Kubernetes服务部署——RabbitMQ(集群版)
1、简介
RabbitMQ 是一个广泛使用的开源消息队列系统,它实现了高级消息队列协议(AMQP),并且支持多种消息传递机制。它作为一个中间件,负责解耦不同应用程序或服务之间的通信,通过高效的消息传递和排队机制确保系统的可靠性、可伸缩性和性能。RabbitMQ 适用于处理大规模数据传输、异步任务和分布式系统中的消息交换。
2、特点
-
高可用性: RabbitMQ 支持集群和镜像队列。集群模式通过分布式节点确保系统的高可用性,而镜像队列则将队列的消息备份到其他节点,确保即使某个节点出现故障,消息仍然不会丢失。
-
可靠的消息传递: RabbitMQ 支持消息的持久化、确认机制、死信队列等特性,确保消息不会丢失,并且消费者能够确保处理到每一条消息。
-
灵活的消息路由: RabbitMQ 提供多种交换机类型(Direct、Fanout、Topic、Headers)来实现不同的路由策略,允许开发者根据消息的类型和内容灵活地决定消息的去向。
-
丰富的客户端支持: RabbitMQ 提供了多种客户端库,支持多种编程语言,包括 Java、Python、Go、C#、Ruby 等,使得它能够集成到各种类型的应用中。
-
支持多个协议: 虽然 RabbitMQ 的核心协议是 AMQP,但它还支持其他协议,例如 STOMP、MQTT 等,使得它适应不同类型的应用需求。
-
灵活的消息队列配置: RabbitMQ 支持多种队列类型(如普通队列、优先级队列、死信队列等),开发者可以根据业务需求自由配置。
-
高吞吐量和低延迟: 通过优化的消息传递机制,RabbitMQ 能够处理每秒成千上万的消息,并保持低延迟,适用于高吞吐量场景。
3、应用场景
-
异步任务处理: 在复杂的分布式系统中,很多任务可能会耗时较长,或者需要在后台执行。RabbitMQ 可以用来解耦任务的提交和处理,使得前端应用能够异步提交任务,后端系统处理完成后再通知前端。比如:用户注册、图片处理、视频转码等耗时操作。
-
事件驱动架构: RabbitMQ 是构建事件驱动架构的理想选择。在这种架构下,事件的产生和处理是解耦的,RabbitMQ 负责在系统中传递事件消息,消费者监听特定的事件并响应。应用场景如:用户行为跟踪、系统日志、交易记录等。
-
分布式系统和微服务架构: 在微服务架构中,各个服务往往独立运行并需要异步通信,RabbitMQ 能帮助微服务之间通过消息传递实现解耦,保证系统的可扩展性和高可用性。比如:电商平台中的订单服务、库存服务和支付服务可以通过 RabbitMQ 传递消息,确保服务间的高效协作。
-
流量削峰: 当系统接收到大量请求时,RabbitMQ 可以用作流量削峰的缓冲区。例如:在高并发场景下,前端应用将请求数据发送到消息队列,后端消费者从队列中逐步处理这些请求,从而避免系统超载或崩溃。
-
日志处理和数据收集: 在一些需要集中处理日志和数据的应用场景中,RabbitMQ 可以用作消息队列,将各个节点或微服务的日志消息传递到中央日志系统,进行统一处理和存储。比如:企业级日志收集、实时数据流处理等。
-
跨平台数据同步: 在多平台应用中,RabbitMQ 可用于跨平台的数据同步。例如,多个不同的系统之间需要共享数据时,可以通过 RabbitMQ 将数据同步到其他系统或平台,保证数据一致性和可靠性。
-
高可用的通知系统: 例如,推送通知系统,RabbitMQ 可以帮助将消息从后端推送到各个客户端,确保消息能够可靠地传递到目标用户。无论是邮件通知、短信通知,还是 APP 推送通知,都可以通过 RabbitMQ 进行消息传递。
4、工作原理
RabbitMQ 的工作原理基于生产者-交换机-队列-消费者模式:
-
生产者:发送消息到 RabbitMQ。
-
交换机(Exchange):负责接收生产者的消息并决定如何路由消息到队列。交换机根据绑定的路由规则将消息路由到不同的队列
-
队列(Queue):存储消息,直到被消费者处理。队列中的消息在消费者处理完之前不会消失。
-
消费者:从队列中消费消息并进行处理。
消息的路由可以通过不同的交换机类型(Direct、Fanout、Topic、Headers)来实现,提供灵活的路由机制。
5、优势与不足
优势:
-
高可靠性:支持消息持久化、确认机制等,确保消息不会丢失。
-
高可用性:支持集群和镜像队列,确保系统在单点故障时仍能正常运行。
-
高度可扩展:支持水平扩展,能够处理更高的吞吐量。
-
丰富的特性:提供各种队列类型、路由策略和协议支持,满足多种场景需求。
不足:
-
消息堆积:如果消费者处理速度较慢,消息可能会堆积在队列中,导致资源占用增加,可能影响系统的稳定性。
-
性能瓶颈:在某些高并发场景下,RabbitMQ 的性能可能成为瓶颈,特别是在消息传递速度要求极高的情况下。
6、模式选择
单机模式
单机模式,就是 Demo 级别的,一般就是你本地启动了玩玩儿的😄,没人生产用单机模式。
普通集群模式(无高可用性)
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。
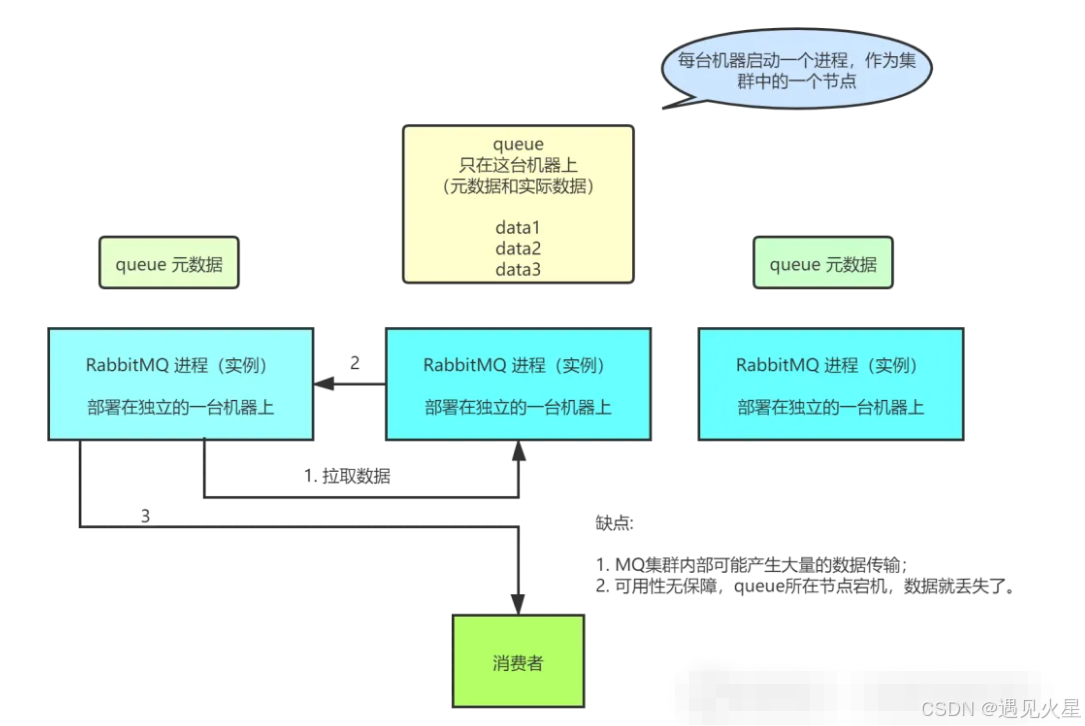 这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
镜像集群模式(高可用性)
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
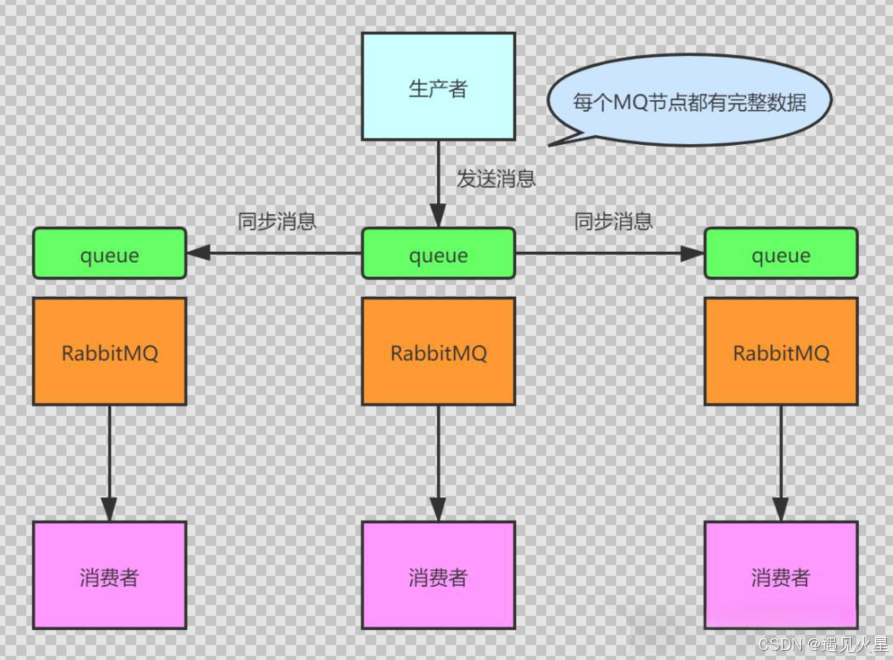 那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!第二,这么玩儿,不是分布式的,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue。你想,如果这个 queue 的数据量很大,大到这个机器上的容量无法容纳了,此时该怎么办呢?
7、队列容量扩展方案
-
水平扩展RabbitMQ集群:
-
可以通过将RabbitMQ部署成集群,增加更多的节点来扩展容量。通过将消息分布到多个节点上,单个机器的容量限制可以被突破。
-
使用Shovel插件或Federation插件,可以实现跨集群的消息转发,把数据分布到不同的集群或集群之间,从而避免单一集群的资源瓶颈。
-
-
使用磁盘存储:
-
RabbitMQ 默认会把队列数据存储到磁盘。如果队列过大,确保磁盘空间足够,并且磁盘I/O性能良好。你可以通过调整存储策略,比如使用快速的SSD,来提升磁盘存取速度。
-
设置合理的磁盘空间阈值,让RabbitMQ在磁盘空间不足时自动触发报警或进行其他操作。
-
-
消息持久化与过期策略:
-
对队列中的消息进行持久化,保证数据不会丢失,但也会增加磁盘空间的需求。你可以调整消息持久化策略,选择更适合的队列类型和消息持久化模式。
-
设置TTL(Time to Live),可以在一定时间后自动丢弃过期消息,减少队列的积压,避免数据无意义地占用空间。
-
-
分批消费(Message Prefetch):
-
可以通过设置合理的prefetch count,限制每个消费者一次性获取的消息数量,从而避免消息积压到队列中。
-
增加消费者数量,增加消费能力,使得队列能够更快地被消费,避免积压。
-
-
优化消息压缩和批处理:
-
如果消息体积大,可以考虑消息压缩,减少每条消息占用的空间。
-
采用批处理模式,多个小消息打包成一个大消息进行处理,可以减少RabbitMQ的消息数量和资源消耗。
-
-
增加消息过滤机制:
-
如果队列数据量大是由于某些无效或过期的数据占用空间,可以考虑设置消息过滤机制,只允许符合某些条件的消息进入队列。
-
-
异步外部存储:
-
将部分消息或数据存储到外部存储系统,如分布式文件系统(如Ceph)或数据库中,RabbitMQ只负责队列和消息传递的控制,存储则交给外部系统处理。可以通过RabbitMQ的插件或者消费者自行去访问外部存储获取数据。
-
8、部署
创建secret
root@ldap:/opt/rabbitmq/test# cat rabbitmq-secret.yaml kind: Secret apiVersion: v1 metadata:name: rmq-cluster-secretnamespace: rocketmq-saas stringData:cookie: ERLANG_COOKIEurl: amqp://admin:admin123@rmq-cluster-balancerusername: adminpassword: admin123 type: Opaque
创建configmap
root@ldap:/opt/rabbitmq/test# cat rabbitmq-configmap.yaml kind: ConfigMap apiVersion: v1 metadata:name: rmq-cluster-confignamespace: rocketmq-saaslabels:addonmanager.kubernetes.io/mode: Reconcile data:enabled_plugins: |[rabbitmq_management,rabbitmq_peer_discovery_k8s].rabbitmq.conf: |loopback_users.guest =falsedefault_user = RABBITMQ_USERdefault_pass = RABBITMQ_PASS## Clusteringcluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8scluster_formation.k8s.host = kubernetes.default.svc.cluster.localcluster_formation.k8s.address_type = hostname################################################## public-service is rabbitmq-cluster's namespace##################################################cluster_formation.k8s.hostname_suffix = .rmq-cluster.rocketmq-saas.svc.cluster.localcluster_formation.node_cleanup.interval =10cluster_formation.node_cleanup.only_log_warning =truecluster_partition_handling = autoheal## queue master locatorqueue_master_locator=min-masters
创建service
root@ldap:/opt/rabbitmq/test# cat rabbitmq-service.yaml kind: Service apiVersion: v1 metadata:labels:app: rmq-clustername: rmq-clusternamespace: rocketmq-saas spec:clusterIP: Noneports:- name: amqpport: 5672targetPort: 5672selector:app: rmq-cluster --- kind: Service apiVersion: v1 metadata:labels:app: rmq-clustertype: LoadBalancername: rmq-cluster-balancernamespace: rocketmq-saas spec:ports:- name: httpport: 15672protocol: TCPtargetPort: 15672nodePort: 31672- name: amqpport: 5672protocol: TCPtargetPort: 5672selector:app: rmq-clustertype: NodePort
创建StatefulSet
root@ldap:/opt/rabbitmq/test# cat rabbitmq-cluster-sts.yaml
kind: StatefulSet
apiVersion: apps/v1
metadata:labels:app: rmq-clustername: rmq-clusternamespace: rocketmq-saas
spec:replicas: 3selector:matchLabels:app: rmq-clusterserviceName: rmq-clustertemplate:metadata:labels:app: rmq-clusterspec:containers:- args:--c-cp-v /etc/rabbitmq/rabbitmq.conf ${RABBITMQ_CONFIG_FILE}; exec docker-entrypoint.shrabbitmq-servercommand:-shenv:- name: RABBITMQ_DEFAULT_USERvalueFrom:secretKeyRef:key: usernamename: rmq-cluster-secret- name: RABBITMQ_DEFAULT_PASSvalueFrom:secretKeyRef:key: passwordname: rmq-cluster-secret- name: RABBITMQ_ERLANG_COOKIEvalueFrom:secretKeyRef:key: cookiename: rmq-cluster-secret- name: K8S_SERVICE_NAMEvalue: rmq-cluster- name: POD_IPvalueFrom:fieldRef:fieldPath: status.podIP- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: RABBITMQ_USE_LONGNAMEvalue: "true"- name: RABBITMQ_NODENAMEvalue: rabbit@$(POD_NAME).rmq-cluster.$(POD_NAMESPACE).svc.cluster.local- name: RABBITMQ_CONFIG_FILEvalue: /var/lib/rabbitmq/rabbitmq.confimage: registry.cn-shanghai.aliyuncs.com/study-03/rabbitmq:3.9.11 imagePullPolicy: IfNotPresentlivenessProbe:exec:command:- rabbitmqctl- statusinitialDelaySeconds: 30timeoutSeconds: 10name: rabbitmqports:- containerPort: 15672name: httpprotocol: TCP- containerPort: 5672name: amqpprotocol: TCPreadinessProbe:exec:command:- rabbitmqctl- statusinitialDelaySeconds: 10timeoutSeconds: 10volumeMounts:- mountPath: /etc/rabbitmqname: config-volumereadOnly: false- mountPath: /var/lib/rabbitmqname: rabbitmq-storagereadOnly: falseserviceAccountName: rmq-clusterterminationGracePeriodSeconds: 30volumes:- configMap:items:- key: rabbitmq.confpath: rabbitmq.conf- key: enabled_pluginspath: enabled_pluginsname: rmq-cluster-configname: config-volume
创建pvc
apiVersion: v1 kind: PersistentVolumeClaim metadata:name: rabbitmq-storage spec:accessModes: ["ReadWriteOnce"]resources:requests:storage: 100GistorageClassName: longhorn
容器查看
root@ldap:/opt/rabbitmq/test# kubectl get pod -n rocketmq-saas rmq-cluster-0 1/1 Running 0 38d rmq-cluster-1 1/1 Running 0 38d rmq-cluster-2 1/1 Running 0 38d