LangChain实践11-问答
加载向量数据库
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/matplotlib/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding)
print(vectordb._collection.count())
question = "这节课的主要话题是什么"
docs = vectordb.similarity_search(question,k=3)
len(docs)

构造检索式问答链
# 使用 ChatGPT3.5,温度设置为0
from langchain.chat_models import ChatOpenAI
# 导入检索式问答链
from langchain.chains import RetrievalQA
# 声明一个检索式问答链
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
# 可以以该方式进行检索问答
question = "这节课的主要话题是什么"
result = qa_chain({"query": question})
print(result["result"])

深入探究检索式问答链
在获取与问题相关的文档后,我们需要将文档和原始问题一起输入语言模型,生成回答。默认是合并所 有文档,一次性输入模型。但存在上下文长度限制的问题,若相关文档量大,难以一次将全部输入模 型。针对这一问题,本章将介绍 MapReduce 、Refine 和 MapRerank 三种策略。
MapReduce 通过多轮检索与问答实现长文档处理
Refine 让模型主动请求信息
MapRerank 则通过问答质量调整文档顺序。
基于模板的检索式问答链
# 中文版
from langchain.prompts import PromptTemplate
# Build prompt
template = """使用以下上下文片段来回答最后的问题。如果你不知道答案,只需说不知道,不要试图编造
答案。答案最多使用三个句子。尽量简明扼要地回答。在回答的最后一定要说"感谢您的提问!"
{context}
问题:{question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
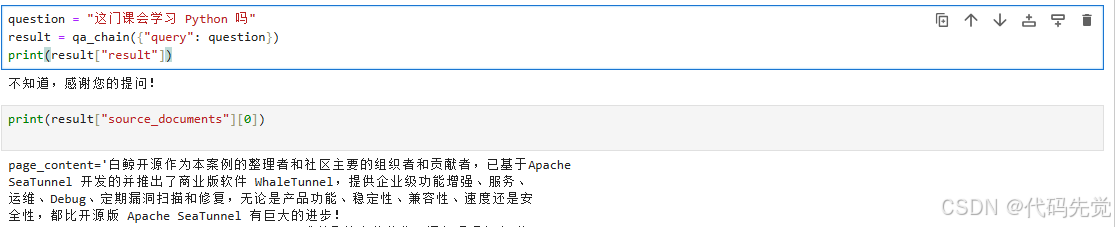
question = "这门课会学习 Python 吗"
result = qa_chain({"query": question})
print(result["result"])
print(result["source_documents"][0])
基于 MapReduce 的检索式问答链
在 MapReduce 技术中,首先将每个独立的文档单独发送到语言模型以获取原始答案。然后,这些答案 通过最终对语言模型的一次调用组合成最终的答案。虽然这样涉及了更多对语言模型的调用,但它的优 势在于可以处理任意数量的文档。
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="map_reduce"
)
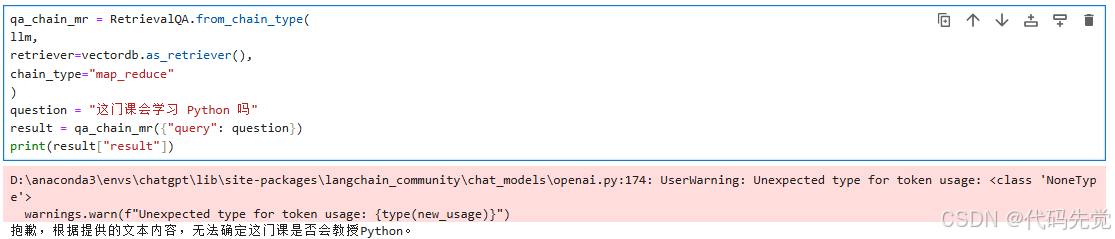
question = "这门课会学习 Python 吗"
result = qa_chain_mr({"query": question})
print(result["result"])
基于 Refine 的检索式问答链
我们还可以将链式类型设置为 Refine ,这是一种新的链式策略。Refine 文档链类似于 MapReduce ,对 于每一个文档,会调用一次 LLM。但改进之处在于,最终输入语言模型的 Prompt 是一个序列,将之前 的回复与新文档组合在一起,并请求得到改进后的响应。因此,这是一种类似于 RNN 的概念,增强了上 下文信息,从而解决信息分布在不同文档的问题。 例如第一次调用,Prompt 包含问题与文档 A ,语言模型生成初始回答。第二次调用,Prompt 包含第一 次回复、文档 B ,请求模型更新回答,以此类推。
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="refine"
)
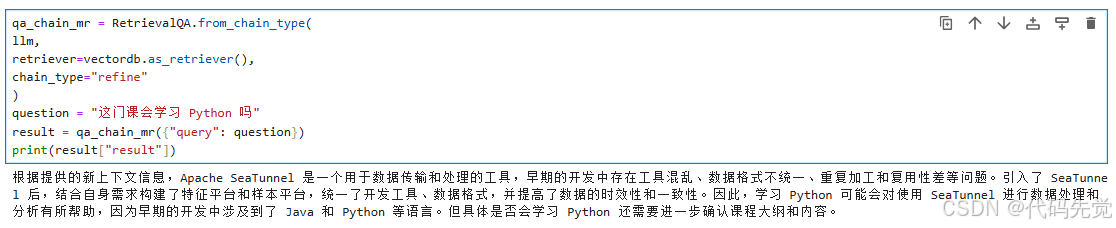
question = "这门课会学习 Python 吗"
result = qa_chain_mr({"query": question})
print(result["result"])
实验:状态记录
让我们在这里做一个实验。我们将创建一个 QA 链,使用默认的 stuff qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
question = "这门课会学习 Python 吗?"
result = qa_chain({"query": question})
print(result["result"])
question = "这些文本片段提到什么语言了"
result = qa_chain({"query": question})
result["result"]

可以看到,它不记得之前的问题或之前的答案。为了实现 这一点,我们需要引入内存,这是我们将在下一节中讨论的内容。