MySQL 知识小结(一)
一、my.cnf配置详解
我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们MySQL数据库,不过这也是企业中常常使用的,我们通常会将这些配置文件自定义好之后,然后就进行编译。
当完成了MySQL安装之后,我们会生成一个My.cnf类型文件,那么这些数据目录又是如何分配的呢?又是如何存放的呢?带着这个问题,咱们来分析下配置。
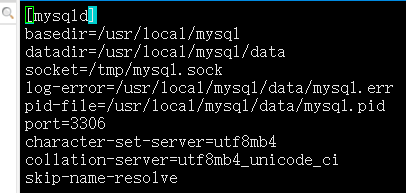
- basedir:即显示了分配的MySQL的安装目录,它存放在/usr/local/mysql目录下
- datadir :这里面指定了数据库的存储目录,数据库的表,索引等机制都存储于该目录下,当我们创建一个新的数据表,相关的数据库文件就会被写入到/usr/local/mysql /data目录以及它的子目录下
- socket=/tmp/mysql.socket,这个文件又叫做一个套接字文件,这个文件能快速帮助本地客户端快速的与MySQL服务端建立连接,进行交互,而无需通过网路层协议
- log-error文件中存储了MySQL服务器错误日志文件的径,但MySQL在运行期间遇到了报错,警告或其他重要事件时,那么相关信息会记录到这个日志文件中
- pid-file:存放着MYSQL服l务进程的进程ID文件的路径。用户可以通过这个文件中的PID来管理MySQL服务进程,启动或停止MySQl服务
二、MySQL引擎
定义:也叫存储引擎,是MySQL处理数据存储的核心组件,它指定了数据库如何进行存储,如何检索数据相关特性。
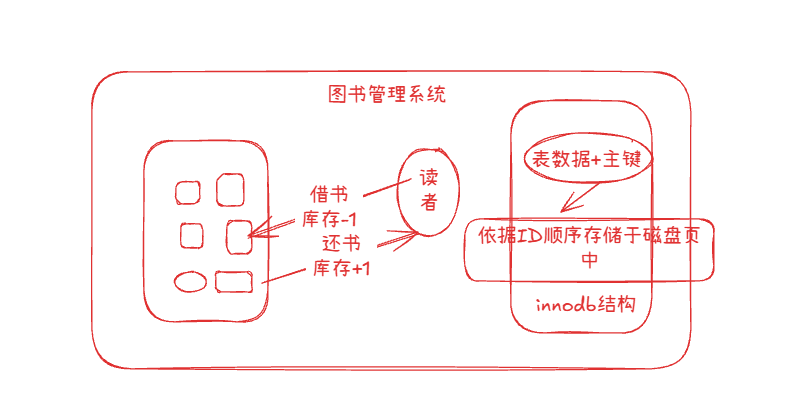
拿我们生活中的例子来说吧,一个图书管理系统采用的是InnoDB结构,当读者借阅图书时,需要进行图书借阅情况的记录,同一本书可能被多人预约,但是为了保准其数据的准确性,,避免超借,此时就需要保证借书和还书数据的一致性(借书时库存减少,还书时库存增加)
那么最终这个管理系统究竟又是如何来确保借书情况的一致性,这里我们就不得不探讨一下MSQL存储引擎的原理了
1.数据存储与组织
Innodb:即将数据和和索引的情况存储在聚集索引中,表数据和主键索引紧密关联在一起形成了一个表(id,name,gender)等字段,InnoDB会根据id的顺序进行数据存储在磁盘页中,这种存储方式基于主键进行查询,具有很高续写性,因为字段中都引入了主键索引,就可以快速的定位到相应的数据行。
采用MyISAM形式进行存储,将数据文件和索引文件分开存储,它有三个文件,.frm文件存储表的结构,.MYD文件存储数据(图书信息查询,适合读多写少的场景),从而根据条件进行查询,.MYI文件存储索引,也就是某个字段建立的索引会存储在.MYD文件中,这个件使得MyISAM在一些只读或读多写少场景下表现更好。
MySQL数据库在服务启动前,需要选择启动引擎,就好比一辆小车,性能好的发动机往往会提升其小车的性能,从而使得启动、运行更加高效,同样,MySQL它也有着类似于发动机引擎。
MySQL引擎包括ISAM,MyISAM,InnoDB,MEMORY等,其中MyISAM,InnoDB使用最为广泛.
| 引擎特性 | MyISAM(MySQL 5.0之前默认引擎) | InnoDB |
| 集群索引 | 不支持 | 支持 |
| 硬盘空间使用 | 低 | 高 |
| 外键支持 | 不支持 | 支持 |
| 事务安全 | 不支持 | 支持 |
| 锁机制 | 表锁 | 行锁 |
2.事务性存储
InnoDB属于事务性数据库的引擎,支持ACID事务
ACID包括:原子性(Automaticity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。其中一个支持事务的数据库,必须具备其四个特性,否则无法再执行数据时,确保其数据额的正确性
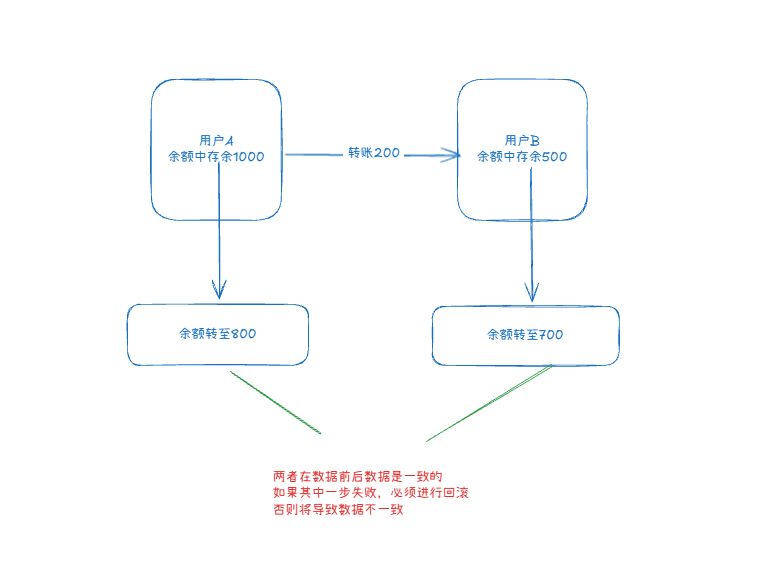
一致性(Consistency)
事务在开始前和结束后,事物的完整性约束都没有被破坏,代表着底层数据的完整性
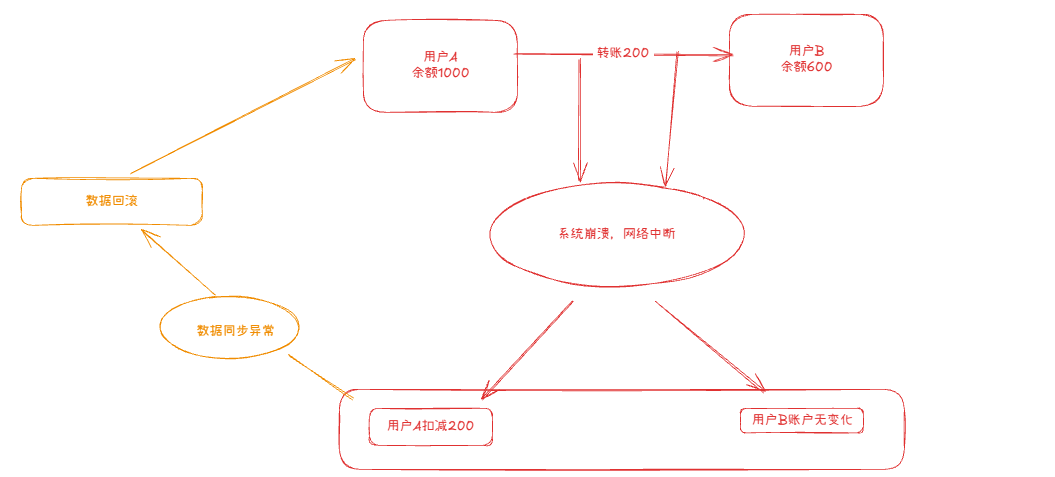
原子性(Automiticity)
事务是一个不可分割的工作单元,事务的操作要么同时执行,要么同时不执行
隔离性(Isolation)
多个事务并发访问时,事务之间的隔离机制是相互隔离的,一个事务不该影响到其他事务的运行效果,这意味着事务必须在不干扰其他进程或事务的前提下独立运行
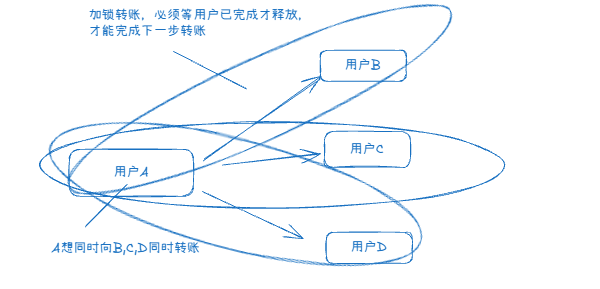
事务并发性隔离机制存在问题(脏读、幻读、不可重复读)
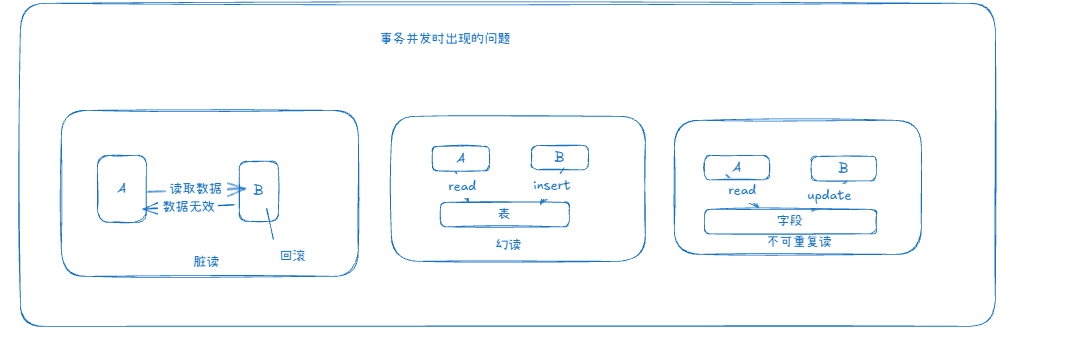
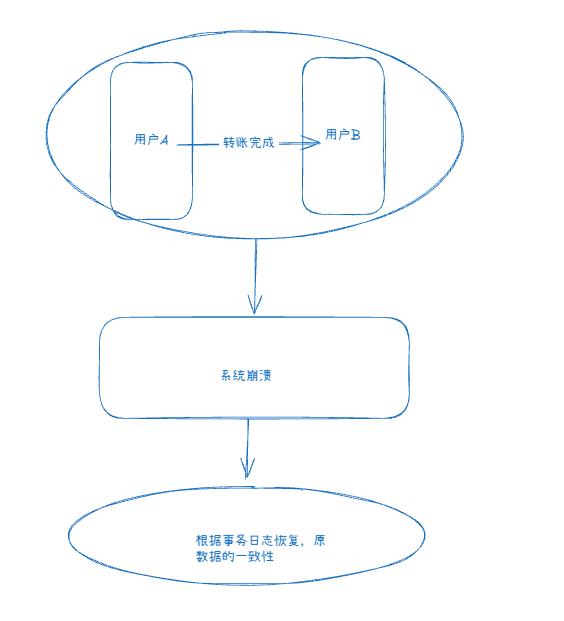
持久性(Durability)事务一旦提交,即使系统崩溃,数据也不会丢失
该事务对数据库的更改是持久保存在数据库中的,一旦数据提交,将持久保存在数据库中
InnoDB通过事务日志(read_log)来保证其持久性
三、MySQL基础用法
建库建表语句
建库语句
-- MySQL启动命令:
mysql -u root -p-- 查看用户和主机:
select user();-- 显示所有数据:
show databases;-- 创建新数据库
create database test_db;-- 删除数据库
drop database test_db;-- 使用数据库
use test_db;-- 显示当前使用数据库
select database();-- 显示当前数据库所有表
show tables;
建表语句
设计如下情况的数据表结构:
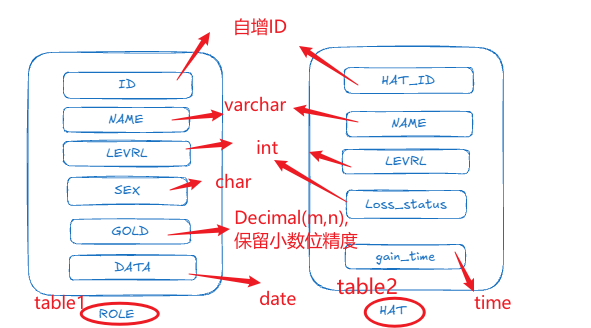
-- ROLE表的创建
CREATE TABLE ROLE (id INT AUTO_INCREMENT PRIMARY KEY,NAME VARCHAR(50) NOT NULL,LEVEL INT,SEX CHAR(1),GOLD DECIMAL(10,2), Birth_data DATE
);-- HAT表的创建
CREATE TABLE HAT (HAT_id INT AUTO_INCREMENT PRIMARY KEY,NAME VARCHAR(50) NOT NULL,LEVEL INT,Loss_status varchar(1),gain_time time
);关于数据库表内容的增、删、改、查分析
插入数据
-- 单条数据插入
INSERT INTO ROLE(NAME,LEVEL,SEX,GOLD,Birth_data)VALUES('z3',3,'男','6666.88','2025-06-09');-- 多条数据插入
INSERT INTO HAT(NAME,LEVEL,Loss_status,gain_time)VALUES('一级头盔',1,0,NOW()),
('三级头盔',3,0,NOW()+1);
查询数据
-- 查看表数据
select * from ROLE;
select * from HAT;-- 条件查询(查询姓名为z3任务的详细情况)
select * from ROLE where name='z3';-- 范围区间查询select * from ROLE where gold between 6000 and 10000;-- 分页查询
-- 1.限制返回0-5条记录
select * from ROLE limit 5 OFFSET 0;
-- 2.限制返回6-10条记录
select * from ROLE limit 5 OFFSET 5;-- 模糊查询(模糊匹配),查询名字中包含z的数据和含有z匹配字段
select * from ROLE where name like '%z%';
select * from ROLE where name like 'z_';-- 聚合函数使用
-- count()、avg()、MAX()、MIN(),结合having和group by分组使用
-- 按人物的等级进行分组,筛选并过滤出平均分大于6666的人
select avg(gold) as avg_gold from role group by level having avg_gold>=6666 修改数据
-- 更新单个字段
update ROLE set GOLD=99999.99 where name='z3';-- 更新多个字段
update ROLE set gold=33333.33,level=8 where name='z3';
删除数据
-- 删除特定数据
delete from ROLE where name='z3';-- 删除所有数据
delete from ROLE;-- 假如误删表的数据了,如何恢复?
-- 1.停止所有写操作
flush tables with read lock;
-- 2.确认删除范围
show binlog events; -- 查询最近操作
-- mysql -uroot -p test_db<backuofile.sql
关于数据库表结构的增删改
-- 增加表中列的相关信息
alter table ROLE add column message varchar(100);-- 修改表中列的相关信息
alter table ROLE modify column gold decimal(12,3);-- 删除表中列的相关信息
alter table ROLE drop column message;-- 重命名表
rename table ROLE to user;三、多表关系构建
就拿员工、部门、项目表三张表表示其表关系如下图所示

数据表结构导入
这里以员工表、部门表、项目表三者为关系来构建
-- 一对多关系的构建(即员工和部门间的关系)-- 创建部门表
create employee(dept_id INT PRIMARY KEY AUTO_INCREMENT, -- 部门ID,设置主键自增属性dept_name varchar(50) NOT NULL, -- 部门名称location varchar(100), -- 位置budget decimal(15,2), -- 预算constraint uk_dept unique (dept_name) -- 取一个列名并添加唯一约束
)ENGINE=INNODB -- 符合INNODB存储引擎,支持事务ACID特性-- 创建员工表CREATE TABLE employees( emp_id INT PRIMARY KEY AUTO_INCREMENT, -- 员工编号emp_name VARCHAR(50) NOT NULL, -- 员工姓名email VARCHAR(100) UNIQUE, -- 员工邮箱hire_date DATE NOT NULL, -- 入职时间salary DECIMAL(10,2), -- 工资dept_id INT, -- 外键字段,关联部门表CONSTRAINT fk_emp_dept FOREIGN KEY (dept_id) REFERENCES departments(dept_id) -- 创建表外键的关系ON DELETE SET NULL -- 当部门被删除的时候,员工dept_id 设为NULLON UPDATE CASCADE -- 当部门dept_id更新的时候,同步更新
)ENGINE=INNODB; -- 创建项目表
CREATE TABLE projects(project_id INT AUTO_INCREMENT PRIMARY KEY,project_name VARCHAR(100) NOT NULL,start_date DATE,end_date DATE,budget DECIMAL(15,2)
)ENGINE=INNODB;-- 创建关联表
CREATE TABLE employee_projects(emp_id INT,project_id INT,join_date DATE NOT NULL,ROLEVARCHAR(50),PRIMARY KEY (emp_id,project_id), -- 复合主键CONSTRAINT fk_ep_emp FOREIGN KEY (emp_id)REFERENCES employees(emp_id)ON DELETE CASCADE, -- 员工删除时候删除关联记录CONSTRAINT fk_ep_project FOREIGN KEY(project_id)REFERENCES projects(project_id)ON DELETE CASCADE -- 项目删除的时候删除关联记录
)ENGINE=INNODB;载入数据
INSERT INTO departments (dept_name,location,budget) VALUES
('研发部','北京总部A座3层',5000000.00),
('市场部','北京总部A座2层',3000000.00),
('人力资源部','北京总部A座1层',1000000.00);
SELECT*FROM departments;-- 插入员工数据
INSERT INTO employees(emp_name,email,hire_date,salary,dept_id) VALUES
('张三','zhangsan@163.com','2020-01-15',15000.00,1),
('李四','lisi@163.com','2019-05-20',18000.00,1),
('王五','wangwu@163.com','2021-03-10',12000.00,2);
SELECT*FROM employees;-- 插入项目数据
INSERT INTO projects(project_name,start_date,end_date,budget) VALUES
('新零售平台开发','2023-01-01','2023-12-31',2000000.00),
('年度市场推广','2023-03-01','2023-11-30',50000.00);
SELECT*FROM projects;-- 建立多对多关联
INSERT INTO employee_projects(emp_id,project_id,join_date,ROLE) VALUES
(1,1,'2023-01-01','后端开发'),
(2,1,'2023-01-01','前端开发'),
(3,2,'2023-03-01','市场策划');
SELECT*FROM employee_projects;查询练习
-- 查询某部门所有员工
select e.emp_name,e.email,e.salary from employee e join department d on e.dept_id=d.dept_id
where d.dept_name='研发部'-- 查询员工参与的所有项目
SELECT p.project_name,p.start_date,p.end_date,ep.role
FROM employee_projects ep
JOIN projects p ON ep.project_id=p.project_id
JOIN employees e ON ep.emp_id=e.emp_id
WHERE e.emp_name='张三';-- 查询某项目的所有参与者以及其部门
SELECT e.emp_name,d.dept_name,ep.role
FROM employee_projects ep
JOIN employees e ON ep.emp_id=e.emp_id
LEFT JOIN departments d ON e.dept_id=d.dept_id
JOIN projects p ON ep.project_id=p.project_id
WHERE p.project_name='新零售平台开发';