基于MediaPipe的手指目标跟踪与手势识别+人体姿态识别估计:MediaPipe与OpenPose算法对比
1 摘要
本实验主要分为两个部分,第一部分是使用MediaPipe提供的Hand检测器实现手指点位跟踪以及使用SVM支持向量机完成手势识别;第二部分是对比MediaPipe提供的Pose检测器与OpenPose算法对人体姿态识别的效果。
在完成上述实验后可以得到如下结论:基于MediaPipe进行手指目标跟踪和手势数字识别的效果均非常出色,能够实现实时跟踪和识别,计算效率高;在姿态评估上OpenPose的姿态识别效果更加出众,能够实现多人姿态的检测,而MediaPipe在人物丰富的情况下容易出现漏检和点位误判。
2 整体方法和模型原理描述
本次实验我按照以下步骤执行:
Step1:阅读MediaPipe和OpenPose论文
Step2:查找资料完成MediaPipe的手指点位跟踪实验;
Step3:寻找0-9各手势数据集,编写基于MediaPipe的手势识别代码;
Step4:查找OpenPose开源代码,完成人体姿态识别跟踪;
Step5:使用MediaPipe构建人体姿态识别跟踪代码;
Step6:对比人体姿态识别实验效果,分析并得出结论;
模型原理部分参考了https://arxiv.org上关于MediaPipe和OpenPose的两篇论文,因此该部分我分为了两个模块,依次介绍MediaPipe机器学习框架以及OpenPose基本原理。
2.1 MediaPipe
MediaPipe是由Google开发的开源跨平台机器学习框架,专注于实时和流媒体应用。它提供易于集成的解决方案,支持移动设备、Web和桌面等多种平台。MediaPipe的核心功能包括预训练模型和可定制的API,允许开发者快速实现手势跟踪、面部识别等复杂功能。
2.1.1 MediaPipe的使用
1. 人脸检测
MediaPipe人脸检测所用模型是BlazeFace的变体,BlazeFace 是谷歌19年提出的一种针对移动 GPU 推断进行优化的轻量级且精确的人脸检测器。该检测器的超实时性能使其可应用于其他需要准确地关注面部区域的模型。
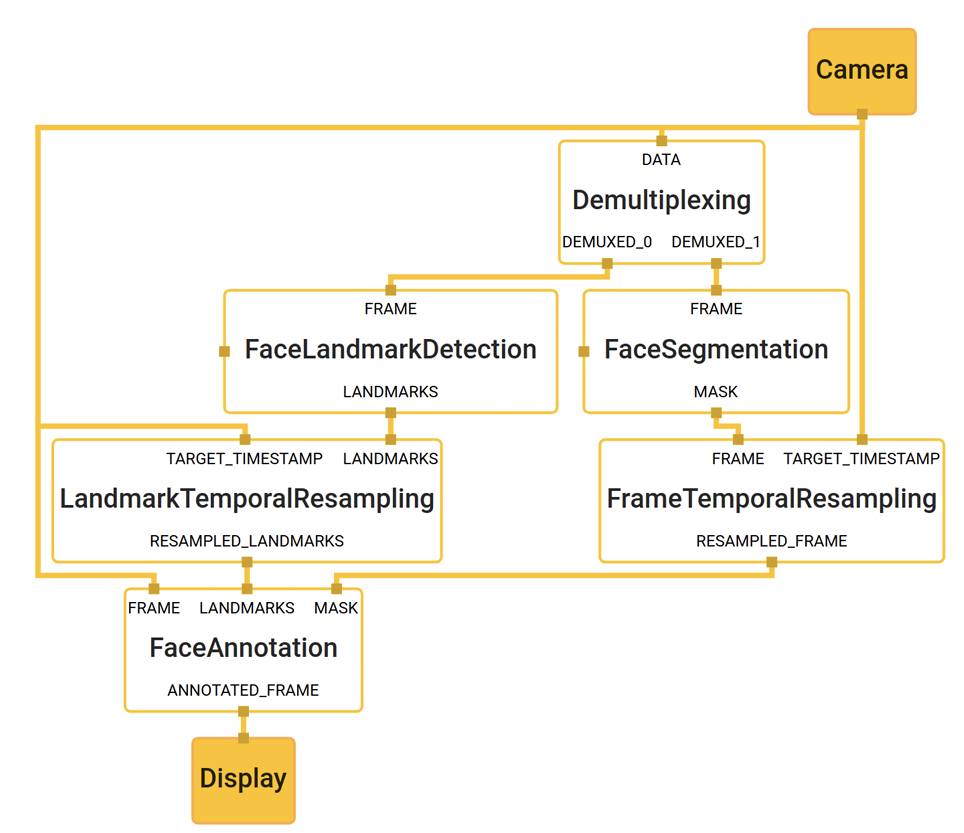
图一 脸部检测组件
BlazeFace是Google专为移动端GPU定制的人脸检测方案,有如下创新点:
1. 专为轻量级检测定制的紧凑型特征提取网络,类似于MobielNet;
2. 相比SSD模型,对GPU更友好的anchor机制;
3. 采用“tie resolution strategy”而非NMS处理重叠的预测结果
关于BlazeFace模型详细情况可参考https://arxiv.org/abs/1907.05047,下面时脸部检测器的实际应用。
具体步骤:
- 导入mp.solutions.face_mesh模块,该模块包含面部网格相关的功能;
- 利用该模块创建FaceMesh()实例;
- 设置static_image_mode为False指定将该FaceMesh将在视频流模式下运行;
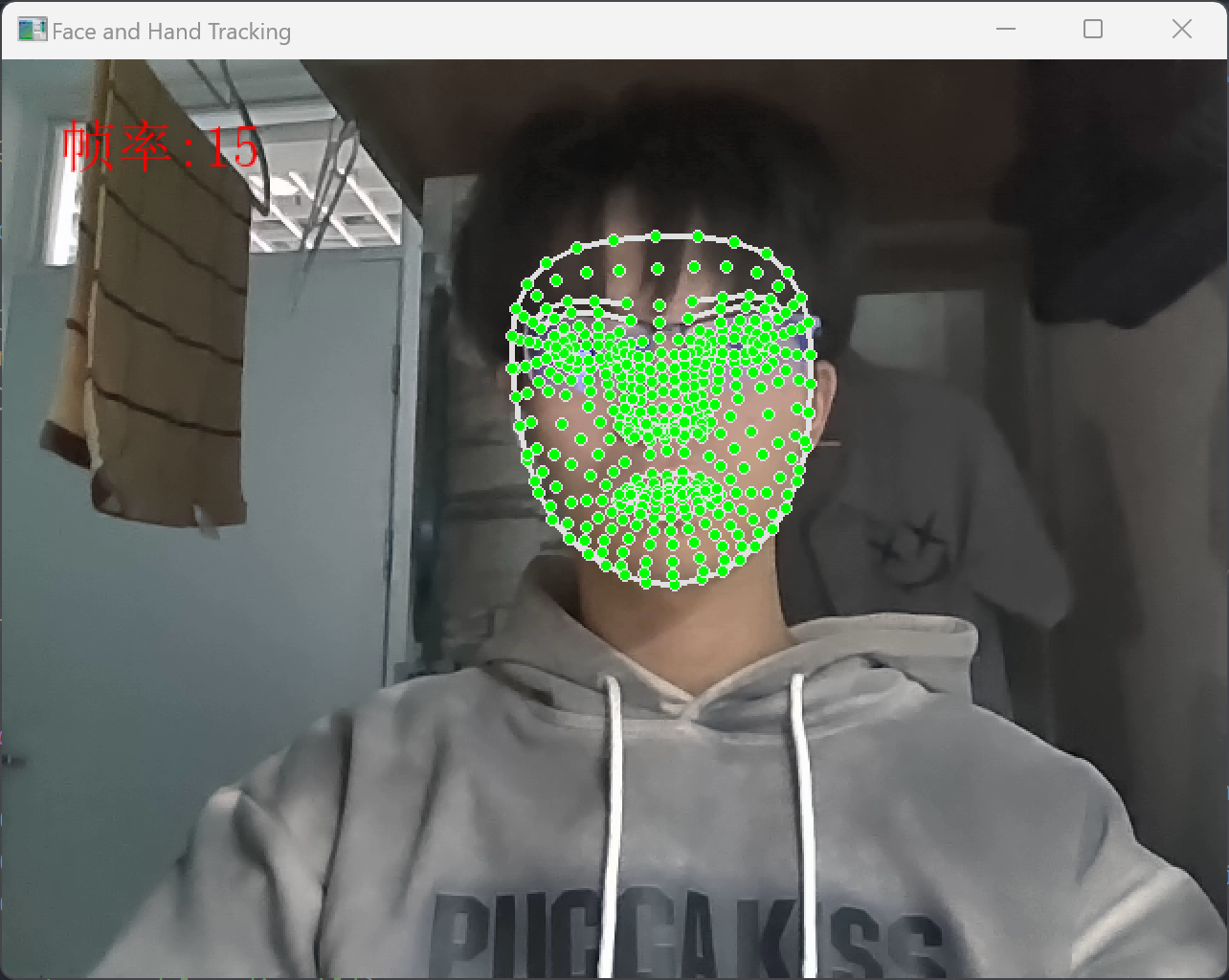
图二 脸部检测效果图
2. 手部检测器
手部检测数据处理流水线由两个模型组成:
- 手掌检测器:提供手的边界框;
- 手部坐标估计模型:预测手的骨架;
手掌检测器使用了NMS非极大值抑制算法与类FPN特征金字塔网络网络编码特征提取器,训练过程使用了FocalLoss,以支撑大尺度方差产生出来的锚框;手部坐标预测模型通过回归预测手部2.5D的关键点坐标,关键点坐标回归模型能学到内在的一致性手部姿势表示,能在手部部分缺失时或自遮挡的情况下表现出非常好的鲁棒性。同时该模型还能有效辨别输入的手时左手还是右手。
手部坐标共21个关键点,坐标表示维度二维x、y坐标加上相对于手腕的三维深度坐标z。
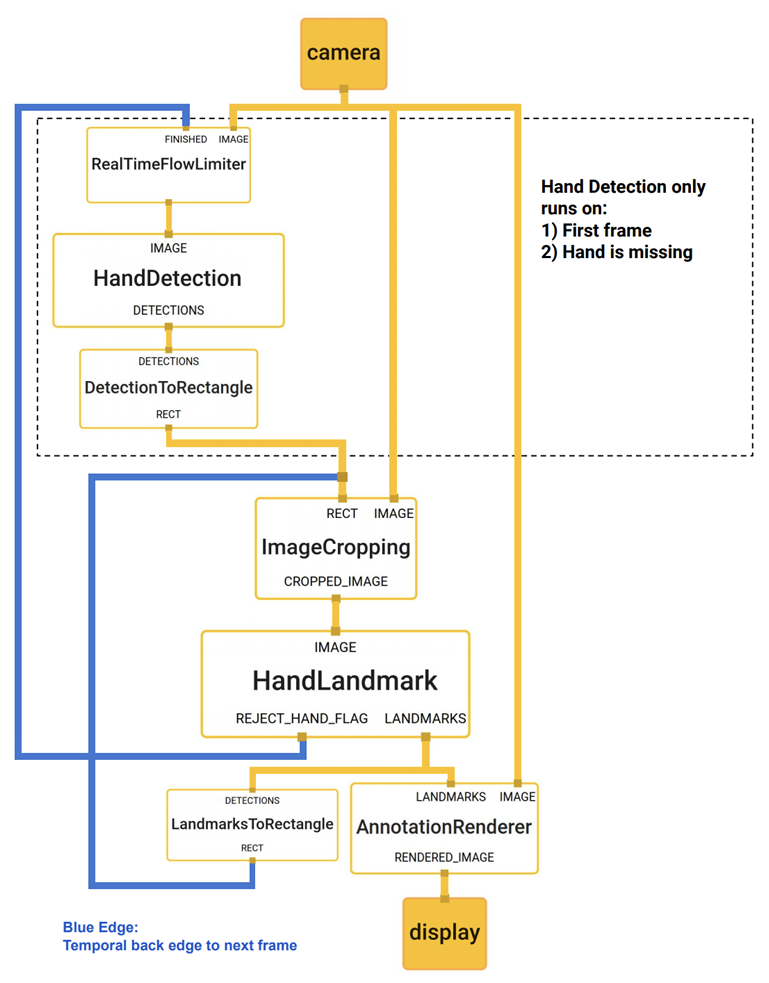
图三 手部检测组件
手部检测器的使用方式如下:
- 导入mp.solutions.hands模块,该模块包含了手掌检测以及坐标估计功能;
- 利用该模块创建Hands()实例;
- 设置static_image_mode为False指定将该Hands将在视频流模式下运行,实现实时跟踪;
- 设置max_num_hands为2表示最多只能检测出两只手;
- 设置min_tracking_confidence为0.5,只有当模型对其跟踪的手部关键点的置信度至少为0.5时关键点才会被考虑;

图四 手部+人脸检测效果图
3. 姿势检测器
MediaPipe Pose是利用BlazePose模型从RGB视频帧推断出整个身体上的33个3D地标和背景分割掩码。在使用Pose检测器时,管道首先在帧内定位人/姿势感兴趣区域(ROI),跟踪器随后裁剪帧ROI作为输入来预测ROI内的姿势标志和分割掩码。
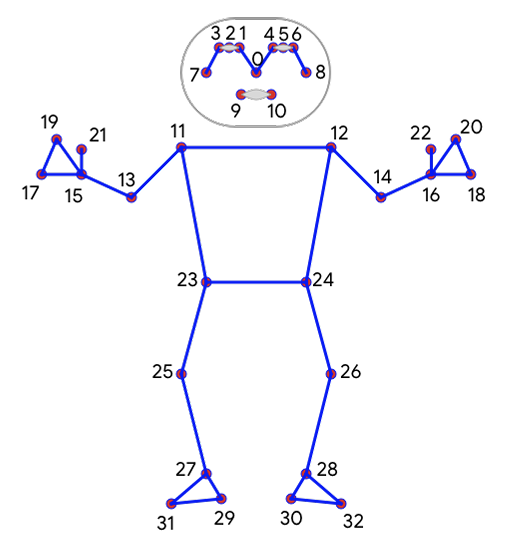
图五 人体关键点拓扑图
Pose姿势检测器的使用方式如下:
- 导入mp.solutions.pose模块,该模块包含了计算人体各关键点的部分;
- 利用该模块创建Pose实例;
- 设置static_image_mode为True指定将该Pose将在静态图模式下运行;
- 设置smooth_landmarks为True,启动关键点平滑,减少抖动和噪声;

图六 姿态检测效果图
2.2 OpenPose
OpenPose是一个由CMU和Intel联合开发的开源框架,专注于实时多人人体姿态估计,它能够检测图像或视频中的人体关键点,并提供手部和面部关键点的检测,支持跨平台运行,适用于多种应用场景。
2.2.1 Bottom-up
OpenPose采用的bottom-up方式,先检测出图片中所有的人体关键点,然后将这些关键点对应到不同的人物个体。
已有的bottom-up算法未能利用全局上下文先验信息,即图片中其他人身体的关键点信息,并且将关键点对应到不同的人物个体算法复杂度太高,因此在OpenPose原论文中提出了新的方法——PAFs,用于表征位置和方向信息,然后通过这些信息使用greedy inference算法将关节点快速对应到不同人物个体。(匈牙利算法)
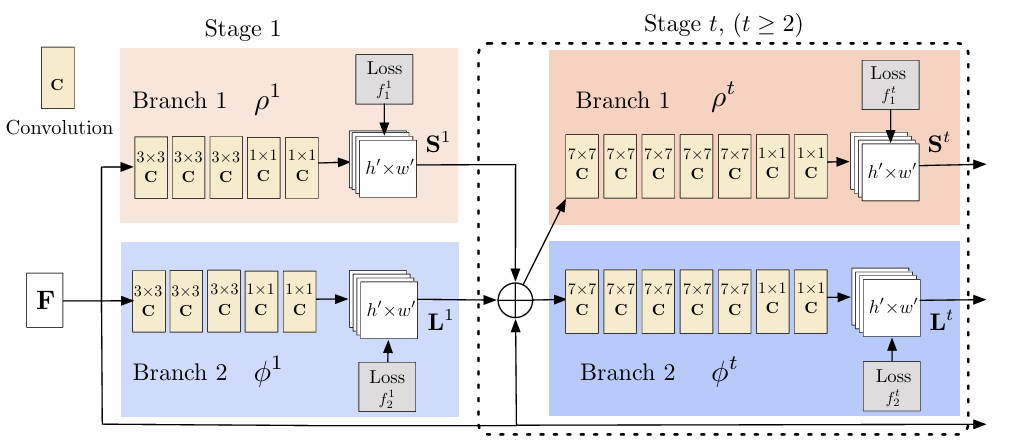
图七 OpenPose核心网络架构
2.2.2 双分支多阶段CNN
由图七可知,网络结构中共有两个分支,其中一个分支用于预测打分(S),另一个分支用于预测PAFs(L),对应着热图(heatmap)和向量图(vectormap),F是输入的特征。
每个阶段网络的输入为:
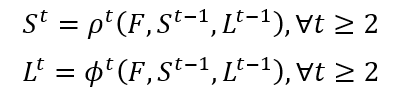

图八 两个分支的计算结果
从上图可以看到,图(b)表示检测到的关节点,一个部位对应了一张feature map;图(c)表示检测到的一段躯干,一个躯干也对应一个feature map。
2.2.3 关节拼接与多人检测
1. 关节拼接
对于任意两个关节点位置dj1 和dj2 ,通过计算PAFs的线性积分来表征骨骼点对的相关性,同时也表征了骨骼点对的置信度,计算公式如下:
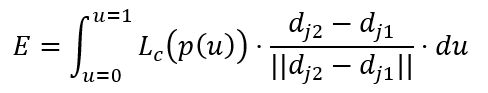
为了快速计算积分,一般采用均匀采样的方式近似这两个关节点之间的相似度,即:
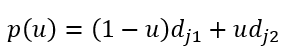
2. 多人检测
由于图片中人数不确定,同时伴随遮挡、变形等问题。因此计算时只使用上述计算关节相似度时只能保证局部最优,因此作者使用了greedy relaxation的思想生成全局较优的搭配。
具体步骤如下:
- 已知不同关节点的heatmap,即不同人的某个关节点的点集;
- 将不同点集进行唯一匹配,比如一个表示手肘的点集和一个表示手腕的点集,两点之间存在唯一匹配;
- 将关节点作为图的顶点,关节点之间的相关性PAF作为图的边权,则多人检测问题转化为二分图匹配问题,使用匈牙利算法求得相连节点的最优匹配;
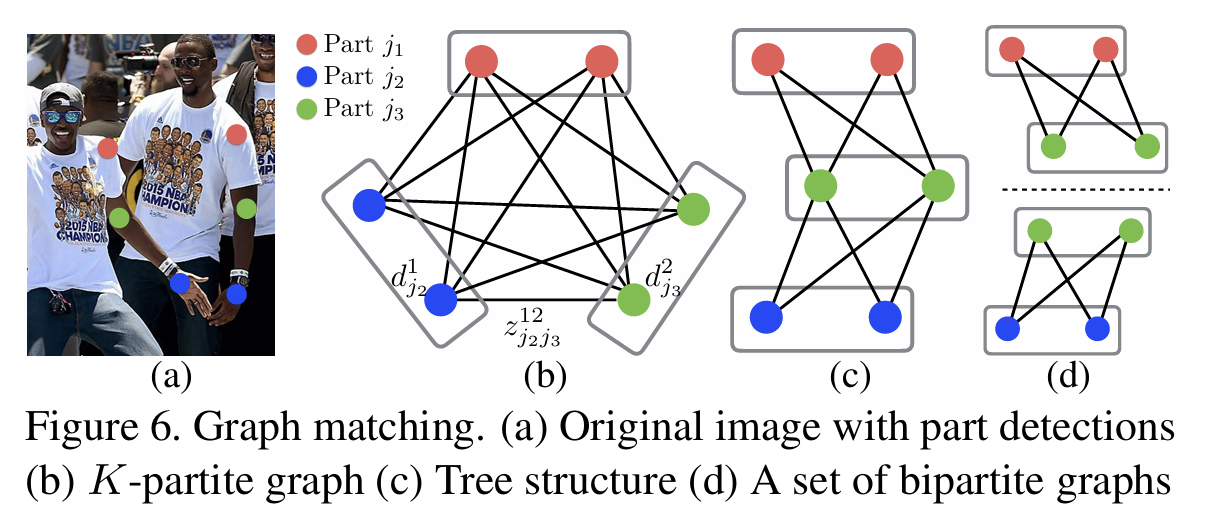
图九 图的三种匹配方式

图十 斯蒂芬·库里
3 实验验证
3.1 实验安排
实验分三个模块,第一个模块实现手部指定点位跟踪;第二个模块实现实时手势数字识别;第三个部分对比MediaPipe与OpenPose在姿态估计上的效果。
3.2 运行环境
MediaPipe是机器学习框架,在无GPU的情况下也能高速运行并取得优异的效果,因此本次实验均在本机上运行(本机无独显),处理器为12th Gen Intel(R) Core(TM) i7-12700H。
3.3 手部点位跟踪
手部点位跟踪实现步骤如下:
- 使用在模型原理部分介绍的方法,初始化Hands实例,并在终端中打印各个点位坐标;
- 指定需要跟踪的点位(例如8号点位),在视频中放大该点位方便观察;
- 以该点位为交点,做水平垂直线将视频画面分割成四部分,并在第二象限实时打印该点坐标;
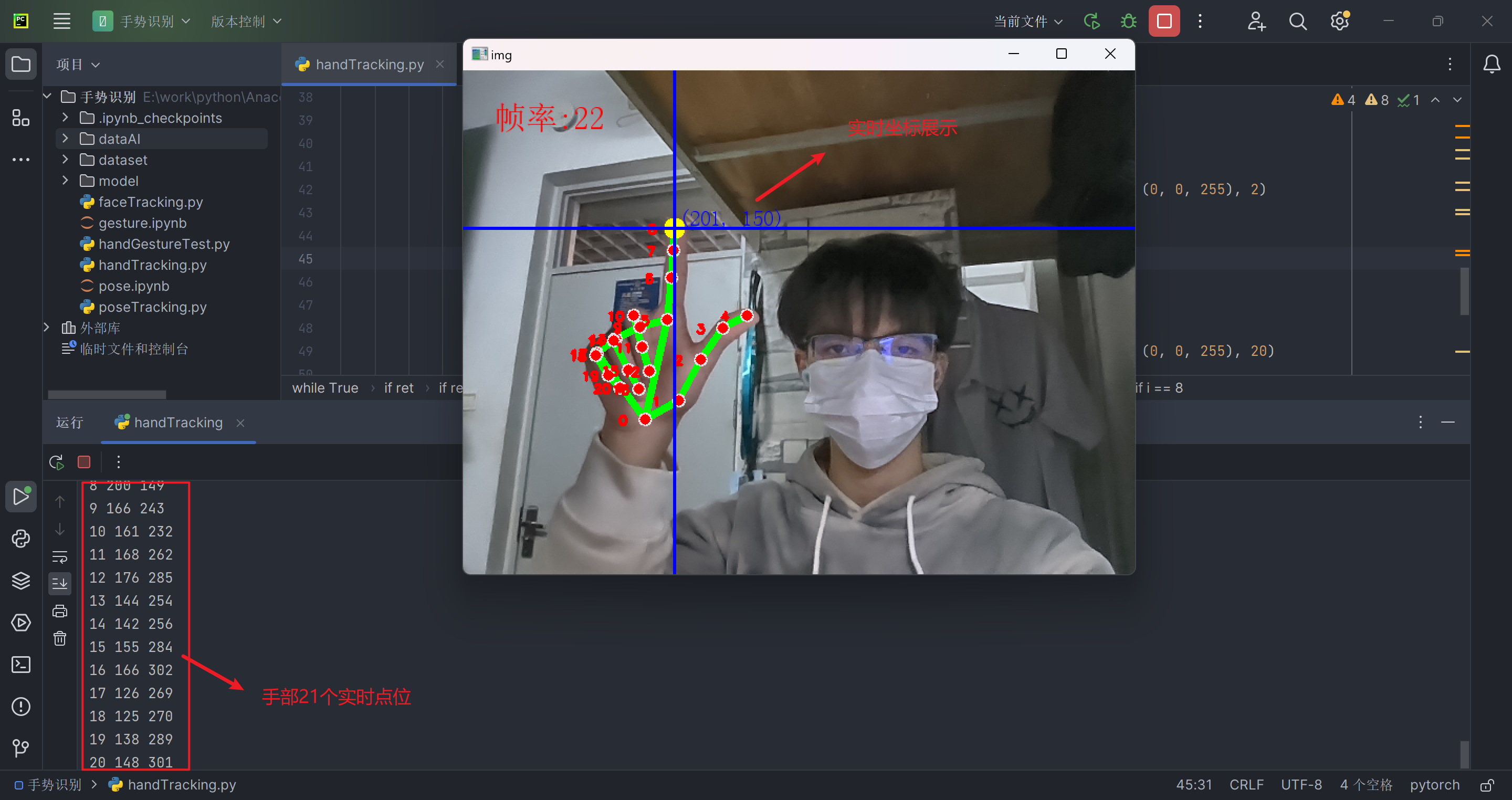
图七 手指指定点位跟踪
3.4 手势数字识别
3.4.1 手部数字数据集
图九展示的是0~9这十个数字的手势表示,从左到右依次为0、1、2、3、4、5、6、7、8、9。手势数字数据集共计2062张,每种手势数据均在206张左右,请注意下面对数字3、6、7、8、9的手势表示。

图九 手势数字展示
3.4.2 数据预处理
在数据预处理部分,使用mp.solutions.hands.Hands()构建手部检测器,通过循环遍历所有手势图片,获取每个手势的二维坐标(x,y)并存放于Dataframe中,后续将该数据集划分为训练集和测试集用于SVC进行训练,在这里需要注意两个地方:
- 对所有点位进行归一化处理;
- 数据集均为右手的手势,在存放到Dataframe之前需将手势坐标镜像翻转,保证数据集中同时包含左右手的数据;
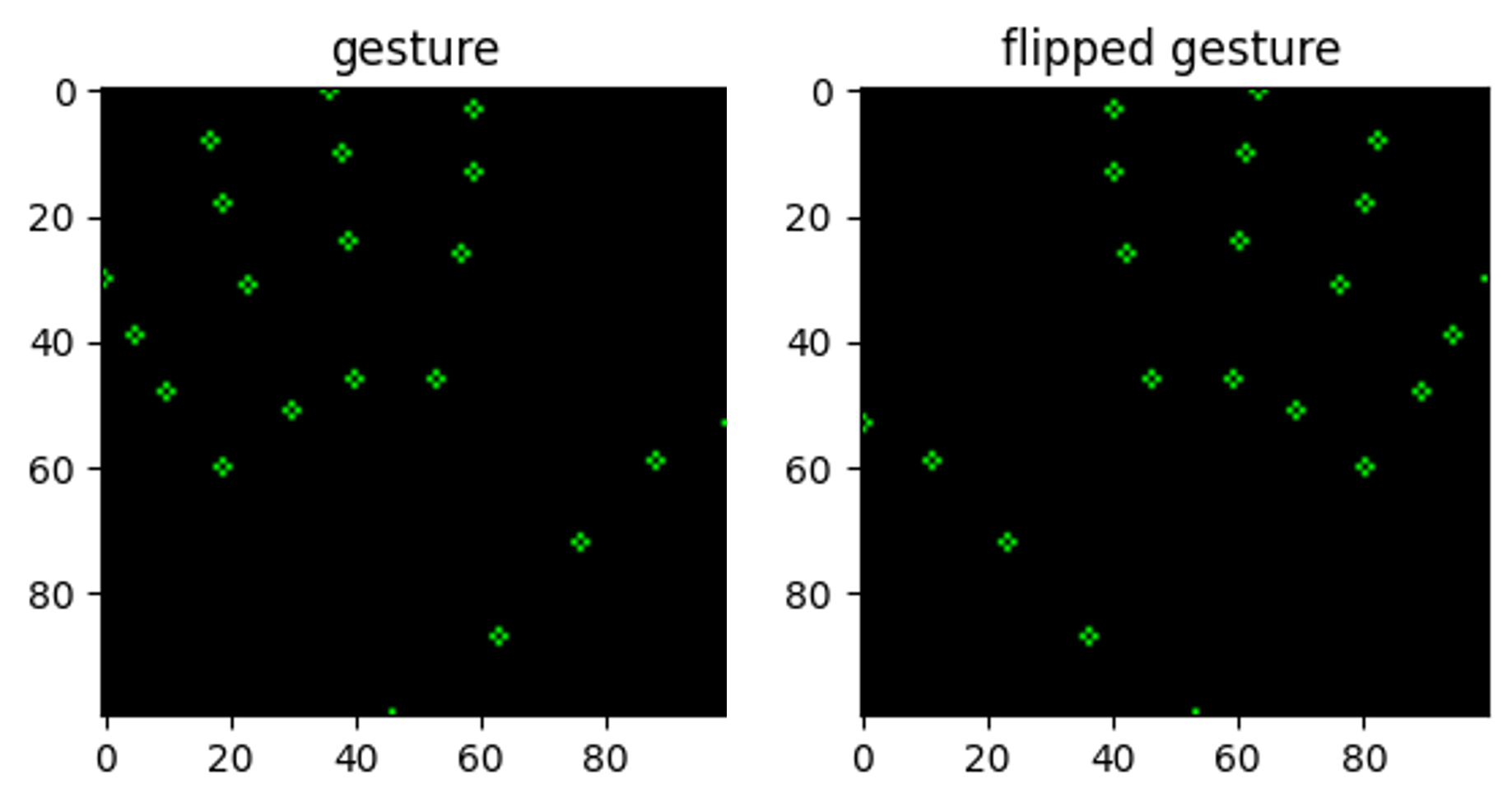
图十 手势点位镜像翻转
3.4.3 SVM
利用scikit-learn库中的SVC类(支持向量机分类器)训练手势识别模型,使用多项式核函数,惩罚参数选择为1.0,并启用概率估计,最终计算得分为99.15% 。
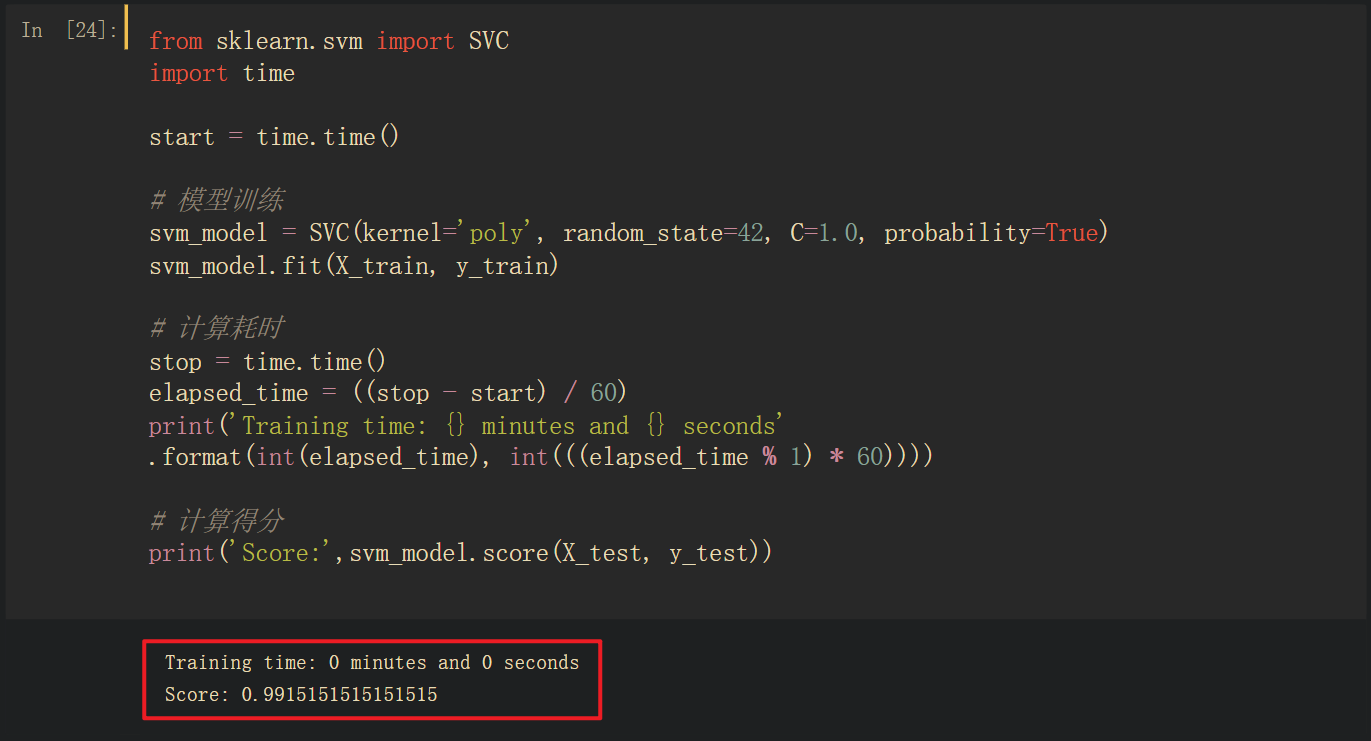
图十一 SVC训练代码
因为是机器学习框架,计算速度很快,但得到的效果也非常棒。如果使用深度学习做图像分类的话,计算效率很有可能会远远低于使用SVC的计算效率,在这里也能体现做一些事情不必进行复杂化,使用简单便捷的方式也能达到比较出色的效果,何乐而不为呢?
image13
手指目标跟踪动画演示
image17
手势数字识别动画演示
通过SVC分类的99.15的高分以及最终的实验效果来看,基于MediaPipe的手势识别效果很好,在这里不在继续调节SVC中的超参数。
3.5 MediaPipe与OpenPose对比
视频素材选取Jabbawockeez(假面舞团)在NBA篮球闭幕式的一段舞蹈视频,分别使用MediaPipe和OpenPose进行姿态识别。
image18
OpenPose姿态识别
image19
MediaPipe姿态识别
对比两段视频可以发现,当视频中出现多个人物时,MediaPipe的检测效果并不好,只能锁定到其中一个人,并且还存在点位的误判和突变等情况,而OpenPose在这种情况下仍然能有出色的检测效果,能将视频中多个人物的关键点都能检测出来。观察OpenPose的检测视频,除了假面舞团,后面的观众也能被检测到,这里也佐证了OpenPose在多人目标下出色的目标跟踪性能。
下面的素材选自抖音,使用OpenPose算法进行姿态识别,纯享版,若有侵权,请联系我删除,谢谢啦。
image20
在人物丰富的情况下,OpenPose完胜MedaiPipe,但MediaPipe也有自己的优点,作为一种机器学习框架,它的优势在于通俗易懂的使用方式和高效的计算速率,在很多方面都是深度学习所不能及的,但具体使用哪种方式还应斟酌。