[AAAI Oral] 简单通用的公平分类方法
文章首发于我的博客:https://mwhls.top/5032.html
前言
太长不看
- [AAAI 2025 Oral] Fair Training with Zero Inputs
- 对于类别无关的全零图像,模型不应偏向于任意类别。
基本信息
- 本人为第一作者潘文杰,通讯作者为朱建清教授,作者均来自于华侨大学。
- 相关下载:
- 论文下载:doi.org/10.1609/aaai.v39i6.32676
- 代码开源:https://github.com/asd123pwj/ZUT
- 开源代码的训练结果:https://drive.google.com/drive/folders/1hWFJ2n4LnGnnD2r-C6dLyE31-0UJldfw?usp=drive_link
- Oral PPT及海报:https://drive.google.com/drive/folders/1hWFJ2n4LnGnnD2r-C6dLyE31-0UJldfw?usp=drive_link
- 开源说明:
- 语义分割基于MMSegmentation 1.2.1,且开源代码在原始代码上重新部署,可与原始代码对照,查看修改位置。
- ReID代码基于Simple-CCReID,或将在扩刊接收后开源。
- 分类代码基于MMPretrain 1.1.1,由于其未原生实现多loss,因此损失改造的较为丑陋,是直接与现有损失结合,因此无开源计划。
实现简单
- 核心思想可用五行代码概括(见论文或本文后的伪代码),在实际部署时,仅需修改训练循环中的几行代码即可.
- 例如,在ICLR 2021的logit-adjustment中,对
main.py在110~115行的代码修改如下。 - 部分如MMSegmentation等封装较多的工具箱需要较多的修改,因此开源代码首先放出MMSegmentation。
- 例如,在ICLR 2021的logit-adjustment中,对
# 例如,在ICLR 2021的logit-adjustment中,对main.py在110~115行的代码修改如下。
if args.ZUT != 0:img_zero = input_var.new_zeros(1, *input_var.shape[1:]) # newinput_parallel = torch.cat((img_zero, input_var), dim=0) # newoutput_parallel = model(input_parallel)output_zero = output_parallel[0] # newoutput = output_parallel[1:] # newacc = utils.accuracy(output.data, target)if args.logit_adj_train:output = output + args.logit_adjustmentsloss = criterion(output, target_var)loss += output_zero.std() * args.ZUT # new""" --- ZUT End --- """
else:output = model(input_var)acc = utils.accuracy(output.data, target)if args.logit_adj_train:output = output + args.logit_adjustmentsloss = criterion(output, target_var)
研究价值
- 个人认为,这篇工作本质上是利用任务无关的数据,优化模型难以量化的性能。
- 在分类任务上,这篇工作将全零数据作为类别无关数据,通过抑制全零图像所揭露的偏见来改善模型公平性。
- 也可以针对任务,进行公平以外的优化,例如:
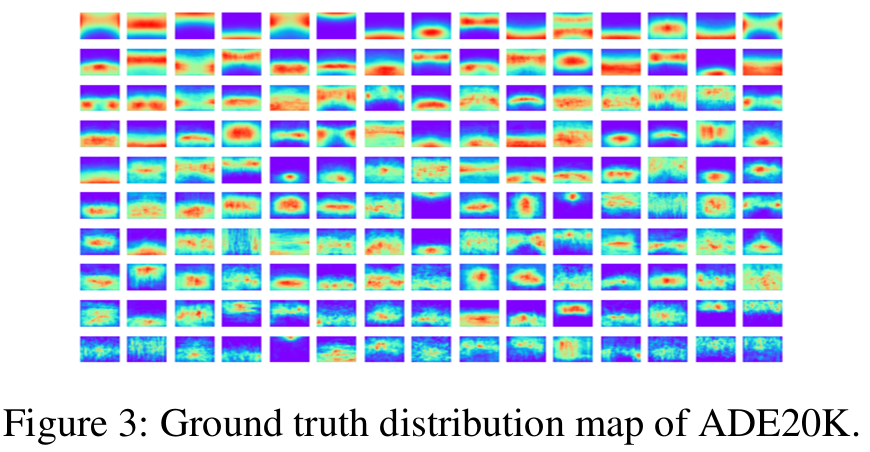
- 在语义分割上,目标有位置先验,例如天空出现在上方,因此可以将位置分布(如论文图3)作为全零图像的标签,来引入位置先验。
- 在目标检测上,背景与全零图像缺乏检测对象,因此背景可以用于抑制检测框存在,全零图像可以用于维持检测框的位置一致性(如令不同位置的检测特征保持一致)。
- 在知识蒸馏上,模型只需要传递对特定输入的输出,因此可以只用噪声输入来传递模型输出,避免对图像-标签对的依赖。
- 在超分辨率上,全零图像没有纹理变化,全零放大之后还是全零,因此全零图像可以抑制噪声;同时,根据已知算法构造输入图像与输出图像,可以学习纹理信息,同时摆脱生成低分辨率数据的下采样算法。
- 在图像检索上,可以拉远非目标对象与目标对象的距离,例如服饰、背景、拍摄角度、光照等目标无关的数据。
论文介绍
- 这里主要介绍本工作发现的现象、相关概念、提出方法与主要实验。更多内容请见论文。
摘要
- 分类有两种公平性:
- 长尾分布(Long-tail distribution):模型更偏向于实例数多的头部类别。
- 注:在长尾分布中,实例数多的类别称为头部(Head)类别,实例数少的称为尾部(Tail)类别。
- 注:长尾分布造成的偏见来源于模型训练过程是一个经验风险最小化[1]的过程,因此常出现的类别受重视,罕见的类别被忽视。
- [1] Vapnik V. Principles of risk minimization for learning theory[J]. Advances in Neural Information Processing Systems, 1991, 4.
- 注:举例来说,如果训练数据中有99%的狗,1%的猫,那么模型在分类时会更偏向于狗。
- 汉斯效应(Clever Hans effect):模型错误地将非鉴别性特征用于分类。
- 注:非鉴别性(Non-discriminative)特征指的是与目标没有必然联系的无关信息,例如背景、光照、拍摄视角等是常见的无关信息。
- 注:汉斯效应[2]来源于一匹叫Hans的德国马,被误认为会进行数学计算,但实际上是对肢体动作作出反应。
- [2] Anders C J, Weber L, Neumann D, et al. Finding and removing clever hans: Using explanation methods to debug and improve deep models[J]. Information Fusion, 2022, 77: 261-295.
- 注:举例来说,如果训练数据只有黑狗和橘猫,那么颜色会错误成为物种分类依据,但现实世界也有黑猫,颜色并不能作为依据。
- 长尾分布(Long-tail distribution):模型更偏向于实例数多的头部类别。
- 在本文中,我们发现类别无关(Category-agnostic)的全零图像能够同时揭露两种类型的不公平性。
- 注:由于全零图像没有纹理变化,值均为零,通常不会归类于任一类别,因此我们称其为类别无关。
- 基于此,我们提出ZUT框架(Zero Uniformity Training, ZUT)以优化公平性。
- ZUT框架将类别无关的全零图像并行地输入至模型,并将结果送入ZUL损失(Zero Uniformity Loss, ZUL)以优化公平性。
- 注:例如,分类任务中输入
(B, 3, H, W)的数据,我们插入一个全零图像变成(B+1, 3, H, W),以实现并行的计算。
- 注:例如,分类任务中输入
- ZUL损失通过均衡化全零图像对应的分类结果,来消除对特定类别的偏见。
- 注:例如,二分类中,全零图像在两个类上的分类概率为
0.9, 0.1,我们希望它能够得到0.5 0.5的均匀分布。
- 注:例如,二分类中,全零图像在两个类上的分类概率为
- ZUT框架能够兼容于多种基于分类的任务。
- 注:不只是图像分类,任意使用分类器的任务应该都行,例如像素级别分类的语义分割,用于坐标回归的姿态估计。
- ZUT框架将类别无关的全零图像并行地输入至模型,并将结果送入ZUL损失(Zero Uniformity Loss, ZUL)以优化公平性。
- 实验表明,ZUT框架能够在图像分类、换装行人再辨识与语义分割任务上提升多种SOTA(State Of The Art, SOTA)模型的性能。
- 注:这三个任务中,分类器有不同的用法:
- 图像分类:训练与推理均使用分类器。
- 换装行人再辨识:仅在训练使用分类器。
- 语义分割:训练与推理均使用分类器,但在像素级别进行分类,前两者在样本级别。
- 注:这三个任务中,分类器有不同的用法:
动机
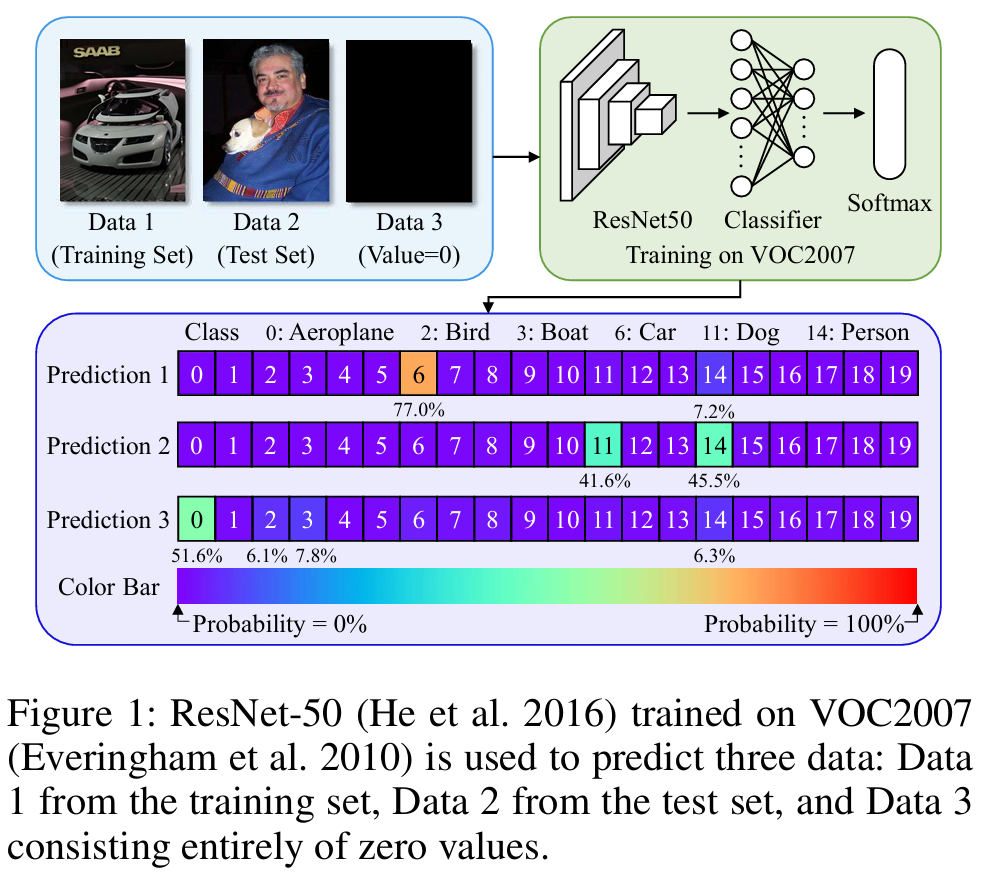
- 如上图所示,我们选择三份样本进行展示,分别来自训练集、测试集与全零图像。
- 可以看到,来自训练集与测试集的图像中,目标类的概率远高于其它类别,表明模型学习到了分类信息。
- 长尾分布:
- 在数据1与数据3中,“人”的概率相对其它负类更高。
- 观察训练集分布,发现几乎一半的数据包含“人”。
- 汉斯效应:
- 数据3被分类为“飞机”、“鸟”、“船”的概率相对较高。
- 这可能是因为这三者的背景通常是天空与海面,而天空/海面的材质较为平滑,和全零图像一样缺乏纹理变化。
- 因此,全零图像≈天空背景,因为它们材质平滑;同时,天空背景≈飞机,因为他们经常同时出现在一张图像。最终,全零图像≈飞机,分类概率为51.6%。
- 可以看到,类别无关的全零图像本不应该被分类为人或者飞机,但却错误的呈现了明显的偏见。
- 因此,我们选择抑制全零图像在分类上的偏见,来优化模型的公平性。
贡献
- 我们提出使用类别无关的全零图像来揭露由长尾分布与汉斯效应引起的分类不公平。
- 我们提出ZUT框架,其利用全零图像进行训练,并使用ZUL损失抑制偏见,进而优化模型公平性。
- ZUT框架在图像分类、换装行人再辨识、语义分割上提升了SOTA模型的性能。
方法-ZUT框架


- ZUT框架如图2所示,其伪代码如算法1所示。
- 在图2中,
- 现有的分类框架为左侧的绿色部分, B B B张图像输入至模型,经过分类器得到分类结果后,利用分类损失 L c l s \mathcal{L}_{cls} Lcls学习分类信息。
- 我们提出的ZUT框架为右侧的蓝色部分,并行地将全零图像输入至模型,经过分类器得到分类结果后,利用ZUL损失 L z \mathcal{L}_{z} Lz优化公平性。
- 在算法1中,
- 首先生成全零图像 z z z,全零图像的通道数、高度与宽度与正常图像一致。
- 随后将全零图像 z z z与正常图像 x x x在 B B B维度进行拼接,以实现并行的分类计算。
- 将拼接结果送入模型与分类器得到分类结果 f f f。
- 拆分分类结果 f f f以得到全零图像与正常图像的分类结果 v v v与 u u u。
- 计算分类损失与ZUL损失,为ZUL损失引入损失权重 α \alpha α,损失相加以得到最终损失。
- ZUT框架仅参与训练过程,且损失权重 α \alpha α是唯一的超参数。
- ZUT框架的兼容性强,因此我们将其应用在三个基于分类的任务上:
- 图像分类:训练与推理均使用分类器。
- 行人再辨识:仅在训练使用分类器。
- 语义分割:训练与推理均使用分类器,但在像素级别进行分类,前两者在样本级别。
- 在图像分类与行人再辨识中,其算法如算法1所示。对于语义分割,由于其还需要在像素级别进行分类,因此还需要考虑空间位置的影响,具体将在下节讨论。
方法-ZUL损失
- ZUL损失的优化目标是抑制分类结果存在的偏见,我们设计了三种优化方式的ZUL损失:
- 基于标准差的 L z s t d \mathcal{L}_{z}^{std} Lzstd,分类特征差异最小化:
-
- 基于均值的 L z m e a n \mathcal{L}_{z}^{mean} Lzmean,分类特征向零优化:
-
- 基于熵的 L z e \mathcal{L}_{z}^{e} Lze,分类概率熵最大化:
-
- 基于标准差的 L z s t d \mathcal{L}_{z}^{std} Lzstd,分类特征差异最小化:
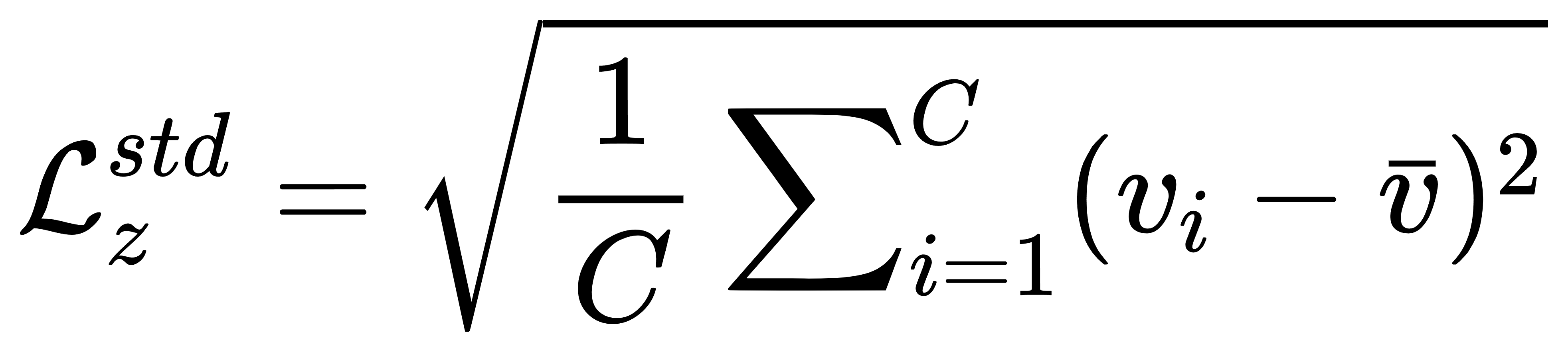
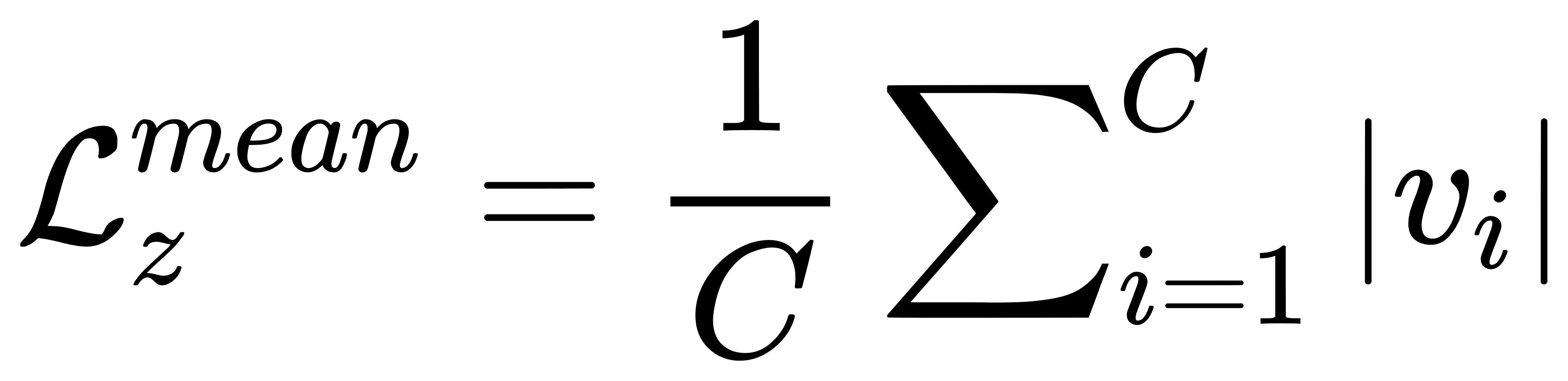
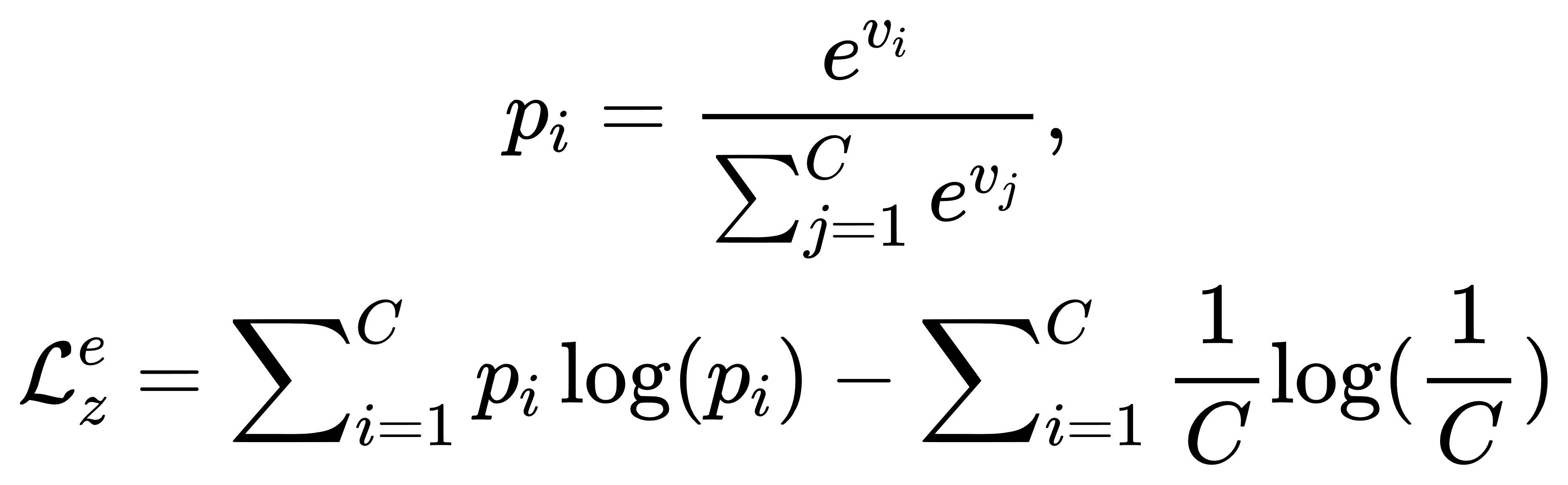
- 在图像分类与行人再辨识中,分类特征都是一维的,仅对类别进行分类。而在语义分割中,分类特征是三维的,是在空间位置上对类别进行分类。
- 因此,语义分割的损失需要特别处理:
- 一种简单的做法是在空间位置上也进行公平优化。
- 然而,如图3所示,我们可视化了语义分割经典数据集ADE20K,发现目标有明显的位置先验。
- 这种位置先验与现实世界相符,例如天空常出现在图像上方。
- 同时,像自动驾驶这类语义分割的典型应用任务中,相机视角是固定的,例如行人与车辆通常在固定区域出现。
- 因此,我们利用全局平均池化(Global Average Pooling, GAP)保留位置信息,仅对类别上总的概率分布进行公平性优化:
-
- 然而,如图3所示,我们可视化了语义分割经典数据集ADE20K,发现目标有明显的位置先验。
- 一种简单的做法是在空间位置上也进行公平优化。
- 因此,语义分割的损失需要特别处理:
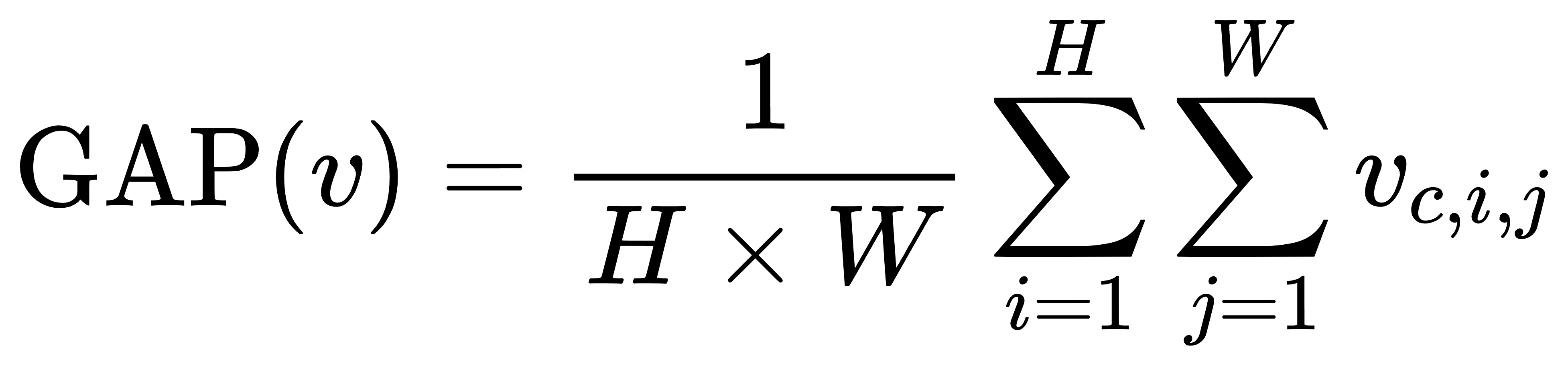
讨论
- 输入类型:
- ZUT框架使用全零数据作为输入来均衡化分类输出。
- 全零数据的使用目的是为了引入一个类别无关的数据,这意味着任意类别无关的数据均可以被使用。
- 例如在随机擦除[3]中使用的全一数据、正则化时的均值、随机值。
- Zhong Z, Zheng L, Kang G, et al. Random erasing data augmentation[C]. AAAI Conference on Artificial Intelligence, New York, USA, 2020:13001-13008.
- 效率:
- ZUT框架只引入一个新的损失,且并行的参与训练过程,因此其训练性能消耗约为 1 B \frac{1}{B} B1。
- 此外,ZUT并不修改模型,同时不参与推理阶段,因此不影响推理性能(如模型大小或推理速度)。
实验-对比实验与消融实验
 |  |  |
|---|---|---|
| 图像分类 | 换装行人再辨识 | 语义分割 |
- 本部分的所有实验,均使用全零图像作为输入,使用基于标准差的 L z s t d \mathcal{L}_{z}^{std} Lzstd作为损失函数。
- 在图像分类上,我们以ResNet-50、Eva02-tiny、Riformer-s12与Poolformer-s12作为Baseline,在VOC2007与CIFAR100-LT数据集上进行评估。
- 在换装行人再辨识上,我们以ResNet-50作为Baseline,在PRCC、VCClothes、Celeb-ReID与CCVID数据集上进行评估。
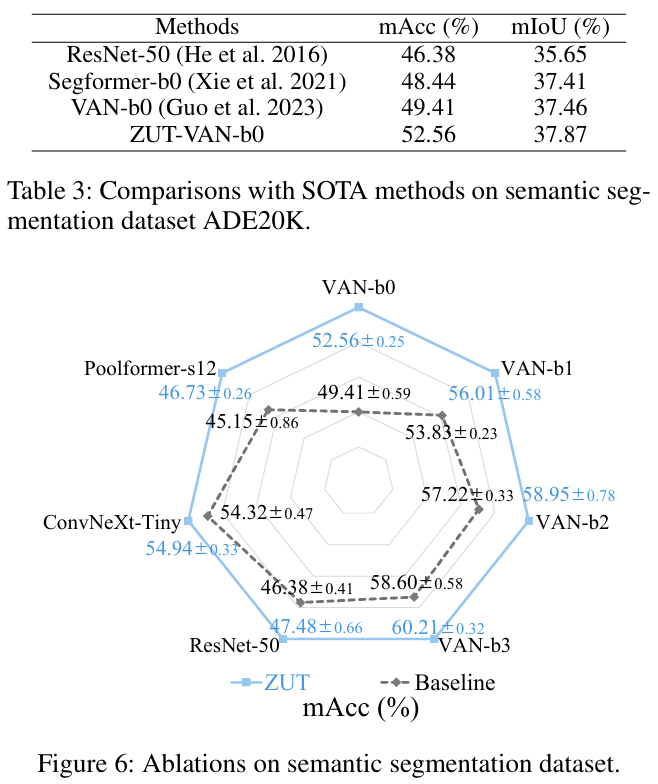
- 在语义分割上,我们以VAN-{b0, b1, b2, b3}、ResNet-50、ConvNeXt-tiny与Poolformer-s12作为Baseline,在ADE20K数据集上进行评估。
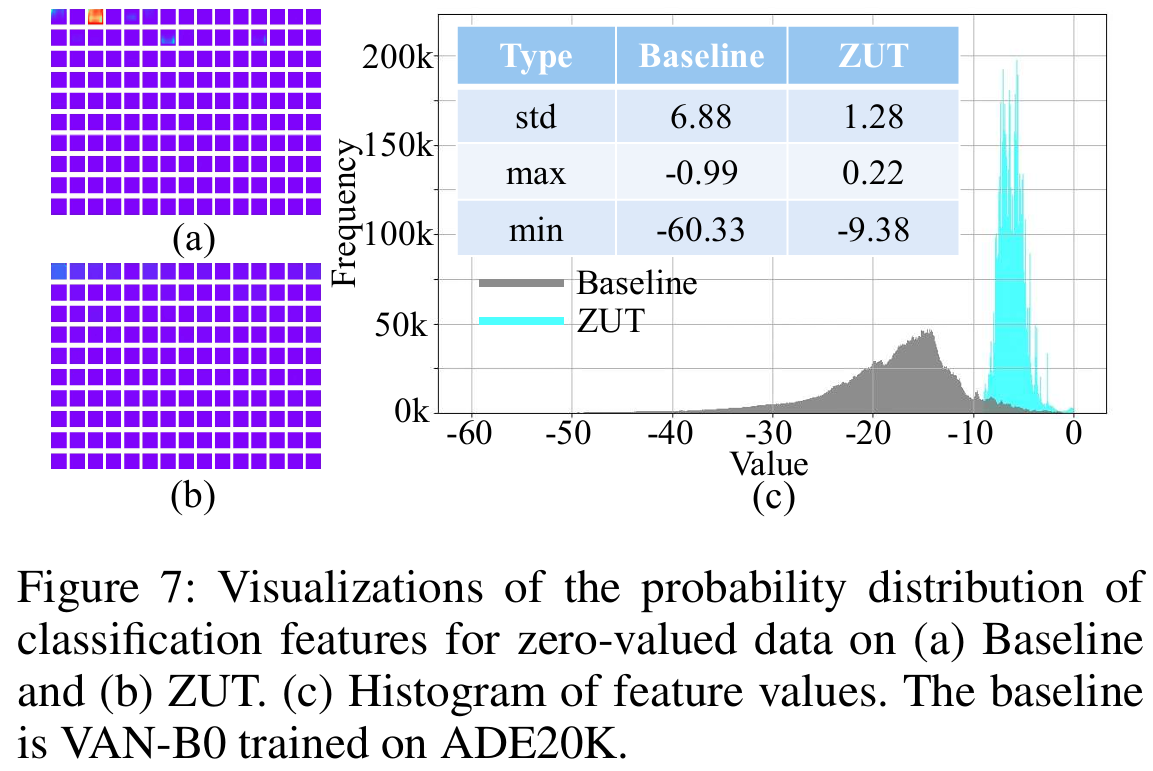
- 在语义分割上的可视化如下图,可视化对象为分割解码器输出的 ( C , H , W ) (C, H, W) (C,H,W)分割特征。
- 图(a)中第一行第三列的高激活区域,在图(b)上被抑制,表明ZUT框架修正了这种不公平。
- 在图©上,分割结果更加集中,从另一个角度展示了ZUT框架抑制不公平的能力。
- 在语义分割上的可视化如下图,可视化对象为分割解码器输出的 ( C , H , W ) (C, H, W) (C,H,W)分割特征。
实验-损失权重
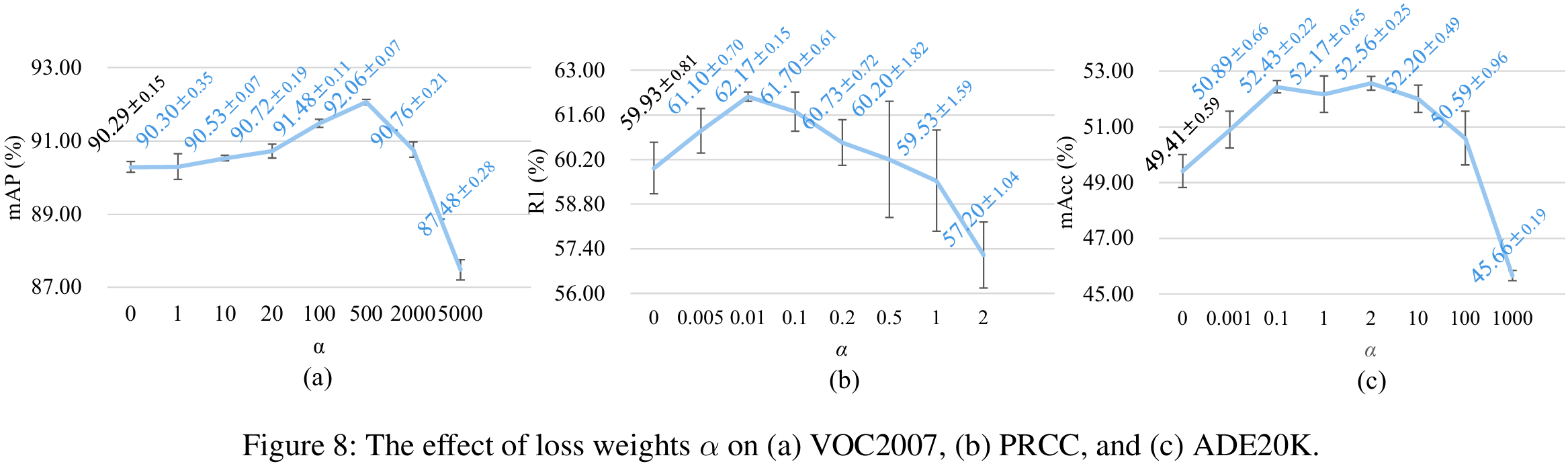
- 在三个任务上,损失权重的影响如上图。
- 可以看到,损失的有效范围较大,例如在VOC2007上,从1~2000的损失权重均有效。
- 在换装行人再辨识数据集PRCC上的范围相对较小,可能由于该任务公平性较高,例如各身份的样本数大致相同,且只能依靠面部、姿态等身份相关信息进行分类。
- 可以看到,损失的有效范围较大,例如在VOC2007上,从1~2000的损失权重均有效。
实验-输入类型
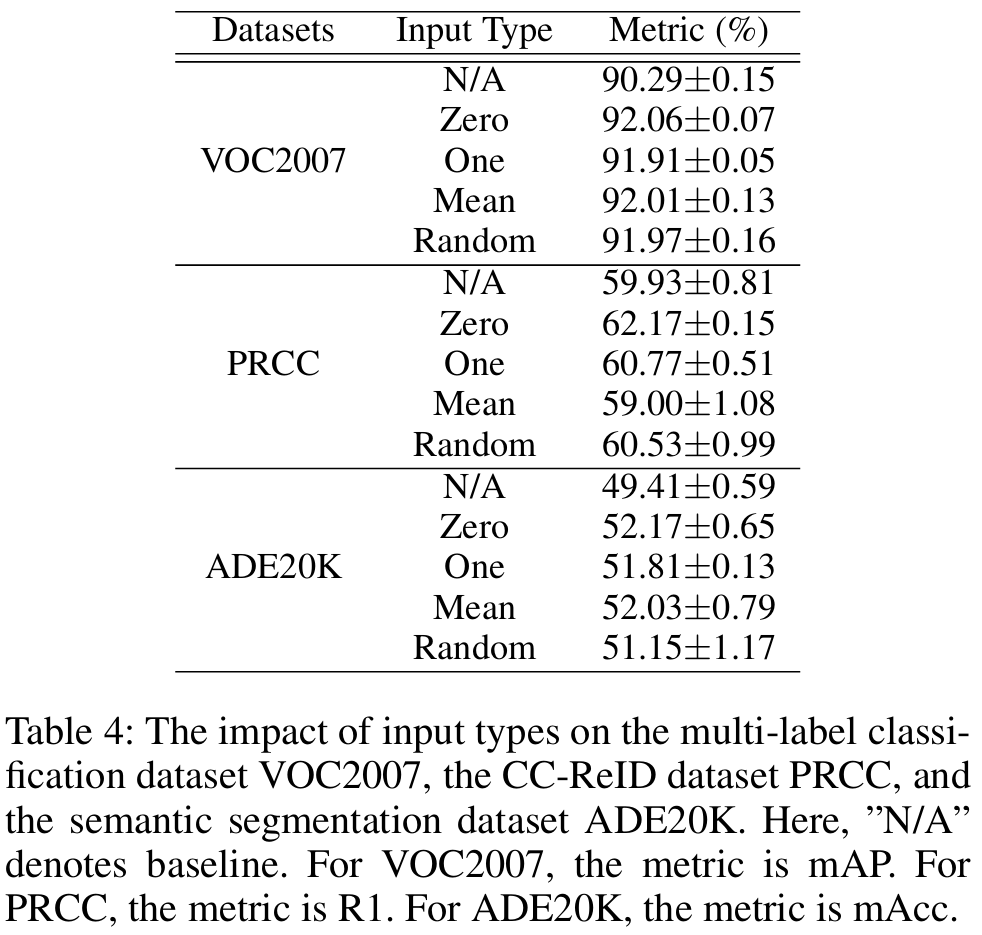
- 在三个任务上,不同输入类型的影响如上表。
- 以全零图像的最优损失权重作为其余数据的损失权重。
- 可以看到,几乎所有类型均有效,仅在换装行人再辨识数据集PRCC上,均值表现不佳。
- 我们前期的猜测是由于该任务使用随机擦除作为数据增强,而随机擦除同样使用均值,导致两者冲突。
- 但在后续的实验中,我们发现调整一下损失权重就有效了,因此,和随机擦除的冲突可以通过调参优化。
实验-损失类型
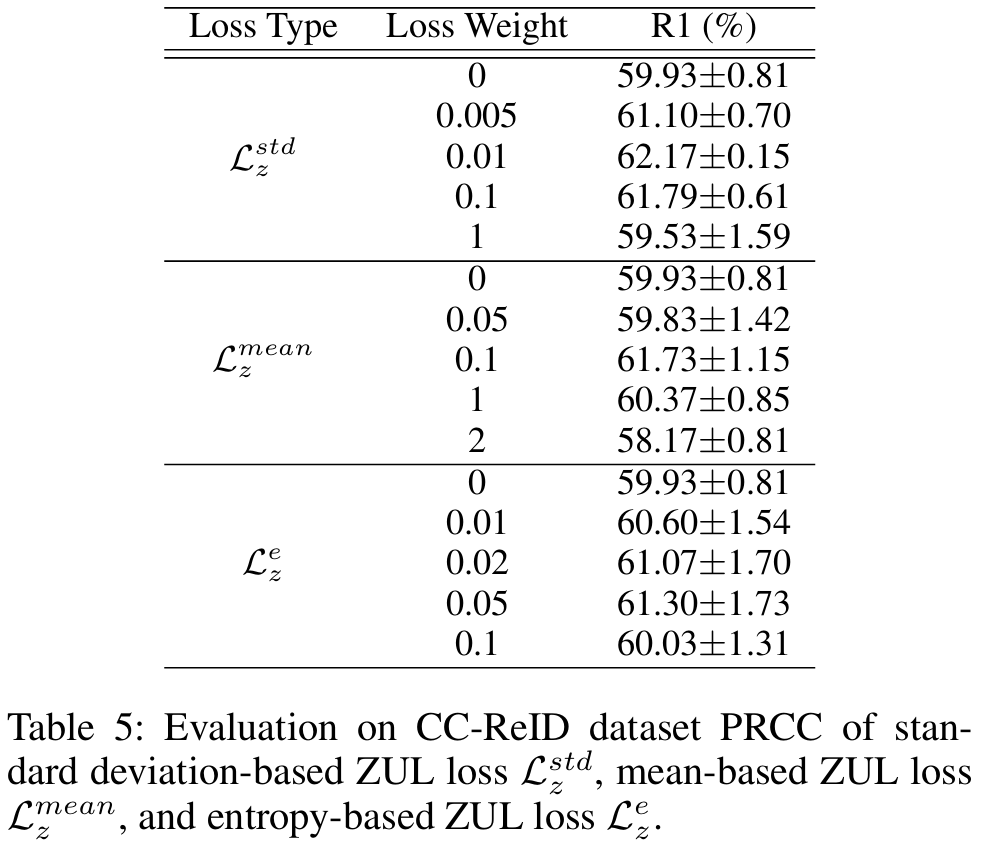
- 在换装行人再辨识数据集PRCC上,三个损失在不同权重下的表现如上表。
- 结果表明,从不同方向抑制偏见的三个损失均有效。
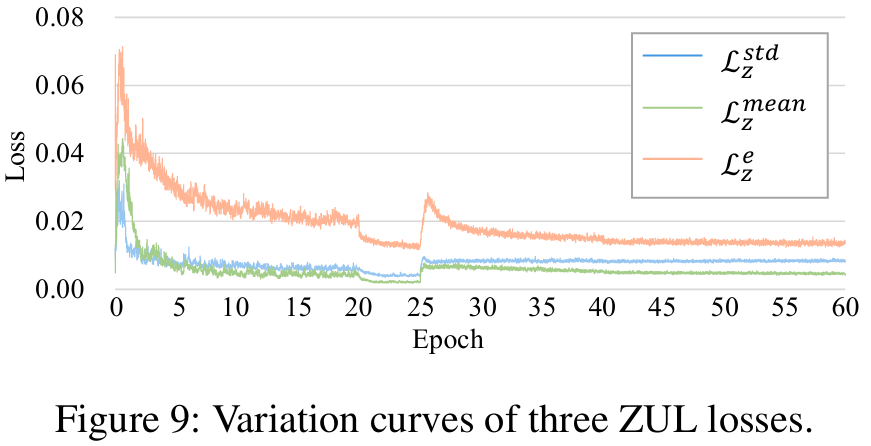
- 损失曲线如下图。
- 可以看到,损失权重先增后减,表明模型无意识学习到了不公平性,并被本方法有效抑制。
- 第20、25、40轮有曲线波动,来自于外部变化。在20与40轮,学习率变化。在第25轮,Baseline所用的CAL损失被启用。
引用本文
@inproceedings{Fairness_ZUT_WJPan,author = {Pan, Wenjie and Zhu, Jianqing and Zeng, Huanqiang},title = {Fair Training with Zero Inputs},booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},volume = {39},pages = {6317-6325},address= {Pennsylvania, USA},year = {2025},type = {Conference Proceedings}
}