Model 复现系列(二)ACT-Plus-Plus Mobile ALOHA
这篇博客用来复现 VLA 中的模型 ACT,这个模型可以算得上是整个 VLA 领域的鼻祖,尽管模型非常小也没使用到非常新颖的模块,但这是第一个在 VLA 领域中有实际作用的模型,也是大家能在很短时间内复现的模型,且对 GPU 的显存要求也不高。但要注意,源码中有很多工程的部分做的不是很好,建议按照这篇博客的顺序来。
这篇 paper 我也做过相应的读书笔记,有关这篇论文的链接如下:
- 官方 Github 仓库:https://github.com/MarkFzp/act-plus-plus
- 官方项目主页:https://mobile-aloha.github.io
- 原始论文链接:https://arxiv.org/abs/2401.02117
- 论文精读博客:https://blog.csdn.net/nenchoumi3119/article/details/147504821
【Note】:由于这个模型是非常基础的模型,因此我会从一个初学者的角度出发尽可能细致地进行复现官方 Github 仓库中的源码。

1. 准备工作
为了统一这篇博客以及后面的所有复现博客,默认你已经在实验电脑上安装了 conda 或者 miniconda,建议使用后者体量会小很多。
1.1 拉取源码与创建环境
首先要从 Github 从库中拉取他们的源码:
(base) $ git clone git@github.com:MarkFzp/act-plus-plus.git
然后创建一个虚拟 conda 环境,这里虽然可以使用更高的 python 版本,但最好还是和他们保持一致。
(bash) $ conda create -n aloha python=3.8.10
创建好环境后进入到代码仓库并激活虚拟环境:
(bash) $ conda activate aloha
源码中环境所依赖的库需要一条一条安装,我这里直接给你整理在一起,创建一个 requirements.txt 文件然后将下面的内容复制进去:
torchvision
torch
pyquaternion
pyyaml
rospkg
pexpect
mujoco==2.3.7
dm_control==1.0.14
opencv-python
matplotlib
einops
packaging
h5py
ipython
wandb
robomimic
diffusers
使用下面的命令安装依赖库:
(aloha) $ pip install -r requirements.txt
根据官方仓库介绍还需要安装 r2rd 的 diffusion-policy-mg 分支源码,从下面的官方仓库中拉取源码:
(aloha) $ git clone git@github.com:ARISE-Initiative/robomimic.git --recurse-submodules
进入这个目录安装依赖:
(aloha) $ cd robomimic
(aloha) $ git checkout diffusion-policy-mg
(aloha) $ pip install -v -e .
(aloha) $ cd act-plus-plus/detr
(aloha) $ pip install -e .
按照我的习惯会有一步抽查数据的操作,结合官方数据集中提供的 hdf5 格式数据集,这里还需要安装一个依赖库以对其进行解析,但这一步不是必要的:
(aloha) $ pip install h5py
1.2 修改 constants.py
做完上面的操作后还需要修改源码中的一处文件路径,打开 constants.py 文件,然后在搜索 DATA_DIR 变量,这个变量在文件头部附近:

将上面的 DATA_DIR 变量修改成 你的训练和验证数据集都要存放在这里,我这里的示例路径为 /gemini/code/act/datas;
【Note】:这个文件路径的空间一定要大,因为后面产生的数据会默认存在这个路径下。
1.3 修改 detr_vae.py
在源码 act-plus-plus/detr/models/detr_vae.py 中找到第 285 行的位置,将编码器由 build_transformer(args) 修改为 build_encoder(args):

[可选] 1.4 修改 imitate_episodes.py
这一步是可以跳过的,但需要确认以下条件是否满足:
- 你只打算在仿真环境中进行训练与评估,且不打算使用真机数据;
- 你的环境中没有安装 ROS;
在文件 act-plus-plus/imitate_episodes.py 文件中大约 596 行附近的 def train_bc() 函数中注释掉 #evaluation 中的两行:
def train_bc(...):...# evaluationif (step > 0) and (step % eval_every == 0):# first save then evalckpt_name = f'policy_step_{step}_seed_{seed}.ckpt'ckpt_path = os.path.join(ckpt_dir, ckpt_name)torch.save(policy.serialize(), ckpt_path)# 注释下面两行# success, _ = eval_bc(config, ckpt_name, save_episode=True, num_rollouts=10)# wandb.log({'success': success}, step=step)...
从整体上来看就是下面这个样子:

1.5 [可选] GPU 云服务器
如果你在数据生成和模型训练阶段都打算在 GPU 云服务器上完成,那么还需要安装一个库用来欺骗显卡输出到虚拟显示器上:
(alopha) $ sudo apt-get install xvfb
除了安装这个库以外在执行代码时也会涉及到一些特殊操作,后面使用时会提到。
2. 准备数据集
在数据集方面也有多种形式可选,下面的两种准备数据的方式 并不冲突,你可以两个方式都用也可以只选择一个。但要注意 2.3 节的生成方法只限于生成 仿真 数据,并且生成的数据类型有限。
如果你想要训练真机或者想要更丰富任务类型的仿真数据,那么 2.3 节的操作是不够的。我后面会补上多钟数据生成和采集方法,届时将打包成开源数据集发出来。
2.1 确认目录结构
为了后面更方便进行表述在这里需要确认一下目录结构,如果你的目录结构和我这存在差异也是可以的,但要记得在后面的时候使用正确的路径:
(aloha) $ tree.
├── act-plus-plus # act 源码
├── ckp # 模型检查点存放位置
├── datas # 数据文件夹
│ ├── gen_data # 就地生成的仿真数据
│ ├── real # 下载的真机数据
│ └── sim # 下载的仿真数据
└── robomimic # robomimic 源码
2.2 下载现成的数据集
在官方仓库中提供了仿真和真机的训练数据集,但在 Google Drive 网盘中,国内访问可能不太方便,我把四个数据包都下载好转移到我的网盘里:
- 仿真数据集:https://drive.google.com/drive/folders/1gPR03v05S1xiInoVJn7G7VJ9pDCnxq9O
- 真机数据集:https://drive.google.com/drive/folders/1FP5eakcxQrsHyiWBRDsMRvUfSxeykiDc
链接: https://pan.baidu.com/s/1-RHGAkf964QSHFSMh8eMjg?pwd=31hd 提取码: 31hd
这个网盘中的数据集包括了仿真(1.36 GB)和真机(51.05 GB)两个包:

【Note】:下载好数据集后要进行解压,可以进入到对应的目录后使用下面的命令解压当前路径下所有 .zip 结尾的文件:
(aloha) $ for file in *.zip; do unzip -o "$file"; done
仿真数据集抽查
此处抽查的是数据集中的 sim_insertion_human-20250617T161346Z-1-009.zip 直接解压后会得到 sim_insertion_human 文件夹:

进入文件夹后里面有四个文件:episode_6.hdf5、episode_12.hdf5、episode_14.hdf5、episode_15.hdf5 ,这四个数据集中都包含了 2 个数据标签 ["action", "observations"],前者是机械臂操作的动作序列,后者是观测值包括图像与传感器,如果对 .h5 格式数据不熟悉的话可以使用下面的脚本查看,这个和 python 的字典读写方式非常相似,但更加高效和方便:
import h5py
file_list = ["episode_6.hdf5", "episode_12.hdf5", "episode_14.hdf5", "episode_19.hdf5"]for file in file_list:with h5py.File(file, 'r') as f:print(f'File {file} contan {f.keys()}')
以文件 episode_6.hdf5 为例,一共包含 500 500 500 帧画面。其中 action 的每条数据长度均为 14 14 14 表示两个机械臂的关节位置 14 个关节值对应论文中的 action_chunk;observations 部分由三个组成 ['images', 'qpos', 'qvel'] 分别表示 顶部相机图像 top、两个机械臂当前姿态、两个机械臂当前关节速度。假设文件读取后标识符为 f,那么内部可用的数据维度如下所示:
f['actions']:shape=(500,14)f['observations']['qpos']:shape=(500,14)f['observations']['qvel']:shape=(500,14)f['observations']['top']:shape=(500,480,640,3)
那么解析这条数据并播放的代码如下:
import h5py
import numpy as np
import time
from matplotlib import pyplot as pltfile_path = "episode_6.hdf5"
frames = []with h5py.File(file_path, 'r') as f:for index in range(len(f["action"])):top_img = f["observations"]['images']['top'][index]frames.append(top_img)print('File parase done.')plt.ion()
fig, ax = plt.subplots()
img = ax.imshow(frames[0], vmin=0, vmax=255)
ax.axis('off')for frame in frames:img.set_data(frame)fig.canvas.draw()fig.canvas.flush_events()time.sleep(0.01) # 控制帧率plt.ioff()
plt.show()运行后结果如下:

【存在问题】真机数据集抽查
检查真机数据和检查仿真数据的步骤基本一致,这里以 aloha_mobile_wipe_wine-20250618T030030Z-1-003.zip 数据包中的 episode_2.hd5 样本为例,但要注意仿真和真机数据包中的元素和格式有些差别,主要多了很多关节,包括底盘关节,同时相机的标签有三个 cam_high、cam_left_wrist、cam_right_wrist,其 shape 均为 (1300, 26222) 。
【Note】:(2025年06月18日)我抽查了几个真机数据集的图像 shape 发现都不能转换成 3 通道的格式,后面我找到这部分的描述文档然后再补充进来,如果有人知道这个文档在哪也欢迎在评论区中补充。
2.3 生成仿真数据
官方仓库中提供了生成仿真数据的命令,在执行这个命令的时候就需要区分云服务器和实体机,但首先都要先进入到 act-plus-plus 文件夹中。
生成命令中有些通用参数源码中没有进行解释,我在这里补充说明一下:
--task_name:任务类型名,只能使用文件record_sim_episodes.py中提供的三个类型sim_transfer_cube_scripted、sim_insertion_scripted、sim_transfer_cube_scripted_mirror;--dataset_dir:存储生成数据的文件路径,在这篇博客中就是上面提到的datas/gen_data;--num_episodes:需要生成多少份数据,这个数每多 1 就需要额外 1 GB 的硬盘空间;--onscreen_render:是否将生成的数据实时渲染出来;
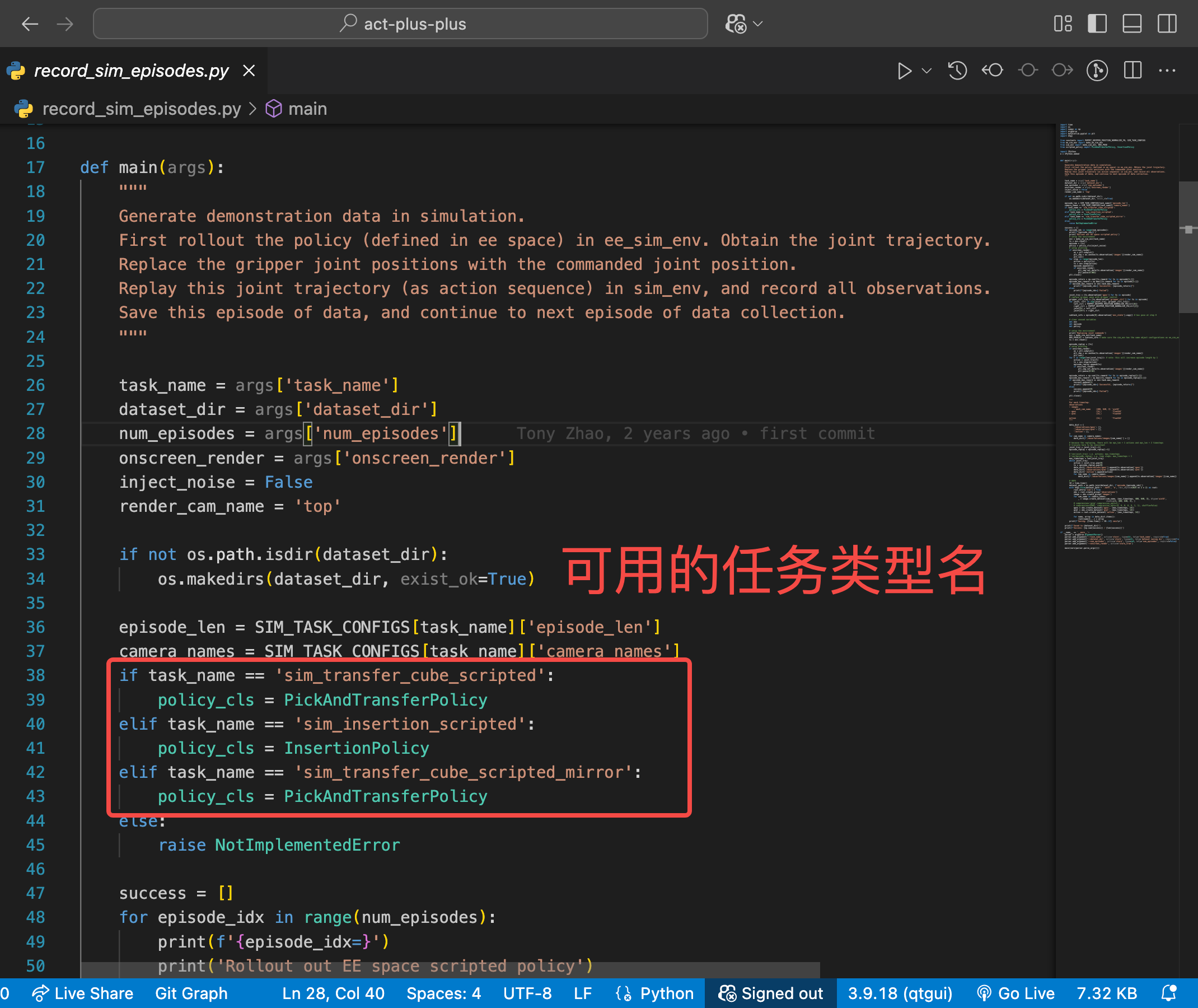
下面的代码含义是:生成 sim_transfer_cube_scripted 类型的任务数据 5 份并保存到 ../datas/gen_data 路径下:
【Note】:这个命令执行后并不会自动生成对应任务名的文件夹,而是会 直接覆盖 存放路径中的数据,因此要注意在生成完一个类型后手动整理下。
- GPU 云服务器
在命令前添加 xvfb-run -s "-screen 0 1400x900x24" 让渲染输出到空的地方:
(aloha) $ xvfb-run -s "-screen 0 1400x900x24" python3 record_sim_episodes.py \--task_name sim_transfer_cube_scripted \--dataset_dir "../datas/gen_data" \--num_episodes 5
- 实体机
实体机的话就可以直接运行,如果你想要实时查看当前生成的样本,那么在命令后面添加 --onscreen_render 即可:
(aloha) $ python3 record_sim_episodes.py \--task_name sim_transfer_cube_scripted \--dataset_dir "../datas/gen_data" \--num_episodes 5 \--onscreen_render
加上渲染后缀后就可以看见弹出的窗口:

【Note】:生成的速度取决于计算机配置,但无论你是在什么环境下生成的数据,都会有下面的输出结果且 episode_idx 值都是从 0 开始;
episode_idx=0
Rollout out EE space scripted policy
episode_idx=0 Successful, episode_return=630
Replaying joint commands
episode_idx=0 Successful, episode_return=653
Saving: 2.6 secs...episode_idx=4
Rollout out EE space scripted policy
episode_idx=4 Successful, episode_return=621
Replaying joint commands
episode_idx=4 Successful, episode_return=642
Saving: 2.8 secsSaved to ../datas/gen_data
Success: 5 / 5
现在查看文件夹 datas/gen_data 就会看到生成了 5 个数据包:
(aloha) $ ll datas/gen_data
total 5.2G
drwxr-xr-x 2 root root 135 Jun 18 19:57 ./
drwxr-xr-x 5 root root 58 Jun 18 19:09 ../
-rw-r--r-- 1 root root 1.1G Jun 18 20:05 episode_0.hdf5
-rw-r--r-- 1 root root 1.1G Jun 18 20:06 episode_1.hdf5
-rw-r--r-- 1 root root 1.1G Jun 18 20:07 episode_2.hdf5
-rw-r--r-- 1 root root 1.1G Jun 18 20:08 episode_3.hdf5
-rw-r--r-- 1 root root 1.1G Jun 18 19:57 episode_4.hdf5
抽查生成结果
生成完的仿真数据可以用上面我提供的脚本进行抽查,也可以使用官方教程中的脚本抽查,这里演示下他们的脚本功能。此时不用去分 GPU 云服务器还是实体机,因为脚本中不涉及调用 GUI 的部分,下面的命令中有两个参数需要注意:
--dataset_dir:上一步生成数据存放的位置;--episode_idx:你要抽查数据的索引号;
(aloha) $ python3 visualize_episodes.py \--dataset_dir "../datas/gen_data" \--episode_idx 0Saved video to: ../datas/gen_data/episode_0_video.mp4
Saved qpos plot to: ../datas/gen_data/episode_0_qpos.png
执行后会在 --dataset_dir 路径下生成对应文件的关节曲线图和视频,这里就是 episode_0_qpos.png 和 episode_0_video.mp4:

得到的是一个三视角的视频:

3. 仿真数据训练
3.1 使用生成的数据训练
【Note】:如果你确定需要将某个任务下生成的仿真数据作为生产条件,那么一定要在上面生成的步骤出多生成一些样本,示例中的 5 是远远不够的。
实际上不仅可以用上面提到的数据生成和下载的仿真数据进行训练,你也可以在 mujoco 中采集更丰富的仿真数据进行训练,只要你的数据格式和真机训练脚本中的数据格式相同即可。
这里由于原始代码中写死了数据读取路径,因此这里需要将之前生成的数据文件夹按照任务类型进行改名,这里就是 sim_transfer_cube_scripted:
(aloha) $ mv datas/gen_data datas/sim_transfer_cube_scripted
此时你的文件结构应该如下所示:
.
├── act-plus-plus # 源码
├── ckp # 检查点存放位置
├── datas
│ ├── real
│ ├── sim
│ └── sim_transfer_cube_scripted # 刚才重命名的文件夹
└── robomimic
执行模型训练:
(aloha) $ python3 imitate_episodes.py \--task_name sim_transfer_cube_scripted \--ckpt_dir "../ckp" \--policy_class ACT \--kl_weight 1 \--chunk_size 10 \--hidden_dim 512 \--batch_size 1 \--dim_feedforward 3200 \--lr 1e-5 \--seed 0 \--num_steps 2000
在执行后会有下面的提示,这里不去使用 wandb 就直接输入 3 即可:
(aloha) $ ...
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice:
由于整个模型的参数量很小,因此对 GPU 的资源占用率也仅有 0.4 GB:

训练完成后终端会显示如下信息:
100%|██████████████████████████████████████████████████████| 2001/2001 [25:03<00:00, 1.33it/s]
Training finished:
Seed 0, val loss 0.199436 at step 2000
Best ckpt, val loss 0.199436 @ step2000
wandb:
wandb:
wandb: Run history:
wandb: kl █▂▂▂▂▁▂▂▁▂▁▂▁▁▁▂▁▁▂▂▁▁▁▁▁▁▂▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: l1 ▄█▅▆▃▃▃▄▄▂▃▂▂▂▂▃▂▂▂▃▃▂▂▂▂▂▂▂▂▂▁▂▂▂▂▂▃▂▂▂
wandb: loss █▇▅▄▄▃▄▅▃▄▂▃▃▂▄▃▂▂▂▂▃▃▃▂▂▃▃▂▂▃▃▂▂▂▂▃▂▂▂▁
wandb: success ▁▁█▁
wandb: val_kl █▁▁▁▁
wandb: val_l1 █▂▁▁▁
wandb: val_loss █▁▁▁▁
wandb:
wandb: Run summary:
wandb: kl 0.25768
wandb: l1 0.12069
wandb: loss 0.37838
wandb: success 0
wandb: val_kl 0.05493
wandb: val_l1 0.14451
wandb: val_loss 0.19944
wandb:
wandb: You can sync this run to the cloud by running:
wandb: wandb sync /gemini/code/act/act-plus-plus/wandb/offline-run-20250618_212908-qmr5tkv8
wandb: Find logs at: ./wandb/offline-run-20250618_212908-qmr5tkv8/logs
然后用来保存模型检查点的问价夹 ckp 会有以下内容:
(aloha) $ ll ckp/
total 2.8G
drwxr-xr-x 2 root root 4.0K Jun 18 21:54 ./
drwxr-xr-x 6 root root 84 Jun 18 21:22 ../
-rw-r--r-- 1 root root 695 Jun 18 21:29 config.pkl
-rw-r--r-- 1 root root 23K Jun 18 21:29 dataset_stats.pkl
-rw-r--r-- 1 root root 406M Jun 18 21:54 policy_best.ckpt
-rw-r--r-- 1 root root 406M Jun 18 21:54 policy_last.ckpt
-rw-r--r-- 1 root root 406M Jun 18 21:29 policy_step_0_seed_0.ckpt
-rw-r--r-- 1 root root 406M Jun 18 21:41 policy_step_1000_seed_0.ckpt
-rw-r--r-- 1 root root 406M Jun 18 21:48 policy_step_1500_seed_0.ckpt
-rw-r--r-- 1 root root 406M Jun 18 21:54 policy_step_2000_seed_0.ckpt
-rw-r--r-- 1 root root 406M Jun 18 21:35 policy_step_500_seed_0.ckpt
-rw-r--r-- 1 root root 230 Jun 18 21:41 result_policy_step_1000_seed_0.txt
-rw-r--r-- 1 root root 237 Jun 18 21:48 result_policy_step_1500_seed_0.txt
-rw-r--r-- 1 root root 230 Jun 18 21:54 result_policy_step_2000_seed_0.txt
-rw-r--r-- 1 root root 230 Jun 18 21:35 result_policy_step_500_seed_0.txt
3.2 使用下载的数据训练
和使用生成的数据进行训练操作基本一致,只要你在下载那一步将压缩包解压完成,这里以 sim_transfer_cube_scripted 数据为例,解压后一共有 18 GB 的数据:

将解压出来的数据拷贝到上一级的目录 datas 中:
(aloha) $ cp -r datas/sim/sim_transfer_cube_scripted datas/
然后执行训练命令:
(aloha) $ python3 imitate_episodes.py \--task_name sim_transfer_cube_scripted \--ckpt_dir "../ckp" \--policy_class ACT \--kl_weight 1 \--chunk_size 10 \--hidden_dim 512 \--batch_size 1 \--dim_feedforward 3200 \--lr 1e-5 \--seed 0 \--num_steps 2000
3.3 评估训练结果
使用下面的命令评估训练效果,这个命令执行后回去自动找到最新的 ckp/policy_last.ckpt 这个检查点。这里作者在工程化上做的也不是特别好,因为默认会使用训练集中数据进行评估,当然也可以手动移动下 sim_transfer_cube_scripted 中的数据,让模型能在新的数据集上评估:
如果你在实体机上想要实时可视化动作,可以在末尾再加上 --onscreen_render。
(aloha) $ python3 imitate_episodes.py \--eval \--task_name sim_transfer_cube_scripted \--ckpt_dir "../ckp" \--policy_class ACT \--kl_weight 1 \--chunk_size 10 \--hidden_dim 512 \--batch_size 1 \--dim_feedforward 3200 \--lr 1e-5 \--seed 0 \--num_steps 20 \
最终你会看到如下输出:

上面的输出中你需要关注的就是最后一行,因为上面的训练步骤中给的 --num_steps 太小加之生成的数据集总量也不大,因此成功率基本为 0:
Warning: step duration: 0.083 s at step 399 longer than DT: 0.02 s, culmulated delay: 25.018 s
Avg fps 12.02865618188396
Rollout 9
episode_return=0, episode_highest_reward=0, env_max_reward=4, Success: FalseSuccess rate: 0.0
Average return: 0.0Reward >= 0: 10/10 = 100.0%
Reward >= 1: 0/10 = 0.0%
Reward >= 2: 0/10 = 0.0%
Reward >= 3: 0/10 = 0.0%
Reward >= 4: 0/10 = 0.0%policy_last.ckpt: success_rate=0.0 avg_return=0.0
我新建了一个 --num_steps 40000, --batch_size 10 的训练任务,使用了生成数据的方式创建了 14 组样本,最终得到的结果如下,如果你想要模型有更高的性能可以用更大的训练样本数:

模型检查点已经放在网盘中 checkpoint-40000 这个文件夹中。
4. 真机环境操作
真机部分使用的是松灵的具身机器人 mobile aloha,虽然没有在他们官网中找到对应的产品介绍,但他们提供了可以进行仿真的完整代码仓库:https://github.com/agilexrobotics/mobile_aloha_sim。
【Note】:后面我做完实验后会在这里补充上,包括如何在 Rviz 中同步显示机械臂关节以及采集数据和部署模型的内容。