从0开始学习R语言--Day28--高维回归
我们一般处理的数据,都是样本数量远大于其特征数量,可用很多种回归方法;但当特征数量远大于样本量时,可能会因为出现无数多个完美解导致过拟合现象,也使得在计算时搜索最有特征子集的方法不再可行(因为计算量过大)。鉴于此,我们可以使用高维回归,该方法会对很多特征的系数做出限制,一是增加惩罚项,许多特征的系数为0,减少算法的计算量;二是用主成分回归的办法,先对数据进行降维,将特征限定在有限的范围内再去做回归。
以下是一个例子:
# 加载必要的包
library(glmnet) # 用于Lasso回归
library(ggplot2) # 用于可视化# 生成高维数据集
set.seed(123)
n <- 100 # 样本量
p <- 200 # 变量数(远大于n)# 生成设计矩阵X(100×200)
X <- matrix(rnorm(n * p), nrow = n, ncol = p)# 生成真实的系数向量(只有前5个变量有真实效应)
true_beta <- c(rep(3, 5), rep(0, p-5))# 生成响应变量 y = Xβ + ε
y <- X %*% true_beta + rnorm(n, sd = 2)# 将数据分为训练集和测试集
train <- sample(1:n, 70)
X_train <- X[train, ]
y_train <- y[train]
X_test <- X[-train, ]
y_test <- y[-train]# 使用交叉验证拟合Lasso模型
cv_fit <- cv.glmnet(X_train, y_train, alpha = 1) # alpha=1表示Lasso# 查看最优lambda值
best_lambda <- cv_fit$lambda.min
cat("最优lambda值:", best_lambda, "\n")# 绘制交叉验证误差
plot(cv_fit)# 使用最优lambda拟合最终模型
final_model <- glmnet(X_train, y_train, alpha = 1, lambda = best_lambda)# 查看非零系数的变量
selected_vars <- predict(final_model, type = "coefficients")
cat("选择的变量数量:", sum(selected_vars != 0) - 1, "\n") # 减去截距# 预测测试集
predictions <- predict(final_model, newx = X_test)# 计算测试集MSE
mse <- mean((predictions - y_test)^2)
cat("测试集MSE:", mse, "\n")# 可视化真实系数与估计系数
coef_df <- data.frame(Variable = 1:p,True = true_beta,Estimated = as.numeric(selected_vars[-1]) # 去掉截距
)ggplot(coef_df, aes(x = Variable)) +geom_point(aes(y = True, color = "真实值")) +geom_point(aes(y = Estimated, color = "估计值")) +scale_color_manual(values = c("真实值" = "red", "估计值" = "blue")) +labs(title = "真实系数与Lasso估计系数比较",y = "系数值",color = "类型") +theme_minimal()输出:
最优lambda值: 0.141299
选择的变量数量: 45
测试集MSE: 6.238843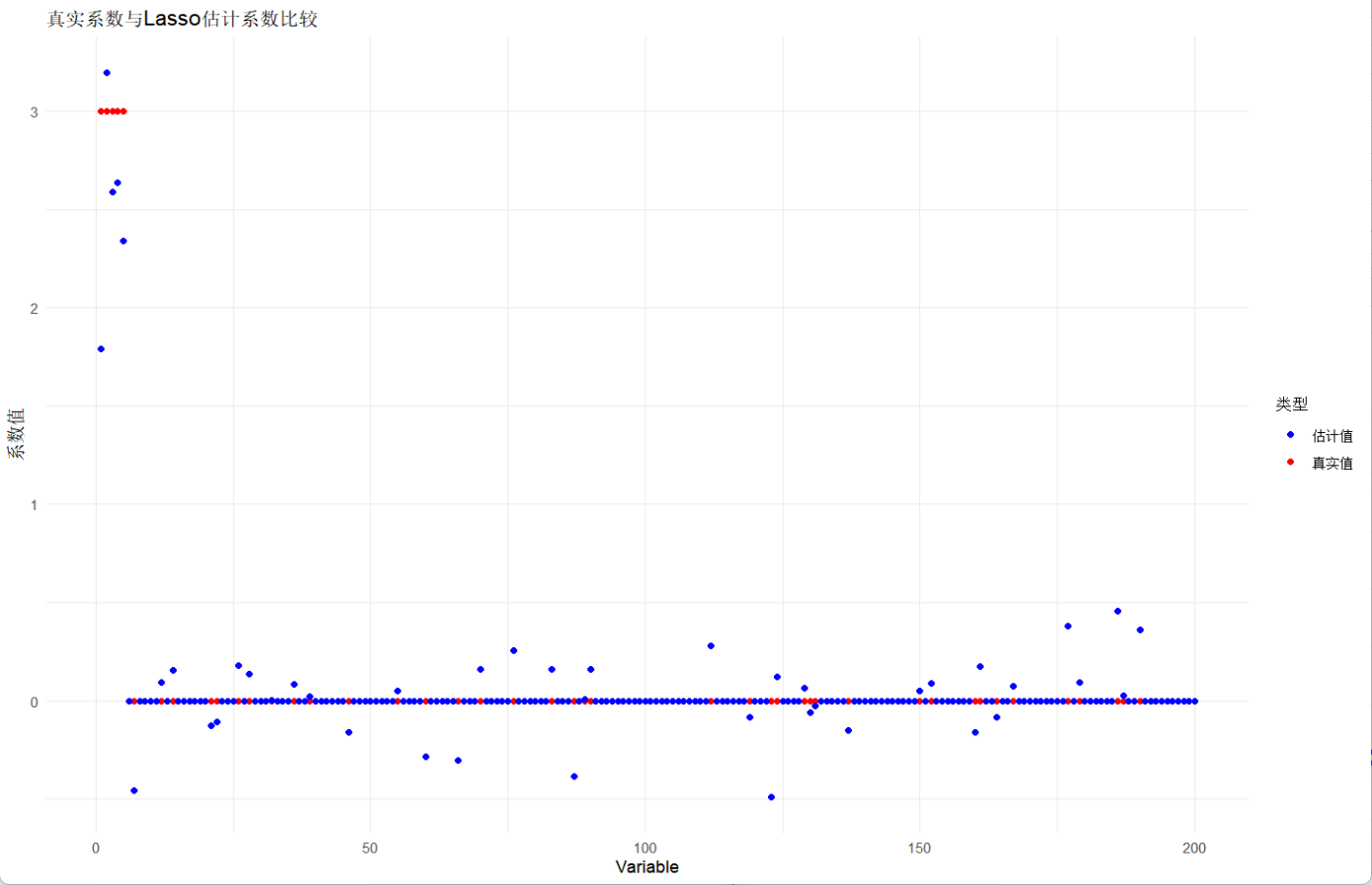
我的结果表明,有45个变量是有效的,但所画的图则表明只有前五个变量是有效的,其他变量的系数都是0,造成这个原因很可能是因为lambda不够大(惩罚值较小),所以才让模型引入了40个无关变量。