hash哈希函数(散列函数)、hash table 哈希表(散列表)
目录
一、散列函数的基知识
二、散列函数的性质
三、散列函数的应用
3.1 保护资料
3.2 确保传递真实的信息
四、目前常见的散列算法
五、 哈希表
5.1 基本概念
5.2 处理冲突
5.3 哈希表应用举例:Linux内核的bcache
一、散列函数的基知识
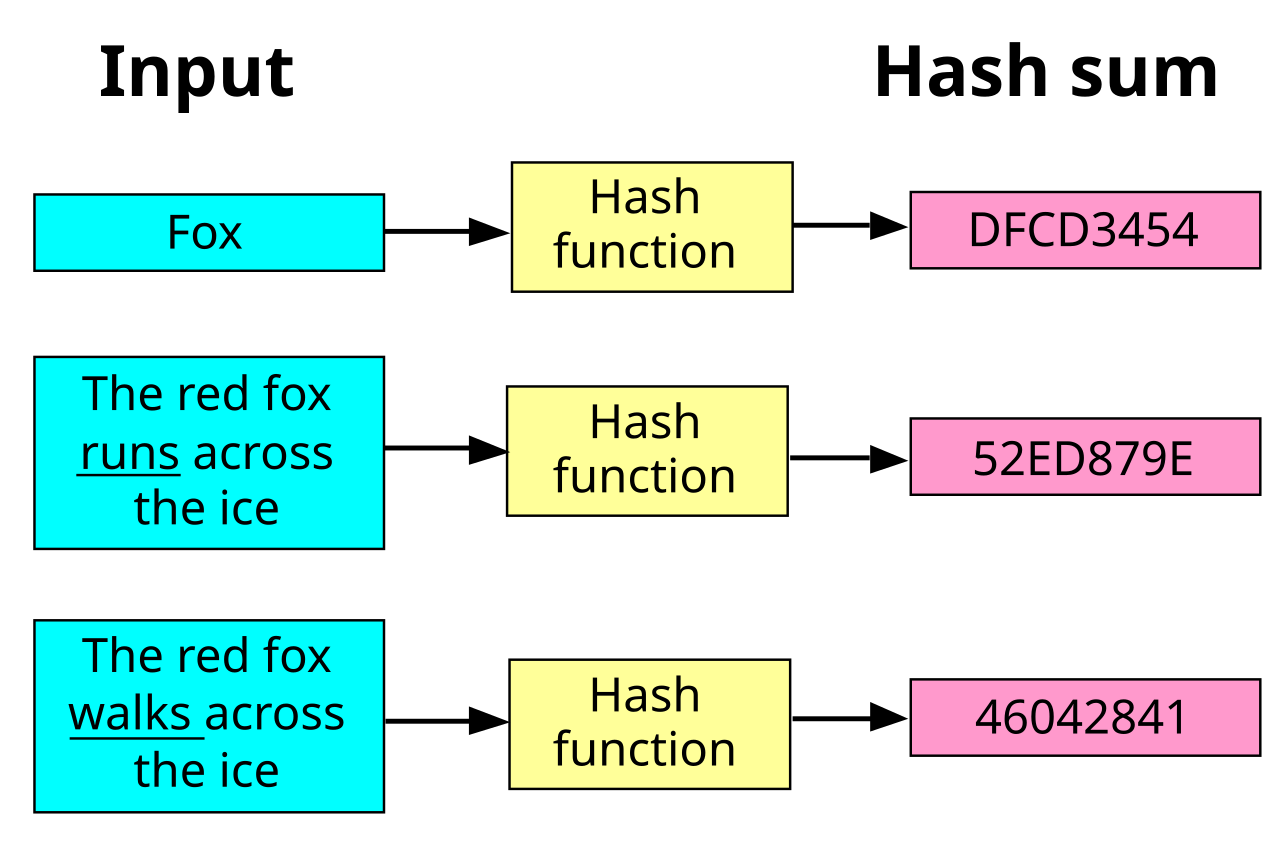
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据计算成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(又叫哈希值)(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。如果在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
指纹
在计算机科学中,“指纹”通常指的是一种能够唯一标识某个数据对象的短小、固定长度的值(指纹的关键特点是它简洁且能够代表整个数据,但它本身比原始数据要小得多)。指纹的作用是通过对数据进行某种形式的处理,生成一个简洁的代表,便于快速识别、查找或比较数据。具体来说,指纹可以看作是数据的摘要或标识符。
- 在哈希函数中的指纹
对于哈希函数而言,指纹就是对输入数据(如字符串、文件、数组等)通过哈希算法生成的唯一标识符,这个标识符通常是一个固定长度的数字或字符串。这个指纹具有以下几个特点:
定长:哈希函数通常会把输入数据(无论其大小如何)转换为固定长度的输出(例如,MD5算法输出的是128位的指纹,SHA-256输出的是256位的指纹)。
高效生成:生成这个指纹的过程通常非常高效,可以在常数时间内计算出来。
唯一性:理想情况下,不同的数据应当生成不同的指纹,哈希函数应尽量避免哈希冲突(不同的数据产生相同的指纹)。
不可逆性:哈希函数是一种单向函数,通过哈希值不能反推原始数据。换句话说,从指纹(哈希值)无法恢复出原始数据。
- 举个例子
假设我们有一个字符串
"hello",我们应用某种哈希算法(例如 SHA-256)来计算其指纹。
- 输入数据:
"hello"- 计算得到的哈希值(指纹):
2cf24dba5fb0a30e26e83b2ac5b9e29e1b169e20b0f21d1dcd7f6a1e6c3cfdb3这里的哈希值
2cf24dba5fb0a30e26e83b2ac5b9e29e1b169e20b0f21d1dcd7f6a1e6c3cfdb3就是"hello"这个字符串的指纹。
- 指纹的实际应用
数据查找:哈希表中通过数据的指纹来快速查找数据。
数据验证:当传输文件或数据时,可以计算数据的哈希值,并与接收端计算的哈希值进行比较,如果相同,则说明数据没有被篡改。比如,下载文件时,文件提供商通常会给出文件的哈希值,用户可以下载文件后计算哈希值来确保文件未被篡改。
数字签名:在数字签名中,通过哈希函数将消息转换为指纹,并对指纹进行加密,确保消息的完整性和来源。
负载均衡和分布式系统:例如,在分布式哈希表(DHT)中,哈希函数用来将数据分配到不同的节点上,确保数据均匀分布。
- 总结
在哈希函数中,指纹就是对原始数据进行哈希计算后得到的一个简短、固定长度的数字值,它充当数据的唯一标识符。通过指纹,我们可以高效地查找、验证、比较数据。
如今,散列算法也被用来加密存在数据库中的密码(password)字符串,由于散列算法所计算出来的散列值(Hash Value)具有不可逆(无法逆向演算回原本的数值)的性质,因此可有效的保护密码。
二、散列函数的性质
所有散列函数都有如下一个基本特性:如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。但另一方面,散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”,这通常是两个不同长度的输入值,刻意计算出相同的输出值。输入一些数据计算出散列值,然后部分改变输入值,一个具有强混淆特性的散列函数会产生一个完全不同的散列值。
典型的散列函数都有非常大的定义域,比如SHA-2最高接受(2^64-1)/8长度的字节字符串。同时散列函数一定有着有限的值域,比如固定长度的比特串。在某些情况下,散列函数可以设计成具有相同大小的定义域和值域间的单射。在密码学中,散列函数必须具有不可逆性。
- 散列碰撞/散列冲突
在计算机科学中,碰撞或冲突是指两个不同的元素具有相同的哈希值、校验和,数字指纹时发生的情况。当数据量足够多(例如将所有可能的人名和计算机文件名映射到一段字符上)时,碰撞是不可避免的。这仅仅是鸽巢原理的一个实例。
哈希碰撞是指两个不同的输入值经过哈希函数处理后得到相同的输出值。 这种情况在哈希表数据结构中尤为重要,因为它可能影响查找和存储的效率。
哈希碰撞的发生是不可避免的,主要原因如下:
- 输入空间通常大于输出空间:哈希函数将任意长度的输入映射到固定长度的输出,必然会有多个输入对应同一个输出.
- 生日悖论:根据概率论,即使在相对较小的样本空间中,也有较高的概率出现重复.
处理哈希碰撞的主要方法有两种:
- 开放寻址法:当发生碰撞时,继续探测散列表的下一个位置,直到找到空槽.
- 链接法:在每个散列表槽位使用链表存储发生碰撞的元素
一个优秀的哈希函数应该满足以下条件:
- 单向性:难以从哈希值反推原始输入。
- 弱无碰撞性:给定一个输入,难以找到另一个输入产生相同的哈希值。
- 强无碰撞性:难以找到任意两个不同输入产生相同的哈希值.
在实际应用中,哈希碰撞可能被恶意利用。例如,攻击者可能通过制造大量碰撞来增加服务器查询哈希表的时间,从而导致性能下降或服务瘫痪.为了减少哈希碰撞的影响,可以采取以下措施:
- 选择高质量的哈希函数。
- 使用足够大的哈希表以减少碰撞概率。
- 实现有效的碰撞解决策略,如链接法或开放寻址法。
- 在必要时动态调整哈希表大小。
总之,虽然哈希碰撞无法完全避免,但通过合理的设计和实现,可以最大限度地减少其对系统性能的影响。
碰撞的影响依程序而异。当散列函数和数字指纹用于标识相似数据时,程序被设计成尽可能增加相似但不同的数据发生碰撞的可能性;校验和则不同,要求尽可能使得相似的数据输出不同,而不考虑不同数据输出相同的情况。
三、散列函数的应用
由于散列函数的应用的多样性,它们经常是专为某一应用而设计的。例如,加密散列函数假设存在一个要找到具有相同散列值的原始输入的敌人。一个设计优秀的加密散列函数是一个“单向”操作:对于给定的散列值,没有实用的方法可以计算出一个原始输入,也就是说很难伪造。为加密散列为目的设计的函数,如SHA-2,被广泛的用作检验散列函数。这样软件下载的时候,就会对照验证代码之后才下载正确的文件部分。此代码不会因为环境因素的变化,如机器配置或者IP地址的改变而有变动。以保证源文件的安全性。
错误监测和修复函数主要用于辨别数据被随机的过程所扰乱的事例。当散列函数被用于校验和的时候,可以用相对较短(但不能短于某个安全参数, 通常不能短于160位)的散列值来验证任意长度的数据是否被更改过。
3.1 保护资料
散列值可用于唯一地识别机密信息。这需要散列函数是抗碰撞(collision-resistant)的,意味着很难找到产生相同散列值的资料。散列函数分类为密码散列函数和可证明的安全散列函数。第二类中的函数最安全,但对于大多数实际目的而言也太慢。透过生成非常大的散列值来部分地实现抗碰撞。例如,SHA-256是最广泛使用的密码散列函数之一,它生成256比特值的散列值。
3.2 确保传递真实的信息
消息或数据的接受者确认消息是否被篡改的性质叫数据的真实性,也称为完整性。发信人通过将原消息和散列值一起发送,可以保证真实性。
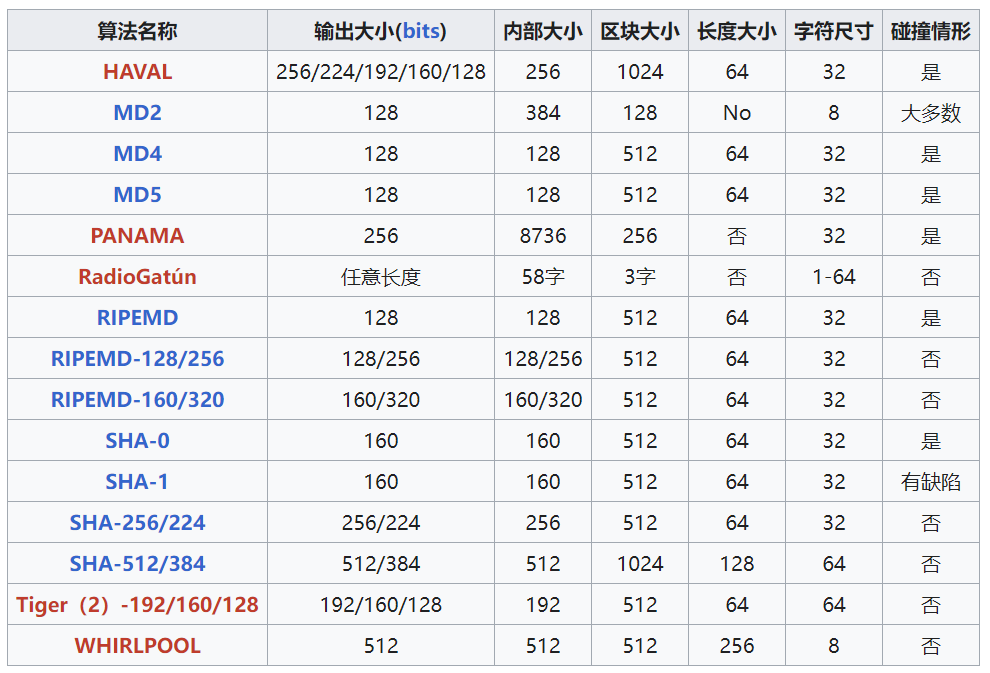
四、目前常见的散列算法
五、 哈希表
5.1 基本概念
散列表(英语:Hash table)是根据键而直接访问在存储器存储位置的数据结构。也就是说,它通过计算出一个键值的函数,将所需查询的数据映射到表中一个位置来让人访问,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名𝑥到首字母𝐹(𝑥)的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则𝐹(),存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
可以将散列表理解为一串按顺序放的数组,数组的下标是从key经过计算得出,数组每个位置存放 value。这里有很多将key转换为下标的函数,比如取模,md5等。可以在哈希表可视化页面 直观操作,理解这里的数据结构。
- 若关键字为𝑘,则其值存放在𝑓(𝑘)的存储位置上。由此,不需比较便可直接获取所查记录。称这个对应关系𝑓为散列函数,按这个思想建立的表为散列表。
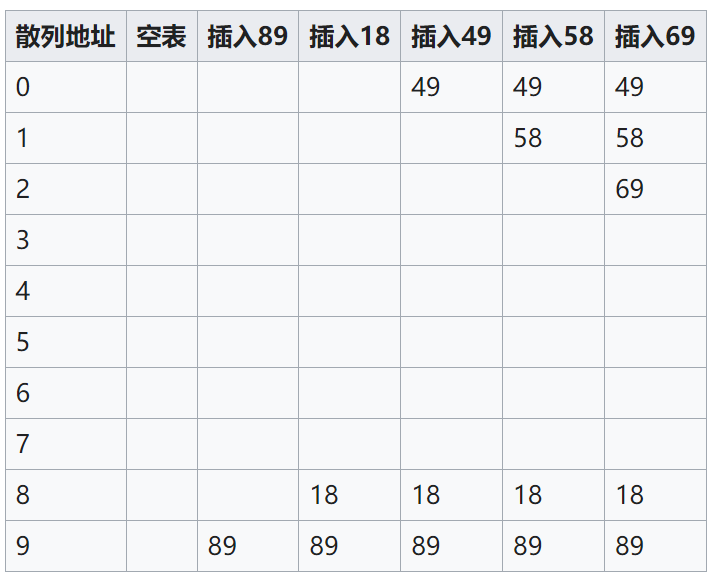
- 对不同的关键字可能得到同一散列地址,即𝑘1≠𝑘2,而𝑓(𝑘1)=𝑓(𝑘2),这种现象称为冲突(英语:Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数𝑓(𝑘)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
- 若对于关键字集合中的任一个关键字,经散列函数镜像到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。
5.2 处理冲突


5.3 哈希表应用举例:Linux内核的bcache
Linux操作系统在物理文件系统与块设备驱动程序之间引入了“缓冲区缓存”(Buffer Cache,简称bcache)。当读写磁盘文件的数据,实际上都是对bcache操作,这大大提高了读写数据的速度。如果要读写的磁盘数据不在bcache中,即缓存不命中(miss),则把相应数据从磁盘加载到bcache中。一个缓存数据大小是与文件系统上一个逻辑块的大小相对应的(例如1KiB字节),在bcache中每个缓存数据块用struct buffer_head记载其元信息:

整个bcache以struct buffer_head为基本数据单元,组织为一个封闭寻址(close addressing,即“单独链表法”解决冲突)的散列表struct buffer_head * hash_table[NR_HASH]; 散列函数的输入关键字是b_blocknr(逻辑块号)与b_dev(设备号)。计算hash值的散列函数表达式为:
(b_dev ^ b_blocknr) % NR_HASH
其中NR_HASH是散列表的条目总数。发生“ 冲突”的struct buffer_head,以b_prev与b_next指针组成一个双向(不循环)链表。bcache中所有的struct buffer_head,包括使用中不空闲与未使用空闲的struct buffer_head,以b_prev_free和b_next_free指针组成一个双向循环链表free_list,其中未使用空闲的struct buffer_head放在该链表的前部。