【大模型:知识库管理】--MinerU本地部署
目录
1.MinerU--定义
2.MinerU--功能
3.MinerU--部署
3.1.🔧本地部署系统要求
3.2.下载源码
3.3.安装magic-pdf
3.4.docker搭建
3.5.启动!
1.MinerU--定义
MinerU:矿工
MinerU是上海人工智能实验室OpenDataLab团队推出的开源智能数据提取工具,专注于复杂PDF文档的高效解析与提取。MinerU能将包含图片、公式、表格等元素的多模态PDF文档转化为易于分析的Markdown格式,支持从网页和电子书中提取内容,提高AI语料准备效率。MinerU具备高精度的PDF模型解析工具链,支持多种输入模型,自动识别乱码,保留文档结构,转换公式为LaTex,适用于学术、财务、法律等多个领域,支持CPU和GPU,兼容Windows/Linux/Mac平台,性能卓越。
官网地址:跳转提示-稀土掘金


更新动态:

2.MinerU--功能
- PDF到Markdown转换:将包含多种内容类型的PDF文档转换为结构化的Markdown格式,便于进一步的编辑和分析。
- 多模态内容处理:能识别和处理PDF中的图像、公式、表格和文本等多种内容。
- 结构和格式保留:在转换过程中,保留原始文档的结构和格式,如标题、段落和列表。
- 公式识别与转换:特别针对数学公式,能识别并转换成LaTeX格式,方便学术交流和技术文档使用。
- 干扰元素去除:自动删除页眉、页脚、脚注和页码等非内容元素,净化文档信息。
- 乱码识别与处理:自动识别并纠正PDF文档中的乱码,提高信息提取的准确性。
- 高质量解析工具链:集成了先进的PDF解析工具,包括布局检测、公式检测和光学字符识别(OCR),确保提取结果的高准确度。
技术路线总结:
| 处理阶段 | 关键技术与方法 | 主要功能/输出 |
|---|---|---|
| 文档分类预处理 | - 类型识别(文本型/图层型/扫描版) - 乱码检测、扫描文档识别 | 分类后的PDF文档及预处理标记(如乱码位置、扫描标识) |
| 模型解析与内容提取 | ||
| - 布局检测 | LayoutLMv3等深度学习模型 | 识别图像、表格、标题、文本区域及其坐标 |
| - 公式检测 | 自研YOLOv8模型 | 区分行内公式和行间公式的位置 |
| - 公式识别 | 自研UniMERNet模型 | 公式转换为LaTeX格式 |
| - OCR | PaddleOCR等技术 | 提取文本内容 |
| 管线处理 | - 块顺序确定 - 无用元素删除 - 版面排序拼装 - 坐标修复/高iou处理等后处理 | 结构化的文档内容(按阅读顺序排列的文本、表格、公式等) |
| 输出格式转换 | 中间态格式(middle-json) | 支持Layout/Span/Markdown/Content list等多种输出格式 |
| 质检与优化 | - 自测评测集检测 - 可视化质检工具人工标注 | 模型效果评估与优化反馈,提升提取准确性 |
- 项目官网:opendatalab.com/OpenSourceT…
- GitHub仓库:github.com/opendatalab…
- HuggingFace模型库:huggingface.co/wanderkid/P…
- 魔搭社区模型库:www.modelscope.cn/models/wand…
3.MinerU--部署
官方文档:https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
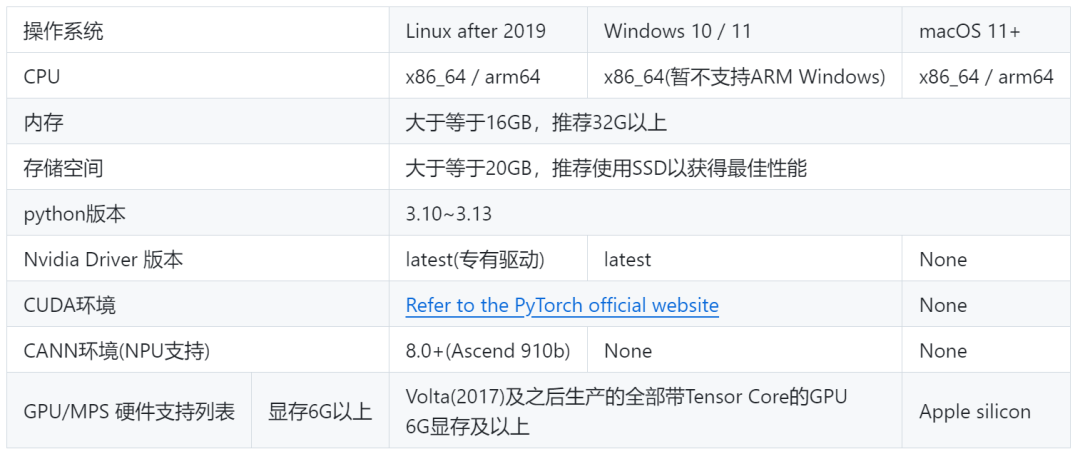
3.1.🔧本地部署系统要求
● Python 3.10~3.13
● Conda(包管理器)
GPU加速要求(可选)
● NVIDIA显卡(显存≥6GB)
基础环境配置推荐:
3.2.下载源码
git clone https://github.com/opendatalab/MinerU.git
cd Mineru 
3.3.安装magic-pdf
需要conda版本:
![]()
创建虚拟环境mineru:
conda create -n mineru python=3.10
激活这个环境:(先初始化终端)
conda init powershell
cd "D:\Anaconda3\envs"conda activate mineru前面出现mineru就可以了:

在虚拟环境下面下载包
pip install -U "magic-pdf[full]" --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple
3.4.docker搭建
1. 从modelscope下载模型(推荐)
官方地址:魔搭社区
下载wget:Index of /misc/wget/releases ,加入环境变量.
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/china/Dockerfile
docker build -t mineru-sglang:latest -f Dockerfile . 使用 Docker Compose 启动:
使用 Docker Compose 启动:
cd "D:\MinerU\docker"
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/compose.yaml
docker compose -f compose.yaml up -dDockerfile默认使用lmsysorg/sglang:v0.4.7-cu124作为基础镜像,如有需要,您可以自行修改为其他平台版本。
3.5.启动!
mineru --helpUsage: mineru [OPTIONS]
Options:
-v, --version 显示版本并退出
-p, --path PATH 输入文件路径或目录(必填)
-o, --output PATH 输出目录(必填)
-m, --method [auto|txt|ocr] 解析方法:auto(默认)、txt、ocr(仅用于 pipeline 后端)
-b, --backend [pipeline|vlm-transformers|vlm-sglang-engine|vlm-sglang-client]
解析后端(默认为 pipeline)
-l, --lang [ch|ch_server|... ] 指定文档语言(可提升 OCR 准确率,仅用于 pipeline 后端)
-u, --url TEXT 当使用 sglang-client 时,需指定服务地址
-s, --start INTEGER 开始解析的页码(从 0 开始)
-e, --end INTEGER 结束解析的页码(从 0 开始)
-f, --formula BOOLEAN 是否启用公式解析(默认开启,仅 pipeline 后端)
-t, --table BOOLEAN 是否启用表格解析(默认开启,仅 pipeline 后端)
-d, --device TEXT 推理设备(如 cpu/cuda/cuda:0/npu/mps,仅 pipeline 后端)
--vram INTEGER 单进程最大 GPU 显存占用(仅 pipeline 后端)
--source [huggingface|modelscope|local]
模型来源,默认 huggingface
--help 显示帮助信息
MinerU 默认在首次运行时自动从 HuggingFace 下载所需模型。若无法访问 HuggingFace,可通过以下方式切换模型源:
切换至 ModelScope 源
mineru -p <input_path> -o <output_path> --source modelscope模型下载地址:C:\Users\asus\.cache\modelscope\hub\models



加速:
mineru -p <input_path> -o <output_path> -b vlm-sglang-engine