体系结构论文(八十六):The Dark Side ofComputing: SilentData Corruptions
The Dark Side of Computing: Silent Data Corruptions
目录
一、背景逻辑
计算的两大核心诉求
Property #1: Correctness
Property #2: Speed
技术难题引入
正确性风险来自哪里?
硅芯片的生命周期中,正确性风险如何发生?
为什么无法做到100%正确?
二、SILICON DEFECTS AFFECTING PROGRAMS
举例分析:从逻辑门缺陷开始
缺陷转化为程序错误需满足的4个条件
条件1:指令使用了乘法
条件2:特定输入值激活缺陷
条件3:逻辑路径传播错误
条件4:错误结果影响最终程序执行
图1的说明
通用化:任何硬件单元都有可能
三、VISIBLE AND SILENT EFFECTS OF DEFECTIVE SILICON
先问核心问题
可见性错误 (Visible Errors)
静默错误 (Silent Data Corruptions, SDC)
很多人会直觉反应:加检测机制不就完了?
硬件 vs 软件检测成本分析
四、SDC DISCLOSURES: PAST AND PRESENT
早期大家对 SDC 的认知:神话 or 个例
大规模云厂商开始披露真实数据
各家披露数据总结 (表 Table 1)
SDC ≠ Detectable Error
理想目标 vs 工程现实
五、WHAT COMPANIES REALLY DISCLOSED?
现有披露仍然非常有限
目前的主要未解问题
问题:不知道弱点就无法防御
核心哲学问题:你无法测量 SDC
如何估算 SDC 规模?
可见性错误 vs 静默错误
终极问题:能接受多少SDC?
六、REDUCING SDCs AND THE COST
六、 MORE DISCLOSURES FROM INDUSTRY?
Meta, Google, Alibaba 是非常罕见的披露者
但为什么大多数公司仍然讳莫如深?
原因一:可靠性≠卖点
原因二:无法验证的指标难以公开
七、SDC-AWARENESS IN COST MODELS
当前变化
新的商业逻辑:按 SDC 风险分级定价
最终,成本承担者在博弈
八、SDCs FROM DATA PARALLEL ARCHITECTURES
目前披露多集中在 CPU
数据并行架构风险更高
直觉结论:AI系统更脆弱
九、PRACTICAL (COST-EFFECTIVE) RESEARCH DIRECTIONS
背景铺垫:技术越进步,风险越难控
三个主要研究方向
① SDC真实发生率的估算模型(SDC rate estimation)
② 数据中心在线扫描机制(In-field fleet scanning)
③ 层次化软硬件容忍机制(Tolerance at HW/SW layers)
全栈式多学科协作
本文聚焦于当今计算系统中的 Silent Data Corruptions (SDCs) —— 即在硬件(尤其是硅芯片)中,由于缺陷导致的无感知数据错误。SDC 的严重性在于:
-
程序运行完成、没有异常、没有崩溃、输出看似合理;
-
实际结果却是错误的,且没有被任何检测机制捕获。.
1. 计算的两大核心诉求
-
正确性(Correctness)
-
性能(Speed)
-
这两者都很昂贵且难以兼顾,尤其在硬件设计和制造中更是如此。
2. 硅缺陷的来源与危害
-
设计缺陷(design bugs)
-
制造缺陷(manufacturing defects)
-
老化、辐射、材料老化(mission time defects)
-
这些缺陷可能导致某些逻辑门在特定条件下输出错误,例如文中举了乘法器里一个 OR 门错误输出的例子。
3. 静默数据错误的危害
-
SDC最大的问题是:用户与系统完全不知情。
-
相比于崩溃或异常,SDC更隐蔽、更难以捕捉,也因此对关键应用(金融、医疗、AI等)危害极大。
4. 大规模云厂商的披露数据
-
Meta:数十万台机器中有上百颗 CPU 存在 SDC
-
Google:几千台机器中有若干核心存在问题
-
Alibaba:3.61% 的 CPU 存在 SDC
-
表明 SDC 不是“极端偶发”,而是实际存在的工程性问题。
5. 为什么难以量化
-
SDC本质是“静默的”,没法直接观测。
-
只能靠间接估算,例如微架构级 fault injection 模拟、数据中心场景仿真等。
6. 降低 SDC 的手段与成本
| 手段 | 降低原因 | 成本 |
|---|---|---|
| 更好的制造测试 | 避免缺陷流入 | 制造成本高 |
| 降低芯片工艺变异 | 筛掉临界品 | 良品率下降 |
| 硬件容错设计 | 运行时修正 | 硬件面积、功耗、性能损失 |
| 软件容错 | 运行时检测修正 | 计算与能耗开销 |
7. 数据中心的商业考虑
-
未来可能出现分级定价:低SDC率的云资源更贵,SDC风险由谁承担需要在云厂商、芯片厂商和用户之间权衡。
8. 未来研究方向
-
更精准的 SDC 率估算与建模
-
数据中心在线检测机制
-
硬件与软件容错共设计
-
跨层次的体系架构可靠性协同(硬件设计、微架构、ISA、编译器、应用层)
“SDC问题正逐渐从神话走向现实,工业界与学术界需共同投入,跨硬件-软件栈设计新一代可依赖的计算系统。”
一、背景逻辑
计算的本质诉求是正确性 + 速度,而这两个目标在工程实践中都非常昂贵,尤其在芯片制造中,「正确性」其实从来不是100%保证的,导致了静默错误的存在。
计算是伟大的,但本文要讲的是隐藏在这一切背后的黑暗面 —— 硅缺陷导致的程序数据损坏,且难以被察觉(即SDC问题)。
计算的两大核心诉求
Property #1: Correctness
-
计算结果必须是正确的。
-
取决于应用领域,不同行业对“正确”的定义不同:
-
有时正确结果是唯一值(如9753);
-
有时是一个范围(如9500~9800都可接受,容许一定误差)。
-
Property #2: Speed
-
正确结果若来得太晚也没有意义;
-
各行业的时间要求不同:从毫秒、秒、小时,到数周。
-
有实时要求的系统里,速度与生命、财产直接挂钩;商业系统中,速度则和收益、市场竞争力有关。
-
底层逻辑:速度是竞争力,速度是生命线。
技术难题引入
-
核心点:
-
计算速度和正确性永远在被极限挑战;
-
两者都非常昂贵;
-
工程师必须权衡:是更快还是更准?
-
每一个正确性和性能的提升背后都是设计、制造和运营成本的提升。
-
正确性风险来自哪里?
-
材料缺陷(原材料不完美)
-
制造缺陷(芯片设计和制造过程引入缺陷)
- 系统装配缺陷(板卡和整机层面的问题)
- 网络错误(通信传输层出错)
- 程序员错误(代码逻辑缺陷)
- 数值精度误差(尤其在并行程序中累积的计算误差)
-
延伸理解:
-
这些问题无处不在,任何一层出错都可能影响到最终计算结果;
-
为了解决这些正确性问题,我们需要付出额外资源与时间成本。
-
硅芯片的生命周期中,正确性风险如何发生?
作者把硅芯片可能出错的阶段分为三大类:
| 阶段 | 典型问题 |
|---|---|
| 设计阶段 (Design Time) | 设计BUG、逻辑漏洞 |
| 制造阶段 (Manufacturing Time) | 硅片缺陷、物理参数波动 |
| 运行阶段 (Mission Time) | 老化(aging)、辐射(radiation) |
为什么无法做到100%正确?
-
理想情况下:厂商能完全消除所有缺陷,但现实中做不到。
-
现实情况:
-
新产品开发周期越来越短(6~12个月)
-
测试覆盖率受限(实际最多能检测掉95%~99%缺陷)
-
即便出厂时无缺陷,随着使用时间的推移,新缺陷仍会出现(老化、辐射等)
-
-
工程实践真相:
-
100%检测覆盖成本极高
-
始终有少量缺陷逃逸进入市场
-
这些逃逸缺陷就是SDC的重要来源
-
二、SILICON DEFECTS AFFECTING PROGRAMS
核心话题:
硅缺陷是怎么一步步影响程序运行的?什么条件下才会造成真正的数据错误?
举例分析:从逻辑门缺陷开始
-
作者用非常简单、工程上常见的例子入手:
-
假设在 整数乘法器(integer multiplier)里,有一个二输入OR门存在制造缺陷:
-
正常情况下 OR 门的真值表:
输入A 输入B 输出 0 0 0 0 1 1 1 0 1 1 1 1 -
现在因为制造缺陷(例如短路、断线等):
-
当输入是 (0,0) 时,错误地输出 1(应为0)
-
其余输入时仍然正常。
-
-
这种缺陷可能是:
-
永久性(Persistent):始终存在;
-
偶发性(Intermittent):只有在某些物理条件下才触发(如温度、电压波动等)。
缺陷转化为程序错误需满足的4个条件
条件1:指令使用了乘法
-
程序中必须包含乘法操作,这样才会调用到这个含有缺陷的乘法器单元。
条件2:特定输入值激活缺陷
-
乘法运算中,部分中间计算逻辑需要输入为 (0,0),才会用到这个错误分支的 OR 门;
-
如果输入不是 (0,0),缺陷不会被激活(这其实就是所谓的 fault activation condition)。
条件3:逻辑路径传播错误
-
出错的 OR 门输出,必须能通过逻辑链路传递到乘法器的最终输出;
-
否则即使 OR 门出错,也可能在后续逻辑中被屏蔽掉(fault masking)。
条件4:错误结果影响最终程序执行
-
错误的乘法结果必须在程序后续中被使用并引起实际危害:
-
程序崩溃(crash、hang、exception)
-
控制流紊乱(如指针计算错误)
-
数据流错误(最终结果出错)
-
注意:
如果以上任一条件不满足,缺陷就不会表现为程序层面的错误。
这其实正是为什么很多 SDC 是间歇性、难以复现、难以检测的核心原因。
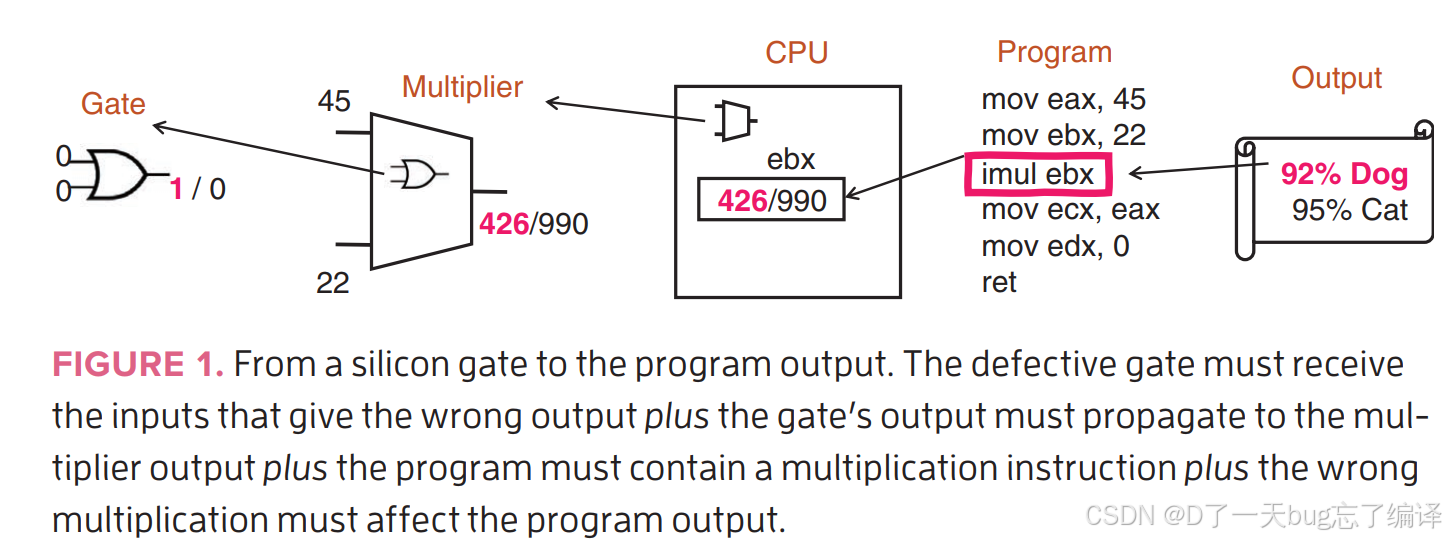
图1的说明
-
图里用了一条“狗和猫”的分类模型例子(有点像AI inference场景):
-
因为乘法结果错误,模型把应当识别为猫的图像识别成狗。
-
-
这是非常典型的静默数据错误 —— 执行完成、没有crash、没有异常,但结果悄悄错了。
通用化:任何硬件单元都有可能
-
不只是乘法器:
-
寄存器(Registers)
-
缓存(Caches)
-
缓冲区(Buffers)
-
控制逻辑(Control Logic)
-
算术逻辑单元(Arithmetic Units)
-
-
甚至包括内存(DRAM、SRAM)
-
这些单元一旦出现缺陷,都可能导致数值在传输、存储、处理过程中产生错误。
三、VISIBLE AND SILENT EFFECTS OF DEFECTIVE SILICON
核心主题:
硅缺陷产生错误以后,错误的后果有两种 ——
可见的(Visible)错误 与 不可见的(Silent Data Corruption, SDC)错误。
先问核心问题
-
一旦芯片中存在缺陷,核心的问题不是“是否出错”,而是:
-
我们知不知道程序出错了?
-
-
这是 SDC 与一般硬件错误本质区别的第一性问题。
可见性错误 (Visible Errors)
-
比如:
-
程序崩溃 (crash)
-
异常抛出 (exception)
-
操作系统或软件检测到异常 (e.g. segmentation fault)
-
-
这些错误虽然让人讨厌,但至少用户知道系统出问题了:
-
可以重试;
-
如果多次出错,用户可能会:
-
更换机器;
-
修理硬件;
-
更换芯片。
-
-
工程意义:
-
可见错误可以感知、可以触发维护流程;
-
在高可靠性系统中,这类错误往往会触发 failover 机制。
静默错误 (Silent Data Corruptions, SDC)
-
SDC定义:
-
程序执行结束;
-
没有crash;
-
没有异常;
-
没有系统报告错误;
-
结果看起来“合理”,但实际上是错误的;
-
没有任何监测机制捕捉到错误。
-
-
危险性在于:
-
"nobody knows!"
-
这才是SDC真正可怕的地方:在不知道的情况下继续使用错误的结果。
-
注意:
SDC结果往往看起来是“可信”的,比如分类模型中把猫错判为狗;
但是在金融、医疗、安全系统等关键场景中,这种悄悄发生的错误可能导致灾难性后果。
很多人会直觉反应:加检测机制不就完了?
-
是的,很多人第一反应就是:
加硬件检测(例如 ECC, parity, logic BIST)或软件检测(例如 redundancy, N-modular redundancy)
-
但作者马上指出:检测机制的代价极高!
硬件 vs 软件检测成本分析
| 类型 | 典型方法 | 代价 |
|---|---|---|
| 硬件检测 (Hardware-based detection) | ECC (Error Correction Code)、Parity、逻辑冗余电路 | 硅面积增加 2% ~ 125%;功耗增加;设计复杂性提升 |
| 软件检测 (Software-based detection) | 冗余执行(如DMR, TMR)、指令级校验、软件投票机制 | 计算性能下降 100%~200%;能耗翻倍甚至更多 |
-
也就是说:理论上可行,工程上很难接受。
-
尤其在高性能计算、AI加速、数据中心等场景,这些检测开销常常是不可承受的。
四、SDC DISCLOSURES: PAST AND PRESENT
早期大家对 SDC 的认知:神话 or 个例
-
在 2008年的DSN会议 上,社区首次系统性地提出了:
“Silent Data Corruption 到底是真实存在,还是只是个传说?”
-
在很长一段时间里大多数人认为:
-
要么即使存在,其概率极低(百万分之一、十亿分之一)。
-
SDC 要么根本不存在;
-
-
这其实反映了早期计算系统小规模、低复杂度时的实际经验。
大规模云厂商开始披露真实数据
-
随着云计算、超大规模数据中心的兴起,现实开始打脸了:
Hyperscalers(如 Meta、Google、Alibaba)在最近几年披露了 远高于原先想象的SDC发生率。
-
大致频率:
-
大约 1/1000 台 CPU 可能产生 SDC;
-
而且不仅限于 CPU,连 AI加速器 (TPU, NPU, GPU) 也存在类似问题。
-
-
重要一点:
SDC 不完全是“制造时没测出来”那么简单,有些是老化、环境变化、芯片工艺变异导致的长期性缺陷。
各家披露数据总结 (表 Table 1)
| Hyperscaler | 描述性表述 | 估算DPPM (Defective Parts Per Million) |
|---|---|---|
| Meta | "hundreds of CPUs across hundreds of thousands of machines" | ≈ 1000 DPPM |
| "a few mercurial cores per several thousand machines" | < 1000 DPPM | |
| Alibaba | "3.61% of CPUs are identified to cause SDCs" | ≈ 361 DPPM |
注意:
-
虽然DPPM量级不同,但三家都承认:
SDC在百万分之一数量级下确实存在,远高于曾经假设的百万分之一/十亿分之一。
SDC ≠ Detectable Error
-
一旦某个缺陷被检测出来,它就已经不属于SDC了。
-
SDC 是“运行时未被检测到的错误结果”:
-
程序执行完毕;
-
没有异常;
-
输出错误;
-
没有任何检测机制发现。
-
-
对应容错计算的经典术语:
-
Fault:缺陷本身(制造缺陷、老化、辐射等)
-
Error:缺陷在执行过程中被激活,产生了计算错误
-
Failure:最终让系统输出了错误结果
-
SDC:隐形 failure
-
-
“SDC检测机制”这种表述在术语上其实是不严谨的(因为能检测就不是SDC了)。
理想目标 vs 工程现实
-
理想世界下,芯片计算结果应满足:
-
正确(either defect is harmless or correction works)
-
错误但可检测(detected but correction unavailable)
-
-
完全消灭SDC(zero-SDC)在现实中是不可能的:
-
因为成本极其高昂;
-
即便你设计了最复杂的检测/容错机制,仍然可能有遗漏。
-
五、WHAT COMPANIES REALLY DISCLOSED?
现有披露仍然非常有限
-
虽然大公司(Meta, Google, Alibaba)已经公布了一些数据(如 Table 1 所示);
-
但实际有很多关键细节仍然未知;
-
简单来说:问题存在,但细节模糊。
目前的主要未解问题
作者列出几个关键研究问题,其实可以看作是未来做SDC相关研究的研究课题列表,非常实用:
| 研究方向 | 具体问题 |
|---|---|
| 真实SDC率是多少? | 实际运行真实工作负载时到底有多少程序输出被悄悄污染? |
| 哪类微架构更容易出SDC? | 哪些CPU设计容易受影响? |
| 哪些硬件单元更容易出SDC? | 比如Alibaba暗示浮点和向量单元更易出问题 |
| 哪些指令更易激活缺陷? | 某些指令组合更容易触发已存在的缺陷 |
| 哪些工艺节点更容易出SDC? | 工艺微缩越先进越难制造,是否反而提升了SDC风险? |
问题:不知道弱点就无法防御
-
作者强调:
-
如果不知道容易出错的硬件单元、指令类型、设计架构;
-
无法合理设计检测、加固、替换或采购策略;
-
甚至芯片厂商自己也很难改进下一代设计。
-
-
这直接暴露出目前芯片设计在可靠性建模上的严重认知缺口。
核心哲学问题:你无法测量 SDC
-
这是作者的核心观点之一:
-
SDC本质是不可观测的;
-
你无法统计一件你看不到、感知不到的东西;
-
所以最终只能做估算(Estimation),而非测量(Measurement)。
-
如何估算 SDC 规模?
-
估算SDC数量需要考虑多个维度:
| 因素 | 说明 |
|---|---|
| 数据中心规模 | 核心数量越多,出错总数越大 |
| 芯片缺陷率 | 不同批次芯片DPPM不同 |
| 工作负载类型 | 算力密集型负载会放大缺陷激活概率 |
| 执行时长 | 任务执行时间越长,暴露缺陷的机会越多 |
使用微架构级故障注入进行初步估算
-
作者团队使用微架构级故障注入在x86 CPU模型上做了首轮估算;
-
只针对 算术单元(包括整数、浮点和向量单元) 的缺陷;
-
这只是初步估算,但能体现出问题的严峻性。
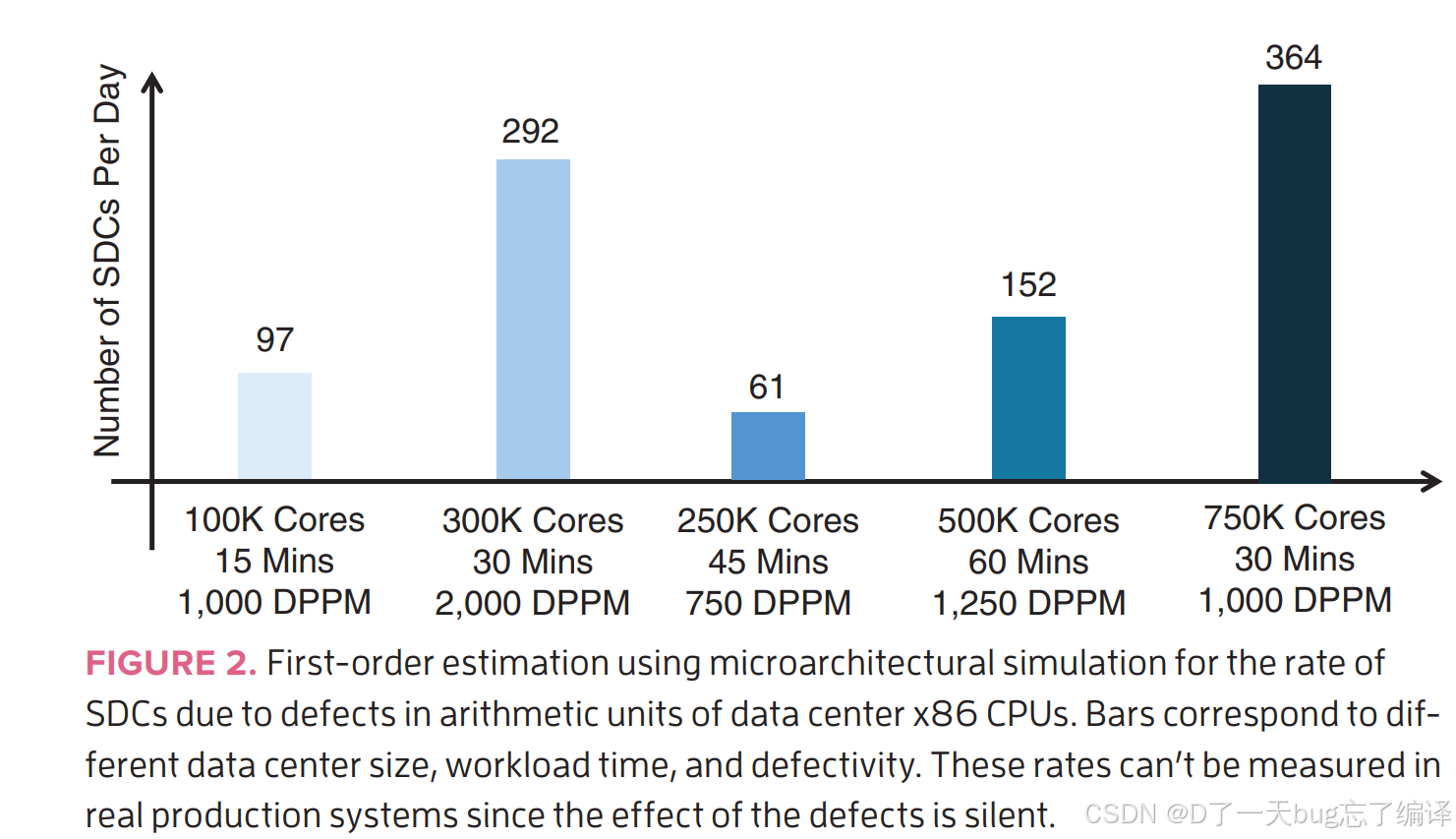
图中变量
-
数据中心规模(核心数)
-
工作负载执行时长(单位分钟)
-
缺陷率(DPPM)
解读:
-
数据中心规模每扩大会放大SDC总数;
-
缺陷率稍有提升也会极大影响总数;
-
任务运行时间越长,激活缺陷的机会越高;
-
每天会悄悄产出几百个有错误的程序结果,用户完全无感知!
可见性错误 vs 静默错误
-
图中数字完全是静默数据错误的估算值;
-
因为:
-
一旦某CPU因为crash等可见错误被检测到,它早已被移出服务器集群;
-
所以这些被移除的CPU不再制造SDC;
-
图里显示的是仍然在服役中的CPU每天还在持续制造 SDC。
-
终极问题:能接受多少SDC?
-
工程角度上,任何SDC都是有害的;
-
在关键任务系统(金融、医疗、航天)里,目标永远是Zero SDC;
-
但现实又让 Zero SDC 几乎无法做到 —— 这就形成了整个可靠性工程的核心张力。
六、REDUCING SDCs AND THE COST
| 方案 | 降低SDC的原因 | 带来的成本 |
|---|---|---|
| 更好的制造测试 (Better manufacturing testing) | 测试流程更严苛,更多制造缺陷能在出厂前被筛掉 → Fewer SDCs! | 制造测试成本上升(测试时间长、设备贵);芯片单价上涨 |
| 减少芯片工艺变异 (Reduced chip variability) | 排除临界合格品(边界良品),只允许完全健康的芯片流入市场 → Fewer SDCs! | 良品率下降,废品率上升;芯片单价上涨 |
| 硬件缺陷容忍 (Enhanced hardware defect tolerance) | 增加硬件冗余、容错逻辑(例如ECC, TMR, Razor) → Fewer SDCs! | 设计复杂度、面积、功耗、验证成本、性能损失全都增加 |
| 软件容错 (Enhanced software error tolerance) | 通过冗余执行、校验性算法在软件层捕获并修正部分错误 → Fewer SDCs! | 性能下降(100%~200%)、能耗上升、复杂度增加 |

SDC其实可以被控制,但所有方法的共同代价就是 —— "system costs more"
六、 MORE DISCLOSURES FROM INDUSTRY?
Meta, Google, Alibaba 是非常罕见的披露者
-
Meta 首次公开 SDC 调研结果,引发学界广泛关注;
-
后续 Google、Alibaba 也相继确认类似现象;
-
一些硬件公司(AMD、Intel、NVIDIA、ARM)也加入了 Open Compute Project(OCP)合作,共同讨论SDC问题;
-
IEEE、ACM、OCP等组织也陆续组织了会议、专题、论文、研讨会推动学术研究。
但为什么大多数公司仍然讳莫如深?
作者总结了两个非常现实的产业动因:
原因一:可靠性≠卖点
-
市场导向问题:
-
市场更关注性能(Performance)、功耗(Power)、单位计算性价比;
-
消费者不太关注芯片内部有多少“隐形错误”;
-
即使偶尔出错,数据中心、软件、算法本身也会掩盖掉很多错误;
-
可靠性从来不是厂商主打的卖点(除了极少数航天、医疗、军工场景)。
-
-
商业逻辑:
-
如果厂商承认产品存在SDC,可能会伤害品牌信任;
-
甚至引发合规、诉讼等风险。
-
原因二:无法验证的指标难以公开
-
工程学本质问题:
-
SDC本身是“静默”的,无法直接测量;
-
任何公司说“我们SDC是一年一次/百万分之一”都无法第三方复现;
-
不像性能、功耗可以反复benchmark确认;
-
因此产业界更倾向于不公开模糊数据,避免争议与不确定性放大。
-
七、SDC-AWARENESS IN COST MODELS
SDC应该被纳入数据中心的成本与商业模型中。
当前变化
-
随着 hyperscalers(超大规模云服务商,如Meta、Google、Alibaba)日益认识到 SDC 问题的现实性:
-
他们在芯片采购时会要求更高的制造质量;
-
也在数据中心运行期间,尝试监测和剔除存在缺陷的芯片;
-
整个产业链正在逐步正视这一问题,开始寻找工程解决方案。
-
新的商业逻辑:按 SDC 风险分级定价
-
提出了一种全新的云计算商业模式设想:
| 方案 | 描述 | 定价策略 |
|---|---|---|
| 高SDC率服务 | 云厂商提供廉价计算资源,但不保证结果正确性(SDC用户自行承担) | 便宜 |
| 低SDC率服务 | 云厂商投入额外硬件检测与验证,最大限度确保结果可靠性 | 收费更高 |
-
本质逻辑:
可靠性也是可以作为一种“服务质量指标(QoS)”进行售卖的。
最终,成本承担者在博弈
-
SDC的代价必须有人来承担:
-
芯片厂商 → 提高制造测试标准,单颗芯片更贵;
-
云厂商 → 增加运维检测与冗余机制,基础设施成本上升;
-
最终用户 → 根据所选服务等级为可靠性付费。
-
八、SDCs FROM DATA PARALLEL ARCHITECTURES
AI/NPU/GPU 等大规模数据并行架构,其实面临更严重的 SDC 风险。
目前披露多集中在 CPU
-
到目前为止,已有数据披露主要集中在 CPU 领域;
-
但是这不代表 GPU、AI加速器、NPU 等更复杂架构就更安全 —— 恰恰相反!
数据并行架构风险更高
-
数据并行架构特点:
-
算术单元数量巨大(特别是乘法器、矩阵乘法单元、Tensor Cores 等);
-
每个计算周期里激活单元的总量极高;
-
AI 训练和推理任务往往长时间高负载运行;
-
缺陷激活机会、错误传播通道远超CPU。
-
经典例子:
CPU里可能有几十个乘法器;
而在一颗TPU/NPU中,可能有成千上万个MAC阵列,SDC暴露概率几何级上升。
直觉结论:AI系统更脆弱
-
对AI加速器来说:
-
SDC已不再是“偶发性极低”的问题;
-
而是体系结构层面天然易感的可靠性风险源;
-
特别是在关键应用(自动驾驶、金融AI、医疗AI等)中影响巨大。
-
九、PRACTICAL (COST-EFFECTIVE) RESEARCH DIRECTIONS
在技术规模和复杂性日益提升的当下,完全消除SDC已经不现实,但可以有一系列成本可接受的研究方向,来降低SDC风险与代价。
背景铺垫:技术越进步,风险越难控
-
技术极限被不断突破(更高频、更小制程、更大规模);
-
硅缺陷、制造波动、老化等概率风险被放大;
-
系统规模指数级扩张 → 微小概率事件累计成显著风险;
-
“速度贪婪”挑战了系统正确性保障的极限能力。
三个主要研究方向
① SDC真实发生率的估算模型(SDC rate estimation)
-
关键逻辑:
-
目前产业报告的 DPPM (每百万颗芯片中缺陷颗数)仅仅告诉我们芯片里有缺陷;
-
但是否产生SDC,取决于缺陷是否被激活(即实际运行负载是否触发缺陷逻辑);
-
同样的缺陷,不同的 workload 触发概率完全不同。
-
-
理想的研究方向:
-
建立 workload-aware 的 SDC 发生概率模型;
-
结合指令分布、执行热度、算术单元激活统计等进行概率建模;
-
支撑软件容错策略设计(如 selective duplication、instruction-level hardening)。
-
② 数据中心在线扫描机制(In-field fleet scanning)
-
制造测试再好也只能抓住出厂缺陷;
-
运行中的设备会由于:
-
老化 (aging)
-
瞬态扰动(如热、电压波动、EMI等)
-
罕见逻辑状态组合暴露出隐藏缺陷;
-
-
因此需要:
-
周期性在线扫描机制;
-
监控复杂 workload 场景下激活的 defect 行为;
-
及时识别问题芯片 → 动态隔离或替换 → 降低大规模SDC堆积风险。
-
-
学术挑战点:
-
如何设计高效的在线筛查机制,不增加太多性能/能耗/成本负担;
-
如何在不影响服务质量的前提下做在线退役或动态降级。
-
③ 层次化软硬件容忍机制(Tolerance at HW/SW layers)
-
核心思想:
-
硬件容忍 → 设计硬件自检、自修复逻辑(如冗余乘法器、局部bypass机制)
-
软件容忍 → 软件冗余计算、校验性算法、soft voting等策略
-
-
但作者也指出:
-
超大规模数据中心很难承受大规模冗余代价(面积、功耗、性能损失)
-
Massive redundancy not affordable
-
-
更实际的策略:
-
当已知芯片某些模块有缺陷但可控 → 局部降级使用;
-
动态屏蔽或绕过缺陷逻辑单元(例如禁用部分向量单元、关闭部分Tensor Core);
-
保持整体系统在“退化容忍模式”下稳定运行。
-
全栈式多学科协作
-
研究责任横跨整个计算系统栈:
| 层次 | 关键贡献点 |
|---|---|
| 物理设计 (Physical Design) | 工艺波动控制、老化容忍 |
| 逻辑/微架构设计 (Logic & Microarchitecture) | 容错逻辑、selective redundancy |
| 指令集架构 (ISA) | 容错友好ISA设计 |
| 系统软件 (OS/Runtime) | 动态任务迁移、在线诊断机制 |
| 编译器 (Compilers) | 编译期冗余注入与安全指令选择 |
| 应用软件 (Applications) | 算法级容错、数据冗余、训练时稳健性优化 |