【python深度学习】Day53 对抗生成网络
知识点:
1.对抗生成网络的思想:关注损失从何而来
2.生成器、判别器
3.nn.sequential容器:适合于按顺序运算的情况,简化前向传播写法
4.leakyReLU介绍:避免relu的神经元失活现象
ps:如果你学有余力,对于 GAN 的损失函数的理解,建议去找找视频看看,如果只是用,没必要学
作业:对于心脏病数据集,对于病人这个不平衡的样本用GAN来学习并生成病人样本,观察不用GAN和用GAN的F1分数差异。
一、概念
简述
对抗生成网络(GAN,Generative Adversarial Network)是一种深度学习模型架构,由生成器(Generator)和判别器(Discriminator)两部分组成,通过两个模型相互对抗、博弈,以达到生成高质量数据样本的目的。
工作原理
- 生成器 :负责从随机噪声中生成逼真的数据样本,如图像、文本等。它类似于一个伪劣艺术家,试图通过学习训练数据的分布,生成能够以假乱真的作品。
- 判别器 :负责判断给定的数据样本是来自真实训练数据,还是生成器生成的假数据。它就像一个专业的艺术评论家,通过不断地审视作品,给出真伪判断。
- 对抗过程 :训练过程中,生成器和判别器相互博弈。生成器不断尝试生成更逼真的样本以欺骗判别器,而判别器则不断学习如何更准确地识别真假样本。在这一过程中,生成器逐渐学习到训练数据的分布规律,生成的样本质量越来越高,判别器的判别能力也越来越强,最终达到纳什均衡,此时生成器生成的样本几乎可以以假乱真。
网络结构
- 生成器结构 :通常以随机噪声作为输入,经过一系列的线性变换、激活函数等操作,逐步将噪声转化为具有一定结构和特征的数据样本,常见的结构有全连接层、反卷积层、批量归一化层等。例如,DCGAN(Deep Convolutional GAN)中的生成器采用反卷积层逐步上采样,将低维噪声映射到高维图像空间。
- 判别器结构 :一般是一个卷积神经网络(CNN),用于接收数据样本并输出其为真实数据的概率值。它通过卷积层、池化层等提取样本的特征,并经过全连接层和激活函数(如 sigmoid)得到概率输出。判别器的设计需要考虑如何有效地捕捉数据样本的真实特征,以便准确地区分真实数据和生成数据。
训练过程
- 初始化 :随机初始化生成器和判别器的网络参数。
- 先训练
判别器:固定生成器的参数,使用真实数据和生成器生成的假数据训练判别器,通过优化损失函数(如交叉熵损失)来调整判别器的参数,使其能够更好地判断数据的真伪。 - 后训练生成器 :固定判别器的参数,使用生成器生成的假数据训练生成器,通过优化损失函数(通常也是基于判别器对假数据的判断结果)来调整生成器的参数,使生成器生成的样本更有可能被误判为真实数据。
- 迭代交替训练 :重复上述训练判别器和生成器的过程,直到达到一定的训练轮数或生成器生成的样本质量达到预期。
应用领域
- 图像生成与编辑 :用于生成高质量的图像,如人物肖像、风景图等;还可以进行图像的风格转换、超分辨率重建、图像修复等图像编辑任务。
- 文本生成 :在自然语言处理领域,GAN 可以用于文本生成,如生成新闻报道、故事、诗歌等,也可以用于文本到文本的转换任务,如机器翻译、文本摘要等。
- 语音生成与合成 :生成逼真的语音信号,实现语音合成、语音转换等功能,在语音助手、语音识别等应用中具有潜在价值。
- 数据增强 :通过生成与真实数据分布相似的样本,为其他机器学习任务提供更多的训练数据,提高模型的性能和泛化能力,尤其在数据稀缺的情况下具有重要意义。
GAN 自提出以来,不断涌现出各种改进和变体,如 WGAN(Wasserstein GAN)、CGAN(Conditional GAN)、StyleGAN 等,这些改进在不同方面提升了 GAN 的性能和应用效果。
二、代码实战
1.前期准备
模型准备:
(1)导入相关的库
(2)解决报错、字体显示不全
(3)设置训练设备 GPU or CPU
(4)一些参数
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")LATENT_DIM = 10 # 潜在空间的维度,这里根据任务复杂程度任选
EPOCHS = 10000 # 训练的回合数,一般需要比较长的时间
BATCH_SIZE = 32 # 每批次训练的样本数
LR = 0.0002 # 学习率
BETA1 = 0.5 # Adam优化器的参数# 检查是否有可用的GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
2.数据预处理
--- 2. 加载并预处理数据 ---
iris = load_iris()
X = iris.data
y = iris.target# 只选择 'Setosa' (类别 0)
X_class0 = X[y == 0] # 一种简便写法# 数据缩放到 [-1, 1]
scaler = MinMaxScaler(feature_range=(-1, 1))
X_scaled = scaler.fit_transform(X_class0) # 转换为 PyTorch Tensor 并创建 DataLoader
# 注意需要将数据类型转为 float
real_data_tensor = torch.from_numpy(X_scaled).float()
dataset = TensorDataset(real_data_tensor)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)print(f"成功加载并预处理数据。用于训练的样本数量: {len(X_scaled)}")
print(f"数据特征维度: {X_scaled.shape[1]}")
3.建立模型(定义模型)
(1)定义生成器
# --- 3. 构建模型 ---# (A) 生成器 (Generator)
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(LATENT_DIM, 16),nn.ReLU(),nn.Linear(16, 32),nn.ReLU(),nn.Linear(32, 4),# 最后的维度只要和目标数据对齐即可nn.Tanh() # 输出范围是 [-1, 1])def forward(self, x):return self.model(x) # 因为没有像之前一样做定义x=某些东西,所以现在可以直接输出模型
(2)定义判别器
# (B) 判别器 (Discriminator)
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(4, 32),nn.LeakyReLU(0.2), # LeakyReLU 是 GAN 中的常用选择nn.Linear(32, 16),nn.LeakyReLU(0.2), # 负斜率参数为0.2nn.Linear(16, 1), # 这里最后输出1个神经元,所以用sigmoid激活函数nn.Sigmoid() # 输出 0 到 1 的概率)def forward(self, x):return self.model(x)
(3)实例化模型
# 实例化模型并移动到指定设备
generator = Generator().to(device)
discriminator = Discriminator().to(device)print(generator)
print(discriminator)
4.定义损失函数和优化器
# --- 4. 定义损失函数和优化器 ---criterion = nn.BCELoss() # 二元交叉熵损失# 分别为生成器和判别器设置优化器
g_optimizer = optim.Adam(generator.parameters(), lr=LR, betas=(BETA1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LR, betas=(BETA1, 0.999))
5.模型训练
# --- 5. 执行训练循环 ---print("\n--- 开始训练 ---")
for epoch in range(EPOCHS):for i, (real_data,) in enumerate(dataloader):# 将数据移动到设备real_data = real_data.to(device)current_batch_size = real_data.size(0)# 创建真实和虚假的标签real_labels = torch.ones(current_batch_size, 1).to(device)fake_labels = torch.zeros(current_batch_size, 1).to(device)# ---------------------# 训练判别器# ---------------------d_optimizer.zero_grad() # 梯度清零# (1) 用真实数据训练real_output = discriminator(real_data)d_loss_real = criterion(real_output, real_labels)# (2) 用假数据训练noise = torch.randn(current_batch_size, LATENT_DIM).to(device)# 使用 .detach() 防止在训练判别器时梯度流回生成器,这里我们未来再说fake_data = generator(noise).detach() fake_output = discriminator(fake_data)d_loss_fake = criterion(fake_output, fake_labels)# 总损失并反向传播d_loss = d_loss_real + d_loss_faked_loss.backward()d_optimizer.step()# ---------------------# 训练生成器# ---------------------g_optimizer.zero_grad() # 梯度清零# 生成新的假数据,并尝试"欺骗"判别器noise = torch.randn(current_batch_size, LATENT_DIM).to(device)fake_data = generator(noise)fake_output = discriminator(fake_data)# 计算生成器的损失,目标是让判别器将假数据误判为真(1)g_loss = criterion(fake_output, real_labels)# 反向传播并更新生成器g_loss.backward()g_optimizer.step()# 每 1000 个 epoch 打印一次训练状态if (epoch + 1) % 1000 == 0:print(f"Epoch [{epoch+1}/{EPOCHS}], "f"Discriminator Loss: {d_loss.item():.4f}, "f"Generator Loss: {g_loss.item():.4f}")print("--- 训练完成 ---")
6.模型可视化
# --- 6. 生成新数据并进行可视化对比 ---print("\n--- 生成并可视化结果 ---")
# 将生成器设为评估模式
generator.eval()# 使用 torch.no_grad() 来关闭梯度计算
with torch.no_grad():num_new_samples = 50noise = torch.randn(num_new_samples, LATENT_DIM).to(device)generated_data_scaled = generator(noise)# 将生成的数据从GPU移到CPU,并转换为numpy数组
generated_data_scaled_np = generated_data_scaled.cpu().numpy()# 逆向转换回原始尺度
generated_data = scaler.inverse_transform(generated_data_scaled_np)
real_data_original_scale = scaler.inverse_transform(X_scaled)# 可视化对比
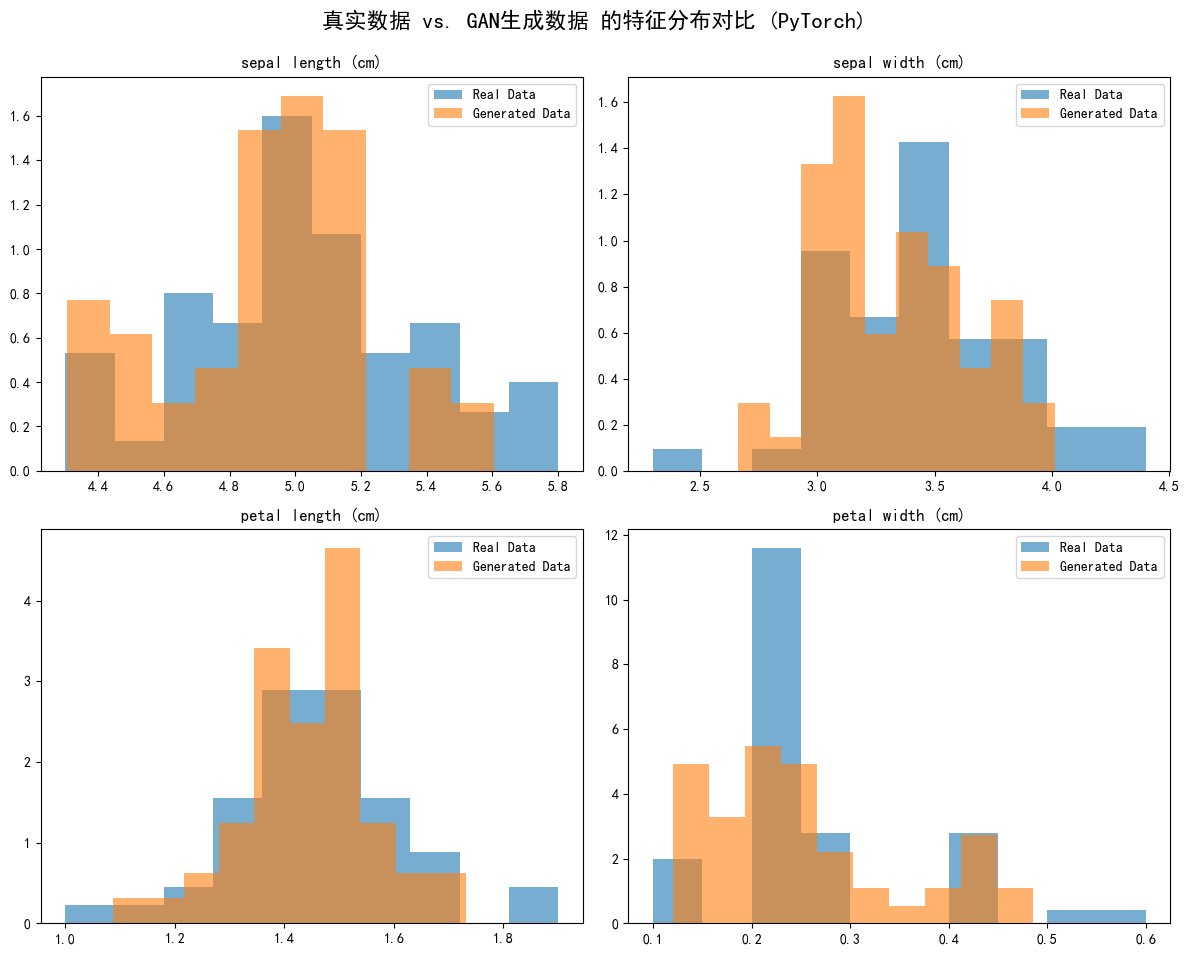
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle('真实数据 vs. GAN生成数据 的特征分布对比 (PyTorch)', fontsize=16)feature_names = iris.feature_namesfor i, ax in enumerate(axes.flatten()):ax.hist(real_data_original_scale[:, i], bins=10, density=True, alpha=0.6, label='Real Data')ax.hist(generated_data[:, i], bins=10, density=True, alpha=0.6, label='Generated Data')ax.set_title(feature_names[i])ax.legend()plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()# 将生成的数据与真实数据并排打印出来看看
print("\n前5个真实样本 (Setosa):")
print(pd.DataFrame(real_data_original_scale[:5], columns=feature_names))print("\nGAN生成的5个新样本:")
print(pd.DataFrame(generated_data[:5], columns=feature_names))