开放词汇检测分割YOLOE从pytorch到caffe
开放词汇检测分割YOLOE从pytorch到caffe
- 0. 前沿
- 开放词汇检测的概念
- CLIP模型
- 1. YOLOE 环境配置
- 1.1 虚拟环境
- 1.2 YOLOE 模型推理测试
- 1.2.1 文本提示检测和分割测试
- 1.2.2 无提示检测和分割
- 2.YOLOE网络结构分析
- 2.1 网络结构概述
- 2.2 可重参数化区域-文本对齐(Re-parameterizable region-text alignment: RepRTA)
- 2.3 语义激活视觉提示编码器(Semantic-activated visual prompt encoder: SAVPE)
- 2.4 懒惰区域-提示对比(Lazy region-prompt contrast: LRPC)
- 3. YOLOE模型导出
- 3.1 修改head.py
- 3.2 修改`ultralytics/engine/exporter.py`
- 3.3 `python export.py `导出onnx模型
- 4. onnx转caffemodel
0. 前沿
一直在用YOLO系列进行目标检测、分割和关键点检测等任务,基于对YOLO-world的了解,进一步认识了开放词汇检测,简单来说就是在原有固定类别的检测器上进行类别数量提升,基于CLIP的文本embedding能力,可以将任意标签转换为512维度的特征向量,将其与图片目标特征进行对比学习,获得目标的匹配类别。YOLOE在检测的基础上补充了分割任务,能够直接实现实例分割的移植和部署;
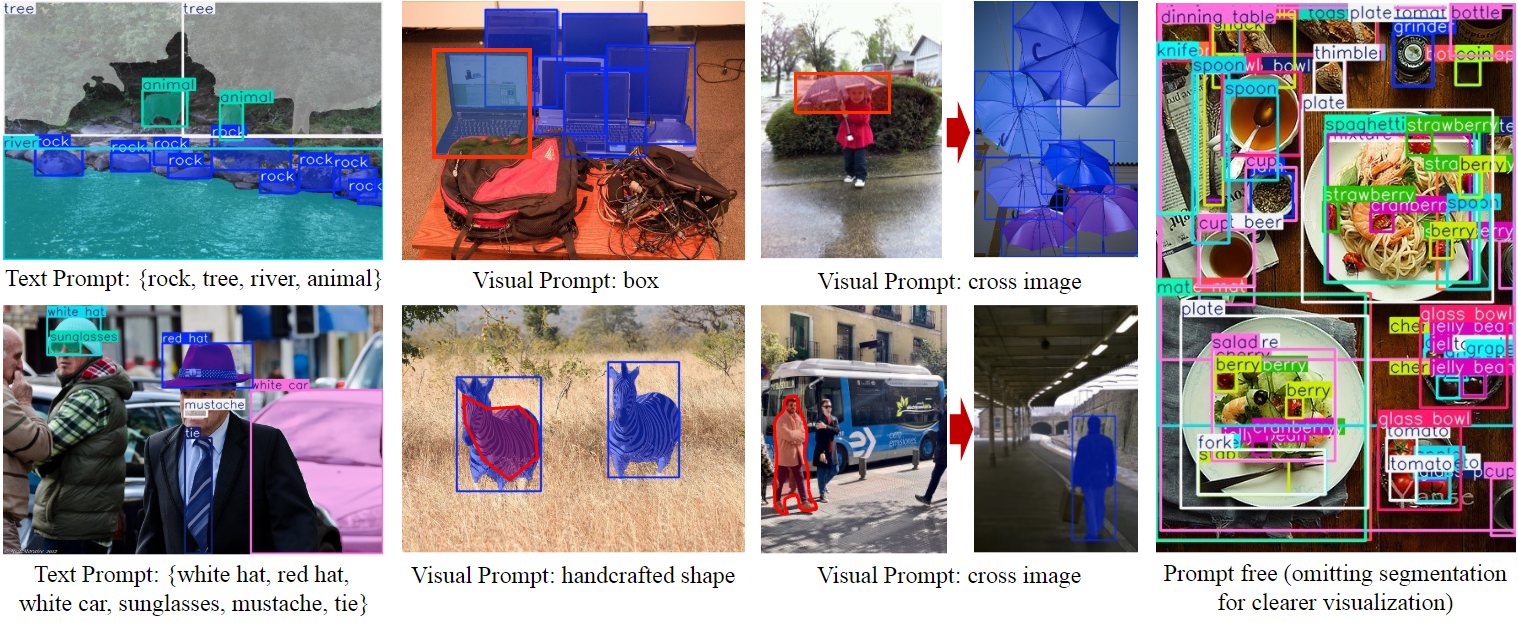
从最后的部署应用来看,在考虑到边缘端的推理效率,采用了重参化移植,export时指定label后,模型的结构和原来的YOLOv8s是一样的,所以总体感觉开放词汇在边缘端还是趋向于闭集检测,优势在于能够进行预标注,对提高新样本的标注效率有一定的帮助。(基于当前认知的感受,后续补充)。本文将针对YOLOE从0到1进行模型的移植部署,整体属于入门级别,没有进行模型微调(微调后会对参与训练的样本精度提升,但其他样本骤降),只对预训练模型进行caffemodel的转换并部