NLP语言发展路径分享
自然语言处理初期发展历程
早期:离散表示
one-hot(只表达“有/无”,语义完全丢失)→ n-gram(局部上下文,但高维稀疏)→ TF-IDF(考虑词频与权重,但不能表达词关联),可见,缺点非常明显,达不到要求
过渡:分布式思想萌芽
LSA等降维尝试,引入“词语义空间”思想,但非神经网络。
突破:神经网络分布式表示
NNLM(深度学习自动学语义嵌入,训练慢)
word2vec(极大提高训练效率与质量,催生“词嵌入”大潮流)
主流趋势
低维、稠密、有语义的词向量成为自然语言理解基础,后续BERT等“上下文相关词向量”技术,是word2vec之后更高阶的语义学习。
理念从“词级one-hot”→“全局加权”→“上下文分布”→“深度学习自学表示”。
小结
one-hot、n-gram、TF-IDF:简单直观,但稀疏、高维、语义弱。
分布式表示、NNLM、word2vec:低维稠密,语义能力强,推动深度学习NLP大发展。
从one-hot到word2vec,是NLP词表示从“人工特征”到“自动语义学习”的质变。
发展过程中,案例展示
一,one-hot
基本的语意:

对文本的表示:

优缺点:

二、TF-IDF
基础公式描述

公式表达:

优缺点分析;

三、N-gram
基础语法表达:
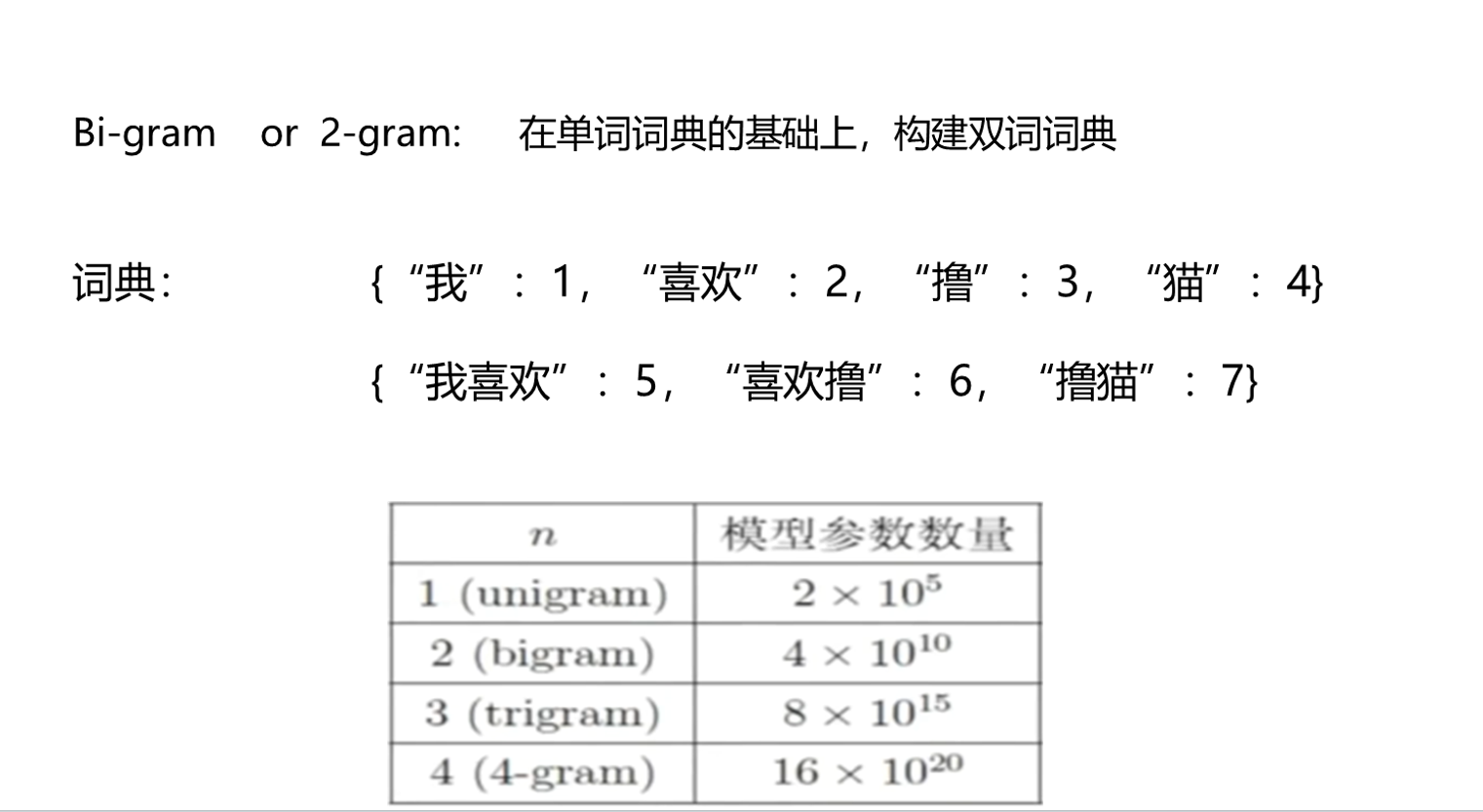
优缺点:

语言模型:

离散表示:

四、分布式
表示方法表示:

优缺点:

共现矩阵的表达方式
表达方式:
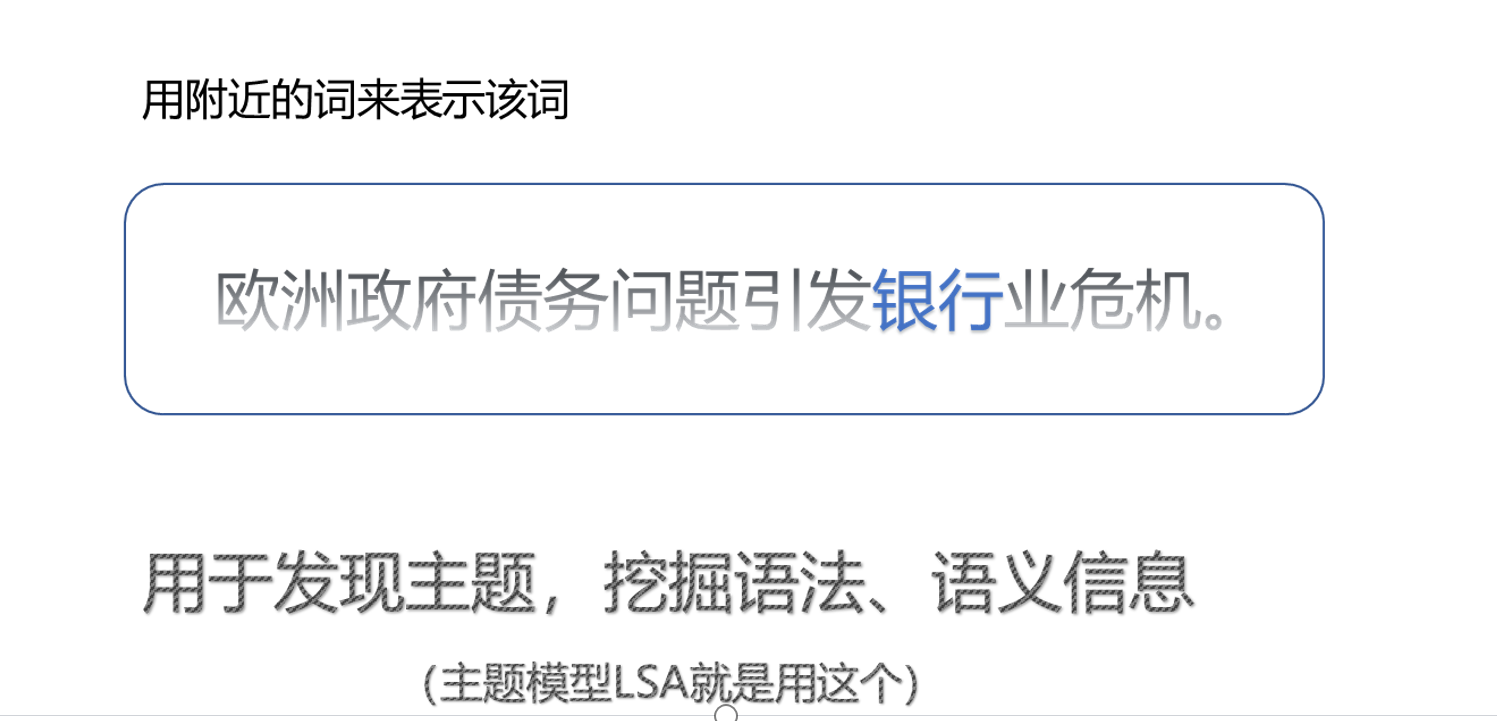
表达案例:
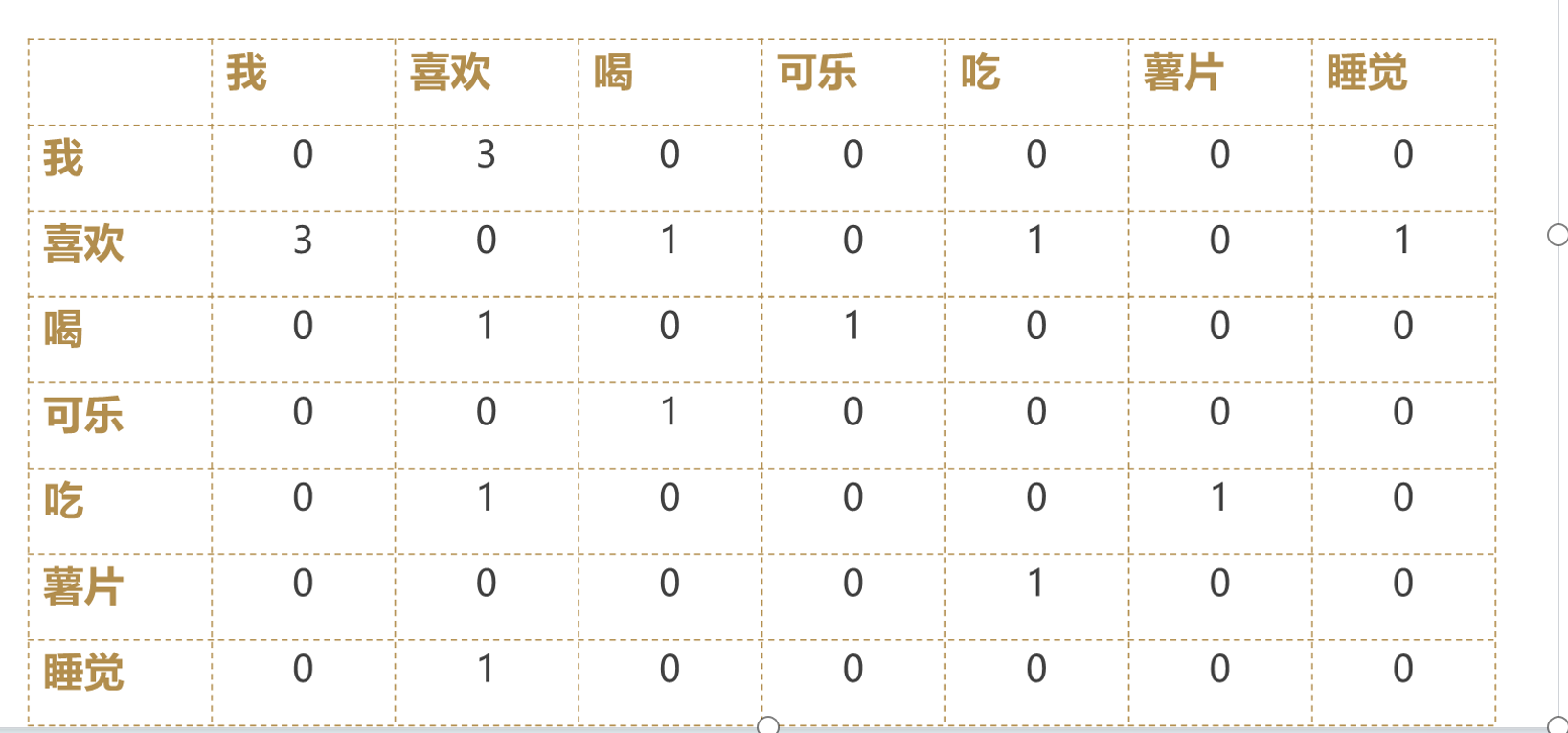
优缺点:

公式展现
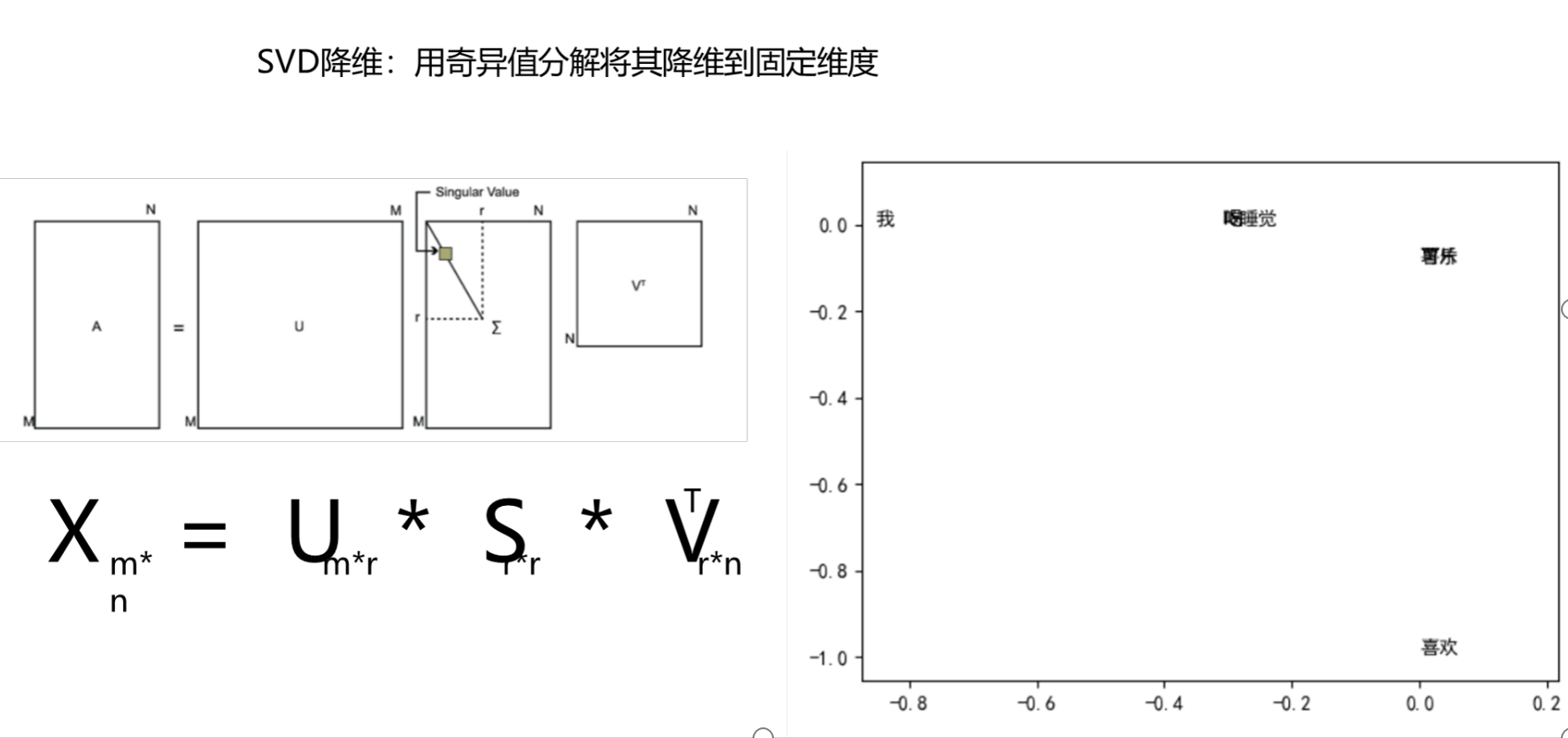
实现代码
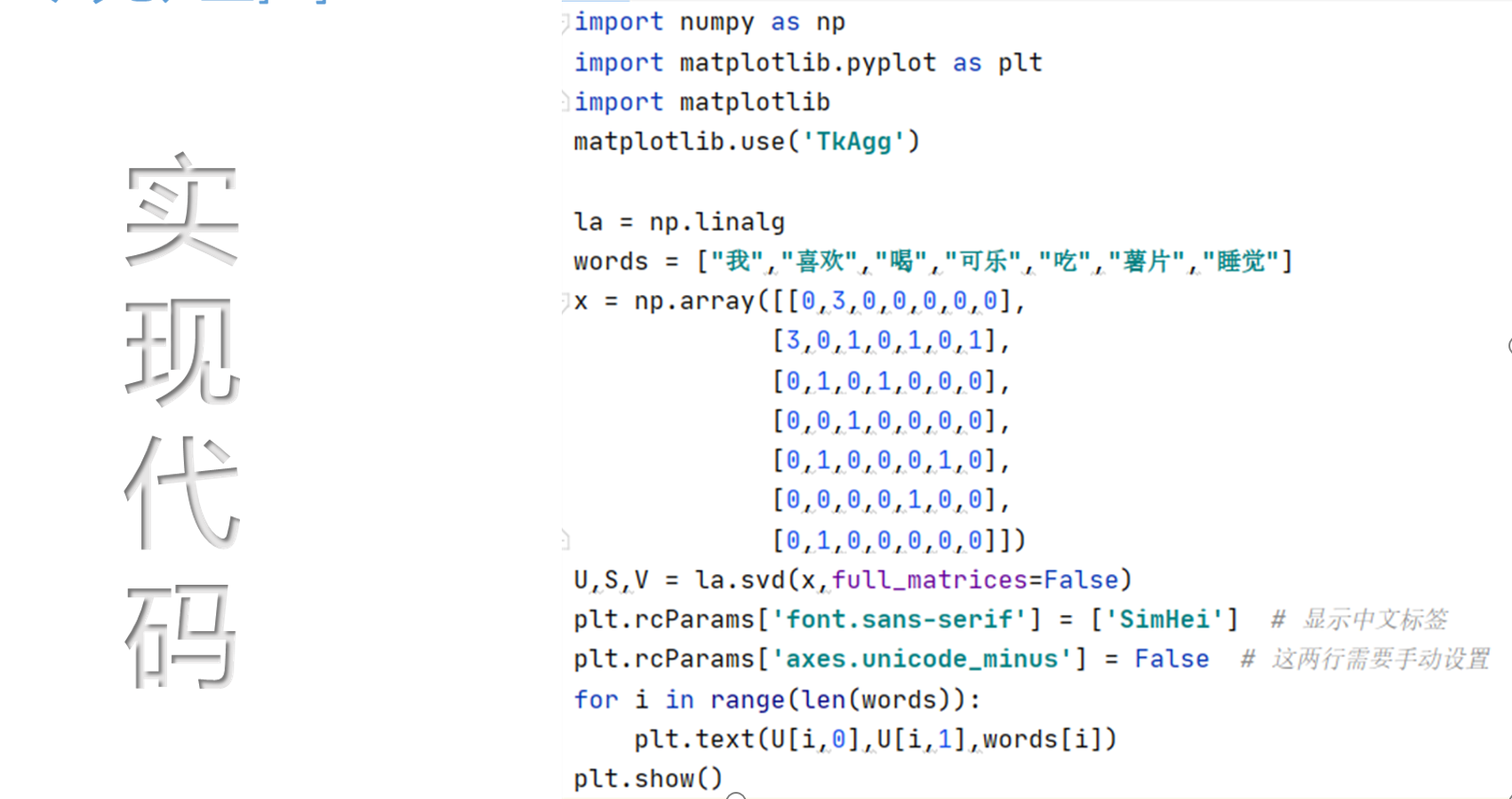
技术实现优缺点:

五、NNLAM
样本案例:

公式:
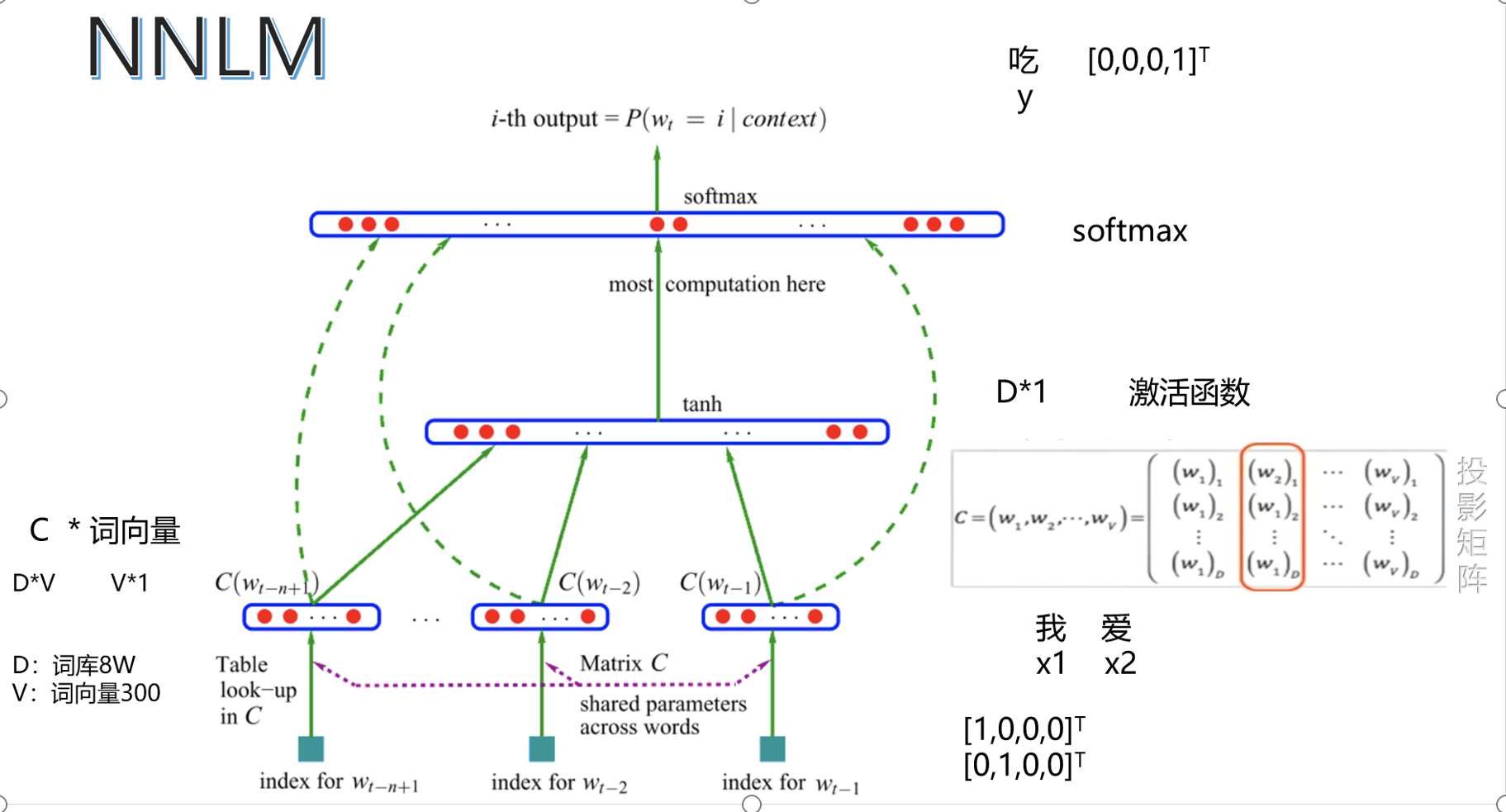
优缺点:

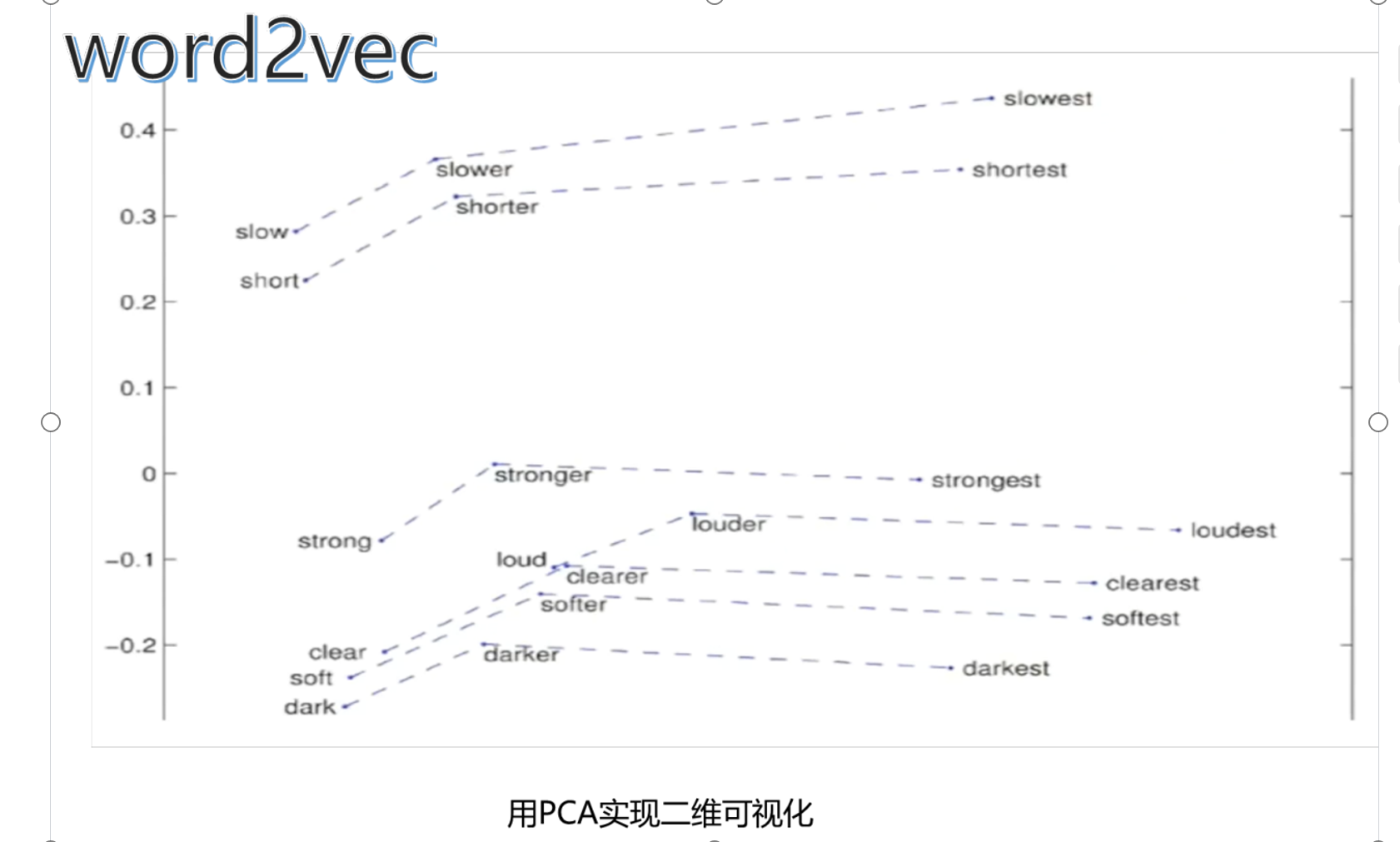
六、word2vec
案例和算法图
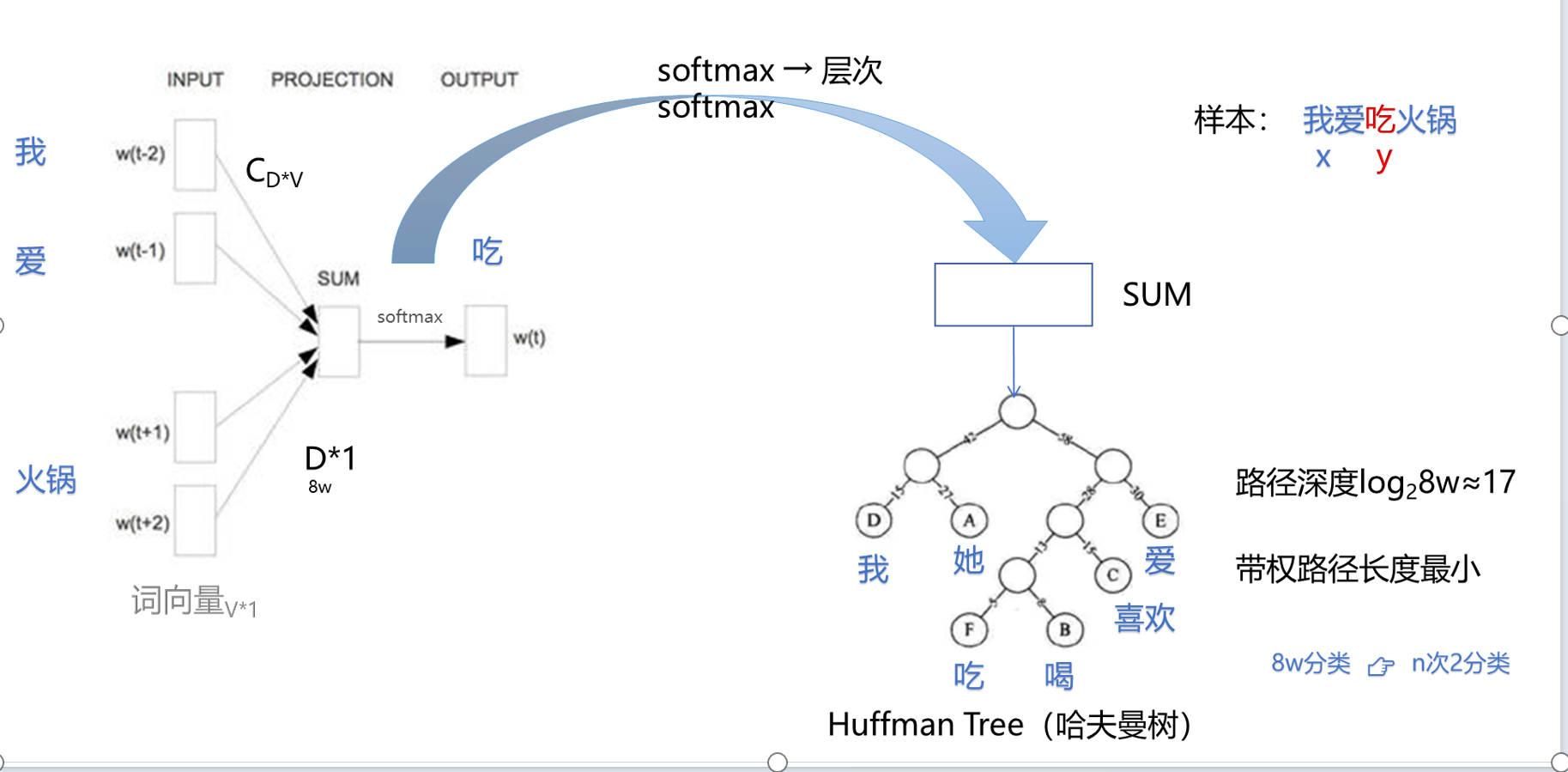
二次方的概率:

PCA实现二维可视化
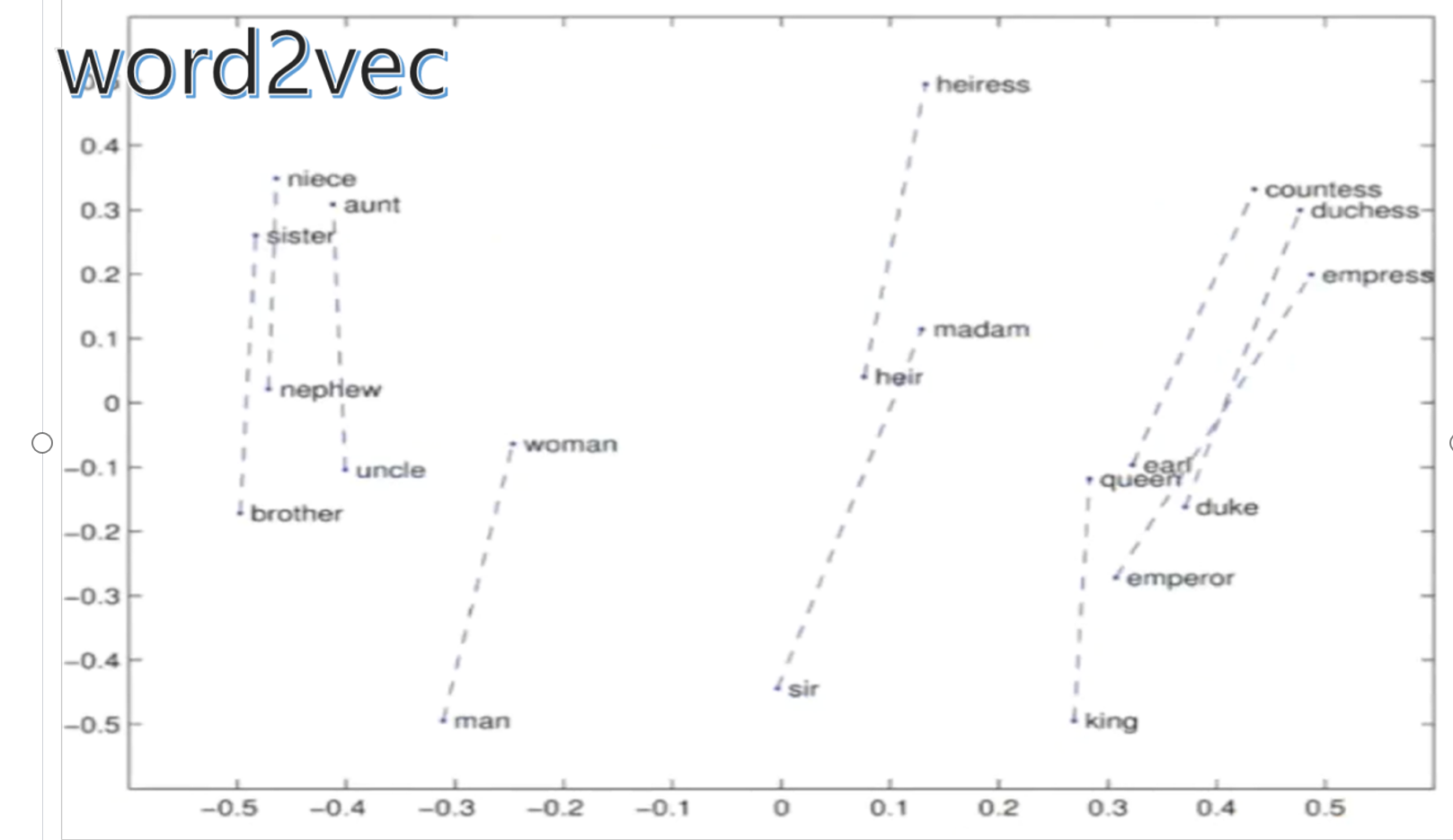
优缺点
