大模型的开发应用(九):模型的客观评估
模型的客观评估
- 1 大模型的常用客观评估指标
- 1.1 准确率 (Accuracy)
- 1.2 困惑度 (Perplexity, PPL)
- 1.3 生成质量 (GEN)
- 1.4 ROUGE-LCS (ROUGE-L)
- 2 通用模型的评估指标的维度及其数据集
- 2.1 知识类(Knowledge)
- 2.2 推理类(Reasoning)
- 2.3 语言类(Language)
- 2.4 代码类(Coding)
- 2.5 多模态类(Multimodal)
- 2.6 为什么这五大维度至关重要?
- 2.7 生成式评估数据集与困惑度评估数据集
- 3 OpenCompass 的使用
- 3.1 OpenCompass 安装
- 3.2 下载数据集
- 3.3 评估 HF 模型
- 3.3.1 查看支持的模型与数据集
- 3.3.2 通过纯命令行评估
- 3.3.3 通过配置文件+命令行评估
- 3.4 使用推理框架进行加速
- 3.5 不同推理引擎的精度差别
- 3.6 评估对模型选型的作用
- 3.7 模型微调后的评估
- 4 实战:用 Ceval 数据集评估Llama3-8b
- 4.1 Ceval 数据集简介
- 4.1.1 Ceval 数据集的诞生背景
- 4.1.2 关键特点
- 4.1.3 应用场景
- 4.1.4 重要性与影响力
- 4.1.5 总结
- 4.2 在OpenCompass中用 Ceval 评估模型
1 大模型的常用客观评估指标
1.1 准确率 (Accuracy)
- 概念: 模型在选择题或分类任务中回答正确的比例。
- 计算例子:
- 假设我们有一个包含 5道 4选1的题目(A, B, C, D)的测试集,模型需要从4个选项中选出正确答案。
- 模型回答的结果是:
第1题: A(正确答案A),第2题: B(正确答案C),第3题: A(正确答案A),第4题: D(正确答案D),第5题: C(正确答案C)。 - 统计结果:
- 总题目数: 5
- 答对题目数: 第1题、第3题、第4题、第5题答对了。共 4题。
- 答错题目数: 第2题答错了(模型选B,正确答案是C)。共 1题。
- 准确率计算:
准确率 (Accuracy) = (答对题目数 / 总题目数) * 100% = (4 / 5) * 100% = 80%
- OpenCompass配置: 在评测任务的配置文件里设置
metric = accuracy。
1.2 困惑度 (Perplexity, PPL)
- 概念: 衡量模型对一组序列(通常是正确选项文本)的预测能力,概率预测越好,PPL越低。
- 计算逻辑(简化,非完整公式): 它基于模型预测序列中下一个词的概率。
- 假设正确选项的文本序列是
W = (w1, w2, w3, ..., wN)。 - 模型会根据之前的词预测下一个词的概率:
P(w2 | w1),P(w3 | w1, w2), …,P(wN | w1, w2, ..., wN-1)。 - PPL的核心是计算序列W的概率
P(W) = P(w1) * P(w2|w1) * P(w3|w1,w2) * ... * P(wN|w1,...,wN-1)。 - PPL定义(简化):
PPL(W) = P(W) ^ (-1/N)(N是序列长度)。更精确的公式涉及对数概率的几何平均和指数运算。 - 核心:概率P(W)越高,PPL越低。模型认为正确选项很“合理、熟悉”,预测出的P(W)高,对应的PPL值就低。模型认为正确选项很“意外、不合理”,预测出的P(W)低,PPL值就高。
- 假设正确选项的文本序列是
- 评估方式,给模型输入一段文字,然后统计每个token的位置能成功预测下一个单词的概率。比如:“团结就是力量。”,输入到大模型前,会整理成“
<S>团结就是力量”,经过大模型隐藏层推理后,在“<S>”的位置上会输出各个token的概率,从这里找到“团”的概率(P(w1)),同样的,在“团”的输入位置,会得到下一个词的概率,从这里可以获得“结”字的概率(P(w2|w1)),以此类推,可以得到P(wN | w1, w2, ..., wN-1),进而得到最后的 PPL。 - OpenCompass配置: 需要使用专门设计用于计算PPL的数据集类型,例如
ceval_ppl。OpenCompass会自动计算每个选项的PPL并进行选择。
1.3 生成质量 (GEN)
- 概念: 模型自由生成文本形式的答案,然后通过后处理脚本解析出答案进行判断。
严格意义上说,它并不是用于评估模型的指标,而是一种评估模式,它要让模型生成一段话,然后用后处理程序从这段话中提取答案,具体指标可以用召回率、准确率等,看需求。比如,让模型回答高考文科的问答题,那么就可以用召回率,我们预先给问题设置了5个关键点,结果模型回答到了3个,那召回率就是0.6;再比如,对于高考数学大题,如果让模型作答,模型会生成解题过程,但我们计算最后得分的时候,一般是用最后的解题结果算准确率,就是看它做对了多少道题,至于中间解题步骤,则不考虑(实际改卷的时候会考虑,但这里评估的时候,无法通过编程实现,因此只能忽略中间过程)。 - 计算过程例子(用关键点召回率):
- 题目:
“请解释万有引力定律。” - 模型生成:
“万有引力定律是由牛顿提出的,它指出宇宙间任意两个物体都相互吸引,引力的大小与两物体质量的乘积成正比,与它们距离的平方成反比。公式表示为:F = G * (m1 * m2) / r²,其中F是引力,G是万有引力常数,m1和m2是两个物体的质量,r是它们之间的距离。” - 标准答案(预期关键点):
牛顿提出,任意物体相互吸引,F与质量积正比,F与距离平方反比,公式F=G*m1*m2/r²。 - 后处理脚本的任务:
- 规则/匹配: 脚本需要设计规则或模式来提取关键点。例如:
- 检查是否提到“牛顿”。
- 检查是否提到“相互吸引”。
- 检查是否提到“质量乘积正比”。
- 检查是否提到“距离平方反比”。
- 检查是否包含公式
F = G * (m1 * m2) / r²或等效表述。
- 评分/判断: 后处理脚本根据匹配到的关键点进行评分。方式可以多样:
- 二值判断: 如果匹配到了所有核心关键点(如上述5点),则认为答案正确(1分),否则错误(0分)。
- 部分匹配: 得分为匹配到的关键点数量(例如匹配到3个关键点,得3/5分)。
- 模糊匹配/相似度: 利用简单的字符串包含检查或更复杂的语义相似度判断。
- 规则/匹配: 脚本需要设计规则或模式来提取关键点。例如:
- 判定结果: 假设后处理脚本识别到生成文本包含了所有5个关键点。最终得分:判为正确(或得满分)。
- 题目:
- OpenCompass配置:
- 使用
gen类型的数据集(如ceval_gen)。 - 在任务配置中设置
metric = gen。 - 最关键: 编写或指定一个后处理脚本(
inferencer.infer_cfg['postprocessor']['type'] = ...),定义如何从模型生成的一大段文本 (response) 中解析(pred_answer)出需要评分的最终答案。 - 解析出的答案 (
pred_answer) 会和标准答案 (references) 比较,通常是按规则匹配或字符串严格/模糊匹配来确定是否正确。
- 使用
1.4 ROUGE-LCS (ROUGE-L)
- 在介绍ROUGE-LCS 之前,可以先了解一下 ROUGE-N ,看这篇文章就够了。
- 概念: 通过计算生成文本与参考文本之间的最长公共子序列 (Longest Common Subsequence, LCS) 来衡量相似度(召回率、精确率、F1值),重点评估句子层级的流畅度和覆盖关键信息的能力。这里的最长公共子序列(序列中的词,在原句子中可以不连续),并不是最长公共子串(字串必须连续出现,不能跳词),公共子序列虽然可以跳词,但词与词之间的顺序是固定的。
- 计算例子:
- 任务: 文本摘要(假设要求只用一句话回答)。
- 参考摘要 (标准答案):
“牛顿的万有引力定律描述了质量间相互吸引的力,力大小与质量积成正比,与距离平方成反比。” - 模型生成摘要:
“万有引力定律由牛顿提出,它说明质量引起物体相互吸引,力按距离平方减少。” - ROUGE-L 计算逻辑:
- 找出最长公共子序列 (LCS):
- 参考句子:
牛顿的万有引力定律描述了质量间相互吸引的力,力大小与质量积成正比,与距离平方成反比。 - 生成句子:
万有引力定律由牛顿提出,它说明质量引起物体相互吸引,力按距离平方减少。 - LCS:
万有引力定律 牛顿 质量 相互吸引 力 距离平方(或等效表述的连续/非连续序列)。
- 参考句子:
- 计算 LCS-Unigram 统计量:
R_lcs(召回率):LCS长度 / 参考摘要长度(词数)。- LCS长度 (词数): 假设匹配到核心6个词:
万有引力定律、牛顿、质量、相互吸引、力、距离平方。长度=6。 - 参考摘要长度 (词数):
"牛顿的万有引力定律描述了质量间相互吸引的力,力大小与质量积成正比,与距离平方成反比。"-> 假设分词后共14个词。 R_lcs = 6 / 14 ≈ 0.4286
- LCS长度 (词数): 假设匹配到核心6个词:
P_lcs(精确率):LCS长度 / 生成摘要长度(词数)。- 生成摘要长度 (词数):
"万有引力定律由牛顿提出,它说明质量引起物体相互吸引,力按距离平方减少。"-> 假设分词后共13个词。 P_lcs = 6 / 13 ≈ 0.4615
- 生成摘要长度 (词数):
F_lcs(F1值):(2 * P_lcs * R_lcs) / (P_lcs + R_lcs)F_lcs = (2 * 0.4286 * 0.4615) / (0.4286 + 0.4615) ≈ (2 * 0.1979) / 0.8901 ≈ 0.3958 / 0.8901 ≈ 0.4447
- 找出最长公共子序列 (LCS):
- 评估结果:
ROUGE-L F1 ≈ 0.4447 (或44.47%)。F1值是召回率和精确率的调和平均,是主要的评估指标。这个值表示模型生成的摘要在包含参考摘要中最长关键信息序列方面,综合表现得分。
- OpenCompass配置:
- 安装依赖:
pip install rouge==1.0.1 - 在数据集配置中设置
metric = rouge。这通常会默认计算包括ROUGE-L在内的多个ROUGE变体。
- 安装依赖:
2 通用模型的评估指标的维度及其数据集
目前市面上最流行的大模型评估框架是 OpenCompass,它将大模型的核心能力划分为以下五大维度,并针对每个维度集成了业界代表性的开源数据集。
2.1 知识类(Knowledge)
核心目标:评估模型对结构化知识的掌握程度,涵盖科学常识、文化、历史等领域。
特点:
- 题型多为选择题或问答形式,需模型从知识库中精准提取信息。
- 强调覆盖多语言、跨学科的知识广度与深度。
代表数据集: - C-Eval(中文考试题):涵盖从中学到专业考试的中文题目,检验中国语境下的知识能力。
- CMMLU(多语言知识问答):测试多语言(含中文)的知识理解和推理能力。
- MMLU(英文多选题):覆盖57个英文科目(如数学、法律、医学),综合性强。
2.2 推理类(Reasoning)
核心目标:衡量模型解决复杂问题的能力,包括逻辑、数学、因果推断等。
特点:
- 任务需多步推导,强调思维链的完整性。
- 对模型的计算能力和符号理解要求高。
代表数据集: - GSM8K(数学推理):针对小学数学应用题,需分步骤求解。
- BBH(复杂推理链):挑战模型对长逻辑链问题的处理能力(如反事实推理)。
2.3 语言类(Language)
核心目标:评估模型的语言理解与生成能力,如语义分析、文本匹配、情感识别等。
特点:
- 聚焦语言本身的精准性、上下文关联性及任务适配能力。
- 中文场景需适配本地化需求(如成语、文化背景)。
代表数据集: - CLUE(中文理解):中文版GLUE,覆盖文本分类、阅读理解等任务。
- AFQMC(语义相似度):判断中文句子对的语义是否等价。
2.4 代码类(Coding)
核心目标:测试模型的编程能力,包括代码生成、补全、调试等。
特点:
- 需理解自然语言描述并转化为可执行代码。
- 强调算法设计、语法正确性和边界处理。
代表数据集: - HumanEval(代码生成):通过函数描述生成代码片段,Python专属评测标杆。
- MBPP(编程问题):提供简单英文需求描述,要求生成可直接运行的代码。
2.5 多模态类(Multimodal)
核心目标:评估模型对图文、音视频等多源信息的融合理解能力。
特点:
- 需同时处理不同模态的输入并联合推理。
- 推动模型突破纯文本局限,迈向通用人工智能。
代表数据集: - MMBench(图像理解):要求基于图像回答复杂问题(如图像描述、视觉推理)。
- SEED-Bench(多模态问答):融合图像、文本、视频的多模态问答测试集。
2.6 为什么这五大维度至关重要?
- 全面性:覆盖模型从基础语言到高阶能力的核心应用场景。
- 针对性:每类数据集聚焦特定能力短板(如C-Eval检验中文知识,HumanEval验证编程)。
- 标准化:开源数据集提供可复现的评估基准,推动模型公平对比(如MMLU全球广泛引用)。
- 前瞻性:多模态类直接关联下一代大模型的演进方向。
💡 补充说明:OpenCompass通过整合70+数据集,支持开发者一键式评测模型在五大维度的表现,其架构设计(见附图)直观体现了评估体系的结构化与专业性。实际应用中,模型需在所有维度均衡发展才能称为“全能型AI”。
2.7 生成式评估数据集与困惑度评估数据集
如果数据集的名称中包含 _gen,则表示用于评估生成质量,若包含 _ppl,则用于评估困惑度。
其中,对于评估生成质量的数据集,opencompass 都有配套的后处理代码,用于从生成的文本中提取答案,具体所用的评估指标,根据后处理代码决定。比如 demo_math 数据集,评估的时候,模型需生成完整解题步骤和最终答案,但最后计算准确率时,用的是最后答案的正确题目数,除以总的题目数。
下面是 demo_math 中第一条样本的输出结果:
{"0": {"origin_prompt": [{"role": "HUMAN","prompt": "If the pattern shown continues, what is the letter in the $2010$th position? MATHLETEMATHLETEMATHLETE...\nPlease reason step by step, and put your final answer within \\boxed{}.\n"}],"prediction": "To determine the letter in the 2010th position of the sequence \"MATHLETEMATHLETEMATHLETE...\", we need to recognize that this sequence repeats every 8 letters. Let's break it down step by step:\n\n1. **Identify the repeating pattern**: The given sequence is \"MATHLETEMATHLETEMATHLETE...\". We can see that the sequence repeats every 8 letters: MATHLETE.\n\n2. **Determine the position within one cycle**: To find out which letter corresponds to the 2010th position, we first need to find the remainder when 2010 is divided by 8. This will tell us where the 2010th position falls within the repeating cycle.\n\n \\[\n 2010 \\div 8 = 251 \\text{ remainder } 2\n \\]\n\n This means that 2010 is equivalent to 2 positions into the repeating cycle \"MATHLETE\".\n\n3. **Locate the letter in the cycle**: In the sequence \"MATHLETE\", the second position is \"A\".\n\nTherefore, the letter in the 2010th position is \\(\\boxed{A}\\).","gold": "A"},...
}
配套的后处理代码,会从 prediction 提取出 A 作为 gold,然后计算做对了多少道题,最后得到准确率。
既然只需要最后的答案就行了,那么为什么还要输出一大堆,完全可以涉及提示词模板让模型生成最后的答案就行了?其实对于生成式评估数据集而言,生成解题步骤可以避免“蒙答案”导致评估失真,支撑复杂题型的可解释性评估,并且方便判断与人工标准解题步骤是否对齐。在某种程度上说,生成解题步骤的实际意义超出评估本身,或者说,统计准确率,只是评估的“一方面”,而不是评估的全部。
3 OpenCompass 的使用
3.1 OpenCompass 安装
新建一个名为 opencompass 的环境,这里 python 版本必须为 3.10,并且需要用源码安装。
conda create -n opencompass python=3.10 -y
conda activate opencompass
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .如果连不上 github,可以把源码下载下来,然后上传到服务器解压。
3.2 下载数据集
接下来是下载数据集,大多数情况下,只需要下载核心数据集就够了:
# 下载数据集到 data/ 处
wget https://github.com/open-compass/opencompass/releases/download/0.1.8.rc1/OpenCompassData-core-20231110.zip
unzip OpenCompassData-core-20231110.zip如果想下载完整数据集 (~500M),则用下面的命令:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
unzip OpenCompassData-complete-20240207.zip
上述两个 zip 文件包含的数据集列表,如链接所示。
数据集下载好了之后,会在 opencompass 目录下看到一个名为 data 的目录,里面是我们下载的数据集:
我们以 ceval 为例,里面有中文各个学科的试题:
3.3 评估 HF 模型
3.3.1 查看支持的模型与数据集
可以通过下面的命令,查看所有支持的模型中,名字带“llama”模型,以及查看所有支持的数据集中,名字带“mmlu”的数据集:
python tools/list_configs.py llama mmlu
下面的左边栏是模型名称或者数据集名称,右边是对应的配置文件的路径:
+-----------------+-----------------------------------+
| Model | Config Path |
|-----------------+-----------------------------------|
| hf_llama2_13b | configs/models/hf_llama2_13b.py |
| hf_llama2_70b | configs/models/hf_llama2_70b.py |
| ... | ... |
+-----------------+-----------------------------------+
+-------------------+---------------------------------------------------+
| Dataset | Config Path |
|-------------------+---------------------------------------------------|
| cmmlu_gen | configs/datasets/cmmlu/cmmlu_gen.py |
| cmmlu_gen_ffe7c0 | configs/datasets/cmmlu/cmmlu_gen_ffe7c0.py |
| ... | ... |
+-------------------+---------------------------------------------------+
通过这个命令列出的模型,可以通过配置文件进行评估,也可以通过命令行的方式评估;如果不在列表中的模型,但有同系列的模型在列表中,也可以通过配置文件;如果没有同系列的模型,那么只能通过命令行评估。
3.3.2 通过纯命令行评估
使用命令行评估自定义的 hugging face 模型,下面的命令必须要在 opencompass 目录下面,因为 run.py 就在这个目录下面:
python run.py \--datasets demo_gsm8k_chat_gen demo_math_chat_gen \ # 当前评估所需要用到的数据集--hf-type chat \--hf-path /data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct \ # 模型路径--debug # 输出评估过程中的日志
通过这种方式,OpenCompass 一次只评估一个模型,而其他方式可以一次评估多个模型。
评估结果如下:
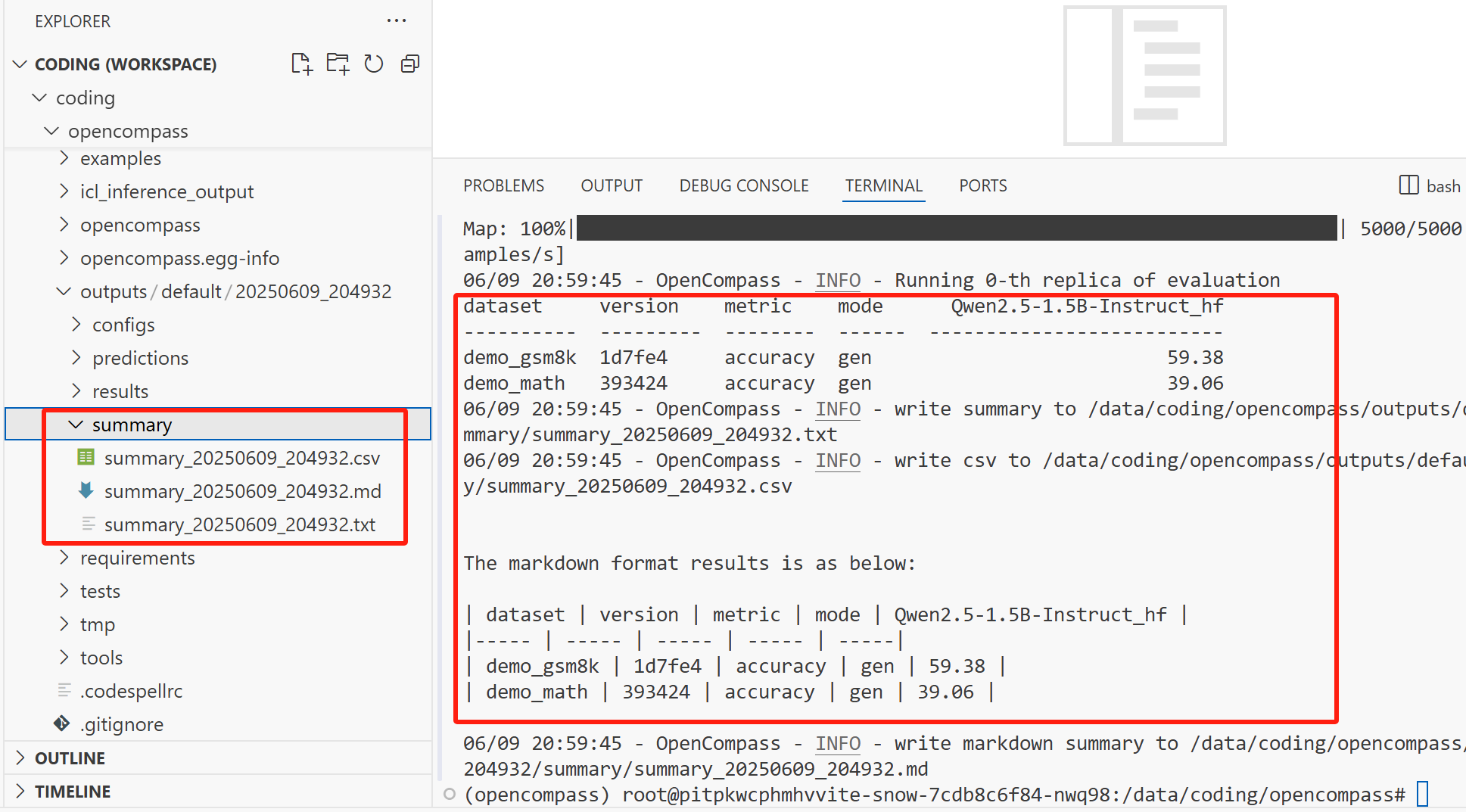
满分是100,也就是说,输出的指标是百分数。
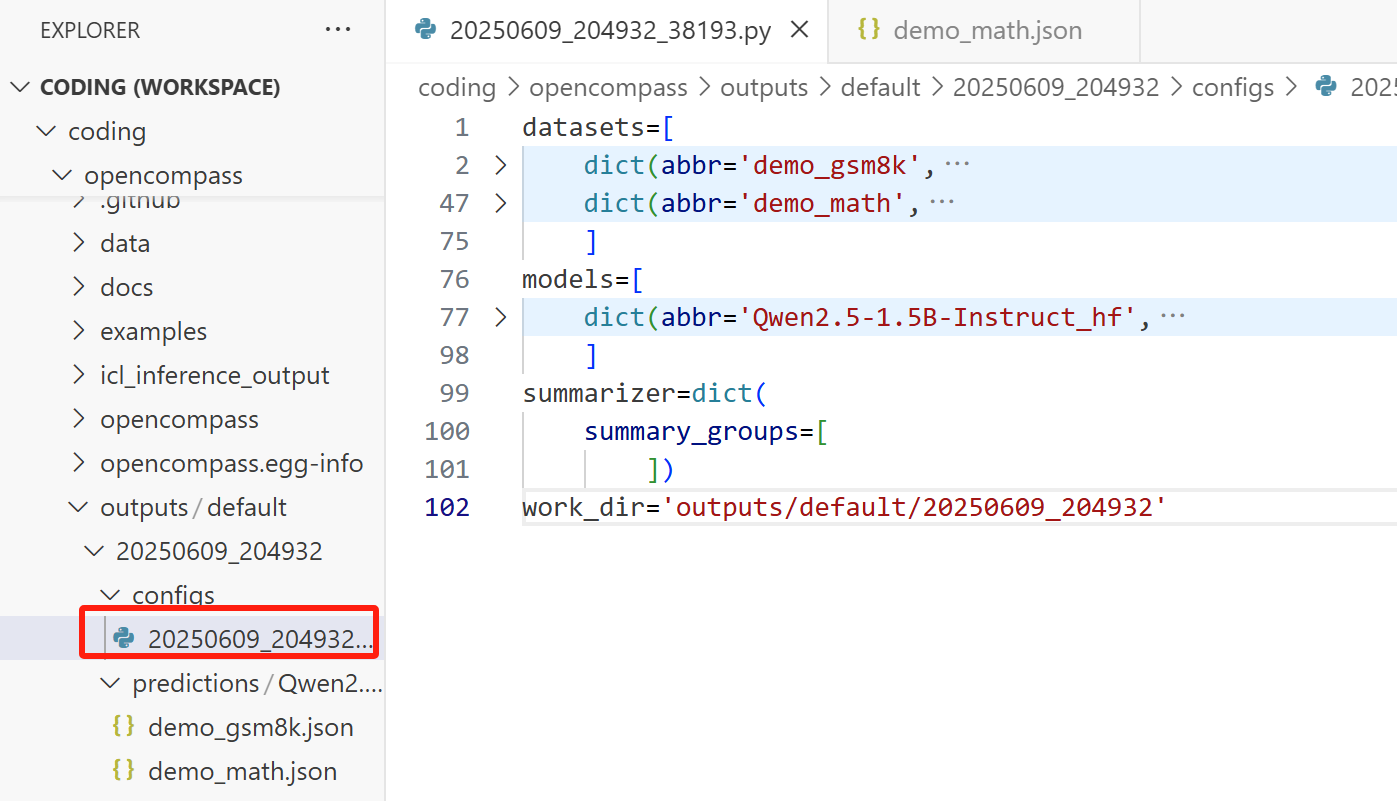
opencompass/outputs/default/20250609_204932/configs下,还能直接看到我们用的数据集和模型
opencompass/outputs/default/20250609_204932/predictions/Qwen2.5-1.5B-Instruct_hf下,还能直接看到每个数据集每条样本的输出:
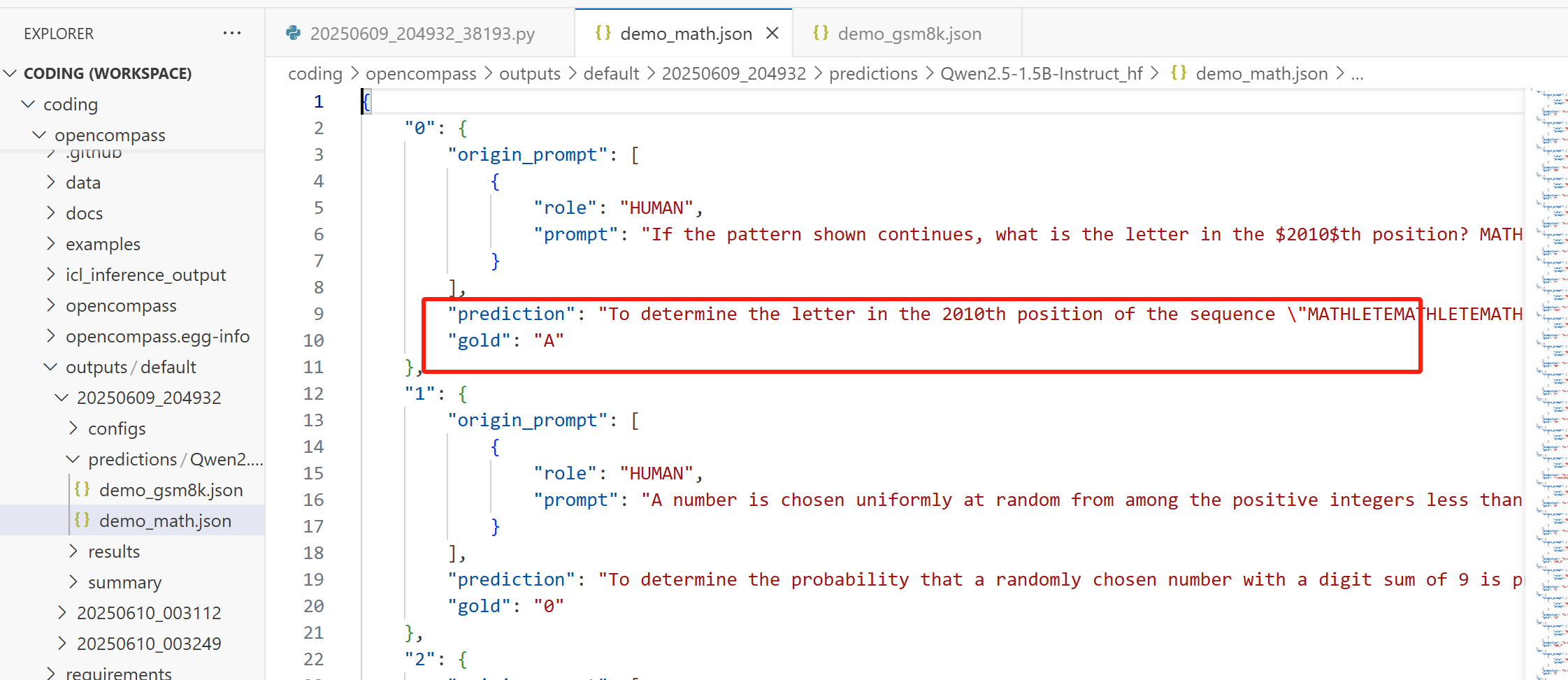
prediction 是模型输出,gold 是需要拿出去计算准确率的最后答案。
3.3.3 通过配置文件+命令行评估
用户可以使用 --models 和 --datasets 结合想测试的模型和数据集,可以一次性评估多个模型,命令如下:
python run.py \--models hf_internlm2_chat_1_8b hf_qwen2_5_1_5b_instruct \ --datasets demo_gsm8k_chat_gen demo_math_chat_gen \--debug
其中,hf_internlm2_chat_1_8b 和 hf_qwen2_5_1_5b_instruct 是模型的配置文件名。比如 hf_qwen2_5_1_5b_instruct 的存放位置及其内容,如下图所示:
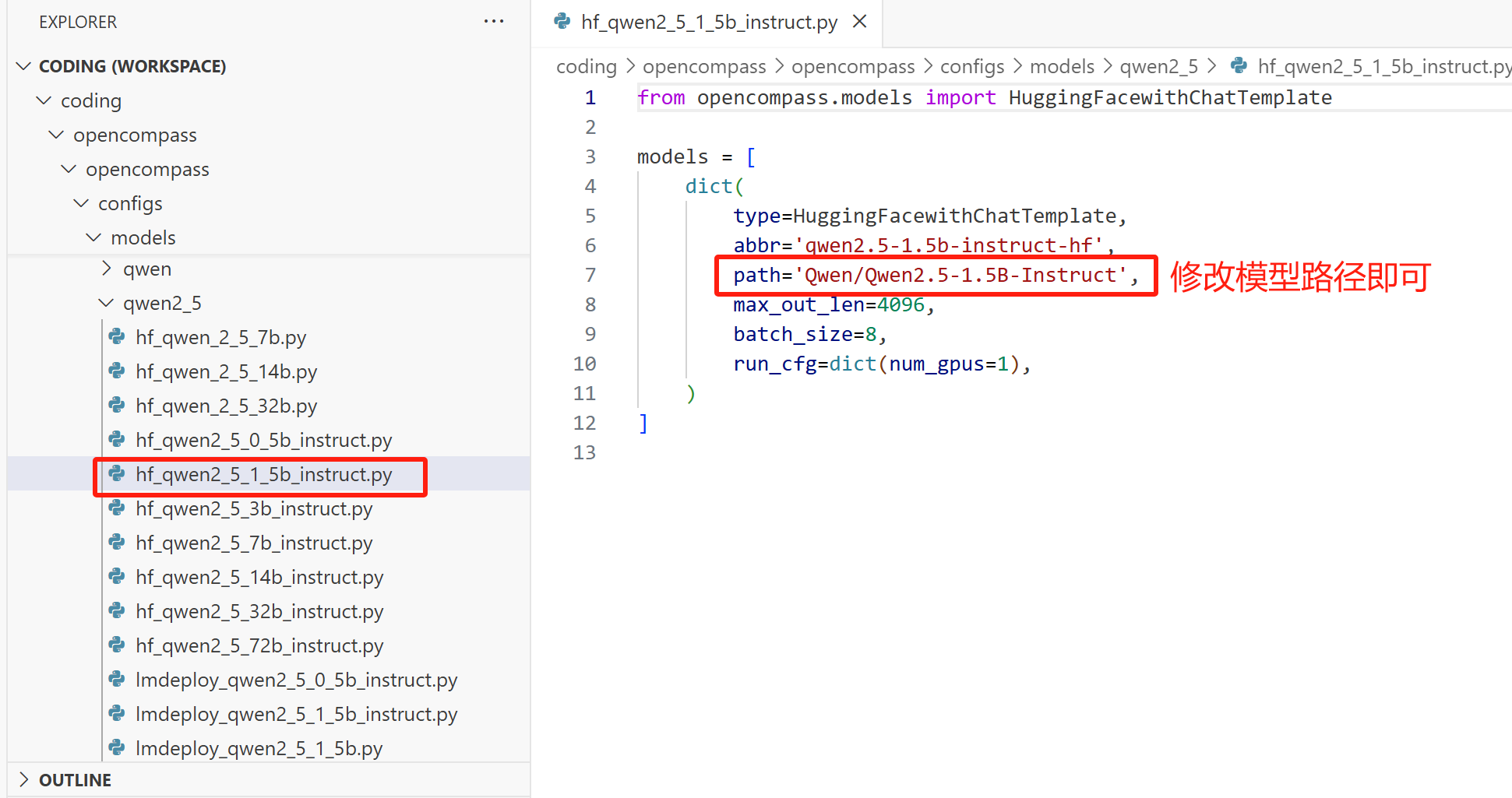
模型路径一定要改,并且模型一定要是 Qwen2.5-1.5B-Instruct 或者其微调版本(即模型要和配置文件适配),其他像 batch-size,max_out_len 等,看需求。这里不需要考虑分布式的问题,如果模型太大,一张卡放不下,那么框架会自动把模型拆分到多张卡上,无需认为设置,即不需要修改 num_gpus,这条仍然为 run_cfg=dict(num_gpus=1),我做了实验,证明依然如此。
修改后的 hf_qwen2_5_1_5b_instruct 配置信息如下:
from opencompass.models import HuggingFacewithChatTemplatemodels = [dict(type=HuggingFacewithChatTemplate,abbr='qwen2.5-1.5b-instruct-hf',# path='Qwen/Qwen2.5-1.5B-Instruct',path='/data/coding/model_weights/Qwen/Qwen2.5-1.5B-Instruct',max_out_len=4096,batch_size=8,run_cfg=dict(num_gpus=1),)
]
命令如下:
python run.py --models hf_qwen2_5_1_5b_instruct --datasets demo_gsm8k_chat_gen demo_math_chat_gen --debug
控制台输出如下:
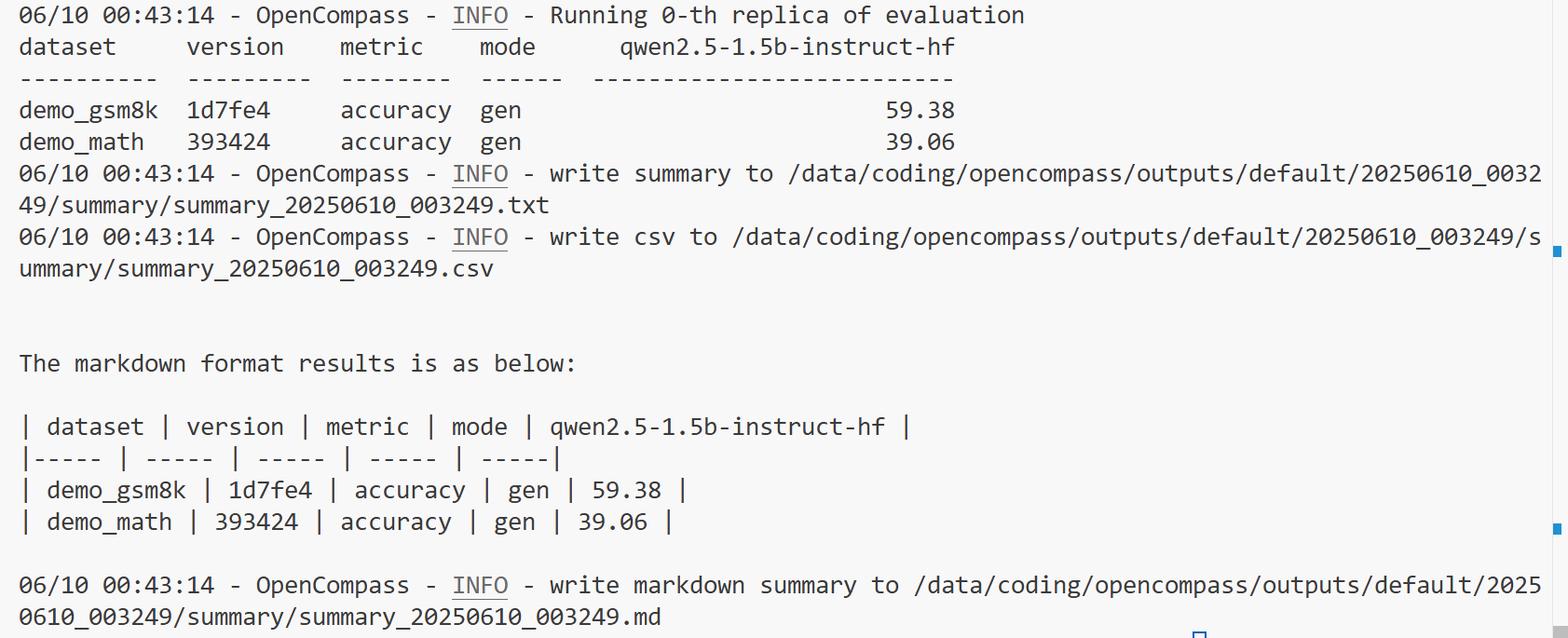
如果有不支持的模型,可以使用相同系列的其他模型的配置文件完成评估。
3.4 使用推理框架进行加速
上面的测评方式调用的是 Hugging Face 推理引擎,速度太慢,我们可以使用 lmdeploy 和 vllm 进行加速,不过先要安装相应的推理框架。(我的环境安装了 lmdeploy,但没安装 vllm,因为 vllm 会自动安装 torch 2.6,会把原先的 torch 2.7 卸载,所以就没有安装 vllm)
这里同时演示分布式推理,我们用两张 12G 的显卡作为 Llama3-8b-Instruct 的推理设备,单张卡是放不下的,所以必须通过分布式。我们找到 Llama3-8b 的 LMDeploy 配置文件(一般情况下,一个模型有三个配置文件,分别是 hf、vllm、lmdeploy 开头),按如下方式修改:
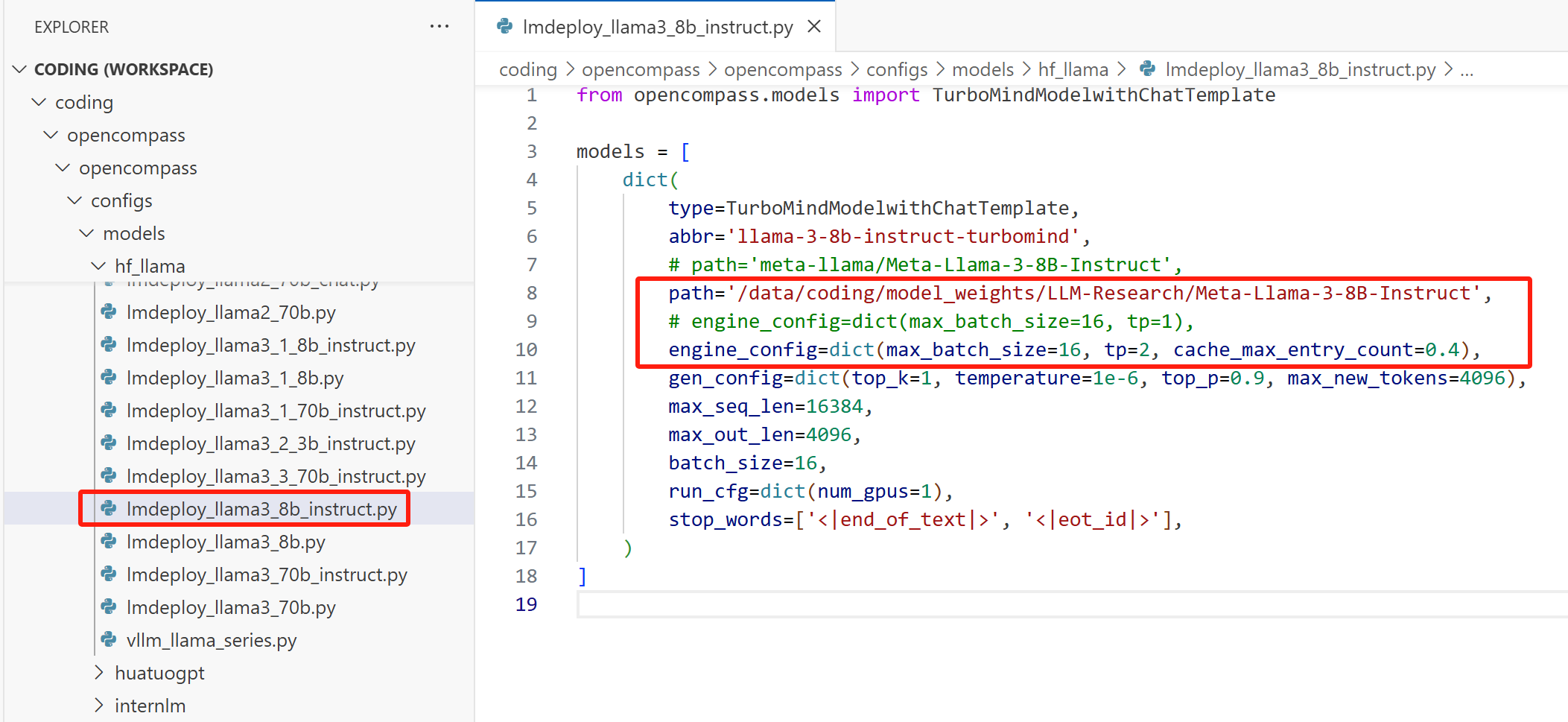
\这里 engine_config=dict(max_batch_size=16, tp=2, cache_max_entry_count=0.4) 是调用 LMDeploy 的参数,我最开始没有设置 cache_max_entry_count,结果显示显存不够用,这个是 KV Cache 所占的剩余显存大小,默认值为0.8,随后我改成0.4,于是跑通了。
另外,要保证 engine_config 中的 max_batch_size 和 batch_size (run_cfg上面的那一行)保持一致。
配置文件修改后,命令为:
python run.py --models lmdeploy_llama3_8b_instruct --datasets demo_gsm8k_chat_gen demo_math_chat_gen --debug
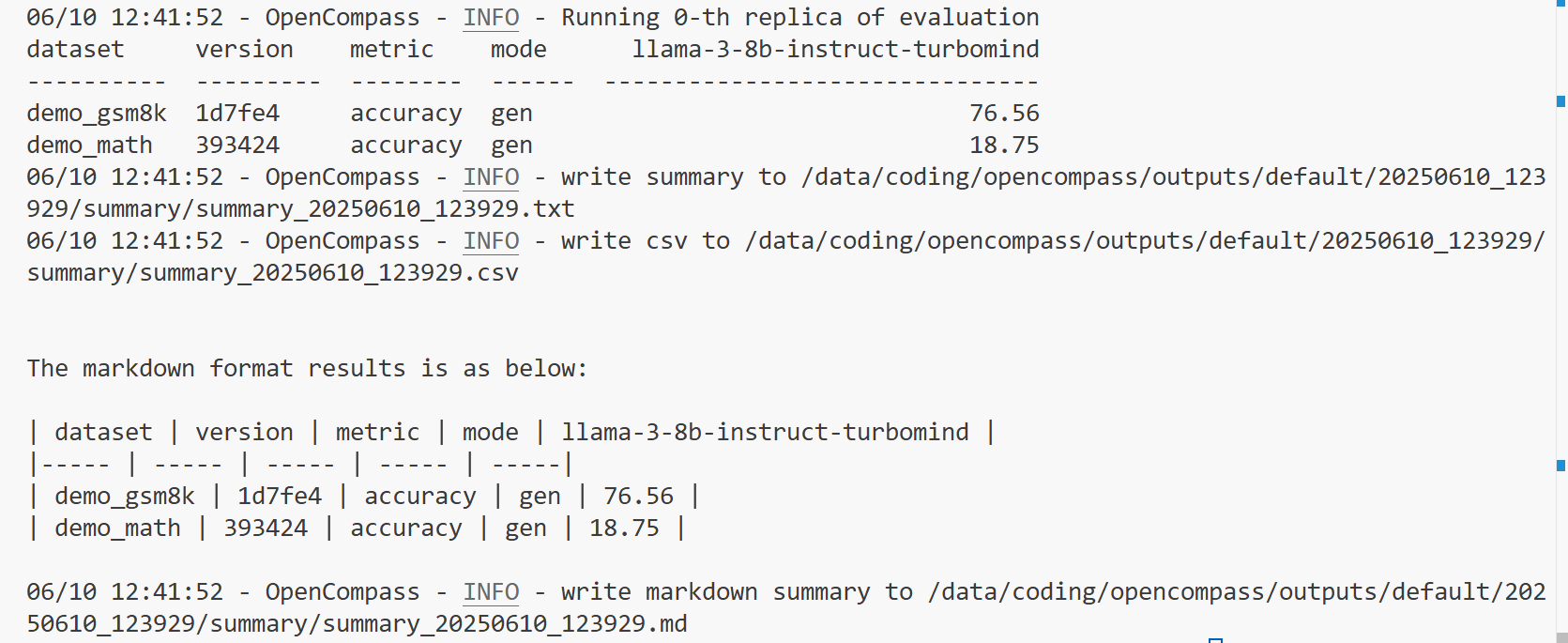
3.5 不同推理引擎的精度差别
值得注意的是,相同的模型,用不同的推理框架,得到的结果会有些许差别,比如我们使用 Hugging Face 推理引擎,配置文件为:
from opencompass.models import HuggingFacewithChatTemplatemodels = [dict(type=HuggingFacewithChatTemplate,abbr='llama-3-8b-instruct-hf',# path='meta-llama/Meta-Llama-3-8B-Instruct',path='/data/coding/model_weights/LLM-Research/Meta-Llama-3-8B-Instruct',max_out_len=1024,batch_size=8,run_cfg=dict(num_gpus=1),stop_words=['<|end_of_text|>', '<|eot_id|>'],)
]评估结果:
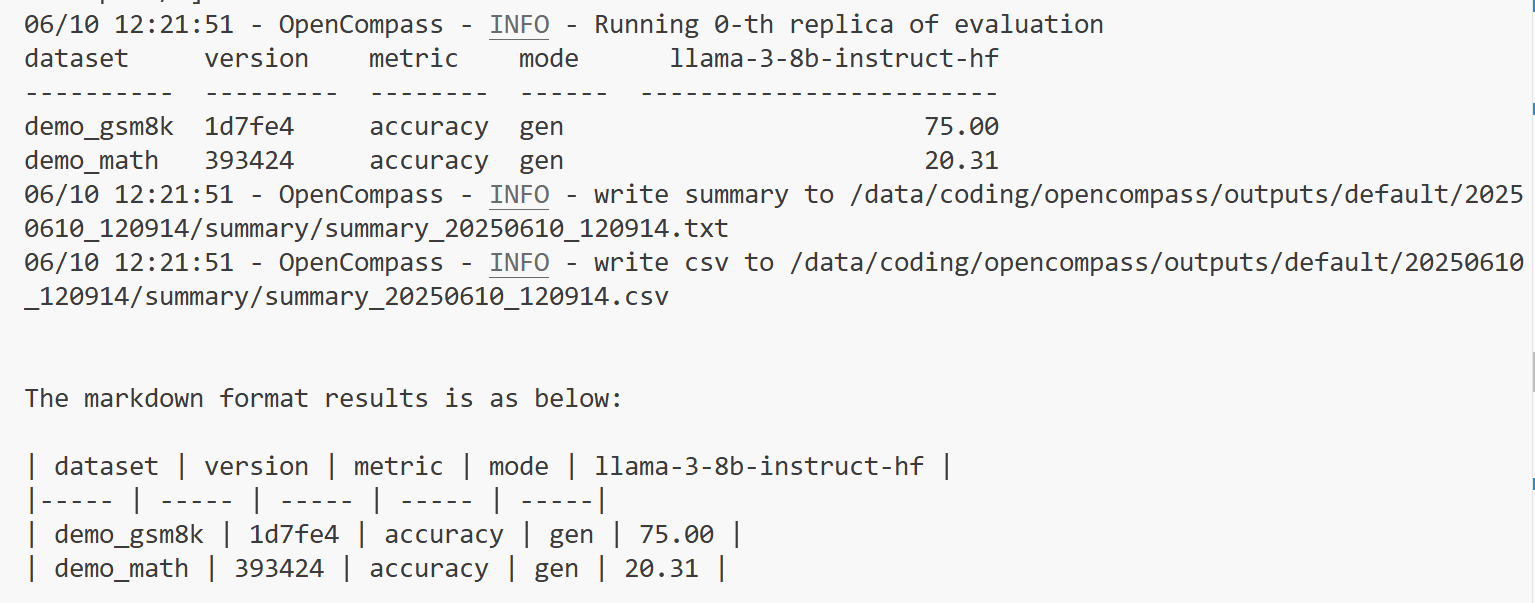
可以看到,和我们刚刚使用 LMDeploy 有差别,在demo_gsm8k数据集上的精度掉了1.56个点,在demo_math上涨了1.6个点,差别主要来自于框架自带的提示词模板,总体而言差别不大。因此,用 LLaMAFactory 和 Xtuner 微调完的模型,可以直接拿过来评估,不需要考虑对话模板对齐的问题,带来的差异可以忽略不计。
3.6 评估对模型选型的作用
通用模型算的是模型在各个任务数据集上的平均得分,但我们工作中用的数据集,很少会涉及到那么多任务,可能只需要其中一个两个,大多数情况下都是对中文进行理解、聊天、回复这些简单的任务。因此,我们选择模型的时候,会从几个排行度比较高的几个开源模型中,找到在相应任务的数据集上表现最高的模型,如果模型给的文档中,没有在相关数据集上的评估指标,那只能自己评估,找到和我们的任务最匹配的基座模型。(大多数大模型应用开发者,一般都是做语言类、知识类模型的开发,因此选用这两个类别的数据集)
模型的评估不分单轮和多轮,都是当一轮处理。
3.7 模型微调后的评估
大多数场景中,只需要在模型选型的时候进行客观评估就好了,模型微调结束之后进行的是主观评估。但在医疗、法律这些业务场景(这些业务场景对结果有比较一致的要求)中,微调结束后还得进行客观评估,这些场景中,微调后需要评估两次:第一次是用开源数据集,一般是使用语言类数据集,看它的通用语言能力有没有退化,如果和微调前差距不大(比如10个点以内),那么评估通过,如果语言能力退化严重,说明微调太过,模型出现过拟合,需要换成前面的检查点重新评估;第二次是在自定义数据集上进行评估,这个是看模型回答垂直领域问题的能力。
当然,如果模型的微调后只回答专业问题,不回答通用问题,那么可以不用进行第一次评估。这个时候,为了防止用户输入非专业问题,可以先设置一个文本分类模型(例如bert),判定用户的问题是否为本专业的问题,如果是,则输入到大模型中,如果不是,则提示用户:该问题我无法回答。
关于如何组织自定义数据集,即有了数据集之后如何使用命令,可以看这个链接。
值得注意的是,使用自定义数据集进行评估的时候,只能使用纯命令行的方式。
4 实战:用 Ceval 数据集评估Llama3-8b
4.1 Ceval 数据集简介
Ceval 数据集是一个专门用于评估大语言模型在中文知识和推理能力上的基准测试数据集。
4.1.1 Ceval 数据集的诞生背景
- 填补空白: 在 Ceval 发布之前,主流的大模型评估基准(如 MMLU)主要侧重于英文。Ceval 旨在提供一个全面、高质量的中文评估基准,以衡量模型在中文语境下的真实能力。
- 多学科评估: 不仅仅测试语言能力,更侧重于评估模型在广泛学科领域的知识掌握程度和推理能力。
- 推动中文大模型发展: 为中文大模型的研发、比较和优化提供一个客观、标准化的衡量标准。
4.1.2 关键特点
- 语言: 中文。所有题目和选项均为中文。
- 题型: 单项选择题。模型需要从四个选项中选择唯一正确答案。
- 学科覆盖广泛: 这是 Ceval 最核心的特点。它涵盖了 4 个大类(学科领域) 下的 52 个具体学科:
- 人文科学: 例如,中国语言文学、历史、哲学、艺术、音乐、设计等。
- 社会科学: 例如,法学、社会学、政治学、教育学、心理学、经济学、管理学等。
- 自然科学: 例如,数学、物理、化学、生物、地球科学等。
- 其他(工程与应用科学): 例如,计算机科学、电子工程、能源动力、环境科学、医学、农学等。
- 题目来源: 题目主要来源于:
- 中国教育考试(如高考、研究生入学考试、职业资格考试等)的真题或模拟题。
- 大学教材、习题集。
- 专业领域的公开题库。
- 确保题目的权威性、代表性和难度适中。
- 数据规模: 包含 13,948 道 中文单项选择题。
- 数据构成:
- 题干: 描述问题。
- 选项: A, B, C, D 四个选项。
- 正确答案: 标注正确的选项字母。
- 解析: 部分题目提供解析,说明为什么该选项正确(这对模型调试和人类理解很有帮助)。
- 数据划分: 通常分为训练集、验证集和测试集。其中测试集是保密的,以防止模型在训练时“偷看”答案,确保评估的公平性。
4.1.3 应用场景
- 模型能力评估: 这是最主要的目的。研究人员和开发者使用 Ceval 来:
- 衡量不同大语言模型(如 GPT-4, Claude, 文心一言,通义千问, 豆包, Kimi, DeepSeek 等)在中文知识和推理上的整体水平。
- 分析模型在不同学科领域(如法律 vs 医学 vs 文学)的优势和劣势。
- 比较同一模型不同版本的能力提升。
- 评估模型在特定任务(如考试答题)上的表现。
- 模型研发与优化: 通过分析模型在 Ceval 上的错误,可以指导模型的改进方向,例如在哪些知识领域需要加强训练,或者推理能力需要提升。
- 学术研究: 为研究大语言模型的知识表示、推理机制、领域适应能力等提供数据支持。
4.1.4 重要性与影响力
- 中文大模型评估的“黄金标准”: Ceval 已成为评估中文大模型能力的最重要和最常被引用的基准之一。模型发布时公布其在 Ceval 上的成绩是常见的做法。
- 推动中文 NLP 发展: 它极大地促进了中文大模型的研究、开发和公平比较。
- 揭示模型局限: Ceval 的广泛学科覆盖有效地揭示了模型在特定专业领域(如高阶数学、特定法律条文、医学细节)知识的不足和推理能力的缺陷。
- 开源与易用: 数据集通常是公开可获取的,方便研究社区使用。
4.1.5 总结
Ceval 数据集是一个精心构建的、覆盖多学科的中文单项选择题基准测试集。它的核心价值在于为评估和比较大语言模型在中文语境下的知识广度、深度和推理能力提供了一个标准化、全面且权威的标尺,对推动中文大模型的发展起到了至关重要的作用。当看到某个中文模型宣称在“Ceval 上达到 SOTA(State-of-the-Art)”时,通常意味着它在中文知识和推理的综合测试中表现优异。
4.2 在OpenCompass中用 Ceval 评估模型
我们看看 Ceval 有哪些数据集:
python tools/list_configs.py ceval
输出:
+--------------------------------+------------------------------------------------------------------------------+
| Dataset | Config Path |
|--------------------------------+------------------------------------------------------------------------------|
| ceval_clean_ppl | opencompass/configs/datasets/ceval/ceval_clean_ppl.py |
| ceval_contamination_ppl_810ec6 | opencompass/configs/datasets/contamination/ceval_contamination_ppl_810ec6.py |
| ceval_gen | opencompass/configs/datasets/ceval/ceval_gen.py |
| ceval_gen_2daf24 | opencompass/configs/datasets/ceval/ceval_gen_2daf24.py |
| ceval_gen_5f30c7 | opencompass/configs/datasets/ceval/ceval_gen_5f30c7.py |
| ceval_internal_ppl_1cd8bf | opencompass/configs/datasets/ceval/ceval_internal_ppl_1cd8bf.py |
| ceval_internal_ppl_93e5ce | opencompass/configs/datasets/ceval/ceval_internal_ppl_93e5ce.py |
| ceval_ppl | opencompass/configs/datasets/ceval/ceval_ppl.py |
| ceval_ppl_1cd8bf | opencompass/configs/datasets/ceval/ceval_ppl_1cd8bf.py |
| ceval_ppl_578f8d | opencompass/configs/datasets/ceval/ceval_ppl_578f8d.py |
| ceval_ppl_93e5ce | opencompass/configs/datasets/ceval/ceval_ppl_93e5ce.py |
| ceval_zero_shot_gen_bd40ef | opencompass/configs/datasets/ceval/ceval_zero_shot_gen_bd40ef.py |
+--------------------------------+------------------------------------------------------------------------------+
评价生成质量,用带“gen_”,评价 ppl,用带“ppl_”的,我们用 ceval_gen 尝试一下:
python run.py --models lmdeploy_llama3_8b_instruct --datasets ceval_gen --debug
因为 ceval_gen 中包含了各个学科的数据集,因此输出有点多:
| dataset | version | metric | mode | llama-3-8b-instruct-turbomind |
|---|---|---|---|---|
| ceval-computer_network | db9ce2 | accuracy | gen | 68.42 |
| ceval-operating_system | 1c2571 | accuracy | gen | 63.16 |
| ceval-computer_architecture | a74dad | accuracy | gen | 47.62 |
| ceval-college_programming | 4ca32a | accuracy | gen | 62.16 |
| ceval-college_physics | 963fa8 | accuracy | gen | 42.11 |
| ceval-college_chemistry | e78857 | accuracy | gen | 33.33 |
| ceval-advanced_mathematics | ce03e2 | accuracy | gen | 42.11 |
| ceval-probability_and_statistics | 65e812 | accuracy | gen | 44.44 |
| ceval-discrete_mathematics | e894ae | accuracy | gen | 31.25 |
| ceval-electrical_engineer | ae42b9 | accuracy | gen | 35.14 |
| ceval-metrology_engineer | ee34ea | accuracy | gen | 58.33 |
| ceval-high_school_mathematics | 1dc5bf | accuracy | gen | 16.67 |
| ceval-high_school_physics | adf25f | accuracy | gen | 26.32 |
| ceval-high_school_chemistry | 2ed27f | accuracy | gen | 52.63 |
| ceval-high_school_biology | 8e2b9a | accuracy | gen | 36.84 |
| ceval-middle_school_mathematics | bee8d5 | accuracy | gen | 26.32 |
| ceval-middle_school_biology | 86817c | accuracy | gen | 71.43 |
| ceval-middle_school_physics | 8accf6 | accuracy | gen | 63.16 |
| ceval-middle_school_chemistry | 167a15 | accuracy | gen | 85.00 |
| ceval-veterinary_medicine | b4e08d | accuracy | gen | 60.87 |
| ceval-college_economics | f3f4e6 | accuracy | gen | 45.45 |
| ceval-business_administration | c1614e | accuracy | gen | 51.52 |
| ceval-marxism | cf874c | accuracy | gen | 57.89 |
| ceval-mao_zedong_thought | 51c7a4 | accuracy | gen | 50.00 |
| ceval-education_science | 591fee | accuracy | gen | 55.17 |
| ceval-teacher_qualification | 4e4ced | accuracy | gen | 77.27 |
| ceval-high_school_politics | 5c0de2 | accuracy | gen | 68.42 |
| ceval-high_school_geography | 865461 | accuracy | gen | 52.63 |
| ceval-middle_school_politics | 5be3e7 | accuracy | gen | 66.67 |
| ceval-middle_school_geography | 8a63be | accuracy | gen | 50.00 |
| ceval-modern_chinese_history | fc01af | accuracy | gen | 43.48 |
| ceval-ideological_and_moral_cultivation | a2aa4a | accuracy | gen | 94.74 |
| ceval-logic | f5b022 | accuracy | gen | 54.55 |
| ceval-law | a110a1 | accuracy | gen | 37.50 |
| ceval-chinese_language_and_literature | 0f8b68 | accuracy | gen | 47.83 |
| ceval-art_studies | 2a1300 | accuracy | gen | 57.58 |
| ceval-professional_tour_guide | 4e673e | accuracy | gen | 62.07 |
| ceval-legal_professional | ce8787 | accuracy | gen | 39.13 |
| ceval-high_school_chinese | 315705 | accuracy | gen | 15.79 |
| ceval-high_school_history | 7eb30a | accuracy | gen | 65.00 |
| ceval-middle_school_history | 48ab4a | accuracy | gen | 68.18 |
| ceval-civil_servant | 87d061 | accuracy | gen | 42.55 |
| ceval-sports_science | 70f27b | accuracy | gen | 63.16 |
| ceval-plant_protection | 8941f9 | accuracy | gen | 68.18 |
| ceval-basic_medicine | c409d6 | accuracy | gen | 73.68 |
| ceval-clinical_medicine | 49e82d | accuracy | gen | 54.55 |
| ceval-urban_and_rural_planner | 95b885 | accuracy | gen | 58.70 |
| ceval-accountant | 002837 | accuracy | gen | 51.02 |
| ceval-fire_engineer | bc23f5 | accuracy | gen | 38.71 |
| ceval-environmental_impact_assessment_engineer | c64e2d | accuracy | gen | 48.39 |
| ceval-tax_accountant | 3a5e3c | accuracy | gen | 36.73 |
| ceval-physician | 6e277d | accuracy | gen | 63.27 |