day 50
预训练模型+cbam模块
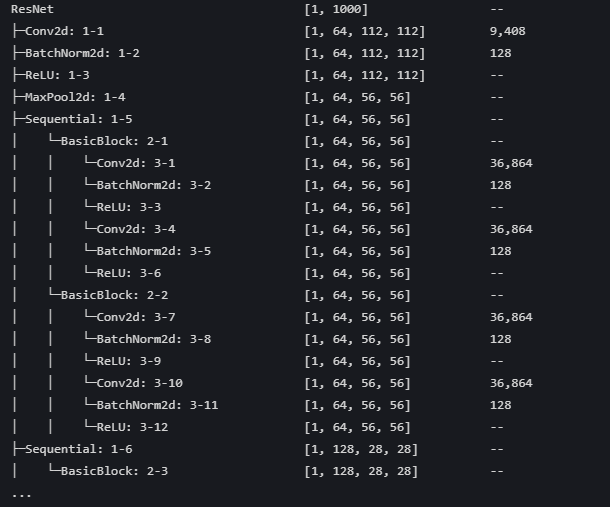
resnet结构
输入预处理:`Conv2d: 1-1` 到 `MaxPool2d: 1-4`
对输入图像进行初步的特征提取,并通过池化操作将特征图尺寸减半,为后续处理做准备。
核心特征提取:四个 `Sequential` 模块 (`1-5` 到 `1-8`)
这是网络的主体,由多个残差块(`BasicBlock`)堆叠而成,负责从浅到深、从粗到细地学习图像特征。
分类输出:`AdaptiveAvgPool2d: 1-9` 和 `Linear: 1-10`
将最终的特征图(feature map)转换成一个特征向量,并通过全连接层映射到最终的 1000 个类别上。
cbam的放置位置
在每一个残差块的输出上应用CBAM注意力
CBAM模块自身的结构——初始状态接近“直通”,这是最核心的技术原因导致可以采用这个结构。CBAM模块的最终操作是:return x * self.sigmoid(attention)。这里的 x 是原始特征;attention 是学到的注意力图。
1. 初始状态分析:在一个模块被随机初始化(还未开始训练)时,其内部的卷积层和全连接层的权重都非常小,接近于0。因此,计算出的 attention 图的值也都会非常接近0。
2. Sigmoid函数的特性:当输入为0时,sigmoid(0) 的输出是 0.5。这意味着在训练刚开始的第一步,CBAM模块的操作近似于 x * 0.5。它并没有用一个完全随机的、混乱的特征图去替换原始特征 x。它只是将原始特征 x 按比例缩小了一半。
缩小0.5只是对特征数值尺度的缩放,它完整地保留了原始特征图中的空间结构和相对关系。下游的预训练层接收到的不再是“垃圾”,而是一个信号稍弱但结构完好的原始特征。这为后续的学习提供了一个非常稳定的起点。
如果CBAM无用:网络可以通过学习,让 attention 图的值都趋近于一个常数,相当于一个固定的缩放。在更理想的情况下,如果能让 attention 图的值都趋近于 sigmoid 函数的反函数中对应输出为1的值,那么CBAM就近似于一个“直通车”(x * 1 = x),网络可以选择“忽略”它。
如果CBAM有用:网络会迅速学会调整权重,让 attention 图中重要的地方值接近1,不重要的地方值接近0,从而实现特征的增强。
所以完全可以在不破坏其核心结构的情况下,将CBAM模块无缝地“注入”到预训练的ResNet中。这样做的逻辑是:
1. 保留原始结构:原始的残差块负责提取核心特征。
2. 增强特征:紧随其后的CBAM模块对这些提取出的特征进行“精炼”,告诉模型应该“关注什么”(what - 通道注意力)和“在哪里关注”(where - 空间注意力)。
3. 不破坏预训练权重:原始残差块的预训练权重得以完整保留,我们只是在其后增加了一个新的、需要从头学习的模块。
import torch
import torch.nn as nn
from torchvision import models# 自定义ResNet18模型,插入CBAM模块
class ResNet18_CBAM(nn.Module):def __init__(self, num_classes=10, pretrained=True, cbam_ratio=16, cbam_kernel=7):super().__init__()# 加载预训练ResNet18self.backbone = models.resnet18(pretrained=pretrained) # 修改首层卷积以适应32x32输入(CIFAR10)self.backbone.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)self.backbone.maxpool = nn.Identity() # 移除原始MaxPool层(因输入尺寸小)# 在每个残差块组后添加CBAM模块self.cbam_layer1 = CBAM(in_channels=64, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer2 = CBAM(in_channels=128, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer3 = CBAM(in_channels=256, ratio=cbam_ratio, kernel_size=cbam_kernel)self.cbam_layer4 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel)# 修改分类头self.backbone.fc = nn.Linear(in_features=512, out_features=num_classes)def forward(self, x):# 主干特征提取x = self.backbone.conv1(x)x = self.backbone.bn1(x)x = self.backbone.relu(x) # [B, 64, 32, 32]# 第一层残差块 + CBAMx = self.backbone.layer1(x) # [B, 64, 32, 32]x = self.cbam_layer1(x)# 第二层残差块 + CBAMx = self.backbone.layer2(x) # [B, 128, 16, 16]x = self.cbam_layer2(x)# 第三层残差块 + CBAMx = self.backbone.layer3(x) # [B, 256, 8, 8]x = self.cbam_layer3(x)# 第四层残差块 + CBAMx = self.backbone.layer4(x) # [B, 512, 4, 4]x = self.cbam_layer4(x)# 全局平均池化 + 分类x = self.backbone.avgpool(x) # [B, 512, 1, 1]x = torch.flatten(x, 1) # [B, 512]x = self.backbone.fc(x) # [B, 10]return x训练策略
1. 阶段 1(epoch 1-5):
仅解冻分类头(fc)和所有 CBAM 模块,冻结 ResNet18 的主干卷积层(layer1-4)。
目标:先让模型通过预训练特征学习新任务的分类边界,同时微调注意力模块。
学习率:1e-3(较高学习率加速分类头收敛)。
阶段 2(epoch 6-20):
解冻高层卷积层(layer3、layer4)+ 分类头 + CBAM,冻结低层卷积层(layer1、layer2)。
目标:释放高层语义特征(如 “物体类别” 相关层),适应新任务的抽象表示。
学习率:1e-4(降低学习率,避免破坏预训练权重)。
阶段 3(epoch 21-50):
解冻所有层(包括低层卷积层 layer1、layer2),端到端微调。
目标:让底层特征(如边缘、纹理)与新任务对齐,提升特征表达能力。
学习率:1e-5(最小学习率,缓慢调整全局参数)。
2. CBAM 模块集成
在每个残差块组(layer1-4)输出后添加 CBAM,确保注意力机制作用于各阶段特征图,且不影响残差块内部的跳连接。
CBAM 参数默认使用ratio=16和kernel_size=7,可根据计算资源调整(如减小ratio以降低参数量)。
3. 学习率与优化器
使用Adam优化器,分阶段手动调整学习率(也可配合自动调度器如CosineAnnealingLR)。
每次解冻新层时,学习率降低一个数量级,避免梯度冲击预训练权重。
import time# ======================================================================
# 4. 结合了分阶段策略和详细打印的训练函数
# ======================================================================
def set_trainable_layers(model, trainable_parts):print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}")for name, param in model.named_parameters():param.requires_grad = Falsefor part in trainable_parts:if part in name:param.requires_grad = Truebreakdef train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs):optimizer = None# 初始化历史记录列表,与你的要求一致all_iter_losses, iter_indices = [], []train_acc_history, test_acc_history = [], []train_loss_history, test_loss_history = [], []for epoch in range(1, epochs + 1):epoch_start_time = time.time()# --- 动态调整学习率和冻结层 ---if epoch == 1:print("\n" + "="*50 + "\n🚀 **阶段 1:训练注意力模块和分类头**\n" + "="*50)set_trainable_layers(model, ["cbam", "backbone.fc"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)elif epoch == 6:print("\n" + "="*50 + "\n✈️ **阶段 2:解冻高层卷积层 (layer3, layer4)**\n" + "="*50)set_trainable_layers(model, ["cbam", "backbone.fc", "backbone.layer3", "backbone.layer4"])optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)elif epoch == 21:print("\n" + "="*50 + "\n🛰️ **阶段 3:解冻所有层,进行全局微调**\n" + "="*50)for param in model.parameters(): param.requires_grad = Trueoptimizer = optim.Adam(model.parameters(), lr=1e-5)# --- 训练循环 ---model.train()running_loss, correct, total = 0.0, 0, 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录每个iteration的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append((epoch - 1) * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 按你的要求,每100个batch打印一次if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_loss_history.append(epoch_train_loss)train_acc_history.append(epoch_train_acc)# --- 测试循环 ---model.eval()test_loss, correct_test, total_test = 0, 0, 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_loss_history.append(epoch_test_loss)test_acc_history.append(epoch_test_acc)# 打印每个epoch的最终结果print(f'Epoch {epoch}/{epochs} 完成 | 耗时: {time.time() - epoch_start_time:.2f}s | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 训练结束后调用绘图函数print("\n训练完成! 开始绘制结果图表...")plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)# 返回最终的测试准确率return epoch_test_acc@浙大疏锦行