计算机组成原理期末题目解析
在我们学习完所有基础内容后才会去解决本学期的期末试题
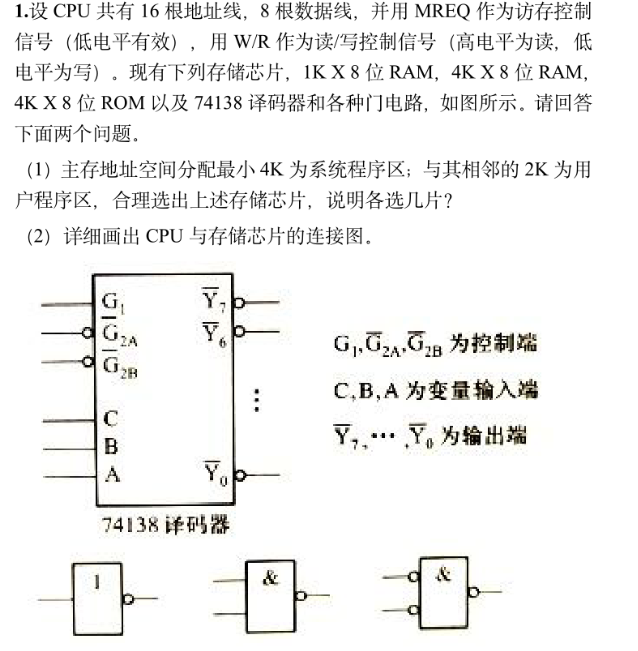
一、存储器设计和连接
解决本题之前可以先看一下博主写的前置课程安排
存储器的分类(RAM,ROM)-CSDN博客
二、高速缓冲存储器

我们要学习的第二个高频考点就是高速缓冲存储器
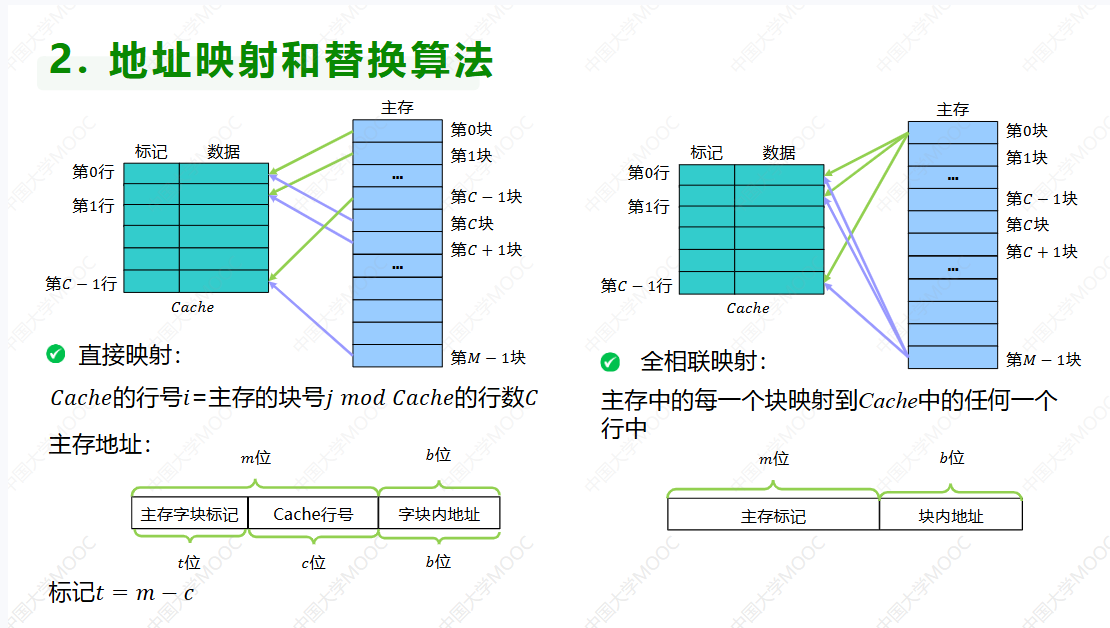
Cache的基本概念
第一问相关知识点
地址映射和替换算法
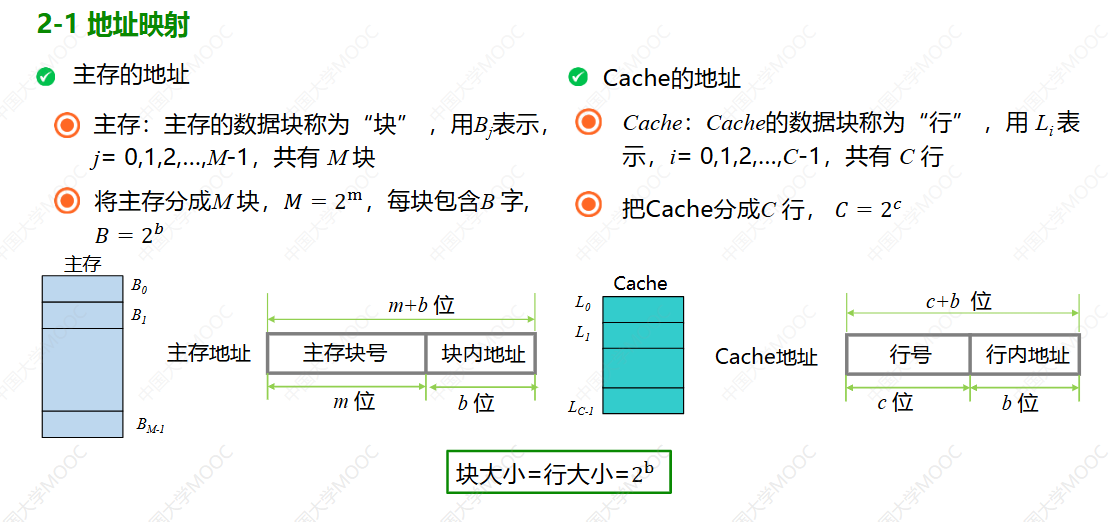


第一问解决步骤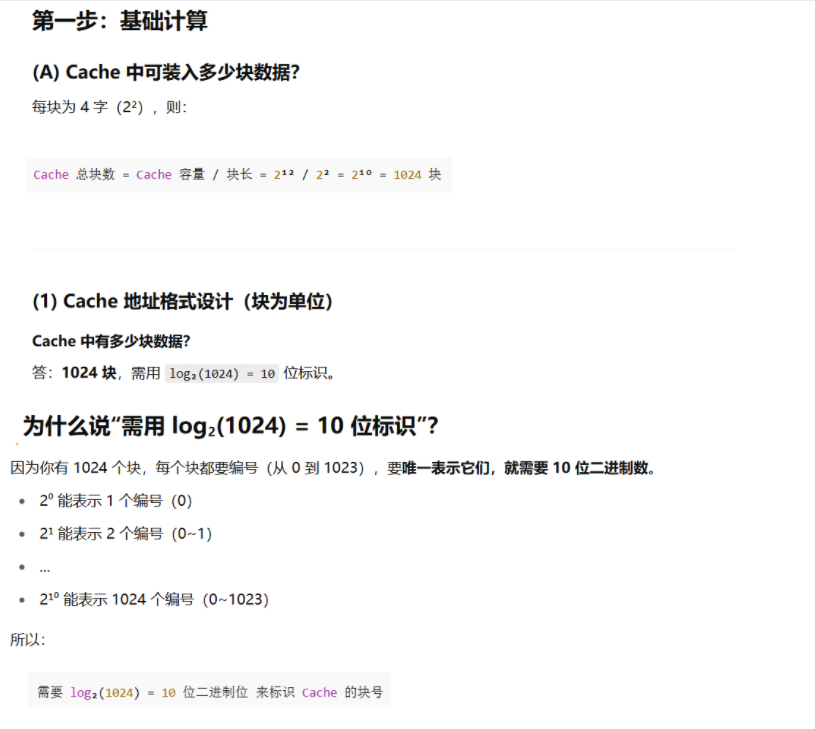
第二问相关知识点

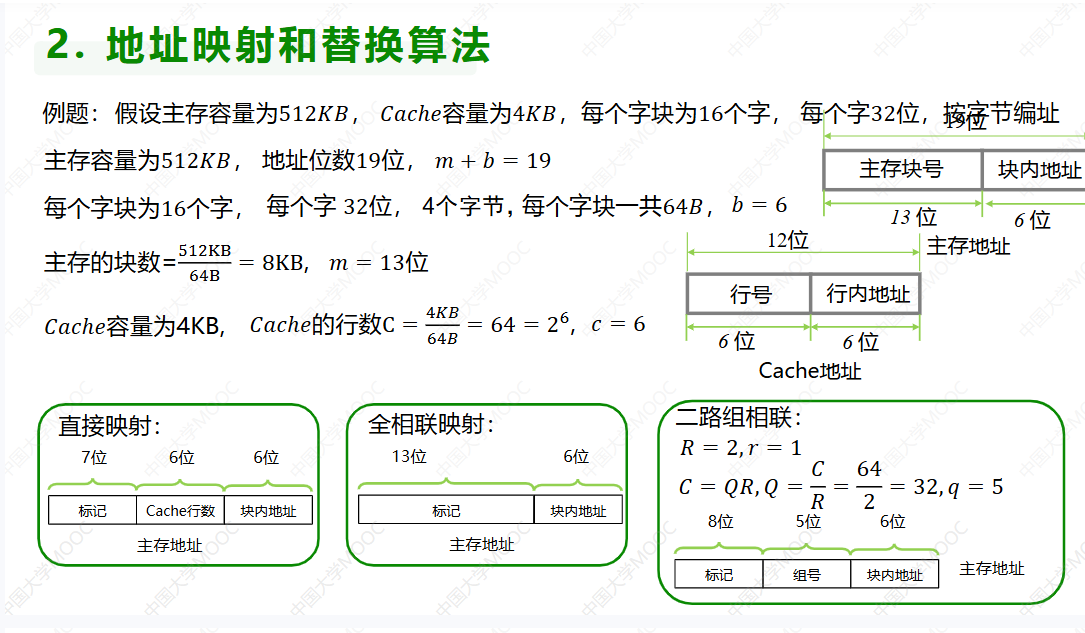
第二问解决过程
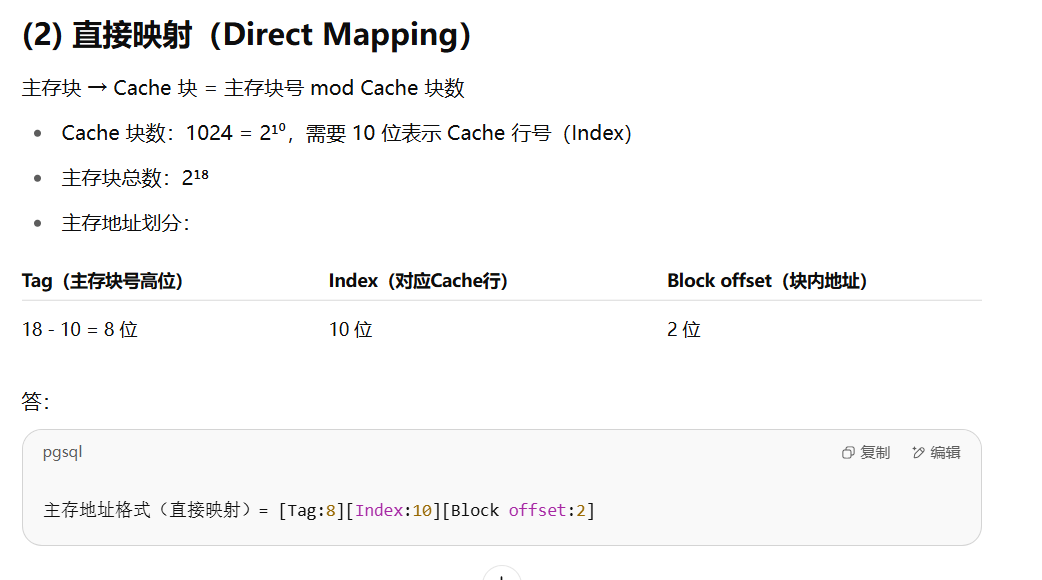
三、计算总线带宽

总线带宽 = 总线周期的频率 * 总线宽度(即一次传输的位数)
总线周期 = 一个时钟周期
时钟频率为12MHz 则 时钟周期 = 总线周期 = 1/12MHz
总线宽度 = 64位 , 64b/8b = 8B
所以总线带宽 = 8B * 1/12MHz = 2/3 (B/MHz)
四、浮点数计算
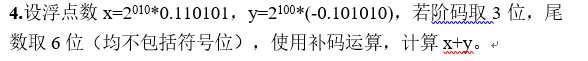
五、指令系统

马士兵
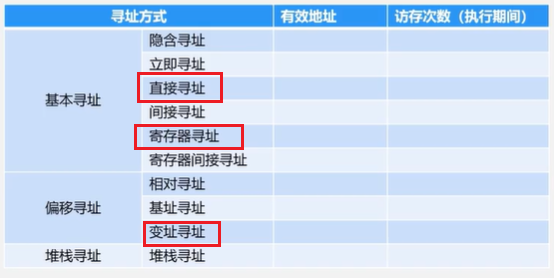

- 为什么PC中存放的是下一条指令的地址,而不是当前指令的地址?
因为在当前指令被“取出”(Fetch)之后,PC 会立即自增,指向下一条指令的地址,以备下一周期使用。
指令周期回顾(以经典冯诺依曼架构为例):
CPU 执行一条指令的基本流程大致如下:
-
取指(Fetch):从内存中读取“当前”指令,地址由 PC 提供。
-
PC 自增:一旦读取完成,PC 通常自动加 1(或加上指令字长),准备好指向下一条指令。
-
译码(Decode):对取出的指令进行译码。
-
执行(Execute):执行指令。
-
写回/更新:更新结果。
关键点是第 2 步:PC 在取指后立刻更新
-
当你说“当前指令”时,它已经被取出并正在执行。
-
同一时间,PC 被更新成下一条指令的地址,为的是:
当前指令执行完后,下一条指令能立刻被读取,无需再回头找地址。
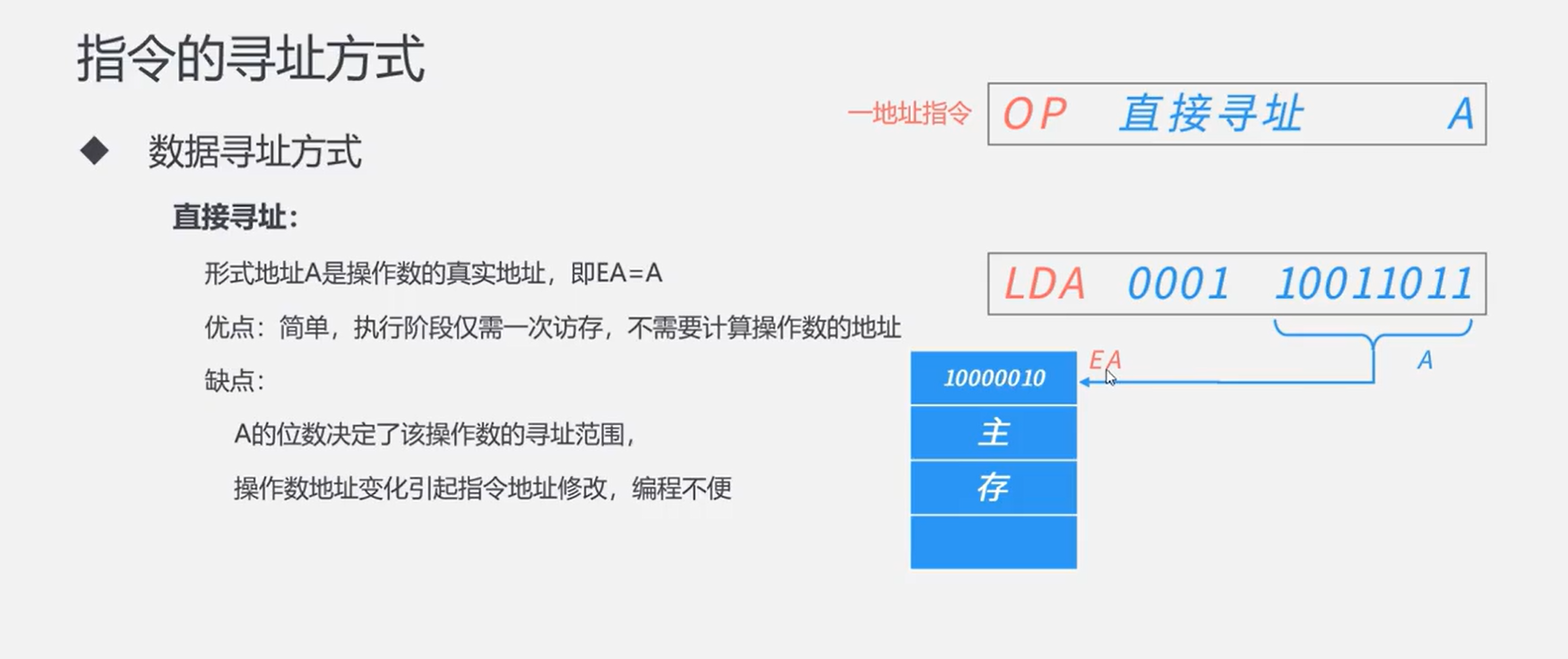
六、指令流水线


第六题和第七题基本是同一个知识点,都是“指令流水线”相关内容。
但它们关注的角度不同:
| 题号 | 知识点 | 主要关注内容 |
|---|---|---|
| 第6题 | 流水线中的数据相关冲突分析与解决方法 | 重点考察 RAW 冲突(Read After Write)及调度/前递/推迟策略 |
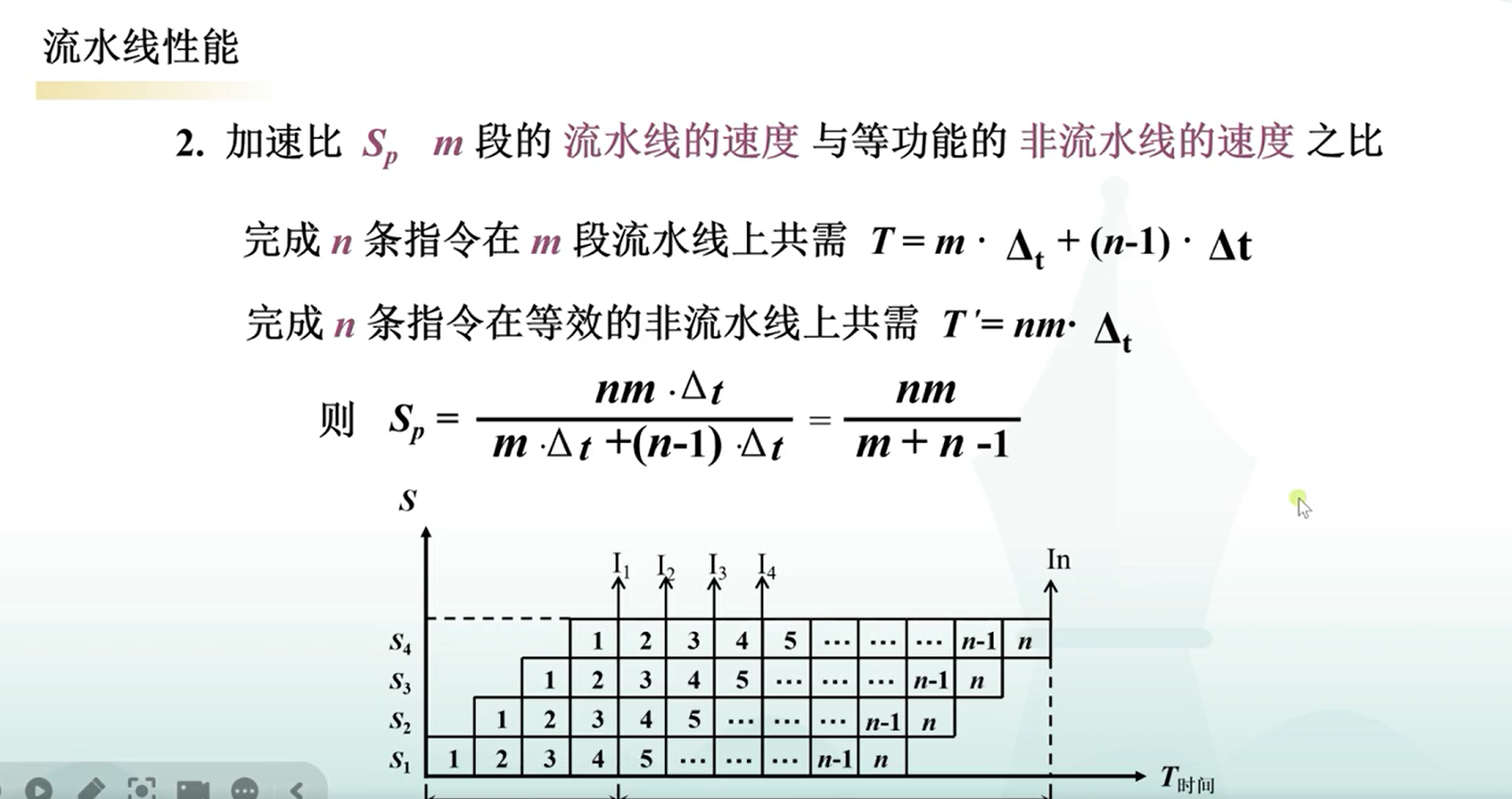
| 第7题 | 流水线的性能评价指标:加速比、吞吐率 | 重点考察理想 vs 实际流水线性能计算,包括时间分析 |
-
流水线:将一个任务拆成多个阶段(比如
m个),每个阶段执行任务的一部分。 -
非流水线:每次任务需要完整执行所有阶段,任务是串行完成的。
流水线吞吐率
✅ 一、什么是吞吐率(Throughput)
吞吐率指的是单位时间内,流水线能完成多少条指令或任务。
通俗点说就是:
**流水线多久能“吐”出一条结果?**越快,吞吐率越高。


流水线加速比

流水线的效率


九、微程序控制器和微指令

取指微程序 在ADD指令和STA指令 中出现重复使用,所以我们可以"提取公因式"

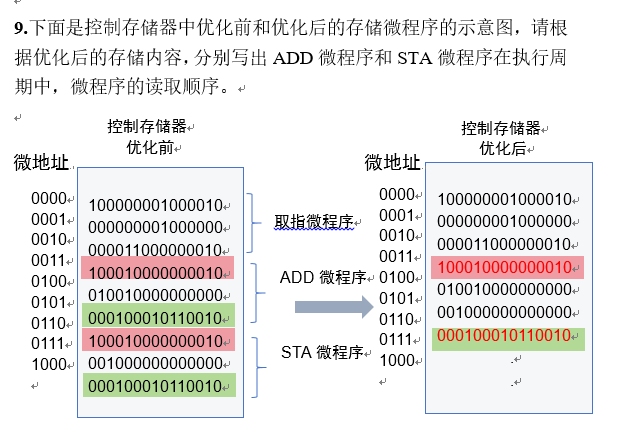

知识点分析:
- - 微程序控制:这是一种实现控制单元的方法,其中控制信号由存储在控制存储器中的微指令序列生成。
- - 微指令:每个微指令包含一组控制信号,用于在CPU的各个部件之间协调操作。
- - 微地址:微指令在控制存储器中的地址。
- - 取指周期:CPU从内存中取指令的周期。
- - 执行周期:指令被解码并执行的周期。
- - 优化:这里通过共享微指令来减少控制存储器的使用,例如,通过重用公共的微指令序列。
用户需要根据优化后的控制存储器内容,写出ADD和STA微程序在执行周期中的微程序读取顺序。
解决过程
ADD微程序在执行周期中的读取顺序:
优化后ADD微程序直接给出了执行序列,读取顺序为以下9个微指令的顺序(按列表顺序):
STA微程序在执行周期中的读取顺序:
优化后未提供STA微程序内容,因此我们基于优化前内容推导。优化前STA的执行序列未明确,但通常使用完整微指令序列。读取顺序为以下9个微指令的顺序(按优化前列表顺序):