华为云Flexus+DeepSeek征文 | 基于Dify构建多语言文件翻译工作流
华为云Flexus+DeepSeek征文 | 基于Dify构建多语言文件翻译工作流
- 一、构建多语言文件翻译工作流引言
- 二、构建多语言文件翻译工作流环境
- 2.1 基于FlexusX实例的Dify平台
- 2.2 基于MaaS的模型API商用服务
- 三、构建多语言文件翻译工作流实战
- 3.1 配置Dify环境
- 3.2 创建多语言文件翻译工作流
- 3.3 使用多语言文件翻译工作流
- 四、总结
一、构建多语言文件翻译工作流引言
在全球化协作日益频繁的今天,企业经常需要处理多语言文档的翻译需求,传统翻译方式存在效率低、成本高、术语不一致等问题。构建智能化工作流可提升效率300%+,降低成本70%,是应对全球化合规与协作的必选项,对于我们平时查看技术电子文件也有帮助。
Dify作为开源的低代码平台,提供了直观的可视化工作流编辑器,无需复杂编程即可构建完整的翻译流水线。通过简单的拖拽操作,就能实现文档解析→术语匹配→AI翻译→格式保持的全流程自动化。
基于Dify的解决方案可以部署在华为云Flexus X实例上,确保敏感数据不出私域。Flexus X实例的"性能模式"提供稳定的QoS保障,特别适合长时间运行的翻译工作负载。特别是与华为云MaaS平台的DeepSeek API无缝集成,DeepSeek-R1/V3模型在文档翻译任务中表现出色,支持56种语言的互译,并能自动适配文化差异和行业术语。
二、构建多语言文件翻译工作流环境
2.1 基于FlexusX实例的Dify平台
华为云FlexusX实例提供高性价比的云服务器,按需选择资源规格、支持自动扩展,减少资源闲置,优化成本投入,并且首创大模型QoS保障,智能全域调度,算力分配长稳态运行,一直加速一直快,用于搭建Dify-LLM应用开发平台。
Dify是一个能力丰富的开源AI应用开发平台,为大型语言模型(LLM)应用的开发而设计。它巧妙地结合了后端即服务(Backend as Service)和LLMOps的理念,提供了一套易用的界面和API,加速了开发者构建可扩展的生成式AI应用的过程。
参考:华为云Flexus+DeepSeek征文 | 基于FlexusX单机一键部署社区版Dify-LLM应用开发平台教程
2.2 基于MaaS的模型API商用服务
MaaS预置服务的商用服务为企业用户提供高性能、高可用的推理API服务,支持按Token用量计费的模式。该服务适用于需要商用级稳定性、更高调用频次和专业支持的场景。
参考:华为云Flexus+DeepSeek征文 | 基于ModelArts Studio开通和使用DeepSeek-V3/R1商用服务教程
三、构建多语言文件翻译工作流实战
3.1 配置Dify环境
输入管理员的邮箱和密码,登录基于FlexusX部署好的Dify网站
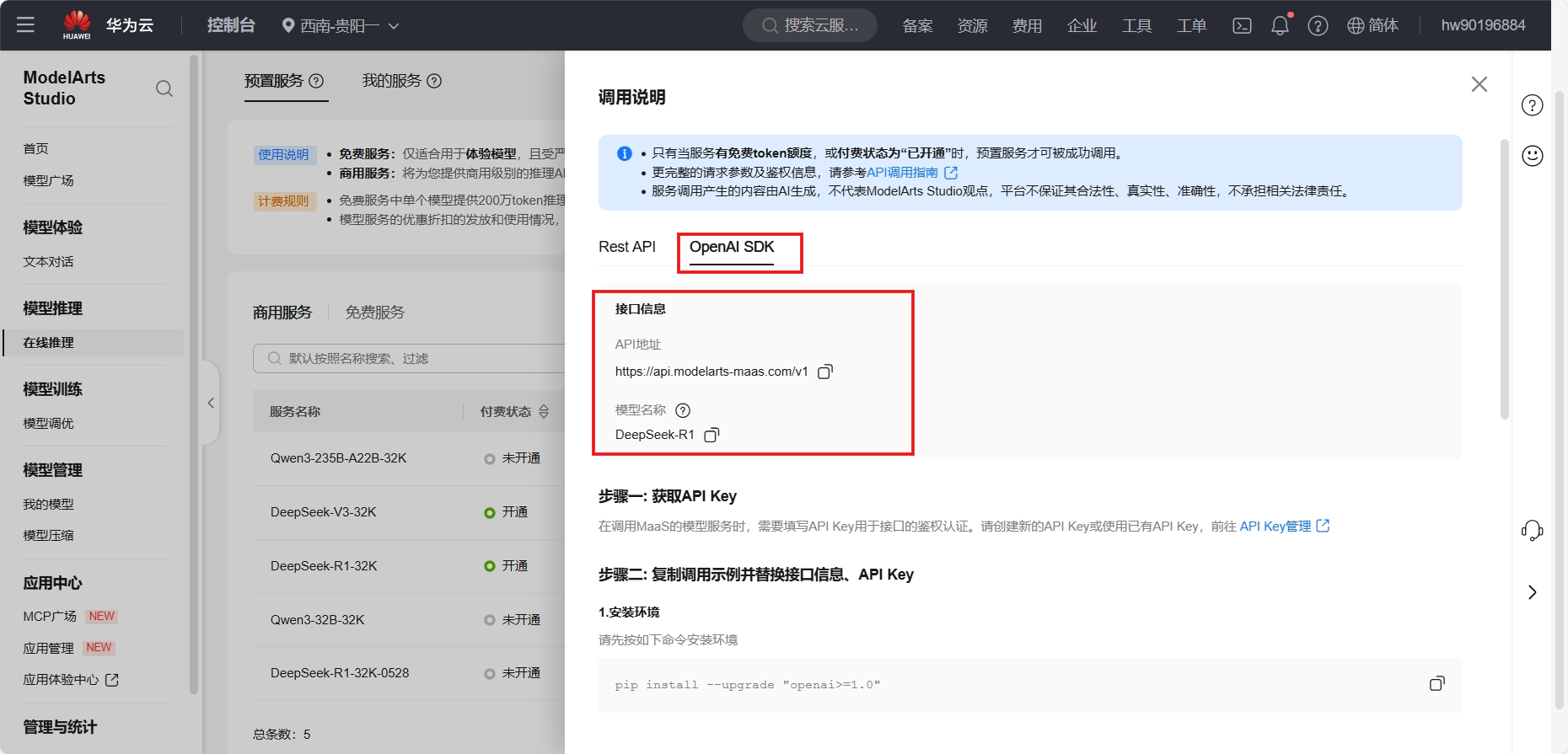
将MaaS平台的模型服务接入Dify,这里我们选择的是DeepSeek R1商用服务,需要记住调用说明中的接口信息和 API Key 管理中API Key,若没有可以重新创建即可
配置Dify模型供应商:设置 - 模型供应商 - 找到OpenAI-API-compatible供应商并单击添加模型,在添加 OpenAI-API-compatible对话框,配置相关参数,然后单击保存
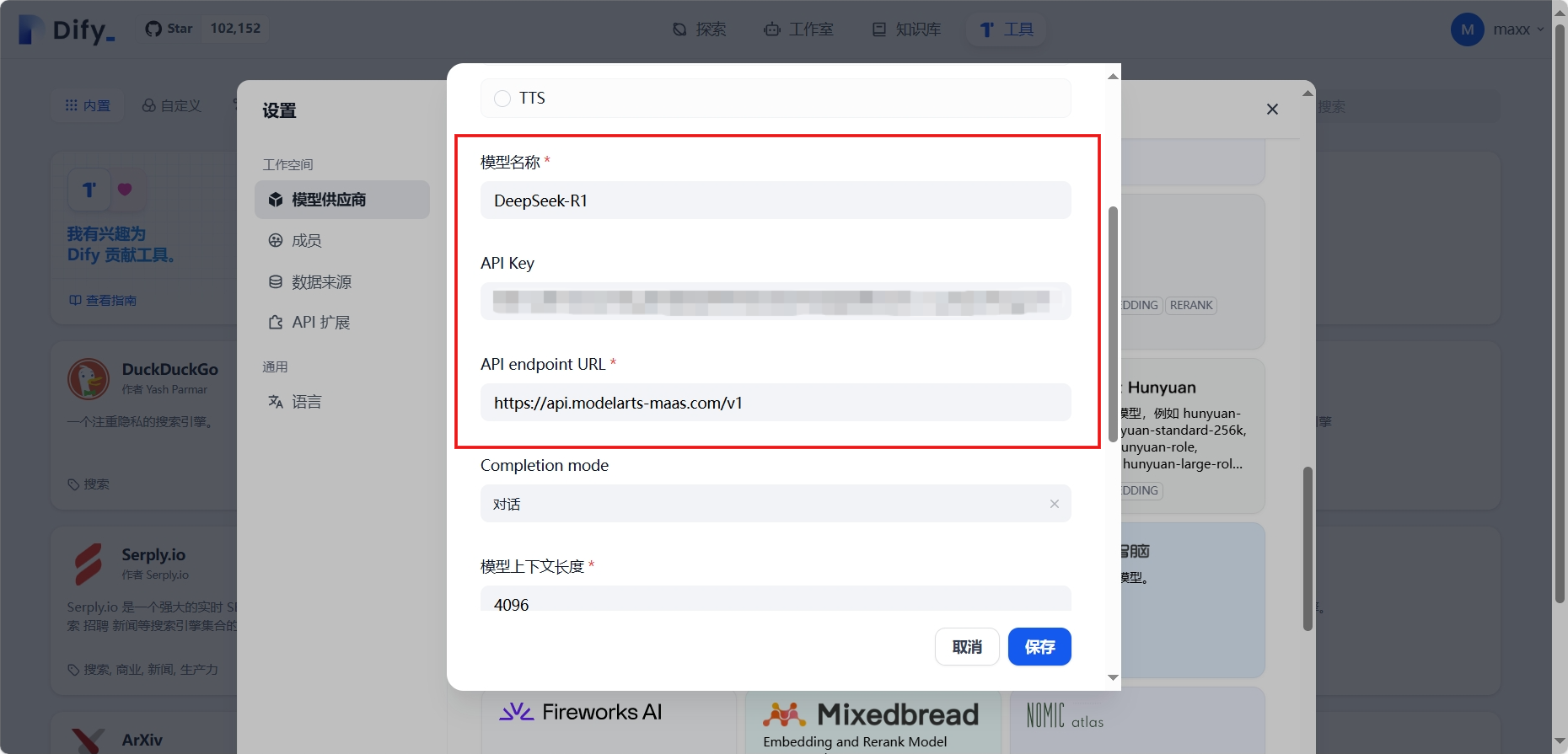
| 参数 | 说明 |
|---|---|
| 模型类型 | 选择LLM。 |
| 模型名称 | 填入模型名称。 |
| API Key | 填入创建的API Key。 |
| API Endpoint URL | 填入获取的MaaS服务的基础API地址,需要去掉地址尾部的“/chat/completions”后填入 |
3.2 创建多语言文件翻译工作流
创建空白应用,选择Chatflow,输出应用名称:多语言翻译,创建
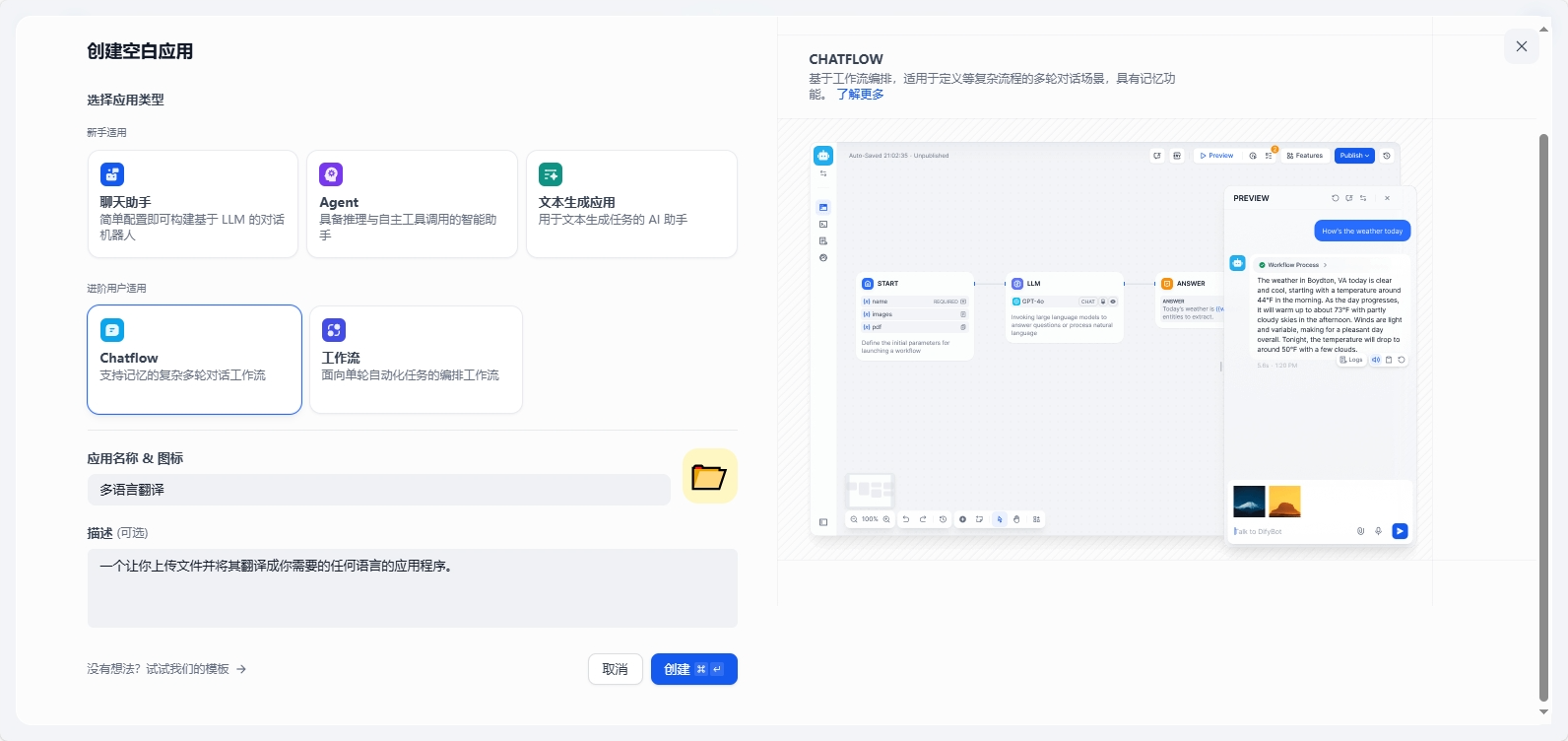
进入编排界面,Chatflow有初始的节点,接下里我们需要根据自己的设计重新编排
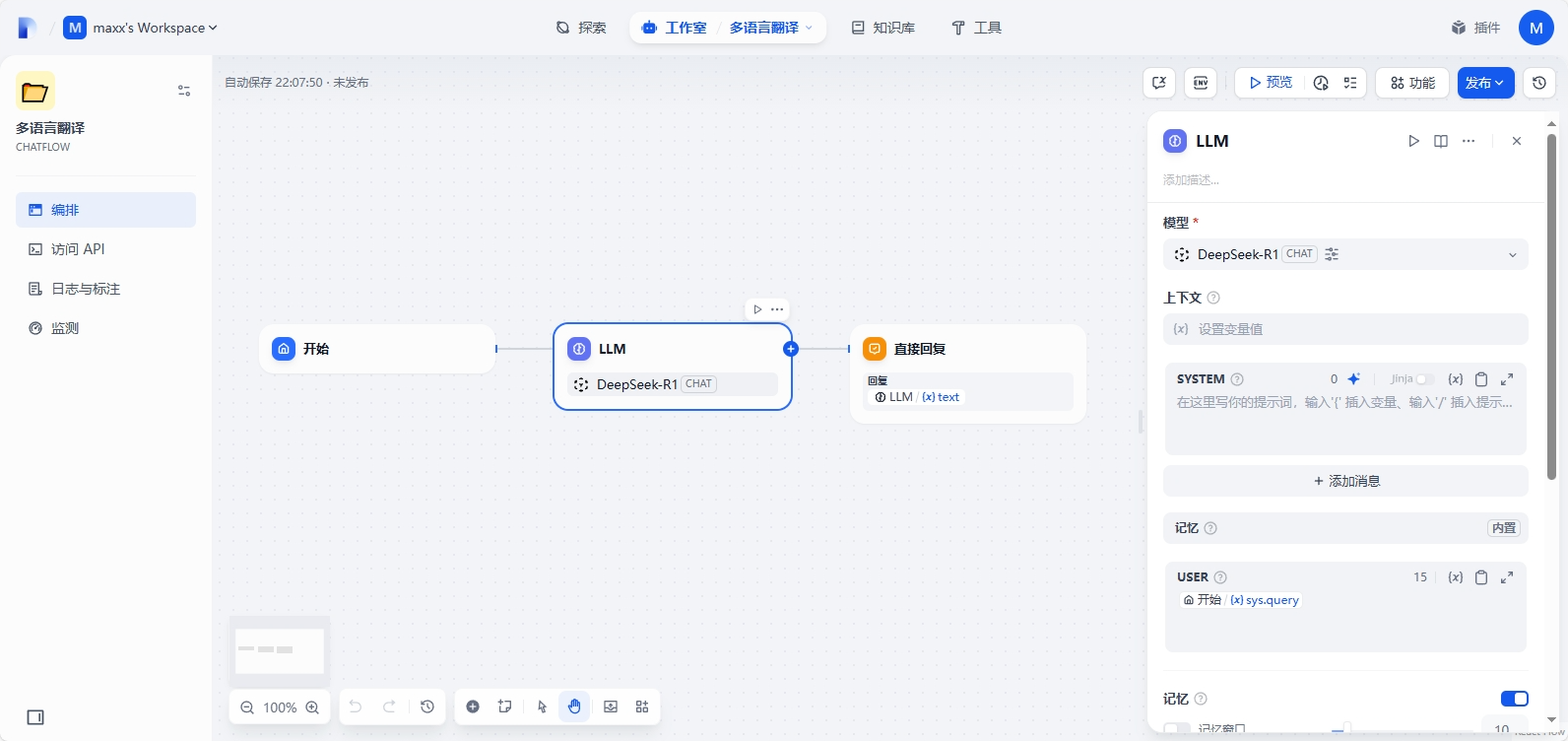
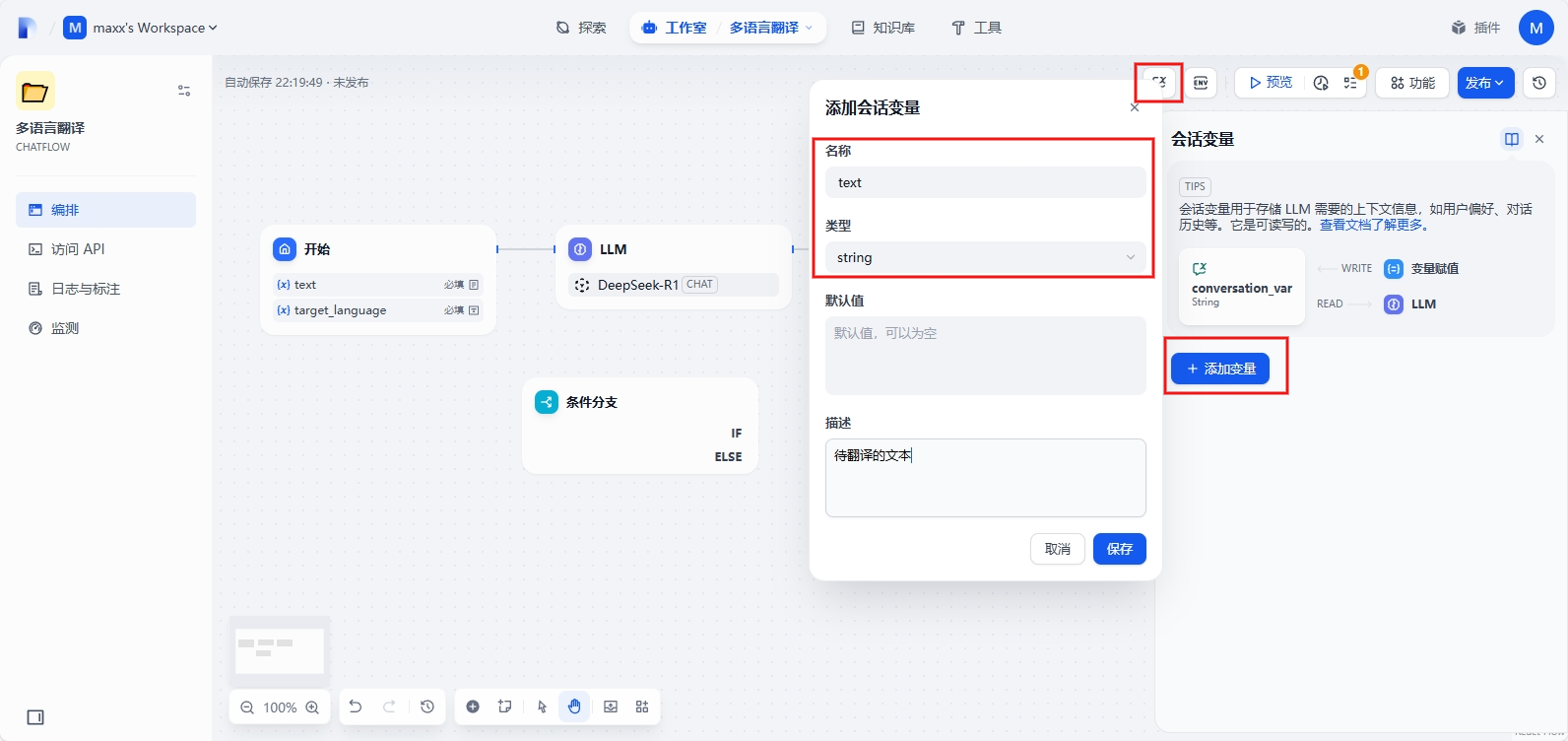
开始节点新增2个输入字段:text - 翻译的文件,target_language - 翻译语言
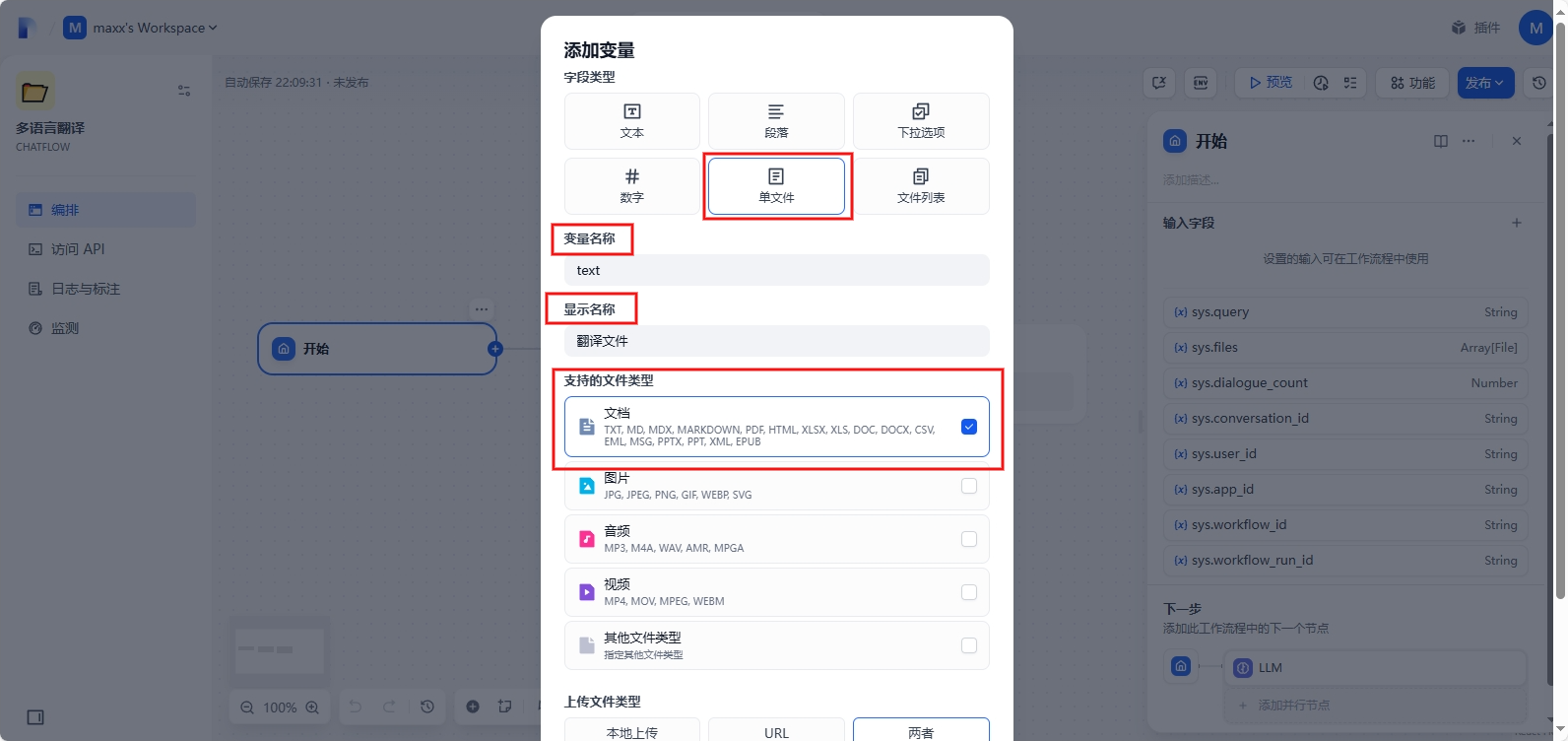
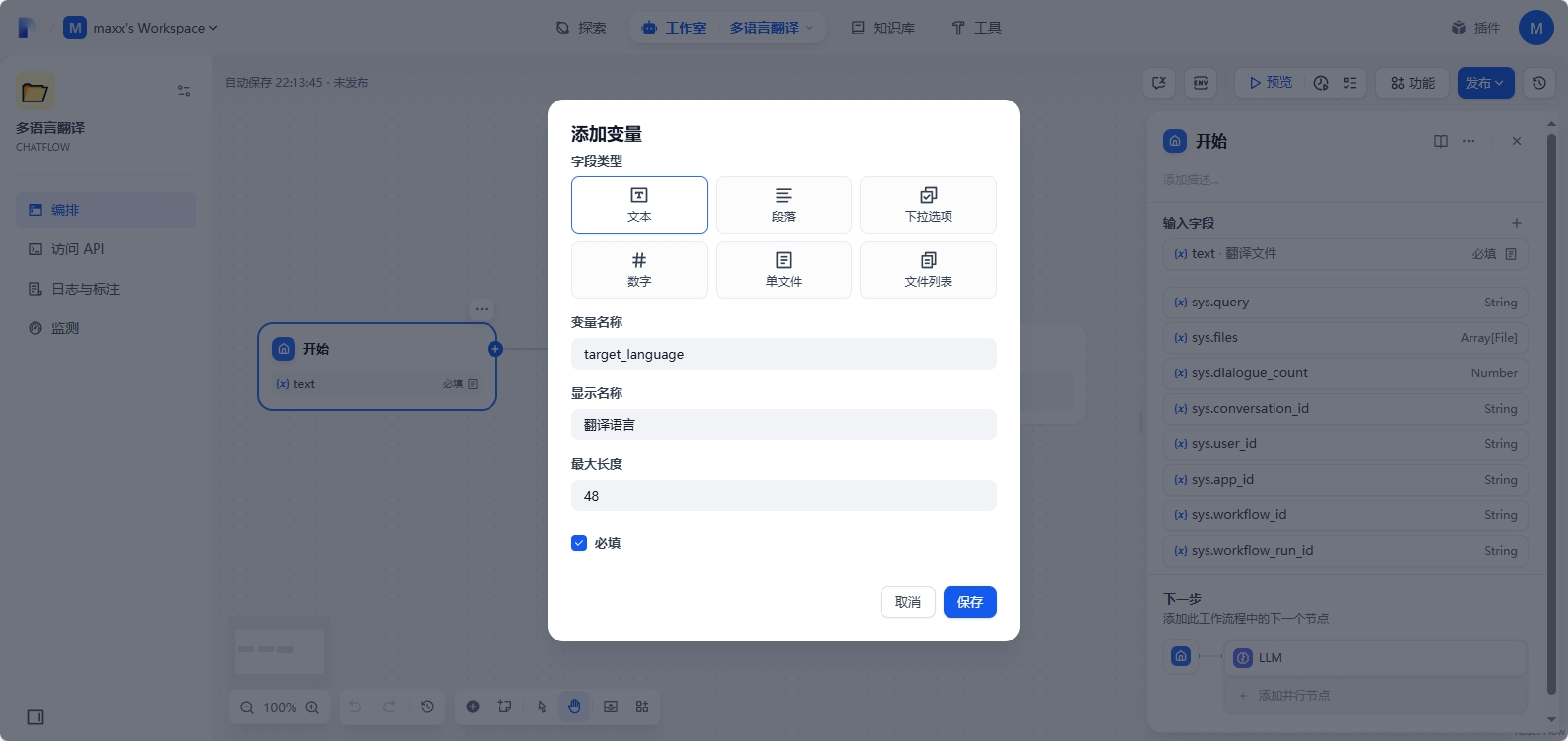
右上角添加会话变量:text - 待翻译的文本
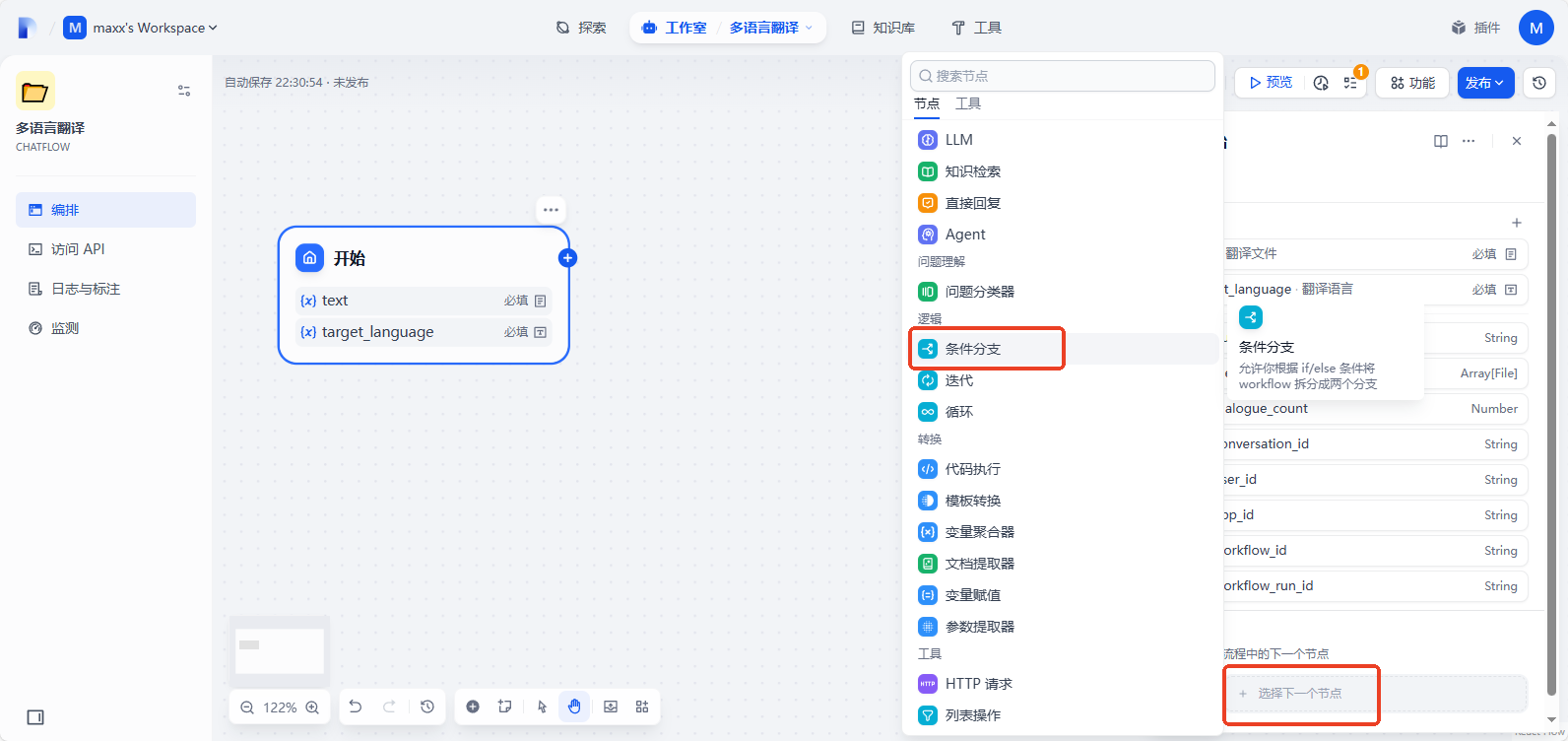
删除开始节点后的其他节点,点击开始节点,下一步添加条件分支
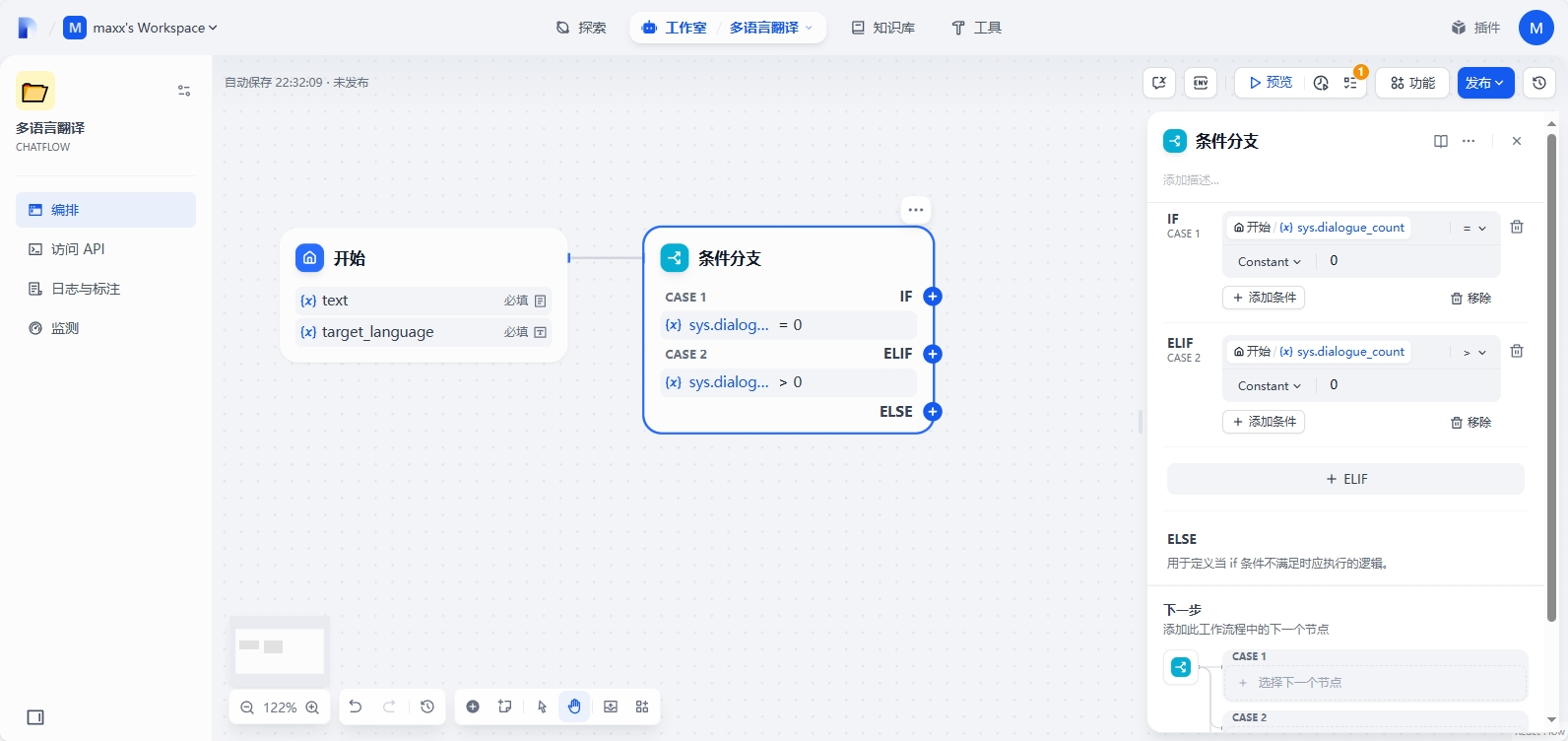
在 if 条件中添加 sys.dialogue_count = 0 ,else 条件中添加 sys.dialogue_count > 0
| 变量名称 | 数据类型 | 说明 |
|---|---|---|
sys.dialogue_count | Number | 用户在与 Chatflow 类型应用交互时的对话轮数。每轮对话后自动计数增加 1,可以和 if-else 节点搭配出丰富的分支逻辑。例如到第 X 轮对话时,回顾历史对话并给出分析 |
Case1 添加下一步节点为文档提取器
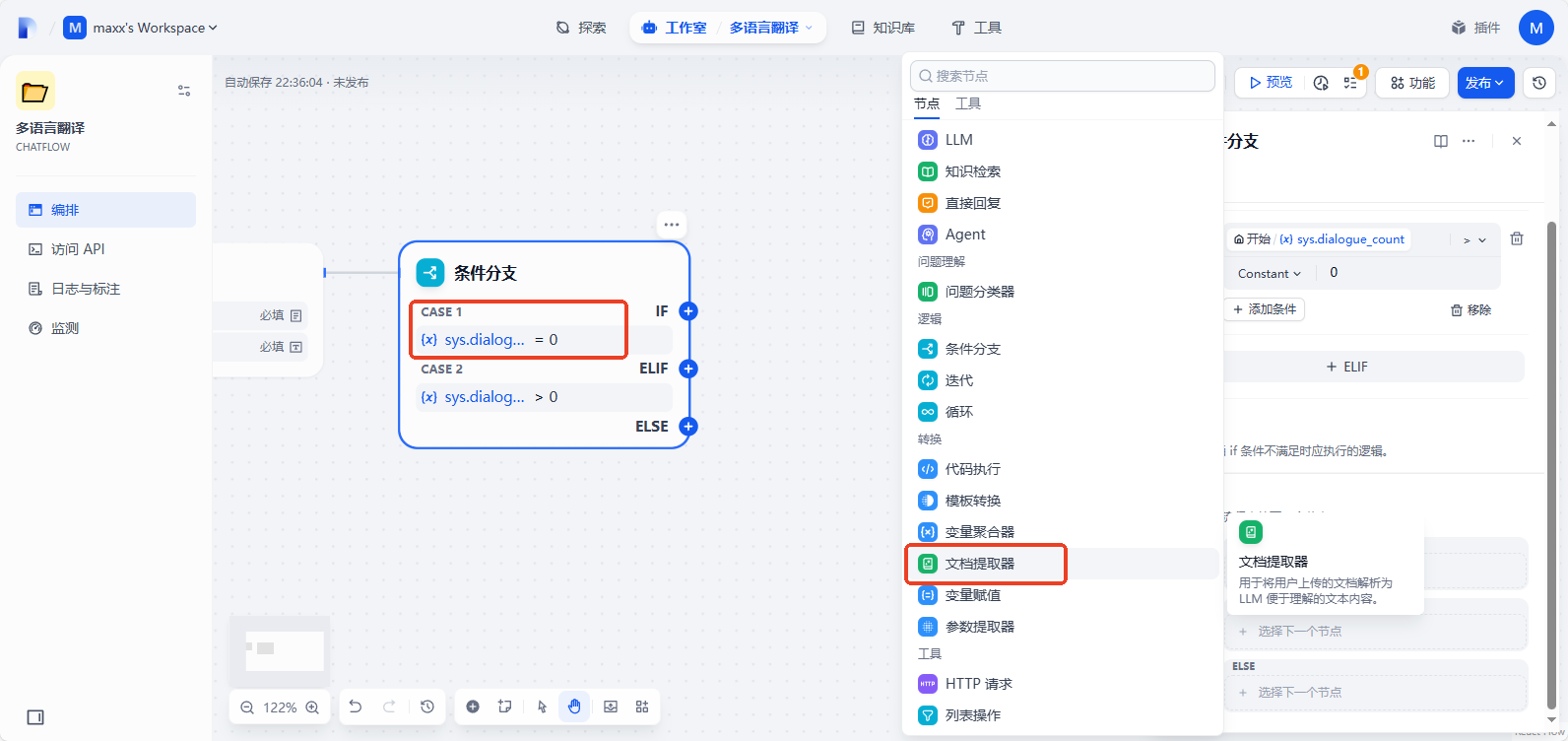
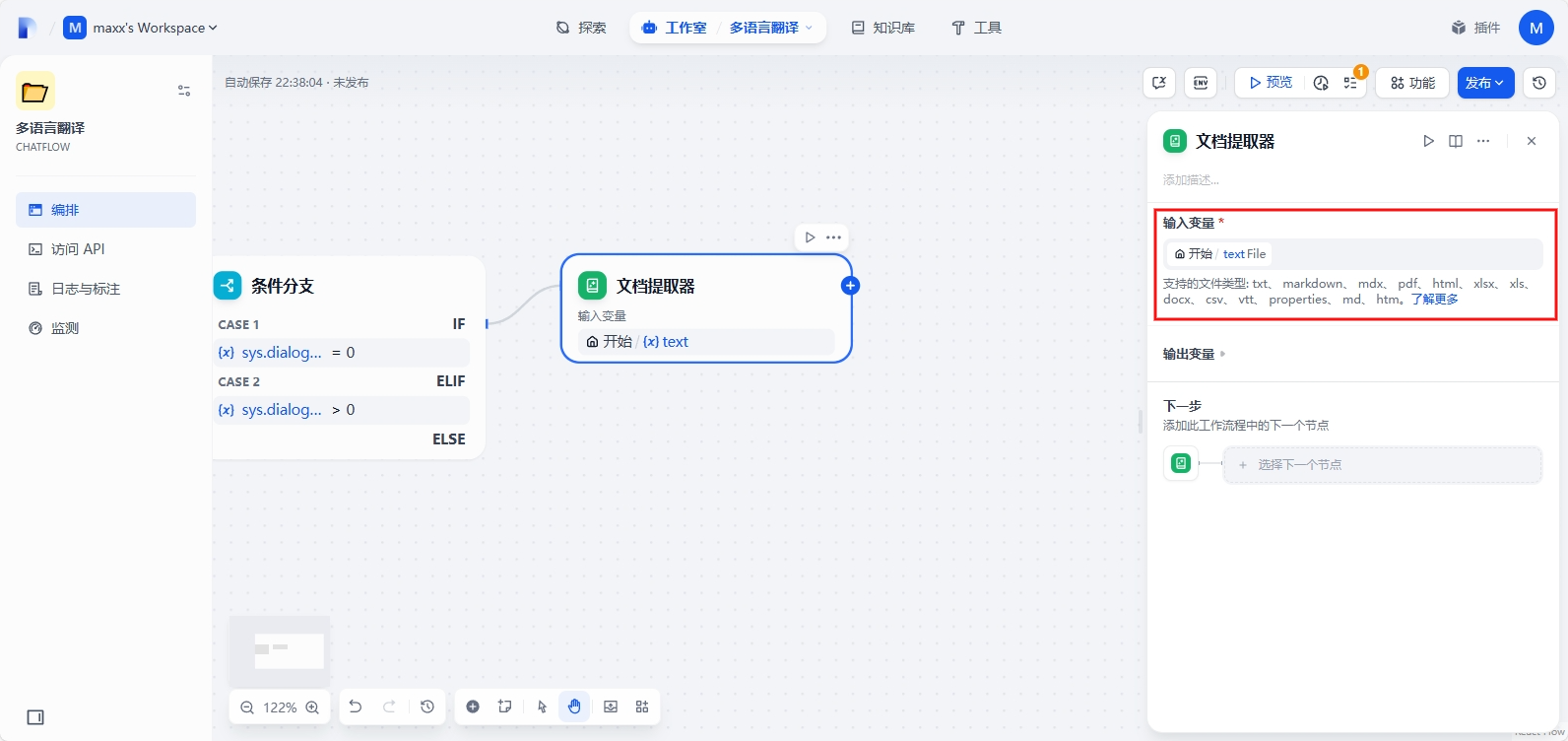
填写输入变量:text File (即上传的待翻译的文件)
再添加下一个节点为变量赋值
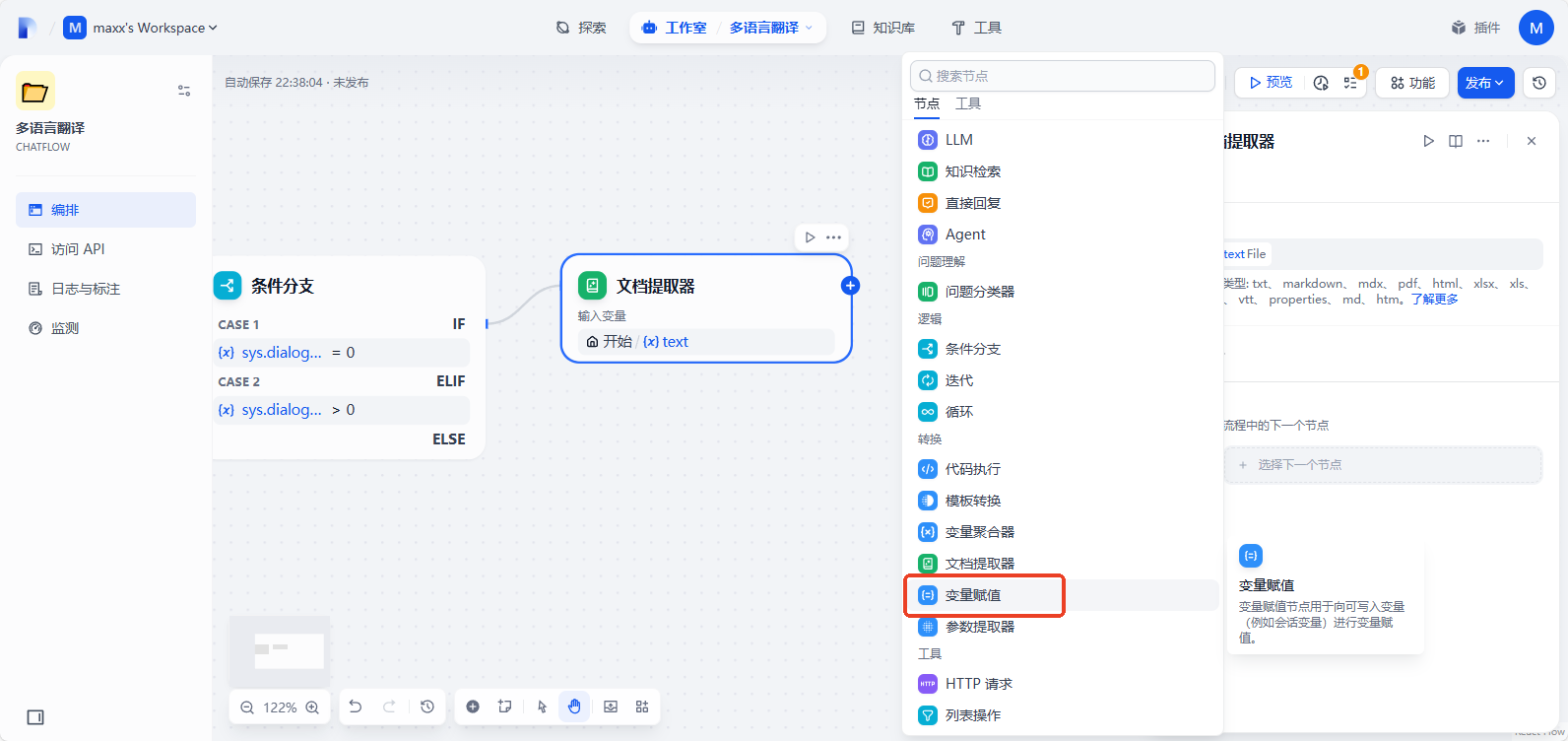
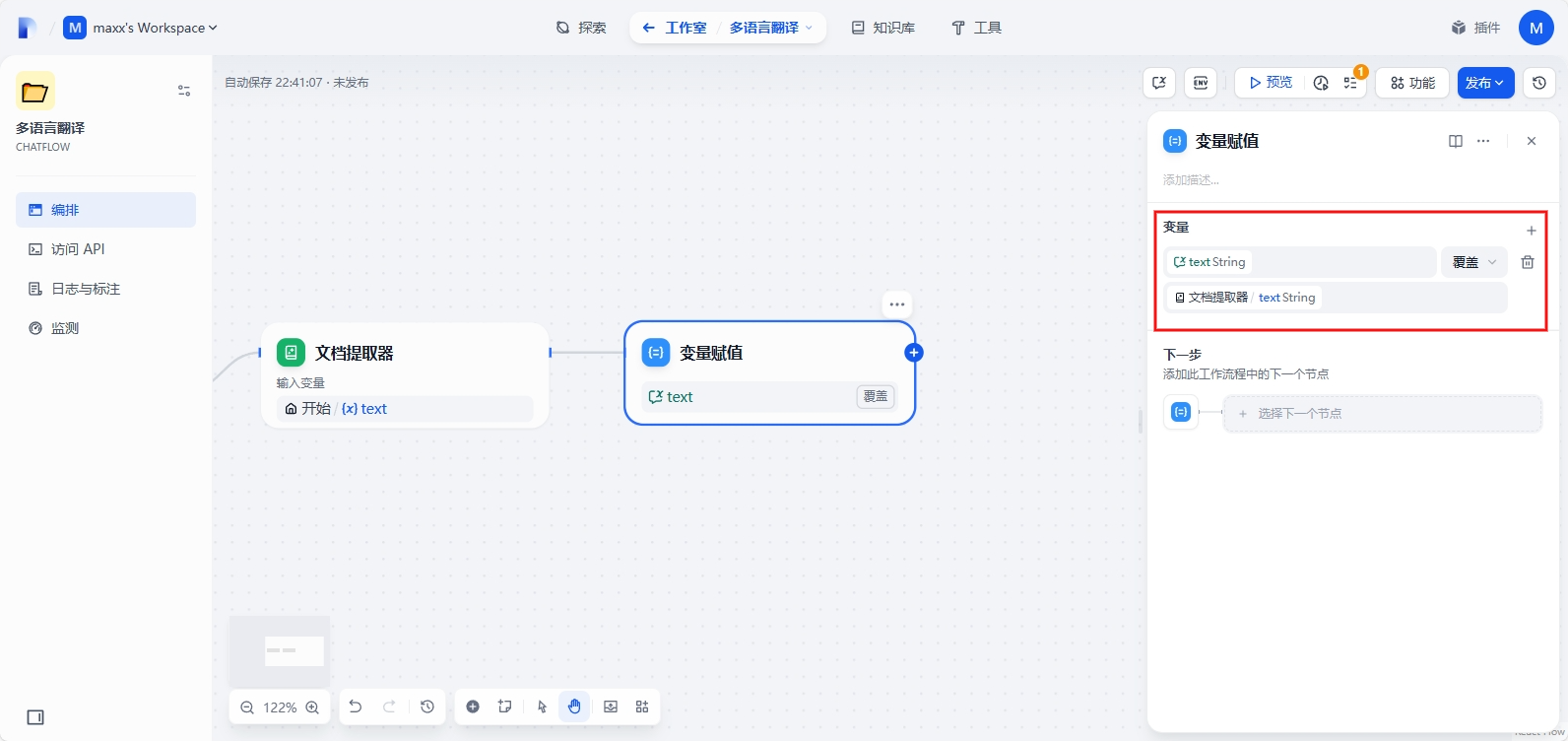
添加变量:text(待翻译的文本) 覆盖 text(文档提取器)
再添加一个直接回复节点
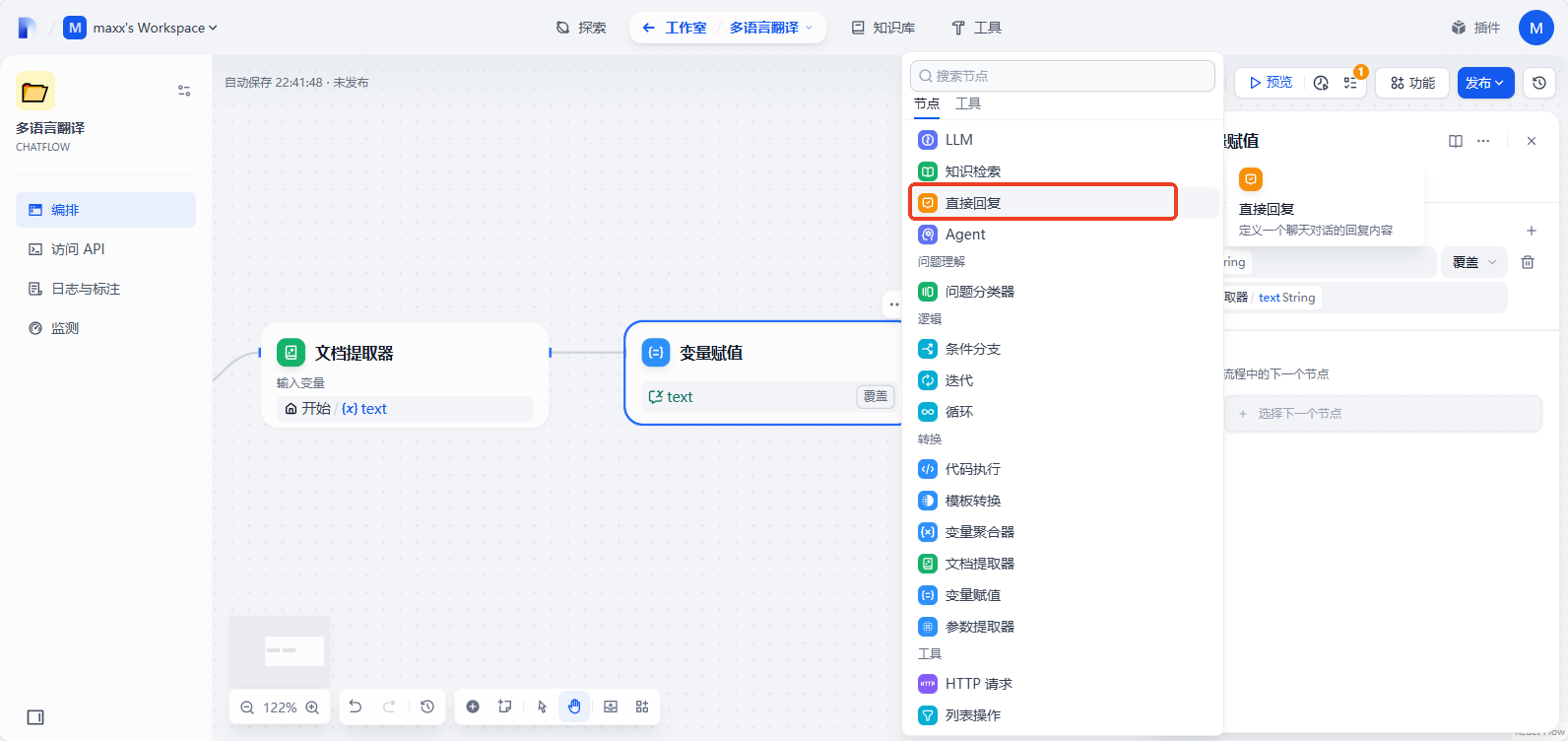
填入回复内容:文件已处理!
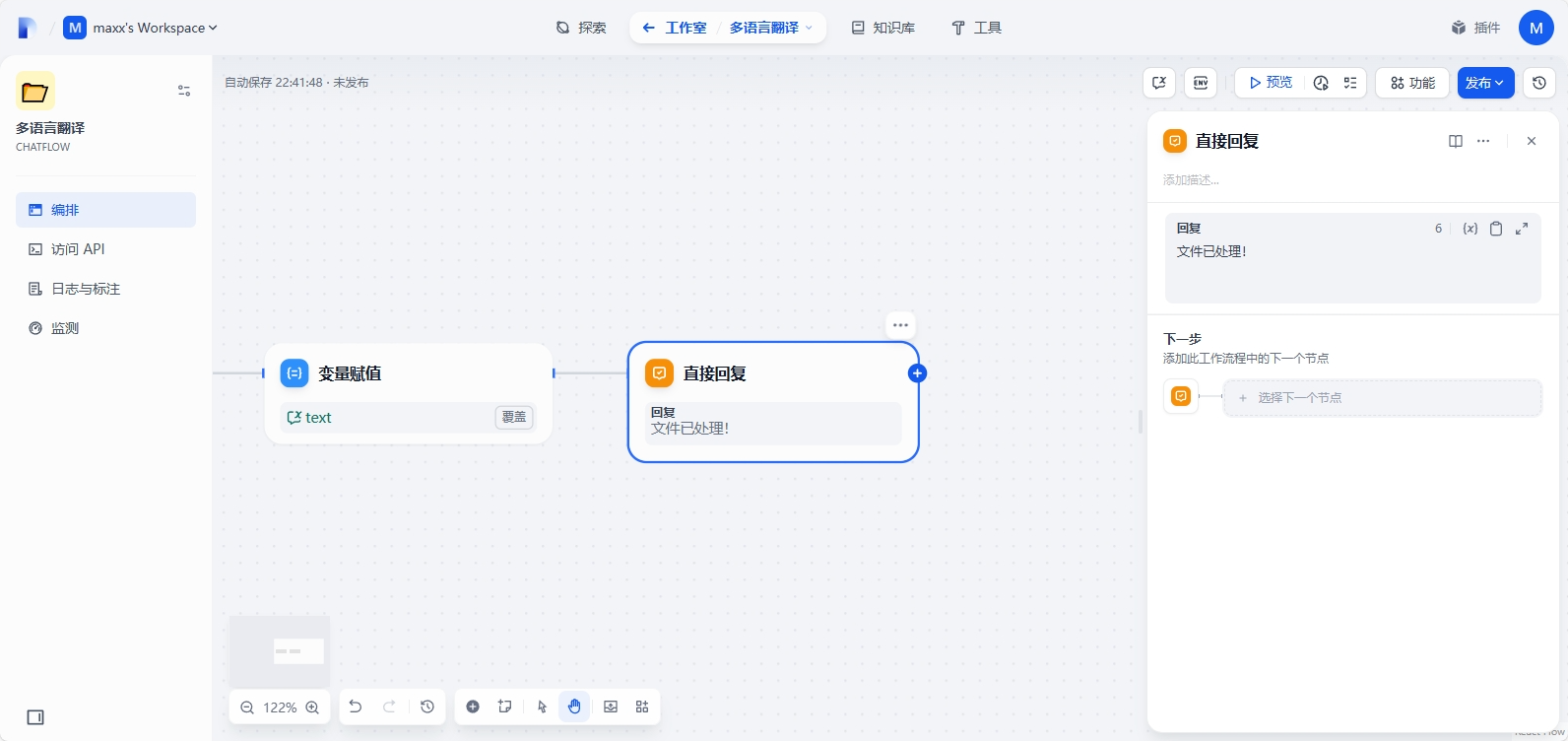
再添加LLM节点,这步是最重要的,借助大模型进行文本的翻译工作
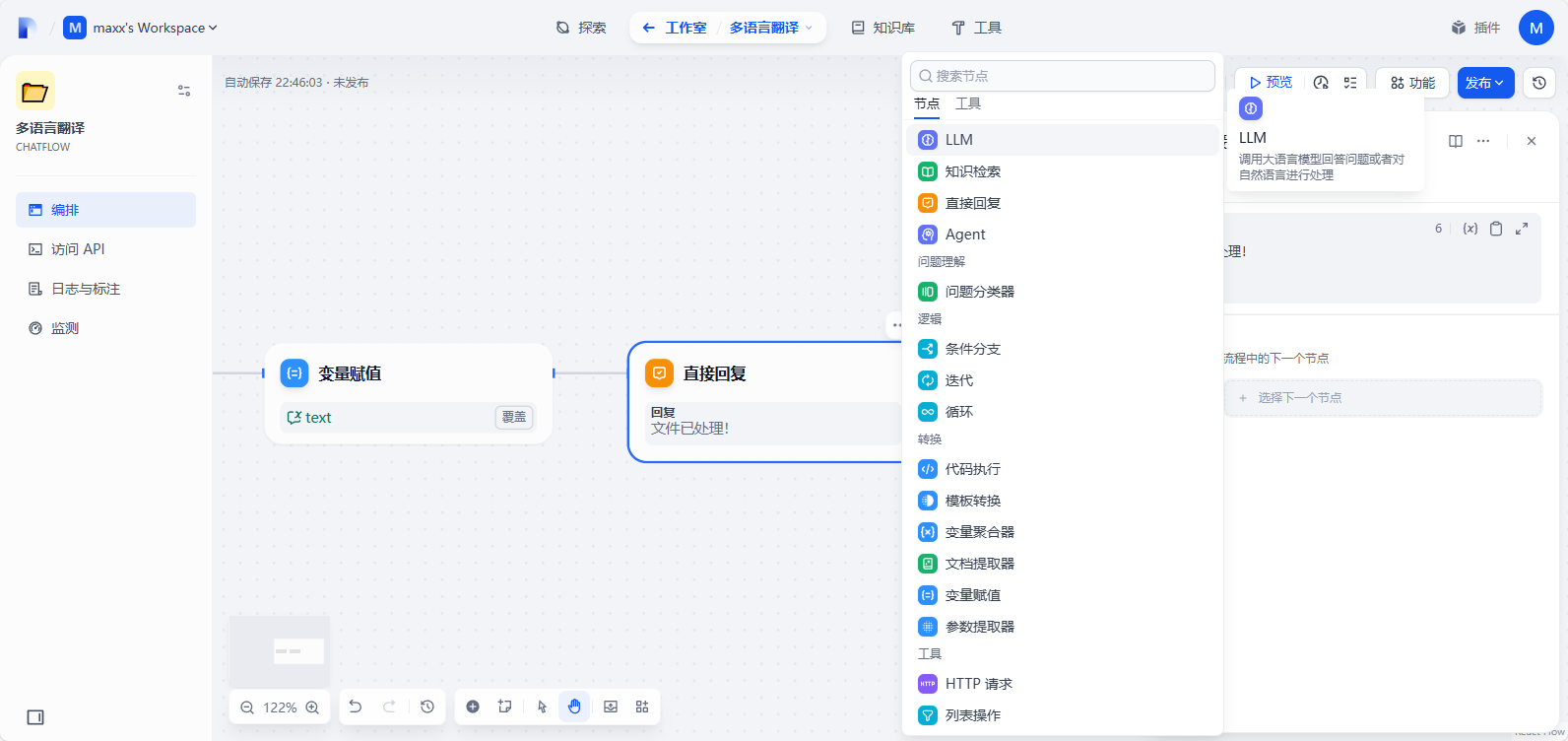
模型默认使用添加的DeepSeek R1,在SYSTEM中填入提示词,能够为对话提供高层指导,提示词参考如下:
You are a translator capable of translating multiple languages. Your task is to accurately translate the given text from the source language to {{#1727234055352.target_language#}}. Follow these steps to complete the task:1. Identify the source language of the input text.
2. Translate the text into {{#1727234055352.target_language#}}.
3. Ensure that the translation maintains the original meaning and context.
4. Use proper grammar, punctuation, and syntax in the translated text.Make sure to handle idiomatic expressions and cultural nuances appropriately. If the input text contains any specialized terminology or jargon, ensure that the translation reflects the correct terms in the target language.

添加消息选择文档提取器 - text
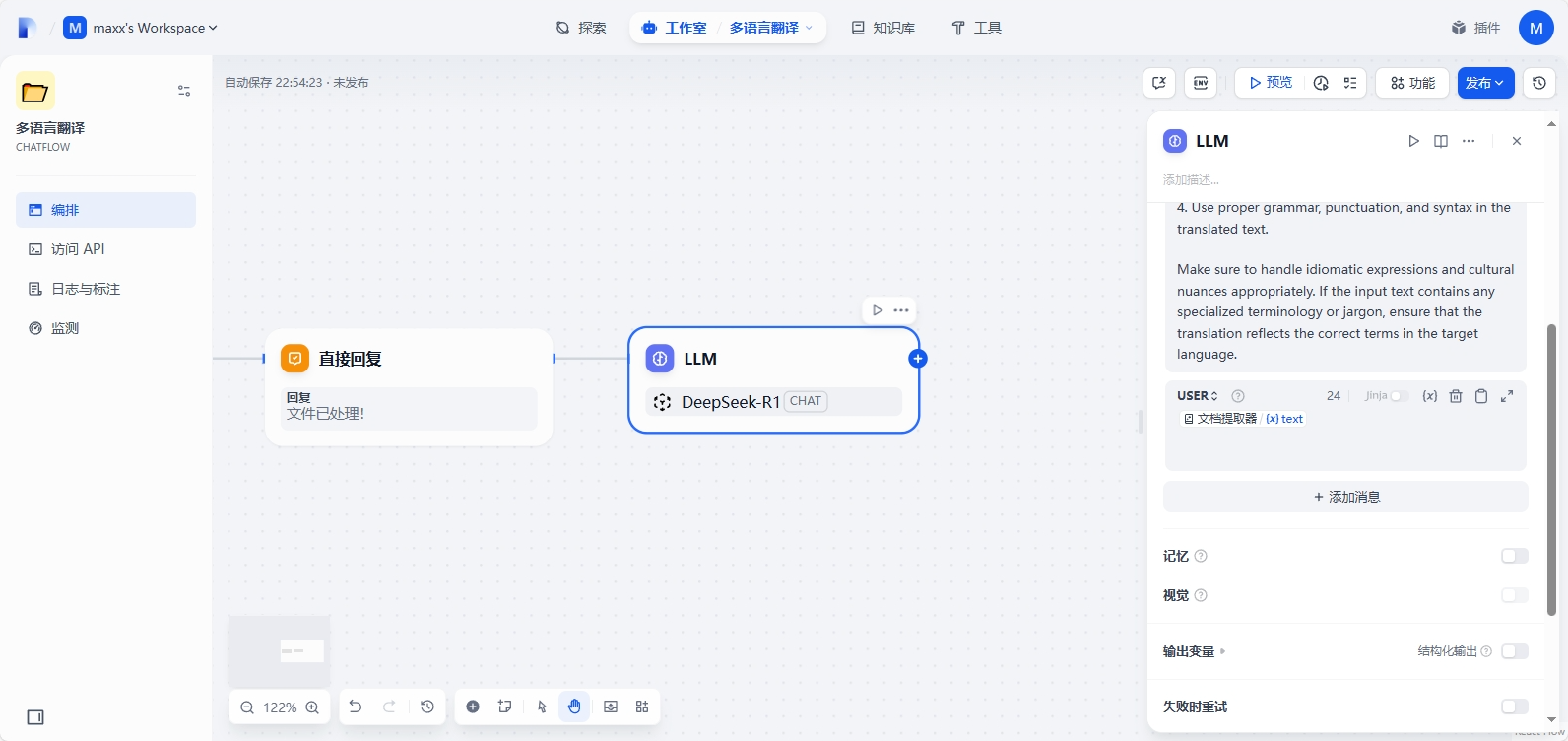
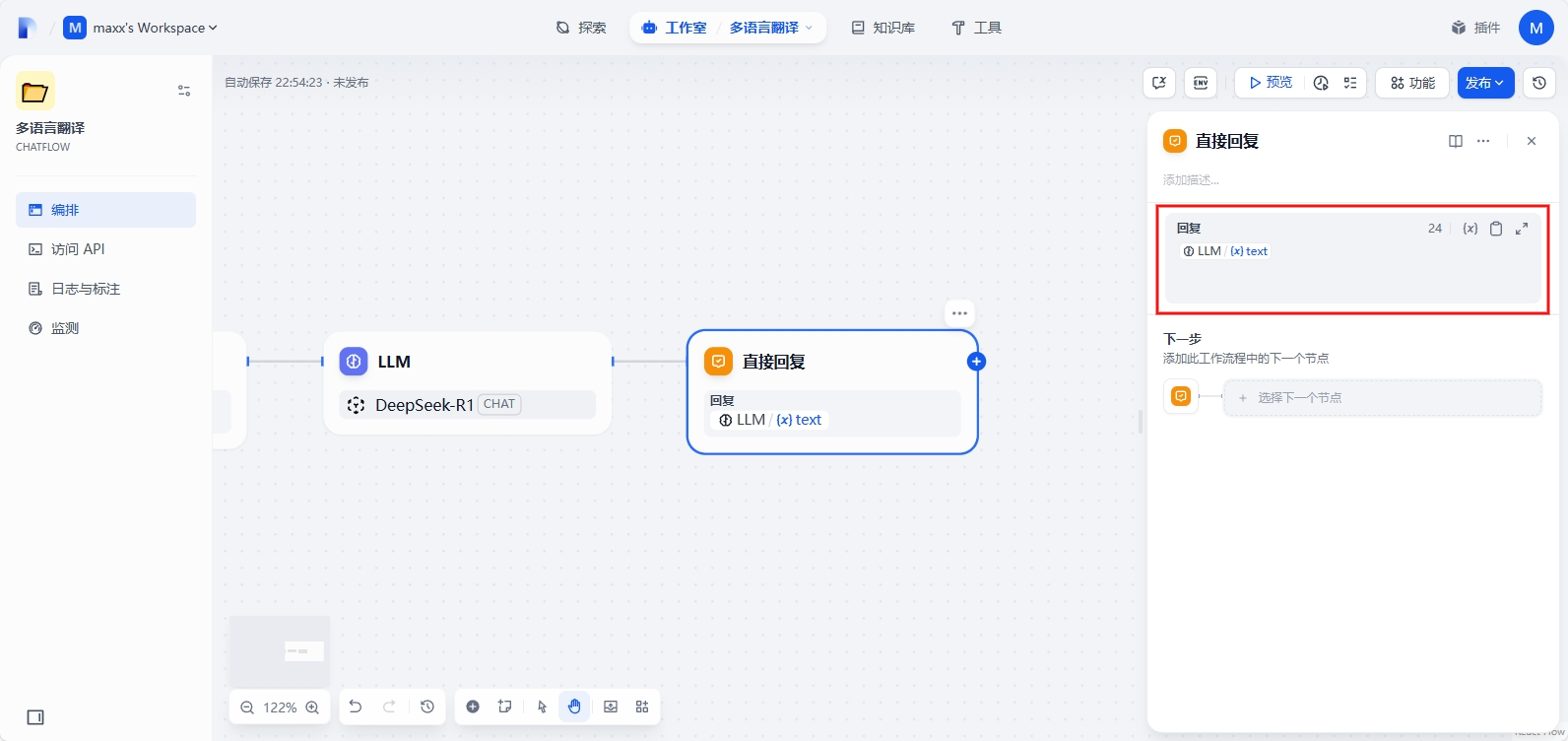
Case1 最后一个节点是直接回复,输出 LLM - text
接下来完成Case2,添加LLM节点,重命名为用户意图,这步旨在解读并总结用户对翻译的具体要求。它会读取用户的输入,提取关键点(例如偏好的语气、术语或风格),并将其概括为要点。这有助于翻译流程确保输出符合用户的特定偏好,例如语气、语言简洁性或文化差异。在SYSTEM中填入如下提示词:
<instructions>
To complete the task of summarizing users' requirements on translated text in bullet points, follow these steps:1. **Read the User's Input**: Carefully read the user's input to understand their requirements, opinions on styles, and terms of translation.
2. **Identify Key Points**: Extract the key points from the user's input. Focus on specific requirements, preferences, and opinions related to the translation.
3. **Summarize in Bullet Points**: Summarize the identified key points in clear and concise bullet points. Ensure each bullet point addresses a distinct requirement or opinion.
4. **Maintain Clarity and Brevity**: Ensure that the bullet points are easy to understand and free from unnecessary details. Each point should be brief and to the point.
5. **Avoid XML Tags in Output**: The final output should be free from any XML tags. Only use bullet points to list the summarized requirements and opinions.Here are some examples to clarify the task further:<examples>
<example>
<user_input>
I prefer the translation to maintain a formal tone. Also, please use the term "client" instead of "customer". The translated text should be easy to read and free from jargon.
</user_input>
<output>
- Maintain a formal tone in the translation.
- Use the term "client" instead of "customer".
- Ensure the translated text is easy to read.
- Avoid using jargon.
</output>
</example><example>
<user_input>
The translation should be culturally appropriate for a Japanese audience. I would like the text to be concise and to the point. Please avoid using slang or colloquial expressions.
</user_input>
<output>
- Ensure the translation is culturally appropriate for a Japanese audience.
- Make the text concise and to the point.
- Avoid using slang or colloquial expressions.
</output>
</example><example>
<user_input>
I want the translation to have a friendly and approachable tone. Use simple language that can be understood by non-native speakers. Please ensure technical terms are accurately translated.
</user_input>
<output>
- Use a friendly and approachable tone in the translation.
- Use simple language for non-native speakers.
- Ensure technical terms are accurately translated.
</output>
</example>
</examples>
</instructions>

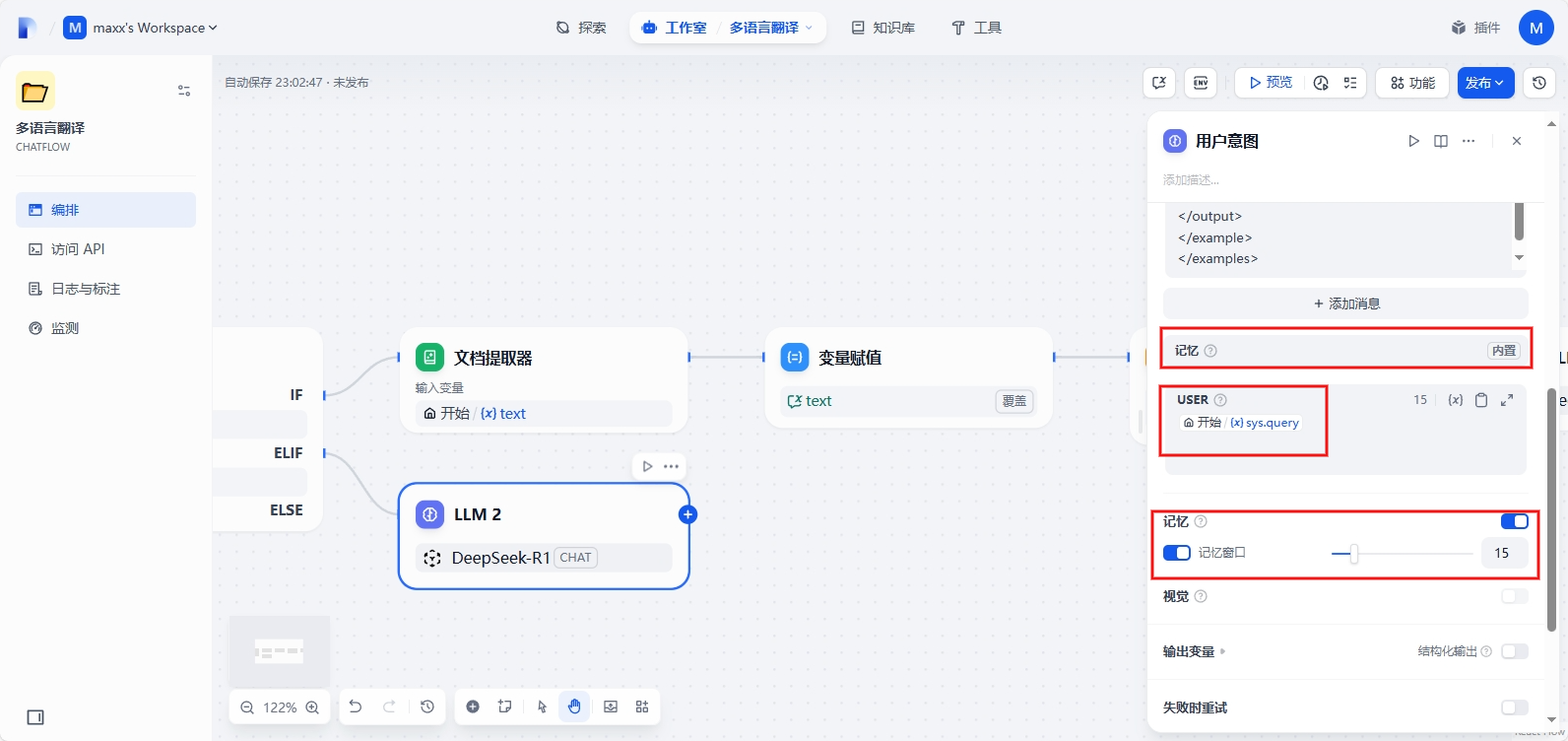
开启聊天记忆功能,记忆窗口调整为15
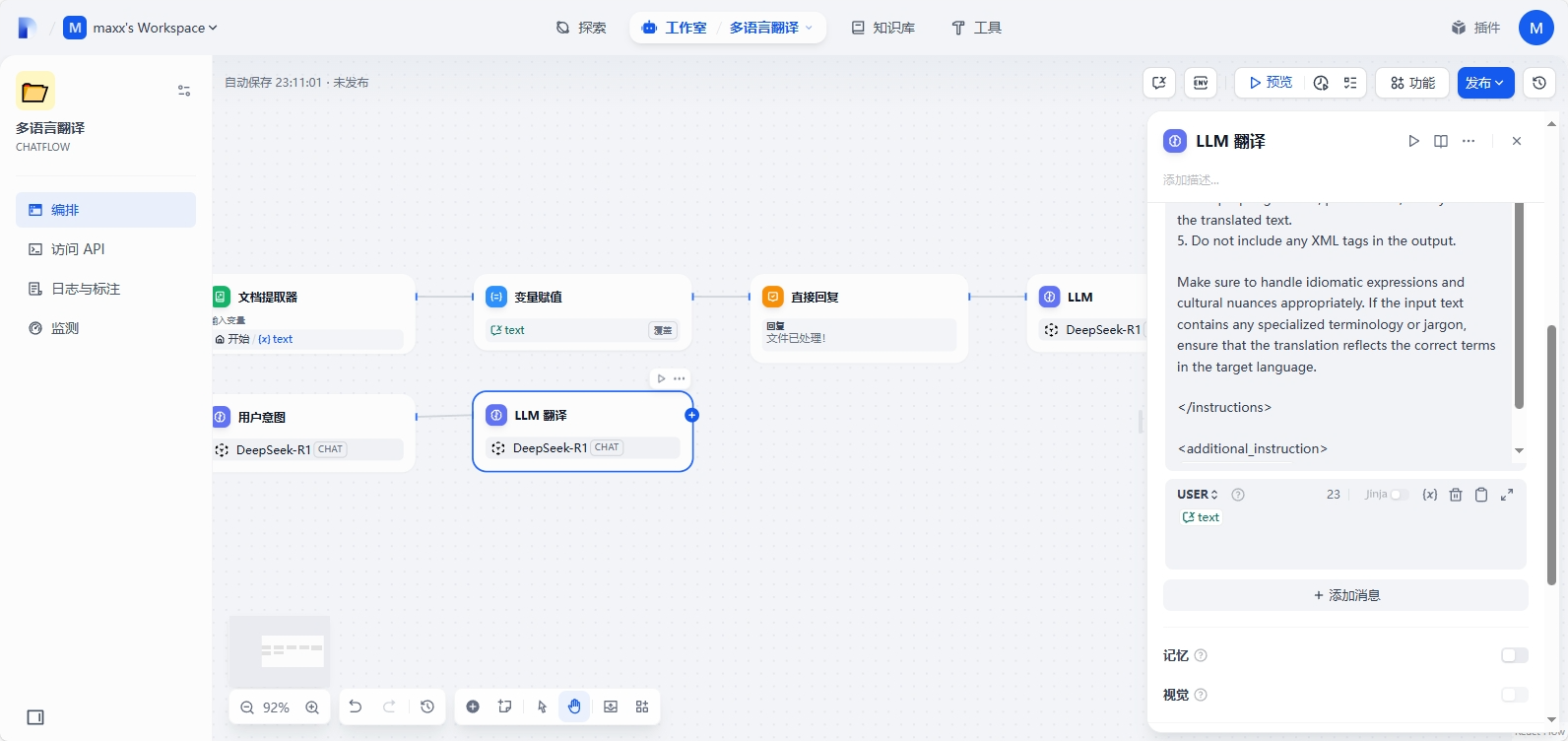
再添加LLM节点,用于重新翻译,输入如下提示词,并添加消息,选择CONVERSATION - text
<instructions>
You are a translator capable of translating multiple languages. Your task is to accurately translate the given text from the source language to the target language specified. Follow these steps to complete the task:1. Identify the source language of the input text.
2. Translate the text into the target language specified.
3. Ensure that the translation maintains the original meaning and context.
4. Use proper grammar, punctuation, and syntax in the translated text.
5. Do not include any XML tags in the output.Make sure to handle idiomatic expressions and cultural nuances appropriately. If the input text contains any specialized terminology or jargon, ensure that the translation reflects the correct terms in the target language.</instructions><additional_instruction>
{{#1749653942013.text#}}
</additional_instruction>
最后节点就是输出结果:LLM - text
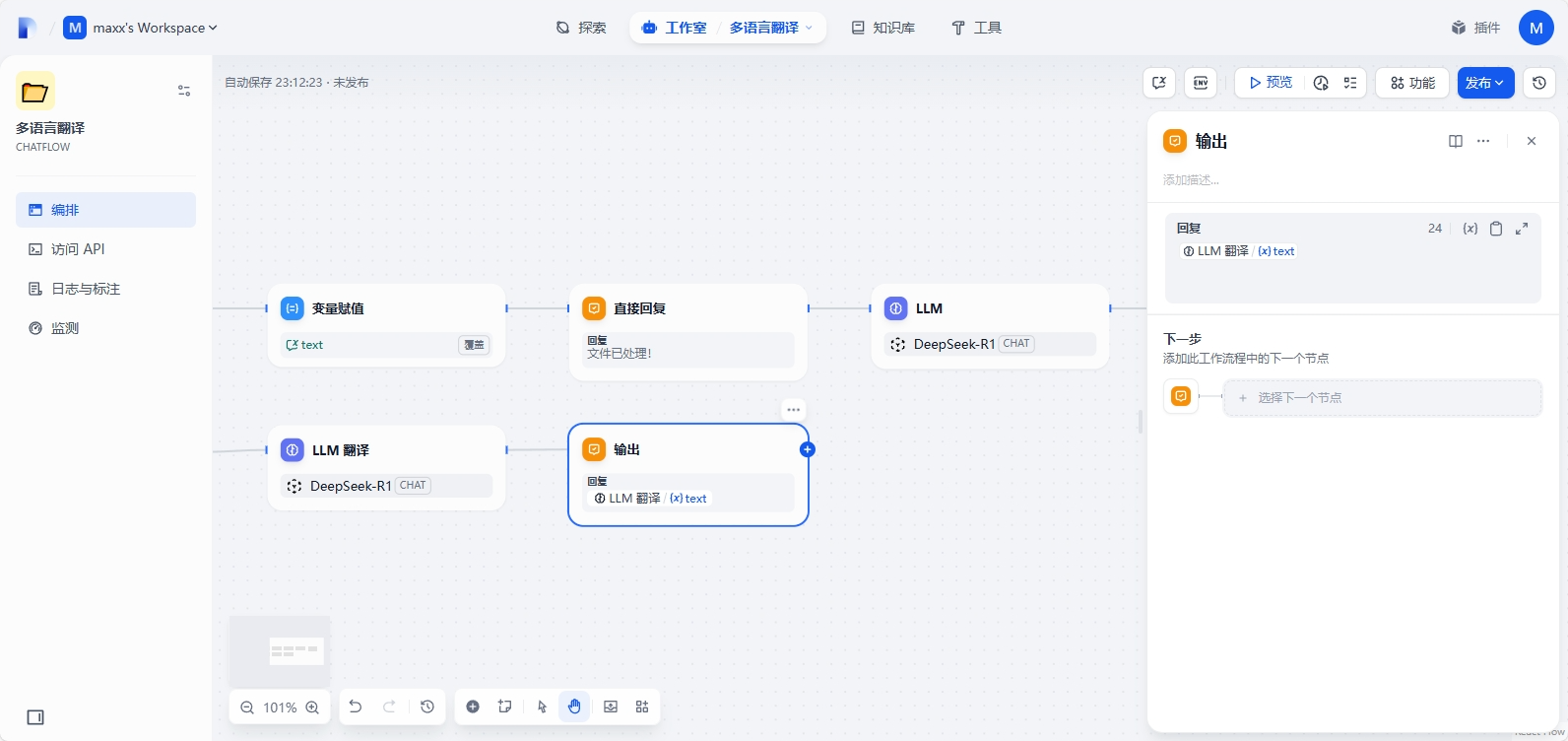
整个 chatflow 编排完成,点击预览,查看效果
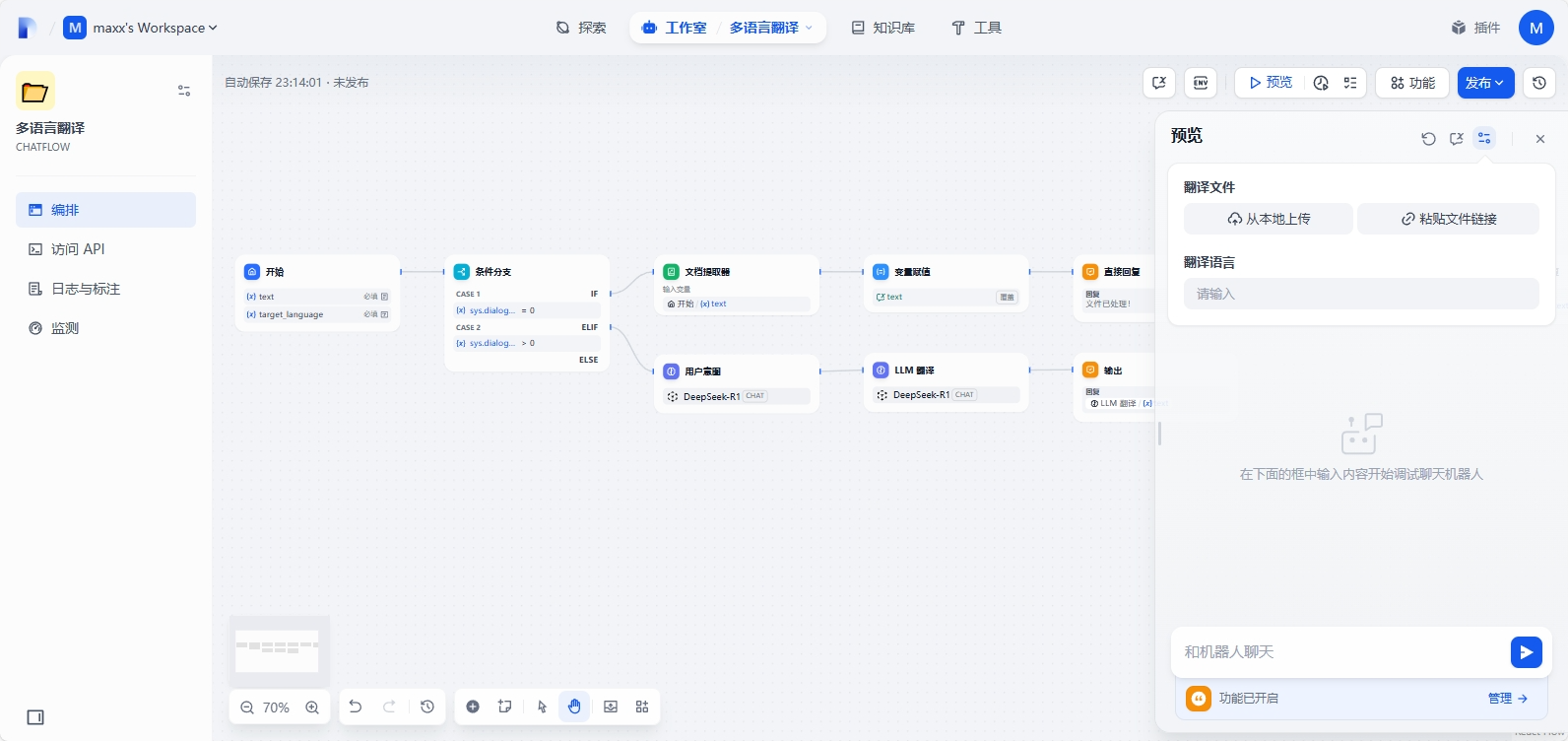
上传文件,输入翻译的语言,在对话框中输入翻译即可
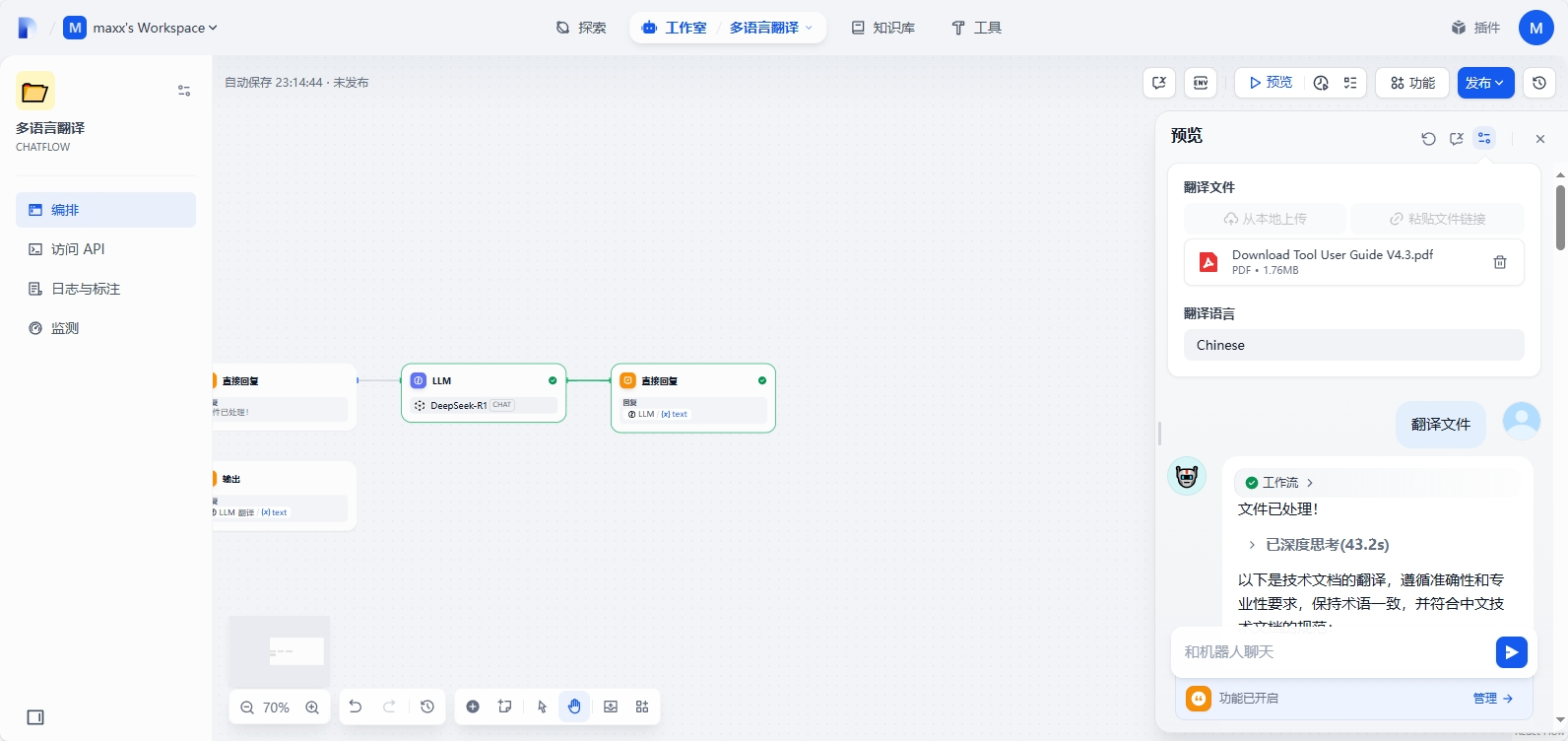
内容不多,但是翻译质量挺高的,并保留了一些英文的术语或缩写,并针对中文阅读习惯优化了表达方式,效果不错,测试完成就可以发布更新到探索页面了!
3.3 使用多语言文件翻译工作流
在探索 - 多语言翻译中开启新对话,上传一份新文件,并翻译成英文

文档提取器过程很快,文件较大时候翻译过程比较耗时,但是翻译质量很高
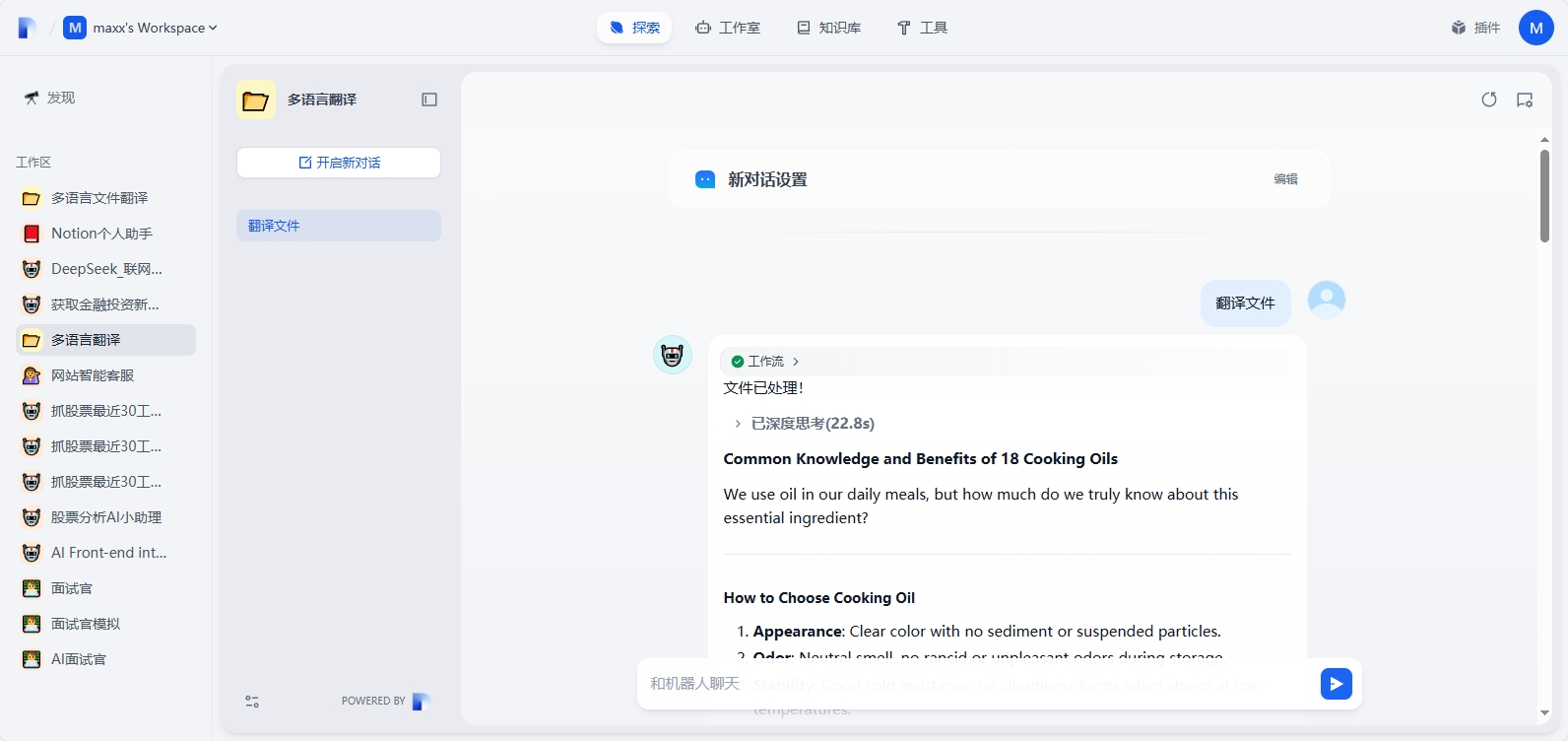
为了验证第二流程,输入用户意图进行二次调整的翻译
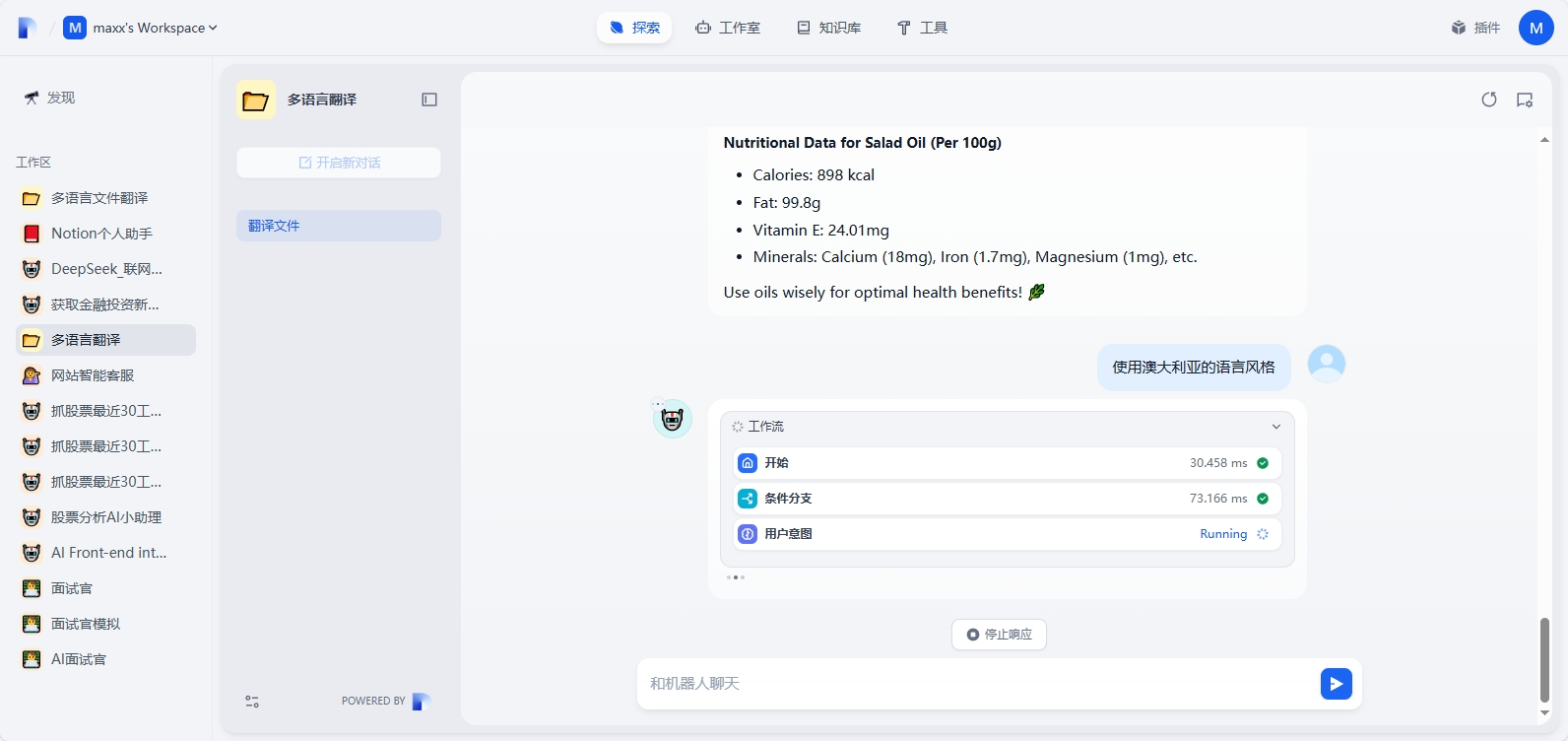
基于DeepSeek的思考过程,可以看出结合用户的反馈进行了调整,再次输出翻译
四、总结
构建多语言文件翻译工作流的解决方案融合了三项核心技术优势,Dify的灵活工作流:可视化编排+模块化扩展,DeepSeek的专业翻译:多语言支持+术语保持,Flexus X的强劲性能:稳定算力+弹性扩展。智能多语言文件翻译工作流有很多实际意义,跨境电商中商品描述多语言同步生成、技术文档中行业术语自动匹配(如医疗/法律领域专业词汇)等。
特别值得一提的是,华为云FlexusX服务器是业界首个X86业务应用智能加速,覆盖网络应用、数据库、虚拟桌面、分析索引、微服务、CI/CD等通用负载场景,最高可达业界同规格6倍性能,保证了多语言文件翻译工作流稳定持久的运行。