(二十七)深度解析领域特定语言(DSL)第四章——词法分析:基于状态机的词法分析器
通过前文示例代码可知,基于正则表达式的词法分析器会输出DSL脚本对应的全部Token。由图 5.6可见,由于语法分析器已获取全部Token,运行过程中无需再与词法分析器交互,二者呈现单向的输出-输入关系。
本小节将基于代码5-1介绍另一种词法分析器实现方式。该方式不依赖正则表达式,也不会一次性向语法分析器输出全部Token。取而代之的是,语法分析器在运行过程中动态调用词法分析器获取Token,遵循"获取一个、分析一个"的循环模式,直至语法分析完成或因语法错误中止,其运作原理如图 5.7所示。
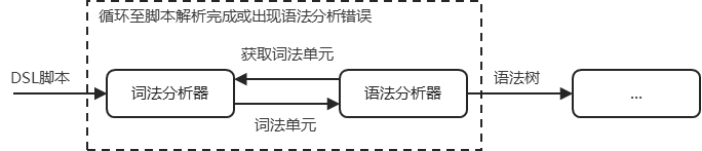
需要强调的是,无论是基于状态机还是正则表达式的实现,本质上均属于词法分析器的实现范式。而词法分析器与语法分析器的交互模式、Token的识别方式,二者并无固定绑定关系。例如,基于状态机的词法分析器可采用图 5.6所示的批量输出模式;基于正则表达式的词法分析器也可按图 5.7所示的按需获取方式运作。这一点在前文已有明确阐述。
客观来讲,上一章中给出的词法分析器存在较为显著的问题,性能问题便是其中之一。由于该词法分析器会一次性输出所有Token,当DSL脚本规模较大时,Token所占用的内存空间可能会变得极为可观。相较之下,本小节采用的实现方式在性能表现上更为优异,其不仅不要求词法分析器输出全部Token,而且在检测到语法错误时,能够迅速宣告语法分析失败并终止整个DSL的编译流程。
尽管笔者在标题中将词法分析器的实现方式划分为基于状态机和基于正则表达式两种类型,但二者并非完全互斥。词法分析器的本质是有限状态机,而正则表达式同样建立在有限状态机理论基础之上,是该理论的具体应用形式。通常情况下,二者(针对基本正则表达式)是可以相互转换的,这也解释了为何许多词法分析器生成器(如Lex或Flex)能够依据正则表达式自动构建词法分析器。因此,即便选择基于状态机的实现方式,也可将正则表达式融入其中——实际上,这正是笔者推荐的实现方式。虽然通过手动匹配方式实现词素识别可能具备更高的执行效率,但通常存在出错概率较高且代码维护难度较大的缺点。鉴于已有成熟工具可供使用,便无需重复开发类似功能。当然,在当前案例中,笔者并未将二者结合,而是更希望向读者展示如何仅依赖纯粹的算法实现词素识别。尽管这需要更多的编程工作,但有助于读者深入理解词法分析器的基本工作原理。
关于词法单元类型TokenType的定义,可参考代码5-8。需要注意的是,其中存在一些重要调整,主要体现在TokenType类型的属性方面。由于不再需要使用正则表达式,因此可从类中移除该字段。
Token类的定义也有一些修改,笔者为其加上了一个用于标识行号的字段lineIndex,如代码5-16所示:
代码5-16class Token {...int lineIndex;Token(TokenType type, String lexeme, int colIndex, int lineIndex) {...this.lineIndex = lineIndex;}
}lineIndex的使用逻辑存在一定的理解门槛。尽管代码5-1所示的DSL以分号作为逻辑行的分隔单位,但引入行号机制仍具有实质意义,具体原因如下:
- 单条DSL语句可能存在物理行长度超过显示范围的场景。虽然多数文本编辑器支持自动换行显示,但代码过长导致的阅读和定位问题依然存在。若词法分析器支持换行解析,允许DSL语句跨物理行延续,则在Token中记录行号信息成为必要——这一机制可在语法分析阶段检测到错误时,提供精确至物理行的定位提示,显著提升错误诊断的效率。
- 从系统设计的通用性目标出发,笔者期望构建一个可扩展的词法分析器框架,以适配未来可能接触的复杂语言结构。随着学习进程的深入,DSL将逐步引入代码块等层次化结构,此时行号信息不仅能满足当前简单场景的错误定位需求,其背后的设计思想(如基于物理行的上下文追踪)更可直接复用于后续复杂案例,确保框架在不同应用场景下的一致性和可维护性。
下面,让我们一起看一下词法分析器的定义,如代码5-17所示:
代码5-17class BaLexer {Map<String, Token> words = new HashMap<>();char peek = ' ';//预读字符int lineIndex = 1;int colIndex = 0;private char[] sourceCode;int readerIndex = 0;List<Character> legalCharacters = Arrays.asList('_', '-');List<Character> empties = Arrays.asList(' ', '\t', '\n');BasicLexer(String sourceCode) {this.sourceCode = sourceCode.toLowerCase().toCharArray();this.initKeyWords();}
}对比代码5-10可发现,新形式的词法分析器的变化还是比较大的,主要体现在如下几个方面:
- 使用了符号表words来存储Token信息。数据结构采用了Hast table,其中键部分为词素名称,值部分为Token对象。它的使用不仅可以提升词法分析的速度,还能够解决词法规则冲突问题。
- DSL代码被加工成了字符数组(char[])类型的对象,即字段sourceCode。这样的设计比较方便使用下标对数组中的内容进行索引。这一点非常重要,因为词法分析器是以字符为单位来读取DSL代码的,每读入一个就执行一次分析操作,这一点亦可由图 5.3或图 5.4推断出来。
- 增加了预读字符属性peek。该字符永远指向下一个要处理的字符(即当前Token词素后面的那个字符)或者空格。这句话似乎有点让人费解,让我们举一个简单的例子。假定词法分析程序的处理流程只包括两个环节:移除空白符和构建运算符Token。对于如下输入“ >< ”,第一次调用词法分析程序的时候会输出大于符号Token,同时peek的值为小于符号(>);第二次调用的时候会输出小于符号Token,peek的值为空格。可以看到,针对这两次调用,peek指向的都是下一个要处理的字符。值得注意的是,预读并不总是会发生,比如在处理等于(=)运算符的时候。因为单独的等于符号是一个完整的Token,所以我们会选择直接对其进行输出,并将peek的值设置为空格,此时并不会让其指向等于符号的下一个字符(即没有预读)。空格并不会带来任何问题,因为每一次进行词法分析的时候都会将其移除掉。由于预读操作只需要使用一个字符,所以我们将它声明为char类型。
- 增加了字符数组索引readerIndex属性,以用于记录词法分析器已经分析到了数组sourceCode中的哪个字符。由于没有考虑到回溯操作,所以只需要使用一个变量来记录数组下标信息即可。否则的话就需要两个变量,即“快慢指针”。这也是该版本的词法分析器与上一个版本的不同之处,即源代码字符串的内容不会发生改变。很显然,由于我们使用数组索引来获取DSL代码中的信息,所以只有索引值在不停地发生变化。而基于正则表达式的版本则正好相反,每解析一个Token都会修改源代码字符串的值。
- 符号表初始化操作。为解决词法规则冲突问题,需要在启动词法分析器之后进行一些初始化操作,比如将关键字、操作符的Token放入到符号表中,如代码5-18所示。由于符号表的结构为Hash table,所以放置Token的顺序并没有要求。
读者如果对上述内容感到不太理解的话,可继续往下阅读。随着内容的展开以及代码的展示,很多疑问自会迎刃而解。
代码5-18void initKeyWords() {words.put(TokenType.AND.name, new Token(TokenType.AND));words.put(TokenType.SET.name, new Token(TokenType.SET));words.put(TokenType.WHERE.name, new Token(TokenType.WHERE));words.put(TokenType.EQ.name, new Token(TokenType.EQ));words.put(TokenType.LESS_THAN.name, new Token(TokenType.LESS_THAN));words.put(TokenType.LE.name, new Token(TokenType.LE));words.put(TokenType.GREATER_THAN.name, new Token(TokenType.GREATER_THAN));words.put(TokenType.GE.name, new Token(TokenType.GE));words.put(TokenType.QUOTATION.name, new Token(TokenType.QUOTATION));words.put(TokenType.RATE.name, new Token(TokenType.RATE));words.put(TokenType.SEMICOLON.name, new Token(TokenType.SEMICOLON));
}在掌握词法分析器的基本结构后,接下来需学习其核心方法scanNext()。该方法实现词法分析逻辑,供语法分析器调用。由于采用手工硬编码方式实现Token类型识别,其复杂度显著高于基于正则表达式的实现方式。为清晰呈现该方法的逻辑架构,此处先展示其结构,如代码5-19所示:
代码5-19Token scanNext() {if (this.isEnd()) {return new Token(TokenType.EOF, TokenType.EOF.name, colIndex, lineIndex);}Token current;this.skipEmpty();current = this.readOperator();if (current.type != TokenType.UNKNOWN) {return current;}current = this.readNum();if (current.type != TokenType.UNKNOWN) {return current;}current = this.readString();if (current.type != TokenType.UNKNOWN) {return current;}current = this.readSemicolon();if (current.type != TokenType.UNKNOWN) {return current;}current = this.readField(); return current;
}上述代码虽然没有展示太多的细节,但仍有如下几点内容值得注意:
- 方法返回值为单一的Token对象而非列表,这一点可以与图 5.7所示流程匹配。
- 虽然当前的主题是基于状态机实现词法分析器,但笔者却并没有显示地定义出一个状态机对象,具体原因已经在前面内容中进行过说明。简单来说,针对简单的DSL,可以使用if、switch等结构来实现隐式的状态机。
- scanNext()的角色主要用于调度,并未包含具体的处理逻辑,是实现隐式状态机的关键。
对代码5-19进行详细解释之前,笔者需要对前文所提及的一些问题做一些相对深入的说明。
一、隐式状态机与显示状态机的选型策略
恰如其名所示,显示状态机会将状态转换逻辑通过代码清晰地表示出来。一般来说,可使用枚举来定义状态,使用switch语句来实现状态转换逻辑。很明显,这种类型的状态机不仅具有明确的状态定义,其对应的状态转换逻辑也是直接可见的。隐式状态机则不然,其状态转换逻辑往往隐含在代码的执行流程之中,通常使用一些小型的if、switch、while语句或函数递归调用来实现,状态定义一般都隐含在程序的执行位置。
代码5-20基于Java语言编写,当我们使用显示状态机对其进行词法分析的时候,其整体逻辑框架将呈代码5-21所示的形式。
代码5-20if (i >= 100) {num = 10;
}代码5-21class ExplicitStatusMachineBasedLexer {State currentState;enum State {START, ID, OPERATOR, NUMBER, GREATER_THAN, GE, ASSIGN}Token scan() {...switch (currentState) {case START:if (Character.isLetter(c)) { //处理标识符currentState = State.ID;...} else if (Character.isDigit(c)) { //处理数字currentState = State.NUMBER;...}...break;case ID: //处理标识符...break;case NUMBER: //处理数字...break; ... //其他状态的处理}return token;}
}通过案例分析可知,显式状态机的代码结构具备清晰性,状态转换逻辑便于理解与维护。该实现方式不仅能够便捷地跟踪状态变化,而且在新增状态及转换规则时具有较高的灵活性。其不足之处在于,当面对复杂状态机时,代码量可能会显著增加。隐式状态机虽然存在明显缺陷(如逻辑理解难度大、维护成本高),但对于简单逻辑场景,能够实现更简洁的代码表达。
因此,状态机实现策略的选择原则较为明确:除非存在特殊场景需求(如逻辑极其简单),否则应优先采用显式状态机。显式状态机在清晰度、可维护性和可扩展性方面的优势,远超过因代码量适度增加而带来的潜在弊端。
二、scanNext()方法的设计思想
在scanNext()方法中,尽管未显式定义状态机逻辑,但其功能至关重要。作为隐式状态机的实现基础,该方法通过调用skipEmpty()、readOperator()、readNum()、readString()、readSemicolon()、readField()等方法,实现对子状态机的调度与控制。换言之,上述一系列方法本质上是小型状态机,分别用于处理空白符、运算符、数字、字符串、分号及优惠条件名称(FIELD)的词法分析。
采用这一设计的核心目的,在于平衡隐式状态机的固有缺陷(尤其是扩展性不足的问题)。尽管当前仅需处理6类词法规则,但无法排除未来词法规则从6类扩展至60类的可能性。在此情形下,开发者可拥有更多设计选择:既可在原方法内部新增子方法,亦可通过“状态模式”对scanNext()方法进行重构,以面向对象的方式处理不同词法规则。无论选择何种方案,均优于直接在scanNext()方法中编写复杂处理逻辑的实现方式。
以下回归正题,对scanNext()方法中涉及的子方法逐一进行解释。首先介绍skipEmpty()方法,其核心功能为移除空白符,具体实现如代码5-22所示。显然,若采用正则表达式实现该功能,仅需一行代码即可完成;若通过手工编码实现,则需编写更多逻辑。
代码5-22void skipEmpty() {while (true) {if (this.isEnd()) {return;}if (this.peek == ' ') {move();continue;}if (this.peek == '\t') {this.colIndex += 3;move();continue;}if (this.peek == '\n') {this.lineIndex++;this.colIndex = 1;move();continue;}return;}
}skipEmpty()方法的核心逻辑是对代码中的空白符、换行符等进行跳过处理,处理过程中也同时会修改DSL脚本行号和列号等变量的信息,这些信息最终会被放到输出的Token对象中。此外,上述代码中还有一些辅助类方法的调用,比如move()、isEnd()等。这些方法主要用于移动数组指针或判断其是否已经到达数组的尾部(到达尾部意味着所有的代码都已经完成分析),具体逻辑如代码5-23所示:
代码5-23void move() {if (this.isEnd()) {this.resetPeek();return;}this.peek = this.sourceCode[readerIndex++];this.colIndex++;
}void resetPeek() {this.peek = ' ';
}boolean isEnd() {return this.readerIndex >= this.sourceCode.length;
}代码比较简单,让我们直接跳过解释环节,重点看一下词法分析器是如何处理运算符的,即方法skipOperator()的实现逻辑,如代码5-24所示:
代码5-24Token readOperator() {switch (this.peek) {case '>':if (this.readChar('=')) {resetPeek();return this.getExisted(TokenType.GE.name);} else {return this.getExisted(TokenType.GREATER_THAN.name);}case '<':if (this.readChar('=')) {resetPeek();return this.getExisted(TokenType.LE.name);} else {return this.getExisted(TokenType.LESS_THAN.name);}case '=':this.resetPeek();return this.getExisted(TokenType.EQ.name);}return Token.UNKNOWN;
}上述代码可实现对>、>=、<、<=、=等五种运算符的词法分析。对于单字符运算符(如>、<),处理逻辑较为直观;而对于双字符运算符(如>=、<=),则需采用“预读”机制。具体而言,当读取到>或<字符时,需预读下一个字符并判断是否为=,再根据检查结果返回对应Token。对于=运算符,若无需支持等于判断(==),则无需预读。运算符分析过程中调用的resetPeek()方法,可将预读字符peek重置为空格,实现输入字符的回退操作。
代码5-24中还调用了另外一个我们未曾展示过的方法readChar(),该方法用于判断预读字符是否和参数值相等,具体实现如代码5-25所示:
代码5-25boolean readChar(char c) {this.move();if (this.peek == c) {return true;}return false;
}可以看到,调用此方法后会修改预读字符peek的值,即move()方法的调用,使其指向它的下一个字符。逻辑比较简单,笔者不做过多解释。下一个要展示的方法是readNum(),该方法用于处理数字类型Token的词法规则,具体实现如代码5-26所示:
代码5-26Token readNum() {if (!Character.isDigit(peek)) {return Token.UNKNOWN;}int value = 0;do {value = 10 * value + Character.digit(this.peek, 10);this.move();} while (Character.isDigit(this.peek));if (this.peek == ' ' || this.peek != '.' ) {return new Token(TokenType.NUM, String.valueOf(value));}float result = value;float d = 10;while (true) {this.move();if (!Character.isDigit(this.peek)) {break;}result = result + Character.digit(peek, 10) / d;d = d * 10;}return new Token(TokenType.NUM, String.valueOf(result));
}readNum()方法能够实现对整数与浮点数的分析,不过实现逻辑似乎有点复杂。看起来还是使用正则表达式的方式更舒服一点,虽然有一定的学习成本,但至少不用写这么多的代码。
接下来我们再来看一下字符串的处理逻辑,即readString()方法。字符串必须以双引号(")做为前、后缀,而引号中的内容则没有任何限制。具体实现如代码5-27所示:
代码5-27Token readString() {if (this.peek == '"') {StringBuilder sb = new StringBuilder();while (true) {if (!this.readChar('"') && !this.isEnd()) {sb.append(this.peek);continue;}break;}if (this.peek == '"') {this.resetPeek();return new Token(TokenType.STRING, sb.toString());}}return Token.UNKNOWN;
}方法readSemicolon()用于处理分号,如代码5-28所示:
代码5-28Token readSemicolon() {if (this.peek == ';') {this.resetPeek();return this.getExisted(TokenType.SEMICOLON.name);}return Token.UNKNOWN;
}最后一个需要展示的方法是readField(),该方法用于识别优惠条件名称(FIELD)类型的Token,您所要重点关注的是它如何解决优惠条件名称和关键字词法规则之间的冲突,具体实现如代码5-29所示:
代码5-29Token readField() {if (!Character.isLetter(this.peek)) {return Token.UNKNOWN;}StringBuilder sb = new StringBuilder();do {sb.append(this.peek);this.move();} while (Character.isLetterOrDigit(peek) || legalCharacters.contains(peek));String value = sb.toString();Token token = this.getExisted(value);if (token.type != TokenType.UNKNOWN) { return token;}token = new Token(TokenType.FIELD, value, colIndex, lineIndex);words.put(value, token);return token;
}从上述代码可见,依据TokenType.FIELD的词法规则解析出词素后,会优先查询符号表中是否已存在该词素。若存在,则直接从符号表返回匹配对象;若不存在,则创建一个新的TokenType.FIELD类型对象并存入符号表。
关于词法分析器的输出在此不再赘述,其与基于正则表达式的词法分析器完全一致,区别仅在于前者每次仅输出单个Token对象,而后者输出Token对象列表。
至此,所有词法分析器相关代码已展示完毕。读者可对比两类词法分析器的实现方式:基于状态机的实现虽具备较高灵活性,但代码复杂度显著较高。因此在实际应用中,可考虑将两种方式结合——以数字类型Token的识别为例,借助简单正则表达式即可完成解析,无需编写大量状态机代码。此外,笔者强烈建议读者在本地实现这些代码以深化理解:尽管处理逻辑相对简单,但语言编译器作为一个全新领域具有其独特性,通过实践可切实增强对该学科的认知。
上一章 下一章