【计算机存储架构】层次化存储架构
引言
计算机存储系统是现代计算机系统的核心组成部分,负责数据的存储和访问。随着计算机技术的快速发展,数据量的爆炸式增长和对性能的需求不断提高,传统的单一存储架构已经难以满足需求。为了解决这一问题,层次化存储架构应运而生。层次化存储架构通过将不同特性的存储介质组合在一起,形成了一个分层的存储系统,以平衡性能、成本和容量的需求。
一、分层架构定义
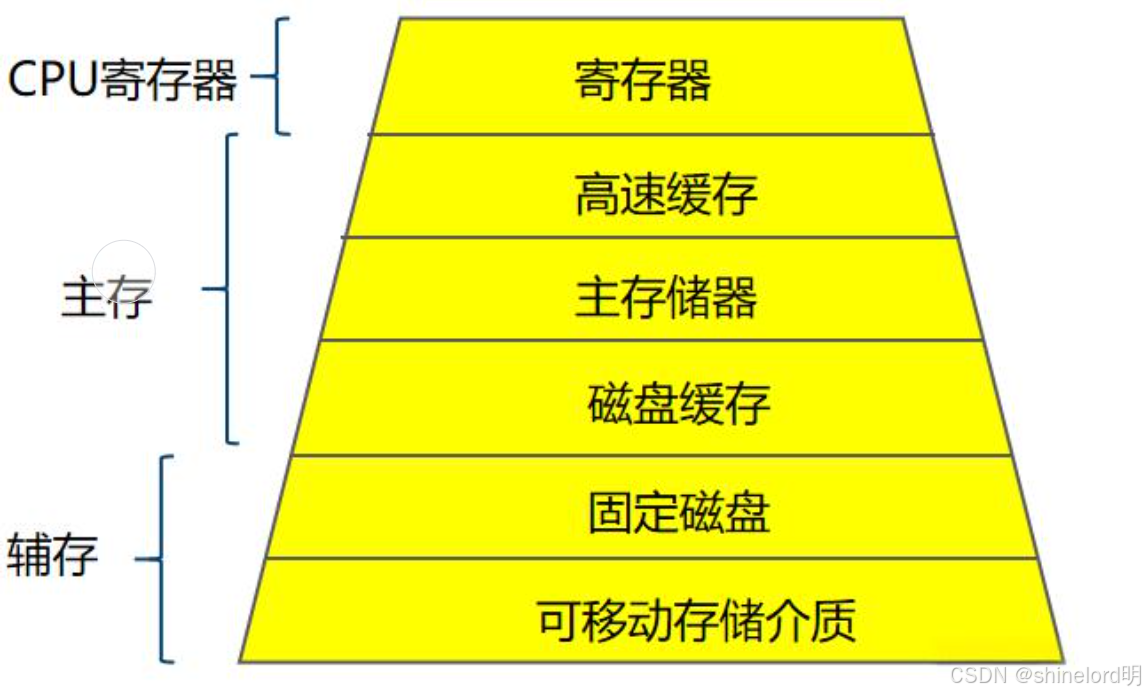
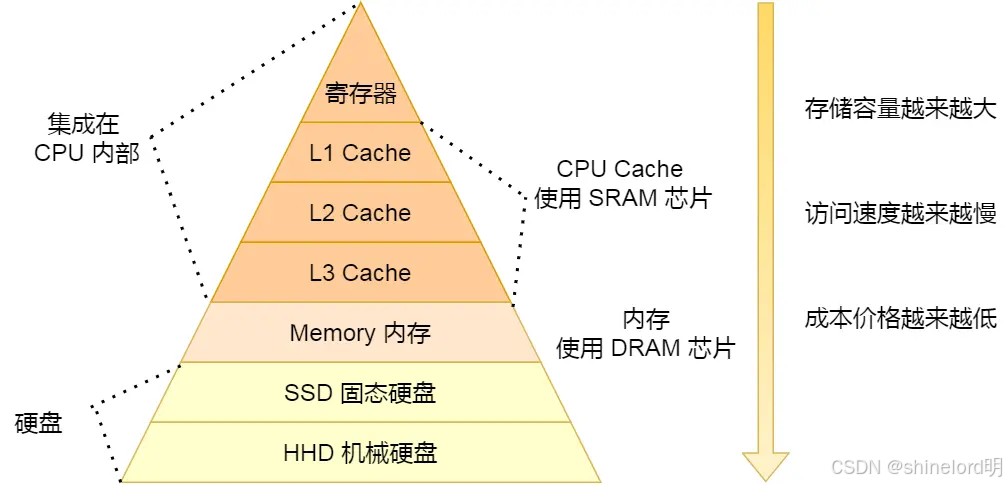
层次化存储架构(Hierarchical Storage Management, HSM)是一种将存储资源按照性能、成本和容量等特性进行分层的存储系统架构。它通过将不同类型的存储介质(如内存、缓存、硬盘、SSD、磁带等)组合在一起,形成一个多层次的存储系统。这种架构的核心思想是将数据放置在最合适的存储层,以实现性能和成本的最佳平衡。
层次化存储架构的主要目标是:
提高性能:将频繁访问的数据放置在高性能存储层(如内存或SSD)。
降低成本:将不频繁访问的数据放置在低成本存储层(如磁盘或磁带)。
扩展容量:通过分层存储,可以灵活扩展存储系统的容量。
二、层次化存储架构发展历史
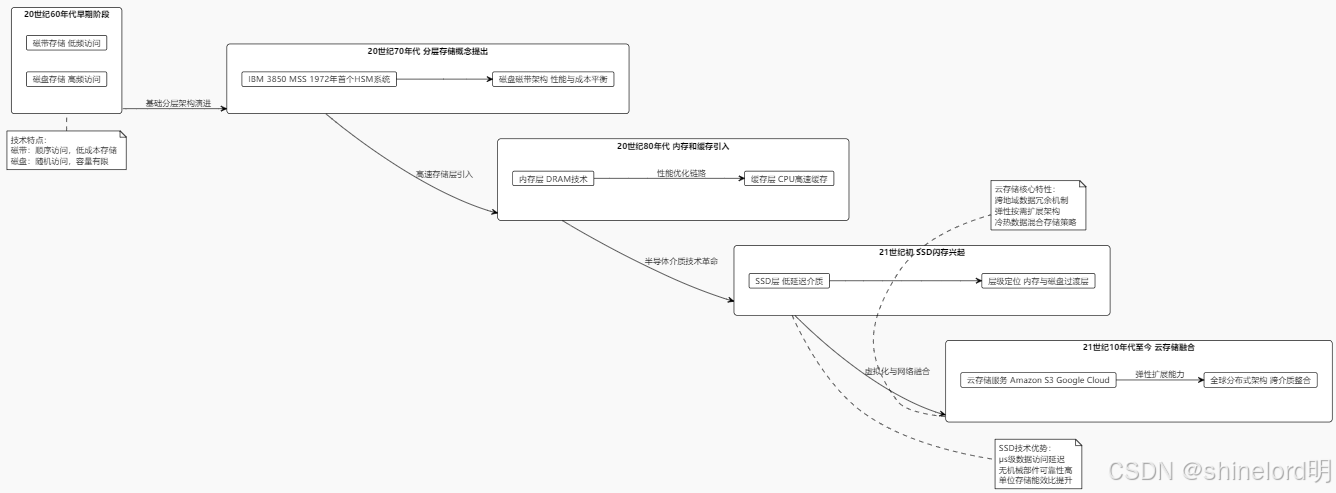
层次化存储架构的发展可以追溯到计算机存储技术的早期阶段。以下是其发展历程的几个关键阶段:
早期阶段(20世纪60年代):
在计算机发展的初期,存储介质主要是磁带和磁盘。由于磁带的访问速度较慢,而磁盘的容量有限,人们开始尝试将数据分层存储,将频繁访问的数据存储在磁盘上,而将不常用的数据存储在磁带上。
分层存储概念的提出(20世纪70年代):
20世纪70年代,随着计算机系统的复杂化,分层存储的概念被正式提出。IBM在1972年推出了第一个层次化存储管理(HSM)系统,名为“IBM 3850 Mass Storage System”。该系统通过将数据存储在磁盘和磁带上,实现了性能和成本的平衡。
内存和缓存的引入(20世纪80年代):
随着内存技术的发展,计算机系统开始引入内存和缓存作为高性能存储层。内存和缓存的引入进一步优化了数据访问性能,形成了更复杂的层次化存储架构。
SSD和闪存的兴起(21世纪初):
21世纪初,固态硬盘(SSD)和闪存技术的快速发展,为层次化存储架构带来了新的选择。SSD的高性能和低延迟使其成为内存和磁盘之间的理想过渡层,进一步优化了存储系统的性能。
云存储和分布式存储的融合(21世纪10年代至今):
随着云计算和分布式存储技术的兴起,层次化存储架构开始与云存储结合,形成了跨地域、跨介质的分布式层次化存储系统。例如,Amazon S3、Google Cloud Storage 等云存储服务都采用了层次化存储架构。
三、层次化存储架构特点
层次化存储架构具有以下显著特点:
分层存储:
将存储介质按照性能、成本和容量划分为多个层次,如内存、缓存、SSD、HDD、磁带等。
数据迁移:
数据会在不同层次之间进行迁移。例如,不常用的数据会从高性能存储层迁移到低成本存储层,而频繁访问的数据则会从低成本存储层迁移到高性能存储层。
智能管理:
层次化存储架构通常配备智能管理系统,能够根据数据的访问频率、使用模式和存储策略自动进行数据迁移和存储优化。
灵活性:
可以根据实际需求动态调整存储层次,支持扩展和缩容。
成本优化:
通过将不常用的数据存储在低成本存储层,显著降低了整体存储成本。
| 特点分类 | 特点描述 | 具体说明与示例 |
|---|---|---|
| 分层存储 | 将存储介质按性能、成本、容量划分为多个层次 | - 常见层次:内存、缓存、SSD、HDD、磁带 - 性能排序:内存 > 缓存 > SSD > HDD > 磁带 - 成本排序:磁带 < HDD < SSD < 缓存 < 内存 |
| 数据迁移 | 数据在不同存储层间动态迁移,根据访问频率调整存储位置 | - 低频数据:从 SSD/HDD 迁移至磁带 - 高频数据:从 HDD 迁移至 SSD / 内存 - 示例:视频网站热点内容自动从冷存储迁移至 SSD 缓存 |
| 智能管理 | 配备智能系统,基于访问模式和策略自动优化数据存储 | - 核心功能:数据访问频率分析、迁移策略制定、存储资源调度 - 技术实现:AI 算法预测数据访问模式,自动触发迁移流程 |
| 灵活性 | 支持存储层次动态调整,可按需扩展或缩容 | - 扩展场景:新增 SSD 层提升数据库性能 - 缩容场景:归档数据迁移至磁带后释放 HDD 空间 - 动态调整:根据业务峰值自动增减缓存容量 |
| 成本优化 | 通过将低频数据存储在低成本介质,降低整体存储成本 | - 成本节省逻辑:1TB 磁带成本约为 1TB SSD 的 1/100 - 典型案例:企业归档数据迁移至磁带,存储成本降低 80% 以上 |
四、层次化存储架构细分类型
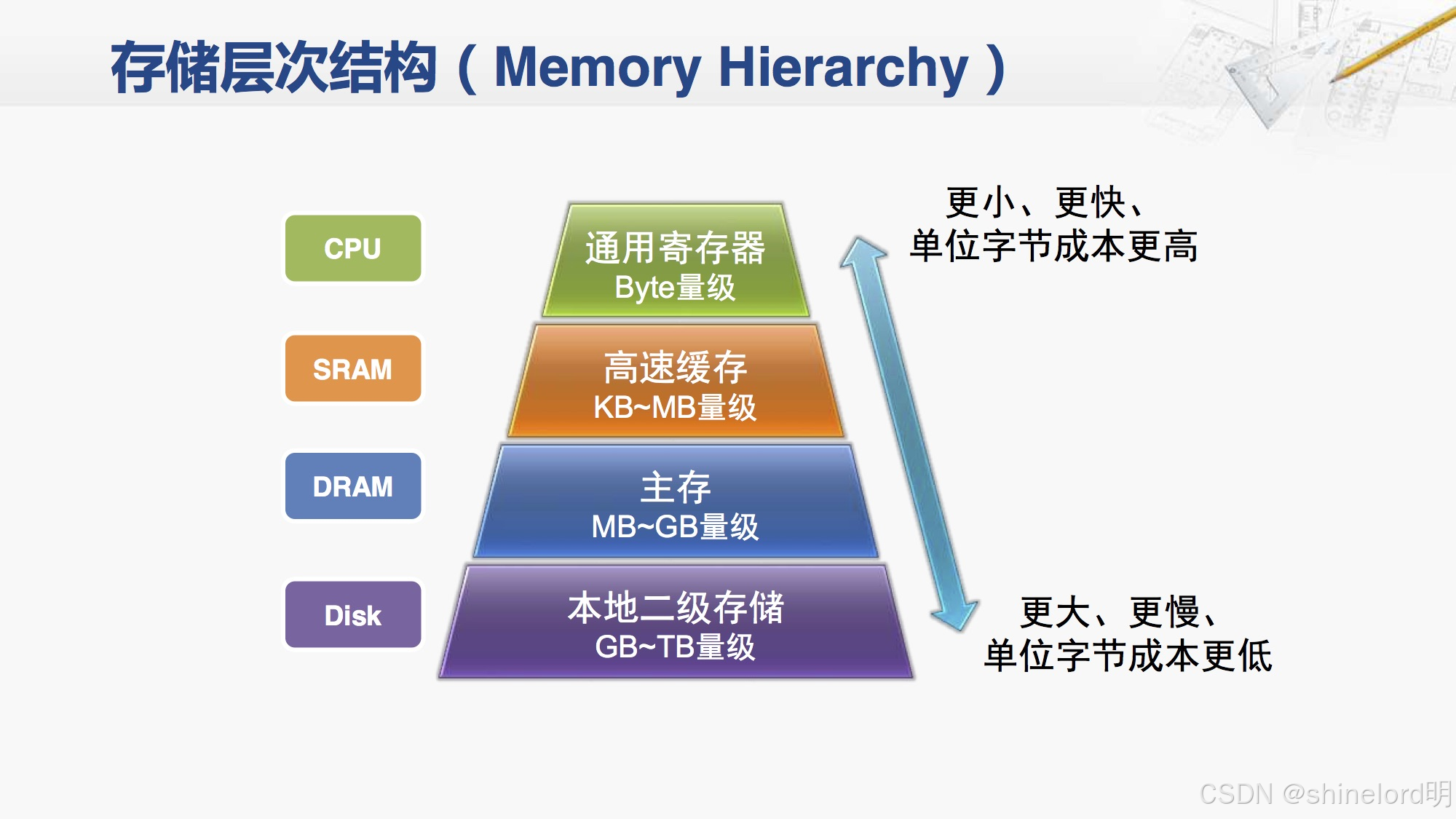
层次化存储架构可以根据存储介质的特性、应用场景和管理策略进行细分。常见的细分类型包括:
按存储介质划分:
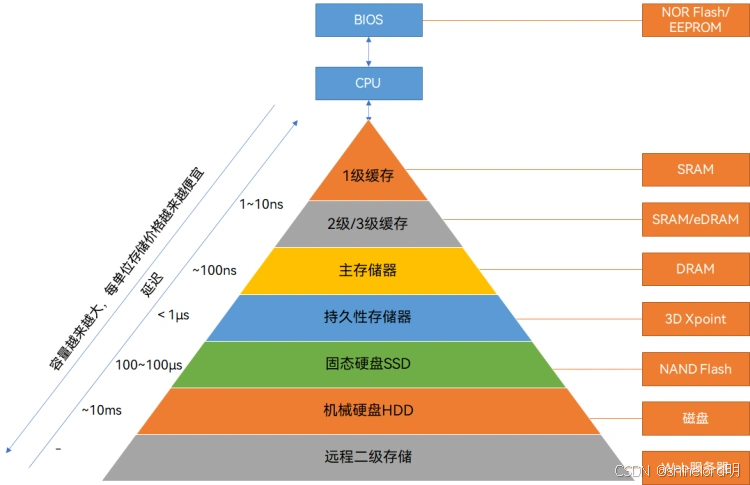
内存层:包括高速缓存(如CPU缓存、DRAM缓存)。
缓存层:包括SSD缓存、NAND Flash缓存。
磁盘层:包括HDD存储。
磁带层:用于长期归档存储。
按访问频率划分:
热数据层:存储频繁访问的数据,通常位于高性能存储层。
温数据层:存储中等访问频率的数据,通常位于中等性能存储层。
冷数据层:存储不常用的数据,通常位于低成本存储层。
按地理位置划分:
本地存储层:存储在本地服务器或数据中心的存储设备。
远程存储层:存储在云端或远程数据中心的存储设备。
按管理策略划分:
静态分层:根据预定义的规则将数据分配到不同层次。
动态分层:根据数据的访问模式和使用情况动态调整数据的存储位置。
| 分类维度 | 细分类型 | 包含介质 / 特征 | 典型应用场景 | 技术特点 |
|---|---|---|---|---|
| 按存储介质 | 内存层 | CPU 缓存、DRAM 内存 | 数据库索引、实时计算数据 | 纳秒级访问延迟,容量通常 < 1TB |
| 缓存层 | SSD、NAND Flash | 热点数据缓存、数据库加速 | 微秒级延迟,容量 10TB-100TB,读写速度 > 1000MB/s | |
| 磁盘层 | HDD 机械硬盘 | 在线业务数据、常规存储 | 毫秒级延迟,单盘容量 4TB-20TB,成本约 0.02 美元 / GB | |
| 磁带层 | LTO 磁带、数据流磁带 | 归档备份、冷数据存储 | 秒级访问延迟,单盒容量 15TB-45TB,成本 < 0.001 美元 / GB | |
| 按访问频率 | 热数据层 | 内存 / SSD 介质 | 电商订单实时处理、金融交易数据 | 日均访问 > 10 次,数据生命周期 < 1 个月 |
| 温数据层 | SSD/HDD 混合介质 | 历史订单数据、用户行为日志 | 周均访问 1-10 次,数据生命周期 1-6 个月 | |
| 冷数据层 | HDD / 磁带介质 | 归档合同、备份数据 | 月均访问 <1 次,数据生命周期> 6 个月 | |
| 按地理位置 | 本地存储层 | 数据中心本地服务器存储 | 低延迟业务、核心系统数据 | 延迟 < 1ms,受限于本地机房容量 |
| 远程存储层 | 公有云存储(如 AWS S3)、异地数据中心 | 灾备数据、跨地域共享数据 | 延迟 > 50ms,支持弹性扩展,成本随流量波动 | |
| 按管理策略 | 静态分层 | 基于文件类型 / 创建时间预定义规则 | 医疗影像归档、法律文件存储 | 策略固定,管理简单但灵活性低 |
| 动态分层 | 基于 AI 算法分析访问模式自动调整 | 互联网平台数据、大数据分析系统 | 实时优化存储位置,需消耗额外计算资源 |
五、层次化存储架构的优缺点
优点
性能优化:通过将频繁访问的数据存储在高性能存储层,显著提高了数据访问速度。
成本降低:不常用的数据存储在低成本存储层,降低了整体存储成本。
容量扩展:通过分层存储,可以灵活扩展存储系统的容量,满足大规模数据存储需求。
智能管理:智能管理系统能够自动优化数据存储和访问,减少人工干预。
缺点
复杂性:层次化存储架构的实现和管理较为复杂,需要专业的技术支持。
数据迁移开销:数据在不同层次之间的迁移会带来一定的性能开销和延迟。
管理难度:需要制定合理的存储策略和迁移规则,否则可能导致性能下降或成本增加。
| 分类 | 具体优势 / 劣势 | 技术原理 | 典型案例 / 影响 |
|---|---|---|---|
| 性能优化 | 高频数据存储于高性能层(内存 / SSD) | 缩短数据访问路径,减少 IO 延迟 | 数据库查询速度提升 300%(SSD 对比 HDD) |
| 成本降低 | 低频数据迁移至低成本层(磁带 / HDD) | 利用存储介质成本差(磁带成本≈SSD 的 1/100) | 企业归档数据存储成本降低 75% 以上 |
| 容量扩展 | 分层架构支持异构介质动态扩展 | 按需添加 SSD/HDD/ 磁带层,无统一规格限制 | 云存储服务可扩展至 EB 级容量(如 Amazon S3) |
| 智能管理 | 自动分析访问模式并触发数据迁移 | AI 算法预测数据热度,按策略执行迁移 | 热点数据自动提升至缓存层,命中率提升 60% |
| 复杂性 | 多层架构设计与异构介质管理难度高 | 需协调内存 / SSD/HDD/ 磁带的协同工作机制 | 中小型企业部署成本增加 20-30% |
| 迁移开销 | 数据跨层迁移产生 IO 和计算资源消耗 | 每次迁移需读取源数据并写入目标层 | 大规模迁移可能导致系统响应延迟增加 50ms |
| 管理难度 | 策略制定失误可能导致性能衰减 | 错误迁移规则会导致热点数据滞留冷层 | 某电商因策略缺陷,订单查询延迟增加 200ms |
六、层次化存储架构的案例
Amazon S3
Amazon S3 是亚马逊云服务(AWS)提供的对象存储服务,采用了层次化存储架构。S3 提供了多种存储类别,包括:
- S3 Standard:高性能存储层,适用于频繁访问的数据。
- S3 Standard-IA:中等性能存储层,适用于不频繁访问的数据。
- S3 One Zone-IA:低成本存储层,适用于归档数据。
- S3 Glacier:超低成本存储层,适用于长期归档数据。
Google Cloud Storage
Google Cloud Storage 也采用了层次化存储架构,提供多种存储类别:
- Nearline:适用于不频繁访问的数据。
- Coldline:适用于极少访问的数据。
- Archive:适用于长期归档数据。
IBM Spectrum Scale
IBM Spectrum Scale 是一个分布式文件系统,支持层次化存储架构。它可以根据数据的访问频率自动将数据迁移到不同的存储层,包括内存、SSD、HDD 和磁带。
| 厂商 / 产品 | 存储层级 | 访问频率 | 性能指标 | 成本特点 | 典型应用场景 | 数据持久性 |
|---|---|---|---|---|---|---|
| Amazon S3 | S3 Standard | 高频访问 | 10ms 级延迟,10 万 + IOPS | 0.023 美元 / GB / 月 | 电商网站图片、实时日志数据 | 12 个 9 持久性(99.9999999999%) |
| S3 Standard-IA | 低频访问 | 50ms 级延迟,1 万 + IOPS | 0.0125 美元 / GB / 月(含 IA 费用) | 季度报表、用户历史数据 | 12 个 9 持久性 | |
| S3 One Zone-IA | 归档数据 | 100ms 级延迟 | 0.01 美元 / GB / 月(单可用区) | 测试数据、非关键备份 | 11 个 9 持久性 | |
| S3 Glacier | 长期归档 | 4-12 小时 retrieval | 0.004 美元 / GB / 月 | 法律合规数据、历史档案 | 12 个 9 持久性 | |
| Google Cloud Storage | Nearline | 低频访问(每月 1 次) | 100ms 级延迟 | 0.01 美元 / GB / 月 + 数据检索费 | 大数据分析中间结果、备份数据 | 3 个区域冗余 |
| Coldline | 极少访问(每年 1 次) | 100ms 级延迟 | 0.007 美元 / GB / 月 + 检索费 | 归档邮件、医疗影像历史数据 | 3 个区域冗余 | |
| Archive | 长期归档(每年 < 1 次) | 数小时 retrieval | 0.004 美元 / GB / 月 + 检索费 | 文物数字化档案、历史气象数据 | 3 个区域冗余 | |
| IBM Spectrum Scale | 内存层 | 高频访问 | 纳秒级延迟 | 最高成本层级 | 数据库索引、实时交易数据 | 本地冗余 |
| SSD 层 | 次高频访问 | 微秒级延迟 | 中高成本 | 热点数据缓存、数据分析中间结果 | 本地 / 跨节点冗余 | |
| HDD 层 | 常规访问 | 毫秒级延迟 | 中等成本 | 在线业务数据、文件存储 | 跨数据中心冗余 | |
| 磁带层 | 归档存储 | 秒级访问 | 最低成本 | 备份数据、合规归档 | 异地磁带库冗余 |
七、层次化存储架构整体框架代码举例
class StorageLayer:def __init__(self, name, capacity, cost):self.name = nameself.capacity = capacityself.cost = costself.data = {}def read(self, key):return self.data.get(key)def write(self, key, value):self.data[key] = valueclass HierarchicalStorage:def __init__(self):self.layers = [StorageLayer("Memory", 1024, 10), # 高性能存储层StorageLayer("SSD", 10240, 5), # 中等性能存储层StorageLayer("HDD", 102400, 1) # 低成本存储层]def read(self, key):for layer in self.layers:data = layer.read(key)if data:# 将数据迁移到高性能层self.migrate_to_top_layer(key, data)return datareturn Nonedef write(self, key, value):# 写入到最高性能层self.layers[0].write(key, value)def migrate_to_top_layer(self, key, value):# 将数据从底层迁移到顶层for layer in self.layers[1:]:if key in layer.data:del layer.data[key]self.layers[0].write(key, value)# 示例使用
storage = HierarchicalStorage()
storage.write("data1", "value1")
print(storage.read("data1")) # 从高性能层读取八、未来发展趋势
新兴存储技术:随着存储技术的发展,新兴存储介质(如MRAM、PCM、ReRAM等)将逐步引入层次化存储架构,进一步优化性能和成本。
人工智能与自动化:人工智能和机器学习技术将被广泛应用于层次化存储架构的管理中,实现更智能的数据迁移和存储优化。
分布式与边缘计算:随着分布式存储和边缘计算的普及,层次化存储架构将与分布式系统结合,形成跨地域、跨设备的存储解决方案。
绿色存储:随着环保意识的增强,层次化存储架构将更加注重能源效率和可持续性,推动绿色存储技术的发展。
| 趋势分类 | 技术方向 | 核心技术 | 预期影响 | 成熟度预测 | 代表厂商 / 案例 |
|---|---|---|---|---|---|
| 新兴存储技术 | MRAM(磁阻随机存储器) | 自旋转移矩效应 | 存取速度提升至纳秒级,功耗降低 50% | 2025-2027 年商用 | Everspin、IBM |
| PCM(相变存储器) | 硫系化合物相变原理 | 读写寿命达 10^12 次,密度提升 3 倍 | 2026-2028 年商用 | Intel、Micron | |
| ReRAM(阻变存储器) | 氧化物阻变效应 | 制程兼容 CMOS,成本降低 40% | 2027-2029 年商用 | Crossbar、东芝 | |
| 人工智能管理 | 智能数据迁移 | 深度学习预测模型 | 迁移决策准确率提升至 95%,延迟降低 30% | 2024-2025 年普及 | AWS Storage Lens、微软 StorageIQ |
| 自动策略优化 | 强化学习算法 | 存储成本自动优化幅度达 20-30% | 2025-2026 年成熟 | Google Cloud AutoML Storage | |
| 分布式边缘融合 | 边缘 - 云分层存储 | 5G 边缘计算节点 + 云端归档 | 实时数据处理延迟 < 10ms,带宽节省 40% | 2024-2026 年落地 | 阿里云边缘存储、Azure Stack Edge |
| 联邦存储架构 | 跨地域数据协同协议 | 全球数据同步延迟 < 50ms,容错能力提升 | 2025-2027 年成熟 | IBM Spectrum Fusion、华为 OceanStor | |
| 绿色存储技术 | 低功耗存储介质 | 自旋电子学、相变材料低电压设计 | 单位存储能耗降低至 0.1mW/GB,PUE<1.1 | 2024-2026 年应用 | 希捷 Exos 2X 系列、HPE GreenLake |
| 可再生能源集成 | 光伏储能 + 智能供电管理 | 数据中心碳足迹降低 50%,TCO 减少 15% | 2025-2028 年普及 | AWS Wind Farm、谷歌可再生能源项目 |