PriorityBlockingQueue实现原理
文章目录
- 类图结构及概要
- 实现原理
- offer方法
- poll方法
- put方法
- take方法
- size方法
- 总结
PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高或者最低的元素。其内部是使用平衡二叉树堆实现的,所以直接遍历队列元素不保证有序。默认使用对象的 compareTo 方法提供比较规则,如果你需要自定义比较规则则可以自定义comparators 。
类图结构及概要
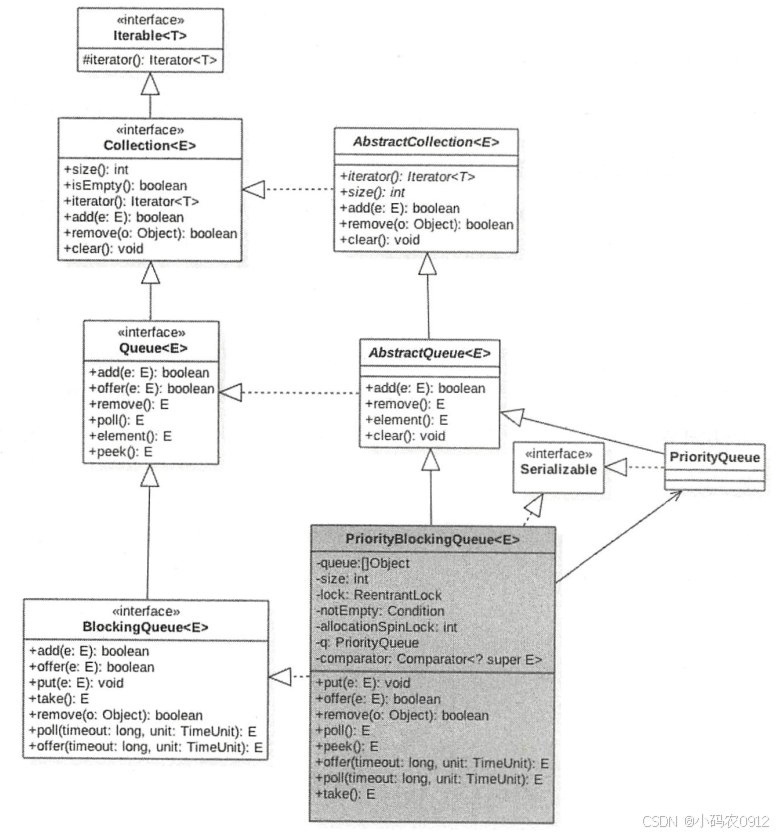
PriorityBlockingQueue 内 部有一个数组 queue,用来存放队列元素,size 用来存放队列元素个数 。 allocationSpinLock 是个自旋锁,其使用 CAS 操作来保证同时只有一个线程可以扩容队列,状态为 0 或者 1 ,其中 0 表示当前没有进行扩容,1表示当前正在扩容。
由于这是一个优先级队列,所以有一个 比较器 comparator 用来比较元素大小 。 lock 独占锁对象用来控制同时只能有一个线程可以进行入队、出队操作。 notEmpty 条件变量用来实现 take 方法阻塞模式。这里没有 notFull 条件变量是因为这里的 put 操作是非阻塞的,为啥要设计为非阻塞的,是因为这是无界队列。 默认队列容量为 11 ,默认比较器为 null,也就是使用元素的compareTo 方法进行 比较来确定元素的优先级 , 这意味着队列元素必须实现了 Comparable接口。
实现原理
offer方法
offer 操作的作用是在队列中插入一个元素,由于是无界队列 , 所 以 一直返回 trne 。
``
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
// 获取独占锁
lock.lock();
int n, cap;
Object[] array;
// (1) )如果当前元素个数>=队列容量,则扩容
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
// (2) 默认比较器为 null
if (cmp == null)
siftUpComparable(n, e, array);
else
// (3) 自定义 比较器
siftUpUsingComparator(n, e, array, cmp);
// (9)将队列元素数增加 1 , 并且激活notEmpty的条件队列里面的 一个阻塞线程
size = n + 1;
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // 释放获取的锁
Object[] newArray = null;
// (4) CAS成功则扩容
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
// oldGap<64 则扩容 , 执行oldcap+2 ,否则扩容 50 % ,并且最大为 MAX_ARAY_SIZE
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // (5) 第 一个线程CAS成功后,第二个线程会进入这段代码 , 然后第二个线程让出 CPU ,尽量让第一个线程
获取锁,但是这得不到保证。
Thread.yield();
lock.lock();
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
``
tryGrow 的作用 是扩容 。 这里为啥在扩容前要先释放锁,然后使用 CAS 控制只有一个线程可以扩容成功?其实这里不先释放锁,也是可行的,也就是在整个扩容期间一直持有锁,但是扩容是需要花时间的,如果扩容时还占用锁那么其他线程在这个时候是不能进行出 队和入队操作的 ,这大大降低 了并发性。 所以为了提高性能 , 使用 CAS 控制只有 一个线程可 以进行扩容,并且在扩容前释放锁,让其他线程可以进行入队和出队操作 。
spinlock 锁使用 CA S 控制只有一 个 线程 可以 进行扩容, CAS 失败的线程会调用Thread.yield() 让出 CPU , 目的是让扩容线程扩容后优先调用 lock.lock 重新获取锁,但是这得不到保证。有可能 yield 的线程在扩容线程扩容完成前己经退 出, 并执行代码( 6 )获取到了锁 , 这时候获取到锁的线程发现 newArray 为 null 就会执行代码 (1)。如果当前数组扩容还没完毕 , 当前线程会再次调用 tryGrow 方法 , 然后释放锁 , 这又给扩容线程获取锁提供了机会 ,如果这时候扩容线程还没扩容完毕 ,则 当 前线程释放锁后又调用 yield 方法让出 CPU。所以当扩容线程进行扩容时, 其他线程原地自旋通过代码( 1 )检查当前扩容是否完毕,扩容完毕后才退 出代码 Cl ) 的循环。
扩容线程扩容完毕后会重置自旋锁变量 allocationSpinLock 为 0,这里并没有使用 UNSAFE 方法的 CAS 进行设置是因为 同时 只可 能 有一个线程获取到该锁 , 并且allocationSpinLock 被修饰为 了 volatile 的。当扩容线程扩容完毕后会执行代码 ( 6 ) 获取锁,获取锁后复制当前 queue 里面的元素到新数组。
``
private static void siftUpComparable(int k, T x, Object[] array) {
Comparable<? super T> key = (Comparable<? super T>) x;
// 队列元素个数> 0 则判断插入位置,否则直接入队( 7)
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (key.compareTo((T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = key;
}
``
假设队列初始化容量为 2,创建的优先级队列的泛型参数为 Integer。
I. 首先调用队列 的 offer(2 ) 方法,希望 向队列 插入元素 2 ,插入前 队 列状态如下所示 :
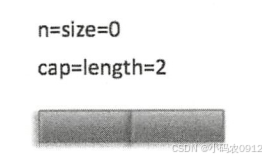
首先执行代码 ( 1 ),从图 中的变量值可知判断结果为 fa lse,所以紧接着执行代码(2)。由于 k=n=size=0,所以代码( 7) 的判断结果为 false ,因此会执行代码 ( 8 )直接把元素 2 入队 。最后执行代码( 9 )将 size 的值加 1 , 这时候队列的状态如下所示 :

II. 第二次调用队列的 o ffer(4)时, 首先执行代码 (1),从图中的变量值可知判断结果为 false,所以执行代码( 2 ) 。由于 k= 1 ,所以进入 while 循环,由于 parent=0;e=2 ;key=4 ;默认元素 比 较器使用元素的 compareTo 方法,可知 key>e,所以执行 break 退出siftUpComparable 中的循环,然后把元素存到数组下标为 1 的地方 。 最后执行代码( 9 )将size 的值加1, 这时候队列状态如下所示:

III. 第三次调用队列的 offer(6)时, 首先执行代码 (1 ) ,从 图中的变量值知道 ,这时候判断结果为 true,所以调用 tryGrow 进行数组扩容 。 由于 2<64,所以执行 newCap=2 +(2+2 )=6 , 然后创建新数组井复制,之后调用 s iftUpComparable 方法 。 由于 k=2> 0 , 故进入while 循环,由于 parent=0 ;e=2;key=6 ;key>e , 所以执行 break 后退出 while 循环 , 并把元素6 放入数组下标为 2 的地方 。 最后将 s ize 的值加1,现在队列状态如下所示 :

IV. 第四次调用队列 的 offer(1)时, 首先执行 代 码(1),从图中的 变量值知道 ,这次判断结果为 false , 所以执行代 码( 2 ) 。 由于 k=3 ,所以进入 while 循 环,由于parent=1;e=4;key=1; key句,所以把元素 4 复制到数组下标为 3 的地方 。然后执行 k=1,再次循环 , 发现e=2,key=1,key句,所以 复制元素 2 到数组下标1处 , 然后 k=0 退出循环 。最后把元素1存放到下标为 0 的地方,现在 的状态如下所示 :

这时候二叉树堆的树形图如下所示 :
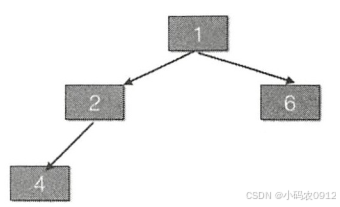
由此可见 , 堆的根元素是1, 也就是这是一个最小堆 , 那么当调用这个优先级队列的poll 方法时,会依次返回堆里面值最小的元素。这其实就是将二叉树下转化为前序遍历的数组。
poll方法
poll 操作的作用是获取队列内部堆树的根节点元素,如果队列为空 ,则 返回 null 。
``
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock(); // 获取独占锁
try {
return dequeue();
} finally {
lock.unlock(); // /释放独占锁
}
}
``
在进行出队操作时要先加锁,这意味着,当前线程在进行出队操作时,其他线程不能再进行入队和出队操作,但是前面在介绍 offer 函数时介绍过,这时候其他线程可以进行扩容。下面看下具体执行出队操作的 dequeue 方法的代码 :
``
private E dequeue() {
// 队列为空,则~回 nul l
int n = size - 1;
if (n < 0)
return null;
else {
// (1) 获取队头元素
Object[] array = queue;
E result = (E) array[0];
// (2) 获取队尾元素,并赋值为 null
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null) // (3)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n; // (4)
return result;
}
}
``
如果队列为空则 直接返回 null ,否则执行代码 Cl )获取数组第一个元素作为返回值存放到变量 Result 中,这里需要注意 ,数组里面的第一个元素是优先级最小或者最大 的元素 ,出队操作就是返回这个元素。然后代码( 2 )获取队列尾部元素并存放到变量 x 中 ,且置空尾部节点 ,然后执行代码。 )将变量 x 插入到数组下标为 0 的位置 ,之后重新调整堆为最大或者最小堆,然后返回 。 这里重要的是,去掉堆的根节点后,如何使用剩下的节点重新调整一个最大或者最小堆 。 下面我们看下 siftDownComparable 的实现代码 :
``
private static void siftDownComparable(int k, T x, Object[] array,
int n) {
if (n > 0) {
Comparable<? super T> key = (Comparable<? super T>)x;
int half = n >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = array[child];
int right = child + 1;
if (right < n &&
((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
c = array[child = right];
if (key.compareTo((T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = key;
}
}
``
I. 第一次调用队列的 poll()方法时, 首先执行代码 CI )和代码( 2 ),这时候变 量size =4 ; n=3 ; result=1 ; x=4· 此时队列状态如下所示 :

然后执行代码( 3 )调整堆后队列状态为

II. 第二次调用队列的 poll () 方法时,首先执行代码( 1 )和代码( 2 ),这时候变量size =3 ; n=2 ; result=2 ; x=6;此时队列状态为:

然后执行代码 (3 )调整堆后队列状态为

III. 第三次调用队列的 poll()方法时,首先执行代码( 1) 和代码( 2 ),这时候变量size =2 ; n=l ; result=4 ; x=6:,此时队列状态为:

然后执行代码 (3 )调整堆后队列状态为:

IV . 第四次直接返回元素 6 。
put方法
put 操作内部调用的是 offer 操作 ,由 于是无界队列,所以不需要阻塞。
take方法
take 操作的作用是获取队列内部堆树的根节点元素 , 如果队列为空则阻塞。首先通过 lock.locklnterruptibly() 获取独占锁,以这个方式获取的锁会对中断进行响应 。然后调用 dequeue 方法返回堆树根节点元素,如果队列为空 ,则返回false 。然后当前线程调用 notEmpty.await()阻塞挂起自己 , 直到有线程调用了 offer()方法(在offer 方法内添加元素成功后会调用 notEmpty.signa l 方法,这会激活一个阻塞在 notEmpty的条件队列里面的一个线程)。另外,这里使用 while 循环而不是 if 语句是为了避免虚假
唤醒 。
size方法
计算 队列元素个数 。在返回 size 前加了锁,以保证在调用 size() 方法时不会有其他线程进行入队和出队操作 。 另外,由于 size 变量没有被修饰为 volatie 的, 所以这里加锁也保证了在多线程下 size 变量的内存可见性 。
总结
PriorityBlockingQueue 队列 在内部使用二叉树堆维护元素优先级,使用数组作为元素存储的数据结构,这个数组是可扩容的 。当当前元素个数>=最大容量时会通过 CAS 算法扩容,出队时始终保证出队的元素是堆树的根节点,而不是在队列里面停留时 间最长的元素。使用元素的 compareTo 方法提供默认的元素优先级比较规则,用户可以自定义优先级的比较规则。
PriorityBlockingQueue 类似于 ArrayBlockingQueue,在内部使用一个独占锁来控制同时只有一个线程可以进行入队和出队操作。另外,前者只使用了一个notEmpty 条件变量而没有使用 notFull ,这是因为前者是无界队列,执行 put 操作时永远不会处于 await 状态,所以也不需要被唤醒。而 take 方法是阻塞方法,并且是可被中断的 。当需要存放有优先级的元素时该队列比较有用 。