Python----大模型(大模型基础)
一、大模型与人工智能关系
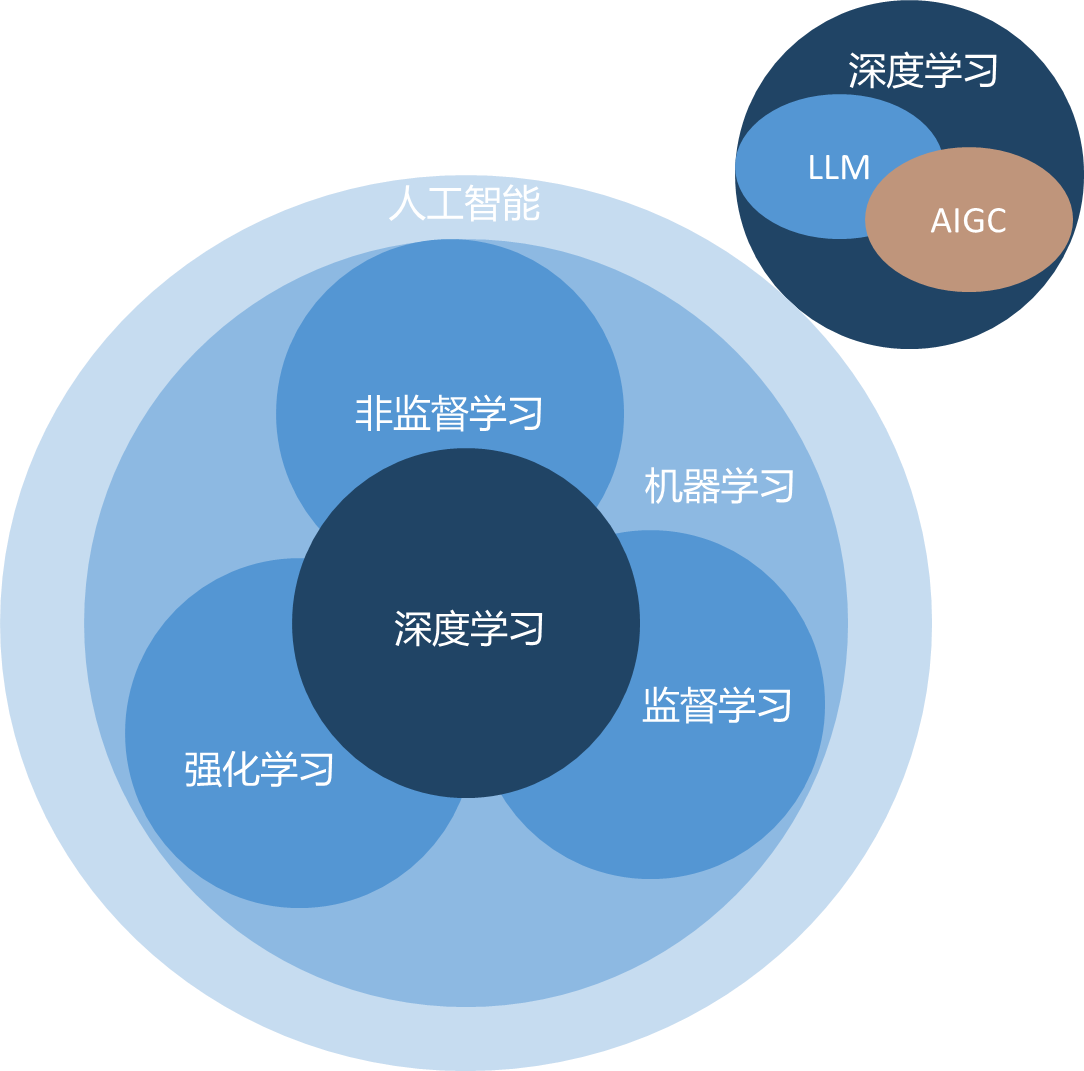
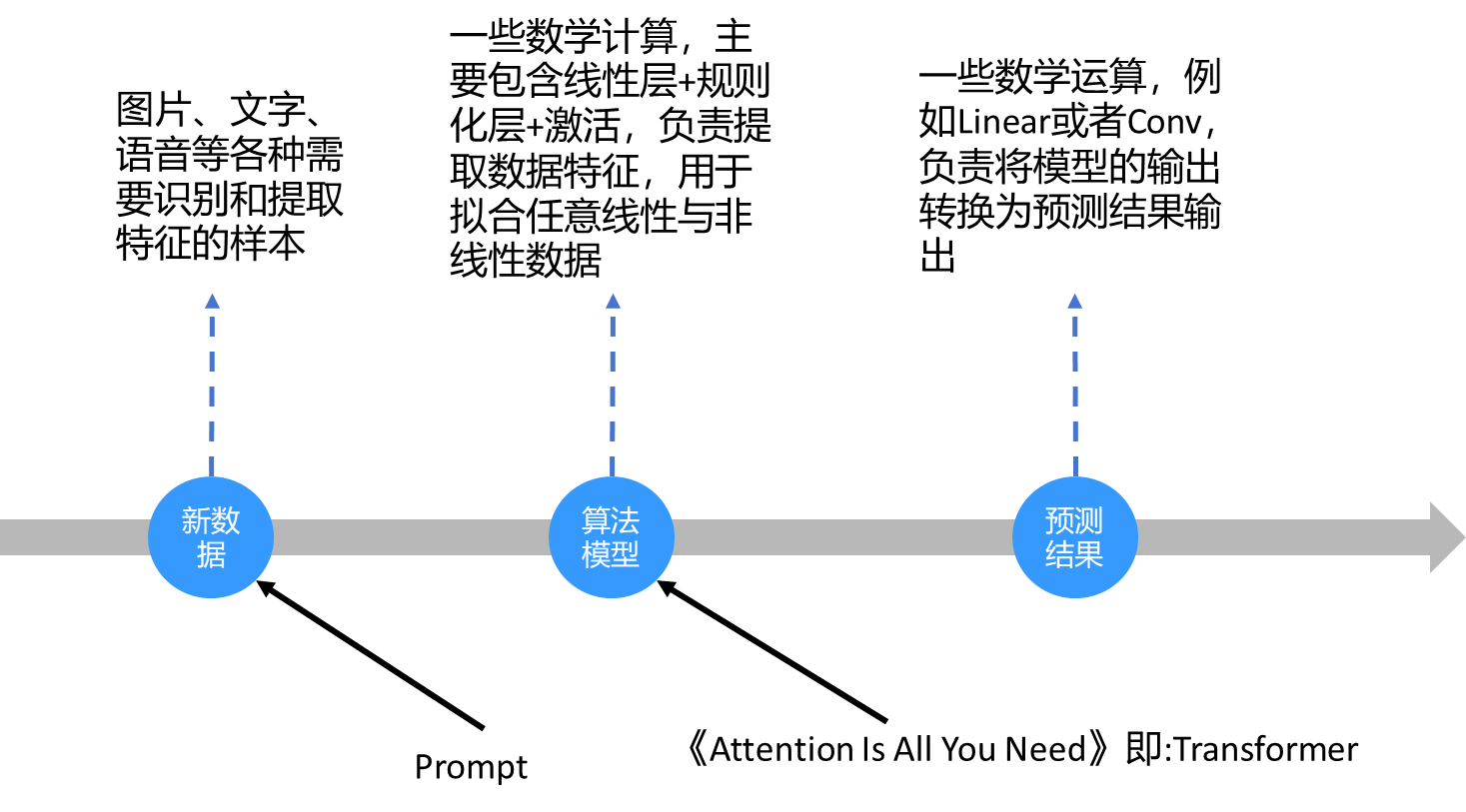
AIGC(Al Generated Content,也称生成式AI)
LLM(Large Language Model,也称大语言模型):大指的参数量大
AIGC是指利用人工智能技术自动生成内容,包括文本、图像、音频、视频等。LLM擅长处理和生成自然语言文本。它通过训练大量文本数据,能够学习语言的模式和规律,并基于这些模式和规律生成新的文本。
总结:LLM与AIGC是有交集的两种。
文生图的扩散模型(例如stable Diffusion)属于AIGC,但是不属于大语言模型。大语言模型也不是全部属于AIGC,例如Google的Bert是大语言模型(3.4亿参数),但是擅长的是协助Google检索和情感分析而非生成。
二、大语言模型的基础
2.1、前向过程
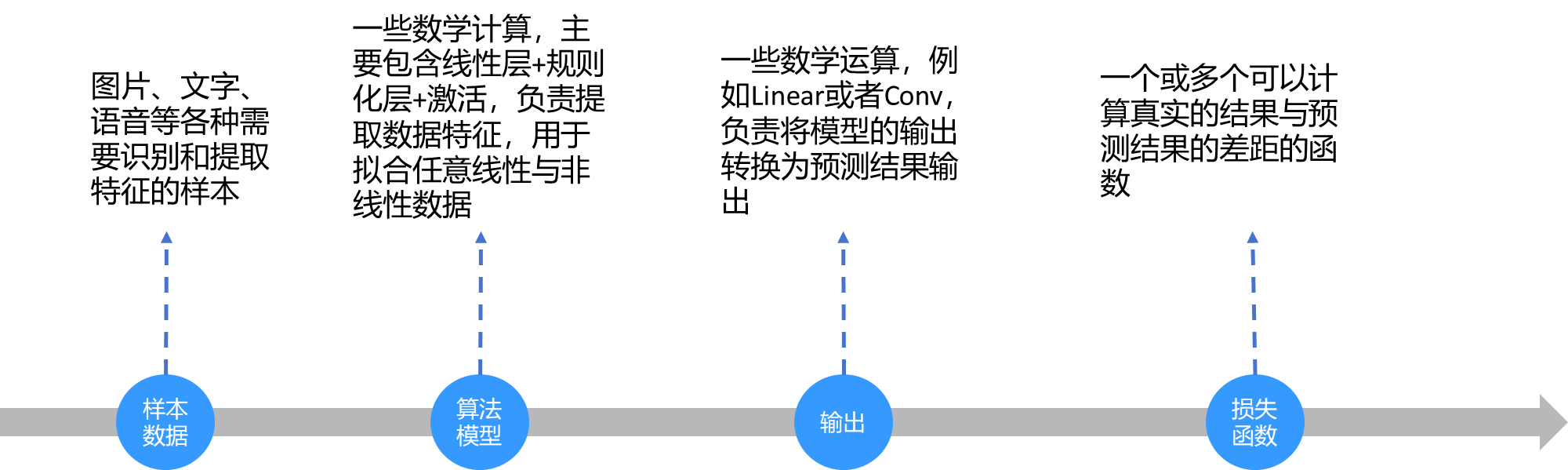
2.2、反向过程
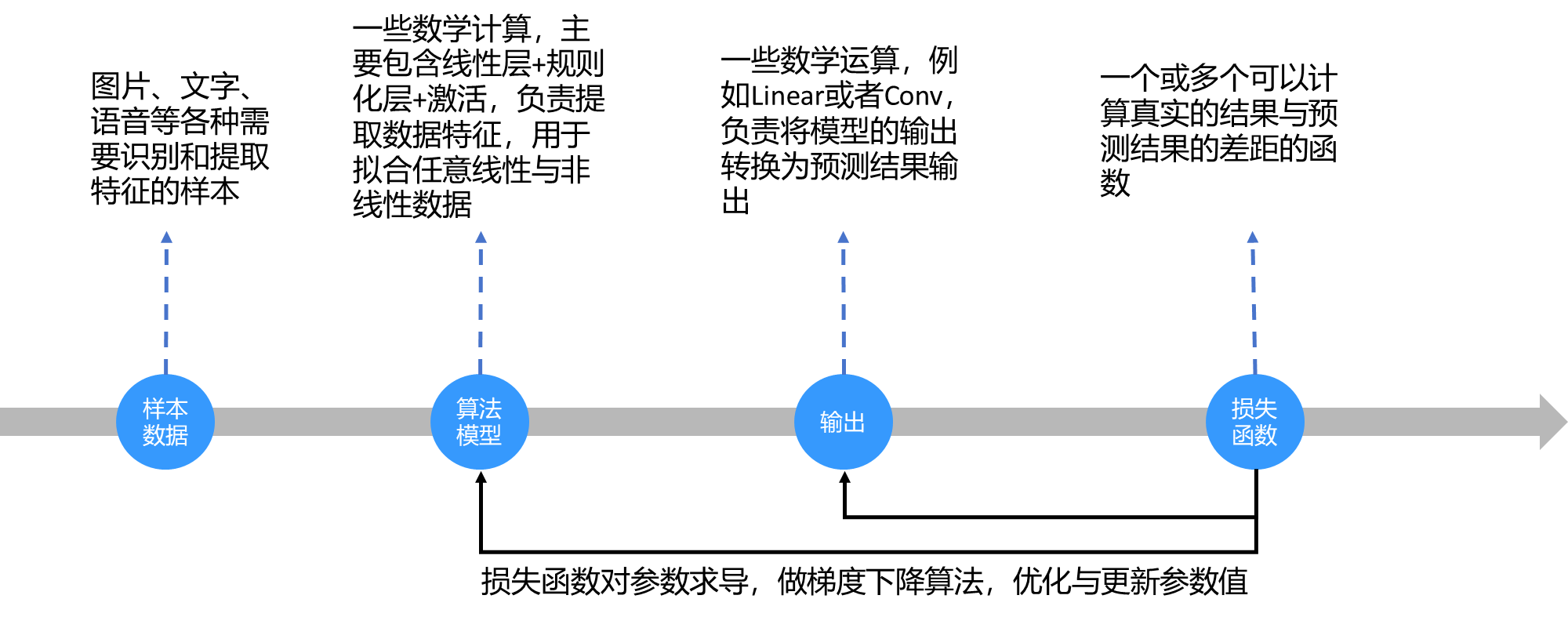
2.3、预测过程
三、RNN的处理方式
3.1、RNN示意图
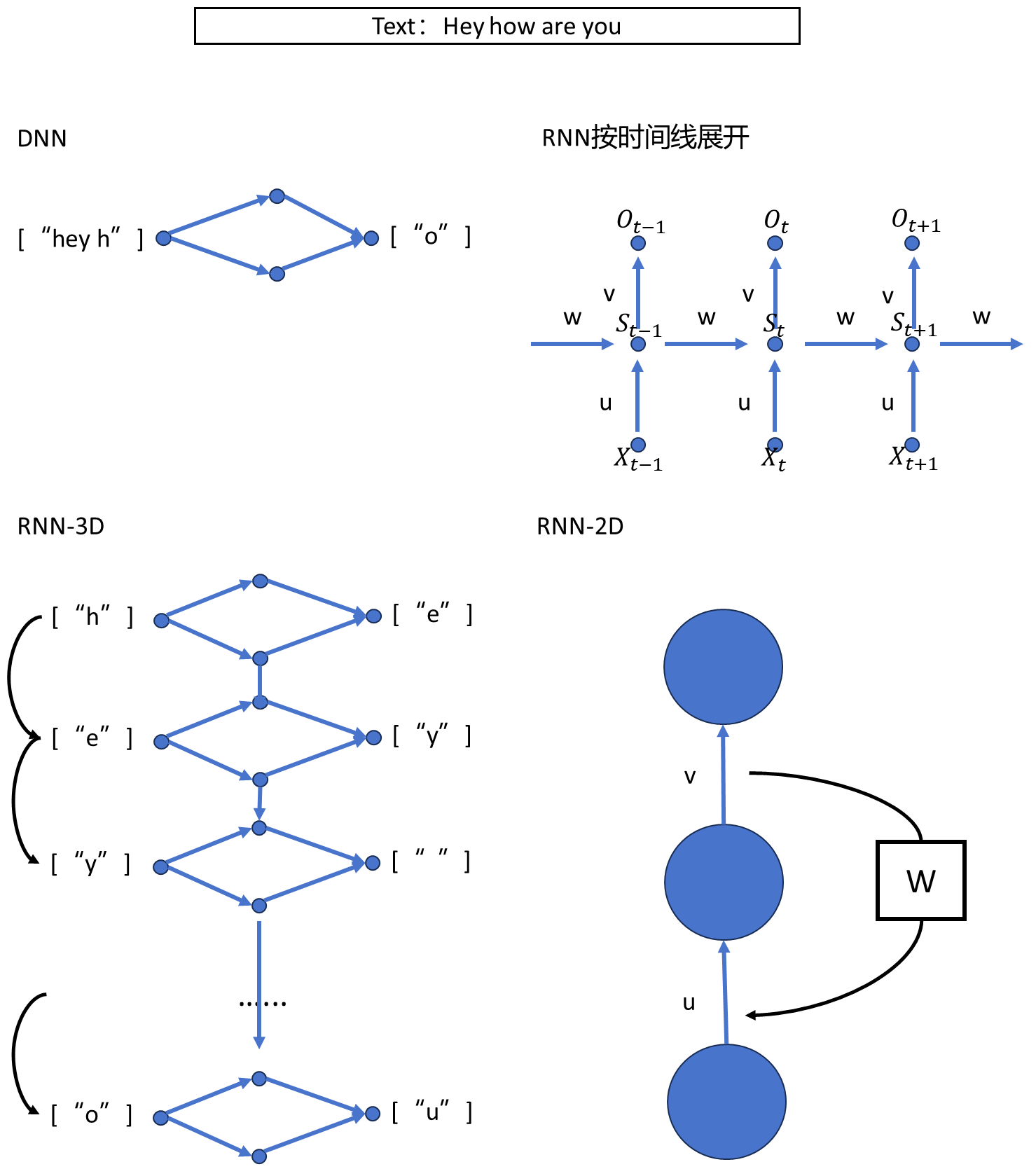
3.2、RNN的缺陷
1、网络的输出具有先后顺序性: 每一步运行输出取决于当前的输入与先 前的隐藏状态,上一步执行完,才会执 行下一步,无法并行计算。
2、记忆丢失: 先前的隐藏状态越往后,越记不住更早 的记忆,会造成记忆丢失,导致没办法 处理长文本,无法捕获长距离的语义关 系。
LSTM/GRU的出现缓解了第二个问题,但依然远远不够。
四、Transformer
目的:学习所有词的相关性和上下文 特征。
Transformer在处理 上下文的时候,不仅会注意到它自己 的词和附近的词,还会注意到序列里 其他的词,并为其赋予不同的权重。 所以能够拿到每一个词与其它所有词 的相关性,所以与距离无关。
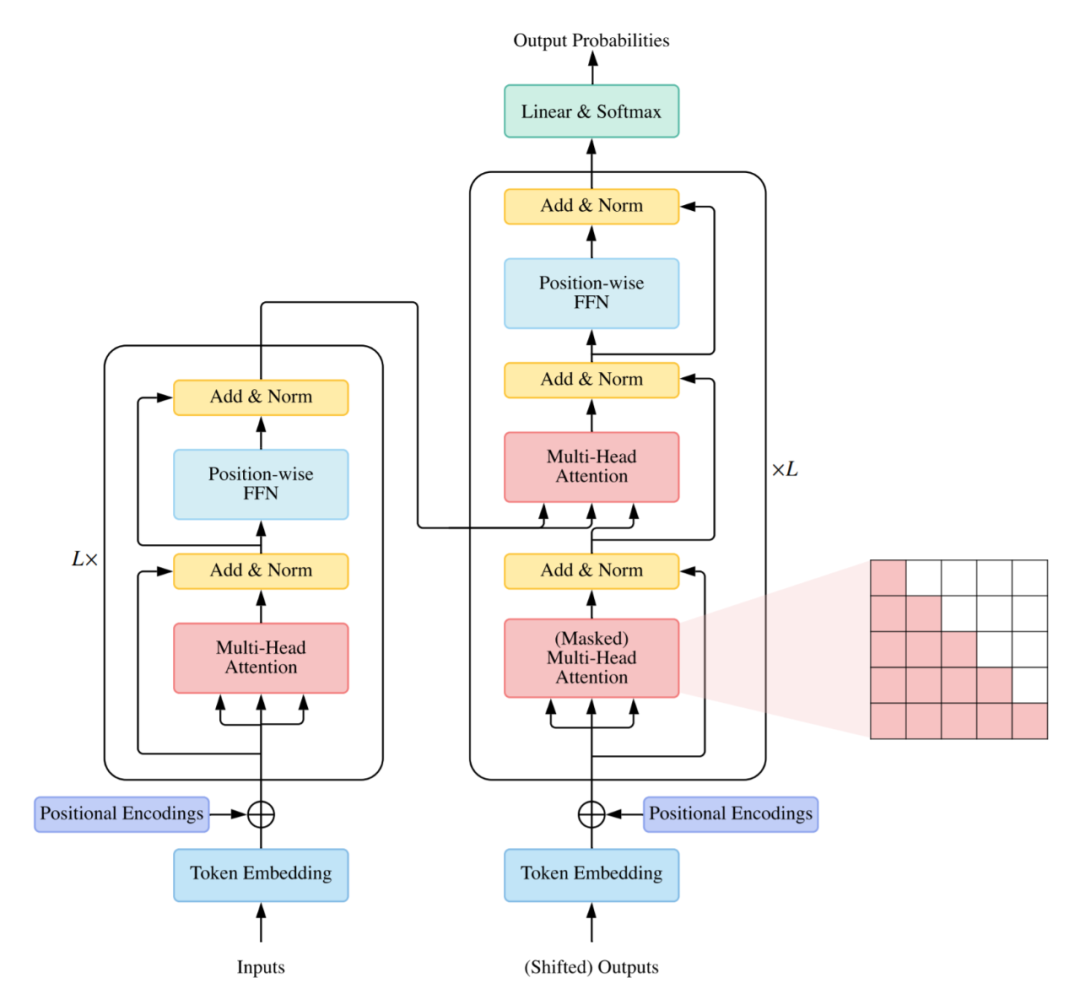
组成:
1、位置编码
2、Embedding词嵌入
3、编码器Encoder
4、解码器Decoder
编码器Encoder:获取某个token前后所有的每个token的特征。
解码器Decoder:基于以及生成的token前面所有的特征,生成新的 token。注意:生成的token后面的不获取。
五、大模型的发展
5.1、发展历程
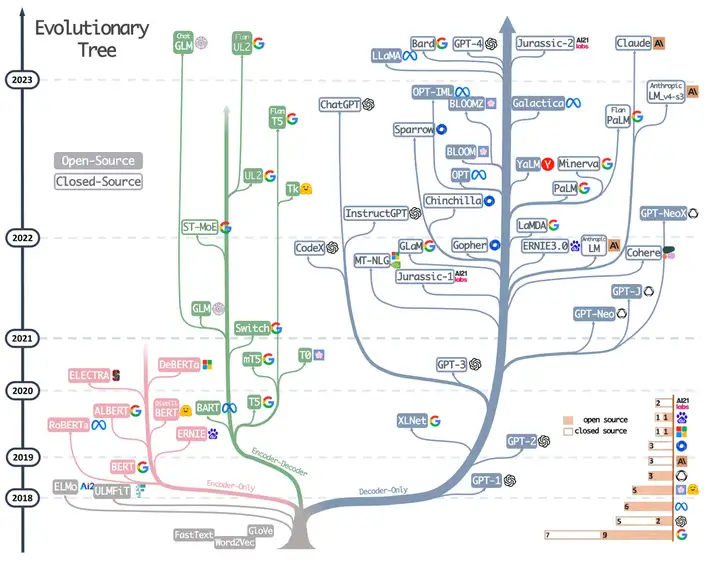
5.2、模型对比
| 模型类型 | 原理 | 优势 | 缺点 | 代表模型 | 应用场景 |
|---|---|---|---|---|---|
| 基于规则的模型 | 通过人工编写的语法规则和词典进行任务处理 | 逻辑清晰,可解释性强 | 只能处理少量数据和简单任务 | 无具体模型 | 机器翻译、信息检索 |
| 基于统计的模型 | 使用数学统计方法预测词序列概率(如N-gram) | 可处理更多数据和复杂任务 | 数据稀疏、历史长度受限 | N-gram | 语音识别、文本摘要 |
| 神经网络的模型 | 利用神经网络学习词的分布式表示和语言结构(如RNN、CNN、LSTM) | 处理大规模数据和复杂任务能力更强 | 依赖计算资源和训练数据 | RNN、CNN、LSTM | 情感分析、对话系统 |
| 基于预训练的模型 | 利用海量无标注文本进行自监督学习,再微调特定任务 | 泛化能力强,适应多任务和多领域 | 泛化能力受限、安全性问题 | BERT、GPT | 问答系统、知识图谱 |
| 基于大规模的模型 | 构建数百亿参数规模的深度神经网络,结合大规模无标注数据自监督学习 | 生成和推理能力极强,覆盖广泛任务 | 计算成本高,资源消耗大 | GPT-3、PaLM | 文本生成、复杂逻辑推理 |
5.3、开源模型
| 模型 | 发布时间 | 参数数量(B) | 基础模型 | 语料库大小 | 硬件 | 训练时间 |
|---|---|---|---|---|---|---|
| T5 | 2019.10 | 11 | - | 1T tokens | 1024 TPU v3 | - |
| PanGu-α | 2021.4 | 13 | - | 1.1TB | 2048 Ascend 910 | - |
| CPM-2 | 2021.6 | 198 | - | - | - | - |
| T0 | 2021.10 | 11 | T5 | - | 512 TPU v3 | 27h |
| CodeGen | 2022.3 | 16 | - | 825GB | - | - |
| GPT-NeoX-20B | 2022.4 | 20 | - | 577B tokens | 96 40G A100 | - |
| TK-Instruct | 2022.4 | 11 | T5 | - | 256 TPU v3 | 4h |
| UL2 | 2022.5 | 20 | - | 1T tokens | 512 TPU v4 | - |
| OTP | 2022.5 | 175 | - | 180B tokens | 992 80G A100 | - |
| NLLB | 2022.7 | 54.5 | - | - | - | - |
| CodeGeeX | 2022.9 | 13 | - | 850B tokens | 1536 Ascend 910 | 60 d |
| GLM | 2022.10 | 130 | - | 400B tokens | 768 40G A100 | 60 d |
| Flan-T5 | 2022.10 | 11 | T5 | - | - | - |
| BLOOM | 2022.11 | 176 | - | 366B tokens | 384 80G A100 | 105 d |
| mT0 | 2022.11 | 13 | - | - | - | - |
| Galactica | 2022.11 | 120 | - | 106B tokens | - | - |
| BLOOMZ | 2022.11 | 176 | BLOOM | - | - | - |
| OPT-IML | 2022.12 | 175 | OPT | - | 128 40G A100 | - |
| LLaMA | 2023.2 | 65 | - | 1.4T tokens | 2048 80G A100 | 21 d |
| Pythia | 2023.4 | 12 | - | 300B tokens | 256 40G A100 | - |
| CodeGeM2 | 2023.5 | 16 | - | 400B tokens | - | - |
| StarCoder | 2023.5 | 15.5 | - | 1T tokens | 512 40G A100 | - |
| LLaMA2 | 2023.7 | 70 | - | 2T tokens | 2000 80G A100 | - |
| Baichuan2 | 2023.9 | 13 | - | 2.6T tokens | 1024 A800 | - |
| QWEN | 2023.9 | 14 | - | 3T tokens | - | - |
| FLM | 2023.9 | 101 | - | 311B tokens | 192 A800 | 22 d |
| Skywork | 2023.10 | 13 | - | 3.2T tokens | 512 80G A800 | - |
5.4、闭源模型
| 模型 | 发布时间 | 参数数量(B) | 基础模型 | 语料库大小 | 硬件 | 训练时间 |
|---|---|---|---|---|---|---|
| GPT-3 | 2020.5 | 175 | - | 300B tokens | - | - |
| GShard | 2020.6 | 600 | - | 1T tokens | 2048 TPU v3 | 4d |
| Codex | 2021.7 | 12 | GPT-3 | 100B tokens | - | - |
| ERNIE 3.0 | 2021.7 | 10 | - | 375B tokens | 384 V100 | - |
| Jurassic-1 | 2021.8 | 178 | - | - | 512 TPU v3 | 27h |
| HyperCLOVA | 2021.9 | 82 | - | 300B tokens | 1024 A100 | 13.4 d |
| FLAN | 2021.9 | 137 | LaMDA-PT | - | 128 TPU v3 | 60 h |
| Yuan 1.0 | 2021.10 | 245 | - | 180B tokens | 2128 GPU | 4h |
| Anthropic | 2021.12 | 52 | - | 400B tokens | - | - |
| WebGPT | 2021.12 | - | GPT-3 | - | - | - |
| Gopher | 2021.12 | 280 | - | 300B tokens | 4096 TPU v3 | 920 h |
| ERNIE 3.0 Titan | 2021.12 | 260 | - | - | - | - |
| GLaM | 2021.12 | 1200 | - | 280B tokens | 1024 TPU v4 | 574 h |
| LaMDA | 2022.1 | 137 | - | 768B tokens | 1024 TPU v3 | 57.7 d |
| MT-NLG | 2022.1 | 530 | - | 270B tokens | 4480 80G A100 | - |
| AlphaCode | 2022.2 | 41 | - | 967B tokens | - | - |
| InstructGPT | 2022.3 | 175 | GPT-3 | - | - | - |
| Chinchilla | 2022.3 | 70 | - | 1.4T tokens | - | - |
| PaLM | 2022.4 | 540 | - | 780B tokens | 6144 TPU v4 | - |
| AlexaTM | 2022.8 | 20 | - | 1.3T tokens | 128 A100 | 120 d |
| Sparrow | 2022.9 | 70 | - | - | 64 TPU v3 | - |
| WeLM | 2022.9 | 10 | - | 300B tokens | 128 40G A100 | 24 d |
| U-PaLM | 2022.10 | 540 | PaLM | - | 512 TPU v4 | 5 d |
| Flan-PaLM | 2022.10 | 540 | PaLM | - | 512 TPU v4 | 37 hd |
| Flan-U-PaLM | 2022.10 | 540 | U-PaLM | - | - | - |
| GPT-4 | 2023.3 | (未知) | - | (多模态, 大) | (未知) | - |
| PanGu-Σ | 2023.3 | 1085 | PanGu-α | 329B tokens | 512 Ascend 910 | 100 d |
| PaLM2 | 2023.5 | 16 | - | 100B tokens | - | - |
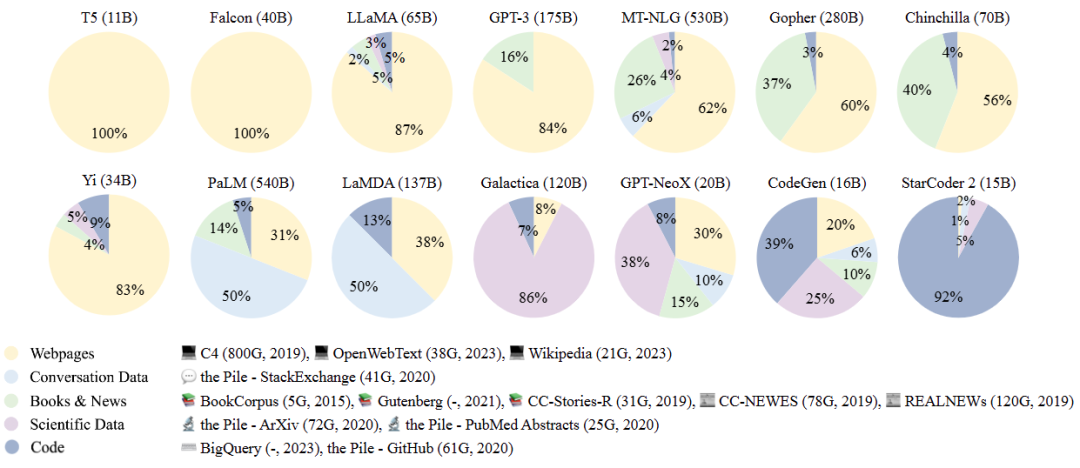
5.5、 不同模型所用数据集的差异