MySQL知识小结(二)
一、MySQL主从复制原理
1.基本原理
MySQL主从复制是基于二进制日志异步复制过程,主要涉及到了三个核心线程
- 主从Binlog Dump线程:将主库的binlog事件发生给从库
- 从库I/O线程:将主库的binlog日志保存为中继日志
- 从库SQL线程:执行中继日志的SQL语句
具体执行的细节如下
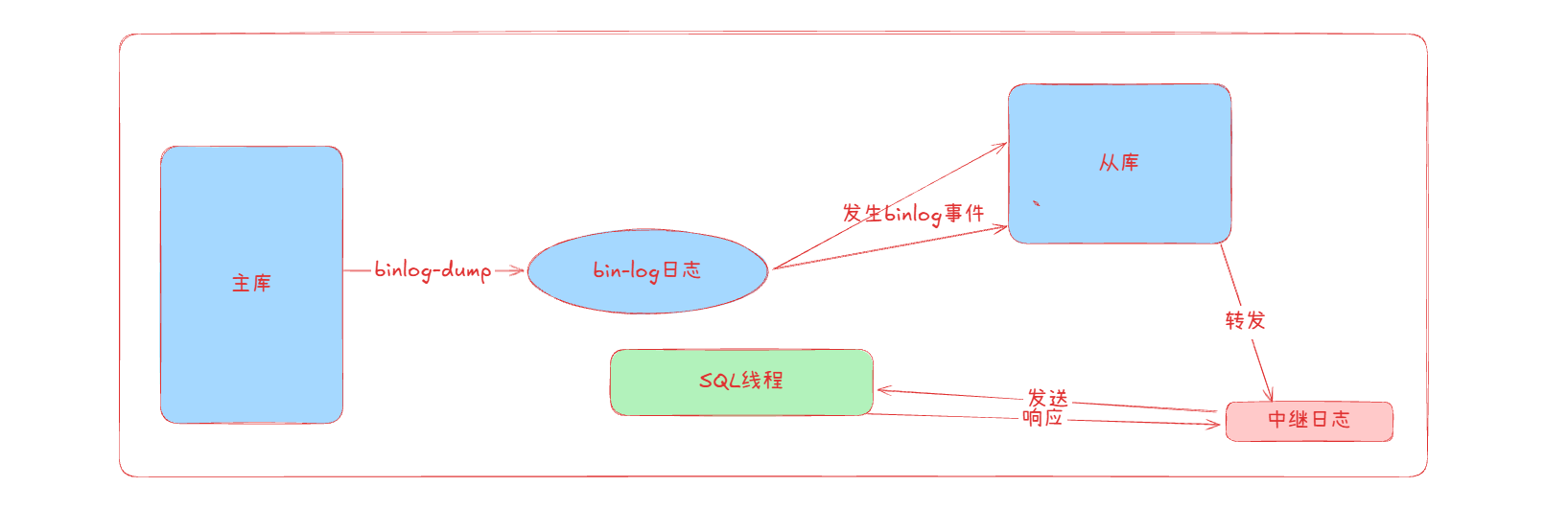
2.复制流程
- 主库记录了所有数据更改到二进制日志(binlog)
- 从库I/O线程连接主库,请求了binlog内容
- 主库的BinlogDump线程发送binlog内容到从库
- 从库将接收到的binlog内容写入到中继日志
- 从库读取中继日志并存取相应的SQL语句
3.MySQL复制特性
- 事务写集(writeset) :提高并行复制效率
- 二进制日志组提交:提高并发复制性能
- clone Plugin:快速创建从库的方式
- 性能提升:比5.7旧版本复制性能提升30%以上
二、配置文件中参数解析
1.必要配置参数
[mysqld]
server-id = 1 # 唯一服务器ID,主从必须不同
log-bin = mysql-bin # 启用二进制日志
binlog_format = mixed # 开启binllog日志(ROW/STATEMENT/MIXED)
2.可选参数
binlog_row_image = FULL # 记录完整的行数据
sync_binlog = 1 # 每次事务提交同步binlog磁盘
expire_log_day = 7 # binlog保留天数
binlog_cache_size = 1M # binlog缓存大小
max_binlog_size = 100 # 单个binlog文件大小3.非复制相关参数
文件参数中的其他参数如key_buffer_size、table_open_cache等等都属于性能调优参数,与主从复制无关,可根据实际服务器配置参数
三、主从复制实战解析
1.环境部署
| 角色 | IP地址 | 主机名 |
| Master | 10.2.53.5 | mysql-master |
| Slave | 10.2.53.6 | mysql-slave |
2.Master主节点部署(10.2.53.5)
环境配置文件如下:
[client]
socket=/var/run/mysqld/mysqld.socket # 客户端需与服务器一致
#gtid_mode=on
#enforce_gtid_consistency=ON[mysqld]
port=3306
socket=/var/run/mysqld/mysqld.socket # 客户端需与服务器一致
server-id = 1
log-bin = mysql-bin # 开启二进制日志
binlog-format = ROW # MySQL默认采用的是ROW模式
binlog_row_image = FULL # 记录完整的行数据
sync_binlog = 1 # 每次事务提交都同步binlog磁盘# 从服务器更新记录到自己的二进制文件
log-slave-updates = ON
# 二进制日志保留天数
expire_log_days = 7执行步骤:
1.修改文件后重启MySQL服务
systemctl restart mysqld2.创建复制专有用户
CREATE USER 'repl'@'10.2.53.%' IDENTIFIED WITH mysql_native_password BY 'Repl@1234';
#用来设置MySQL主从复制的权限授予命令
#GRANT REPLICATION SLAVE 授予复制从库所需的特殊权限,允许账号从主库读取二进制日志(binglog)
#ON *.* 指定权限范围所有数据库的所有表
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'10.2.53.%';
FLUSH PRIVILEGES;3.查看主库状态,记录File和PosItionz值
SHOW MATER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 785 | | | |
+------------------+----------+--------------+------------------+-------------------+
3.Slave节点配置(10.2.53.6)
环境配置文件如下:
[client]
port=3306
socket=/var/run/mysqld/mysqld.sock #客户端配置需与服务器一致
[mysqld]
port=3306
socket=/var/run/mysqld/mysqld.sock
server-id=2 #从库的唯一ID
relay-log=mysql-relay-bin #中继日志文件名前缀
log-slave-updates=ON #从库是否记录自己的二进制文件 是就是ON 否就是OFF
read-only=ON #从库设为只读执行步骤:
1.修改配置文件后重启MySQL
systemctl restart mysqld 2.配置复制链(依据主库中的File和position)
CHANGE MASTER TO
MASTER_HOST='192.168.101.134',
MASTER_USER='repl',
MASTER_PASSWORD='Repl@1234',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=785;
如果配置完成之后出现了报错:
ERROR 3021 (HY000): This operation cannot be performed with a running replica io thread; run STOP REPLICA IO_THREAD FOR CHANNEL '' first.
解决方法如下:
mysql>stop slave3.启动复制
start slave;4.检查复制的状态
## 查询SLAVE运行状态
SHOW SLAVE STATUS\G
## 检查如下两个配置状态情况
Slave_IO_Running: YesSlave_SQL_Running: Yes4.验证主从复制
创建测试文件
CREATE DATABASE repl_test;
USE repl_test;
CREATE TABLE test_table(id INT PRIMARY KEY AUTO_INCREMENT, data VARCHAR(100));
INSERT INTO test_table(data) VALUES('Master data');
具体的执行过程如下:
创建数据库名称 repl_test
mysql> CREATE DATABASE repl_test;
Query OK, 1 row affected (0.01 sec)
使用这个数据库
mysql> USE repl_test;
Database changed
创建表 test_table
mysql> CREATE TABLE test_table(id INT PRIMARY KEY AUTO_INCREMENT, data VARCHAR(100));
Query OK, 0 rows affected (0.01 sec)
向表里面插入数据
mysql> INSERT INTO test_table(data) VALUES('Master data');
Query OK, 1 row affected (0.02 sec)
在从库中使用如下查询语句
SELECT * FROM repl_test.test_table;+----+-------------+
| id | data |
+----+-------------+
| 1 | Master data |
+----+-------------+
1 row in set (0.00 sec)5.主从内容补充
-
补充使用命令
## 查看主节点日志
show master status;## 显示日志
show binary logs;## 刷新日志
flush binary logs## 查看已创建的用户
SELECT User, Host FROM mysql.user;
若SHOW SLAVE STATUS无输出(检查从库是否配置)
首先需要初始化主库,主要通过master_log_pos选项来进一步确定主库值,具体初始化帮助如下:
a.从主库中锁表并获取当前位置情况
FLUSH TABLES WITH READ LOCK;
SHOW MASTRE STATUS; --记录了file和position值b.备份数据后解锁
UNLOCK TABLES;
6.MySQL主从复制错误排查
场景分析:在MySQL集群同步生产环境中,如主从服务器之间的网络通信较差或数据库中数据量突然增大,那么就容易导致MySQL主从复制延长的情况,一旦产生了延长,那么必然会导致主库服务器宕机,从而影响到达从服务器中的数据,重新启动从服务器,会导致主从复制的同步关系
解决方式如下:
忽略错误,继续同步
此方法主要针对数据内容相差不大,数据可以不完全统一的情况
首先需要在Master 执行如下SQL,将数据库设置为全局多锁
FLUSH TABLE WITH READ LOCK;
set global sql_slave_skip_counter =1;Slave端停止Slave I/O线程及SQL线程,同时将同步SQL的错误跳过一次,跳过会导致数据不一致,最后启动从库 使用命令
START SLAVE主要报错情况如下以及解决步骤:
## 1.主键冲突
Last_Error:Could not executewrite_rows event on table db.tab1;Duplicate entry '123' for key 'primary'## 2.数据不一致Last_Error:Could not executeUpdate_rows event on table db.tb1;Can't find recored in 'tb1'## 3.临时性错误Last_Error:Query caused different errors on master and slave一旦碰到上面的错误之后完整的操作流程## 1.查看错误信息show slave status\g## 2.停止复制线程stop slave## 3.跳过错误事件set global sql_slave_skip_counter=1;## 4.重启复制start slave;## 5.验证状态show slave status\g检查 Slave_IO_Running: Yes 和 Slave_SQL_Running: Yes 的这个状态四、CGI与FastCGI概念解析
CGI即“公共网关接口”,是一个将HTTP服务器与本机或其他机器进行通信的一个工具,其程序运行在网络服务器上。
传统CGI接口主要缺点表现在性能很查,每次HTTP遇到动态程序时都需要重新启动脚本解析器,然后将结果返回给HTTP服务器。
Fast-CGI是从CGI发展改进而来的,FastCGI接口方式采用C/S结构,可以将HTTP服务器和脚本解析(PHP-FPM|PHP-CGI)服务器分开,同时在脚本解析服务器上启动一个或者多个脚本解析守护进程。当HTTP服务器每次遇到动态程序时,可以将其直接交付给Fast-CGI进程来执行,然后将得到的结果返回给浏览器。这种方式可以让HTTP服务器专一地处理静态请求或者将动态脚本服务器的结果返回给客户端,这在很大程度上提高了整个应用系统的性能。
FastCGI是语言无关的、可伸缩架构的CGI开放扩展,将CGI解释器进程保持在内存中,以此获得较高的性能。FastCGI是一个协议,php-fpm实现了这个协议,php-fpm的FastCGI协议需要有进程池,php-fpm实现的FastCGI进程叫php-cgi,所以php-fpm其实是他自身的FastCGI或php-cgi进程管理器。
总得来说FastCGI相较于CGI而言:1.它具有长期守护进程。2.实现多个请求对同一进程复用。3.采用了连接池技术。4.团队分工并没有CGI零散,高吞吐,低延迟,内存占用少。