PosterSQL日常维护
基本使用
登录数据库
Pgsql登录时,必须使用postgres用户,登录后命令提示符魏 “postgres=#” postgres表示你当期那所在的库。
[root@bogon ~]# su - postgres
[postgres@bngon ~]# /usr/local/pgsql/bin/sql
psql (16.3)
Type "hulp" for help.postgres=#数据库操作
列出库
常用的三种方法如下:
方法一
postgres=#\l在PostgresSQL 的交互式终端psql中, “\” 开头的命令称为元命令(类似MySQL的show语句),用于快速管理数据库。常用元命令有:
| 命令 | 功能描述 | 示例 |
|---|---|---|
|
| 列出所有数据库 | \l |
|
| 连接到指定数据库 | \c mydatabase |
|
| 连接到指定数据库(与 \c 等效) | \connect mydatabase |
|
| 列出所有模式(Schemas) | \dn |
|
| 列出所有表空间 | \db |
|
| 显示 psql 元命令帮助 | \? |
|
| 退出 psql 会话 | \q |
|
| 列出当前数据库的所有表 | \dt |
|
| 列出指定模式下的所有表 | \dt public.* |
|
| 查看指定表的详细结构 | \d users |
|
| 查看表的详细结构(包含更多信息) | \d+ products |
|
| 列出所有用户和角色 | \du |
|
| 查看 SQL 命令的语法帮助 | \h SELECT |
|
| 执行 SQL 文件 | \i /path/to/script.sql |
|
| 在编辑器中打开当前 SQL 命令 | \e |
\dv | 列出所有视图 | \dv |
\df | 列出所有函数 | \df |
\di [表名] | 查看表的索引 | \di orders |
\da | 列出所有聚合函数 | \da |
\pset [选项] | 设置输出格式(如 \pset format aligned) | \pset format aligned |
方法二:
使用SQL命令
postgres=# select datname from pg_database;pg_database 是系统表:他储存了PostgreSQL 实力中所有的元信息(如数据库名称、所有者、编码等)。属于系统目录(system Catalog ):类似MySQl的information_schema,但 PostgrsSQL 的系统目录更底层且直接储存在pg_catalog模式中。
pg_database 是系统表,所以无论当链接那个数据库,该表始终可见系统表默认属于 pg_catalog模式,而pg_catalog始终位于搜索路径(search_path)的首位。因此,查询时无需指定模式(如 pg_catalog.pg_database)。
创建库
postgres=# create database mydb;
CREATE DATABASE删除库
postgres=# \c mydb
DROP DATABASE切换库
postgres=# \c mydb
You are now connected to database "mydb" as user "postgres".
mydb=#查看库大小
函数以字节为单位返回数据的大小
postgres=# selecl pg_size_prettty(pg_database_size('mydb'));
pg_database_size
------------------7594499
(1 行记录)
pg_size_pretty() #函数将字节装维更容易阅读值
postgres=# selsct pg_size_pretty(pg_database_size('mydb'));
pg_size_pretty
------------------7417 kB
(1 行记录)数据表操作
列出表
列出表的常用方法:
mydb=# \dt;列出表(显示search_path中模式里的表,默认public)
mydb=# \d;列出表视图和序列
mysb=# \d+;mydb=# \dt my_schema.*列出制定模式下的表(例如 my_schema)
mydb=# \dt *.*查看当前数据库的所有表(包括系统表)
mydb=# select * from pg_table where schmaname = 'public';使用SLQL方式列出当前数据库中 public 模式下所有表及其详细信息pg_tables 是视图: 属于 pg_catalog 模式,但它是基于 pg_class 和pg_namespace 的逻辑视图,并费物理表。无需切换数据库,直接查询pg_catalog.pg_tables 即可获取数据库的表信息
创建表
PostgrsSQL支持标准的SQL类型int、 smallint、real、double precision、char(N)、varchar(N)、data、time、timestamp和interval,还支持其他的通用功能的类型和丰富的几何类型。PostgreSQL中可以定制任意数量的用户定义数据类型。因而类型名并不是语法关键字,除了SQL标准要求的支持例外。
postgres=# cerate table test(id int,name char(10),age int);
CREATE TABLE复制表
要将已有的 table_name 表复制为新表 naw_table,包括表结构和数据,请使用以下语句
create table new_table as table table_name;例如:
postgres+# create table test2 as table test;
SELECT 0
postgres=# \dt关联列表
架构模式 | 名称 | 类型 | 拥有者
---------+---------+---------+----------
hr |employes | 数据表 | postgres
hr |test | 数据表 | postgres
hr |test2 | 数据表 | postgres
(3 行记录)删除表
postgres=# drop table test2;查看表结构
postgres=# \d trst;数据表"hr.test"栏位 | 类型 | 校规规则 | 可空的 | 预设
------+----------------+---------+--------+------
id | integer | | |
name | character (10) | | |
age | integer | | |模式操作命令
在PostgreSQL 中,模式(SChema) 是一个逻辑容器,用于组织和管理数据库对象(如表、视图 、函数、索引等)。它类似文件系统中的文件夹,帮助你在同一个数据库中储存不同的对象,避免命名冲突,并实现权限隔离
创建模式
在当前库postgres 中创建名为 hr 的模式
postgres=# create schema hr;
CREATE SCHEMA默认模式
PostgreSQL 每个数据库都有一个默认模式public。如果创建对象(表、视图等)时不能指定模式,弄人会放在public模式中
通过search_path参数可以设置模式的搜索优先级(类似PATH环境变量):
postgres=# show search_path;search_path
------------------
"$user", pubilc
(1 行记录)search_path 用于控制对象解析顺序,避免酶促查询都要写模式名
$user,public 表示优先查找当前用户同名模式,再找public 模式。
删除模式
删除空模式
postgres=# drop schema hr;
DROP SCHEMA墙纸删除模式及其所有对象
postgres=# \dn架构模式列表名称 | 拥有者
--------+-------------------
public | pg_database_owner
(1 行记录)SQL查询,列出当前苦衷所有模式
postgres=# select shema_name from information_schemata;schema_name
--------------------
information_schema
pg_catalog
pg_toast
public
(4 行记录)在制定模式中创建表
未指定模式时,创建的对象(表,视图等)会按照search_path 孙旭创建到第一个可用的模式中
在postgres库中的hr模式下创建一个名为employees的库
postgres=# vreate hr.employees (id serial primary key,name text);切换当前模式
切换到单个 schema
set search_path to new_schema;切换到多个schema(按优先级顺序)
set search_path to hr,public;表示优先级搜索hr模式,其次public
查看当前所在schema
postgres=# selsct surent_schema();current_schema
----------------
hr
(1 行记录)查看搜索路径(Search Path)
postgres=# show search_path;search_path
--------------
hr, public
(1 行记录)PostgreSQL的模式隔离性
PostreSQL 的模式是数据库内的逻辑分组,不同模式可以在同名比表。这也是和mysql的不同之处
跨模式查询需显示指定模式名(如 schemal. users),或通过search_path 设置默认模式
无需切换数据库连接,所有操作在同一数据库内完成
创建一个数据库
创建数据库mydb
postgres=# create database mydb;切换到mydb
postgres=# \c mydb在数据库中创建两个模式
创建模式schema1 和 schema2
mydb=# create schema schema1;
mydb=# create schema schema2;在每个模式中创建同名表,并插入数据
在schema1 中创建users表
mydb=# creath table schema2.users (id int);
mydb=# insert into schemal.users values(1);在schema1 中创建同名users表
mydb=# create table schema2.users (id int);
mydb=# insert into schema2.users valuse(2);跨模式查询
查询schema1.users 和 schema2.users (需要制定模式名命名)
mydb=# select * from schema1.users;
mydb=# secect * from schema2.users;设置search.users_path 切换默认模式(不许呀制定模式名)
mydb=# set search_path to schemal;
mydb=# select * from users; --默认访问schema1.usersmydb=# set search_path to schema2;
mydb=# select * from users; --默认访问schema2.users数据操作
添加数据
在postgres库,新建表test
postgres=# create table teat (id int,name char(10),age int);
CREATE TABLE
postgres=# insert into test caluse(1,'zhangsan' ,18);
INSERT 0 1查询数据
postgres=# select * from test;id | name | age
----+-------------+------
1 | zhangsan | 18
(1 行记录)修改数据
postgres=# update test set age=20 where id=1;
UPDATE 1
postgres=# select * from test;id | name | age
---+-------------+-----
1 | zhangsan | 20
(1 行记录)删除数据库
mydb=# delet from test where id=1;
DELETE 1
mydb=# select * from test;id | name | age
------+-------------+------
(0 行记录)备份与恢复
| 备份方法 | 描述 | 优点 | 缺点 | 常用命令/工具 |
|---|---|---|---|---|
| SQL 转储 | 使用 pg_dump 或 pg_dumpall 生成 SQL 脚本或归档文件,包含数据库结构和数据。 | - 可恢复单个表或数据库 - 跨版本兼容性好 - 支持压缩和自定义导出格式 | - 大型数据库备份较慢 - 恢复时需重新执行 SQL,可能耗时较长 | pg_dump -U user -d dbname -f backup.sql |
| 文件系统级备份 | 直接复制 PostgreSQL 的数据目录文件(需确保数据库处于一致状态)。 | - 备份速度快 - 适合大型数据库 | - 需停止服务或使用快照 - 恢复时需保持相同 PostgreSQL 版本和配置 | rsync 或文件系统快照工具(如 LVM、ZFS) |
| 连续归档 | 结合 WAL(预写式日志)归档和基础备份,支持时间点恢复(PITR)。 | - 支持增量备份 - 可精确恢复到任意时间点 - 几乎不影响生产性能 | - 配置复杂 - 需要额外存储空间管理 WAL 文件 | pg_basebackup + archive_command 配置 |
6.1 SQL转储
• c(自定义归档)• d(目录格式)• t(tar 格式) | pg_dump -F c dbname -f backup.dump | |
| 压缩输出 | 直接压缩备份文件(-Z 选项) | pg_dump dbname | gzip > backup.sql.gz |
| 指定表/模式 | 仅备份特定表或模式: • -t table(单表)• -n schema(整个模式) | pg_dump -t users -t orders dbname > partial.sql |
| 远程备份 | 从远程服务器备份(-h 主机,-p 端口) | pg_dump -h 192.168.1.100 -p 5432 dbname > remote_backup.sql |
| 认证方式 | 指定用户名(-U)或使用环境变量(PGUSER) | pg_dump -U postgres dbname > backup.sql |
| 并行备份 | 使用多线程加速(-j 选项,仅适用于 -F d 目录格式) | pg_dump -F d -j 4 dbname -f backup_dir |
| 仅结构/仅数据 | 选择性备份: • -s(仅结构)• -a(仅数据) | pg_dump -s dbname > schema_only.sql |
| 恢复备份 | 使用 psql 或 pg_restore(取决于备份格式) | psql -U postgres -d newdb < backup.sqlpg_restore -d newdb backup.dump |
从转储中恢复
| 类别 | 说明 | 示例 |
|---|---|---|
| 基本恢复(SQL 格式) | 使用 psql 恢复纯文本 SQL 备份 | psql -U postgres -d dbname < backup.sql |
| 强制错误停止 | 遇到错误时停止恢复(ON_ERROR_STOP) | psql --set ON_ERROR_STOP=on -d dbname < backup.sql |
| 事务模式恢复 | 将整个恢复作为单个事务(失败则完全回滚) | psql -1 -d dbname < backup.sql |
| 恢复自定义/目录格式 | 使用 pg_restore 恢复非纯文本备份(如 -F c、-F d 格式) | pg_restore -U postgres -d dbname backup.dump |
| 跨服务器直接恢复 | 通过管道直接从源服务器转储并恢复到目标服务器 | pg_dump -h host1 dbname | psql -h host2 dbname |
| 恢复前准备 | 需手动创建空数据库(建议基于 template0) | createdb -T template0 -U postgres dbname |
| 恢复后优化 | 执行 ANALYZE 更新统计信息 | psql -U postgres -c "ANALYZE;" dbname |
| 权限与用户要求 | 恢复前需确保原用户和权限已存在,否则对象归属可能丢失 | 需提前创建用户:CREATE ROLE original_owner LOGIN; |
| 部分恢复选项 | 选择性恢复表或数据(仅适用于 pg_restore) | pg_restore -t table_name -d dbname backup.dump |
使用 pg_dumpall
| 类别 | 说明 | 示例 |
|---|---|---|
| 基本用法 | 备份整个 PostgreSQL 集群(所有数据库 + 全局对象) | pg_dumpall > full_backup.sql |
| 仅备份全局对象 | 只备份角色、表空间等集群级信息(不包含数据库数据) | pg_dumpall --globals-only > globals.sql |
| 恢复整个集群 | 使用 psql 恢复完整集群备份(需超级用户权限) | psql -f full_backup.sql postgres |
| 备份到自定义文件 | 指定输出文件路径 | pg_dumpall -f /path/to/backup.sql |
| 包含表空间定义 | 备份时会包含表空间信息(需确保目标服务器路径匹配) | 自动包含,恢复时需检查路径有效性 |
| 并行备份(间接) | 通过结合 pg_dump 并行备份单个数据库(pg_dumpall 本身不支持并行) | 需手动编写脚本结合 pg_dump -j N |
| 过滤系统对象 | 排除系统数据库(如 template0、template1) | pg_dumpall --exclude-database="template*" |
| 压缩备份 | 直接生成压缩备份 | pg_dumpall | gzip > full_backup.sql.gz |
| 恢复后验证 | 检查恢复的数据库和全局对象 | psql -c "\l" 和 psql -c "\du" |
远程链接
修改PostgreSQL 监听地址
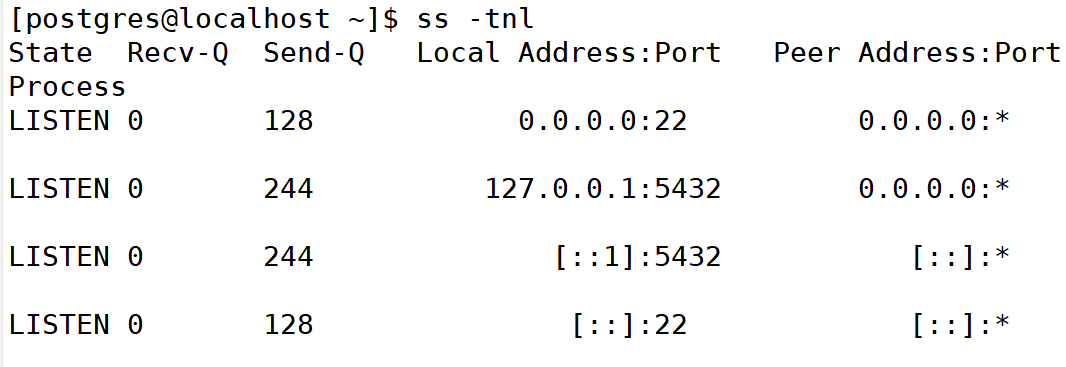
默认 PostgreSql 监听的地址是 127.0.0.1,别的机器无法远程连接上,所以需要调整,修改 postgresql.conf 文件。
通过 dnf 安装的pgsql配置文件在
/var/lib/pgsql/data/postgresql.conf
通过源码编译安装的 pgsql配置文件在
/usr/local/pgsql/data/postgresql.conf
下面操作以 dnf 安装为例:
更改第60行,取消注释并把localhost改成*
listen_addresses = '*'
重启服务
![]()
配置访问权限
默认是只能本地访问 PostgreSQ 的,我们需要在 pg_hba.conf 里面配置
找到 IPv4 local connections 这一行,在这一行下面添加
hostall all 0.0.0.0/0 trust
![]()

配置项 含义说明
host 指定连接类型,host 表示适用于 TCP/IP 远程连接;本地连接常用 local
all(数据库规则) 定义规则适用的数据库范围,all 表示所有数据库,也可指定如 mydatabase 等特定数据库名
all(用户规则) 定义规则适用的用户范围,all 表示所有用户,也可指定如 myuser 等特定用户名
0.0.0.0/0 定义可接受规则的客户端 IP 地址或范围,0.0.0.0/0 表示任意 IP 地址(无限制 ),也可指定具体 IP(如 192.168.1.100 )或网段(如 192.168.1.0/24 )
trust 认证方法,trust 表示无需密码等认证可直接连接,仅适合本地 / 受信网络环境(开发、测试场景 ),生产环境建议用更安全的如 scram-sha-256 等认证方式
如果不是设置的trust,而是选择了md5或password之类的,需要有密码才行,配置 PostgreSQL密码流程如下
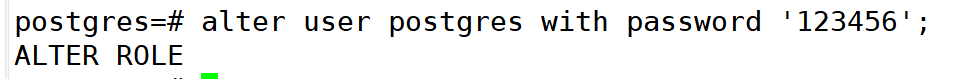
重启服务
[root@localhost]#systemctl start postgresql验证远程连接
使用其它主机远程连接本机数据库,设置的是trust,无密码,可直接登录
[postgres@localhost~]$ psql -h 192.168.10.101
psql(16.3,server 15.12)
Type "help" for help.
postgres=#如果设置的是 md5 或 password 之类的需要有密码才行
[postgres@localhost ~]$ psql -h 192.168.10.101
Password for user postgres:
psql(16.3,server 15.12)
Type "help" for help.postgres=#重置密码
在 PostgreSQL 中如果密码忘记了怎么重置密码
8.1备份配置文件
对 pg_hba.conf 文件,进行备份
[root@localhost ~]# vim /var/lib/pgsql/data/postgresql.conf
# IPv4 local connections:
host all al1 127.0.0. 1/32 trust
host all all 0.0.0.0/0 md5重启服务
[root@localhost ~]# systemctl restart postgresql修改密码
登录数据库修改密码,密码自定义
postgres=# ALTER USER postgres WITH PASSWORD 'new_password';
ALTER ROLEpostgres=# ALTER USER postgres WITH PASSWORD 'new_password';
ALTER ROLE恢复 pg_hba.conf 配置文件
将 postgresql.confbak 文件的内容覆盖 pg_hba.conf,重启 PostgreSQlL数据库服务器,重新登陆时,如果提示输入密码,则输入刚才修改的密码即可
对象型数据库与实体关系型数据库的比较与选择
对象型数据库(Object-Oriented Database, OODB)的定义
对象型数据库是一种基于面向对象编程模型的数据库管理系统,它将数据和操作数据的方法(函数或过程)封装为一个完整的 “对象”,并按照面向对象的概念(如类、继承、多态等)组织和管理数据。
- 核心思想:直接存储和管理对象(如编程语言中的对象实例),避免传统关系型数据库中 “对象 - 关系” 映射的复杂性,适用于处理复杂数据结构(如图形、多媒体、复杂业务逻辑等)
对象型数据库的主要特征
面向对象的数据模型
- 对象封装:数据(属性)和操作(方法)被封装在对象中,例如一个 “学生” 对象包含姓名、年龄等属性,以及计算成绩的方法。
- 类与继承:通过 “类” 定义对象的模板,子类可继承父类的属性和方法,减少代码冗余。例如,“本科生” 类继承 “学生” 类的基本属性,并添加特有的属性(如专业方向)。
- 多态性:不同类的对象可对同一消息(方法调用)做出不同响应,提高系统灵活性。
支持复杂数据类型
- 可直接存储非结构化或半结构化数据,如文本、图像、音频、视频、嵌套对象(对象中包含其他对象)等,无需转换为关系型数据库的二维表结构。
强类型与模式动态性
- 强类型:对象的属性和方法在类定义中严格声明,确保数据一致性。
- 模式动态性:允许在运行时修改类的结构(如添加属性或方法),适应需求变化频繁的场景(如软件开发过程中的迭代)。
高效的对象操作
- 支持直接通过对象标识符(OID)访问对象,避免传统关系型数据库中复杂的连接(JOIN)操作,提升查询效率,尤其适用于处理大量关联对象的场景。
与编程语言无缝集成
- 通常与面向对象编程语言(如 Java、C++)深度集成,可直接操作数据库中的对象,减少数据转换开销。
对象型数据库与实体关系型数据库(ERDB)的区别
| 对比维度 | 对象型数据库(OODB) | 实体关系型数据库(ERDB) |
| 数据模型 | 基于面向对象模型(对象、类、继承) | 基于关系模型(表、行、列、键) |
| 数据结构 | 支持复杂对象(嵌套对象、自定义类型) | 结构化数据(二维表,需拆分为简单字段) |
| 数据与行为 | 数据与操作(方法)封装在对象中 | 数据(存储在表中)与操作(SQL 语句)分离 |
| 模式灵活性 | 动态模式,可运行时修改类结构 | 静态模式,修改表结构需通过 DDL 语句 |
| 查询方式 | 通过对象标识符(OID)或对象查询语言(OQL) | 使用 SQL 语句,需通过 JOIN 处理关联数据 |
| 适用场景 | 复杂数据类型(如多媒体、CAD 设计、生物信息)、面向对象应用开发 | 结构化数据管理(如金融交易、企业资源计划) |
| 性能特点 | 适合处理对象间的复杂关联和频繁更新 | 适合处理大规模结构化查询和事务一致性 |
| 典型产品 | MongoDB(文档型数据库,部分面向对象特性)、ObjectDB、Versant | Oracle、MySQL、SQL Server |