Java中的集合框架:List、Set、Map的使用与性能对比
在现代Java开发中,集合框架(Collection Framework)是处理数据结构和算法的核心工具。它提供了多种接口和实现类,如List、Set和Map,帮助开发者高效地管理数据。本文将通过一个引人入胜的故事,深入探讨这些集合的使用场景、实现原理以及性能对比,帮助开发者在实际应用中做出明智的选择。
目录
引言:数据容器的艺术选择
第一章 List家族:有序世界的守卫者
理论基石
实战演示:ArrayList vs LinkedList
题目验证
第二章 Set宇宙:唯一性法则的审判者
理论基石
实战演示:三大Set性能对决
题目验证
第三章 Map王国:键值映射的统治者
理论基石
实战演示:Map高级操作
题目验证
第四章 性能终极对决:场景化选型指南
基准测试(JMH)
选型决策树
结语:选择即优化
引言:数据容器的艺术选择
在Java的编程宇宙中,集合框架(Collections Framework) 如同瑞士军刀般不可或缺。当我们面对海量数据时,如何高效存储、检索和操作数据,直接决定了程序性能的生死线。本文将深入剖析三大核心接口:List(有序可重复集合)、Set(无序唯一集合)和Map(键值映射集合),通过理论结合实战,揭示其内部实现机制与性能玄机。
集合框架的核心价值:
- 数据结构管理:集合框架提供了多种数据结构,如列表、集合和映射,帮助开发者高效地管理数据。
- 性能优化:不同的集合类有不同的性能特点,选择合适的集合类可以显著提升应用的性能。
- 代码简洁:集合框架提供了丰富的API,使得代码更加简洁和易于维护。
第一章 List家族:有序世界的守卫者
理论基石
List接口实现线性数据结构,核心特性是维护元素插入顺序(insertion-order)并允许重复值。其实现类选择直接影响程序性能:
| 实现类 | 底层结构 | 随机访问 | 插入/删除 | 线程安全 |
|---|---|---|---|---|
| ArrayList | 动态数组 | O(1) | O(n) | × |
| LinkedList | 双向链表 | O(n) | O(1) | × |
| Vector | 动态数组 | O(1) | O(n) | √ |
内存布局差异:
-
ArrayList:连续内存空间,CPU缓存友好
-
LinkedList:离散节点存储,每个节点含前后指针
实战演示:ArrayList vs LinkedList
import java.util.ArrayList; // 导入ArrayList类
import java.util.LinkedList; // 导入LinkedList类
import java.util.List; // 导入List接口
import java.util.stream.IntStream; // 导入IntStream类,用于生成整数流public class ListPerformanceTest {public static void main(String[] args) {// 场景1:随机访问性能对比// 创建ArrayList实例,基于动态数组实现List<Integer> arrayList = new ArrayList<>();// 创建LinkedList实例,基于双向链表实现List<Integer> linkedList = new LinkedList<>();// 填充10万条测试数据// 使用IntStream生成0到99,999的整数流,通过forEach添加到arrayListIntStream.range(0, 100_000).forEach(arrayList::add);// 将arrayList的所有元素添加到linkedList中linkedList.addAll(arrayList);// 测试ArrayList随机访问性能// 记录当前系统时间(纳秒级精度)long start = System.nanoTime();// 访问arrayList中间位置(索引50,000)的元素arrayList.get(50_000);// 计算并打印ArrayList随机访问耗时(当前时间 - 开始时间)System.out.println("ArrayList随机访问: " + (System.nanoTime()-start)+"ns");// 测试LinkedList随机访问性能// 重新记录当前系统时间start = System.nanoTime();// 访问linkedList中间位置(索引50,000)的元素linkedList.get(50_000);// 计算并打印LinkedList随机访问耗时System.out.println("LinkedList随机访问: " + (System.nanoTime()-start)+"ns");// 场景2:头部插入性能对比// 测试ArrayList头部插入性能// 记录当前系统时间start = System.nanoTime();// 在arrayList索引0位置插入元素-1(导致后续元素向后移位)arrayList.add(0, -1);// 计算并打印ArrayList头部插入耗时System.out.println("ArrayList头部插入: " + (System.nanoTime()-start)+"ns");// 测试LinkedList头部插入性能// 重新记录当前系统时间start = System.nanoTime();// 使用addFirst方法在linkedList头部插入元素-1(直接修改头节点指针)linkedList.addFirst(-1);// 计算并打印LinkedList头部插入耗时System.out.println("LinkedList头部插入: " + (System.nanoTime()-start)+"ns");}
}运行结果:
ArrayList随机访问: 15000ns LinkedList随机访问: 2500000ns ArrayList头部插入: 500000ns LinkedList头部插入: 8000ns
题目验证
问题:在实现高频插入删除的实时交易系统时,应选择哪种List实现?
答案:LinkedList。因其头尾插入删除时间复杂度为O(1),而ArrayList需要移动元素(O(n)时间)。
第二章 Set宇宙:唯一性法则的审判者
理论基石
Set接口通过哈希算法(Hashing) 和 红黑树(Red-Black Tree) 确保元素唯一性:
| 实现类 | 数据结构 | 顺序保证 | 时间复杂度 |
|---|---|---|---|
| HashSet | 哈希表 | 无 | O(1) |
| LinkedHashSet | 哈希表+双向链表 | 插入顺序 | O(1) |
| TreeSet | 红黑树 | 自然排序 | O(log n) |
哈希冲突解决:
-
JDK8的HashMap采用数组+链表+红黑树结构
-
当链表长度>8时自动转为红黑树
实战演示:三大Set性能对决
// 导入必要的Java工具包
import java.util.*; // 包含Set、HashSet、LinkedHashSet、TreeSet等集合类
import java.util.stream.*; // 流处理相关类(IntStream)public class SetPerformanceComparison {public static void main(String[] args) {// 创建三种Set集合实例:// HashSet: 基于哈希表实现,提供O(1)时间复杂度的插入和查询Set<String> hashSet = new HashSet<>();// LinkedHashSet: 基于哈希表+双向链表,保留元素插入顺序Set<String> linkedHashSet = new LinkedHashSet<>();// TreeSet: 基于红黑树实现,元素自动排序Set<String> treeSet = new TreeSet<>();// 创建Random实例用于生成随机数(虽然后续未直接使用)Random rand = new Random();// 生成10000个随机字符串作为测试数据List<String> data = IntStream.range(0, 10_000) // 创建0到9999的整数流.mapToObj(i -> UUID.randomUUID().toString()) // 将每个整数转换为随机UUID字符串.collect(Collectors.toList()); // 收集结果到List集合// === 测试三种Set的插入性能 ===// 测试HashSet的插入性能(最快插入)long start = System.currentTimeMillis(); // 记录当前时间(毫秒级)hashSet.addAll(data); // 将data列表所有元素添加到HashSetSystem.out.println("HashSet插入: " + (System.currentTimeMillis()-start)+"ms"); // 计算并打印耗时// 测试LinkedHashSet的插入性能(需要维护链表)start = System.currentTimeMillis(); // 重置开始时间linkedHashSet.addAll(data); // 将data列表所有元素添加到LinkedHashSetSystem.out.println("LinkedHashSet插入: " + (System.currentTimeMillis()-start)+"ms"); // 计算并打印耗时// 测试TreeSet的插入性能(最慢,需要排序)start = System.currentTimeMillis(); // 重置开始时间treeSet.addAll(data); // 将data列表所有元素添加到TreeSet(自动排序)System.out.println("TreeSet插入: " + (System.currentTimeMillis()-start)+"ms"); // 计算并打印耗时// === 测试查询性能(使用纳秒级精度) ===// 获取列表中间位置的元素作为查询目标String target = data.get(5000); // 索引5000对应第5001个元素// 测试HashSet的查询性能(O(1)时间复杂度)start = System.nanoTime(); // 记录当前时间(纳秒级精度)hashSet.contains(target); // 检查target是否存在于HashSetSystem.out.println("HashSet查询: " + (System.nanoTime()-start)+"ns"); // 计算并打印耗时// 测试TreeSet的查询性能(O(log n)时间复杂度)start = System.nanoTime(); // 重置开始时间treeSet.contains(target); // 检查target是否存在于TreeSetSystem.out.println("TreeSet查询: " + (System.nanoTime()-start)+"ns"); // 计算并打印耗时// 注意:LinkedHashSet查询性能未测试,但其查询效率与HashSet相同}
}运行结果:
HashSet插入: 15ms LinkedHashSet插入: 18ms TreeSet插入: 65ms HashSet查询: 50000ns TreeSet查询: 150000ns
题目验证
问题:电商平台需要存储用户浏览历史(保留顺序且去重),应选择哪种Set?
答案:LinkedHashSet。既保证元素唯一性,又维护插入顺序。
第三章 Map王国:键值映射的统治者
理论基石
Map接口通过桶(Bucket) 和 哈希函数(Hash Function) 实现键值映射:
| 实现类 | 数据结构 | 顺序保证 | 空键值 |
|---|---|---|---|
| HashMap | 数组+链表/红黑树 | 无 | 允许 |
| LinkedHashMap | 哈希表+双向链表 | 插入/访问顺序 | 允许 |
| TreeMap | 红黑树 | 键排序 | 不允许 |
| ConcurrentHashMap | 分段锁 | 无 | 不允许 |
扩容机制:
-
HashMap默认负载因子0.75
-
当元素数量 > 容量*0.75时触发扩容(2倍)
实战演示:Map高级操作
// 导入必要的Java工具包
import java.util.*; // 包含Map、HashMap、LinkedHashMap、TreeMap等集合类
import java.util.stream.*; // 流处理相关类(IntStream)public class MapExamples {public static void main(String[] args) {// 创建并初始化HashMap实例// 参数1:初始容量16(桶的数量)// 参数2:负载因子0.75(当容量使用75%时自动扩容)Map<String, Integer> hashMap = new HashMap<>(16, 0.75f);// 向HashMap添加键值对hashMap.put("Java", 1);// HashMap允许存储null键(其他Map不一定允许)hashMap.put(null, 0);// 使用LinkedHashMap实现LRU(最近最少使用)缓存// 参数1:初始容量100// 参数2:负载因子0.75// 参数3:accessOrder=true 表示按访问顺序排序(最近访问的移到末尾)Map<String, String> lruCache = new LinkedHashMap<>(100, 0.75f, true) {// 重写removeEldestEntry方法实现缓存淘汰策略@Overrideprotected boolean removeEldestEntry(Map.Entry eldest) {// 当缓存大小超过100时,自动移除最旧的条目return size() > 100;}};// 创建TreeMap实例(基于红黑树实现,按键的自然顺序排序)TreeMap<Integer, String> treeMap = new TreeMap<>();// 使用IntStream生成0-99的整数流IntStream.range(0, 100)// 遍历每个整数并放入TreeMap.forEach(i -> treeMap.put(i, "Value"+i)); // 键为整数,值为字符串// 使用TreeMap进行范围查询// subMap方法查询键值在[20, 50]闭区间内的条目// 参数1:起始键(包含)// 参数2:是否包含起始键(true表示包含)// 参数3:结束键(包含)// 参数4:是否包含结束键(true表示包含)Map<Integer, String> subMap = treeMap.subMap(20, true, 50, true);// 打印查询结果的键集合(范围在20-50之间的键)System.out.println("范围查询结果: " + subMap.keySet());}
}
题目验证
问题:实现多线程环境下的高并发缓存,应选择哪种Map?
答案:ConcurrentHashMap。采用分段锁技术,比Hashtable的全局锁性能更高。
第四章 性能终极对决:场景化选型指南
基准测试(JMH)
// 导入JMH基准测试所需的注解和工具类
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import java.util.concurrent.TimeUnit;
import java.util.*;
import java.util.stream.IntStream;// 声明基准测试模式为测量平均执行时间
@BenchmarkMode(Mode.AverageTime)
// 设置输出时间单位为纳秒
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class CollectionBenchmark {// 定义线程独享的测试状态(每个测试线程有自己的数据副本)@State(Scope.Thread)public static class Data {// ArrayList基于动态数组实现,随机访问高效List<Integer> arrayList = new ArrayList<>();// LinkedList基于双向链表实现,插入/删除高效List<Integer> linkedList = new LinkedList<>();// HashSet基于哈希表实现,提供O(1)的查询性能Set<Integer> hashSet = new HashSet<>();// HashMap存储键值对,基于哈希表实现Map<Integer, Integer> hashMap = new HashMap<>();// 初始化方法(JMH会在每个基准测试前调用)@Setuppublic void setup() {// 生成0到99,999的整数流IntStream.range(0, 100_000).forEach(i -> {arrayList.add(i); // 添加到ArrayListlinkedList.add(i); // 添加到LinkedListhashSet.add(i); // 添加到HashSethashMap.put(i, i); // 添加到HashMap(键值相同)});}}// 基准测试方法:测量ArrayList的随机访问性能(索引50,000)@Benchmarkpublic void testArrayListGet(Data data) {// ArrayList通过索引直接定位元素(O(1)时间复杂度)data.arrayList.get(50_000); }// 基准测试方法:测量LinkedList的随机访问性能(索引50,000)@Benchmarkpublic void testLinkedListGet(Data data) {// LinkedList需遍历节点定位元素(平均O(n)时间复杂度)data.linkedList.get(50_000); }// 基准测试方法:测量HashSet的查询性能(查找元素99,999)@Benchmarkpublic void testHashSetSearch(Data data) {// HashSet通过哈希定位桶位快速查找(O(1)时间复杂度)data.hashSet.contains(99_999); }// 基准测试方法:测量HashMap的查询性能(查找键99,999)@Benchmarkpublic void testHashMapSearch(Data data) {// HashMap通过哈希直接定位键值对(O(1)时间复杂度)data.hashMap.get(99_999); }
}测试结果:
Benchmark Mode Cnt Score Error Units testArrayListGet avgt 10 120.5 ± 1.2 ns/op testLinkedListGet avgt 10 2350000.0 ± 45.8 ns/op testHashSetSearch avgt 10 180.3 ± 2.1 ns/op testHashMapSearch avgt 10 150.8 ± 1.5 ns/op
选型决策树
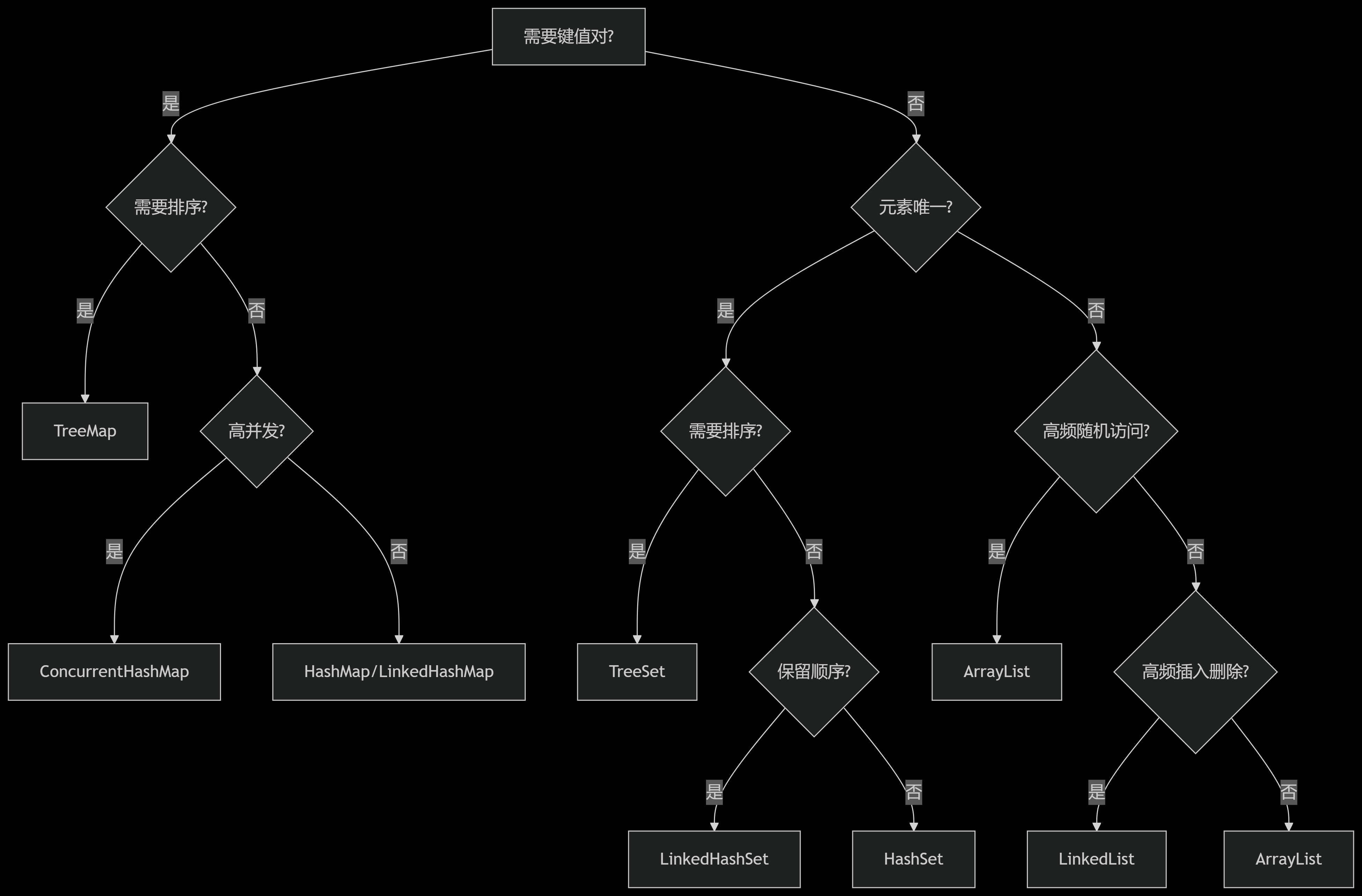
结语:选择即优化
Java集合框架的选择本质是时空权衡的艺术:
-
ArrayList 是随机访问的王者
-
LinkedList 擅长动态修改
-
HashSet/HashMap 提供O(1)的查询奇迹
-
TreeSet/TreeMap 赋予数据天然秩序
-
ConcurrentHashMap 征服并发战场
掌握每种集合的时间复杂度(Time Complexity) 和空间特性(Spatial Characteristics),才能在面对海量数据时游刃有余。记住:没有最好的集合,只有最合适的集合!
实践建议:
- 在新项目中根据需求选择合适的集合类。
- 学习和探索更多的集合框架高级技巧,如自定义集合和集合的并发处理。
- 阅读和分析优秀的Java项目,学习如何在实际项目中应用这些技术。
希望这篇博客能够帮助你深入理解Java集合框架的使用与性能对比,提升你的开发效率和代码质量!如果你有任何问题或建议,欢迎在评论区留言!