数据治理域——数据建模设计
摘要
数据建模设计是数据治理体系中的关键组成,承载着数据标准化、资产化与高质量使用的核心目标。本文从治理视角出发,深入探讨数据建模在保障企业数据一致性、复用性和共享性方面的重要作用。文章首先梳理了建模的三层体系:概念模型、逻辑模型与物理模型,并分析它们在治理流程中的职责分工与协同机制。接着,重点介绍了维度建模(如星型、雪花模型)与范式建模的特点与适用场景,特别是在大数据环境下的实践差异。在建模规范方面,文章提出应遵循统一命名、粒度控制、键值管理和维度共享等标准,确保数据模型在多系统、多主题下的兼容性与可控性。围绕一致性维度、数据总线架构和交叉探查等关键设计方法,进一步强化了跨主题的数据整合与业务联动能力。结合阿里巴巴等领先企业实践,文章总结出以业务为主线、共享为导向、标准为底座的数据建模治理方法论,强调数据模型不仅是数据管理工具,更是企业数字化治理能力的重要体现。
1. 为什么需要数据建模
在大数据系统中,数据建模是指通过定义数据结构、关系、规则和约束,将现实世界的业务需求转化为可计算的数字化模型的过程。其核心目标是高效组织、存储和处理海量数据,确保数据可被系统理解、分析和应用。现代架构中(如Lambda架构),还会引入实时数仓(如Apache Doris)和Data Lake(如Delta Lake),进一步扩展建模灵活性。
1.1. 为什么需要数据建模?
- 结构化数据,降低复杂度
大数据环境通常包含多源异构数据(如日志、文本、图像等)。数据建模通过分类、关联和标准化(如星型模型、宽表设计)将杂乱数据转化为有逻辑的体系,减少处理复杂度。 - 提升查询与分析效率
合理的模型设计(如列式存储、分区键选择)能显著优化查询性能。例如,在Hive中通过分区和分桶减少I/O开销;在ClickHouse中使用预聚合模型加速分析。 - 支持业务需求
模型需反映业务逻辑(如用户行为漏斗、供应链链路)。例如,电商场景的“用户-订单-商品”关系模型直接影响推荐算法的准确性。 - 数据一致性与质量
通过约束(如主外键、非空校验)和标准化(如维度建模中的缓慢变化维处理),避免数据冗余和冲突,确保下游应用(如BI报表、AI训练)的可靠性。 - 适应技术栈特性
不同大数据工具对模型有特定要求。例如:
-
- HBase:需设计行键(RowKey)以实现高效随机读写。
- Kafka:通过Topic分区策略影响消息并行处理能力。
- 图数据库(如Neo4j):需明确节点与边的属性以优化遍历查询。
- 成本优化
模型设计直接影响存储和计算成本。例如:
-
- 数据湖中合理的分区策略可减少扫描数据量,降低AWS S3请求费用。
- 列式存储(Parquet/ORC)结合压缩技术节省存储空间。
1.2. 大数据建模的关键方法
- 维度建模(如Kimball模型):面向分析场景,构建事实表(交易记录)与维度表(用户、时间等)。
- 数据仓库分层(ODS→DWD→DWS→ADS):逐层加工,平衡冗余与效率。
- 流式数据模型:处理实时数据时需考虑时间窗口、状态管理等(如Flink的Keyed State)。
- NoSQL模型:如文档数据库(MongoDB)的嵌套结构、时序数据库(InfluxDB)的时间线设计。
1.3. 实际案例
- 推荐系统:用户画像模型需整合行为日志(点击、购买)、社交关系等,建模为特征向量供算法使用。
- 风控系统:通过图模型关联设备、IP、交易记录,识别欺诈团伙。
2. 关系数据库系统与数据仓库
关系数据库系统(RDBMS)和数据仓库(Data Warehouse)在数据建模中扮演不同的角色,但共同服务于数据的组织、存储和分析。以下是它们的核心作用对比及协同关系:
2.1. 关系数据库系统(RDBMS)的建模作用
核心目标:支持事务处理(OLTP),保证数据的实时性、一致性和完整性。
典型场景:业务系统(如ERP、CRM)、在线交易(如电商订单)。
建模特点:
- 范式化设计(3NF或更高):通过消除冗余(如拆分表、外键关联)确保数据一致性。例如,用户表、订单表、商品表分开存储,通过主外键关联。
- ACID事务支持:模型需满足原子性、一致性(如转账操作必须同时更新双方账户)。
- 优化高频小查询:索引设计(如B树索引)加速点查询(如按订单ID查详情)。
局限性:复杂分析查询(如多表JOIN、聚合)性能较差,因范式化导致多次表关联。
2.2. 数据仓库的建模作用
核心目标:支持分析决策(OLAP),实现高性能复杂查询和历史数据分析。
典型场景:BI报表、趋势分析、数据挖掘。
建模特点:
- 维度建模(星型/雪花模型):
-
- 事实表:存储业务度量(如销售额、点击量),通常为数值型且数据量大。
- 维度表:描述业务上下文(如时间、用户、地区),通过外键与事实表关联。
- 反范式化设计:允许冗余(如将常用维度属性直接嵌入事实表)以减少JOIN操作。
- 分层架构(ODS→DWD→DWS→ADS):
逐层加工,从原始数据(ODS)到主题宽表(DWS),最终生成应用层聚合结果(ADS)。 - 优化批量分析:
列式存储(如Parquet)、分区(按日期)、预聚合(如物化视图)加速聚合查询。
局限性:不适合高频写入或实时事务,通常通过ETL定期从RDBMS同步数据。
2.3. 两者在数据建模中的协同关系
| 维度 | 关系数据库(OLTP) | 数据仓库(OLAP) |
| 建模目标 | 支持事务,确保数据精确 | 支持分析,提升查询性能 |
| 设计范式 | 高度范式化(减少冗余) | 反范式化(允许冗余) |
| 查询类型 | 简单查询(单行增删改查) | 复杂查询(多表聚合、时间窗口分析) |
| 数据时效性 | 实时 | 近实时或T+1(依赖ETL调度) |
| 典型工具 | MySQL、PostgreSQL、Oracle | Snowflake、Redshift、Hive、ClickHouse |
2.4. 协同流程示例:
- 数据产生:业务系统的RDBMS处理交易(如用户下单),模型需满足高并发写入。
- ETL同步:通过工具(如Airflow、Kafka)将RDBMS数据抽取到数据仓库,建模转为星型模型。
- 分析应用:数据仓库中预计算指标(如月度销售额TOP10),供BI工具(如Tableau)展示。
2.5. 实际案例对比
- 电商场景:
-
- RDBMS模型:订单表(
orders)与用户表(users)分开,通过user_id关联。 - 数据仓库模型:宽表
dws_orders直接包含用户姓名、地区等维度字段,避免分析时JOIN用户表。
- RDBMS模型:订单表(
- 性能差异:
-
- RDBMS查询:
SELECT * FROM orders WHERE order_id = 1001(毫秒级响应)。 - 数据仓库查询:
SELECT region, SUM(sales) FROM dws_orders GROUP BY region(秒级响应,但处理亿级数据)。
- RDBMS查询:
2.6. 关系数据库与数仓总结
- 关系数据库建模是业务系统的基石,确保数据的准确性和事务安全。
- 数据仓库建模是分析的引擎,通过牺牲部分实时性换取分析效率。
- 两者互补:RDBMS为数据仓库提供高质量数据源,数据仓库释放RDBMS的分析压力。
3. 典型的数据仓库建模方法
数据仓库建模方法论的核心是将数据高效组织为适合分析的结构,兼顾查询性能、灵活性和可维护性。以下是几种典型方法论及其应用场景:
| 建模方法 | 简要定义 | 典型使用场景 | 为什么使用该方法 |
| 维度建模(维度模型) | 以“事实表 + 维度表”的结构设计,强调数据可读性和分析便利性 | BI 报表分析、运营分析、用户行为分析、销售分析等 OLAP 场景 | - 易理解、面向业务人员 |
| 范式建模(规范化模型) | 数据高度规范化,避免冗余,通过主外键连接形成结构复杂的模型 | ERP、CRM、银行核心系统、强一致性业务系统等 OLTP 场景 | - 数据一致性强 |
| Data Vault 建模 | 将数据拆分为 Hub(主键)、Link(关系)、Satellite(属性)三类表 | 跨系统数据整合、企业级数据仓库建设、数据湖仓融合项目 | - 支持历史追踪(变化记录) |
| 宽表建模(扁平建模) | 将多个维度字段拉平到一个大表中(避免 JOIN) | 实时报表、指标计算、面向应用的查询(如大屏、接口) | - 查询简单、性能高(特别是 NoSQL/OLAP 引擎) |
| 分层建模(数仓分层架构) | 按数据处理粒度、加工深度将数据划分为多个层级 | 大型企业数仓、实时数仓、银行/保险等典型业务数仓 | - 逻辑清晰、利于治理 |
3.1. 维度建模(Dimensional Modeling)
核心理念:以业务过程为中心,构建事实表+维度表的星型/雪花模型,直观易用且优化分析性能。
适用场景:BI报表、即席查询(如零售销售分析、用户行为漏斗)。
3.1.1. 关键组件:
- 事实表(Fact Table)
-
- 存储业务过程的度量值(如销售额、点击量),通常是数值型、可聚合的字段。
- 类型:事务型(每条记录独立)、周期快照型(如每日库存)、累积快照型(如订单全链路状态)。
- 维度表(Dimension Table)
-
- 描述业务上下文(如时间、用户、产品),包含文本属性用于过滤和分组。
- 特殊处理:缓慢变化维(SCD)解决维度属性随时间变化的问题(如用户地址变更)。
3.1.2. 模型变体:
- 星型模型:维度表直接关联事实表,查询简单但可能存在冗余。
- 雪花模型:维度表进一步规范化(如地区维度拆分为国家、省、市),减少冗余但增加JOIN复杂度。
3.2. 规范化建模(Inmon方法)
核心理念:先构建企业级原子数据仓库(EDW),高度范式化(3NF),再按主题生成数据集市。
适用场景:大型企业需要长期维护单一数据源(如金融行业合规报表)。
3.2.1. 特点:
- 自上而下:先集中整合全企业数据,确保一致性,再按部门需求派生数据集市。
- 强调整体性:数据冗余少,但ETL复杂,初期投入大。
3.3. Data Vault建模
核心理念:适应数据变化的混合模型(结合范式化和维度建模),强调可追溯性和灵活性。
适用场景:数据集成复杂、需求变化快的场景(如医疗数据合并、供应链追踪)。
3.3.1. 关键组件:
- Hub:业务实体核心标识(如客户ID、订单ID)。
- Link:实体间关系(如客户-订单关联)。
- Satellite:实体的详细属性(如客户姓名、订单金额),支持历史跟踪。
优势:
- 易于扩展,新增数据源时只需添加Hub/Link/Satellite,不影响现有结构。
- 天然支持数据血缘和审计。
3.4. 宽表模型(宽列模型)
核心理念:将常用维度属性冗余存储到事实表中,形成“一行包含所有分析字段”的宽表。
适用场景:实时分析、高并发查询(如广告点击日志分析)。
3.4.1. 特点:
- 反范式化极致:减少JOIN操作,适合列式存储(如Parquet、ClickHouse)。
- 预计算友好:可直接嵌入衍生指标(如UV、转化率)。
3.5. 分层建模(数据仓库分层)
通用实践:将数据加工流程分为多层,每层有明确职责。常见分层:
- ODS(Operational Data Store):原始数据镜像,保留细节,不做清洗。
- DWD(Data Warehouse Detail):清洗后的明细数据,保持业务过程粒度。
- DWS(Data Warehouse Summary):轻度汇总的主题宽表(如用户行为宽表)。
- ADS(Application Data Store):高度聚合的应用层结果(如日报、风控指标)。
优势:平衡处理效率与数据复用,便于问题回溯。
3.6. 数仓建模方法论对比
| 方法 | 设计重点 | 灵活性 | 查询性能 | 适用阶段 |
| 维度建模 | 业务过程直观性 | 中 | 高 | 敏捷分析、部门级应用 |
| Inmon范式化 | 企业数据一致性 | 低 | 中 | 企业级EDW建设 |
| Data Vault | 变化适应性和追溯性 | 高 | 中低 | 数据集成、长期演进 |
| 宽表模型 | 极致查询速度 | 低 | 极高 | 实时分析、日志场景 |
3.7. 数仓建模选择
| 场景 | 推荐建模方法 | 理由 |
| BI 报表分析 (销售、用户行为) | 维度建模(星型) | 面向分析,支持多维度、聚合查询 |
| 高并发写入、事务性操作 | 范式建模(3NF) | 数据一致性高,减少冗余 |
| 企业级整合数据仓库 | Data Vault | 支持异构源整合、变化追踪、数据血缘 |
| 实时接口或大屏展示 | 宽表建模 | 查询快、结构简单,减少延迟 |
| 通用大数据数仓 | 分层建模(ODS-DWD-DWS-ADS) | 结构清晰、支撑全链路数据处理与管控 |
4. 阿里数据建模设计
阿里巴巴集团在大数据建设方面积累了丰富实践经验,其大数据方法论具有高度系统性和工程化能力,常被业内称为“大数据中台”或“数据中台”架构。阿里巴巴的大数据方法论核心:以分层建模为基础、以原子指标为核心、以 OneModel 为抽象、以工程化平台为保障、以数据服务化为目标。这种方法论既能支撑复杂的业务场景,又能保障数据资产的质量、复用和可控性,是目前许多大型企业模仿与借鉴的标杆。
| 核心要素 | 内容说明 |
| 1. 分层建模(分层设计) | 基于“数仓分层思想”,将数据建模分为多个层级: |
| 2. 原子指标 & 轻聚合 | 所有指标先分解为最小粒度原子指标(如交易金额、订单数),聚合逻辑分离,避免“报表越做越乱”的问题,支持灵活复用。 |
| 3. 数据中台思维 | 抽象业务逻辑,沉淀为“公共、复用、标准”的数据资产,提供统一的接口服务化输出能力,服务于多个业务前台(如天猫、淘宝、饿了么等)。 |
| 4. 血缘分析 & 数据质量治理 | 全链路数据血缘管理:字段级追踪、任务依赖关系;建立数据质量体系(如数据稽核、校验、告警)确保可用性与可靠性。 |
| 5. OneModel 模型体系 | 建立标准的数据模型(如交易模型、会员模型、商品模型),实现模型复用、语义统一,支撑各种报表、分析、机器学习任务。 |
| 6. 指标中心 + 数据服务化 | 所有业务指标统一进入“指标平台”管理,实现指标的定义、计算、口径说明、版本控制、权限管理,并以 API / SQL / 可视化方式统一服务输出。 |
| 7. 工程化开发流程(OneData) | 阿里内部打造了一整套标准化数据开发平台与流程(如 MaxCompute + DataWorks),支持自动生成 SQL、自动运维、调度、测试、发布全流程。 |
| 8. 全域数据统一编码体系(OneID) | 将不同系统中的用户、商品、店铺、设备、交易等标识统一映射到 OneID,打通数据孤岛,支撑用户画像、精准推荐等算法模型。 |
4.1. 系统架构
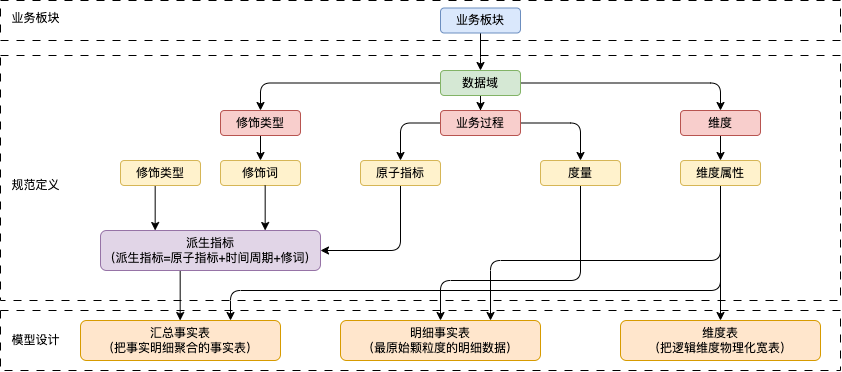
- 业务板块:由于阿里巴巴集团业务生态庞大,所以根据业务的属性划分出几个相对独立的业务板块,业务板块之间的指标或业务重叠性较小。如电商业务板块涵盖淘系、B2B系和AliExpress系等。
- 规范定义:阿里数据业务庞大,结合行业的数据仓库建设经验和阿里数据自身特点,设计出的一套数据规范命名体系,规范定义将会被用在模型设计中。后面章节将会详细说明。
- 模型设计:以维度建模理论为基础,基于维度建模总线架构,构建一致性的维度和事实(进行规范定义)。同时,在落地表模型时,基于阿里自身业务特点,设计出一套表规范命名体系。
4.2. 规范定义
规范定义指以维度建模作为理论基础,构建总线矩阵,划分和定义数据域、业务过程、维度、度量/原子指标、修饰类型、修饰词、时间周期、派生指标。
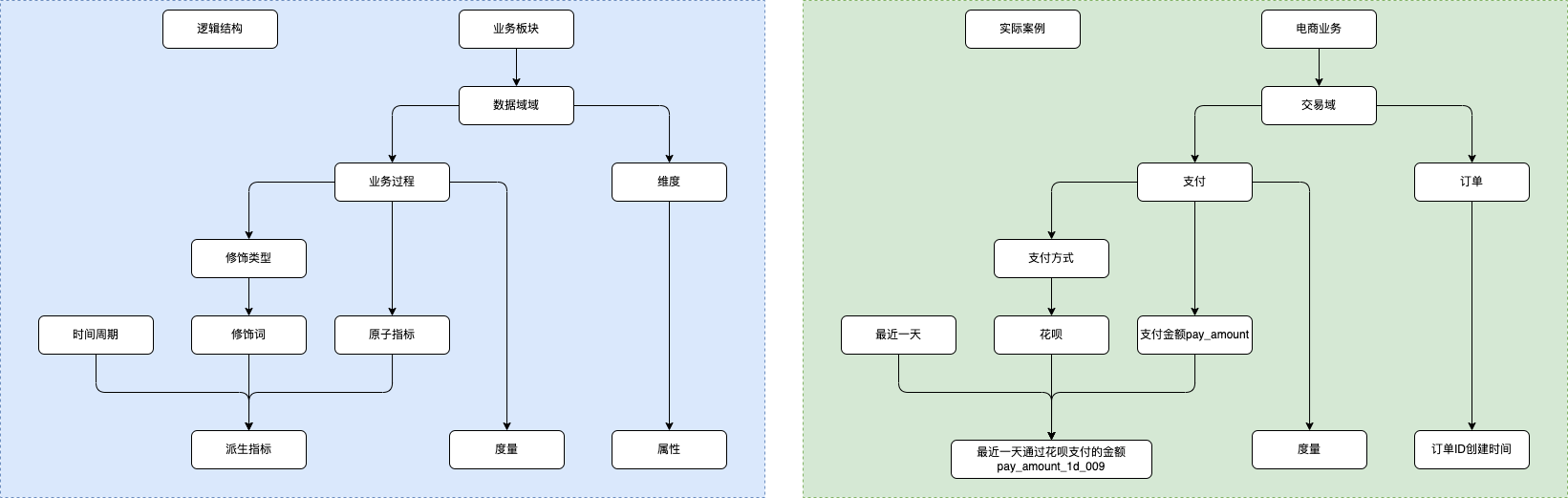
- 数据域:指面向业务分析,将业务过程或者维度进行抽象的集合。其中,业务过程可以概括为一个个不可拆分的行为事件,在业务过程之下,可以定义指标;维度是指度量的环境,如买家下单事件,买家是维度。为保障整个体系的生命力,数据域是需要抽象提炼,并且长期维护和更新的,但不轻易变动。在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中和扩展新的数据域指企业的业务活动事件,如下单、支付、退款都是业务过程。请注意,业务过程。
- 业务过程:是一个不可拆分的行为事件,通俗地讲,业务过程就是企业活动中的事件。
- 时间周期:用来明确数据统计的时间范围或者时间点,如最近30天、自然周、截至当日等是对修饰词的一种抽象划分。修饰类型从属于某个业务域,如日志域的访问终端。
- 修饰类型:类型涵盖无线端、PC端等修饰词指除了统计维度以外指标的业务场景限定抽象。修饰词隶属于一种修饰类型,如修饰词在日志域的访问终端类型下,有修饰词PC端、无线端等。
- 度量/原原子指标:度量/原原子指标和度量含义相同,基于某一业务事件行为下的度量,是业务定义中不可子指标再拆分的指标,具有明确业务含义的名词,如支付金额。
- 维度:维度是度量的环境,用来反映业务的一类属性,这类属性的集合构成一个维度,也可以称为实体对象。维度属于一个数据域,如地理维度(其中包括国家、地区、省以及城市等级别的内容)入、时间维度(其中包括年、季、月、周、日等级别的内容)。
- 维度属性:维度属性隶属于一个维度,如地理维度里面的国家名称、国家D、省份名称等都属于维度属性。
- 派生指标:派生指标=一个原子指标+多个修饰词(可选)+时间周期。可以理解为对原子指派生指标标业务统计范围的圈定。如原子指标:支付金额,最近1天海外买家支付金额则为(最近1天为时间周期,海外为修饰词,买家作为维度,而不作为修饰词)。
4.3. 指标体系
4.3.1. 组成体系之间关系
派生指标由原子指标、时间周期修饰词、若干其他修饰词组合得到。
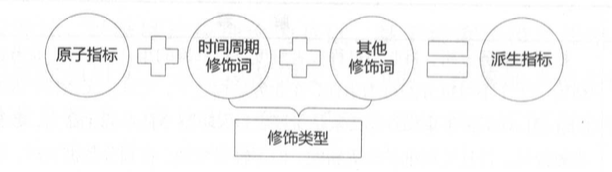
- 原子指标、修饰类型及修饰词,直接归属在业务过程下,其中修饰词继承修饰类型的数据域。
- 派生指标可以选择多个修饰词,修饰词之间的关系为“或”或者“且”,由具体的派生指标语义决定。
- 派生指标唯一归属一个原子指标,继承原子指标的数据域,与修饰词的数据域无关。
一般而言,事务型指标和存量型指标(见下文定义)只会唯一定位到一个业务过程,如果遇到同时有两个行为发生、需要多个修饰词、生成一个派生指标的情况,则选择时间靠后的行为创建原子指标,选择时间靠前的行为创建修饰词。原子指标有确定的英文字段名、数据类型和算法说明;派生指标要继承原子指标的英文名、数据类型和算法要求。
4.3.2. 命名约定
命名所用术语。指标命名,尽量使用英文简写,其次是英文,当指标英文名太长时,可考虑用汉语拼音首字母命名。如中国质造,用zgzc。在OneData工具中维护着常用的名词术语,以用来进行命名。
- 业务过程。英文名:用英文或英文的缩写或者中文拼音简写;中文名:具体的业务过程中文即可。
- 关于存量型指标(见下文定义)对应的业务过程的约定:实体对象英文名+stock。如在线会员数、一星会员数等,其对应的业务过程为mbr_stock;在线商品数、商品SKU种类小于5的商品数,其对应的业务过程为itm_stock。
- 原子指标。英文名:动作+度量;中文名:动作+度量。
- 原子指标必须挂靠在某个业务过程下。
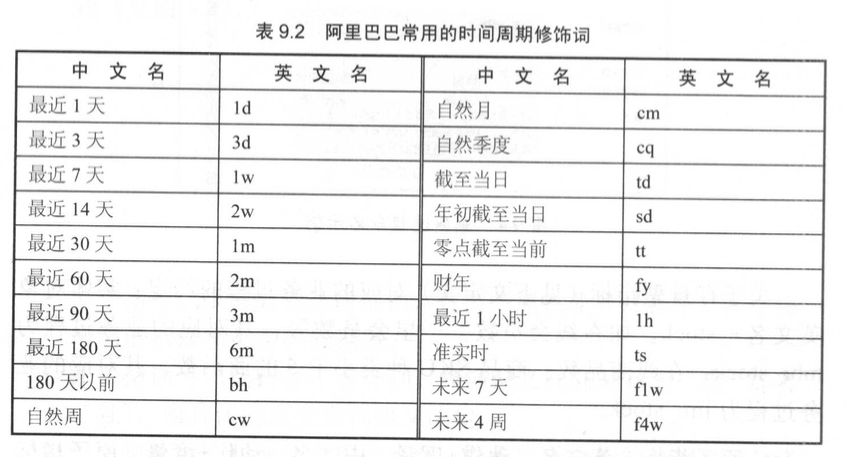
- 修饰词。只有时间周期才会有英文名,且长度为2位,加上“_”为3位,例如_1d。其他修饰词无英文名。
- 派生指标。英文名:原子指标英文名+时间周期修饰词(3位,例如1d)+序号(4位,例如001);中文名:时间周期修饰词+[其他修饰词]+原子指标。
4.3.3. 操作细则
派生指标的种类
- 派生指标可以分为三类:事务型指标、存量型指标和复合型指标。按照其特性不同,有些必须新建原子指标,有些可以在其他类型原子指标的基础上增加修饰词形成派生指标。
- 事务型指标:是指对业务活动进行衡量的指标。例如新发商品数、重发商品数、新增注册会员数、订单支付金额,这类指标需维护原子指标及修饰词,在此基础上创建派生指标。
- 存量型指标:是指对实体对象(如商品、会员)某些状态的统计。例如商品总数、注册会员总数,这类指标需维护原子指标及修饰词,在此基础上创建派生指标,对应的时间周期一般为“历史截至当前某个时间”。
- 复合型指标:是在事务型指标和存量型指标的基础上复合而成的。例如浏览UV下单买家数转化率,有些需要创建新原子指标,有些则可以在事务型或存量型原子指标的基础上增加修饰词得到派生指标。
复合型指标的规则
- 比率型:创建原子指标,如CTR、浏览UV下单买家数转化率、满意率等。例如,“最近1天店铺首页CTR”,原子指标为“CTR”,时间周期为“最近1天”,修饰类型为“页面类型”,修饰词为“店铺首页”。
- 比例型:创建原子指标,如百分比、占比。例如“最近1天无线支付金额占比”,原子指标为“支付金额占比”,修饰类型为“终端类型”,修饰词为“无线”。
- 变化量型:不创建原子指标,增加修饰词,在此基础上创建派生指标。例如,“最近1天订单支付金额上1天变化量”,原子指标为“订单支付金额”,时间周期为“最近1天”,修饰类型为“统计方法”,修饰词为“上1天变化量”。
- 变化率型:创建原子指标。例如,“最近7天海外买家支付金额上7天变化率”,原子指标为“支付金额变化率”,修饰类型为“买家地域”,修饰词为“海外买家”。
- 统计型(均值、分位数等):不创建原子指标,增加修饰词,在此基础上创建派生指标;在修饰类型“统计方法”下增加修饰词,如人均、日均、行业平均、商品平均、90分位数、70分位数等。例如,“自然月日均UV”,原子指标为“UV”,修饰类型为“统计方法”,修饰词为“日均”。
- 排名型:创建原子指标,一般为top xxx xxx,有时会同时选择rank和top_XXXXXX组合使用。创建派生指标时选择对应的修饰词如下:
-
- 统计方法(如降序、升序)。
- 排名名次(如TOP10)。
- 排名范围(如行业、省份、一级来源等)。
- 根据什么排序(如搜索次数、PV)。
4.4. 模型设计
阿里巴巴集团数据公共层设计理念遵循维度建模思想,据模型的维度设计主要以维度建模理论为基础,基于维度数据模型总线架构,构建一致性的维度和事实。阿里巴巴的数据团队把表数据模型分为三层:操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括明细数据层(DWD)和汇总数据层(DWS)。
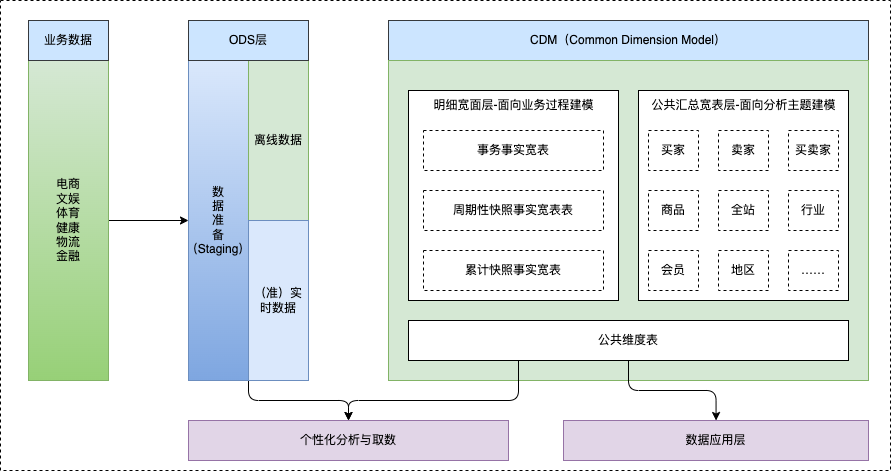
操作数据层(ODS):把操作系统数据几乎无处理地存放在数据仓库系统中。
- 同步:结构化数据增量或全量同步到MaxCompute。
- 结构化:非结构化(日志)结构化处理并存储到MaxCompute。
- 累积历史、清洗:根据数据业务需求及稽核和审计要求保存历史数据、清洗数据。
公共维度模型层(CDM): 存放明细事实数据、维表数据及公共指标汇总数据,其中明细事实数据、维表数据一般根据ODS层数据加工生成;公共指标汇总数据一般根据维表数据和明细事实数据加工生成。CDM层又细分为DWD层和DWS层,分别是明细数据层和汇总数据层,采用维度模型方法作为理论基础,更多地采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联,提高明细数据表的易用性;同时在汇总数据层,加强指标的维度退化,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。其主要功能如下:
- 组合相关和相似数据:采用明细宽表,复用关联计算,减少数据扫描。
- 公共指标统一加工:基于OneData体系构建命名规范、口径一致和算法统一的统计指标,为上层数据产品、应用和服务提供公共指标;建立逻辑汇总宽表。
- 建立一致性维度:建立一致的数据分析维表,降低数据计算口径、算法不统一的风险。
应用数据层(ADS): 存放数据产品个性化的统计指标数据,根据CDM层与ODS层加工生成。
- 个性化指标加工:不公用性、复杂性(指数型、比值型、排名型指标)。
- 基于应用的数据组装:大宽表集市、横表转纵表、趋势指标串。
4.5. 基本原则
4.5.1. 高内聚和低耦合
一个逻辑或者物理模型由哪些记录和字段组成,应该遵循最基本的软件设计方法论的高内聚和低耦合原则。主要从数据业务特性和访问特性两个角度来考虑:将业务相近或者相关、粒度相同的数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
4.5.2. 核心模型与扩展模型分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用的核心业务,扩展模型包括的字段支持个性化或少量应用的需要,不能让扩展模型的字段过度侵入核心模型,以免破坏核心模型的架构简洁性与可维护性。
4.5.3. 公共处理逻辑下沉及单一
越是底层公用的处理逻辑越应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑多处同时存在。
4.5.4. 成本与性能平衡
适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
4.5.5. 数据可回滚
处理逻辑不变,在不同时间多次运行数据结果确定不变。
4.5.6. 一致性
具有相同含义的字段在不同表中的命名必须相同,必须使用规范定义中的名称。
4.5.7. 命名清晰、可理解
表命名需清晰、一致,表名需易于消费者理解和使用。
4.6. 模型实施过程
4.6.1. Kimball维度建模
Kimball维度建模主要探讨需求分析、高层模型、详细模型和模型审查整个过程。构建维度模型一般要经历三个阶段:第一个阶段是高层设计时期,定义业务过程维度模型的范围,提供每种星形模式的技术和功能描述;第二个阶段是详细模型设计时期,对每个星形模型添加属性和度量信息;第三个阶段是进行模型的审查、再设计和验证等工作,第四个阶段是产生详细设计文档,提交ETL设计和开发。
高层模型
高层模型设计阶段的直接产出目标是创建高层维度模型图,它是对业务过程中的维表和事实表的图形描述。确定维表创建初始属性列表,为每个事实表创建提议度量。
详细模型
详细的维度建模过程是为高层模型填补缺失的信息,解决设计问题,并不断测试模型能否满足业务需求,确保模型的完备性。确定每个维表的属性和每个事实表的度量,并确定信息来源的位置、定义,确定属性和度量如何填入模型的初步业务规则。
模型审查、再设计和验证
本阶段主要召集相关人员进行模型的审查和验证,根据审查结果对详细维度进行再设计。
提交ETL设计和开发
最后,完成模型详细设计文档,提交ETL开发人员,进入ETL设计和开发阶段,由ETL人员完成物理模型的设计和开发。
4.6.2. Inmon模型实施过程
Inmon对数据模型的定位是:扮演着通往数据仓库其他部分的智能路线图的角色。由于数据仓库的建设不是一蹴而就的,为了协调不同人员的工作以及适应不同类型的用户,非常有必要建立一个路线图一数据模型,描述数据仓库各部分是如何结合在一起的。
Inmon将模型划分为三个层次,分别是ERD (Entity IRelationshipDiagram,实体关系图)层、DIS(Data Item Set,数据项集)层和物理层(Physical Model,物理模型)。
ERD层是数据模型的最高层,该层描述了公司业务中的实体或主题域以及它们之间的关系;ERD层是中间层,该层描述了数据模型中的关键字、属性以及细节数据之间的关系;物理层是数据建模的最底层,该层描述了数据模型的物理特性。
Inmon对于构建数据仓库模型建议采用螺旋式开发方法,采用迭代方式完成多次需求。但需要采用统一的ERD模型,才能够将每次迭代的结果整合在一起。ERD模型是高度抽象的数据模型,描述了企业完整的数据。而每次迭代则是完成ERD模型的子集,通过DIS和物理数据模型实现。
4.6.3. 其他模型实施过程
在实践中经常会用到如下数据仓库模型层次的划分,和KimballInmon的模型实施理论有一定的相通性,但不涉及具体的模型表达。
- 业务建模,生成业务模型,主要解决业务层面的分解和程序化。
- 领域建模,生成领域模型,主要是对业务模型进行抽象处理,生成领域概念模型。
- 逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
- 物理建模,生成物理模型,主要解决逻辑模型针对不同关系数据库的物理化以及性能等一些具体的技术问题。
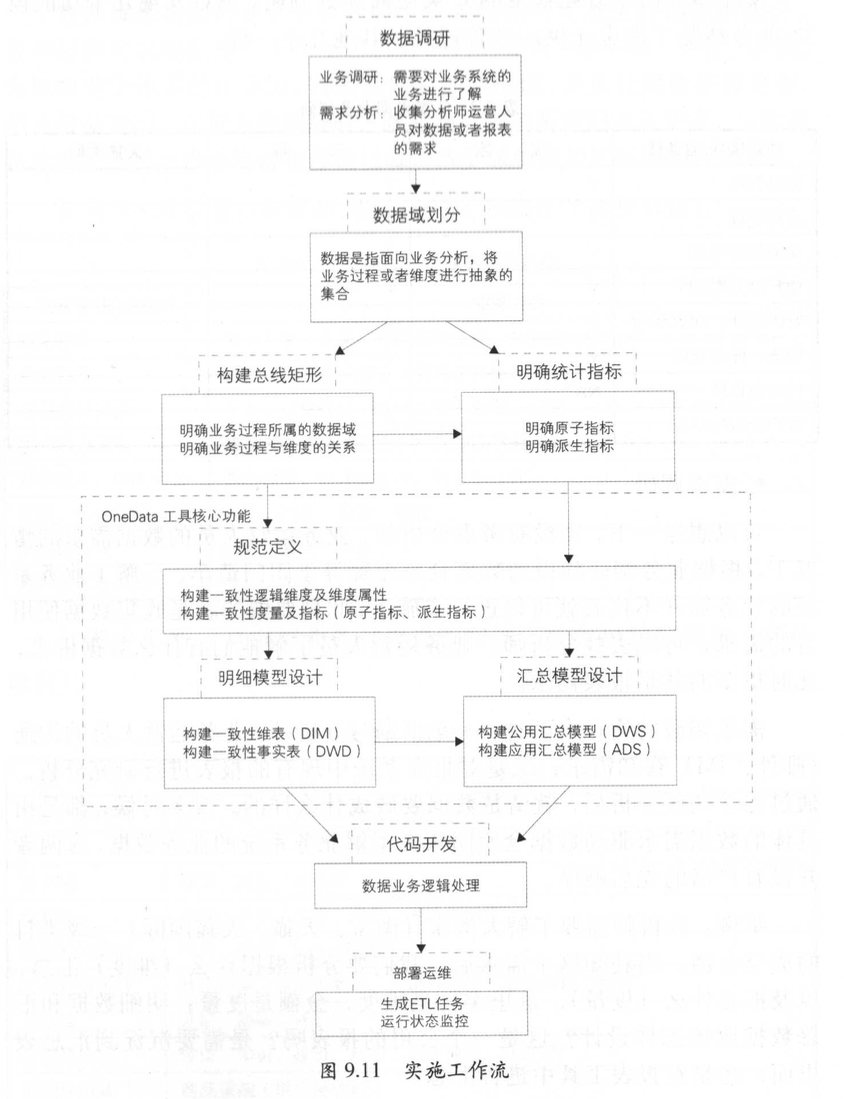
4.7. OneData实施过程
首先,在建设大数据数据仓库时,要进行充分的业务调研和需求分析。这是数据仓库建设的基石,业务调研和需求分析做得是否充分直接决定了数据仓库建设是否成功。其次,进行数据总体架构设计,主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽象出业务过程和维度。再次,对报表需求进行抽象整理出相关指标体系,使用OneData工具完成指标规范定义和模型设计。最后,就是代码研发和运维。本文将会重点讲解物理模型设计之前(含)步骤的内容。
4.7.1. 数据调研
业务调研:整个阿里集团涉及的业务涵盖电商、数字娱乐、导航(高德)、移动互联网服务等领域。各个领域又涵盖多个业务线,如电商领域就涵盖了C类(淘宝、天猫、天猫国际)与B类(阿里巴巴中文站、国际站、速卖通)业务。数据仓库是要涵盖所有业务领域,还是各个业务领域独自建设,业务领域内的业务线也同样面临着这个问题。所以要构建大数据数据仓库,就需要了解各个业务领域、业务线的业务有什么共同点和不同点,以及各个业务线可以细分为哪几个业务模块,每个业务模块具体的业务流程又是怎样的。业务调研是否充分,将会直接决定数据仓库建设是否成功。
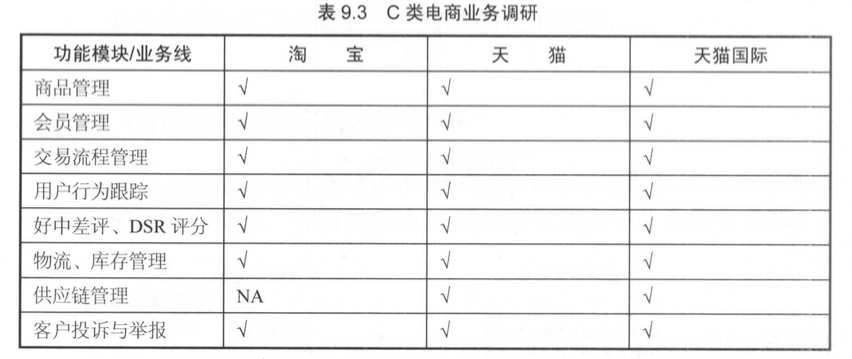
在阿里巴巴,一般各个业务领域独自建设数据仓库,业务领域内的业务线由于业务相似、业务相关性较大,进行统一集中建设。如图所示是粗粒度的C类电商业务调研,不难发现几个功能模块业务线除了淘宝无供应链管理外,其他几乎一样。
4.7.2. 需求调研
可以想象一下,在没有考虑分析师、业务运营人员的数据需求的情况下,根据业务调研建设的数据仓库无疑等于闭门造车。了解了业务系统的业务后并不代表就可以进行实施了,此刻要做的就是收集数据使用者的需求,可以去找分析师、业务运营人员了解他们有什么数据诉求,此时更多的就是报表需求。
需求调研的途径有两种:一是根据与分析师、业务运营人员的沟通(邮件、M)获知需求;二是对报表系统中现有的报表进行研究分析。通过需求调研分析后,就清楚数据要做成什么样的。很多时候,都是由具体的数据需求驱动数据仓库团队去了解业务系统的业务数据,这两者并没有严格的先后顺序。
举例:分析师需要了解大淘宝(淘宝、天猫、天猫国际)一级类目的成交金额。当获知这个需求后,我们要分析根据什么(维度)汇总,以及汇总什么(度量),这里类目是维度,金额是度量;明细数据和汇总数据应该怎样设计?这是一个公用的报表吗?是需要沉淀到汇总表里面,还是在报表工具中进行汇总?
4.7.3. 数据域
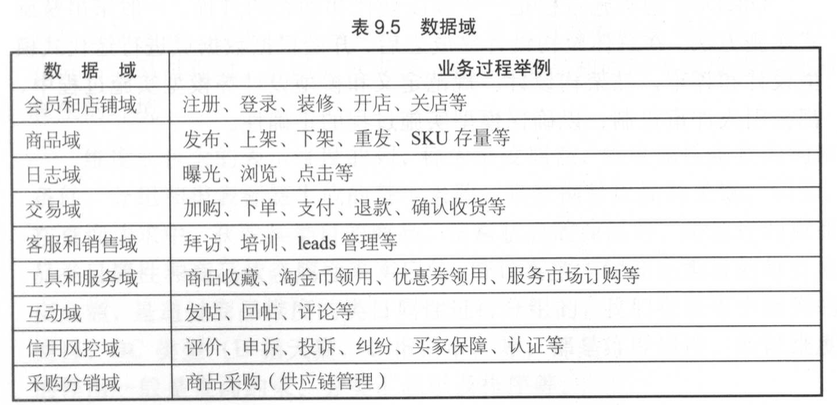
数据域划分:数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。业务过程可以概括为一个个不可拆分的行为事件,如下单、支付、退款。为保障整个体系的生命力,数据域需要抽象提炼,并且长期维护和更新,但不轻易变动。在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中或者扩展新的数据域。如表9.4所示是功能模块/业务线的业务动作(部分示例)。

构建总线矩阵:在进行充分的业务调研和需求调研后,就要构建总线矩阵了。需要做两件事情:明确每个数据域下有哪些业务过程;业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
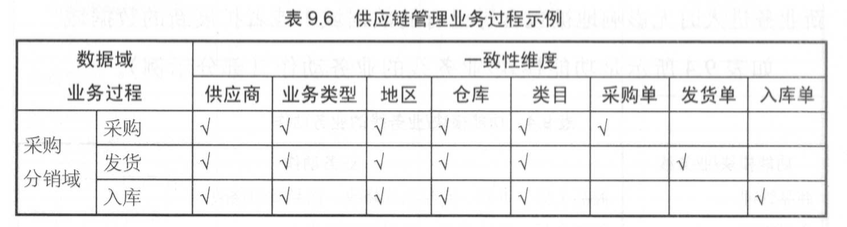
4.7.4. 规范定义
规范定义主要定义指标体系,包括原子指标、修饰词、时间周期和派生指标。
4.7.5. 模型设计
模型设计主要包括维度及属性的规范定义,维表、明细事实表和汇总事实表的模型设计。
博文参考
- 《阿里巴巴大数据实践》