从0开始学习R语言--Day20--Wilcoxon秩和检验
Wilcoxon秩和检验
当数据不满足正态分布时,我们常常会苦恼于如何处理数据。即使是用缩进的方法,把数据缩进到(1-99%)或(1-95%)的范围内,假如有一些数据点集中在数据分布的尾端,这依然会影响到我们对数据特点的判断,尤其是需要探寻数据组之间的联系或关系的时候。
而实际上,假设我们要探究的不是数据在统计上的数值关系,而是因果关系或比较,我们可以把数据处理成秩次的形式,从而去对比数据组,这样相当于把数据的分布都固定下来,也就相当于去对比两组数据的中位数了。
要注意的是,使用这个方法的前提是对比的数据之间要相互独立,不能是分类数据,在使用前要核对数据量的差别不能太大,统一好单位,避免无关的变量影响结果。
以下是一个例子:
# 生成两组数据(假设A组和B组)
set.seed(123) # 确保结果可重复
group_A <- rnorm(30, mean = 50, sd = 10) # A组:均值50,标准差10
group_B <- rnorm(35, mean = 60, sd = 12) # B组:均值60,标准差12# 创建数据框
data <- data.frame(value = c(group_A, group_B),group = factor(rep(c("A", "B"), times = c(30, 35))))head(data) # 查看前6行boxplot(value ~ group, data = data, col = c("lightblue", "pink"),main = "Comparison of Group A and B",xlab = "Group", ylab = "Value")# 方法1:直接输入两组数据
wilcox.test(group_A, group_B)# 方法2:使用公式(推荐)
wilcox.test(value ~ group, data = data)# 输出结果解读:
# p-value < 0.05 表示两组中位数差异显著
# W值:秩和统计量输出:
Wilcoxon rank sum exact testdata: value by group
W = 211, p-value = 1.819e-05
alternative hypothesis: true location shift is not equal to 0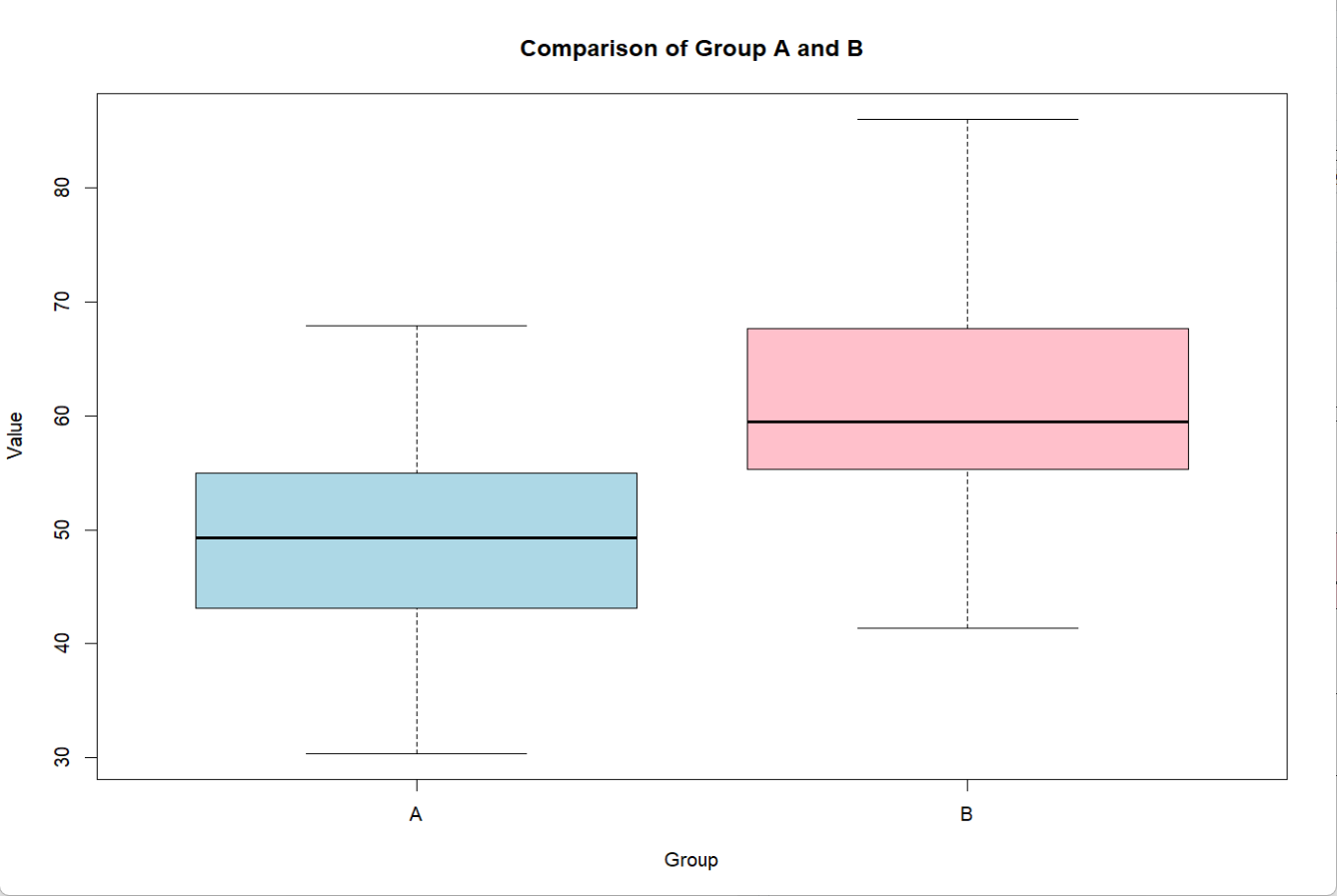
从结果可以看到,p值远小于0.05,所画的箱线图也证明了A、B组的差异比较明显,中位数相差了10。