参数量计算举例
文章目录
- 参数量计算举例
- 1. 卷积神经网络结构
- 2. 参数量计算
- 2.1 手工计算
- 2.2 使用 .parameters() 进行编程计算
- 2.3 计算内存占用
- 2.4 使用 torchinfo 库
- 3. ADAM 优化器
- 4. 批归一化(BatchNorm)
- 5. 总结
参数量计算举例
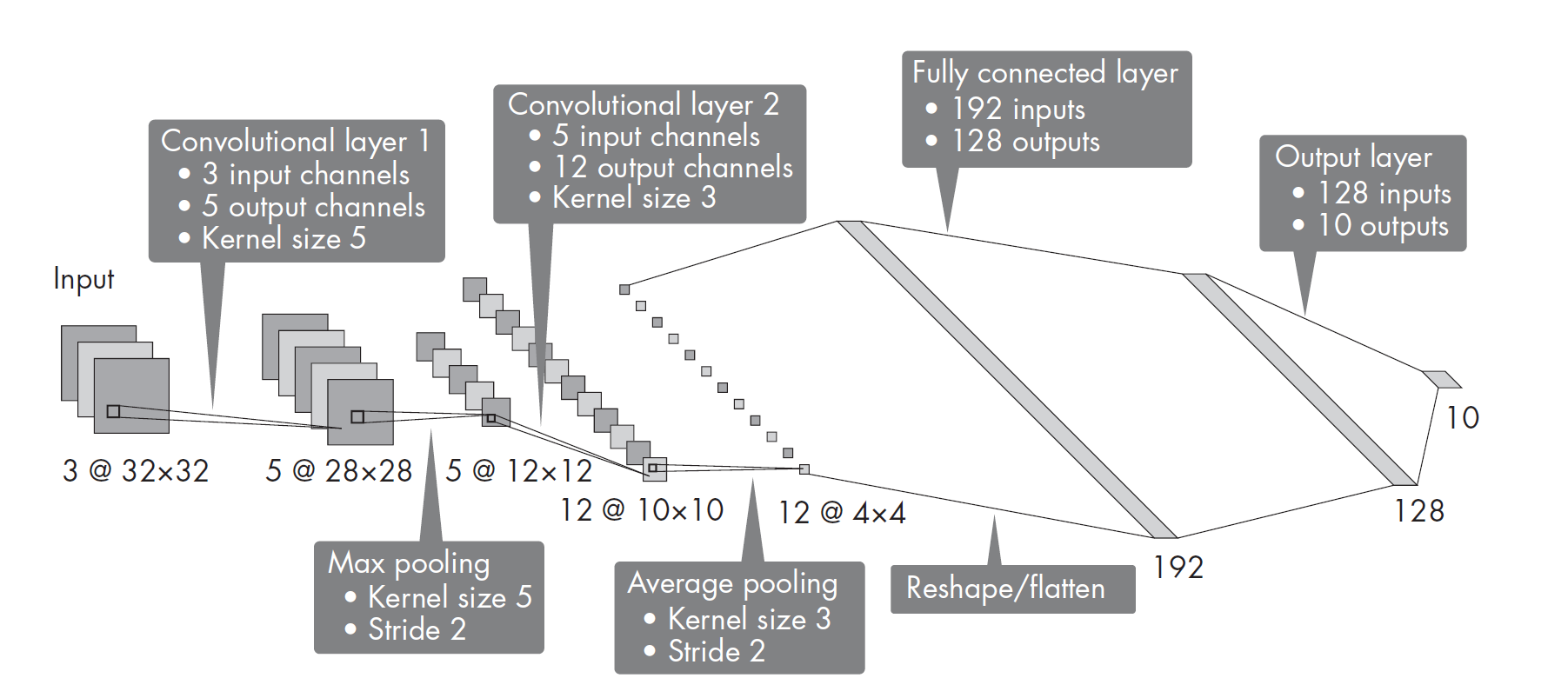
假设我们正在操作一个卷积神经网络,该网络包含两个卷积层,其卷积核尺寸分别是5和3.第一个卷积层有个3个输入通道和5个输出通道,第二个卷积层有5个输入通道和12个输出通道。这些卷积层的步长(stride)均为1.此外,该网络还有两个池化层(最大池化层和平均池化层),其中一个核尺寸为3,步长为2,另一个核尺寸为5,步长也是2。该网络还有两个全连接隐藏层,分别含有192个和128个隐藏单元,而输出层是10个类别的分类层,如下图:
import torch
print(f"PyTorch version: {torch.__version__}")
PyTorch version: 2.7.0+cpu
1. 卷积神经网络结构
class PyTorchCNN(torch.nn.Module):def __init__(self, num_classes):super().__init__()self.num_classes = num_classesself.features = torch.nn.Sequential(torch.nn.Conv2d(3, 5, kernel_size=5, stride=1), # 5 * (5*5 * 3) + 5torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=5, stride=2),torch.nn.Conv2d(5, 12, kernel_size=3, stride=1), # 12 * (3*3 * 5) + 12torch.nn.ReLU(),torch.nn.AvgPool2d(kernel_size=3, stride=2),torch.nn.ReLU(),)self.classifier = torch.nn.Sequential(torch.nn.Flatten(),torch.nn.Linear(192, 128), # 192 * 128 + 128torch.nn.ReLU(),torch.nn.Linear(128, num_classes), # 128 * 10 + 10)def forward(self, x):x = self.features(x)x = self.classifier(x)return x
2. 参数量计算
2.1 手工计算
参考上一篇博客《卷积神经网络参数量计算》,对各部分进行参数量计算。
# 卷积层部分
conv_part = (5 * (5*5 * 3) + 5 ) + ( 12 * (3*3 * 5) + 12 )
print(conv_part)
932
# 全连接层部分
fc_part = 192*128+128 + 128*10+10
print(fc_part)
25994
# 总量
print(conv_part + fc_part)
26926
2.2 使用 .parameters() 进行编程计算
model = PyTorchCNN(10)def count_parameters(model): return sum(p.numel() for p in model.parameters() if p.requires_grad)
# 卷积部分
count_parameters(model.features)
932
# 全连接层部分
count_parameters(model.classifier)
25994
# 参数总量
count_parameters(model)
26926
2.3 计算内存占用
根据参数量,我们可以计算模型的内存占用情况。
import sysdef calculate_size(model): return sum(p.element_size()*p.numel() for p in model.parameters())size_in_bytes = calculate_size(model)
size_in_megabytes = size_in_bytes * 1e-6print(f"{size_in_megabytes: .2f} MB")
0.11 MB
2.4 使用 torchinfo 库
# 使用 https://github.com/TylerYep/torchinfo
# pip install torchinfo 或 uv add torchinfoimport torchinfoprint(f"Torchinfo version: {torchinfo.__version__}")batch_size = 16
torchinfo.summary(model, input_size=(batch_size, 3, 32, 32))
Torchinfo version: 1.8.0==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
PyTorchCNN [16, 10] --
├─Sequential: 1-1 [16, 12, 4, 4] --
│ └─Conv2d: 2-1 [16, 5, 28, 28] 380
│ └─ReLU: 2-2 [16, 5, 28, 28] --
│ └─MaxPool2d: 2-3 [16, 5, 12, 12] --
│ └─Conv2d: 2-4 [16, 12, 10, 10] 552
│ └─ReLU: 2-5 [16, 12, 10, 10] --
│ └─AvgPool2d: 2-6 [16, 12, 4, 4] --
│ └─ReLU: 2-7 [16, 12, 4, 4] --
├─Sequential: 1-2 [16, 10] --
│ └─Flatten: 2-8 [16, 192] --
│ └─Linear: 2-9 [16, 128] 24,704
│ └─ReLU: 2-10 [16, 128] --
│ └─Linear: 2-11 [16, 10] 1,290
==========================================================================================
Total params: 26,926
Trainable params: 26,926
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 6.07
==========================================================================================
Input size (MB): 0.20
Forward/backward pass size (MB): 0.67
Params size (MB): 0.11
Estimated Total Size (MB): 0.98
==========================================================================================
3. ADAM 优化器
使用Adam优化器来优化神经网络,从而缩减需要存储的参数量。
optimizer = torch.optim.Adam(model.parameters())
optimizer.param_groups.count
<function list.count(value, /)>
sum(p.numel() for p in optimizer.param_groups[0]['params'])
26926
4. 批归一化(BatchNorm)
假设在上述的网络中添加三个BatchNorm(批归一化)层,一个置于第一个卷积层之后,一个置于第二个卷积层之后,最后一个接在第一个全连接层之后(一般不应在输出层放置批归一化层)。那么,这三个BatchNorm层会给模型额外增加多少参数?下面用代码说明。
class PyTorchCNN(torch.nn.Module):def __init__(self, num_classes):super().__init__()self.num_classes = num_classesself.features = torch.nn.Sequential(torch.nn.Conv2d(3, 5, kernel_size=5, stride=1),torch.nn.BatchNorm2d(5), # 新增的批归一化层torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=5, stride=2),torch.nn.Conv2d(5, 12, kernel_size=3, stride=1),torch.nn.BatchNorm2d(12), # 新增的批归一化层torch.nn.ReLU(),torch.nn.AvgPool2d(kernel_size=3, stride=2),torch.nn.ReLU(),)self.classifier = torch.nn.Sequential(torch.nn.Flatten(),torch.nn.Linear(192, 128),torch.nn.BatchNorm1d(128), # 新增的批归一化层torch.nn.ReLU(),torch.nn.Linear(128, num_classes),)def forward(self, x):x = self.features(x)x = self.classifier(x)return x
model = PyTorchCNN(10)torchinfo.summary(model, input_size=(batch_size, 3, 32, 32))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
PyTorchCNN [16, 10] --
├─Sequential: 1-1 [16, 12, 4, 4] --
│ └─Conv2d: 2-1 [16, 5, 28, 28] 380
│ └─BatchNorm2d: 2-2 [16, 5, 28, 28] 10
│ └─ReLU: 2-3 [16, 5, 28, 28] --
│ └─MaxPool2d: 2-4 [16, 5, 12, 12] --
│ └─Conv2d: 2-5 [16, 12, 10, 10] 552
│ └─BatchNorm2d: 2-6 [16, 12, 10, 10] 24
│ └─ReLU: 2-7 [16, 12, 10, 10] --
│ └─AvgPool2d: 2-8 [16, 12, 4, 4] --
│ └─ReLU: 2-9 [16, 12, 4, 4] --
├─Sequential: 1-2 [16, 10] --
│ └─Flatten: 2-10 [16, 192] --
│ └─Linear: 2-11 [16, 128] 24,704
│ └─BatchNorm1d: 2-12 [16, 128] 256
│ └─ReLU: 2-13 [16, 128] --
│ └─Linear: 2-14 [16, 10] 1,290
==========================================================================================
Total params: 27,216
Trainable params: 27,216
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 6.07
==========================================================================================
Input size (MB): 0.20
Forward/backward pass size (MB): 1.34
Params size (MB): 0.11
Estimated Total Size (MB): 1.65
==========================================================================================
5. 总结
本文介绍了一个包含卷积层、池化层和全连接层的典型卷积神经网络结构,并详细讲解了各层参数量的手工计算与编程实现。通过 .parameters() 方法和 torchinfo 工具,展示了如何自动统计模型参数量和内存占用。随后,介绍了Adam优化器的参数管理方式,并分析了添加批归一化(BatchNorm)层后对参数量的影响。整体流程涵盖了模型结构设计、参数量与内存计算、优化器使用及正则化方法,为理解和实践深度学习模型的参数管理提供了系统的参考。