大模型之微调篇——指令微调数据集准备
写在前面
高质量数据的准备是微调大模型的重中之重,一些高质量的数据集可能远比模型性能更佳重要。
我是根据自己的数据照着B站up code花园LLaMA Factory 微调教程:如何构建高质量数据集?_哔哩哔哩_bilibili做的。
数据集格式
在LLaMA Factory中,支持Alpaca 格式和 ShareGPT 两种格式,详细可以自行去查查,下面是两个格式的示例。

Alpaca 数据格式

ShareGPT 数据格式
采用Easy Dataset制作数据集
Easy Dataset是一个专门创建大型语言模型数据集的程序。它能将行业领域的语料库转换为结构化的数据集。

安装
安装教程见官方文档https://docs.easy-dataset.com/
Easy Dataset工具使用
打开程序,然后创建项目

进入模型配置,这里我旋转qwen模型(主要是阿里大气,学生认证免费送300代金卷),注意需要配置对应平台的api key。


任务配置可以更具需求设置

提示词配置可以不做,如果生成的有问题在调整提示词。

文献处理,这里先选择模型,再选择需要处理的文献,然后就可以开始处理文献了,

可以查看右方的GA对,GA对可以参考https://zhuanlan.zhihu.com/p/1916488453228561713。主要意思就是针对不同群里设置的不同深度语气格式的数据集。


查看分割和领域分析数据是否生成合理,如果不合理需要人工干预

一切就绪之后开始提取问题
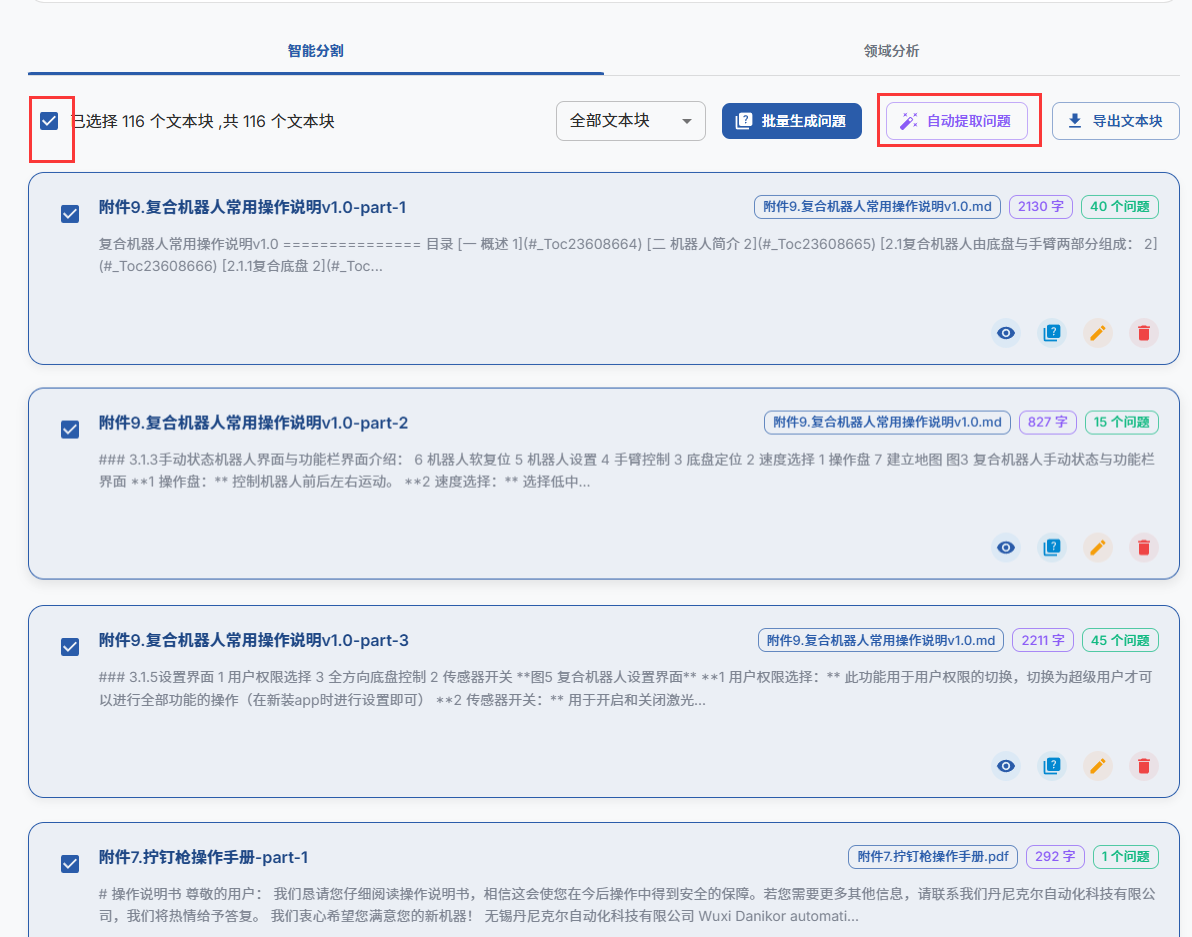
右上方有任务进行进度,整个过程都是并发运行,可以切换到其他界面操作。一些就绪之后进入问题管理界面查看问题,然后切换模型到推理效果好的deepseek-R1模型,就可以生成答案了.

然后等待生成。幸好deepseek便宜,一个小时才花5块钱,而且硅基流动也有学生认证,认证送50代金卷。

还能用数据蒸馏增加数据集,这个步骤等待时间较长,生成的数据集也多。

等数据生成结束之后,进入数据集管理界面,导出数据,这里可以导出在LLaMA Factory中使用,会得到一个配置文件。


进入这个文件路径,打开dataset_info文件发现就是LLaMA Factory要求的格式。


在LLaMA Factory直接将数据路径粘贴到数据集路径那里

最后配置好LLaMA Factory的参数就可以开始训练了。