《射频识别(RFID)原理与应用》期末复习 RFID第四章 数据校验和防碰撞算法(知识点总结+习题巩固)
第四章 数据校验和防碰撞算法
知识点总结
一、差错控制技术
1. 差错类型与性质
| 差错类型 | 特征 | 成因 |
|---|---|---|
| 随机错误 | 错误位离散无关联 | 信道随机噪声(如热噪声) |
| 突发错误 | 错误位连续相关(如连续多位错误) | 脉冲干扰、信号衰减 |
| 混合错误 | 随机与突发错误并存 | 复杂信道环境 |
2. 差错控制方法
| 方法 | 原理 | 适用场景 |
|---|---|---|
| 前向纠错(FEC) | 发送纠错码,接收端自动纠错(如汉明码) | 单向传输,实时性要求高 |
| 检错重发(ARQ) | 发送检错码(如CRC),接收端请求重传错误数据 | 双向通信,可靠性优先 |
| 混合纠错(HEC) | FEC与ARQ结合:先尝试纠错,失败则重传 | 平衡效率与可靠性 |
3. 常用校验码
| 校验方式 | 算法描述 | RFID应用 |
|---|---|---|
| 奇偶校验 | 添加1位校验位,使"1"的个数为奇/偶(奇校验或偶校验) | 简单场景,成本敏感系统 |
| 纵向冗余(LRC) | 数据块按字节异或(XOR),结果作为校验字节 | ISO/IEC 15693标准 |
| 循环冗余(CRC) | 关键步骤: 1. 信息多项式 M ( x ) M(x) M(x) 左移 r r r 位 2. 模2除生成多项式 G ( x ) G(x) G(x) 3. 余数作为校验码 | ISO/IEC 14443(CRC-A/CRC-B) |
CRC计算示例:
题目描述:待发送的信息为1001,生成多项式为G(x)=1011,计算余数R(x),传递的信息T(x),展示循环冗余校验的过程。
生成多项式 G ( x ) = 1011 G(x)=1011 G(x)=1011,对应的阶为 r = 3 r=3 r=3 (总位数-1),
将原始待发送的信息 M ( x ) M(x) M(x)左移 r = 3 r=3 r=3 位,得到 M ( x ) ′ = 1001000 M(x)'=1001000 M(x)′=1001000(右侧补3个0),
用左移后的 M ( x ) ′ M(x)' M(x)′除以给定的生成多项式 G ( x ) G(x) G(x),
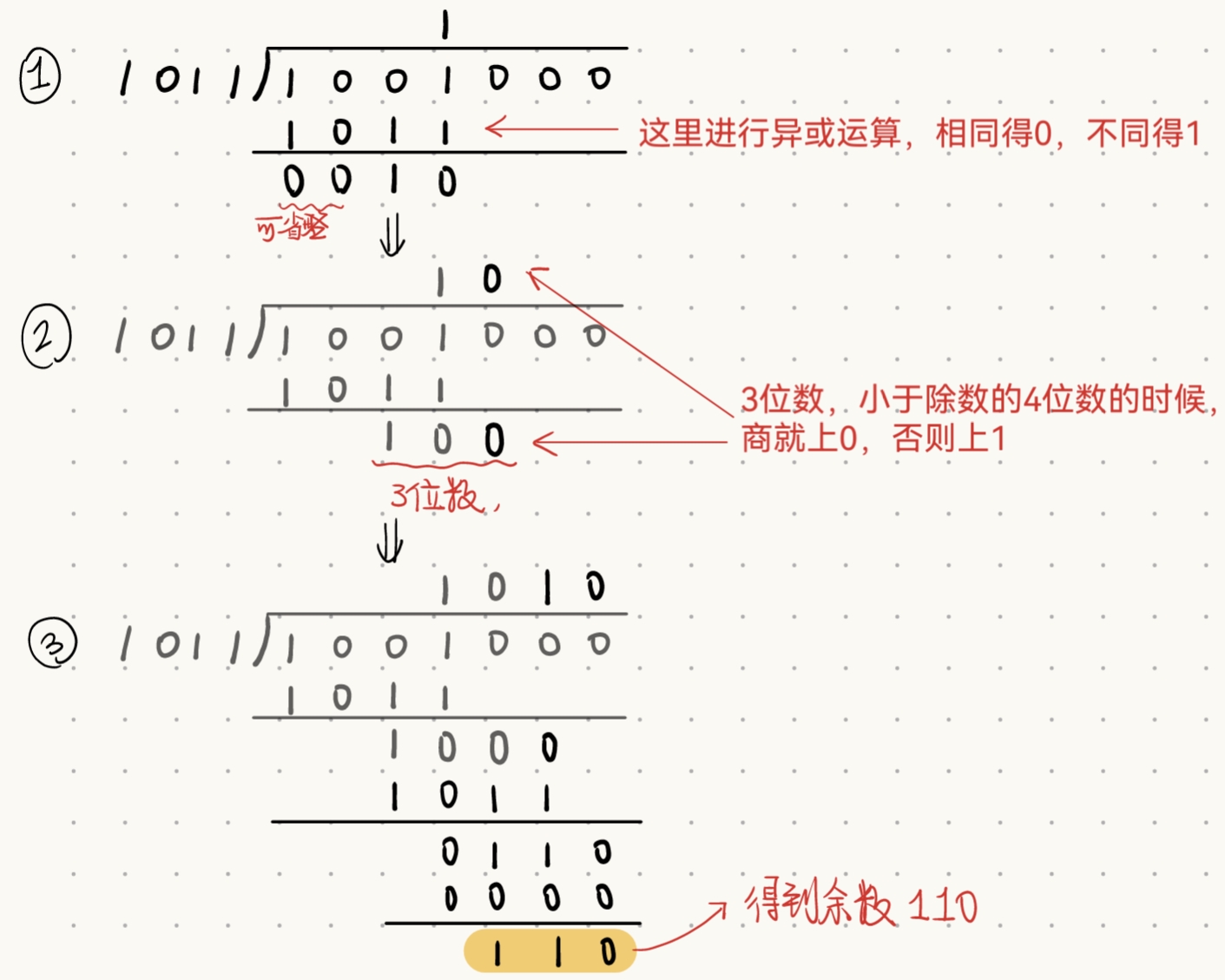
运算结果得到余数 R ( x ) = 110 R(x)=110 R(x)=110,
将待发送信息 M ( x ) M(x) M(x) 左移后的信息加上得到的余数 R ( x ) R(x) R(x),就得到应传送的信息
T ( x ) = 1001000 + 110 = 1001110 T(x)=1001000+110=1001110 T(x)=1001000+110=1001110,
发送码即为 1001110 1001110 1001110.
- ( M(x) = 1001 )(信息码:9)
- ( G(x) = 1011 )(生成多项式:( x^3 + x + 1 ))
- 余数 ( R(x) = 110 ) → 发送码:1001110
二、防碰撞算法原理
1. 碰撞类型与多路访问方法
| 碰撞类型 | 特征 | 解决方案 |
|---|---|---|
| 标签碰撞 | 多标签同时响应读写器 | TDMA(时分多址)主导方案 |
| 读写器碰撞 | 相邻读写器信号重叠干扰 | 空分多址(SDMA)或功率控制 |
| 多路访问方法 | 实现原理 | RFID适用性 |
|---|---|---|
| 空分多址(SDMA) | 定向天线控制波束指向特定标签 | 成本高,仅用于>850MHz |
| 频分多址(FDMA) | 不同标签使用不同载波频率 | 标签电路复杂,少用 |
| 码分多址(CDMA) | 标签用唯一扩频码区分 | 频带利用率低,难推广 |
| 时分多址(TDMA) | 主流方案:标签分时隙响应 | 所有频段通用 |
2. TDMA防碰撞算法分类
| 算法类型 | 代表算法 | 工作原理 | 优缺点 |
|---|---|---|---|
| 概率型算法 | ALOHA家族 | 标签随机选择时隙发送,冲突则随机退避重发 | 实现简单,存在"标签饥饿" |
| 确定型算法 | 树形搜索家族 | 递归分割冲突标签集,直至唯一标签响应 | 100%识别,通信开销大 |
三、核心算法详解
1. ALOHA家族算法
| 算法变体 | 关键机制 | 吞吐率 | 应用场景 |
|---|---|---|---|
| 纯ALOHA | 标签随时发送,冲突则随机退避 | 峰值18.4% (G=0.5) | 只读标签系统 |
| 时隙ALOHA(S-ALOHA) | 标签仅在时隙起点发送 | 峰值36.8% (G=1) | HF频段(如13.56MHz) |
| 动态时隙ALOHA | 读写器动态调整帧长(时隙数) | 可达40%+ | EPC Gen2标准 |
| Q值算法 | 时隙数= 2 Q 2^Q 2Q(Q动态调整) | 优化冲突/空闲平衡 | ISO/IEC 18000-6C |
Q值算法流程:
- 读写器发送
Query(Q)设置时隙数 N = 2 Q N = 2^Q N=2Q - 标签随机选择时隙 s ∈ [ 0 , N − 1 ] s \in [0, N-1] s∈[0,N−1]
- 时隙计数归零的标签响应
- 冲突则增大Q,空闲则减小Q
2. 二进制树形搜索算法
| 算法变体 | 分裂方式 | 碰撞检测方法 |
|---|---|---|
| 基于序列号 | 查询比特前缀 | 曼彻斯特码位冲突检测 |
| 基于随机数和时隙 | 递归遇到碰撞就分支 | 曼彻斯特编码 |
二进制树搜索流程:
- 读写器发送
REQUEST(前缀) - 匹配前缀的标签响应UID
- 若冲突,根据最高碰撞位修改前缀(追加0或1)
- 递归直至无冲突,用
SELECT选中标签
四、标准协议实现
1. ISO/IEC 14443 防碰撞协议
| 类型 | 防碰撞机制 | 命令集 | 特点 |
|---|---|---|---|
| TYPE A | 位检测防碰撞 | REQA→ATQA→ANTICOLLISION→SELECT→SAK | 基于曼彻斯特码碰撞位检测 |
| TYPE B | 时隙ALOHA | REQB→ATQB→SLOT-MARKER→ATTRIB | 时隙数动态调整,兼容性好 |
TYPE A防碰撞流程:
- 标签状态:Power-off → Idle → Ready → Active → Halt
- 冲突处理:逐级匹配UID CLn(CL1→CL2→CL3),按碰撞位分裂
TYPE A防碰撞流程:
- 冲突处理:时隙响应(读卡器调整时隙数,降低碰撞概率)
ISO/IEC 14443 防碰撞协议 Type A Type B(点击链接跳转博客详解)
2. EPC Gen2 Q算法
- 时隙管理:
- Q ∈ [ 0 , 15 ] Q \in [0,15] Q∈[0,15],时隙数 N = 2 Q N=2^Q N=2Q
- 冲突时: Q ← Q + c Q \leftarrow Q + c Q←Q+c( c ≈ 0.5 c \approx 0.5 c≈0.5)
- 空闲时: Q ← max ( 0 , Q − 1 ) Q \leftarrow \max(0, Q-1) Q←max(0,Q−1)
五、设计实例
1. MCRF250芯片
- 工作频率(载波)位125kHz
- 工作模式:Native模式(直接响应) vs 读模式(防碰撞流程)
- 编码方式:NRZ码 曼彻斯特码 差分曼彻斯特码
- 调制方式:FSK PSK 直接调制
- 防碰撞电路:基于时隙ALOHA,支持动态帧长调整
习题巩固
以下是根据PPT《RFID数据校验和防碰撞算法》第四章内容设计的20道习题,涵盖差错控制、防碰撞算法及标准协议,附带答案与解析:
一、选择题
-
CRC校验中,生成多项式 G ( x ) = x 3 + x + 1 G(x) = x^3 + x + 1 G(x)=x3+x+1 对应的二进制序列是?
A. 1011
B. 1101
C. 1110
D. 1001
答案:A
解析:最高次项系数为1, x 3 x^3 x3 →1, x 2 x^2 x2→0, x x x→1, 常数→1,故为1011。 -
时隙ALOHA算法的峰值吞吐率约为?
A. 18.4%
B. 36.8%
C. 50%
D. 75%
答案:B
解析:时隙ALOHA最大吞吐率 S max = 1 / e ≈ 0.368 S_{\max} = 1/e \approx 0.368 Smax=1/e≈0.368。 -
ISO/IEC 14443 TYPE A防碰撞协议的关键机制是?
A. 时隙ALOHA
B. 位检测碰撞
C. CDMA扩频
D. 随机退避
答案:B
解析:TYPE A通过曼彻斯特码检测碰撞位,逐级匹配UID。 -
EPC Gen2标准采用的防碰撞算法是?
A. 纯ALOHA
B. 二进制树搜索
C. Q值算法
D. 查询树算法
答案:C
解析:Q值算法动态调整时隙数 N = 2 Q N = 2^Q N=2Q,用于UHF标签。 -
下列校验方式中,按字节异或运算的是?
A. 奇偶校验
B. CRC校验
C. LRC校验
D. 汉明码
答案:C
解析:LRC(纵向冗余校验)对数据块所有字节异或生成校验码。
二、填空题
- 纯ALOHA算法的峰值吞吐率是 18.4%(当G=0.5时)。
- 二进制树搜索算法中,检测碰撞需使用 曼彻斯特 编码。
- ISO/IEC 14443 TYPE B的防碰撞机制基于 时隙ALOHA。
- CRC校验中,接收端判定无错误的依据是余数为 0。
- 动态时隙ALOHA通过调整 帧长(时隙数) 优化性能。
- 标签碰撞是指 多个标签同时响应同一读写器。
三、判断题
- FEC(前向纠错)需要反向信道支持重传。(×)
解析:FEC接收端自主纠错,无需重传,ARQ才需反向信道。 - 树形搜索算法100%识别标签,但通信开销大。(√)
解析:需递归分割冲突集,交互次数多。 - TYPE A防碰撞流程中,SELECT命令用于激活标签。(√)
解析:SELECT匹配UID后标签进入Active状态。 - Q值算法中,冲突时应减小Q值以减少时隙数。(×)
解析:冲突需增大Q值(增加时隙数),空闲时减小Q值。 - 突发错误由随机噪声引起,错误位离散。(×)
解析:突发错误位连续相关,随机错误位离散。
四、简答题
-
简述CRC校验发送端计算步骤。
答案:- 信息码左移r位(r=生成多项式阶数)
- 用生成多项式G(x)做模2除法
- 余数作为校验码附加到信息码后
-
对比纯ALOHA与时隙ALOHA的优缺点。
答案:算法 优点 缺点 纯ALOHA 无需时隙同步,实现简单 吞吐率低(18.4%),碰撞概率高 时隙ALOHA 吞吐率翻倍(36.8%) 需时隙同步,成本高 -
二进制树搜索中为何用曼彻斯特码?
答案:
曼彻斯特码位中间跳变可定位碰撞位(如跳变缺失表示该位冲突),便于读写器修改搜索前缀。 -
Q值算法的Q=3时,可用时隙数是多少?冲突后Q如何调整?
答案:- 时隙数 N = 2 3 = 8 N = 2^3 = 8 N=23=8
- 冲突时: Q ← Q + c Q \leftarrow Q + c Q←Q+c(典型值c=0.5,即Q=3.5→取整为4)
五、综合题(每题10分,共2题)
-
CRC计算题
已知信息码 M = 1100 M = 1100 M=1100,生成多项式 G = 1011 G = 1011 G=1011( x 3 + x + 1 x^3 + x + 1 x3+x+1),求发送码。
解:- 步骤1:( M ) 左移3位 → 1100000
- 步骤2:模2除法:
1100000 ÷ 1011 1011 → 商1 ----- 1110 1011 → 商1 ----- 1010 1011 → 商1 ----- 0010 → 余数010 - 发送码:信息码 + 余数 = 1100010
-
防碰撞流程分析
标签UID:Tag1=1010, Tag2=1100, Tag3=1011。
基于序列号的二进制树搜索法:
列出读写器请求序列。
答案:
| 编号 | Request命令 | 响应标签 | 读写器接收数据 | 成功识别 |
|---|---|---|---|---|
| 1 | 1111 | Tag1, Tag2, Tag3 | 1xxx | 无 |
| 2 | 1011 | Tag1, Tag3 | 101x | 无 |
| 3 | 1010 | Tag1 | 1010 | Tag1 |
| 4 | 1111 | Tag2, Tag3 | 1xxx | 无 |
| 5 | 1011 | Tag3 | 1011 | Tag3 |
| 6 | 1111 | Tag2 | 1100 | Tag2 |
请求序列:Tag1, Tag3, Tag2