是玩伴 没有感情 没有
过滤后: 我偶尔独来独往 只因为生活过于繁忙 想逛逛 你何必那么紧张 我从来都不曾有 背叛的思想 别乱想 我爱你天经地义 地久又天长 请相信 我的忧郁 只是短暂 爱人请你不要紧张
那个人只是玩伴 没有感情 没有
分词结果前10个: ['我', '偶尔', '独来独往', '只', '因为', '生活', '过于', '繁忙', '想', '逛逛']
✅ 成功处理,词数: 206, 有意义词数: 206
=== 处理第 8/19995 条记录 ===
处理歌曲: 天长地久 - 杜德伟
原始歌词前100字符: ['你 对我来说', '是个最美的梦', '总是让我寄托', '和你迎着风', '带着我一直痴心的温柔', '让每一分钟都不会错过', '爱 天长地久', '有话想对你说', '你是
我的所有', '有
格式处理后: 你 对我来说 是个最美的梦 总是让我寄托 和你迎着风 带着我一直痴心的温柔 让每一分钟都不会错过 爱 天长地久 有话想对你说 你是我的所有 有你就有我 这世上只愿为
了你守侯 不再容易寂寞 在我生活中
过滤后: 你 对我来说 是个最美的梦 总是让我寄托 和你迎着风 带着我一直痴心的温柔 让每一分钟都不会错过 爱 天长地久 有话想对你说 你是我的所有 有你就有我 这世上只愿为了你
守侯 不再容易寂寞 在我生活中
分词结果前10个: ['你', '对', '我', '来说', '是', '个', '最美', '的', '梦', '总是']
✅ 成功处理,词数: 184, 有意义词数: 184
=== 处理第 9/19995 条记录 ===
处理歌曲: 爱不坏 - 杜德伟
原始歌词前100字符: ['你摇头要我的爱不坏', '还是要我别离开', '你摇头要我的爱不改', '还是要我别过来', '你要你的自由自在', 'Baby I cant read your mind', '你只是心摇摆',
格式处理后: 你摇头要我的爱不坏 还是要我别离开 你摇头要我的爱不改 还是要我别过来 你要你的自由自在 Baby I cant read your mind 你只是心摇摆 却是渴望爱 你从不怕伤害 最好
全场一起hi
过滤后: 你摇头要我的爱不坏 还是要我别离开 你摇头要我的爱不改 还是要我别过来 你要你的自由自在 Baby I cant read your mind 你只是心摇摆 却是渴望爱 你从不怕伤害 最好全场
一起hi
分词结果前10个: ['你', '摇头', '要', '我', '的', '爱', '不坏', '还是', '要', '我别']
✅ 成功处理,词数: 467, 有意义词数: 463
=== 处理第 10/19995 条记录 ===
处理歌曲: 这一双手 - 杜德伟
原始歌词前100字符: ['他一手捧你到处应酬 他施舍给你富有', '不必我工作没计较报酬', '', '没晚没夜 也要奋斗', '', '他珠光宝气叫你好奇 他供给你花花世界', '', '可是我只会
赠你爱情 再送你浪漫回
格式处理后: 他一手捧你到处应酬 他施舍给你富有 不必我工作没计较报酬 没晚没夜 也要奋斗 他珠光宝气叫你好奇 他供给你花花世界 可是我只会赠你爱情 再送你浪漫回味 抱歉我只得
这一对手 或者找不到辉煌成就 与你以心
过滤后: 他一手捧你到处应酬 他施舍给你富有 不必我工作没计较报酬 没晚没夜 也要奋斗 他珠光宝气叫你好奇 他供给你花花世界 可是我只会赠你爱情 再送你浪漫回味 抱歉我只得这一
对手 或者找不到辉煌成就 与你以心
分词结果前10个: ['他', '一手', '捧', '你', '到处', '应酬', '他', '施舍', '给', '你']
✅ 成功处理,词数: 192, 有意义词数: 192
=== 处理第 11/19995 条记录 ===
处理歌曲: 不走 - 杜德伟
原始歌词前100字符: ['挺著胸 勇敢的面對呼唏的風', '傷心總是帶不走痛', '有時候我覺得自己很沒用', '沉默 完完全全把你放在心中', '有太多的話想對你說面對你都說不出口', '眼
睜睜的看著你離開我', '我明
格式处理后: 挺著胸 勇敢的面對呼唏的風 傷心總是帶不走痛 有時候我覺得自己很沒用 沉默 完完全全把你放在心中 有太多的話想對你說面對你都說不出口 眼睜睜的看著你離開我 我明
白你有你的理由 你回頭笑笑的看我 我心中
过滤后: 挺著胸 勇敢的面對呼唏的風 傷心總是帶不走痛 有時候我覺得自己很沒用 沉默 完完全全把你放在心中 有太多的話想對你說面對你都說不出口 眼睜睜的看著你離開我 我明白你
有你的理由 你回頭笑笑的看我 我心中
分词结果前10个: ['挺著', '胸', '勇敢', '的', '面', '對', '呼', '唏', '的', '風']
✅ 成功处理,词数: 222, 有意义词数: 222
调试模式:只处理前10条记录
✅ 清理完成: 11 条有效记录 / 19995 条原始记录
Building tokenizer and vocabulary...
总token数: 2567
独特token数: 774
最常见的20个tokens:
'我': 107
'你': 85
'的': 76
',': 54
'i': 44
'you': 39
'to': 36
'要': 31
'me': 30
'love': 30
'爱': 28
'the': 28
'在': 24
'my': 22
'有': 21
'girl': 21
',': 21
'be': 20
'不': 19
'your': 18
文本样本:
样本1: 深情 的 人 在 夜里 扬着 脸 星光 闪烁 在 天边 耳语 喧哗 在 不眠 树影 间 灵魂 游走 夜 的 边缘 风中 的 真心 呼唤 有 谁 听见 水瓶 星座 有 透明 心愿 为 谁 永不 厌
倦 的...
样本2: i just want to be your everthing 杜德伟 edited by crazyxp for so long you and me been finding each othe...
样本3: 谁 令 我 当晚 举止 失常 难 自禁 望君 你 能 见谅 但觉 万分 紧张 皆 因 跟 你 遇上 谁 令 我 突然 充满 幻想 谁 令 我 音韵 脑际 飘扬 撩动 我 内心 爱情 酝酿 为 我
拨开...
✅ Tokenizer构建完成:
词汇表大小: 776
OOV token: <UNK>
词汇表前20个词:
'<UNK>': 1
'我': 2
'你': 3
'的': 4
',': 5
'i': 6
'you': 7
'to': 8
'要': 9
'me': 10
'love': 11
'爱': 12
'the': 13
'在': 14
'my': 15
'有': 16
'girl': 17
',': 18
'be': 19
'不': 20
=== 分词测试 ===
文本1: 深情 的 人 在 夜里 扬着 脸 星光 闪烁 在 天边 耳语 喧哗 在 不眠 树影 间 灵魂 游走 ...
序列1: [379, 4, 56, 14, 217, 380, 381, 218, 219, 14]...
解码1: 深情 的 人 在 夜里 扬着 脸 星光 闪烁 在 天边 耳语 喧哗 在 不眠 树影 间 灵魂 游走 ...
--------------------------------------------------
文本2: i just want to be your everthing 杜德伟 edited by cra...
序列2: [6, 75, 40, 8, 19, 21, 420, 421, 242, 243]...
解码2: i just want to be your everthing 杜德伟 edited by cra...
--------------------------------------------------
文本3: 谁 令 我 当晚 举止 失常 难 自禁 望君 你 能 见谅 但觉 万分 紧张 皆 因 跟 你 遇上 ...
序列3: [27, 80, 2, 433, 434, 435, 436, 437, 438, 3]...
解码3: 谁 令 我 当晚 举止 失常 难 自禁 望君 你 能 见谅 但觉 万分 紧张 皆 因 跟 你 遇上 ...
--------------------------------------------------
� 修复成功!
词汇表大小: 775
有效歌词数: 11
03
conda activate nlp_tf
如果电脑先前没配cudnn,还需要下载
选择transfomer开始训练

正常训练由于数据量很大,时间很久
demo版本快很多



GPU加速下


GPU下跑30轮





可视化训练过程

模型还需要优化参数,明显验证上效果不佳
tensorboard --logdir="C:\Users\user\Desktop\nlp\logs\tensorboard\train"
使用绝对路径访问

04
进行验证
进入logs目录
tensorboard --logdir="C:\Users\user\Desktop\nlp\logs\tensorboard\train"



生成验证数据

05
运行应用网站

注意,要在浏览器输入:http://localhost:7860

演示效果(图片、视频)