PyTorch框架-自动微分模块
1.自动微分概念
自动微分(Automatic Differentiation,AD)是一种利用计算机程序自动计算函数导数的技术,它是机器学习和优化算法中的核心工具(如神经网络的梯度下降)
2.梯度的计算
训练神经网络时,最常用的算法就是反向传播。在该算法中,参数(模型权重)会根据损失函数关于对应参数的梯度进行调整。为了计算这些梯度,PyTorch内置了名为 torch.autograd 的微分模块。计算梯度就是为了更新权重,以下是计算流程:
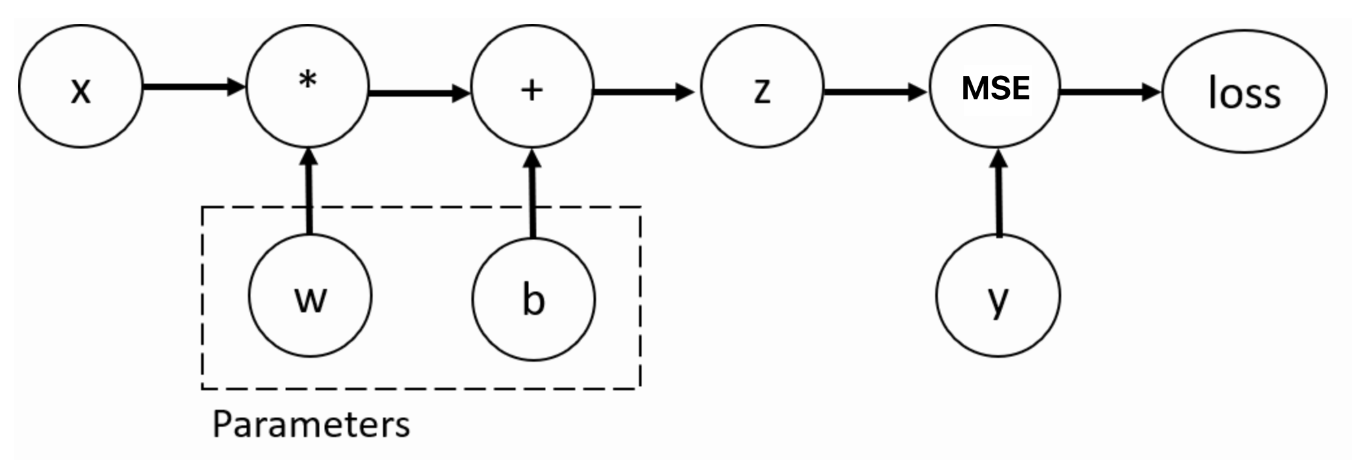
计算公式:
① 梯度下降法公式: w = w - r*grad (r是学习率, grad是梯度值)
即:下一个点 = 起始点 - 学习率*梯度
② w和b一定是可自动微分的张量, 类型是float类型
需要设置 torch.tensor(requries_grad=True)
注: 自动微分的张量不能转换成numpy数组, 通过.detach()张量剥离成不自动微分, 可以转换
单轮
# 导包
import torch# TODO 自动微分模块主要用于梯度计算!!!
# 定义权重 requires_grad=True:开启自动微分
w = torch.tensor([10, 20], requires_grad=True, dtype=torch.float)
# 定义损失函数(loss,cost,criterion...)
loss = 2 * w ** 2
# 自动微分求梯度,自动更新梯度
loss.sum().backward()
# 格式化输出
print(f"当前权重: {w.data},固定学习率:{0.01} 更新后梯度: {w.grad},下一个权重: {w.data - 0.01 * w.grad}")
# TODO 手动更新权重
# 公式: w1 = w0 - learning_rate * grad
w.data = w.data - 0.01 * w.grad当前权重: tensor([10., 20.]),固定学习率:0.01 更新后梯度: tensor([40., 80.]),下一个权重: tensor([ 9.6000, 19.2000])
多轮自动微分
# 导包
import torch# TODO 自动微分模块主要用于梯度计算!!!
# 定义权重 requires_grad=True:开启自动微分
w = torch.tensor(10, requires_grad=True, dtype=torch.float)
# 打印首次默认梯度
print(f"初始权重: {w.data},初始梯度: {w.grad}") # 初始梯度None
# TODO 定义遍历轮次
epochs = 500
# TODO 开始遍历
for epoch in range(epochs):# 定义损失函数(自定义即可loss,cost,criterion...)loss = w ** 2 + 20# loss = 2 * w ** 2# TODO 注意: 默认梯度是累加的,所以每个轮次需要在自动微分之前进行清零!!!if w.grad is not None:w.grad.zero_() # 后续使用优化器清零# 自动微分求梯度,自动更新梯度loss.sum().backward()# 格式化输出print(f"当前轮次:{epoch + 1} 当前权重: {w.data},固定学习率:{0.01} 更新后梯度: {w.grad},下一个权重: {w.data - 0.01 * w.grad}")# TODO 手动更新权重# 公式: w1 = w0 - learning_rate * gradw.data = w.data - 0.01 * w.grad
代码量太多,结果只放最开始和结束的权重
初始权重: 10.0,初始梯度: None
当前轮次:1 当前权重: 10.0,固定学习率:0.01 更新后梯度: 20.0,下一个权重: 9.800000190734863当前轮次:500 当前权重: 0.000418612064095214,固定学习率:0.01 更新后梯度: 0.000837224128190428,下一个权重: 0.00041023982339538634
推导w,b梯度
# 导包
import torch# 准备x训练数据
x = torch.ones(2, 5)
print(x)
# 准备y训练数据
y = torch.zeros(2, 3)
print(y)
# 准备w权重矩阵,开启自动微分!!!
w = torch.randn(5, 3, requires_grad=True)
print(w)
# 准备b偏置矩阵,开启自动微分!!!
b = torch.randn(3, requires_grad=True)
print(b)
print('=========================================')
# TODO 最终目的根据上述数据,使用自动微分推导w和b的梯度
# 1.首先获取损失函数
loss_fn = torch.nn.MSELoss()
# 2.然后,计算预测值-> z=wx+b 注意: 这里面的wx是矩阵乘法需要遵循 (n,m)*(m,p)=(n,p)
z = x.matmul(w) + b
# 3.接着,根据损失函数计算损失值
loss = loss_fn(z, y)
# 4.最后,反向传播推导更新梯度
loss.sum().backward()
# TODO 打印更新后w和b梯度
print(f'w.grad: {w.grad}')
print(f'b.grad: {b.grad}')[1., 1., 1., 1., 1.]])
tensor([[0., 0., 0.],[0., 0., 0.]])
tensor([[ 0.5068, 0.7041, -0.3873],[ 0.2316, -0.6001, -2.0265],[ 0.7206, -0.3271, -1.6952],[ 0.0378, 0.3277, -0.1473],[-0.9443, -0.8589, 0.6169]], requires_grad=True)
tensor([-0.0277, 0.5842, -0.5767], requires_grad=True)
=========================================
w.grad: tensor([[ 0.3498, -0.1134, -2.8108],[ 0.3498, -0.1134, -2.8108],[ 0.3498, -0.1134, -2.8108],[ 0.3498, -0.1134, -2.8108],[ 0.3498, -0.1134, -2.8108]])
b.grad: tensor([ 0.3498, -0.1134, -2.8108])