2025-06-02-数据库的分类和应用
数据库的分类和应用
参考资料
- 数据库介绍与分类 - 随心朝阳 - 博客园
- 众多的数据库类型,你该怎么选择? | Amazon Web Services
- 数据库类型:2025 年需要了解的一切 | Astera
- 面向对象数据库详解:概念、设计与优化-CSDN 博客
- 面向对象数据库解析-CSDN 博客
- www.cnblogs.com
概述
数据库就是一个存放数据的仓库,这个仓库按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织存储的,我们可以通过数据库提供的多种方法来管理数据库里的数据。
我们的程序都是在内存中运行的,一旦程序运行结束或者计算机断电,程序运行中的数据都会丢失,所以我们就需要将一些程序运行的数据持久化到硬盘之中,以确保数据的安全性。说白了,数据库就是存储数据的仓库。
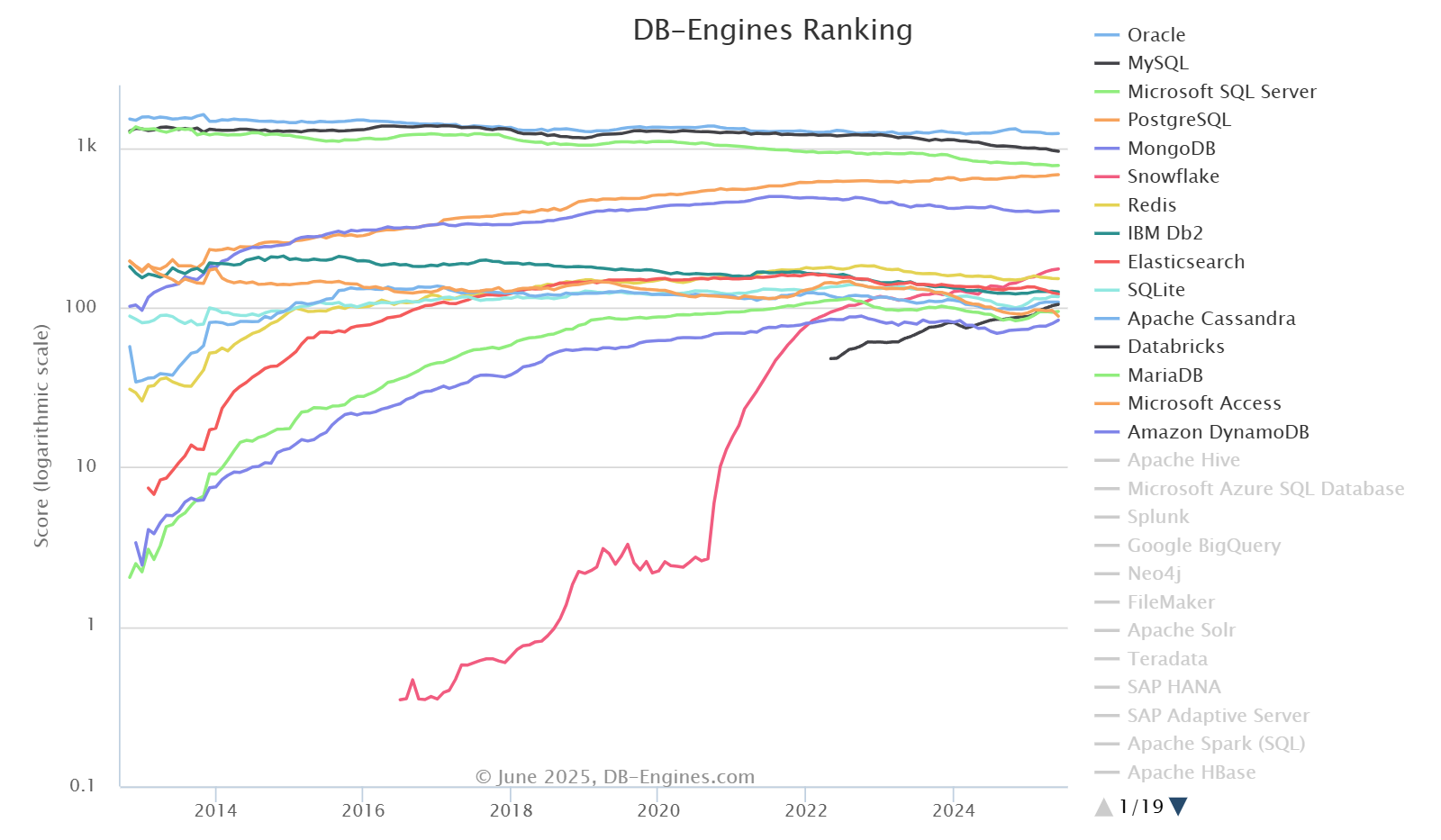
下面是数据库引擎的实时排名网站
- DB-Engines Ranking
关系型数据库(RDBMS)
关系型数据库以表—行—列结构存储数据,通过外键管理实体间关联,支持复杂联表和事务处理,是最成熟的数据库类型 。它使用 ANSI SQL 作为标准查询语言,可执行多表 JOIN、子查询和存储过程等操作,满足 OLTP(联机事务处理)场景需求 。
架构与事务
主流 RDBMS 如 MySQL(InnoDB 引擎)和 PostgreSQL 采用多版本并发控制(MVCC)实现高并发读写,同时提供行级锁、两阶段锁等机制保证隔离性 。在分布式部署中,一般通过主从复制、读写分离、分库分表或中间件 ShardingSphere 实现水平扩展,解决单机性能瓶颈。
性能优化
- 索引设计:B+ 树、哈希索引和全文索引,各有取舍;
- 查询优化:执行计划(EXPLAIN)、覆盖索引、分区表减少 I/O;
- 缓存机制:如 MySQL Query Cache(已弃用)与 Buffer Pool;
- 物理架构:SSD 替换 HDD、NUMA 拆分及内存调优 。
典型应用
- 电商订单系统:保证库存扣减的强一致性与事务原子性;
- 金融支付场景:对账、清分要求 ACID 特性;
- 企业级 CRM/ERP:多表联动,复杂报表生成 。
NoSQL 数据库
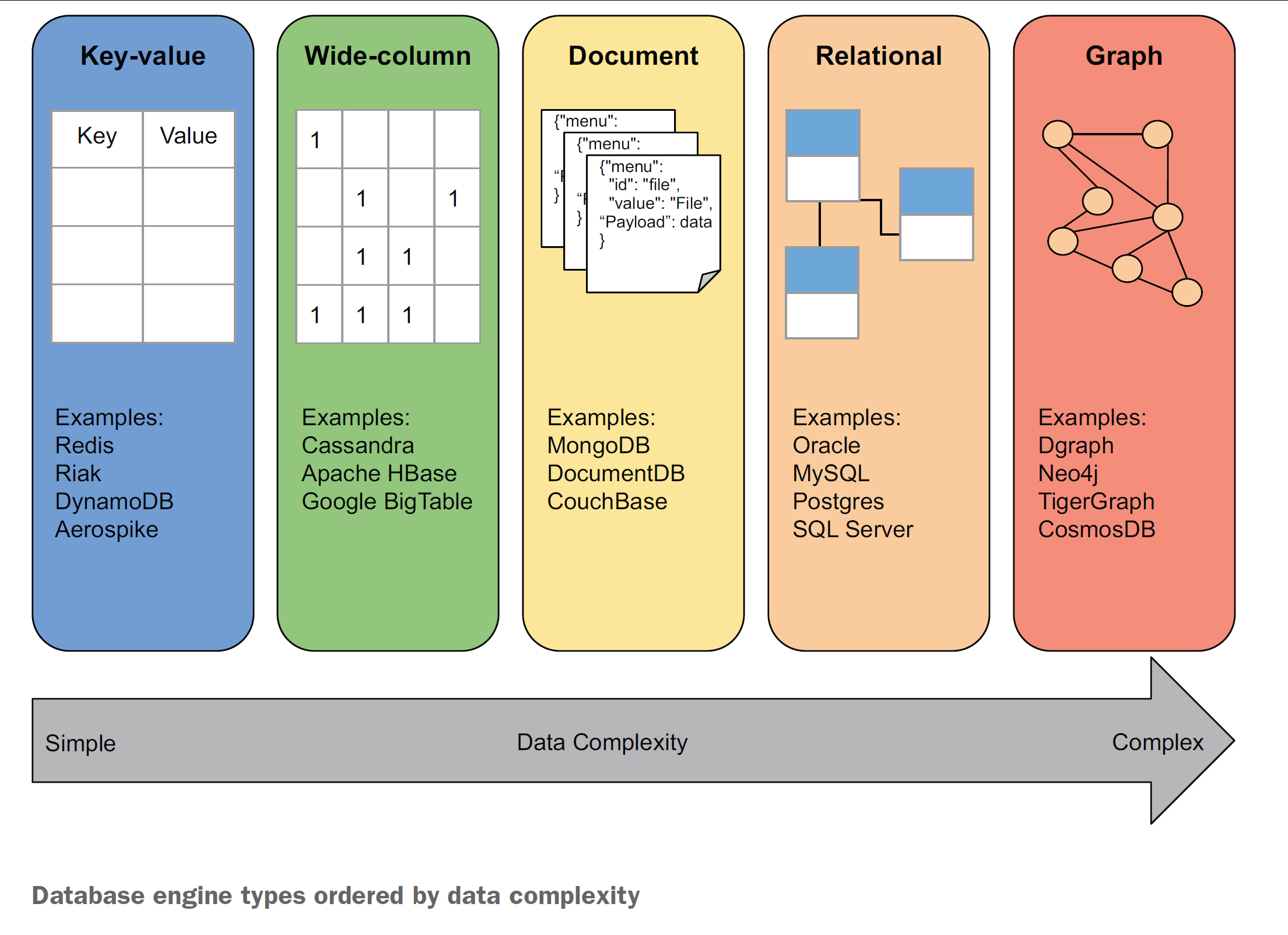
NoSQL 数据库借助灵活的数据模型和可线性扩展架构,应对大数据、高并发与非结构化场景。主要分为以下几类:
键值存储(Key–Value)
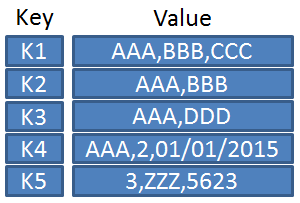
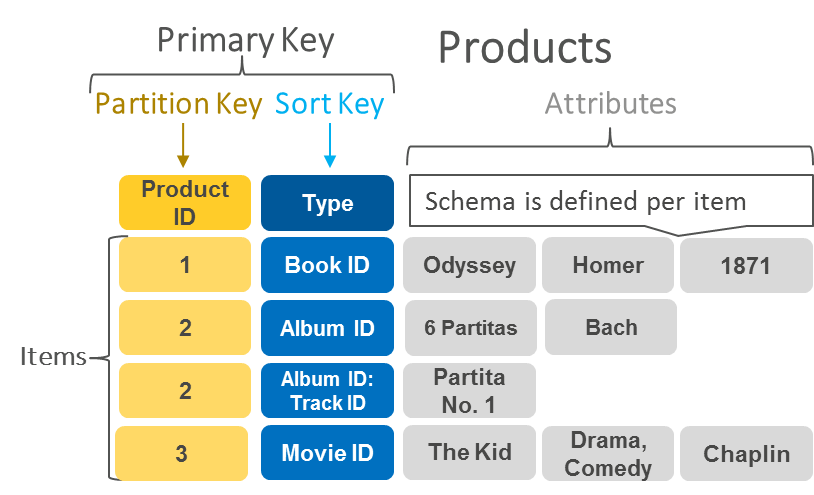
键值数据库以唯一键(Key)直接定位值(Value),最典型产品是 Redis 与 Memcached 。
- Redis 支持字符串、列表、集合、有序集合及哈希等多种数据类型,并提供持久化(RDB/AOF)与主从复制功能,可用作缓存、分布式锁、消息队列等 。
- Memcached 轻量且高性能,专注内存缓存,适合对持久化需求不高的场景 。
文档存储(Document)
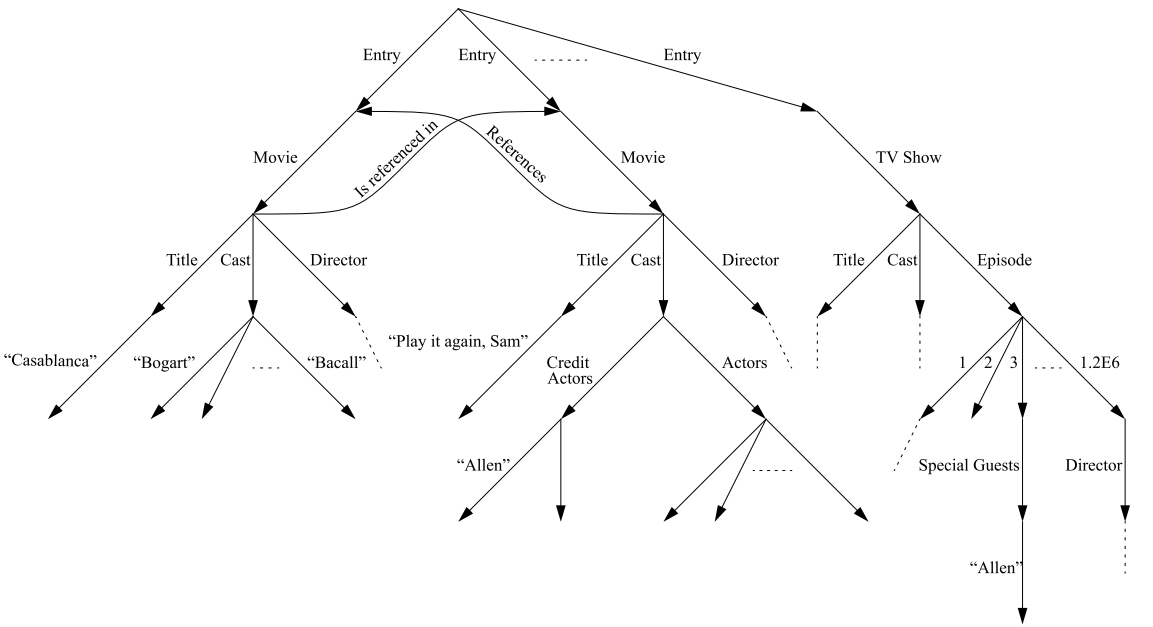
文档数据库以 JSON/BSON 形式存储半结构化数据,Collections 与 Documents 对应 RDBMS 的表与行。
- MongoDB 提供二级索引、聚合框架与复制集、分片集群,可动态 Schema、轻松存储嵌套对象,常用于内容管理、用户画像和配置中心 。
- Amazon DocumentDB(兼容 MongoDB)则是托管型服务,简化集群管理 。
列族存储(Column-Family)
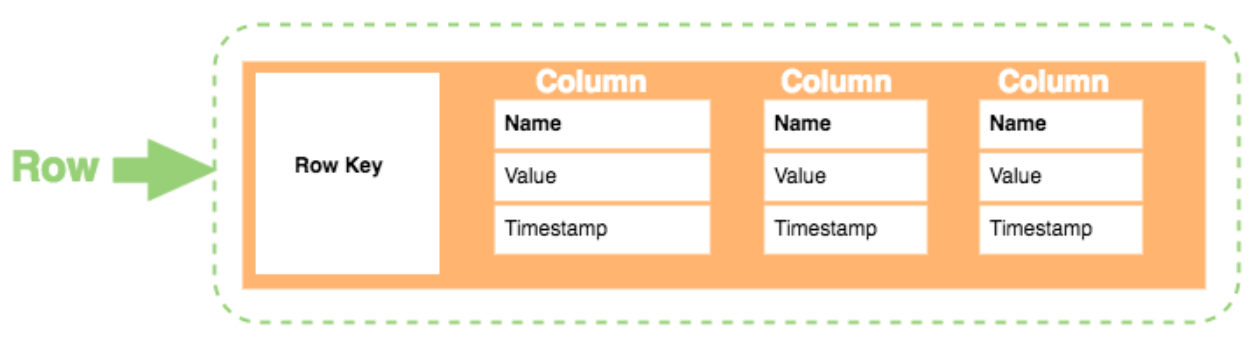
列族数据库以列簇方式存储行数据,适合宽表和稀疏表场景 。
- Apache Cassandra 采用去中心化 P2P 架构,利用 Gossip 协议和一致性哈希分布数据,支持跨 DC 多活部署;
- Apache HBase 构建于 HDFS 之上,通过 RegionServer 管理数据分片,擅长大规模时序和日志数据存储 。
这两者广泛应用于物联网指标存储、用户行为日志及大规模特征库等场景 。
图数据库(Graph)
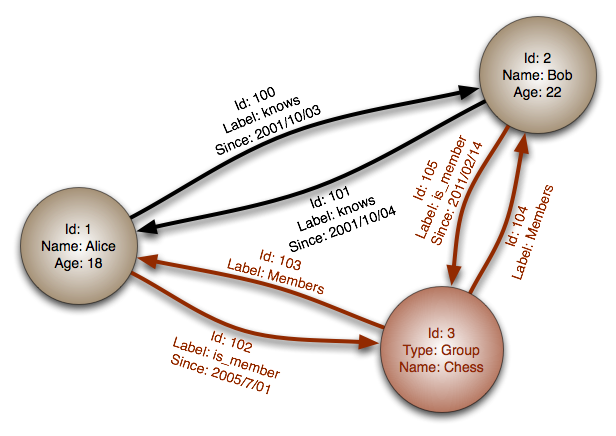
图数据库基于属性图模型,节点(Node)和边(Edge)存储实体及其关系,擅长多跳遍历与图算法。
- Neo4j 原生支持 ACID 图事务和 Cypher 查询语言,适合社交网络、知识图谱及欺诈检测场景 。
- JanusGraph 支持后端 Cassandra、HBase 存储,可结合 Gremlin 实现分布式图计算 。
面向对象数据库(OODBMS)
- ORM 实例教程 - 阮一峰的网络日志
ORM 实例
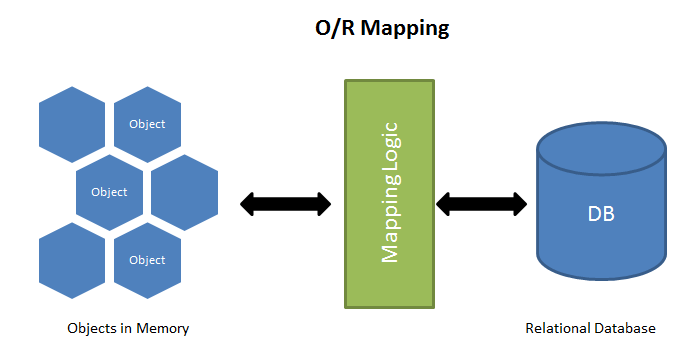
简单说,ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术,是"对象-关系映射"(Object/Relational Mapping) 的缩写。
ORM 把数据库映射成对象。

面向对象数据库将 OOP 对象直接存储于数据库,支持类、继承与方法 。它适用于 CAD/CAE、嵌入式系统与 GIS 等复杂对象场景,避免了 ORM 带来的映射开销。
层次式与网状数据库
- 层次式数据库(IMS、Windows 注册表)使用父子一对多结构,检索效率高但缺乏灵活性 。
- 网状数据库 允许多对多父子关系,曾用于大型主机系统,如 IDMS,但因查询复杂逐步被关系型数据库取代 。
NewSQL:ACID + 分布式扩展
NewSQL 兼顾了关系型 SQL 事务和 NoSQL 的水平扩展能力,通常基于 Raft、Paxos 或 Google TrueTime 协议实现分布式一致性 。
- TiDB 通过 PD+TiKV 自动分片、调度,兼容 MySQL 协议,适用于流量大、节点众多的 OLTP 场景 。
- CockroachDB 利用 Raft 保证多副本强一致,支持多活部署;
- Google Spanner 则借助硬件时钟同步提供全球一致性 。
NewSQL 常见于互联网金融、全链路电商订单等要求强一致且海量扩展的场景 。
专用型数据库
时序数据库
针对时间序列做了专门优化,包括写密集、压缩、高效时间窗口查询 。
- InfluxDB 的 TSM 引擎和 TICK Stack 生态;
- TimescaleDB 基于 PostgreSQL 分区表实现,兼容 SQL 与生态 。
地理空间数据库
- PostGIS 在 PostgreSQL 上提供 GiST 空间索引;
- MongoDB 2dsphere 支持 GeoJSON 查询 。
全文搜索与分析引擎
- Elasticsearch 基于 Lucene,支持倒排索引、聚合分析及 Near Real-Time(NRT)搜索 。
- 常与 Logstash/Beats/Kibana 构建 ELK 堆栈,用于日志收集、处理与可视化 。
混合架构与选型指南
大型系统普遍采用 Polyglot Persistence,不同业务模块选用最合适的存储引擎:
- 缓存层:Redis/Memcached 提升读写性能 。
- 核心事务:MySQL/PostgreSQL 或 TiDB/CockroachDB 保证 ACID 。
- 流式处理:Kafka、RabbitMQ 解耦异步;
- 实时 BI:Elasticsearch/ClickHouse 提供快速聚合 。
选型建议
- 强一致事务 → 关系型/NewSQL
- 超高并发缓存 → Redis/Memcached
- 半结构化文档 → MongoDB/DocumentDB
- 宽表稀疏存储 → Cassandra/HBase
- 复杂关系分析 → Neo4j/JanusGraph
- 时序数据 → InfluxDB/TimescaleDB
- 全文检索 → Elasticsearch