自主学习-《Absolute Zero: Reinforced Self-play Reasoning with Zero Data》
1. 监督学习:需要人工给出推理过程;
2. RLVR: 推理过程由agent自我生成和学习,计算reward的gold值是环境或工具给出的,题目仍需要人工给出;
3. 本方法:题目也是agent自己生成的。(gold值仍需环境或工具给出)。

基本理论:
1. SFT的公式:(优化
,使得input prompt x生成推理c*和结果y*的概率最大化)
痛点:模型吸收了足够多的知识后,没有更强的模型可供生成数据了,人工来标注数据又太费钱;
2. Reinforcement Learning with Verifiable Rewards的公式:(波浪线表示采样;y是模型采样得到的结果,y*是ground truth结果, r是reward function)
3. 本方法的公式:
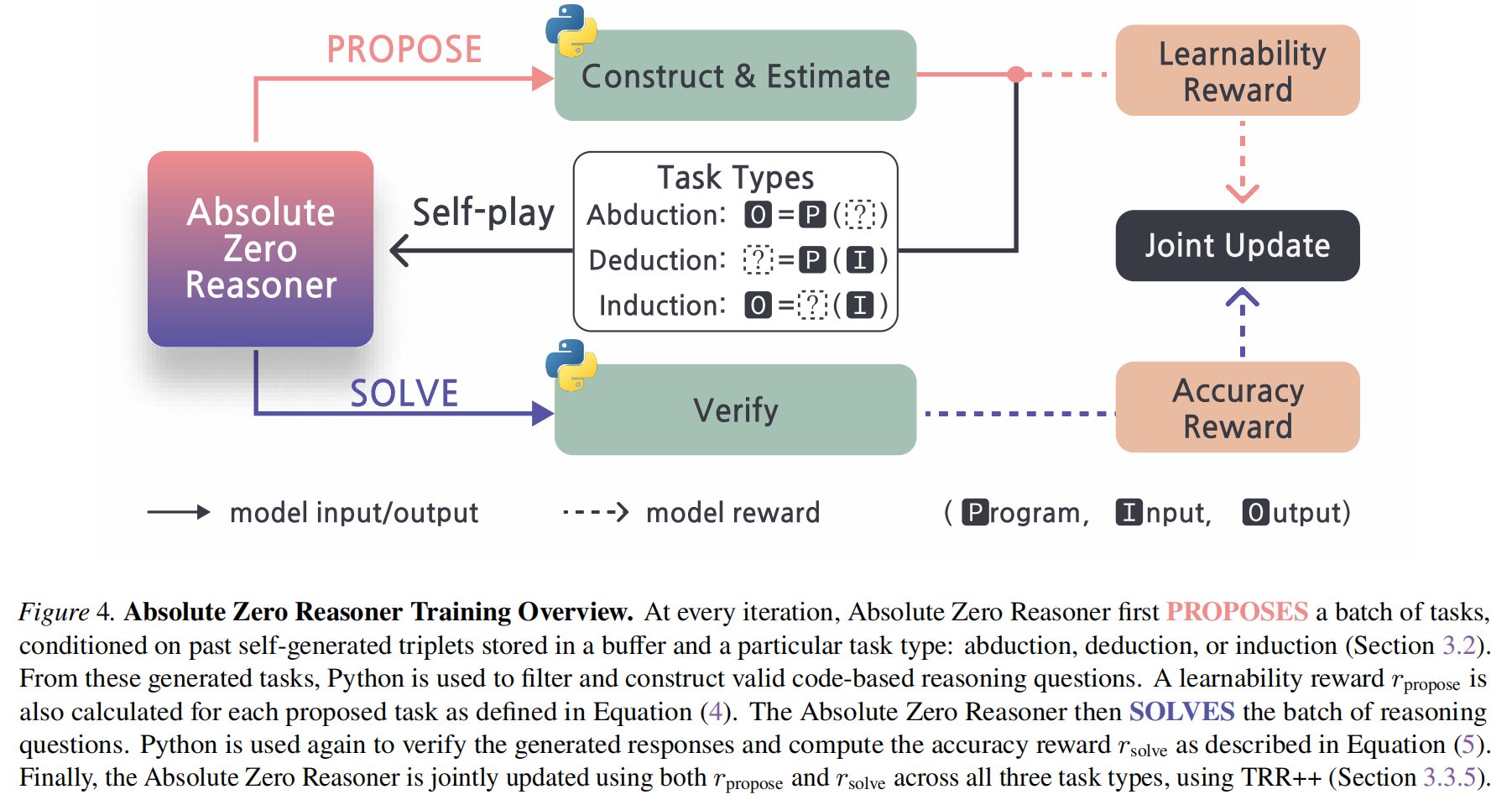
示意图:
learnability: 模型训练了该样本之后,变强了多少;(太简单,模型每次都答对,则该样本没价值;太难,模型每次都打错,则该样本也没价值)
本文中,z这个随机变量,是用当前的题目集合中采样几个得到的题目集合;
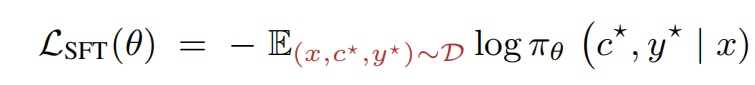
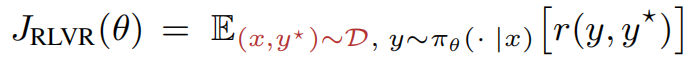
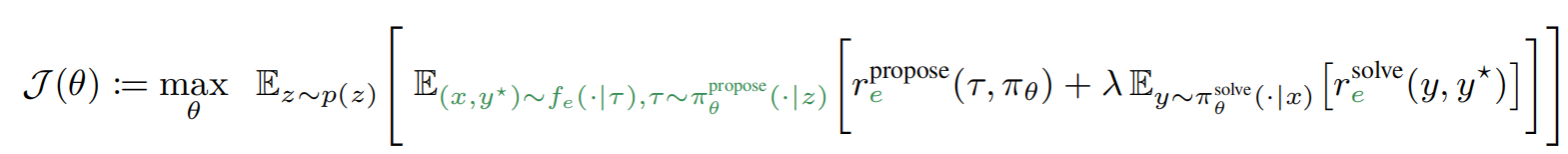
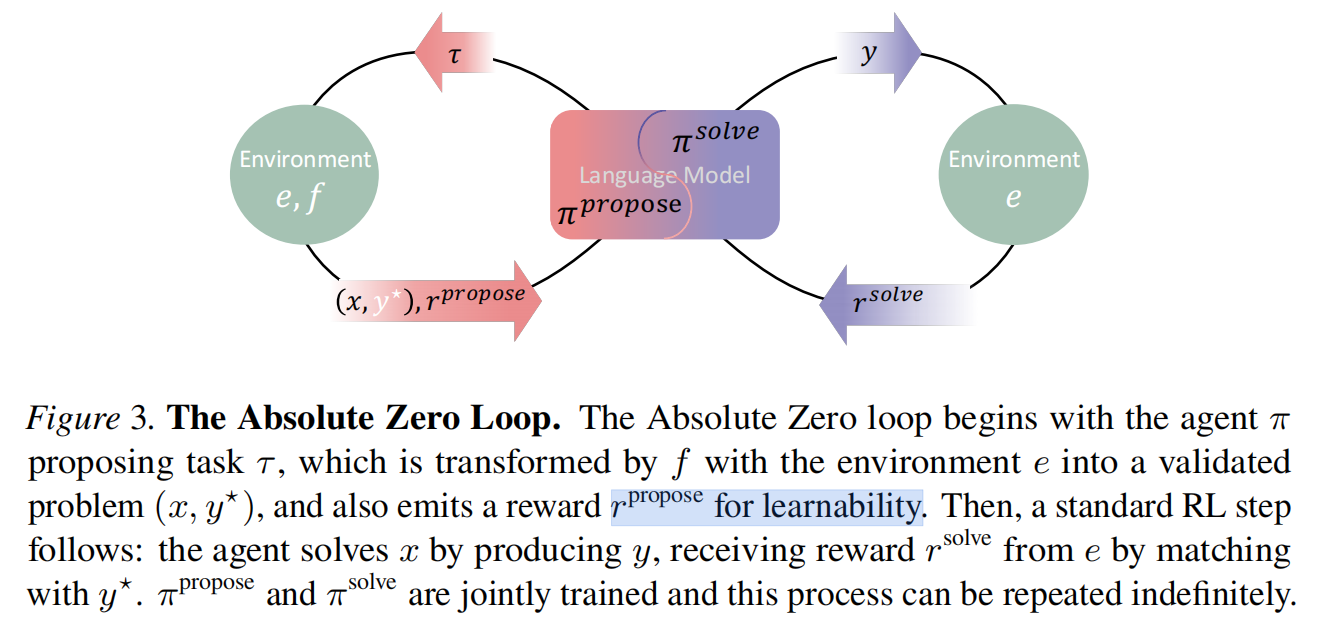
流程图: