Redis中的zset的底层实现
Redis中的zset的底层实现
今天我们来聊聊Redis中一个非常有趣且实用的数据结构——有序集合(zset)。就像我们平时在超市购物时,商品会按照价格从低到高排列一样,zset也能帮我们维护一个有序的数据集合。那么Redis是如何实现这种高效的有序结构的呢?让我们一起来探索它的底层实现原理。
1. zset的基本概念
在开始深入之前,我们先简单回顾一下zset的基本特性。zset是Redis提供的一种有序集合数据结构,它类似于普通的集合(set),但每个成员都会关联一个分数(score),Redis会根据这个分数对集合中的成员进行从小到大的排序。
zset在实际应用中非常有用,比如我们可以用它来实现:
- 排行榜系统(按分数排序)
- 带权重的任务队列
- 时间线功能(按时间戳排序)
- 范围查询(如查找分数在80-90之间的学生)
zset的一个关键特性是:虽然成员是唯一的,但分数可以重复。这就像班级里每个学生学号唯一,但可以有多个学生考同样的分数。
2. zset的底层实现结构
理解了zset的基本概念后,我们来看看Redis是如何实现它的。Redis的zset实际上使用了两种数据结构组合来实现:
2.1 哈希表(Hash Table)
Redis使用一个哈希表来存储成员(member)到分数(score)的映射关系。这就像我们有一个学生名册,可以快速通过学生姓名查找到他的考试成绩。
哈希表的优势在于:
- O(1)时间复杂度查找成员对应的分数
- 快速判断某个成员是否存在
- 高效更新成员的分数
2.2 跳跃表(Skip List)或压缩列表(Zip List)
为了维护成员的有序性,Redis会根据数据量的大小选择使用跳跃表或压缩列表:
- 当元素数量较少或元素较小时,使用压缩列表(Zip List)
- 当元素数量超过阈值或元素较大时,使用跳跃表(Skip List)
这种设计是Redis典型的"小数据优化"思想,对于小数据集使用更紧凑的存储方式,对于大数据集则使用性能更好的结构。
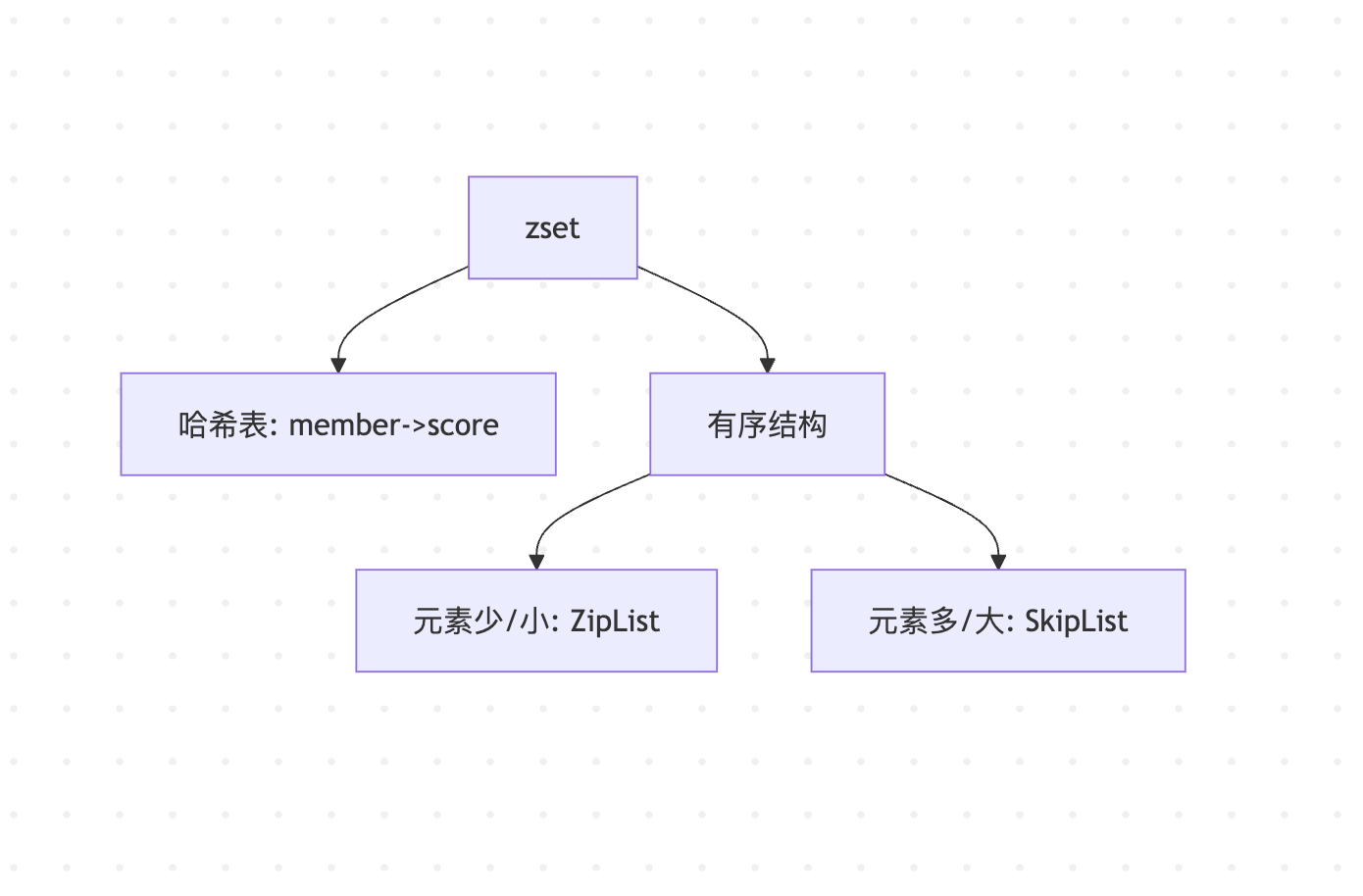
以上流程图说明了zset的底层实现结构。它同时使用了哈希表和有序结构(可能是压缩列表或跳跃表)来满足不同的操作需求。
3. 压缩列表实现细节
现在我们来详细看看zset在小数据情况下的实现——压缩列表(Zip List)。压缩列表是Redis为了节省内存而设计的一种特殊编码方式。
3.1 压缩列表的结构
压缩列表是一块连续的内存空间,它按照特定的格式存储数据。想象一下,这就像我们把所有数据整齐地打包在一个行李箱里,而不是分散放在房间各处。
一个压缩列表包含以下部分:
+--------+--------+--------+--------+--------+--------+--------+--------+
| zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+--------+--------+--------+--------+--------+--------+--------+--------+其中:
zlbytes: 整个压缩列表占用的内存字节数zltail: 最后一个节点的偏移量,方便快速定位zllen: 节点数量entry1..N: 各个节点数据zlend: 结束标记(0xFF)
3.2 压缩列表中的元素存储
在zset中使用压缩列表时,每个成员和它的分数会作为两个连续的节点存储。这就像我们把学生的姓名和成绩写在相邻的两张卡片上。
例如,存储一个zset {“alice”: 85, “bob”: 92},在压缩列表中的布局如下:
+-------+-------+-------+-------+-------+-------+-------+-------+
| ... | 85 | alice | 92 | bob | ... |
+-------+-------+-------+-------+-------+-------+-------+-------+这种存储方式非常紧凑,没有额外的指针开销,因此在小数据量时非常高效。
需要注意的是,当zset使用压缩列表存储时,所有操作都需要遍历整个列表,因此时间复杂度是O(N)。这就是为什么Redis会在数据量大时切换到跳跃表的原因。
4. 跳跃表实现细节
当zset中的元素数量超过zset-max-ziplist-entries(默认128)或元素大小超过zset-max-ziplist-value(默认64字节)时,Redis会将底层结构转换为跳跃表(Skip List)。
4.1 跳跃表的基本概念
跳跃表是一种概率平衡的数据结构,可以看作是多层链表。想象一下地铁系统:有普通站(每站都停)和快速站(只停大站),这样乘客可以根据需要选择不同速度的线路。
一个简单的跳跃表示例:
Level 3: 1 --------------------------------> 9
Level 2: 1 ------------> 5 ------------> 9
Level 1: 1 ---> 3 ---> 5 ---> 7 ---> 9
Level 0: 1->2->3->4->5->6->7->8->9在这个结构中,查找时可以跳过一些节点,从而将查找时间复杂度从O(N)降低到O(logN)。
4.2 Redis中跳跃表的具体实现
Redis中的跳跃表实现包含两个主要结构:
1. zskiplistNode(跳跃表节点)
typedef struct zskiplistNode {robj *obj; // 成员对象double score; // 分数struct zskiplistNode *backward; // 后退指针struct zskiplistLevel {struct zskiplistNode *forward; // 前进指针unsigned int span; // 跨度} level[]; // 层级数组
} zskiplistNode;2. zskiplist(跳跃表)
typedef struct zskiplist {struct zskiplistNode *header, *tail; // 头尾节点unsigned long length; // 节点数量int level; // 当前最大层数
} zskiplist;跳跃表在Redis中的实际内存布局如下图所示:
[图片位置1:Redis跳跃表内存布局示意图]
4.3 跳跃表的操作原理
让我们以插入操作为例,看看跳跃表是如何工作的:
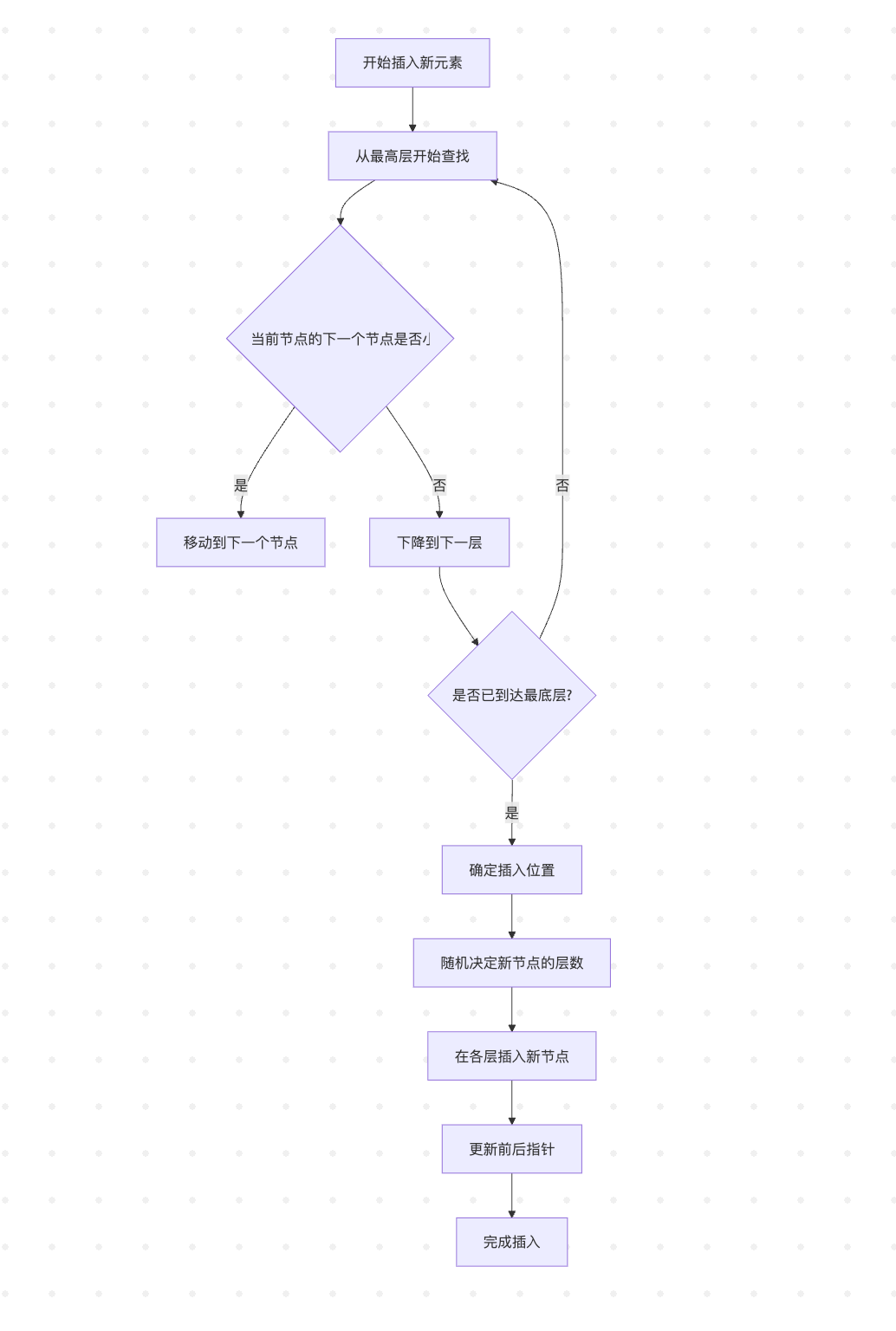
以上流程图说明了在跳跃表中插入一个新元素的完整过程。关键在于从高层开始快速定位,然后逐步精确到插入位置,最后通过随机算法决定新节点的层数。
4.4 为什么Redis选择跳跃表而不是平衡树
很多同学可能会问,为什么Redis不使用更常见的平衡树(如AVL树或红黑树)来实现有序集合呢?这主要有以下几个原因:
- 实现简单:跳跃表的实现比平衡树简单得多,代码更易于维护
- 范围查询高效:跳跃表在范围查询时非常高效,因为底层是一个链表
- 并发友好:跳跃表比平衡树更容易实现无锁并发操作
- 性能相当:对于大多数操作,跳跃表的平均时间复杂度与平衡树相同
5. zset的常用操作分析
了解了zset的底层结构后,我们来看看一些常用操作在这些结构上是如何执行的。
5.1 ZADD操作
ZADD key score member 是向zset中添加元素的基本命令。它的执行流程如下:
-
检查zset是否存在,不存在则创建
-
如果底层是压缩列表:
- 检查是否需要转换为跳跃表(根据元素数量和大小)
- 如果不需要转换,则遍历压缩列表查找插入位置
- 插入新元素(可能需要重新分配内存)
-
如果底层是跳跃表:
- 使用跳跃表查找算法定位插入位置
- 创建新节点并插入到适当位置
- 更新哈希表中的member->score映射
5.2 ZRANGE操作
ZRANGE key start stop 用于获取指定范围内的元素。它的执行流程:
-
检查zset是否存在
-
如果底层是压缩列表:
- 从头开始遍历到start位置
- 继续遍历直到stop位置,收集结果
-
如果底层是跳跃表:
- 从头节点开始,利用跳跃表的层级快速定位到start位置
- 沿着最底层链表遍历到stop位置
5.3 ZSCORE操作
ZSCORE key member 用于获取成员的分数。这个操作非常高效,因为它直接通过哈希表查找:
- 在哈希表中查找member对应的score
- 返回结果(无论底层是压缩列表还是跳跃表,这一步都是O(1))
从这些操作中我们可以看到,Redis巧妙地结合了哈希表和有序结构的优势:哈希表提供快速的成员查找,有序结构维护排序和范围查询能力。
6. zset的内存优化技巧
在实际使用中,我们经常需要考虑如何优化zset的内存使用。下面分享几个实用的技巧:
6.1 合理设置ziplist参数
我们可以根据实际数据特点调整这两个参数:
# 修改redis.conf或通过CONFIG SET命令
zset-max-ziplist-entries 256 # 默认128
zset-max-ziplist-value 128 # 默认64上述配置将允许更多的元素或更大的元素使用压缩列表存储。但要注意:
- 增加这些值会节省内存,但可能降低操作性能
- 需要根据实际数据特点进行测试和权衡
6.2 使用更短的成员名称
由于成员名称存储在内存中,使用更短的名称可以显著节省内存。例如:
- 使用用户ID而不是用户名
- 使用缩写或编码代替完整名称
6.3 考虑使用整数分数
如果业务允许,使用整数而不是浮点数作为分数可以节省一些内存。
6.4 定期清理过期数据
对于排行榜等场景,可以定期移除排名靠后的数据,保持zset的大小可控。
7. 实际应用案例
让我们看一个实际的排行榜实现案例,展示如何充分利用zset的特性。
7.1 游戏排行榜实现
假设我们要实现一个游戏玩家积分排行榜,支持以下功能:
- 记录玩家分数
- 获取前10名玩家
- 查询玩家排名
- 查询分数段内的玩家
Redis命令实现:
# 添加或更新玩家分数
ZADD leaderboard 3500 "player1"
ZADD leaderboard 2800 "player2"
ZADD leaderboard 4200 "player3"# 获取前10名玩家(按分数从高到低)
ZREVRANGE leaderboard 0 9 WITHSCORES# 查询特定玩家排名(从0开始)
ZREVRANK leaderboard "player1"# 查询分数在3000-4000之间的玩家
ZRANGEBYSCORE leaderboard 3000 4000 WITHSCORES上述代码展示了如何使用zset实现一个完整的排行榜系统。考虑到排行榜需要频繁更新和查询,zset的O(logN)操作复杂度非常适合这种场景。
8. 总结
通过今天的探讨,我们对Redis中zset的底层实现有了深入的理解。让我们总结一下本文的主要内容:
- zset的基本概念:有序集合,成员唯一但分数可重复
- 底层结构:哈希表+有序结构(压缩列表或跳跃表)
- 压缩列表实现:小数据时使用,内存紧凑但操作复杂度高
- 跳跃表实现:大数据时使用,O(logN)时间复杂度,支持高效范围查询
- 操作分析:不同操作在不同结构上的执行流程
- 优化技巧:合理配置参数、缩短成员名称等
- 实际应用:排行榜系统的完整实现
Redis的zset通过巧妙的双结构设计,既保证了高效的成员查找,又维护了良好的排序特性,是很多有序场景的理想选择。希望通过本文的分享,能帮助大家更好地理解和使用这个强大的数据结构。