【强化学习】TD-MPC论文解读
文章目录
- 前言
- 一、总体概述/创新贡献
- 二、算法inference的前提知识(MPC、CEM)
- cem知识
- mpc知识(MPPI)
- 三、算法inference
- 四、算法训练前提知识(TD)
- 五、算法训练(training)
- 六、总结
前言
探究论文TD-MPC的原理。
论文:https://arxiv.org/pdf/2203.04955
代码:https://github.com/nicklashansen/tdmpc
一、总体概述/创新贡献
此论文的创新点主要是这样:
基于数据驱动的模型预测控制(MPC)相较于无模型方法有两个关键优势:通过模型学习提高样本效率的潜力,以及随着规划计算预算的增加表现更佳。
有模型的环境下可以使用的算法(有RL算法也有不是RL的算法):如下表的MPC,POLO,LOOP,PLaNet,Dreamer,MuZero,EfficientZero,需要的计算资源高。
无模型环境下的RL算法:SAC,QT-Opt(适合于连续动作空间的DQN算法),样本效率低,不能随着规划计算预算的增加表现更好。
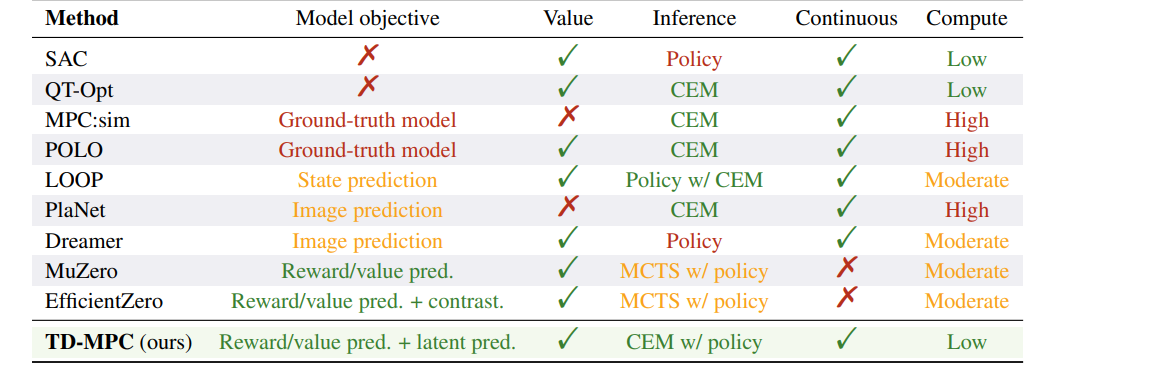
注:
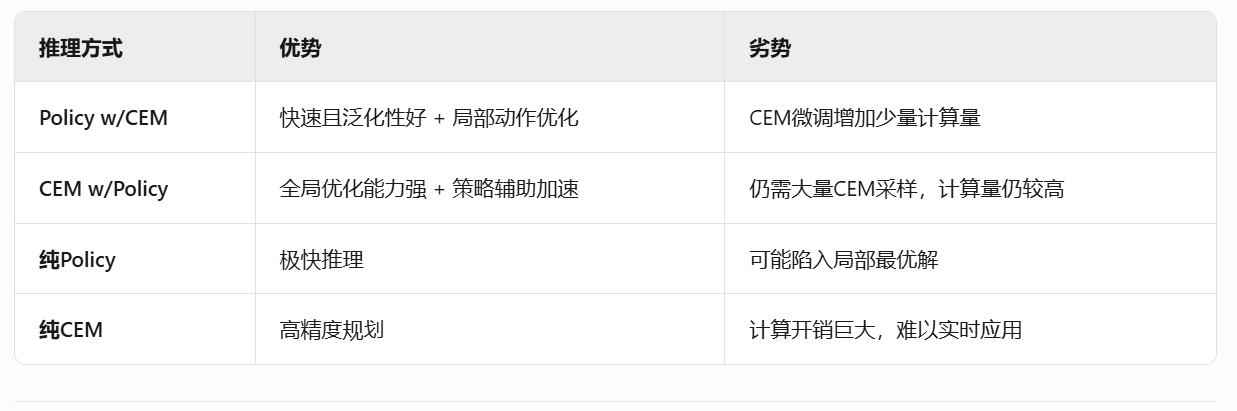
上两表由AI生成,可参考,但是这里的CEM w/policy 的劣势可能不准确(要看与哪个算法比),例如下表,walk环境下,与同样的模型算法LOOP比,推理速度快16倍,训练速度快3倍,但是与SAC比推理速度差不多,但是训练速度慢了4倍
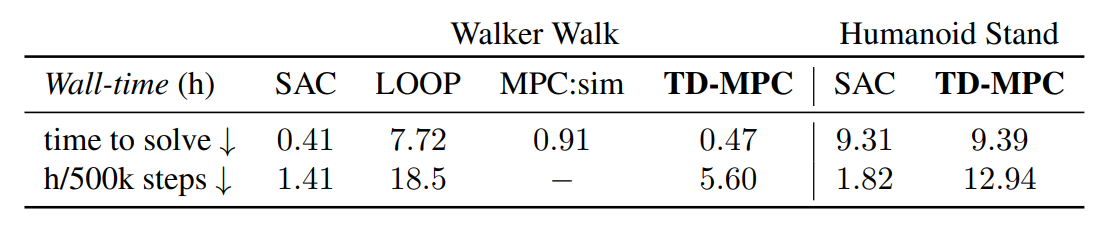
而提出的TD-MPC就结合了这两个优点。
效果:
DMControl 和 MetaWorld 的基于状态和基于图像的连续控制任务上,相较于先前工作,实现了更优的样本效率和渐近性能。(摘要)
是首个解决 DMControl 复杂 Dog 任务的文献记录结果。(文中)
能够在各种连续控制任务上超越基于模型和无模型的方法,并且(经过微小的修改)同时匹配基于图像的 RL 任务的当前最佳水平,
是。(总结)
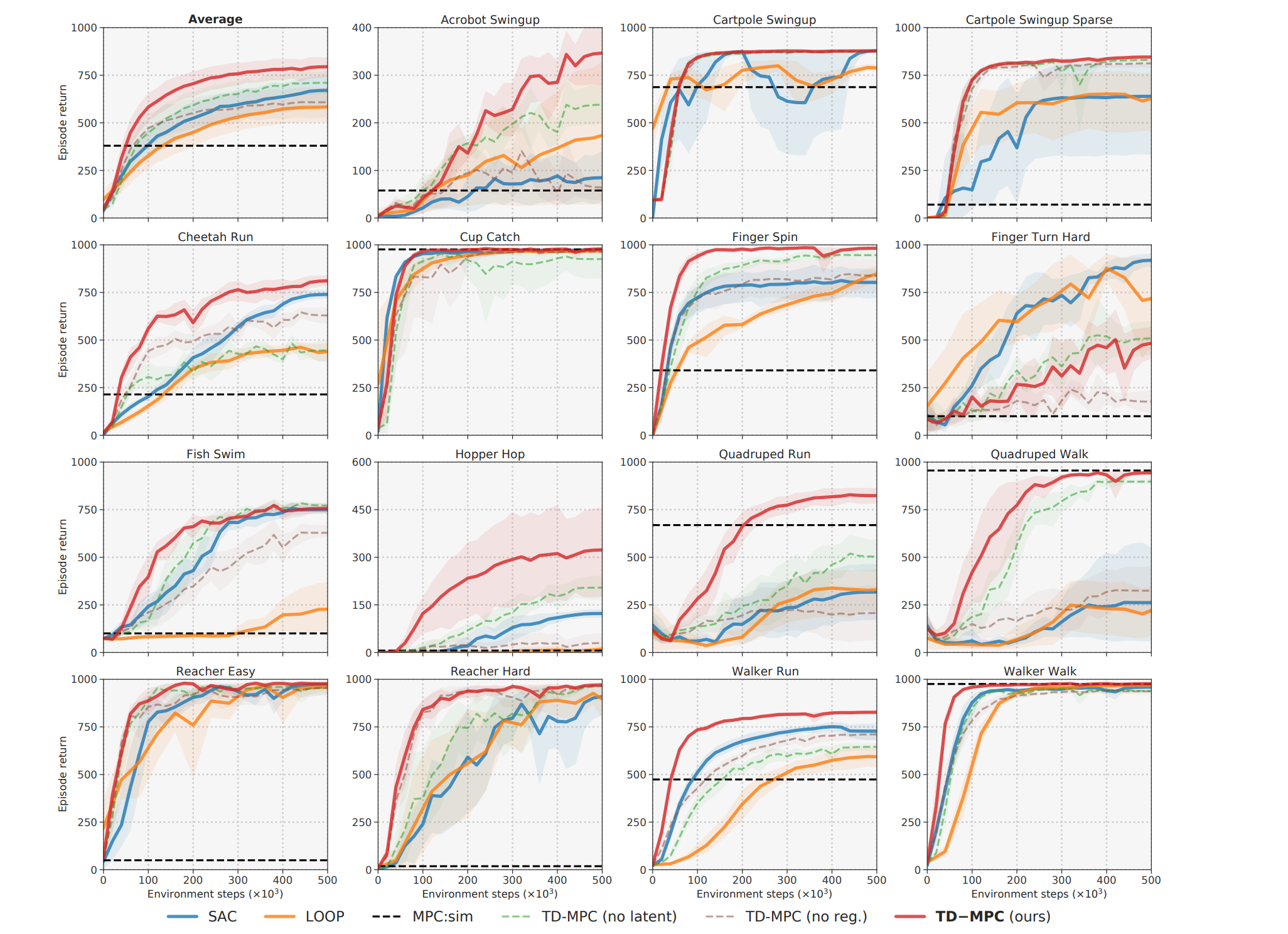
可以看出,大部分的确效果更好,也都能在500k个step完成任务,确实实现了样本效率的提高,代价是训练的时间会略微增加,如果我们给SAC相同的时间,可能SAC的效果也不会差。
不过我后来查看了TD-MPC2版本的论文https://arxiv.org/pdf/2310.16828,由重复的环境,扩大训练步数的实验,SAC部分环境还是没能收敛,所以此算法确实比较好在当时。
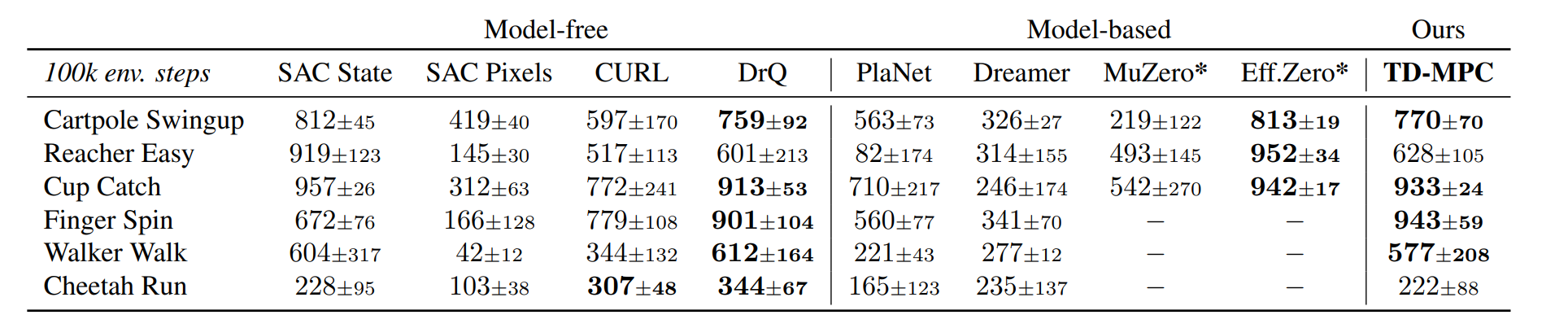
与专门用于增强图像的基于视觉的强化学习对比也有不错的性能。
二、算法inference的前提知识(MPC、CEM)
cem知识
CEM cross-entropy method算法理解
具体想法:
第一步: 假设输入为obs(ob1, ob2, ob3, ob4 … ob_10), action 为5位,如果策略就是一个一层的神经网络,那么需要参数W 和 b, W为10 * 5,b为5 * 1. 总的参数个数就是 10 * 5 + 5 * 1 = 55个参数。 初始化均值为0,标准差为1,通过随机生成一个batch,例如n=100个参数组, 然后把这100个参数组丢到环境里面看,前20%reward最高的参数组是哪些。
然后,根据这前20%参数组,重新计算下均值和标准差,然后基于这个新的标准差,重复第一步的过程,不断循环。正常情况下 一代比一代好,最后效果就很好。 当然理论上证明收敛还不太清楚。–来自CEM cross-entropy method算法理解
伪代码如下:

import numpy as npdef cem_optimize(f, dim, n_iter=100, n_samples=100, elite_frac=0.2, noise=0.01):# 初始化分布参数mu = np.zeros(dim)sigma = np.ones(dim)for _ in range(n_iter):# 采样候选解samples = mu + sigma * np.random.randn(n_samples, dim)# 评估并选择精英样本scores = np.array([f(s) for s in samples])elite_ids = scores.argsort()[-int(n_samples * elite_frac):]elite_samples = samples[elite_ids]# 更新分布参数mu = elite_samples.mean(axis=0)sigma = elite_samples.std(axis=0) + noisereturn mu # 返回最优解
和强化学习的联想:
也就是说cem的这里的均值mu 可以代表为强化学习中的采样的均值
samples可以为强化学习中采样的轨迹
scores 可以为强化学习中的价值的一类用来打分的东西
mpc知识(MPPI)
MPPI的论文:https://arxiv.org/pdf/1509.01149
MPPI 是一种 MPC 算法,它通过使用估计的预期回报最高的 k 条采样轨迹的重要性加权平均值来迭代更新参数族。
伪代码

其中上面的更新均值对应于论文中这里的更新均值,加权算术平均值及其标准差。

下面是AI写的一个简单的例子,用来简单说明
'''以下代码模拟一个2D小车从起点到目标点的轨迹优化(状态:位置x,y;控制:速度vx,vy)'''
import numpy as np# 参数设置
num_samples = 100 # 采样轨迹数
horizon = 20 # 预测步长
gamma = 0.1 # 温度参数# 初始状态和控制序列
current_state = np.array([0, 0])
target = np.array([5, 5])
u_sequence = np.zeros((horizon, 2)) # 初始控制序列(全0)# 动力学模型(简单线性模型)
def dynamics(state, u):return state + u # 下一状态 = 当前状态 + 控制输入# 代价函数:距离目标越近代价越低
def cost_trajectory(states):return np.sum([np.linalg.norm(s - target) for s in states])# MPPI 单步优化
def mppi_step(state, u_sequence):total_cost = 0weighted_u = np.zeros_like(u_sequence)for k in range(num_samples):noise = np.random.normal(0, 1, (horizon, 2)) # 生成随机噪声perturbed_u = u_sequence + noise# 模拟轨迹states = [state]for t in range(horizon):next_state = dynamics(states[-1], perturbed_u[t])states.append(next_state)# 计算轨迹代价cost = cost_trajectory(states)weight = np.exp(-gamma * cost)# 累加加权控制weighted_u += weight * perturbed_utotal_cost += weight# 更新控制序列new_u_sequence = weighted_u / total_costreturn new_u_sequence# 运行10步
for step in range(1000):u_sequence = mppi_step(current_state, u_sequence)current_state = dynamics(current_state, u_sequence[0]) # 执行第一步控制print(f"Step {step}: State={current_state}, Cost={np.linalg.norm(current_state - target):.2f}")
这里生成的new_u_sequence可以看作是动作序列[a1,a2…],其中horizon 为这个动作序列的长度,这里的动作序列正好可以充当上述cem的samples。可以看成强化学习的一个轨迹的动作序列。
cost可以看成强化学习中当前状态价值和最好状态价值的差值之类的东西
这里的weight 为每个num_samples的加权系数,就是上文论文中的Ω_i。
(若是将这里每个sample的weight放入一个列表再除以这个权重的和就可以得到这个权重的分布,[weight1,weight2,…] / sum(weight_list),即:Ω)
perturbed_u 为动作序列[a1,a2…]
gamma 即温度系数,即论文中的 τ,高温度:更平坦的分布,更多探索 低温度:更尖锐的分布,更多利用
dynamics为动力学模型,可以看成强化学习的一个model,用来从表示状态加上动作后的一个输出
三、算法inference
然后这里的论文就根据以上两个知识,自创了一个inference,就像下面的这里的发散部分
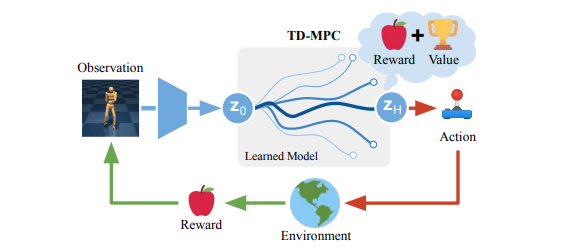
可以这么想:
cem是通过迭代随机动作的序列,找到最优的几个动作来优化均值和方差来输出动作的均值。
mppi是根据随机动作的序列(预测后几步的动作)来生成随机的状态轨迹,根据每个轨迹的代价,来生成一个加权权重的动作序列,然后选取第一个动作。
(这里权重:weight = np.exp(-gamma * cost))
然后作者思想是在cem的框架下加入MPPI和policy

Require:首先初始化cem/mppi的mean,std,mppi要用到的H,N,N_pi,以及强化学习要用到的policy和state
(这里将MPPI和cem的mean和std合并了,将MPPI的mean和std的更新公式替代了cem的,使其从优化action的mean和std,转变为优化mean和std而得到更好的用来cem迭代的轨动作序列)
1.这里使用了论文提出的TOLD模型里的h函数来进行一个表征学习(将state/pixel统一学习为一个潜在层)
TOLD里的模型其实和正常的强化学习模型没多大区别,只是方便代码上的书写
2.大框架使用cem的迭代式框架
3.生成N个长度为H的动作序列轨迹,这里使用mppi的类似samples,每次迭代使用更新后的均值和方差,来生成新的动作序列
4.使用策略和动力学模型来生成生成N个长度为H的动作序列轨迹,每次cem的迭代都一样
5-9。根据生成的每个轨迹,使用奖励模型(用来预测未来的奖励)和Q函数来计算当前的奖励值(或者说这几步之后得到的终值奖励)。
在这一部分,有点像n步step的思想
(省略的部分:根据这些奖励值,选取前k个最好的,将前k个奖励最好的-这里面最大的奖励作为轨迹代价,来优化mppi的均值和方差
)
10:根据mppi思想更新均值和方差。(还使用了动量更新的方法来更新mean)
(省略的部分:迭代完后,根据代价值得到的归一化分布来采样一条轨迹,将此轨迹的第一个动作值作为均值,mppi更新的std来作为方差,来随机一个动作推理,有点类似于ddpg,但是加一个双q截断的trick)
注:这里为什么是需要采样一条而mppi不需要?
elite_actions是sample的个数和原始的mppi的是horizon,不一样(需对比上述mppi知识的代码和原代码)
这里作者改完后,这个mppi像是在从n个轨迹根据来优化出一个轨迹,变成了从n个轨迹优化出前k个较好的轨迹。
公式(5):为了促进在不同的任务中有一致的泰索,这里加了约束
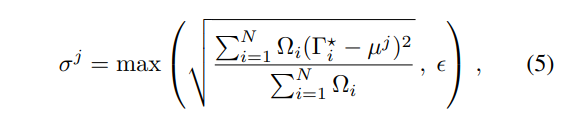
四、算法训练前提知识(TD)
《动手学强化学习》–时序差分方法

多步时序差分


五、算法训练(training)

首先:初始化网络和目标网络
η, τ,分别为学习率和目标网络的更新率,
λ为系数,是一个常数,它使近期预测的权重更高(注意这个不是折扣率,在代码里折扣率和这个值分开来的)
B为buffer,这里buffer为PER buffer(根据TD误差优先级来采样,误差高的采样优先级高)
1-6 为环境交互
8:每个片段段都更新(达到随机步数时为更新随机步数次,否则为更新片段长度次)
9:采样batch_size个H(步长)长度的片段
10:将第一个状态编码
11:损失值置为0
12-17:使用学习到的奖励模型(预测奖励的),Q网络模型,动态动力学模型(mppi中要学习的),策略函数,来计算(H步的)损失值。
18:取H步的平均损失值来优化模型,
19:更新目标网络模型
其中更新的损失公式如下:


这里的reward模型®优化相当于学习一个预测此环境的奖励模型
动力学模型(d)其实就是学习下一个状态的表征。
策略的实际更新为公式11,代码中实际是先更新了(critic+其他)模型,再更新了策略模型,所以这里伪代码可以说是少写了一步。
反观这个多步时序差分,在training中并没有使用,而是在inference中实现了
(摘自TDMPC类的update函数(training部分))
for t in range(self.cfg.horizon): # 第12行# PredictionsQ1, Q2 = self.model.Q(z, action[t])z, reward_pred = self.model.next(z, action[t])with torch.no_grad():next_obs = self.aug(next_obses[t])next_z = self.model_target.h(next_obs)td_target = self._td_target(next_obs, reward[t])zs.append(z.detach())# Lossesrho = (self.cfg.rho ** t)consistency_loss += rho * torch.mean(h.mse(z, next_z), dim=1, keepdim=True)reward_loss += rho * h.mse(reward_pred, reward[t])value_loss += rho * (h.mse(Q1, td_target) + h.mse(Q2, td_target))priority_loss += rho * (h.l1(Q1, td_target) + h.l1(Q2, td_target)) # l1 绝对误差 相当于计算td误差
这里是计算每步预测的价值/奖励/下一步状态的损失值来更新模型。
这里的rho,则是论文中λ,应该是新创的,类似于折扣率,但是这里不表示折扣率,两者在代码中分开来表示
多步时序差分 是累计步数的真实奖励来估计
而在inference中用来计算估计回报时,则用到了实际上的多步时序差分。
@torch.no_grad()def estimate_value(self, z, actions, horizon):"""Estimate value of a trajectory starting at latent state z and executing given actions."""# 对应论文公式3G, discount = 0, 1for t in range(horizon):z, reward = self.model.next(z, actions[t])G += discount * rewarddiscount *= self.cfg.discountG += discount * torch.min(*self.model.Q(z, self.model.pi(z, self.cfg.min_std)))return Gcem来筛选精英轨迹时用到
# Compute elite actionsvalue = self.estimate_value(z, actions, horizon).nan_to_num_(0) #对应论文公式3 滚动生成回报 伪代码第6,7,8,9行elite_idxs = torch.topk(value.squeeze(1), self.cfg.num_elites, dim=0).indices #elite_value, elite_actions = value[elite_idxs], actions[:, elite_idxs] # 提出前N个最优轨迹
六、总结
看了论文和代码后,感觉这个
算法= DDPG (带有双q截断trick)+ cem + MPC (这两个用来实际推理,策略则辅助推理) + 表征学习(不知道这个说法是否正确) + PER_buffer
其中学习的模型:
critic
actor
d (mpc的动力学模型)
h (表征模型)
r (奖励模型)
算法上没有收敛证明,但是可以理解的过去,实验做的效果也很好。
但是一些遗传算法/启发式算法实际上也没有理论性的证明,实际上效果也是很好。
由于这个代码只给了内置的环境,环境不好自定义,所以之后再看tdmpc2的代码,看如何运用到自己的环境上。