pytorch 实战二 CNN手写数字识别
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、torchvision.datasets
- 1. 数据下载
- 2. 数据分批次传入
- 二、网络
- 1. 网络搭建
- 2. 训练
- 3.测试
- 完整代码
- 三、保存模型与推理(inference)
- 模型保存
- 推理
- 鸣谢
前言
手写数字识别,就是要根据手写的数字0~9,然后我们搭建网络,进行智能识别。说句实话,中草药识别啊,等等。都可以用在本科的毕业设计论文中,妥妥的加分项,而且还不难。最离谱的是我有一个研究生的哥们儿,也用这个当做毕业设计论文,准确率高达99%。笑死我了,哈哈哈,我只能说,水深啊
在实战一中,我们已经详细讲解了 torch 完成一个神经网络搭建的过程,在以后我将直接给出代码,讲解额外的库函数。
一、torchvision.datasets
1. 数据下载
本文使用的手写数字的识别就在 torchvision.datasets 中,我们可以直接调用。在手写数据中,有 6 w张训练集和 1 w 张测试集。
dowload = True, 只能运行一次,之后改成False, transform.Tensor ,就是把数据转化成我们可以使用的 Tensor 数据类型。
代码加载数据:
# data
train_data = datasets.MNIST(root='./datasets',train = True,transform = transforms.ToTensor(),download=True)
但是这个下载可能有点慢?这里给出一个百度链接:
https://pan.baidu.com/s/1ia3vFA73hEtWK9qU-O-4iQ?pwd=mnis
2. 数据分批次传入
在第一个章节中,我们把数据一次加载到训练集和测试集中,但是深度学习的照片可能很大,我们这里要用一种新的方法:
# batchSize
train_loader = data_util.DataLoader(dataset=train_data,batch_size=64,shuffle=True)test_loader = data_util.DataLoader(dataset=test_data,batch_size=64,shuffle=True)
dataset = train_data 这个参数是传入要分割的数据集,batch_size 分块的批次,shuffle 数据是否需要打乱,那必须的啊。所以把这个当做模版来,用的时候就 CV。
二、网络
1. 网络搭建
在实战一中,我们是直接定义算子,然后组合在一起。在实战二中,我们玩点不一样的,使用序列定义算子。
class CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 定义第一个卷积操作self.conv = torch.nn.Sequential(# 参数的具体含义我们在卷积神经网络中介绍torch.nn.Conv2d(1, 32, kernel_size=(5,5),padding = 2),# 第一个参数是灰度,第二个参数是输出通道,第三个参数是卷积核torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14*14*32,10) # 第一个是特征图整体的数量,第二个是Y的种类def forward(self, x):out = self.conv(x) # 第一个卷积out = out.view(out.size()[0],-1) # 拉成一个一维的向量out = self.fc(out) # 线性运算return out # 返回最后的输出
cnn = CNN()
class 用于构建我们的网络,第一个函数除了继承父类的初始化操作,还要定义我们的算子。卷积操作,用一个序列torch.nn.Sequential,在里面定义了一个 2d 卷积、BatchNorm等等,这些参数的配置我们在卷积神经网络会细讲。此处我们需要了解编程的结构。网络中定义了一个前向传播算子,经过卷积,拉直,输出的线性化。
2. 训练
cnn = cnn.cuda()
# loss
loss_fn = torch.nn.CrossEntropyLoss() # 交叉熵的损失函数# optimizer
optimizer = torch.optim.Adam(cnn.parameters(),lr=0.01)# 采用Adam 对学习率不是特别敏感
# training
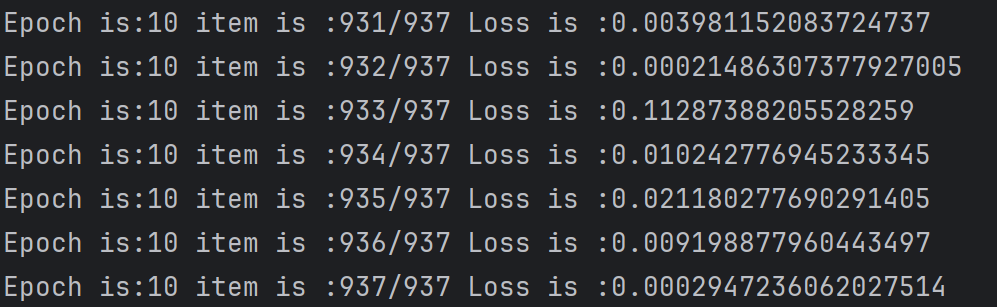
for epoch in range(10):# 这里我们把整个数据集过 10 遍for i, (images, labels) in enumerate(train_loader):images = images.cuda() # 图片放到cuda上面labels = labels.cuda()# 定义输出结构outputs = cnn(images)loss = loss_fn(outputs,labels) # loss 传入输出的结果optimizer.zero_grad() # 梯度优化loss.backward() # 反向传播optimizer.step()print("Epoch is:{} item is :{}/{} Loss is :{}".format(epoch+1,i,len(train_data)//64,loss.item()))
把网络加载到cuda上面,使用显卡跑数据。损失函数采用交叉熵,优化函数采用Adam,这可以减小学习率的影响。然后训练10个轮次,每个轮次还有64个区块,我们都要训练完全。训练过程每个batch:
- 把数据加载到 cuda 上面
- 网络上跑一边获得第一个输出,输出在net中已经处理了。
- 计算损失函数
- 梯度优化器
- 损失函数反向传播
- 优化器保存参数
图片:
3.测试
测试我们在每个epoch测试一次(每轮测试),注意代码的位置。用测试集来跑模型,然后计算出准确率。
# testloss_test = 0accuracy = 0for i, (images, labels) in enumerate(test_loader):images = images.cuda() # 图片放到cuda上面labels = labels.cuda()# 定义输出结构outputs = cnn(images)# 我们使用交叉熵计算,label 的维度是[batchsize],每个样本的标签样本是一个值# outputs = batches * cls_num cls_num 概率分布也就是种类10 个loss_test += loss_fn(outputs, labels) # loss 传入输出的结果,对text_loss 进行一个累加,最后求平均值_, predicted = outputs.max(dim=1) # 获得最大的概率作为我们的预测值accuracy += (predicted ==labels).sum().item() # 我们通过相同的样本进行统计求和,通过item获取这个值accuracy = accuracy/len(test_data)loss_test=loss_test/(len(test_data)//64) # 除以batch的个数print("测试:\nEpoch is:{} accuracy is :{} loss_test is :{}".format(epoch+1,accuracy,loss_test.item()))
测试我们定义在每轮测试一次。先定义损失函数的值和准确率为零,我们把他们的每个batch求和,然后求得平均值,这是我们测试经常做的。注意预测, _, predicted = outputs.max(dim=1) 我们取得最大的预测结果,_ 表示忽略索引,只保留预测的标签。accuracy += (predicted ==labels).sum().item() 把预测值和真实值进行比较,再求和,再取得数据,加到 accuracy (每个batch的轮次)。.item() 将单元素张量转换为Python标量,有利于计算。最后计算求平均值,准确率除以整个测试集,而loss_test 除以batch的数量,因为损失函数这一个batch只有一个,准确率统计了这个batch的所有正确样本。
图片:
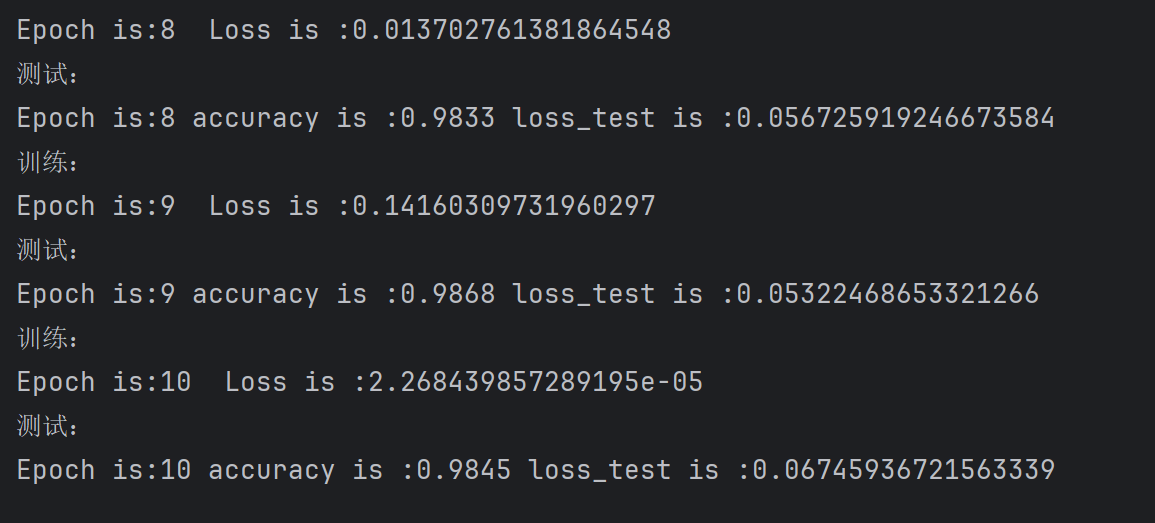
从数据来看,准确率 98%,loss 也在0.06 左右,基本是个好模型了。
完整代码
记得修改数据集的路径:
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.utils.data as data_util
# data
train_data = datasets.MNIST(root='datasets',train = True,transform = transforms.ToTensor(),download=True)
test_data = datasets.MNIST(root='datasets',train = False,transform = transforms.ToTensor(),download=False)# batchSize
train_loader = data_util.DataLoader(dataset=train_data,batch_size=64,shuffle=True)test_loader = data_util.DataLoader(dataset=test_data,batch_size=64,shuffle=True)
# net
class CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 定义第一个卷积操作self.conv = torch.nn.Sequential(# 参数的具体含义我们在卷积神经网络中介绍torch.nn.Conv2d(1, 32, kernel_size=(5,5),padding=2),# 第一个参数是灰度,第二个参数是输出通道,第三个参数是卷积核torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14*14*32,10) # 第一个是特征图整体的数量,第二个是Y的种类def forward(self, x):out = self.conv(x) # 第一个卷积out = out.view(out.size()[0],-1) # 拉成一个一维的向量out = self.fc(out) # 线性运算return out # 返回最后的输出
cnn = CNN()
cnn = cnn.cuda()
# loss
loss_fn = torch.nn.CrossEntropyLoss() # 交叉熵的损失函数# optimizer
optimizer = torch.optim.Adam(cnn.parameters(),lr=0.01)# 采用Adam 对学习率不是特别敏感
# training
for epoch in range(10):# 这里我们把整个数据集过 10 遍for i, (images, labels) in enumerate(train_loader):images = images.cuda() # 图片放到cuda上面labels = labels.cuda()# 定义输出结构outputs = cnn(images)loss = loss_fn(outputs,labels) # loss 传入输出的结果optimizer.zero_grad() # 梯度优化loss.backward() # 反向传播optimizer.step()# print("训练:\nEpoch is:{} Loss is :{}".format(epoch+1,loss.item()))
# testloss_test = 0accuracy = 0for i, (images, labels) in enumerate(test_loader):images = images.cuda() # 图片放到cuda上面labels = labels.cuda()# 定义输出结构outputs = cnn(images)# 我们使用交叉熵计算,label 的维度是[batchsize],每个样本的标签样本是一个值# outputs = batches * cls_num cls_num 概率分布也就是种类10 个loss_test += loss_fn(outputs, labels) # loss 传入输出的结果,对text_loss 进行一个累加,最后求平均值_, predicted = outputs.max(dim=1) # 获得最大的概率作为我们的预测值accuracy += (predicted ==labels).sum().item() # 我们通过相同的样本进行统计求和,通过item获取这个值accuracy = accuracy/len(test_data)loss_test=loss_test/(len(test_data)//64) # 除以batch的个数# .item() 将单元素张量转换为Python标量# print("测试:\nEpoch is:{} accuracy is :{} loss_test is :{}".format(epoch+1,accuracy,loss_test.item()))# 保存模型
torch.save(cnn,"model/cnn.pkl")三、保存模型与推理(inference)
模型保存
# 保存模型
torch.save(cnn,"model/cnn.pkl")
推理
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.utils.data as data_util# net
class CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 定义第一个卷积操作self.conv = torch.nn.Sequential(# 参数的具体含义我们在卷积神经网络中介绍torch.nn.Conv2d(1, 32, kernel_size=(5,5),padding=2),# 第一个参数是灰度,第二个参数是输出通道,第三个参数是卷积核torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14*14*32,10) # 第一个是特征图整体的数量,第二个是Y的种类def forward(self, x):out = self.conv(x) # 第一个卷积out = out.view(out.size()[0],-1) # 拉成一个一维的向量out = self.fc(out) # 线性运算return out # 返回最后的输出test_data = datasets.MNIST(root='../datasets',train = False,transform = transforms.ToTensor(),download=False)# batchSize
test_loader = data_util.DataLoader(dataset=test_data,batch_size=64,shuffle=True)
cnn = torch.load("cnn.pkl")
cnn = cnn.cuda()
# loss
loss_fn = torch.nn.CrossEntropyLoss() # 交叉熵的损失函数# optimizer
optimizer = torch.optim.Adam(cnn.parameters(),lr=0.01)# 采用Adam 对学习率不是特别敏感
# training
for epoch in range(10):# 这里我们把整个数据集过 10 遍
# testloss_test = 0accuracy = 0for i, (images, labels) in enumerate(test_loader):images = images.cuda() # 图片放到cuda上面labels = labels.cuda()# 定义输出结构outputs = cnn(images)# 我们使用交叉熵计算,label 的维度是[batchsize],每个样本的标签样本是一个值# outputs = batches * cls_num cls_num 概率分布也就是种类10 个loss_test += loss_fn(outputs, labels) # loss 传入输出的结果,对text_loss 进行一个累加,最后求平均值_, predicted = outputs.max(dim=1) # 获得最大的概率作为我们的预测值accuracy += (predicted ==labels).sum().item() # 我们通过相同的样本进行统计求和,通过item获取这个值accuracy = accuracy/len(test_data)loss_test=loss_test/(len(test_data)//64) # 除以batch的个数# .item() 将单元素张量转换为Python标量# print("测试:\nEpoch is:{} accuracy is :{} loss_test is :{}".format(epoch+1,accuracy,loss_test.item()))
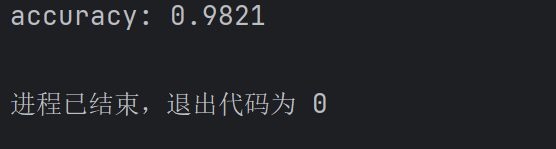
print("accuracy:",accuracy)模型推理的数据集一定要找准确,模型调用的路径也要准确。我们可以直接复制代码到新建的推理 python 文件中:
- 删除所有与训练有关的数据
- 删除模型的保存部分
3.模型初始化改成调用:cnn = torch.load("cnn.pkl")
4.修改打印参数
运行结果:
鸣谢
为了感谢我弟对我的照顾,我也没有什么可以报答的,如果这篇文章有助于大家搭建一个神经网络,有助于大家的pytorch编程,还请大家来我弟的小店逛一逛,增加一点访问量,小店才开也不容易,点击一下这里 ,谢谢大家~。